基于C#实现外排序
一、N 路归并排序
1.1、概序
我们知道算法中有一种叫做分治思想,一个大问题我们可以采取分而治之,各个突破,当子问题解决了,大问题也就 KO 了,还有一点我们知道内排序的归并排序是采用二路归并的,因为分治后有 LogN 层,每层两路归并需要 N 的时候,最后复杂度为 NlogN,那么外排序我们可以将这个“二”扩大到 M,也就是将一个大文件分成 M 个小文件,每个小文件是有序的,然后对应在内存中我们开 M 个优先队列,每个队列从对应编号的文件中读取 TopN 条记录,然后我们从 M 路队列中各取一个数字进入中转站队列,并将该数字打上队列编号标记,当从中转站出来的最小数字就是我们最后要排序的数字之一,因为该数字打上了队列编号,所以方便我们通知对应的编号队列继续出数字进入中转站队列,可以看出中转站一直保存了 M 个记录,当中转站中的所有数字都出队完毕,则外排序结束。如果大家有点蒙的话,我再配合一张图,相信大家就会一目了然,这考验的是我们的架构能力。
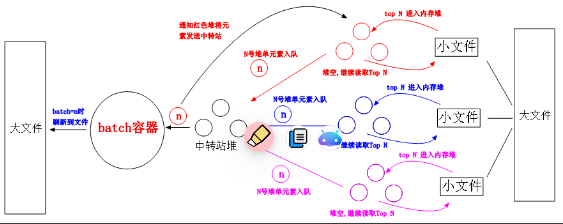
图中这里有个 Batch 容器,这个容器我是基于性能考虑的,当 batch=n 时,我们定时刷新到文件中,保证内存有足够的空间。
1.2、构建
<1> 生成数据
这个基本没什么好说的,采用随机数生成 n 条记录。
<2> 切分数据
根据实际情况我们来决定到底要分成多少个小文件,并且小文件的数据必须是有序的,小文件的个数也对应这内存中有多少个优先队列。
<3> 加入队列
我们知道内存队列存放的只是小文件的 topN 条记录,当内存队列为空时,我们需要再次从小文件中读取下一批的 TopN 条数据,然后放入中转站继续进行比较。
<4> 测试
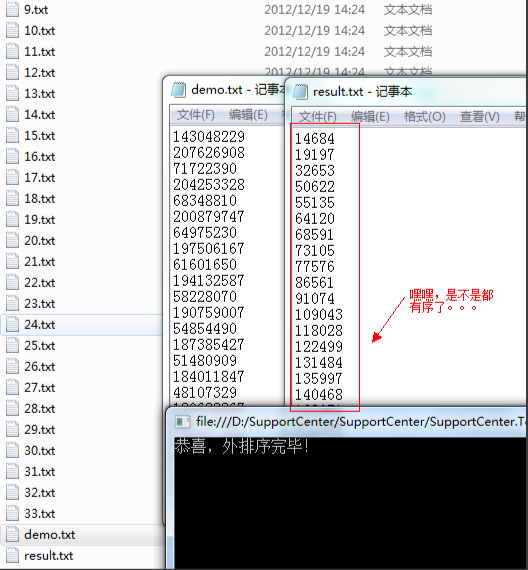
最后我们来测试一下:
数据量:short.MaxValue。
内存存放量:1200。
在这种场景下,我们决定每个文件放 1000 条,也就有 33 个小文件,也就有 33 个内存队列,每个队列取 Top100 条,Batch=500 时刷新
硬盘,中转站存放 332 个数字(因为入中转站时打上了队列标记),最后内存活动最大总数为:sum=33100+500+66=896<1200。
时间复杂度为 N*logN。
总的代码:
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Diagnostics;using System.Threading;using System.IO;using System.Threading.Tasks;namespace ConsoleApplication2{public class Program{public static void Main(){//生成2^15数据CreateData(short.MaxValue);//每个文件存放1000条var pageSize = 1000;//达到batchCount就刷新记录var batchCount = 0;//判断需要开启的队列var pageCount = Split(pageSize);//内存限制:1500条List<PriorityQueue<int?>> list = new List<PriorityQueue<int?>>();//定义一个队列中转器PriorityQueue<int?> queueControl = new PriorityQueue<int?>();//定义每个队列完成状态bool[] complete = new bool[pageCount];//队列读取文件时应该跳过的记录数int[] skip = new int[pageCount];//是否所有都完成了int allcomplete = 0;//定义 10 个队列for (int i = 0; i < pageCount; i++){list.Add(new PriorityQueue<int?>());//i: 记录当前的队列编码//list: 队列数据//skip:跳过的条数AddQueue(i, list, ref skip);}//初始化操作,从每个队列中取出一条记录,并且在入队的过程中//记录该数据所属的 “队列编号”for (int i = 0; i < list.Count; i++){var temp = list[i].Dequeue();//i:队列编码,level:要排序的数据queueControl.Eequeue(i, temp.level);}//默认500条写入一次文件List<int> batch = new List<int>();//记录下次应该从哪一个队列中提取数据int nextIndex = 0;while (queueControl.Count() > 0){//从中转器中提取数据var single = queueControl.Dequeue();//记录下一个队列总应该出队的数据nextIndex = single.t.Value;var nextData = list[nextIndex].Dequeue();//如果改对内弹出为null,则说明该队列已经,需要从nextIndex文件中读取数据if (nextData == null){//如果该队列没有全部读取完毕if (!complete[nextIndex]){AddQueue(nextIndex, list, ref skip);//如果从文件中读取还是没有,则说明改文件中已经没有数据了if (list[nextIndex].Count() == 0){complete[nextIndex] = true;allcomplete++;}else{nextData = list[nextIndex].Dequeue();}}}//如果弹出的数不为空,则将该数入中转站if (nextData != null){//将要出队的数据 转入 中转站queueControl.Eequeue(nextIndex, nextData.level);}batch.Add(single.level);//如果batch=500,或者所有的文件都已经读取完毕,此时我们要批量刷入数据if (batch.Count == batchCount || allcomplete == pageCount){var sw = new StreamWriter(Environment.CurrentDirectory + "//result.txt", true);foreach (var item in batch){sw.WriteLine(item);}sw.Close();batch.Clear();}}Console.WriteLine("恭喜,外排序完毕!");Console.Read();}#region 将数据加入指定编号队列/// <summary>/// 将数据加入指定编号队列/// </summary>/// <param name="i">队列编号</param>/// <param name="skip">文件中跳过的条数</param>/// <param name="list"></param>/// <param name="top">需要每次读取的条数</param>public static void AddQueue(int i, List<PriorityQueue<int?>> list, ref int[] skip, int top = 100){var result = File.ReadAllLines((Environment.CurrentDirectory + "//" + (i + 1) + ".txt")).Skip(skip[i]).Take(top).Select(j => Convert.ToInt32(j));//加入到集合中foreach (var item in result)list[i].Eequeue(null, item);//将个数累计到skip中,表示下次要跳过的记录数skip[i] += result.Count();}#endregion#region 随机生成数据/// <summary>/// 随机生成数据///<param name="max">执行生成的数据上线</param>/// </summary>public static void CreateData(int max){var sw = new StreamWriter(Environment.CurrentDirectory + "//demo.txt");for (int i = 0; i < max; i++){Thread.Sleep(2);var rand = new Random((int)DateTime.Now.Ticks).Next(0, int.MaxValue >> 3);sw.WriteLine(rand);}sw.Close();}#endregion#region 将数据进行分份/// <summary>/// 将数据进行分份/// <param name="size">每页要显示的条数</param>/// </summary>public static int Split(int size){//文件总记录数int totalCount = 0;//每一份文件存放 size 条 记录List<int> small = new List<int>();var sr = new StreamReader((Environment.CurrentDirectory + "//demo.txt"));var pageSize = size;int pageCount = 0;int pageIndex = 0;while (true){var line = sr.ReadLine();if (!string.IsNullOrEmpty(line)){totalCount++;//加入小集合中small.Add(Convert.ToInt32(line));//说明已经到达指定的 size 条数了if (totalCount % pageSize == 0){pageIndex = totalCount / pageSize;small = small.OrderBy(i => i).Select(i => i).ToList();File.WriteAllLines(Environment.CurrentDirectory + "//" + pageIndex + ".txt", small.Select(i => i.ToString()));small.Clear();}}else{//说明已经读完了,将剩余的small记录写入到文件中pageCount = (int)Math.Ceiling((double)totalCount / pageSize);small = small.OrderBy(i => i).Select(i => i).ToList();File.WriteAllLines(Environment.CurrentDirectory + "//" + pageCount + ".txt", small.Select(i => i.ToString()));break;}}return pageCount;}#endregion}}
优先队列:
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Diagnostics;using System.Threading;using System.IO;namespace ConsoleApplication2{public class PriorityQueue<T>{/// <summary>/// 定义一个数组来存放节点/// </summary>private List<HeapNode> nodeList = new List<HeapNode>();#region 堆节点定义/// <summary>/// 堆节点定义/// </summary>public class HeapNode{/// <summary>/// 实体数据/// </summary>public T t { get; set; }/// <summary>/// 优先级别 1-10个级别 (优先级别递增)/// </summary>public int level { get; set; }public HeapNode(T t, int level){this.t = t;this.level = level;}public HeapNode() { }}#endregion#region 添加操作/// <summary>/// 添加操作/// </summary>public void Eequeue(T t, int level = 1){//将当前节点追加到堆尾nodeList.Add(new HeapNode(t, level));//如果只有一个节点,则不需要进行筛操作if (nodeList.Count == 1)return;//获取最后一个非叶子节点int parent = nodeList.Count / 2 - 1;//堆调整UpHeapAdjust(nodeList, parent);}#endregion#region 对堆进行上滤操作,使得满足堆性质/// <summary>/// 对堆进行上滤操作,使得满足堆性质/// </summary>/// <param name="nodeList"></param>/// <param name="index">非叶子节点的之后指针(这里要注意:我们/// 的筛操作时针对非叶节点的)/// </param>public void UpHeapAdjust(List<HeapNode> nodeList, int parent){while (parent >= 0){//当前index节点的左孩子var left = 2 * parent + 1;//当前index节点的右孩子var right = left + 1;//parent子节点中最大的孩子节点,方便于parent进行比较//默认为left节点var min = left;//判断当前节点是否有右孩子if (right < nodeList.Count){//判断parent要比较的最大子节点min = nodeList[left].level < nodeList[right].level ? left : right;}//如果parent节点大于它的某个子节点的话,此时筛操作if (nodeList[parent].level > nodeList[min].level){//子节点和父节点进行交换操作var temp = nodeList[parent];nodeList[parent] = nodeList[min];nodeList[min] = temp;//继续进行更上一层的过滤parent = (int)Math.Ceiling(parent / 2d) - 1;}else{break;}}}#endregion#region 优先队列的出队操作/// <summary>/// 优先队列的出队操作/// </summary>/// <returns></returns>public HeapNode Dequeue(){if (nodeList.Count == 0)return null;//出队列操作,弹出数据头元素var pop = nodeList[0];//用尾元素填充头元素nodeList[0] = nodeList[nodeList.Count - 1];//删除尾节点nodeList.RemoveAt(nodeList.Count - 1);//然后从根节点下滤堆DownHeapAdjust(nodeList, 0);return pop;}#endregion#region 对堆进行下滤操作,使得满足堆性质/// <summary>/// 对堆进行下滤操作,使得满足堆性质/// </summary>/// <param name="nodeList"></param>/// <param name="index">非叶子节点的之后指针(这里要注意:我们/// 的筛操作时针对非叶节点的)/// </param>public void DownHeapAdjust(List<HeapNode> nodeList, int parent){while (2 * parent + 1 < nodeList.Count){//当前index节点的左孩子var left = 2 * parent + 1;//当前index节点的右孩子var right = left + 1;//parent子节点中最大的孩子节点,方便于parent进行比较//默认为left节点var min = left;//判断当前节点是否有右孩子if (right < nodeList.Count){//判断parent要比较的最大子节点min = nodeList[left].level < nodeList[right].level ? left : right;}//如果parent节点小于它的某个子节点的话,此时筛操作if (nodeList[parent].level > nodeList[min].level){//子节点和父节点进行交换操作var temp = nodeList[parent];nodeList[parent] = nodeList[min];nodeList[min] = temp;//继续进行更下一层的过滤parent = min;}else{break;}}}#endregion#region 获取元素并下降到指定的level级别/// <summary>/// 获取元素并下降到指定的level级别/// </summary>/// <returns></returns>public HeapNode GetAndDownPriority(int level){if (nodeList.Count == 0)return null;//获取头元素var pop = nodeList[0];//设置指定优先级(如果为 MinValue 则为 -- 操作)nodeList[0].level = level == int.MinValue ? --nodeList[0].level : level;//下滤堆DownHeapAdjust(nodeList, 0);return nodeList[0];}#endregion#region 获取元素并下降优先级/// <summary>/// 获取元素并下降优先级/// </summary>/// <returns></returns>public HeapNode GetAndDownPriority(){//下降一个优先级return GetAndDownPriority(int.MinValue);}#endregion#region 返回当前优先队列中的元素个数/// <summary>/// 返回当前优先队列中的元素个数/// </summary>/// <returns></returns>public int Count(){return nodeList.Count;}#endregion}}
相关文章:
基于C#实现外排序
一、N 路归并排序 1.1、概序 我们知道算法中有一种叫做分治思想,一个大问题我们可以采取分而治之,各个突破,当子问题解决了,大问题也就 KO 了,还有一点我们知道内排序的归并排序是采用二路归并的,因为分治…...

HTML CSS登录网页设计
一、效果图: 二、HTML代码: <!DOCTYPE html> <!-- 定义HTML5文档 --> <html lang="en"> …...

dos 命令 判断路径中包含某字符并移动文件
SET GenFolder C:\Users\administered\Desktop\t2\old_file set path1C:\Users\administered\Desktop\t1\crontab_master set path2C:\Users\administered\Desktop\t2\old_file if not exist %GenFolder% ( echo %GenFolder%目录不存在,已创建该目录&#x…...
electron+vue3全家桶+vite项目搭建【26】electron本地安装Vue Devtool插件,安装浏览器扩展
文章目录 引入获取vue devtool导入插件排除插件的npm脚本最终效果 引入 demo项目地址 Vue Devtools插件是vue项目必备插件,它是安装在浏览器里的,而咱们的electron中实际就包含了一个浏览器,同理它也可以加载浏览器插件 获取vue devtool 直…...
Modbus TCP
Modbus (👆 百度百科,放心跳转) 起源 Modbus 由 Modicon 公司于 1979 年开发,是一种工业现场总线协议标准。 Modbus 通信协议具有多个变种,支持串口,以太网多个版本,其中最著名的…...

基于人工兔算法优化概率神经网络PNN的分类预测 - 附代码
基于人工兔算法优化概率神经网络PNN的分类预测 - 附代码 文章目录 基于人工兔算法优化概率神经网络PNN的分类预测 - 附代码1.PNN网络概述2.变压器故障诊街系统相关背景2.1 模型建立 3.基于人工兔优化的PNN网络5.测试结果6.参考文献7.Matlab代码 摘要:针对PNN神经网络…...
微服务学习(十二):安装Minio
微服务学习(十二):安装Minio 一、简介 MinIO 是一款基于Go语言发开的高性能、分布式的对象存储系统。客户端支持Java,Net,Python,Javacript, Golang语言。MinIO系统,非常适合于存储大容量非结构化的数据,例如图片、视…...
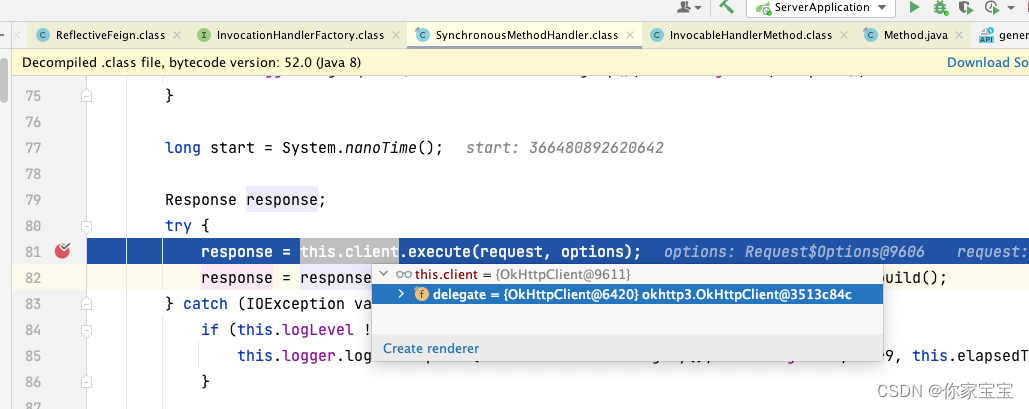
SpringCloud实用-OpenFeign整合okHttp
文章目录 前言正文一、OkHttpFeignConfiguration 的启用1.1 分析配置类1.2 得出结论,需要增加配置1.3 调试 二、OkHttpFeignLoadBalancerConfiguration 的启用2.1 分析配置类2.2 得出结论2.3 测试 附录附1:本系列文章链接附2:OkHttpClient 增…...

Python 异步套接字编程
异步套接字编程是异步编程在网络通信中的应用,它使用异步 IO 操作和事件循环来实现高并发的网络应用。Python 中的 asyncio 模块提供了对异步套接字编程的支持,以下是异步套接字编程的一些重要概念和使用方法: 1. 异步套接字服务器ÿ…...

今年的校招薪资真的让人咋舌!
秋招接近尾声,各大公司基本也陆续开奖了。这里整理了部分公司的薪资情况,数据来源于 OfferShow 和牛客网。 ps:爆料薪资的几乎都是 211 和 985 的,并不是刻意只选取学校好的。另外,无法保证数据的严格准确性。 淘天 …...

debian 设置系统默认以命令行方式启动,关闭x windows
debian 设置系统默认以命令行方式启动,关闭x windows 2021-01-02 tech linux 设置 grub启动设置在/etc/default/grub中,打开 default grub 配置: $ sudo vim /etc/default/grub修改以下配置: 更新grub,设置多用户启动: …...

AMEYA360:蔡司新能源汽车解决方案驱动产业未来
电动化正在重塑中国汽车工业。自中国汽车工业开始发展以来,在电动化和智能化的浪潮推动下,汽车行业从未面临着如此巨大的变革。得益于中国汽车产业尤其是新能源车过去十余年的激流勇进,消费者对新能源汽车的接受度也在发生转变。新能源汽车市…...

C#面试问题整理
sqlserver中视图和表的区别 在 SQL Server 中,视图(View)和表(Table)是不同的对象,它们有以下几点区别: 数据存储方式:表是一种实际存储数据的数据库对象,它包含列和行&…...
微信小程序 基于Android的共享付费自习室座位选座系统uniAPP
题目: 基于Android的共享自习室APP设计与实现 (学校要求:数据库不少于有逻辑关系的20个表,系统功能不少于60个功能点) 技术: 功能: 1. 用户端: 一、首页: (1&…...
方法解析)
Java中类的类型判断技巧以及没有无参构造函数时的应对策略。isInstance()方法解析
类的类型判断 基本数据类型的包装类中,例如Integer、Long这些类是没有无参构造方法的,因此在以下情况中,会出错 具体类型是未知的,只有全路径类名 String typeSte "java.lang.Integer"; Class<?> typeClass …...
基于微信小程序的员工宿舍报修系统
项目介绍 随着信息技术和网络技术的飞速发展,人类已进入全新信息化时代,传统管理技术已无法高效,便捷地管理信息。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生,各行各业相继进入信息管理时…...
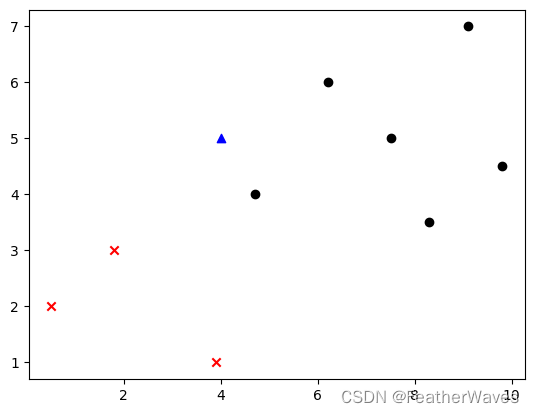
机器学习探索计划——KNN算法流程的简易了解
文章目录 数据准备阶段KNN预测的过程1.计算新样本与已知样本点的距离2.按照举例排序3.确定k值4.距离最近的k个点投票 scikit-learn中的KNN算法 数据准备阶段 import matplotlib.pyplot as plt import numpy as np# 样本特征 data_X [[0.5, 2],[1.8, 3],[3.9, 1],[4.7, 4],[6.…...

ES6之class类
ES6提供了更接近传统语言的写法,引入了Class类这个概念,作为对象的模板。通过Class关键字,可以定义类,基本上,ES6的class可以看作只是一个语法糖,它的绝大部分功能,ES5都可以做到,新…...

17 redis集群方案
1、RedisCluster分布式集群解决方案 为了解决单机内存,并发等瓶颈,可使用此方案解决问题. Redis-cluster是一种服务器Sharding技术,Redis3.0以后版本正式提供支持。 这里的集群是指多主多从,不是一主多从。 2、redis集群的目标…...
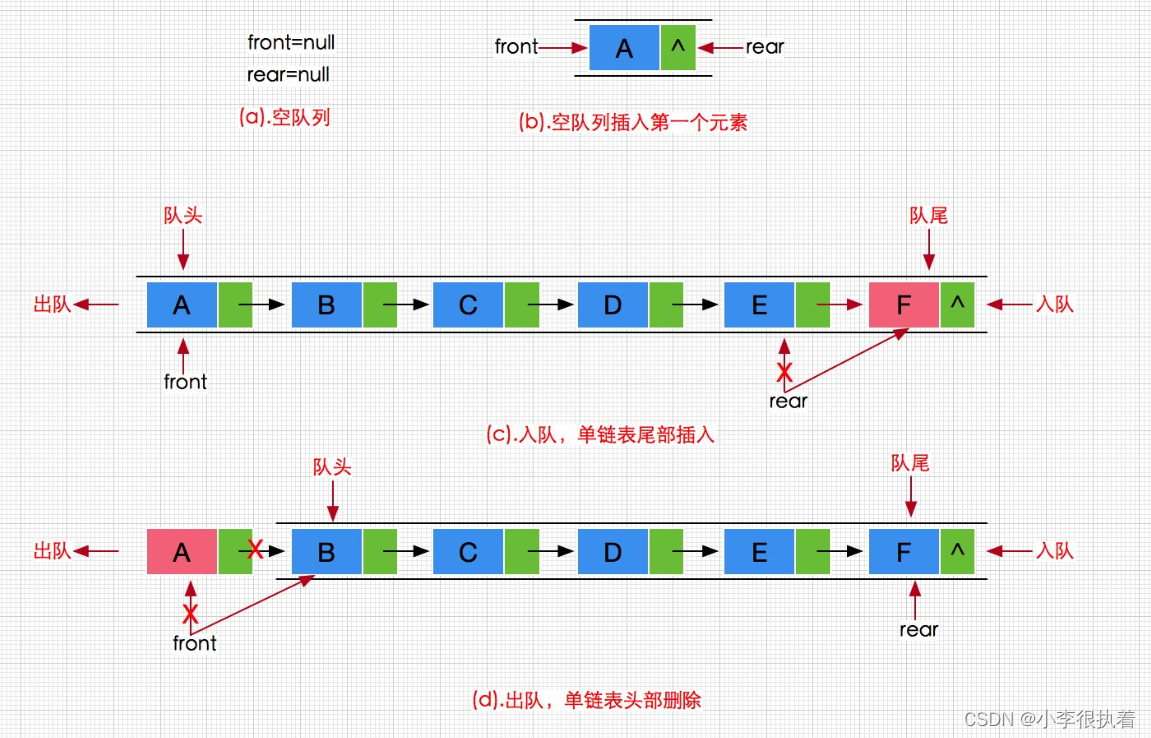
[数据结构]—栈和队列
💓作者简介🎉:在校大二迷茫大学生 💖个人主页🎉:小李很执着 💗系列专栏🎉:数据结构 每日分享✨:到头来,有意义的并不是结果,而是我们度…...
)
python+Vue实现摄像头视频流服务(支持启停控制)
python+Vue实现摄像头视频流服务(支持启停控制) 在开发视频监控、人脸识别或远程预览应用时,常常需要搭建一个可随时启动/停止的摄像头视频流服务,并同时支持Web浏览器实时预览。本文提供一套完整的解决方案: 后端使用 Flask + OpenCV + Waitress,提供 MJPEG 视频流。 支…...

从部署视角看模型优化:如何用PyTorch Profiler和thop分析,让你的模型在边缘设备上跑得更快
从部署视角看模型优化:如何用PyTorch Profiler和thop分析,让你的模型在边缘设备上跑得更快 边缘计算设备的算力限制常常成为AI模型落地的瓶颈。当我们将一个在高端GPU上训练流畅的PyTorch模型部署到Jetson Nano或树莓派这类边缘设备时,往往会…...
)
C# Winform Chart控件实战:如何将数据库数据动态绑定到饼状图?(以SQL Server为例)
C# Winform Chart控件实战:SQL Server数据动态绑定饼状图全解析 在企业级应用开发中,数据可视化是决策支持系统的核心组件。本文将深入探讨如何将SQL Server数据库中的实时业务数据动态绑定到Winform的Chart控件,构建专业级的饼状图分析界面…...

终极指南:如何用STB字符串哈希表避开90%的C语言坑
终极指南:如何用STB字符串哈希表避开90%的C语言坑 【免费下载链接】stb stb single-file public domain libraries for C/C 项目地址: https://gitcode.com/GitHub_Trending/st/stb 在C语言开发中,手动管理数据结构往往是错误的重灾区。内存泄漏、…...

LotusDB错误处理完全指南:构建健壮的应用程序
LotusDB错误处理完全指南:构建健壮的应用程序 【免费下载链接】lotusdb Most advanced key-value database written in Go, extremely fast, compatible with LSM tree and B tree. 项目地址: https://gitcode.com/gh_mirrors/lo/lotusdb LotusDB是一款用Go编…...

OpenBoardView:完全免费的.brd电路板查看终极方案
OpenBoardView:完全免费的.brd电路板查看终极方案 【免费下载链接】OpenBoardView View .brd files 项目地址: https://gitcode.com/gh_mirrors/op/OpenBoardView 还在为昂贵的电路板设计软件而烦恼吗?想要一款真正免费、跨平台、功能强大的.brd文…...

如何在英雄联盟国服中免费解锁所有皮肤:R3nzSkin完整指南
如何在英雄联盟国服中免费解锁所有皮肤:R3nzSkin完整指南 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 你是否曾经羡慕其他玩家拥有炫酷的…...

3步构建:用Finnhub Python打造专业金融数据系统
3步构建:用Finnhub Python打造专业金融数据系统 【免费下载链接】finnhub-python Finnhub Python API Client. Finnhub API provides institutional-grade financial data to investors, fintech startups and investment firms. We support real-time stock price,…...

1500对工业级图像!DeepPCB:开启PCB缺陷检测的AI时代
1500对工业级图像!DeepPCB:开启PCB缺陷检测的AI时代 【免费下载链接】DeepPCB A PCB defect dataset. 项目地址: https://gitcode.com/gh_mirrors/de/DeepPCB 还在为PCB缺陷检测项目寻找高质量数据集而烦恼吗?DeepPCB为你提供了一个工…...

如何快速掌握VideoSrt:Windows平台免费视频字幕生成工具终极指南
如何快速掌握VideoSrt:Windows平台免费视频字幕生成工具终极指南 【免费下载链接】video-srt-windows 这是一个可以识别视频语音自动生成字幕SRT文件的开源 Windows-GUI 软件工具。 项目地址: https://gitcode.com/gh_mirrors/vi/video-srt-windows VideoSrt…...