手动实现 git 的 git diff 功能

这是 git diff 后的效果,感觉挺简单的,不就是 比较新旧版本,新增了就用 "+" 显示新加一行,删除了就用 "-" 显示删除一行,修改了一行就用 "-"、"+" 显示将旧版本中的该行干掉了并且新版本中增加了一行,即使用 "删除" + "新增" 操作代替 "修改" 操作,然后就用
然后我们写的测试代码如下:
import com.goldwind.ipark.common.util.MyStringUitls;
import org.apache.commons.text.similarity.LevenshteinDistance;import java.io.BufferedReader;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.List;public class MyDiffTest {public static void main(String[] args) {List<String> lines_old = loadTxtFile2List("C:\\E\\javaCode\\git\\outer_project\\guodiantou\\gdtipark-user-servie\\src\\main\\java\\com\\goldwind\\ipark\\base\\test\\DemoClass1.java" );List<String> lines_new = loadTxtFile2List("C:\\E\\javaCode\\git\\outer_project\\guodiantou\\gdtipark-user-servie\\src\\main\\java\\com\\goldwind\\ipark\\base\\test\\DemoClass2.java");// lines1的起始行和 lines2 的起始行做映射// 扫描旧版本中的每一行int size = lines_old.size();for( int i=0;i<size;i++ ){// 从新版本中找该行String line_old = lines_old.get(i);String line_new = lines_new.get(i);// 如果发现版本中中该行的数据变了,那么提示删除了旧的行,添加了新的行if( line_new.equals( line_old ) ){System.out.println( line_old );}else {System.out.println( "- " + line_old );System.out.println( "+ " + line_new );}}// xxxx xxxx1 -xxxx// yyyy yyyy +xxxx1// xxxxxx xxxxxx xxxxxx// zzzz zzzz zzzz}private static List<String> loadTxtFile2List(String filePath) {BufferedReader reader = null;List<String> lines = new ArrayList<>();try {reader = new BufferedReader(new FileReader(filePath));String line = reader.readLine();while (line != null) {// System.out.println(line);lines.add( line );line = reader.readLine();}return lines;} catch (Exception e) {e.printStackTrace();return null;} finally {if (reader != null) {try {reader.close();} catch (Exception e) {e.printStackTrace();}}}}
}其中用到的2个新旧版本的文本如下:
DemoClass1.java:
import com.goldwind.ipark.common.exception.BusinessLogicException;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.text.similarity.LevenshteinDistance;@Slf4j
public class DemoClass1 {private static final LevenshteinDistance LEVENSHTEIN_DISTANCE = LevenshteinDistance.getDefaultInstance();public static String null2emptyWithTrim( String str ){if( str == null ){str = "";}str = str.trim();return str;}public static String requiredStringParamCheck(String param, String paramRemark) {param = null2emptyWithTrim( param );if( param.length() == 0 ){String msg = "操作失败,请求参数 \"" + paramRemark + "\" 为空";log.error( msg );throw new BusinessLogicException( msg );}return param;}public static double calculateSimilarity( String str1,String str2 ){int distance = LEVENSHTEIN_DISTANCE.apply(str1, str2);double similarity = 1 - (double) distance / Math.max(str1.length(), str2.length());System.out.println("相似度:" + similarity);return similarity;}
}DemoClass2.java:
import com.goldwind.ipark.common.exception.BusinessLogicException;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.text.similarity.LevenshteinDistance;@Slf4j
public class DemoClass2 {private static final LevenshteinDistance LEVENSHTEIN_DISTANCE = LevenshteinDistance.getDefaultInstance();private static final LevenshteinDistance LEVENSHTEIN_DISTANCE1 = LevenshteinDistance.getDefaultInstance();private static final LevenshteinDistance LEVENSHTEIN_DISTANCE2 = LevenshteinDistance.getDefaultInstance();public static String null2emptyWithTrim( String str ){if( str == null ){str = "";}str = str.trim();return str;}public static String requiredStringParamCheck(String param, String paramRemark) {param = null2emptyWithTrim( param );if( param.length() == 0 ){String msg = "操作失败,请求参数 \"" + paramRemark + "\" 为空";log.error( msg );throw new BusinessLogicException( msg );}return param;}public static double calculateSimilarity( String str1,String str2 ){int distance = LEVENSHTEIN_DISTANCE.apply(str1, str2);double similarity = 1 - (double) distance / Math.max(str1.length(), str2.length());System.out.println("相似度:" + similarity);return similarity;}
}DemoClass2.java 相较于 DemoClass1.java 的区别是 "public class" 后面的类名不同,"private static final LevenshteinDistance LEVENSHTEIN_DISTANC..." 多复制了2行并改了名称,然后运行后显示差别如下:
import com.goldwind.ipark.common.exception.BusinessLogicException;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.text.similarity.LevenshteinDistance;@Slf4j
- public class DemoClass1 {
+ public class DemoClass2 {private static final LevenshteinDistance LEVENSHTEIN_DISTANCE = LevenshteinDistance.getDefaultInstance();
-
+ private static final LevenshteinDistance LEVENSHTEIN_DISTANCE1 = LevenshteinDistance.getDefaultInstance();
- public static String null2emptyWithTrim( String str ){
+ private static final LevenshteinDistance LEVENSHTEIN_DISTANCE2 = LevenshteinDistance.getDefaultInstance();
- if( str == null ){
+
- str = "";
+ public static String null2emptyWithTrim( String str ){
- }
+ if( str == null ){
- str = str.trim();
+ str = "";
- return str;
+ }
- }
+ str = str.trim();
-
+ return str;
- public static String requiredStringParamCheck(String param, String paramRemark) {
+ }
- param = null2emptyWithTrim( param );
+
- if( param.length() == 0 ){
+ public static String requiredStringParamCheck(String param, String paramRemark) {
- String msg = "操作失败,请求参数 \"" + paramRemark + "\" 为空";
+ param = null2emptyWithTrim( param );
- log.error( msg );
+ if( param.length() == 0 ){
- throw new BusinessLogicException( msg );
+ String msg = "操作失败,请求参数 \"" + paramRemark + "\" 为空";
- }
+ log.error( msg );
- return param;
+ throw new BusinessLogicException( msg );
- }
+ }
-
+ return param;
- public static double calculateSimilarity( String str1,String str2 ){
+ }
- int distance = LEVENSHTEIN_DISTANCE.apply(str1, str2);
+
- double similarity = 1 - (double) distance / Math.max(str1.length(), str2.length());
+ public static double calculateSimilarity( String str1,String str2 ){
- System.out.println("相似度:" + similarity);
+ int distance = LEVENSHTEIN_DISTANCE.apply(str1, str2);
- return similarity;
+ double similarity = 1 - (double) distance / Math.max(str1.length(), str2.length());
- }
+ System.out.println("相似度:" + similarity);
- }
+ return similarity;为啥???

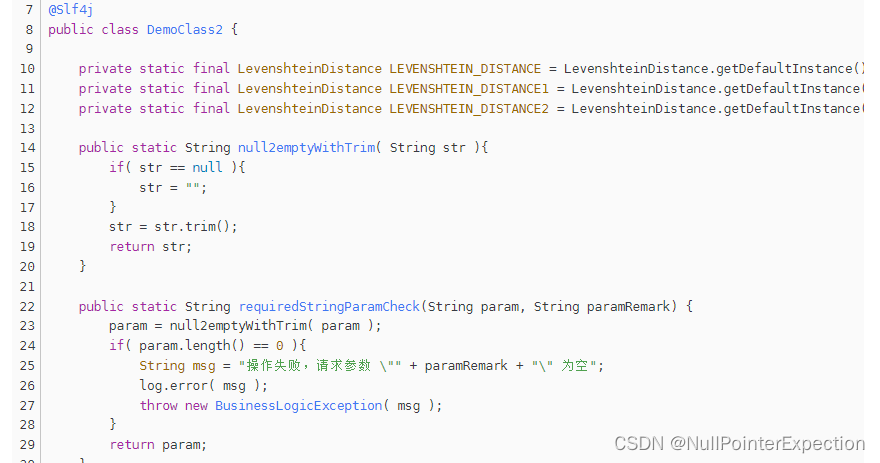
如上两张图片,旧版本的第10行和新版本的第10行对应,从直观上看新版本的第11、12行是在旧版本的第10行和第11行之间插进去的,但是程序并不这么认为,它会认为将旧版本的第11行的空白行修改为了新版本的 “private static final LevenshteinDistance LEVENSHTEIN_DISTANCE1 = LevenshteinDistance.getDefaultInstance();” 为什么我们人眼会这么直观的感觉到 新版本的 第11、12行时插进去的,因为我们比较了新旧版本的第7、8、9、10行都差不多,旧版本的11~27行和新版本的 13~29行都差不多,所以自然而然的认为新版本的11、12行是直接插进去的,那么现在我们就来算法实现吧!( ps:前文中的 “差不多” 是差几多?是完全equals 还是很像?”其实这里可以设置一个阈值,使用求字符串的相似度算法求出相似度,网上有现成的类库求相似度,自己也可以使用动态规划写一个简单的字符串相似度算法 )
感觉恰当的算法的执行过程应该是这样的:
新旧版本各维持一个行号游标:index_old、index_new,最开始这两个游标相同,越往后可能不同,但是他们表示的行的内容应该是应该相似的,因为新版本的修改会导致内容越来越 “错位”。假设我们从上面2张图片的第7行开始描:
1. 最开始 index_old = index_new = 7,算法检测到新旧版本的第7行的内容相同( 后面我们就尽量用伪代码表示,就不说这么多啰里啰嗦的话了 ),即 lines_old[ 7] = lines_new[ 7]。
2. index_old++,index_new++,都变为8,算法检测到 lines_old[ 8 ] != lines_new[ index_new ],并且他们的相似度很高,所以算法判断新版本的第8行相较于旧版本的第8行是做了修改操作。
3. index_old++,index_new++,都变为9,算法检测到 lines_old[ 9 ] = lines_new[ 9 ]。
4. index_old++,index_new++,都变为10,算法检测到 lines_old[ 10 ] = lines_new[ 10 ]。
5. index_old++,index_new++,都变为11,算法检测到 lines_old[ 11 ] != lines_new[ 11 ],并且这两行的文本内容及不相似,所以判断新版本是在旧版本的第11行插入了一行 “private static final LevenshteinDistance LEVENSHTEIN_DISTANCE1 =LevenshteinDistance.getDefaultInstance();”,所以此时旧版本的第11行就和新版本的第11行对应不上了,而是和新版本的第12行做对应。
6. index_old 不变,index_new++,index_old 还是11,index_new 变为 12,即旧版本的第11行要和新版本的第12行做对应,就像找老婆一样,旧7和新7结为了夫妻,旧8和新8结为了夫妻( 虽然有一点点的裂痕,但不打紧 ),新9和新9结为了夫妻,...,所以旧11也要在新版本中找到一个新x作为自己的伴侣,本来已经找到了一个新11,但是发现新11和自己三观差别很大,根本合不来,所以pass掉,继续找,现在发现了下一个相亲对象 新12,发现lines_old[ 11 ] 和 lines_new[ 12 ] 相似度还是差别很大,所以算法判断新版本又插入了一个新行 “private static final LevenshteinDistance LEVENSHTEIN_DISTANCE2 = LevenshteinDistance.getDefaultInstance();”。
7. index_old 不变,index_new++,index_old 还是11,index_new 变为 13,因为 lines_old[ 11 ] = lines_new[ 13 ],所以 旧11 很幸运的找到了自己的伴侣 新13,。
8. index_old++,index_new++,index_old变为12,index_new变为14,因为 lines_old[ 12 ] = lines_new[ 14 ],所以此步未检测到变化。
...
改进后的测试代码如下:
todo相关文章:
手动实现 git 的 git diff 功能
这是 git diff 后的效果,感觉挺简单的,不就是 比较新旧版本,新增了就用 "" 显示新加一行,删除了就用 "-" 显示删除一行,修改了一行就用 "-"、"" 显示将旧版本中的该行干掉了并…...
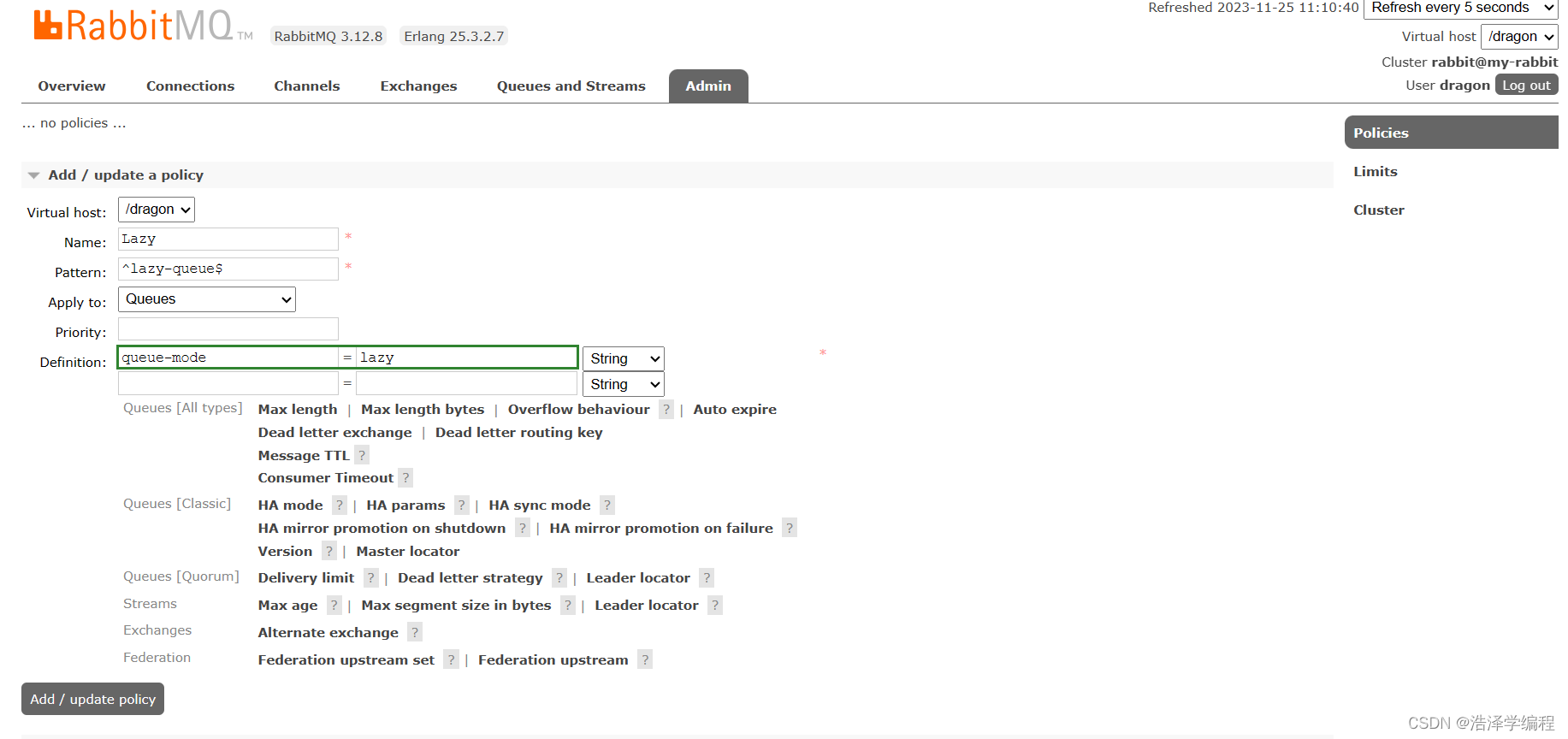
RabbitMQ之MQ的可靠性
文章目录 前言一、数据持久化交换机持久化队列持久化消息持久化 二、LazyQueue控制台配置Lazy模式代码配置Lazy模式更新已有队列为lazy模式 总结 前言 消息到达MQ以后,如果MQ不能及时保存,也会导致消息丢失,所以MQ的可靠性也非常重要。 一、…...
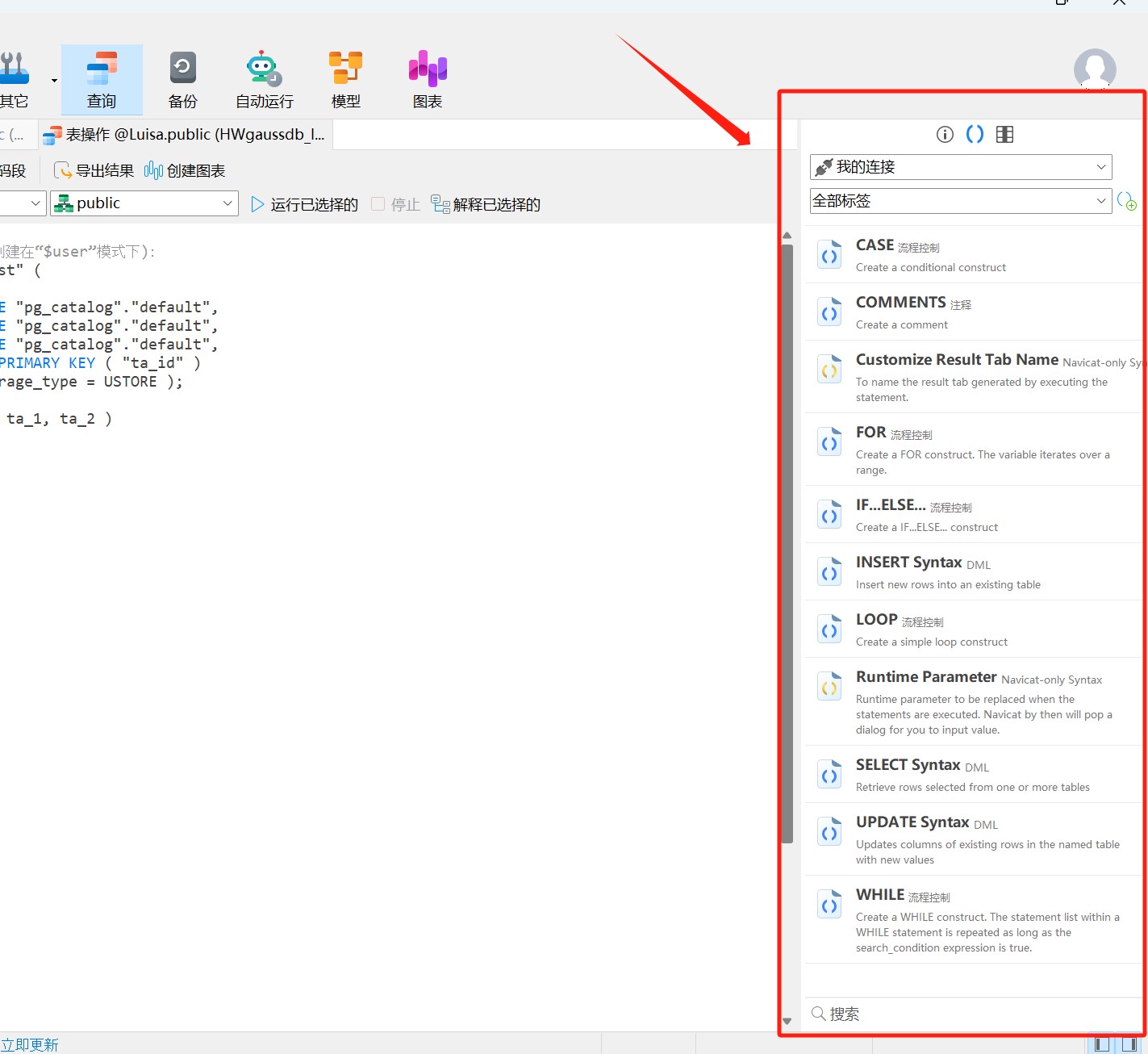
Navicat 技术指引 | 适用于 GaussDB 的查询编辑器
Navicat Premium(16.2.8 Windows版或以上) 已支持对 GaussDB 主备版的管理和开发功能。它不仅具备轻松、便捷的可视化数据查看和编辑功能,还提供强大的高阶功能(如模型、结构同步、协同合作、数据迁移等),这…...
Jenkins+Maven+Gitlab+Tomcat 自动化构建打包、部署
JenkinsMavenGitlabTomcat 自动化构建打包、部署 1、环境需求 本帖针对的是Linux环境,Windows或其他系统也可借鉴。具体只讲述Jenkins配置以及整个流程的实现。 1.JDK(或JRE)及Java环境变量配置,我用的是JDK1.8.0_144࿰…...
(2023码蹄杯)省赛(初赛)第三场真题(原题)(题解+AC代码)
题目1:MC0227堆煤球 码题集OJ-堆煤球 (matiji.net) 思路: 1.i从l枚举到r,i是8的倍数就跳过,i不是8的倍数就用等差数列求和公式i(1i)/2,最后累加到答案中即可 AC_Code:C #include<bits/stdc.h> using namespace std;int main( ) {in…...

第十二章 : Spring Boot 日志框架详解
第十二章 : Spring Boot 日志框架详解 前言 本章知识重点:介绍了日志诞生背景,4种日志框架:Logback、Log4j、Log4j2和Slf4j的优劣势分析,以及重点介绍了log4j2的应用示例以及配置,以及日志框架应用中遇到常见的问题以及如何处理。 背景 Java日志框架的发展历程可以追…...
STM32 -Bin/Hex文件格式解析
文章目录 1. 概述2. Hex文件2.1 格式解析2.2 数据类型2.3 举例解析2.4 合并两个Hex文件方法 3. Bin文件3.1 生成方式3.2 合并多个Bin文件方法3.3 打开Bin文件方式3.4 和Hex文件比较 4 总结 1. 概述 Hex文件:它是单片机和嵌入式工程编译输出的一种常见的目标文件格式…...

【Java 进阶篇】Redis:打开缓存之门
介绍 Redis(Remote Dictionary Server)是一个高性能的键值对存储系统,被广泛用作缓存、消息中间件和数据库。它以其快速的读写能力、支持多种数据结构和丰富的功能而闻名。在这篇博客中,我们将深入了解Redis的概念、安装以及基本…...

Python与设计模式--享元模式
10-Python与设计模式–享元模式 一、网上咖啡选购平台 假设有一个网上咖啡选购平台,客户可以在该平台上下订单订购咖啡,平台会根据用户位置进行 线下配送。假设其咖啡对象构造如下: class Coffee:name price 0def __init__(self,name):se…...
亚马逊云科技向量数据库助力生成式AI成功落地实践探秘(二)
向量数据库选择哪种近似搜索算法,选择合适的集群规模以及集群设置调优对于知识库的读写性能也十分关键,主要需要考虑以下几个方面: 向量数据库算法选择 在 OpenSearch 里,提供了两种 k-NN 的算法:HNSW (Hierarchical…...

怎么当代课老师教学生
老师朋友们,有没有帮忙当过代课老师呢?或者,没当过的老师是不是对这种职业充满了好奇?让我来分享一下,当代课老师的日常是什么样的吧! 备课 说起备课,那可是个大工程!不过ÿ…...
之表的数据插入及基本查询)
『 MySQL数据库 』表的增删查改(CRUD)之表的数据插入及基本查询
文章目录 📂 Create(创建/新增)📌全列插入与指定列插入📌📌单行数据插入与多行数据插入📌📌插入数据否则更新📌📌数据的替换📌 📂 Retrieve(查询)Ὄ…...

Vue中mvvm的作用
目录 模型表示应用程序的数据。在Vue.js中,它们是JavaScript对象。视图是用户界面。在Vue.js中,使用模板语法编写HTML的表示层。ViewModel是视图的抽象表示,负责处理用户输入的数据,并处理视图的数据绑定。ViewModel使用模型中的…...
基于springboot实现高校食堂移动预约点餐系统【项目源码】
基于springboot实现高校食堂移动预约点餐系统演示 Java语言简介 Java是由SUN公司推出,该公司于2010年被oracle公司收购。Java本是印度尼西亚的一个叫做爪洼岛的英文名称,也因此得来java是一杯正冒着热气咖啡的标识。Java语言在移动互联网的大背景下具备…...

用element ui上传带参数的文件,并用flask接收
需求 网页需要实现上传一个csv文件,并携带两个表单的参数给后端 方法 上传组件 <el-uploadclass"upload-demo"dragaction"/upload" <!--要上传到的路由地址,跟flask路由函数对应-->accept".csv" <!--只接…...
[Android]使用Git将项目提交到GitHub
如果你的Mac还没有安装Git,你可以通过Homebrew来安装它: brew install git 方式一:终端管理 1.创建本地Git仓库 在项目的根目录下,打开终端(Terminal)并执行以下命令来初始化一个新的Git仓库࿱…...

python cv2.imread()和Image.open()的区别和联系
文章目录 1. cv2.imread()1.1 cv2.imread参数说明1.2 注意事项 2. Image.open()3. cv2.imread()与Image.open()相互转化3.1 cv2.imread()转成Image.open():Image.fromarray()3.2 Image.open()转成cv2.imread():np.array() 1. cv2.imread() cv2.imread()…...
hdlbits系列verilog解答(exams/m2014_q4i)-45
文章目录 一、问题描述二、verilog源码三、仿真结果 一、问题描述 实现以下电路: 二、verilog源码 module top_module (output out);assign out 1b0;endmodule三、仿真结果 转载请注明出处!...
flink源码分析之功能组件(二)-kubeclient
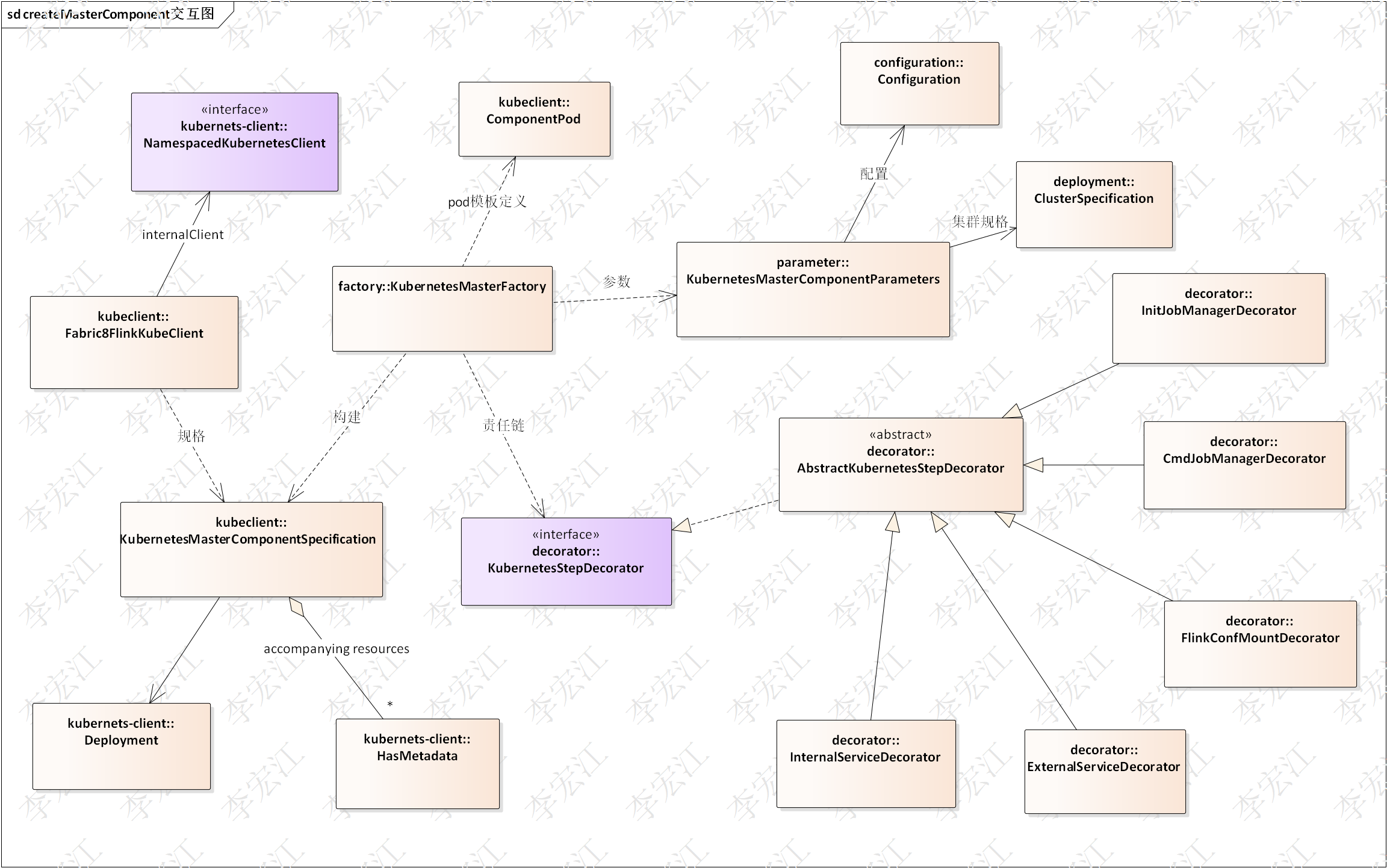
简介 本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics,future。其中kubeclient上一个系列介绍过,为了系列完整性,这里“copy”一下。 kubeclient组件…...
无需API开发,有赞小程序集成广告推广系统,提升品牌曝光
无需API开发,实现有赞小程序与其他系统的连接 有赞小程序作为一个多功能的电子商务解决方案,为商家提供了无需复杂API开发就可以实现系统连接和集成的便捷途径。通过有赞小程序,商家可以轻松实现与各种系统的数据同步和应用互联,…...

VOOHU:组合电感在多相DC-DC变换器中的选型与应用解析
随着CPU、GPU、FPGA等高性能处理器对供电电流的需求不断攀升(高达数百安培),多相DC-DC变换器成为主流拓扑。传统的分立电感方案需要大量元件,占据PCB空间,且瞬态响应受限。组合电感(又称耦合电感、集成式耦…...

哇!牛!快来报名“香港科大-哇牛”2026[人工智能]百万奖金国际创业大赛!!!
有些比赛,给你一张奖状。有些比赛,给你一次亮相。而更多项目方需要的,是一次从实验室走向市场,从技术验证走向产业放大,从中国走向全球舞台的机会。一十年只做一件事:深耕AI科创香港科技大学百万奖金国际创…...

基于 Qt C++ 开发一套集成阿里通义千问大模型的多模态智能应用终端
你想要基于 Qt C++ 开发一套**集成阿里通义千问大模型的多模态智能应用终端**,支持**图文音视频理解**,适配电商客服、工业质检、智能创作等阿里生态全场景,并具备高并发、高稳定性(日均调用超10亿次级别的架构设计)。 下面我给你一套**可直接落地的 Qt + 通义千问多模态…...
)
VSCode护眼主题终极指南:如何完美复刻Eclipse绿色背景(附详细配置代码)
VSCode护眼主题终极指南:如何完美复刻Eclipse绿色背景(附详细配置代码) 作为一名长期与代码打交道的开发者,眼睛的健康问题不容忽视。许多从Eclipse转向VSCode的用户都会怀念那个经典的绿色背景——它不仅代表着一种习惯ÿ…...

【Dify 2026插件开发权威指南】:零基础到生产级自定义插件的7大核心实践与避坑清单
第一章:Dify 2026插件生态全景与开发范式演进Dify 2026标志着插件架构从“能力扩展”迈向“智能协同”的关键跃迁。其插件生态不再局限于API代理或简单工具封装,而是以统一的语义契约(Semantic Contract)为基础,支持跨…...

为什么你的C# 14 AOT版Dify客户端在ARM64上崩溃?3类NativeAOT互操作雷区+2个[UnmanagedCallersOnly]避坑模板
第一章:为什么你的C# 14 AOT版Dify客户端在ARM64上崩溃?3类NativeAOT互操作雷区2个[UnmanagedCallersOnly]避坑模板ARM64平台上的NativeAOT(.NET 9 C# 14)编译器会彻底剥离JIT和运行时反射能力,导致传统P/Invoke与回调…...

2026届学术党必备的十大AI写作助手实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 一款基于先进自然语言处理跟知识图谱技术被构建的智能辅助系统是 AI 开题报告工具ÿ…...

SketchUp选择工具全解析:从点选到反选,6种技巧提升建模效率
SketchUp选择工具全解析:从点选到反选,6种技巧提升建模效率 在三维建模的世界里,精确选择是高效创作的基石。就像雕塑家需要精准控制每一处凿刻的力度和位置,SketchUp用户也必须掌握选择工具的精髓。许多中级用户虽然能完成基础建…...

基于KITTI数据集:从LIO-SAM部署到EVO精度评估全流程解析
1. KITTI数据集准备与格式转换 KITTI数据集作为自动驾驶领域最经典的公开数据集之一,包含了丰富的传感器数据和多场景的道路环境信息。对于SLAM研究者来说,2011_09_30_drive_0016等序列常被用作算法测试基准。但原始数据需要经过格式转换才能在ROS环境中…...
)
别再手动调间距了!用Matlab的tiledlayout函数搞定论文级多图排版(附代码)
告别繁琐排版:用Matlab tiledlayout打造学术级多图布局 还在为论文中的多图排版焦头烂额?每次调整subplot位置都要耗费半小时?Matlab R2019b引入的tiledlayout功能彻底改变了这一局面。这个被严重低估的工具,能让你的科研图表排版…...