『 MySQL数据库 』表的增删查改(CRUD)之表的数据插入及基本查询
文章目录
- 📂 Create(创建/新增)
- 📌全列插入与指定列插入📌
- 📌单行数据插入与多行数据插入📌
- 📌插入数据否则更新📌
- 📌数据的替换📌
- 📂 Retrieve(查询)
- 📌SELECT语句📌
- 全列查询 📨
- 指定列查询 📨
- 查询字段为表达式 📨
- 查询结果取别名 📨
- 去重 📨
- 📌where条件📌
- 📌比较运算符📌
- 📌逻辑运算符📌
- 📌结果排序📌
- 📌筛选分页结果📌
📂 Create(创建/新增)
对于表内数据的创建无非就是对数据的插入;
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...
存在一张表为:
mysql> create table if not exists stu(-> id int(2) unsigned zerofill primary key comment'id并设置主键约束',-> sn int(5) unsigned zerofill not null unique comment'学号',-> name varchar(20) not null comment'姓名',-> email varchar(32) null comment'邮箱'-> );
Query OK, 0 rows affected (0.00 sec)mysql> desc stu;
+-------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------------------+------+-----+---------+-------+
| id | int(2) unsigned zerofill | NO | PRI | NULL | |
| sn | int(5) unsigned zerofill | NO | UNI | NULL | |
| name | varchar(20) | NO | | NULL | |
| email | varchar(32) | YES | | NULL | |
+-------+--------------------------+------+-----+---------+-------+📌全列插入与指定列插入📌
以该表为例,若是需要为该表插入数据,插入数据的方式分为全列插入与指定列插入;
-
全列插入
全列插入指的是在插入数据时需要插入表中所有的字段;
即表中有几个字段就需要根据字段个数与字段要求插入对应的数据;mysql> insert into stu values(1,1,'Lihua','123456@xx.com'); #全列插入 Query OK, 1 row affected (0.00 sec)mysql> select * from stu; +----+-------+-------+---------------+ | id | sn | name | email | +----+-------+-------+---------------+ | 01 | 00001 | Lihua | 123456@xx.com | +----+-------+-------+---------------+ 1 row in set (0.00 sec)在默认的插入中使用的即为全列插入,在全列插入时
values前不需要使用()来指明需要插入 的字段,只需要在values后使用()按照字段顺序插入对应数据即可;
语法:insert [into] table_name values (value_list) [, (value_list)] ...其中带
[]的为可省略; -
指定列插入
指定列插入,顾名思义是需要指定所插入的字段进行插入;
mysql> insert into stu (id,name,sn)value(2,'Zhangqian',2);#指定列插入 Query OK, 1 row affected (0.00 sec)mysql> select * from stu; +----+-------+-----------+---------------+ | id | sn | name | email | +----+-------+-----------+---------------+ | 01 | 00001 | Lihua | 123456@xx.com | | 02 | 00002 | Zhangqian | NULL | +----+-------+-----------+---------------+ 2 rows in set (0.00 sec)如该段代码所示,这段代码演示了如何使用指定列插入,插入数据时在
values前使用()指定了需要插入数据的字段,在插入数据时根据所指定字段的顺序以及对应的要求对表进行数据的插入;
语法:insert [into] table_name [(column [, column] ...)/*指定列*/]values (value_list) [, (value_list)] ...
📌单行数据插入与多行数据插入📌
无论是全列插入还是指定列插入都能进行对应的单行数据与多行数据插入;
这表示在MySQL中对于各种条件的混用是十分灵活的;
-
单行数据插入
单行数据插入即在解释全列插入与指定列插入所使用的数据插入;
mysql> insert into stu values(1,1,'Lihua','123456@xx.com'); #单行数据插入
这个代码中为什么叫做单行数据插入?
在MySQL中我们将字段称之为列,对应的行即为对应的一组数据;
这里的values(1,1,'Lihua','123456@xx.com')即为插入一行数据,该行数据根据对应的字段如上; -
多行数据插入
而要进行多行数据插入则可以直接使用
,(value_list)来对数据进行追加;
示例:(这里以全列插入为例,指定列插入不再作示范)mysql> insert into stu values(3,3,'Liqiang','112233'),(4,4,'Zhangwu','223344'),(5,5,'Liuba','445566'); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0mysql> select * from stu; +----+-------+-----------+---------------+ | id | sn | name | email | +----+-------+-----------+---------------+ | 01 | 00001 | Lihua | 123456@xx.com | | 02 | 00002 | Zhangqian | NULL | | 03 | 00003 | Liqiang | 112233 | | 04 | 00004 | Zhangwu | 223344 | | 05 | 00005 | Liuba | 445566 | +----+-------+-----------+---------------+ 5 rows in set (0.00 sec)
📌插入数据否则更新📌
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...
插入数据否则更新这个是为了应对当在插入数据时发生的主键冲突或者唯一键冲突;
当插入数据时发生主键冲突或者唯一键冲突时使用这个语法时将会将原本的数据删除并以新的数据进行插入并替换该数据;
以该表为例:
+----+-------+-----------+---------------+
| id | sn | name | email |
+----+-------+-----------+---------------+
| 01 | 00001 | Lihua | 123456@xx.com |
| 02 | 00002 | Zhangqian | NULL |
| 03 | 00003 | Liqiang | 112233 |
| 04 | 00004 | Zhangwu | 223344 |
| 05 | 00005 | Liuba | 445566 |
+----+-------+-----------+---------------+
mysql> show create table stu\G
*************************** 1. row ***************************Table: stu
Create Table: CREATE TABLE `stu` (`id` int(2) unsigned zerofill NOT NULL COMMENT 'id并设置主键约束',`sn` int(5) unsigned zerofill NOT NULL COMMENT '学号',`name` varchar(20) NOT NULL COMMENT '姓名',`email` varchar(32) DEFAULT NULL COMMENT '邮箱',PRIMARY KEY (`id`),UNIQUE KEY `sn` (`sn`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
从上面的代码可以看出其中id字段设有主键约束,sn字段设有唯一键约束;
在不使用替换的语法前对其进行插入数据,且人为的触发其中一个约束冲突;
#主键冲突
mysql> insert into stu values(5,6,'Lianhua','22222');
ERROR 1062 (23000): Duplicate entry '05' for key 'PRIMARY'#唯一键冲突
mysql> insert into stu values(6,5,'Lianhua','22222');
ERROR 1062 (23000): Duplicate entry '00005' for key 'sn'
当发生冲突时使用语法使其完成当发生键值冲突进行替换;
mysql> insert into stu values(5,6,'Lianhua','22222') -> on duplicate key update id = 6,sn = 6,name ='LIANHUA',email='22222';
Query OK, 2 rows affected (0.00 sec)mysql> select * from stu;
+----+-------+-----------+---------------+
| id | sn | name | email |
+----+-------+-----------+---------------+
| 01 | 00001 | Lihua | 123456@xx.com |
| 02 | 00002 | Zhangqian | NULL |
| 03 | 00003 | Liqiang | 112233 |
| 04 | 00004 | Zhangwu | 223344 |
| 06 | 00006 | LIANHUA | 22222 | #->已经发生了替换
+----+-------+-----------+---------------+
从上面的操作可以看出原来的其中一个字段为:
| 05 | 00005 | Liuba | 445566 |
在这次插入失败后进行了替换,替换为了:
| 06 | 00006 | LIANHUA | 22222 |
不仅如此,在替换成功时也有对应的提示:
Query OK, 2 rows affected (0.00 sec)
在MySQL中以该方式进行数据插入时,会有对应提示:
-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,并且数据已经被更新
📌数据的替换📌
数据的替换类比于上一个插入数据否则更新;
数据的替换真正的意义上是:
- 若是发生主键冲突或者唯一键冲突,则删除原数据再进行插入;
- 若是未发生主键冲突也未发生唯一键冲突,则直接插入数据;
对应的语法即为INSERT INTO变为REPLACE INTO;
mysql> replace into stu values(5,6,'Lianhua','22222');
Query OK, 2 rows affected (0.00 sec)
📂 Retrieve(查询)
在数据库中查询是一个非常频繁的工作,需要根据不同的场合以及不同的条件进行查找;
+----+---------+---------+------+---------+
| id | name | chinese | math | english |
+----+---------+---------+------+---------+
| 1 | Lihua | 67 | 88 | 90 |
| 2 | Liming | 57 | 58 | 70 |
| 3 | Zhaolao | 66 | 80 | 47 |
| 4 | Wu | 76 | 70 | 47 |
| 5 | Wuqi | 88 | 43 | 80 |
| 6 | Liqiang | 89 | 92 | 90 |
| 7 | Qinsu | 90 | 74 | 67 |
| 8 | Zhaoli | 54 | 74 | 100 |
+----+---------+---------+------+---------+
📌SELECT语句📌
在MySQL中SELECT语句是一个高频语句;
其功能可以根据条件对表数据进行查询;
其查询不单单能对数据,还能对表达式、函数等等…
mysql> select 1+1;
+-----+
| 1+1 |
+-----+
| 2 |
+-----+
1 row in set (0.00 sec)
全列查询 📨
在MySQL中*符号代表通配符;
SELECT * FROM table_name;
该句指令即表示查询表中所有字段(列);
以该中方式即可以打印出表中的所有字段的数据;
mysql> select * from Point;
+----+---------+---------+------+---------+
| id | name | chinese | math | english |
+----+---------+---------+------+---------+
| 1 | Lihua | 67 | 88 | 90 |
| 2 | Liming | 57 | 58 | 70 |
| 3 | Zhaolao | 66 | 80 | 47 |
| 4 | Wu | 76 | 70 | 47 |
| 5 | Wuqi | 88 | 43 | 80 |
| 6 | Liqiang | 89 | 92 | 90 |
| 7 | Qinsu | 90 | 74 | 67 |
| 8 | Zhaoli | 54 | 74 | 100 |
+----+---------+---------+------+---------+
指定列查询 📨
指定列查询,顾名思义就是指定对应的字段进行查询;
语句:SELECT 字段1,字段2... FROM table_name;
示例:
mysql> select name,chinese from Point;
+---------+---------+
| name | chinese |
+---------+---------+
| Lihua | 67 |
| Liming | 57 |
| Zhaolao | 66 |
| Wu | 76 |
| Wuqi | 88 |
| Liqiang | 89 |
| Qinsu | 90 |
| Zhaoli | 54 |
+---------+---------+
查询字段为表达式 📨
SELECT不仅能查询表中的字段,也能查询表达式;
示例:
mysql> select name,chinese,6 from Point;
+---------+---------+---+
| name | chinese | 6 |
+---------+---------+---+
| Lihua | 67 | 6 |
| Liming | 57 | 6 |
| Zhaolao | 66 | 6 |
| Wu | 76 | 6 |
| Wuqi | 88 | 6 |
| Liqiang | 89 | 6 |
| Qinsu | 90 | 6 |
| Zhaoli | 54 | 6 |
+---------+---------+---+
在该次查询中查询的除了字段以外还查询了一个常量表达式;
查询结果取别名 📨
当一个查询的字段由一个较为复杂的表达式合成时,可以将该表达式使用as将其改名;
需要注意的是,在SELECT查询为结果的字段进行改名时,这个操作一般是靠后的,即将数据处理完后将其打印时才能将其进行改名,所以不能先进行改名再将其进行其他操作;
示例:
mysql> select name,chinese+math+english as '总分' from Point;
+---------+--------+
| name | 总分 |
+---------+--------+
| Lihua | 245 |
| Liming | 185 |
| Zhaolao | 193 |
| Wu | 193 |
| Wuqi | 211 |
| Liqiang | 271 |
| Qinsu | 231 |
| Zhaoli | 228 |
+---------+--------+
其中这里的as可以省略不写;
去重 📨
这里的去重指的是对最终的结果在显示前进行去重;
其语法即为SELECT DISTINCT 字段 FROM table_name;
mysql> select math from Point; # 未使用去重
+------+
| math |
+------+
| 88 |
| 58 |
| 80 |
| 70 |
| 43 |
| 92 |
| 74 |
| 74 |
+------+mysql> select distinct math from Point; # 结果去重
+------+
| math |
+------+
| 88 |
| 58 |
| 80 |
| 70 |
| 43 |
| 92 |
| 74 |
+------+
📌where条件📌
在大部分的情况下,SELECT在查询数据时应该配合着行的限制与列的限制从而达到筛选数据的效果;
若是不对数据进行筛选而是无脑选择SELECT * FROM table_name;来将数据进行全部显示的话可能会因为数据量过于庞大不便于观察且并没有筛选出需要条件的数据而做出的无用查看;
在MySQL中可以使用where条件来为SELECT查看的数据做出对应的条件限制从而达到能够查看到对应的数据;
同样的接下来的操作将基于上表进行;
📌比较运算符📌
-
>,>=,<,<=
若是满足条件则显示1,否则显示0;mysql> select 1>2; +-----+ | 1>2 | +-----+ | 0 | +-----+ 1 row in set (0.00 sec)mysql> select 1<2; +-----+ | 1<2 | +-----+ | 1 | +-----+ 1 row in set (0.00 sec)示例:
显示出math大于90的人的名字与成绩mysql> select name,math from Point where math>90; +---------+------+ | name | math | +---------+------+ | Liqiang | 92 | +---------+------+
-
=与<=>在MySQL中的等于有两种,分别为以上两种;
两种的等于在实质性的使用层面并没有太多的区别;
唯一的区别只是对NULL进行判断;#-------------------------------------- mysql> select 1 = 1; +-------+ | 1 = 1 | +-------+ | 1 | +-------+mysql> select 1 = 2; +-------+ | 1 = 2 | +-------+ | 0 | +-------+mysql> select NULL = NULL; +-------------+ | NULL = NULL | +-------------+ | NULL | +-------------+ #-------------------------------------- mysql> select 1<=>1; +-------+ | 1<=>1 | +-------+ | 1 | +-------+mysql> select 1<=>2; +-------+ | 1<=>2 | +-------+ | 0 | +-------+mysql> select NULL<=>NULL; +-------------+ | NULL<=>NULL | +-------------+ | 1 | +-------------+ #--------------------------------------
-
不等于
!=、<>在MySQL中的不等于为以上两种,但是无论哪种不等于都无法对
NULL做比较;mysql> select NULL <> NULL; +--------------+ | NULL <> NULL | +--------------+ | NULL | +--------------+ 1 row in set (0.00 sec)mysql> select NULL = NULL; +-------------+ | NULL = NULL | +-------------+ | NULL | +-------------+ 1 row in set (0.00 sec)
-
范围匹配
BETWEEN a0 AND a1范围匹配一般用来判断一个数是否属于该范围内,且该范围属于左闭右闭区间(
[a0,a1]);mysql> select 5 between 0 and 10; +--------------------+ | 5 between 0 and 10 | +--------------------+ | 1 | +--------------------+ 1 row in set (0.00 sec)示例:找出math区间为[70,75]的数据:
mysql> select name,math from Point where math between 70 and 75; +--------+------+ | name | math | +--------+------+ | Wu | 70 | | Qinsu | 74 | | Zhaoli | 74 | +--------+------+
-
该数据是否为一组数据中的其中一个
IN (option,...)该运算符一般判断一个数据是否存在于一组数据中;
mysql> select 12 in (10,12,14); +------------------+ | 12 in (10,12,14) | +------------------+ | 1 | +------------------+ 1 row in set (0.00 sec)示例:分别找出english为(70,80,90,100)的数据;
mysql> select name,english from Point where english in (70,80,90,100); +---------+---------+ | name | english | +---------+---------+ | Lihua | 90 | | Liming | 70 | | Wuqi | 80 | | Liqiang | 90 | | Zhaoli | 100 | +---------+---------+ 5 rows in set (0.00 sec)
-
是NULL
IS NULL与 非NULLIS NOT NULL该运算符一般用来判断一个字段是否为NULL;
mysql> select NULL IS NULL; +--------------+ | NULL IS NULL | +--------------+ | 1 | +--------------+ 1 row in set (0.00 sec)mysql> select NULL IS NOT NULL; +-------------------+ | NULL IS NOT NULL | +-------------------+ | 0 | +-------------------+ 1 row in set (0.00 sec)
-
模糊匹配
LIKE该运算符一般用来模糊匹配,其中
%表示多个(包括0)个任意字符,_表示任意一个字符;
示例:分别找出name为W的字段与W_ 的字段;mysql> select * from Point where name like 'W%'; +----+------+---------+------+---------+ | id | name | chinese | math | english | +----+------+---------+------+---------+ | 4 | Wu | 76 | 70 | 47 | | 5 | Wuqi | 88 | 43 | 80 | +----+------+---------+------+---------+mysql> select * from Point where name like 'W_'; +----+------+---------+------+---------+ | id | name | chinese | math | english | +----+------+---------+------+---------+ | 4 | Wu | 76 | 70 | 47 | +----+------+---------+------+---------+
📌逻辑运算符📌
| 运算符 | 说明 |
|---|---|
| AND | 多个条件为TRUE(1)时结果为TRUE(1); |
| OR | 任意一个条件为TRUE(1)时结果为TRUE(1); |
| NOT | 条件为TRUE(1)时结果为FALSE(0); |
📌结果排序📌
结果排序可以将数据再处理完时对其进行排序处理(一般该操作的顺序为最后的操作);
且没有进行ORDER BY子句的查询所返回的结果顺序一般都是未定义的,即不可靠的;
语法:
SELECT ... FROM table_name [ WHERE ... ]ORDER BY column [ASC|DESC],[...];#其中:#ASC为升序,DESC为降序;#默认为ASC升序;
示例:
显示name与math的字段且math为升序的条件显示;
mysql> select name,math from Point order by math ASC;
+---------+------+
| name | math |
+---------+------+
| Wuqi | 43 |
| Liming | 58 |
| Wu | 70 |
| Qinsu | 74 |
| Zhaoli | 74 |
| Zhaolao | 80 |
| Lihua | 88 |
| Liqiang | 92 |
+---------+------+
8 rows in set (0.00 sec)
📌筛选分页结果📌
在MySQL中经常会因为数据量过大而导致不便于数据的观察;
而在MySQL中有这么一条语句可以便于结果的观察,即为筛选分页结果;
语法:
#分页时的起始下标为0;SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从起始下标开始筛选n条结果;SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s,n;
-- 从s开始,筛选n条结果SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
-- 从s开始,筛选n条结果(该方法的表达更为明确)
示例:
查看name与math字段并使用order by以降序的方式进行排序最终结果每页显示3条;
mysql> SELECT name,math from Point order by math desc limit 3 offset 0;
+---------+------+
| name | math |
+---------+------+
| Liqiang | 92 |
| Lihua | 88 |
| Zhaolao | 80 |
+---------+------+
3 rows in set (0.01 sec)mysql> SELECT name,math from Point order by math desc limit 3 offset 3;
+--------+------+
| name | math |
+--------+------+
| Qinsu | 74 |
| Zhaoli | 74 |
| Wu | 70 |
+--------+------+
3 rows in set (0.00 sec)mysql> SELECT name,math from Point order by math desc limit 3 offset 6;
+--------+------+
| name | math |
+--------+------+
| Liming | 58 |
| Wuqi | 43 |
+--------+------+
2 rows in set (0.00 sec)
相关文章:
之表的数据插入及基本查询)
『 MySQL数据库 』表的增删查改(CRUD)之表的数据插入及基本查询
文章目录 📂 Create(创建/新增)📌全列插入与指定列插入📌📌单行数据插入与多行数据插入📌📌插入数据否则更新📌📌数据的替换📌 📂 Retrieve(查询)Ὄ…...

Vue中mvvm的作用
目录 模型表示应用程序的数据。在Vue.js中,它们是JavaScript对象。视图是用户界面。在Vue.js中,使用模板语法编写HTML的表示层。ViewModel是视图的抽象表示,负责处理用户输入的数据,并处理视图的数据绑定。ViewModel使用模型中的…...
基于springboot实现高校食堂移动预约点餐系统【项目源码】
基于springboot实现高校食堂移动预约点餐系统演示 Java语言简介 Java是由SUN公司推出,该公司于2010年被oracle公司收购。Java本是印度尼西亚的一个叫做爪洼岛的英文名称,也因此得来java是一杯正冒着热气咖啡的标识。Java语言在移动互联网的大背景下具备…...

用element ui上传带参数的文件,并用flask接收
需求 网页需要实现上传一个csv文件,并携带两个表单的参数给后端 方法 上传组件 <el-uploadclass"upload-demo"dragaction"/upload" <!--要上传到的路由地址,跟flask路由函数对应-->accept".csv" <!--只接…...
[Android]使用Git将项目提交到GitHub
如果你的Mac还没有安装Git,你可以通过Homebrew来安装它: brew install git 方式一:终端管理 1.创建本地Git仓库 在项目的根目录下,打开终端(Terminal)并执行以下命令来初始化一个新的Git仓库࿱…...

python cv2.imread()和Image.open()的区别和联系
文章目录 1. cv2.imread()1.1 cv2.imread参数说明1.2 注意事项 2. Image.open()3. cv2.imread()与Image.open()相互转化3.1 cv2.imread()转成Image.open():Image.fromarray()3.2 Image.open()转成cv2.imread():np.array() 1. cv2.imread() cv2.imread()…...
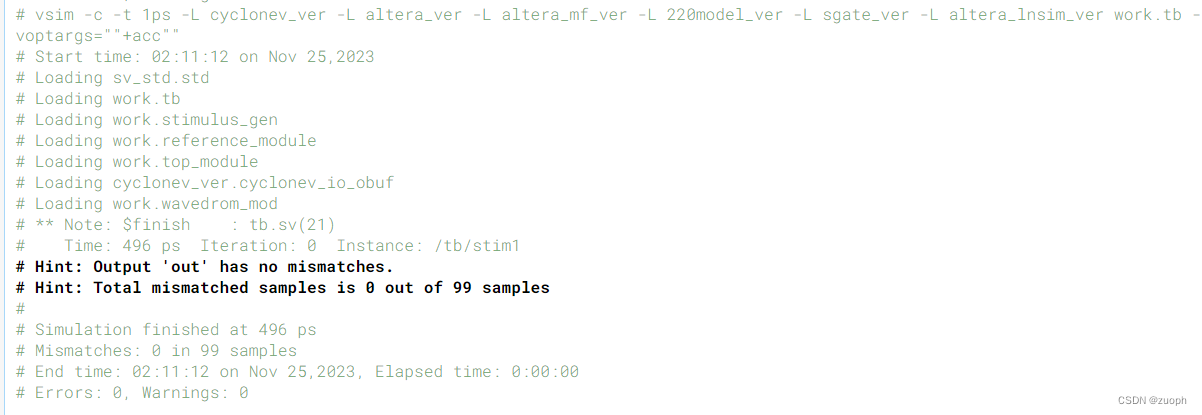
hdlbits系列verilog解答(exams/m2014_q4i)-45
文章目录 一、问题描述二、verilog源码三、仿真结果 一、问题描述 实现以下电路: 二、verilog源码 module top_module (output out);assign out 1b0;endmodule三、仿真结果 转载请注明出处!...
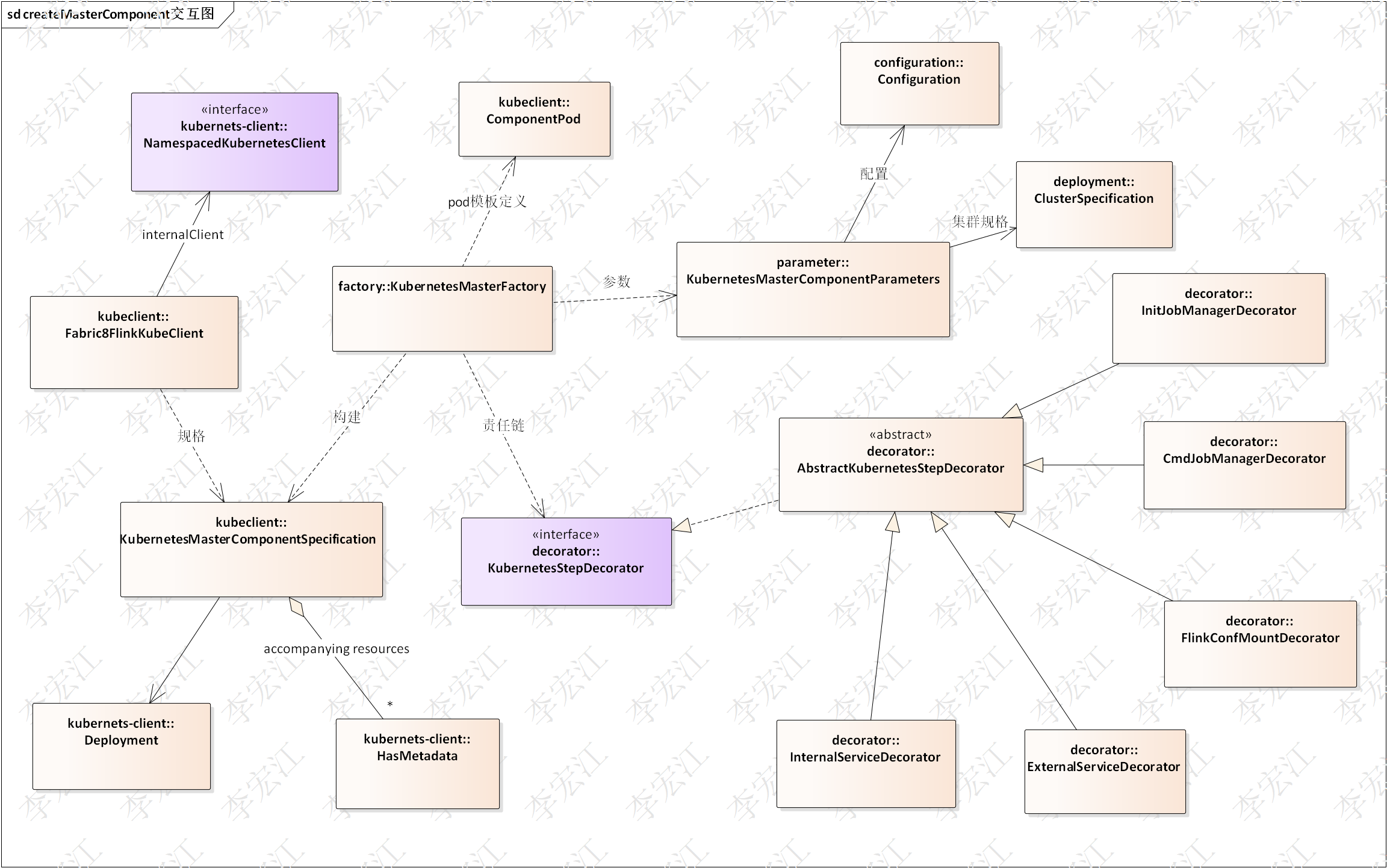
flink源码分析之功能组件(二)-kubeclient
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics,future。其中kubeclient上一个系列介绍过,为了系列完整性,这里“copy”一下。 kubeclient组件…...
无需API开发,有赞小程序集成广告推广系统,提升品牌曝光
无需API开发,实现有赞小程序与其他系统的连接 有赞小程序作为一个多功能的电子商务解决方案,为商家提供了无需复杂API开发就可以实现系统连接和集成的便捷途径。通过有赞小程序,商家可以轻松实现与各种系统的数据同步和应用互联,…...
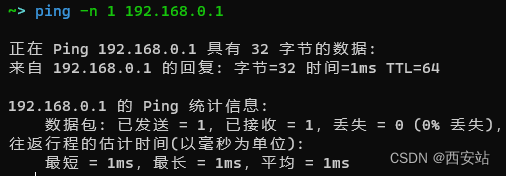
CMD - ping
文章目录 前言参数 前言 ping 命令主要测试到达指定 IP 或主机的连通性. 参数 -t: ping 指定的计算机直到中断 -a: 将地址解析为主机名 -n count: 要发送的回显请求数...

数据结构与算法编程题23
设计二叉树的双序遍历算法(双序遍历是指对于二叉树的每一个结点来说,先访问这个结点,再按双序遍历它的左子树,然后再一次访问这个结点,接下来按双序遍历它的右子树) #define _CRT_SECURE_NO_WARNINGS#inclu…...

小程序中的大道理之二--抽象与封装
继续扒 接着 上一篇 的叙述, 健壮性也有了, 现在是时候处理点实际的东西了, 但我们依然不会一步到底, 让我们来看看. 一而再地抽象(Abstraction Again) 让我们继续无视那些空格以及星号等细节, 我们看到什么呢? 我们只看到一整行的内容, 当传入 3 时就有 3 行, 传入 4 时就…...

基于卷积神经网络CNN开发构建HAR人类行为识别Human Activity Recognition【完整代码实践】
行为识别相关的开发实践在我们之前的博文中也有过相关的实践了,感兴趣的话可以自行移步阅读即可:《python实现基于TNDADATASET的人体行为识别》 《UCI行为识别——Activity recognition with healthy older people using a batteryless wearable sensor Data Set》《人体行为…...

excel自己记录
1、清除换行符号 2、添加特殊符号&并清除换行符号 7日&15日&30日&60日 3、判断单元格最后一个字符是不是数字,不是就删掉 IF(ISNUMBER(--RIGHT(B2,1)),B2,SUBSTITUTE(B2,RIGHT(B2,1),"")) ISNUMBER(--RIGHT(B2,1))判断最右边的一个数是否…...
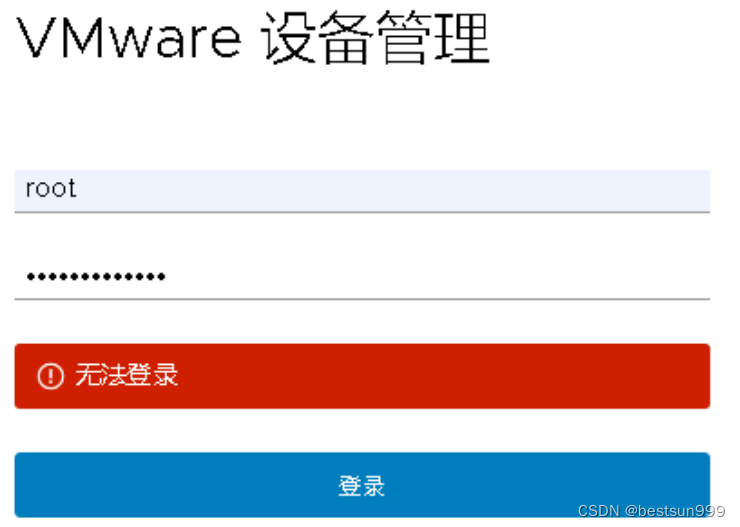
vcsa6.7 5480无法登录
停电维护硬件后,发现vcsa异常,https://ip:5480无法登录,https://ip/ui正常,ssh登录页正常 kb资料 通过端口 5480 登录到 VMware vCenter Server Appliance Web 控制台失败 (2120477) 操作过程 Connecting to 192.16.20.31:22..…...

CSS 属性列表
CSS属性列表 序号 属性类别 属性 描述 1 动画属性 keyframes 定义一个动画,keyframes定义的动画名称用来被animation-name所使用。 2 animation 复合属性。检索或设置对象所应用的动画特效。 3 animation-name 检索或设置对象所应用的动画名称 ,必须与规则keyfra…...
浅谈能源智能管理系统在大学高校中的应用
安科瑞 华楠 摘要:结合深圳南方科技大学能效系统工程设计实例,针对校园中电耗、热量消耗、冷量消耗及水资源消耗数据的采集、传输、分析管理系统,分析了系统中的水、电、气在高校中的能耗分布,并阐述了节能应用方案,可…...

脚本自动化定制开发:实现高效工作的魔法钥匙
在当今这个快节奏的工作环境中,自动化已成为提高工作效率的黄金标准。如果你是一名Windows用户,那么通过Windows脚本自动化,你可以将你的工作流程化繁为简,实现高效工作。而在众多Windows脚本自动化工具中,Python以其简…...

使用websocket获取thingsboard设备的实时数据
背景 有一个读者前来咨询,如何实时获取设备的遥测数据。 其实tb是有提供websocket接口来获取设备数据的。而且还支持js跨域调用。下面给大家演示一下。 websocket地址 完整代码 <!DOCTYPE HTML> <html><h...

使用Linux JumpServer堡垒机本地部署与远程访问
🌈个人主页:聆风吟 🔥系列专栏:网络奇遇记、Cpolar杂谈 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. 安装Jump server二. 本地访问jump server三. 安装 cpolar内网穿透软件四. 配…...

5分钟快速上手:QMCDecode音频格式转换完整指南
5分钟快速上手:QMCDecode音频格式转换完整指南 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果…...

Qianfan-OCR应用场景:跨境电商商品说明书多语言文本提取
Qianfan-OCR应用场景:跨境电商商品说明书多语言文本提取 1. 跨境电商文档处理的痛点与机遇 跨境电商行业每天需要处理海量的商品说明书,这些文档通常具有以下特点: 多语言混合(中文英文目标国语言)复杂排版…...

前端工程规范制定
前端工程规范制定:打造高效协作的基石 在快节奏的前端开发中,工程规范是团队协作的“隐形契约”。随着项目复杂度提升,缺乏统一的代码风格、目录结构或提交规范可能导致维护成本激增、协作效率低下。制定科学的前端工程规范,不仅…...

GeoAI 的4大核心技术如何重塑行业应用
1. 图像分类:从像素到决策的智能之眼 我第一次接触GeoAI图像分类技术是在一个农业监测项目中。当时需要从无人机拍摄的农田图像中自动识别作物类型,传统方法需要人工标注每张图片,效率极低。而当我用上基于卷积神经网络(CNN&#…...

告别花屏!用Arduino TFT_eSPI库驱动SPI LCD显示中文的保姆级避坑指南
告别花屏!用Arduino TFT_eSPI库驱动SPI LCD显示中文的保姆级避坑指南 第一次点亮SPI接口的LCD屏幕时,那种兴奋感就像打开了新世界的大门。但随之而来的花屏、乱码、内存溢出等问题,又让人瞬间跌入谷底。作为过来人,我完全理解这种…...

22岁天才小伙破解“AI黑箱“:融合DeepSeek思路,参数效率翻倍!
本报讯 人工智能领域近日传来震动性消息:一位年仅22岁的年轻创业者,仅凭公开资料和对"第一性原理"的深刻理解,竟成功推导出了Anthropic公司号称"捂得最严实"的Claude Mythos大模型核心架构,并将完整代码开源至…...
)
YOLO26落石滑坡识别检测系统:从数据集构建到地质灾害自动定位的全流程实现(项目源码+数据集+模型权重+UI界面+python+深度学习+远程环境部署)
摘要 落石与滑坡是我国山区常见的地质灾害类型,具有突发性强、破坏性大、监测预警困难等特点,严重威胁山区公路、铁路及居民点安全。针对传统人工巡查效率低、传感器监测成本高等问题,本文提出了一种基于改进YOLO26的目标检测方法࿰…...

Dify多模态Pipeline调试失败率下降82%的关键动作:OpenTelemetry埋点+自定义Trace Context注入实战
第一章:Dify多模态集成调试的挑战与现状Dify 作为低代码 AI 应用开发平台,原生支持文本生成、RAG 和 Agent 编排,但其多模态能力(如图像理解、语音转写、跨模态检索)仍需通过自定义模型服务、插件或外部 API 集成实现。…...
在现代Web应用中,**图形渲染性能)
# WebGPU实战:从零构建高性能图形渲染管线(附完整代码与流程图)在现代Web应用中,**图形渲染性能
WebGPU实战:从零构建高性能图形渲染管线(附完整代码与流程图) 在现代Web应用中,图形渲染性能的提升已成为开发者关注的核心问题之一。随着浏览器对硬件加速能力的支持不断增强,WebGPU作为下一代Web图形API,…...

m4s-converter:3分钟实现B站缓存视频永久保存的终极方案
m4s-converter:3分钟实现B站缓存视频永久保存的终极方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的…...