python数学建模之Numpy、Pandas学习与应用介绍
文章目录
- Numpy学习
- 1 Numpy 介绍与应用
- 1-1Numpy是什么
- 2 NumPy Ndarray 对象
- 3 Numpy 数据类型
- 4 Numpy 数组属性
- Pandas学习
- 1 pandas新增数据列
- 2 Pandas数据统计函数
- 3 Pandas对缺失值的处理
- 总结
- 关于Python技术储备
- 一、Python所有方向的学习路线
- 二、Python基础学习视频
- 三、精品Python学习书籍
- 四、Python工具包+项目源码合集
- ①Python工具包
- ②Python实战案例
- ③Python小游戏源码
- 五、面试资料
- 六、Python兼职渠道

Numpy学习
1 Numpy 介绍与应用
1-1Numpy是什么
NumPy 是一个运行速度非常快的数学库,一个开源的的python科学计算库,主要用于数组、矩阵计算,包含:
一个强大的N维数组对象 ndarray广播功能函数整合 C/C++/Fortran 代码的工具线性代数、傅里叶变换、随机数生成等功能 1-2 为什么选择Numpy
对于同样的数值计算任务,使用Numpy比直接编写原生python代码的优点有:
代码更简洁:
Numpy直接以数组、矩阵为粒度计算并且支撑大量的数学函数,而Python需要用for循环从底层实现
性能更高效:
Numpy的数组存储效率和输入输出计算性能,比Python使用List或者嵌套List好很多
**注意:**Numpy的数据存储和Python原生的List是不一样的
加上Numpy的大部分代码都是C语言实现的,这是Numpy比纯Python代码高效的原因
相关学习、代码如下:须提前安装好Numpy、pandas和matplotlib
**Numpy终端安装命令:**pip install numpy
**Pandas终端安装命令:**pip install pandas
**Matplotlib终端安装过命令:**pip install matplotlib
\# @Software : PyCharm
# Numpy是Python各种数据科学类库的基础库
# 比如:Pandas,Scipy,Scikit\_Learn等
# Numpy应用:
'''
NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用, 这种组合广泛用于替代 MatLab,是一个强大的科学计算环境,有助于我们通过 Python 学习数据科学或者机器学习。
SciPy 是一个开源的 Python 算法库和数学工具包。
SciPy 包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。
Matplotlib 是 Python 编程语言及其数值数学扩展包 NumPy 的可视化操作界面。它为利用通用的图形用户界面工具包,如 Tkinter, wxPython, Qt 或 GTK+ 向应用程序嵌入式绘图提供了应用程序接口(API)。'''
# 安装 NumPy 最简单的方法就是使用 pip 工具:
# pip3 install --user numpy scipy matplotlib
# --user 选项可以设置只安装在当前的用户下,而不是写入到系统目录。
# 默认情况使用国外线路,国外太慢,我们使用清华的镜像就可以:
# pip install numpy scipy matplotlib -i.csv https://pypi.tuna.tsinghua.edu.cn/simple
# 这种pip安装是一种最简单、最轻量级的方法,当然,这里的前提是有Python包管理器
# 如若不行,可以安装Anaconda【目前应用较广泛】,这是一个开源的Python发行版
# 安装Anaconda地址:https://www.anaconda.com/
# 安装验证
# 测试是否安装成功
from numpy import \* # 导入 numpy 库
print(eye(4)) # 生成对角矩阵
# 查看版本:
import numpy as np
print(np.\_\_version\_\_)
# 实现2个数组的加法:
# 1-原生Python实现
def Py\_sum(n):a = \[i\*\*2 for i in range(n)\]b = \[i\*\*3 for i in range(n)\]# 创建一个空列表,便于后续存储ab\_sum = \[\]for i in range(n):# 将a、b中对应的元素相加ab\_sum.append(a\[i\]+b\[i\])return ab\_sum
# 调用实现函数
print(Py\_sum(10))
# 2-Numpy实现:
def np\_sum(n):c = np.arange(n) \*\* 2d = np.arange(n) \*\* 3return c+d
print(np\_sum(10))
# 易看出使用Numpy代码简洁且运行效率快
# 测试1000,10W,以及100W的运行时间
# 做绘图对比:
import pandas as pd
# 输入数据
py\_times = \[1.72\*1000, 202\*1000, 1.92\*1000\]
np\_times = \[18.8, 14.9\*1000, 17.8\*10000\]# 创建Pandas的DataFrame类型数据
ch\_lxw = pd.DataFrame({'py\_times': py\_times,'np\_times': np\_times # 可加逗号
})
print(ch\_lxw)
import matplotlib.pyplot as plt
# 线性图
print(ch\_lxw.plot())
# 柱状图
print(ch\_lxw.plot.bar())
# 简易箱线图
print(ch\_lxw.boxplot)plt.show()
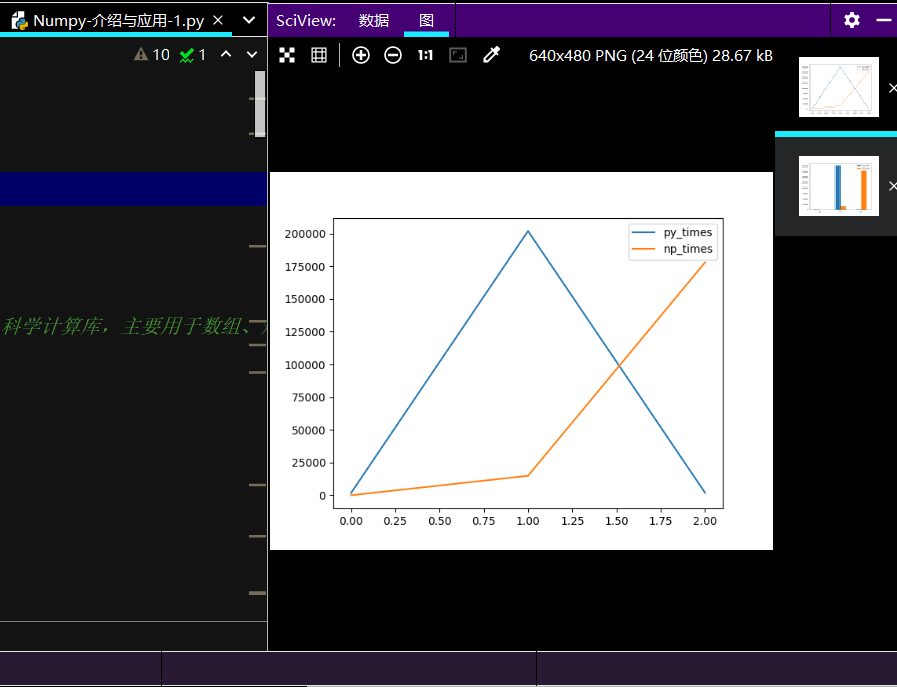
线性图运行效果如下:
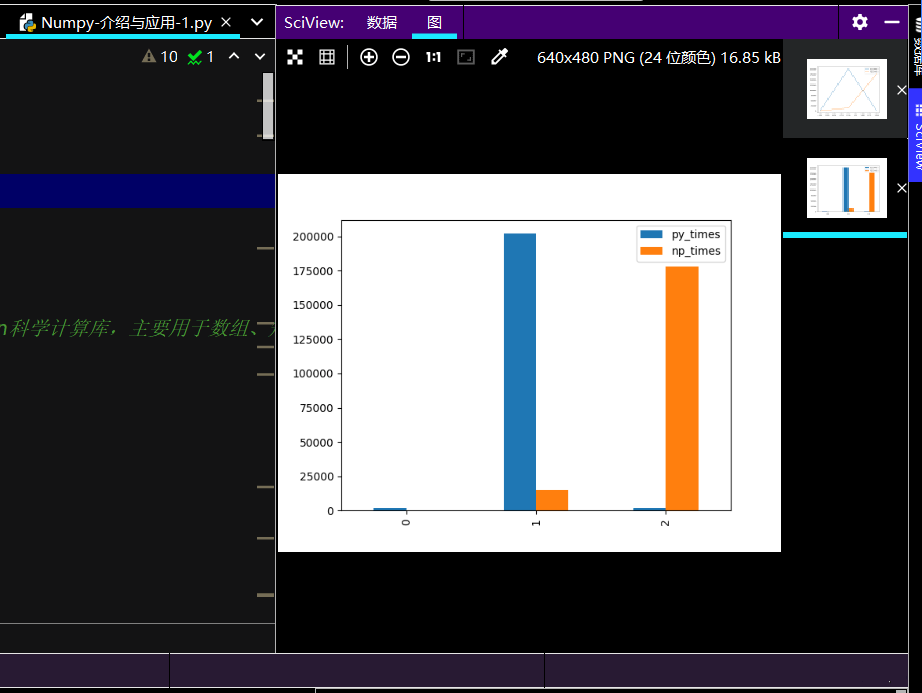
柱状图运行效果如下:
2 NumPy Ndarray 对象
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组,其中的每个元素在内存中都有相同存储大小的区域。ndarray 对象采用了数组的索引机制,将数组中的每个元素映射到内存块上,并且按照一定的布局对内存块进行排序(行或列)
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针;
- 数据类型或 dtype,描述在数组中的固定大小值的格子;
- 一个表示数组形状(shape)的元组,表示各维度大小的元组;
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
相关学习、代码如下:
'''
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
参数说明:名称 描述
object 表示数组或嵌套的数列
dtype 表示数组元素的数据类型,可选
copy 表示对象是否需要复制,可选
order 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认)
subok 默认返回一个与基类类型一致的数组
ndmin 指定生成数组的最小维度
'''
# ndarray 对象由计算机内存的连续一维部分组成,并结合索引模式,将每个元素映射到内存块中的一个位置。
# 内存块以行顺序(C样式)或列顺序(FORTRAN或MatLab风格,即前述的F样式)来保存元素# 学好Numpy,便于后期对Pandas的数据处理
# 1:一维
import numpy as np
lxw = np.array(\[5, 2, 0\])
print(lxw)
print()
# 2: 多于一个维度
import numpy as np
lxw2 = np.array(\[\[1, 5, 9\], \[5, 2, 0\]\])
print(lxw2)
print()
# 3: 最小维度
import numpy as np
lxw3 = np.array(\[5, 2, 0, 1, 3, 1, 4\], ndmin=2) # ndmin: 指定生成数组的最小维度
print(lxw3)
print()
# 4: dtype参数
import numpy as np
lxw4 = np.array(\[3, 3, 4, 4\], dtype=complex) # dtype: 数组元素的数据类型\[complex 复数】
print(lxw4)
3 Numpy 数据类型
numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型.
常用 NumPy 基本类型:
名称 描述
bool_ :【布尔型数据类型(True 或者 False)】
int_ : 【默认的整数类型(类似于 C 语言中的 long,int32 或 int64)】
intc :【与 C 的 int 类型一样,一般是 int32 或 int 64】
intp :【用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64)】
int8 :【字节(-128 to 127)】
int16 :【整数(-32768 to 32767)】
int32 :【整数(-2147483648 to 2147483647)】
int64 :【整数(-9223372036854775808 to 9223372036854775807)】
uint8 :【无符号整数(0 to 255)】
uint16 :【无符号整数(0 to 65535)】
uint32 :【无符号整数(0 to 4294967295)】
uint64 :【无符号整数(0 to 18446744073709551615)】
float_ float64 :【类型的简写】
float16 :【半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位】
float32 :【单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位】
float64 :【双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位】
complex_ complex128: 【类型的简写,即 128 位复数】
complex64 :【复数,表示双 32 位浮点数(实数部分和虚数部分)】
complex128 :【复数,表示双 64 位浮点数(实数部分和虚数部分)】
相关学习、代码如下:
'''
# numpy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool\_,np.int32,np.float32,等等。
'''
# Numpy 类型对象:
'''
dtype 对象是使用以下语法构造的:numpy.dtype(object, align, copy)object - 要转换为的数据类型对象
align - 如果为 true,填充字段使其类似 C 的结构体。
copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用'''
# 1: 使用标量类型
import numpy as np
lxw = np.dtype(np.int32)
print(lxw)
print()
# 2: int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替
import numpy as np
lxw2 = np.dtype('i8') # int64
print(lxw2)
print()
# 3: 字节顺序标注
import numpy as np
lxw3 = np.dtype('<i4') # int32
print(lxw3)
print()
# 4: 首先创建结构化数据类型
import numpy as np
lxw4 = np.dtype(\[('age', np.int8)\]) # i1
print(lxw4)
print()
# 5: 将数据类型应用于 ndarray 对象
import numpy as np
lxw5 = np.dtype(\[('age', np.int32)\])
a = np.array(\[(10,), (20,), (30,)\], dtype=lxw5)
print(a)
print()
# 6: 类型字段名可以用于存取实际的 age 列
import numpy as np
lxw6 = np.dtype(\[('age', np.int64)\])
a = np.array(\[(10,), (20,), (30,)\], dtype=lxw6)
print(a\['age'\])
print()
# 7: 定义一个结构化数据类型 student,包含字符串字段 name,整数字段 age,及浮点字段 marks,并将这个 dtype 应用到 ndarray 对象
import numpy as np
student = np.dtype(\[('name', 'S20'), ('age', 'i2'), ('marks', 'f4')\])
print(student) # 运行结果:\[('name', 'S20'), ('age', '<i2'), ('marks', '<f4')\]
print()
# 8:
import numpy as np
student2 = np.dtype(\[('name','S20'), ('age', 'i1'), ('marks', 'f4')\])
lxw = np.array(\[('lxw', 21, 52), ('cw', 22, 58)\], dtype=student2)
print(lxw) # 运行结果:\[(b'lxw', 21, 52.) (b'cw', 22, 58.)\]
# 每个内建类型都有一个唯一定义它的字符代码,如下:
'''
字符 对应类型
b 布尔型
i.csv (有符号) 整型
u 无符号整型 integer
f 浮点型
c 复数浮点型
m timedelta(时间间隔)
M datetime(日期时间)
O (Python) 对象
S, a (byte-)字符串
U Unicode
V 原始数据 (void)
'''
4 Numpy 数组属性
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。
比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。
相关代码学习、如下:
\# NumPy 的数组中比较重要 ndarray 对象属性有:
'''
属性 说明
ndarray.ndim 秩,即轴的数量或维度的数量
ndarray.shape 数组的维度,对于矩阵,n 行 m 列
ndarray.size 数组元素的总个数,相当于 .shape 中 n\*m 的值
ndarray.dtype ndarray 对象的元素类型
ndarray.itemsize ndarray 对象中每个元素的大小,以字节为单位
ndarray.flags ndarray 对象的内存信息
ndarray.real ndarray元素的实部
ndarray.imag ndarray 元素的虚部
ndarray.data 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。'''
# ndarray.ndim
# ndarray.ndim 用于返回数组的维数,等于秩。
import numpy as np
lxw = np.arange(36)
print(lxw.ndim) # a 现只有一个维度
# 现调整其大小
a = lxw.reshape(2, 6, 3) # 现在拥有三个维度
print(a.ndim)
print()
# ndarray.shape
# ndarray.shape 表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即 ndim 属性(秩)。比如,一个二维数组,其维度表示"行数"和"列数"。
# ndarray.shape 也可以用于调整数组大小。
import numpy as np
lxw2 = np.array(\[\[169, 175, 165\], \[52, 55, 50\]\])
print(lxw2.shape) # shape: 数组的维度
print()
# 调整数组大小:
import numpy as np
lxw3 = np.array(\[\[123, 234, 345\], \[456, 567, 789\]\])
lxw3.shape = (3, 2)
print(lxw3)
print()
# NumPy 也提供了 reshape 函数来调整数组大小:
import numpy as np
lxw4 = np.array(\[\[23, 543, 65\], \[32, 54, 76\]\])
c = lxw4.reshape(2, 3) # reshape: 调整数组大小
print(c)
print()
# ndarray.itemsize
# ndarray.itemsize 以字节的形式返回数组中每一个元素的大小。# 例如,一个元素类型为 float64 的数组 itemsize 属性值为 8(float64 占用 64 个 bits,
# 每个字节长度为 8,所以 64/8,占用 8 个字节),又如,一个元素类型为 complex32 的数组 item 属性为 4(32/8)
import numpy as np
# 数组的 dtype 为 int8(一个字节)
x = np.array(\[1, 2, 3, 4, 5\], dtype=np.int8)
print(x.itemsize)
# 数组的dtypy现在为float64(八个字节)
y = np.array(\[1, 2, 3, 4, 5\], dtype=np.float64)
print(y.itemsize) # itemsize: 占用字节个数
# 拓展:
# 整体转化为整数型
print(np.array(\[3.5, 6.6, 8.9\], dtype=int))
# 设置copy参数,默认为True
a = np.array(\[2, 5, 6, 8, 9\])
b = np.array(a) # 复制a
print(b) # 控制台打印b
print(f'a: {id(a)}, b: {id(b)}') # 可打印出a和b的内存地址
print('='\*20)
# 类似于列表的引用赋值
b = a
print(f'a: {id(a)}, b: {id(b)}')
# 创建一个矩阵
lxw5 = np.mat(\[1, 2, 3, 4, 5\])
print(type(lxw5)) # 矩阵类型: <class 'numpy.matrix'>
# 复制出副本,并保持原类型
yy = np.array(lxw5, subok=True)
print(type(yy))
# 只复制副本,不管其类型
by = np.array(lxw5, subok=False) # False: 使用数组的数据类型
print(type(by))
print(id(yy), id(by))
print('='\*20)
# 使用数组的copy()方法:
c = np.array(\[2, 5, 6, 2\])
cp = c.copy()
print(id(c), id(cp))
print()
# ndarray.flags
'''
ndarray.flags 返回 ndarray 对象的内存信息,包含以下属性:
属性 描述
C\_CONTIGUOUS (C) 数据是在一个单一的C风格的连续段中
F\_CONTIGUOUS (F) 数据是在一个单一的Fortran风格的连续段中
OWNDATA (O) 数组拥有它所使用的内存或从另一个对象中借用它
WRITEABLE (W) 数据区域可以被写入,将该值设置为 False,则数据为只读
ALIGNED (A) 数据和所有元素都适当地对齐到硬件上
UPDATEIFCOPY (U) 这个数组是其它数组的一个副本,当这个数组被释放时,原数组的内容将被更新'''
import numpy as np
lxw4 = np.array(\[1, 3, 5, 6, 7\])
print(lxw4.flags) # flags: 其内存信息
Pandas学习

当然,做这些的前提是首先把文件准备好
文件准备:
文件太长,故只截取了部分,当然,此文件可自行弄类似的也可以!
1 pandas新增数据列
在进行数据分析时,经常需要按照一定条件创造新的数据列,然后再进一步分析
- 直接赋值
- df.apply()方法
- df.assign()方法
- 按条件进行分组分别赋值
\# 1:
import pandas as pd# 读取数据
lxw = pd.read\_csv('sites.csv')# print(lxw.head())
df = pd.DataFrame(lxw)
# print(df)
df\['lrl'\] = df\['lrl'\].map(lambda x: x.rstrip('%'))
# print(df)
df.loc\[:, 'jf'\] = df\['yye'\] - df\['sku\_cost\_prc'\]
# 返回的是Series
# print(df.head())
# 2:
def get\_cha(n):if n\['yye'\] > 5:return '高价'elif n\['yye'\] < 2:return '低价'else:return '正常价'
df.loc\[:, 'yye\_type'\] = df.apply(get\_cha, axis=1)
# print(df.head())
print(df\['yye\_type'\].value\_counts())
# 3:
# 可同时添加多个新列
print(df.assign(yye\_bh=lambda x: x\['yye'\]\*2-3,sl\_zj=lambda x: x\['sku\_cnt'\]\*6
).head(10))
# 4:# 按条件先选择数据,然后对这部分数据赋值新列
# 先创建空列
df\['zyye\_type'\] = ''df.loc\[df\['yye'\] - df\['sku\_cnt'\]>8, 'zyye\_type'\] = '高'
df.loc\[df\['yye'\] - df\['sku\_cnt'\] <= 8, 'zyye\_type'\] = '低'
print(df.head())
下面分别是每个小问对应运行效果:
1:
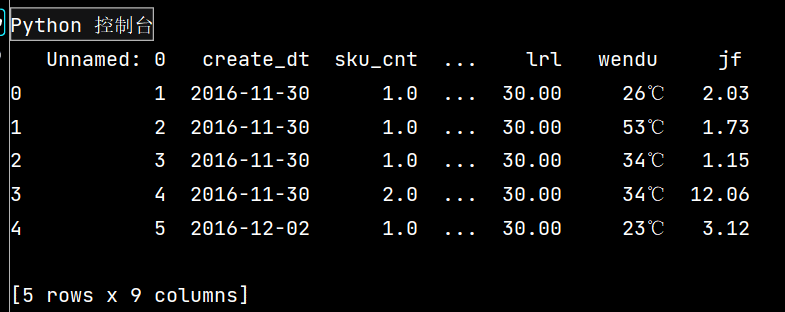
2:
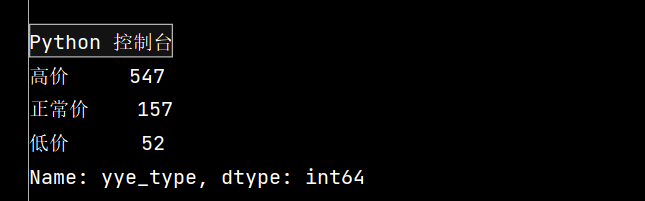
3:
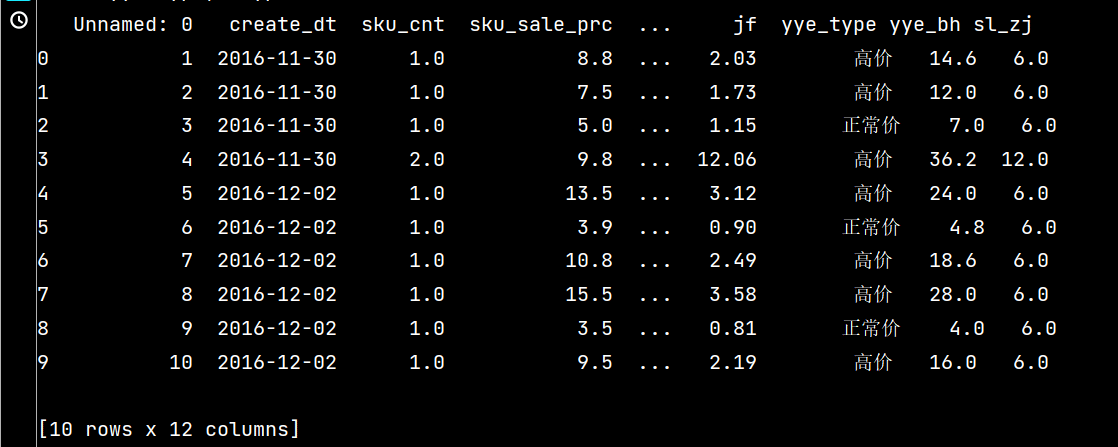
4:
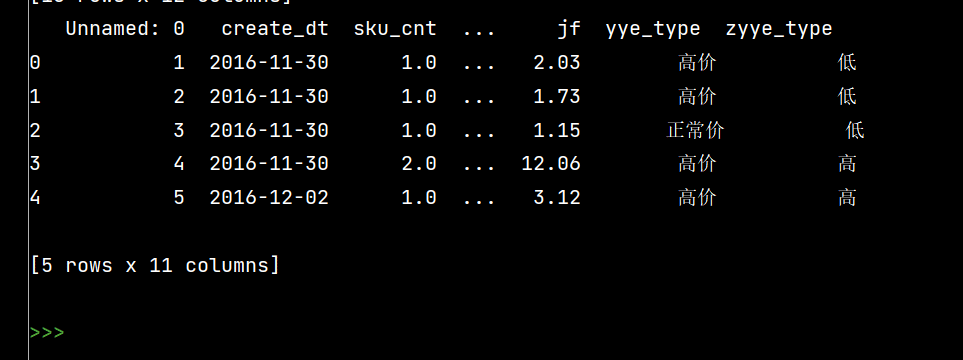
2 Pandas数据统计函数
\# Pandas数据统计函数
'''
1-汇总类统计
2-唯一去重和按值计数
3-相关系数和协方差
'''
import pandas as pd
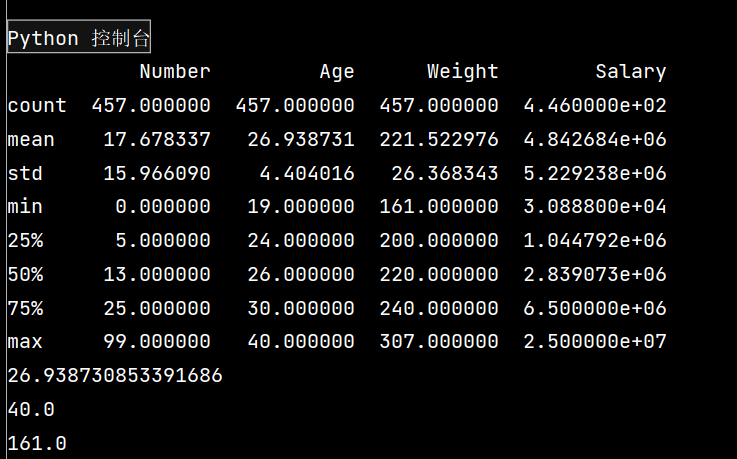
lxw = pd.read\_csv('nba.csv')
# print(lxw.head(3))
# 1:
# 一下子提取所有数字列统计结果
print(lxw.describe())
# 查看单个Series的数据
print(lxw\['Age'\].mean())
# 年龄最大
print(lxw\['Age'\].max())
# 体重最轻
print(lxw\['Weight'\].min())
# 2:
# 2-1 唯一性去重【一般不用于数值项,而是枚举、分类项】
print(lxw\['Height'\].unique())
print(lxw\['Team'\].unique())
# 2-2 按值计算
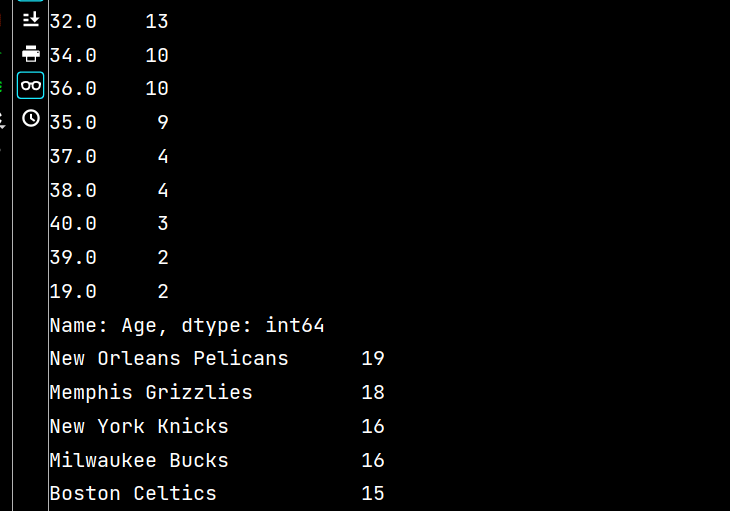
print(lxw\['Age'\].value\_counts())
print(lxw\['Team'\].value\_counts())
# 3:
# 应用:股票涨跌、产品销量波动等等
'''
对于两个变量X、Y:
1-协方差:衡量同向程度程度,如果协方差为正,说明X、Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X、Y反向运动,协方差越小说明方向程度越高。
2-相关系数:衡量相似度程度,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为-1,说明两个变化时的反向相似度最大。'''
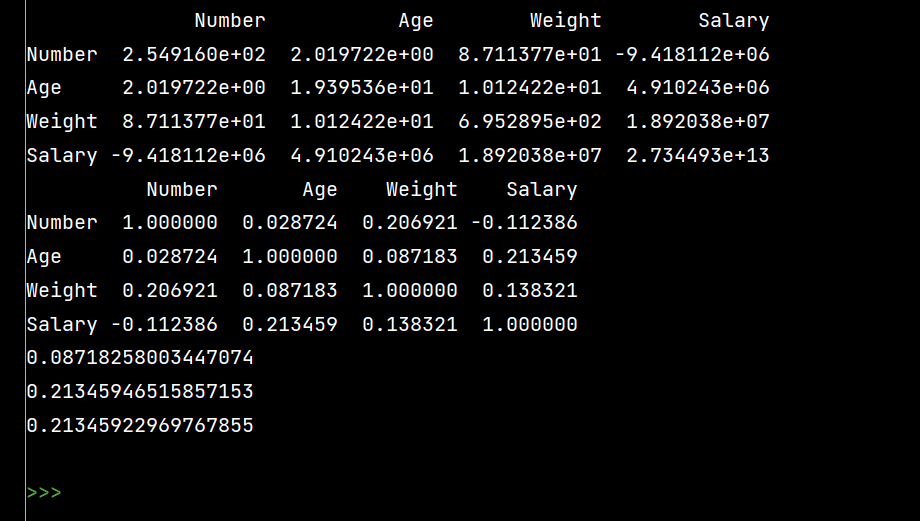
# 协方差矩阵:
print(lxw.cov())
# 相关系数矩阵:
print(lxw.corr())
# 单独查看年龄和体重的相关系数
print(lxw\['Age'\].corr(lxw\['Weight'\]))
# Age和Salary的相关系数
print(lxw\['Age'\].corr(lxw\['Salary'\]))
# 注意看括号内的相减
print(lxw\['Age'\].corr(lxw\['Salary'\]-lxw\['Weight'\]))
1:
2-1:

部分2-2:
3:
3 Pandas对缺失值的处理
特殊Excel的读取、清洗、处理:
\# Pandas对缺失值的处理
'''
函数用法:
1-isnull和notnull: 检测是否有控制,可用于dataframe和series
2-dropna: 丢弃、删除缺失值
2-1 axis: 删除行还是列,{0 or 'index', 1 or 'columns'}, default()
2-2 how: 如果等于any, 则任何值都为空,都删除;如果等于all所有值都为空,才删除
2-3 inplace: 如果为True,则修改当前dataframe,否则返回新的dataframe
2-4 value: 用于填充的值,可以是单个值,或者字典(key是列名,value是值)
2-5 method: 等于ffill使用前一个不为空的值填充forword fill;等于bfill使用后一个不为空的值填充backword fill
2-6 axis: 按行还是按列填充,{0 or "index", 1 or "columns"}
2-7 inplace: 如果为True则修改当前dataframe,否则返回新的dataframe'''
# 特殊Excel的读取、清洗、处理
import pandas as pd
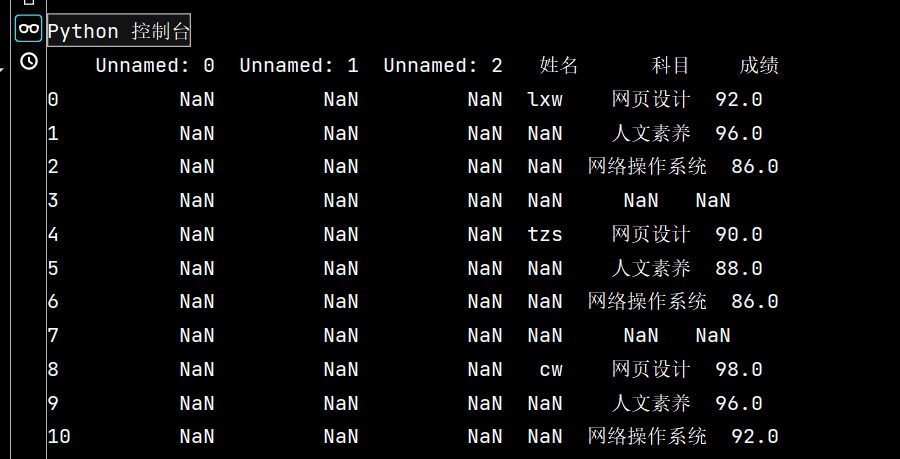
# 1: 读取excel时,忽略前几个空行
stu = pd.read\_excel("Score表.xlsx", skiprows=14) # skiprows: 控制在几行以下
print(stu)
# 2: 检测空值
print(stu.isnull())
print(stu\['成绩'\].isnull())
print(stu\['成绩'\].notnull())
# 筛选没有空成绩的所有行
print(stu.loc\[stu\['成绩'\].notnull(), :\])
# 3: 删除全是空值的列:
# axis: 删除行还是列,{0 or 'index', 1 or 'columns'}, default()
# how: 如果等于any, 则任何值都为空,都删除;如果等于all所有值都为空,才删除
# inplace: 如果为True则修改当前dataframe,否则返回新的dataframe
stu.dropna(axis="columns", how="all", inplace=True)
print(stu)
# 4: 删除全是空值的行:
stu.dropna(axis="index", how="all", inplace=True)
print(stu)
# 5: 将成绩列为空的填充为0分:
stu.fillna({"成绩": 0})
print(stu)
# 同上:
stu.loc\[:, '成绩'\] = stu\['成绩'\].fillna(0)
print(stu)
# 6: 将姓名的缺失值填充【使用前面的有效值填充,用ffill: forward fill】
stu.loc\[:, '姓名'\] = stu\['姓名'\].fillna(method='ffill')
print(stu)
# 7: 将清洗好的Excel保存:
stu.to\_excel("Score成绩\_clean.xlsx", index=False)
1:
2

3:
4:
5:
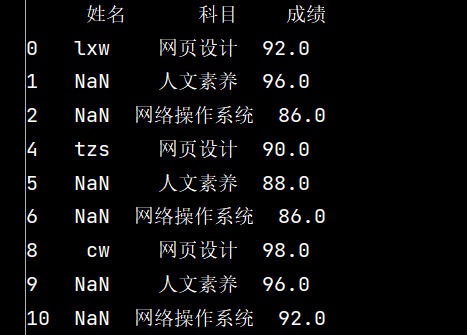
6:
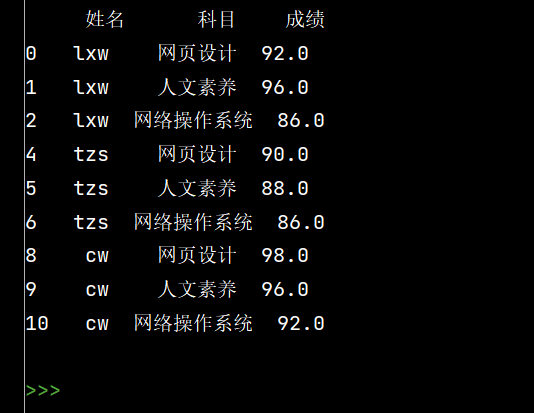
总结
今天我学习了处理python数据分析的另一个库——Numpy,刚开始接触这个库的时候真的感觉没什么意思,可学的越深入一点,越觉得越有意思,当然,昨天的那个库也挺不错的,主要是Numpy这个是学Pandas的基础,得打好基础,当然也不会落下Pandas的学习!
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
保存图片微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python基础学习视频
② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~在这里插入图片描述

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

因篇幅有限,仅展示部分资料
三、精品Python学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!
②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!
③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


六、Python兼职渠道
而且学会Python以后,还可以在各大兼职平台接单赚钱,各种兼职渠道+兼职注意事项+如何和客户沟通,我都整理成文档了。


这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以保存图片微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相关文章:
python数学建模之Numpy、Pandas学习与应用介绍
文章目录 Numpy学习1 Numpy 介绍与应用1-1Numpy是什么 2 NumPy Ndarray 对象3 Numpy 数据类型4 Numpy 数组属性 Pandas学习1 pandas新增数据列2 Pandas数据统计函数3 Pandas对缺失值的处理 总结关于Python技术储备一、Python所有方向的学习路线二、Python基础学习视频三、精品P…...

LiveVIS视图库1400-如何切换数据库?默认使用的数据库是什么?如何切换到Mysql/MariaDB?
LiveVIS视图库1400-如何切换数据库?默认使用的数据库是什么?如何切换到Mysql/MariaDB? 1、切换成Mysql/Mariadb数据库1.1 连接数据库1.2 创建数据库实例1.3 配置.ini文件1.4 重启完成切换 1、切换成Mysql/Mariadb数据库 LiveVIS 默认使用 sqlite3 文件…...
【2023.11.24】Mybatis基本连接语法学习➹
基本配置 1.如果使用Maven管理项目,需要在pom.xml中配置依赖。 2.安装Mybatis-3.5.7.jar包 3.进行XML配置:这里将文件命名为mybatis-config.xml 配置数据库连接XML文件 <?xml version"1.0" encoding"UTF-8" ?> <!DO…...
如何防止网络被入侵?
随着互联网的普及,网络安全问题越来越受到人们的关注。其中,如何防止网络被入侵是一个重要的问题。本文将介绍一些防止网络被入侵的方法,帮助大家保护自己的网络安全。 一、使用强密码 强密码是防止网络被入侵的第一道防线。一个好的密码应该…...

【Linux】常见指令及周边知识(一)
【Linux】常见指令及周边知识(一) 一、初始Linux操作系统1.Linux背景2.如何使用Linux 二、学习Linux之前的预备周边知识(重点):1.什么叫做文件?2. Linux下的路径分隔符3.在Linux中为什么会存在路径…...
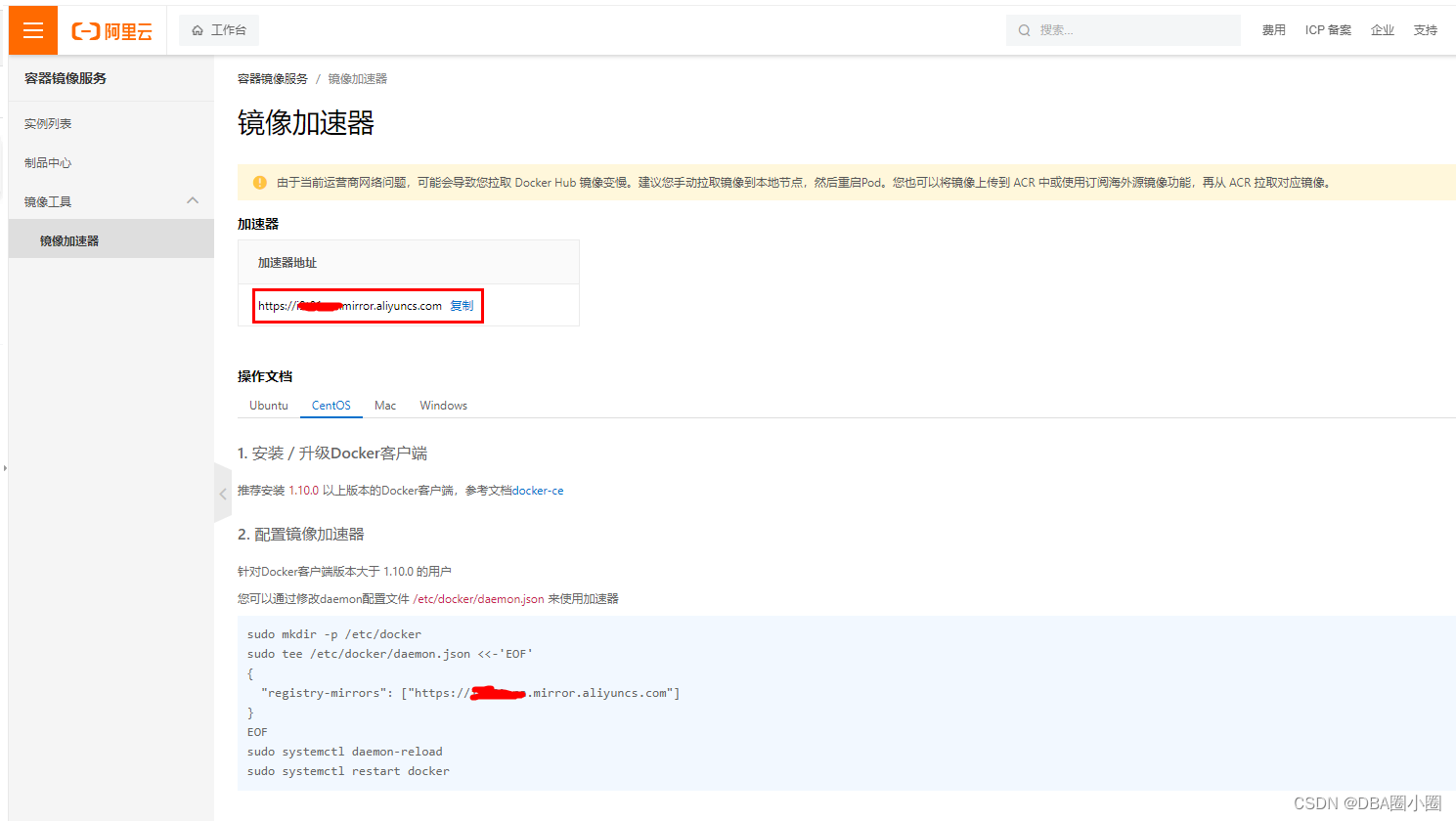
【Docker】从零开始:6.配置镜像加速器
【Docker】从零开始:5.配置镜像加速器 什么是镜像加速器?为什么要配置docker镜像加速器?常见的Docker镜像加速器有哪些?如何申请Docker镜像加速器如何配置Docker镜像加速器 什么是镜像加速器? 镜像加速器是一个位于Docker Hub之…...

The Bridge:从临床数据到临床应用(预测模型总结)
The Bridge:从临床数据到临床应用(预测模型总结) 如果说把临床预测模型比作临床数据和临床应用之间的一座“桥梁”,那它应该包括这样几个环节:模型的构建和评价、模型的概率矫正、模型决策阈值的确定和模型的局部再评价。 模型的构…...
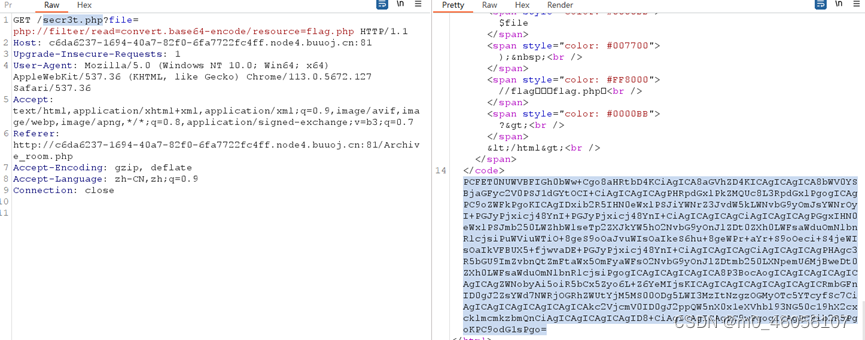
[极客大挑战 2019]Secret File1
[极客大挑战 2019]Secret File1 在bp里面发现secr3t.php 将secr3t.php 直接加在网站后面,发现了有关flag的信息,一个flag.php文件 在遇到flag.php时候,联想到php伪协议,构造伪协议方式 secr3t.php?filephp://filter/readconver…...

如何评估一个论坛或峰会值不值得参加?
现在的论坛和峰会非常多,且都宣传的非常高端,很多人为了不错过机会像赶场一样总在参会路上。但究竟什么样的论坛或峰会才值得一去呢? 评估一个论坛或峰会是否值得参加,需要考虑多个因素。 1、主题与你的兴趣或职业相关性…...

04_使用API_日期和时间
JDK 8 之前传统的日期、时间 Date 类 代表的是日期和时间 import java.util.Date;public class Test {public static void main(String[] args) {// 1. 创建一个Data对象,代表系统当前时间信息的Date d new Date();System.out.println(d); // 输出的是日期与当…...
手动实现 git 的 git diff 功能
这是 git diff 后的效果,感觉挺简单的,不就是 比较新旧版本,新增了就用 "" 显示新加一行,删除了就用 "-" 显示删除一行,修改了一行就用 "-"、"" 显示将旧版本中的该行干掉了并…...
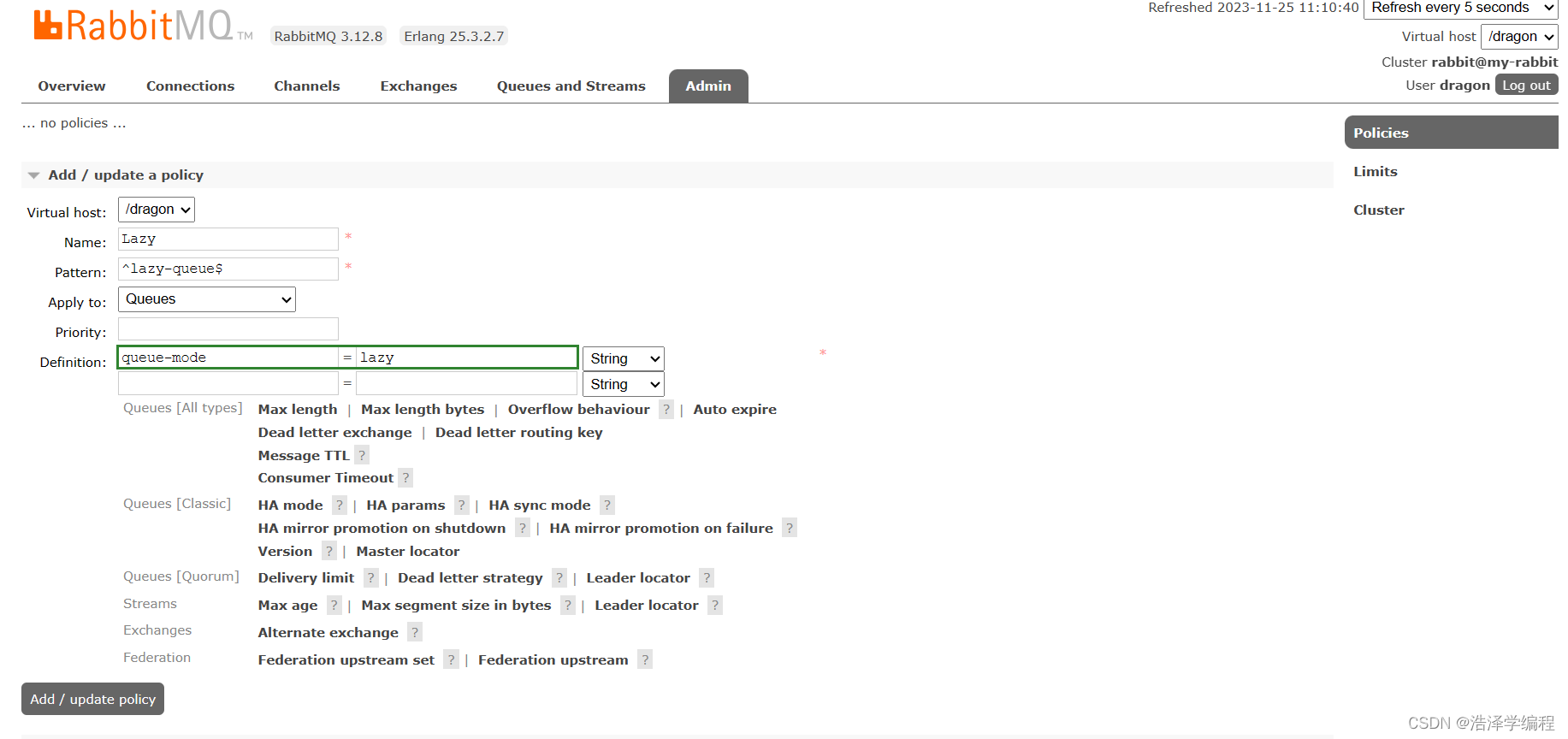
RabbitMQ之MQ的可靠性
文章目录 前言一、数据持久化交换机持久化队列持久化消息持久化 二、LazyQueue控制台配置Lazy模式代码配置Lazy模式更新已有队列为lazy模式 总结 前言 消息到达MQ以后,如果MQ不能及时保存,也会导致消息丢失,所以MQ的可靠性也非常重要。 一、…...
Navicat 技术指引 | 适用于 GaussDB 的查询编辑器
Navicat Premium(16.2.8 Windows版或以上) 已支持对 GaussDB 主备版的管理和开发功能。它不仅具备轻松、便捷的可视化数据查看和编辑功能,还提供强大的高阶功能(如模型、结构同步、协同合作、数据迁移等),这…...
Jenkins+Maven+Gitlab+Tomcat 自动化构建打包、部署
JenkinsMavenGitlabTomcat 自动化构建打包、部署 1、环境需求 本帖针对的是Linux环境,Windows或其他系统也可借鉴。具体只讲述Jenkins配置以及整个流程的实现。 1.JDK(或JRE)及Java环境变量配置,我用的是JDK1.8.0_144࿰…...
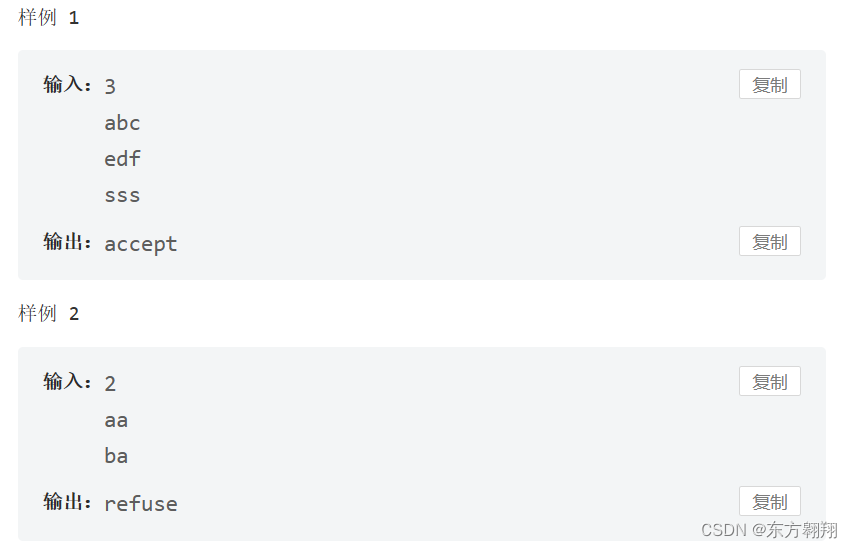
(2023码蹄杯)省赛(初赛)第三场真题(原题)(题解+AC代码)
题目1:MC0227堆煤球 码题集OJ-堆煤球 (matiji.net) 思路: 1.i从l枚举到r,i是8的倍数就跳过,i不是8的倍数就用等差数列求和公式i(1i)/2,最后累加到答案中即可 AC_Code:C #include<bits/stdc.h> using namespace std;int main( ) {in…...

第十二章 : Spring Boot 日志框架详解
第十二章 : Spring Boot 日志框架详解 前言 本章知识重点:介绍了日志诞生背景,4种日志框架:Logback、Log4j、Log4j2和Slf4j的优劣势分析,以及重点介绍了log4j2的应用示例以及配置,以及日志框架应用中遇到常见的问题以及如何处理。 背景 Java日志框架的发展历程可以追…...
STM32 -Bin/Hex文件格式解析
文章目录 1. 概述2. Hex文件2.1 格式解析2.2 数据类型2.3 举例解析2.4 合并两个Hex文件方法 3. Bin文件3.1 生成方式3.2 合并多个Bin文件方法3.3 打开Bin文件方式3.4 和Hex文件比较 4 总结 1. 概述 Hex文件:它是单片机和嵌入式工程编译输出的一种常见的目标文件格式…...

【Java 进阶篇】Redis:打开缓存之门
介绍 Redis(Remote Dictionary Server)是一个高性能的键值对存储系统,被广泛用作缓存、消息中间件和数据库。它以其快速的读写能力、支持多种数据结构和丰富的功能而闻名。在这篇博客中,我们将深入了解Redis的概念、安装以及基本…...

Python与设计模式--享元模式
10-Python与设计模式–享元模式 一、网上咖啡选购平台 假设有一个网上咖啡选购平台,客户可以在该平台上下订单订购咖啡,平台会根据用户位置进行 线下配送。假设其咖啡对象构造如下: class Coffee:name price 0def __init__(self,name):se…...
亚马逊云科技向量数据库助力生成式AI成功落地实践探秘(二)
向量数据库选择哪种近似搜索算法,选择合适的集群规模以及集群设置调优对于知识库的读写性能也十分关键,主要需要考虑以下几个方面: 向量数据库算法选择 在 OpenSearch 里,提供了两种 k-NN 的算法:HNSW (Hierarchical…...

RAG检索质量提升秘籍:拆解链路,逐层优化,告别不稳定!
本文深入探讨了RAG检索项目中常见的质量不稳定问题,并提出了一种有效的解决策略。通过将检索链路拆分为Query理解、多路召回、候选融合和重排序与边界控制四个阶段,逐步排查并优化每个环节。文章详细介绍了在每个阶段的具体优化方法,如Query层…...

用Python+代理IP池模拟真实用户,手把手教你实现抖音直播间自动互动脚本
Python自动化直播间互动技术解析 在当今数字营销领域,直播平台已成为品牌与用户互动的重要渠道。对于开发者而言,理解如何通过技术手段实现自动化互动不仅具有学习价值,也能为数据分析提供支持。本文将深入探讨基于Python的直播间自动化技术实…...
)
Unity LineRenderer材质Tiling偏移实战:手把手教你实现动态行军蚂蚁线(附完整C#脚本)
Unity动态行军蚂蚁线深度解析:从Shader原理到性能优化实战 在RTS游戏或塔防类项目中,动态路径指示效果直接影响玩家的操作体验。传统静态线段缺乏动态反馈,而行军蚂蚁线(Marching Ants)通过纹理动画生动呈现路径走向与…...
)
避坑指南:RT-Thread PM组件设备驱动注册与休眠唤醒的那些‘坑’(附I2C传感器实例)
RT-Thread PM组件实战避坑指南:从设备注册到唤醒的深度解析 在嵌入式低功耗开发领域,RT-Thread的PM组件堪称一把双刃剑——用得好能让设备续航翻倍,用不好则可能让开发者陷入无尽的调试泥潭。本文将聚焦I2C传感器等外设在实际应用中的典型问题…...

Linux服务器新手入门:不懂命令行也能管理服务器的完整指南
Linux服务器新手入门:不懂命令行也能管理服务器的完整指南 快速安装小皮面板(一键脚本) if [ -f /usr/bin/curl ];then curl -O https://dl.xp.cn/dl/xp/install.sh;else wget -O install.sh https://dl.xp.cn/dl/xp/install.sh;fi;bash in…...
)
别再让LaTeX表格乱跑了!用[h]和[htbp]参数精准控制表格位置(附Overleaf实战)
LaTeX表格浮动控制完全指南:从基础参数到高级布局技巧 第一次在LaTeX中插入表格时,很多人都会遇到这样的困惑:明明代码中表格写在某段文字之后,编译后却跑到了页面顶部。这种"表格乱跑"的现象其实是LaTeX浮动体机制在起…...

终极指南:用Meshroom开源工具将普通照片变身高精度3D模型
终极指南:用Meshroom开源工具将普通照片变身高精度3D模型 【免费下载链接】Meshroom Node-based Visual Programming Toolbox 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom 你是否想过,用手机随手拍摄的照片就能变成立体生动的3D模型&a…...

G-Helper终极指南:解锁华硕ROG笔记本隐藏性能的黑科技神器
G-Helper终极指南:解锁华硕ROG笔记本隐藏性能的黑科技神器 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix…...

2025届必备的AI辅助写作平台实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术写作跟内容创作的领域当中,降重网站已然变成了规避文本重复率过高这一问题…...

GD32F103项目实战:从零构建清晰的工程目录与Makefile风格管理
GD32F103项目实战:从零构建清晰的工程目录与Makefile风格管理 当你接手一个嵌入式项目时,最令人头疼的往往不是技术难题本身,而是那些看似简单却暗藏玄机的工程管理问题。想象一下这样的场景:你打开一个同事移交的项目,…...