【Python百宝箱】Python数据探险:Excel与数据科学的完美结合
前言
在当今信息爆炸的时代,数据处理和分析已经成为各行各业不可或缺的一部分。在众多数据处理工具中,Python以其简洁而强大的语法成为数据科学家和分析师的首选之一。本文将深入探讨与电子表格处理相关的Python库,介绍它们的功能、应用场景以及实际示例,帮助读者更好地利用这些工具进行数据处理和分析。
本文将重点介绍五个与电子表格处理相关的Python库,包括 openpyxl、pandas、xlrd、xlsxwriter、以及 pyexcel。每个库都有其独特的特点和应用场景,涵盖了从Excel文件读写到复杂数据分析的方方面面。此外,我们还将探讨三个在数据处理中与Excel集成的工具:pandasgui、DataNitro、和 xlwings,以及两个用于数据分析报告和SQL语法查询的库:pandas-profiling和pandasql。
探索Python中的电子表格处理神器
文章目录
- 前言
- 探索Python中的电子表格处理神器
- 1. **`openpyxl` - Excel文件的掌控者**
- 1.1 简介
- 1.2 常见应用场景
- 1.3 示例代码 - 基础操作
- 1.4 示例代码 - 添加图表
- 1.5 示例代码 - 数据合并与样式设置
- 1.6 示例代码 - 读取Excel文件
- 2. **`pandas` - 数据分析的黄金利器**
- 2.1 简介
- 2.2 常见应用场景
- 2.3 示例代码 - 创建和显示DataFrame
- 2.4 示例代码 - 数据清洗与统计
- 2.5 示例代码 - 数据可视化
- 2.6 示例代码 - 数据筛选与分组
- 3. **`xlrd` - Excel数据的快速解读者**
- 3.1 简介
- 3.2 常见应用场景
- 3.3 示例代码 - 基础读取
- 3.4 示例代码 - 逐行读取数据
- 3.5 示例代码 - 数据类型处理
- 3.6 示例代码 - 数据筛选与统计
- 4. **`xlsxwriter` - 打造独具特色的Excel文件**
- 4.1 简介
- 4.2 常见应用场景
- 4.3 示例代码 - 基础数据写入
- 4.4 示例代码 - 添加图表
- 4.5 示例代码 - 条件格式设置
- 4.6 示例代码 - 单元格样式设置
- 4.7 示例代码 - 多工作表操作
- 5. **`pyexcel` - 轻松驾驭Excel的好帮手**
- 5.1 简介
- 5.2 常见应用场景
- 5.3 示例代码 - 数据写入到Excel文件
- 5.4 示例代码 - 从Excel文件读取数据
- 5.5 示例代码 - 数据操作与过滤
- 6. **`pandasgui` - 数据探索的图形化利器**
- 6.1 简介
- 6.2 常见应用场景
- 6.3 示例代码
- 6.4 示例代码 - 数据过滤与统计
- 7. **`DataNitro` - 将Excel变身为Python IDE**
- 7.1 简介
- 7.2 常见应用场景
- 7.3 示例代码
- 7.4 示例代码 - 利用Python进行数据分析
- 8. **`xlwings` - 在Excel中集成Python代码**
- 8.1 简介
- 8.2 常见应用场景
- 8.3 示例代码
- 8.4 示例代码 - 利用Python进行高级数据分析
- 9. **`pandas-profiling` - 自动生成数据分析报告**
- 9.1 简介
- 9.2 常见应用场景
- 9.3 示例代码
- 9.4 示例代码 - 通过报告进行数据可视化
- 10. **`pandasql` - 使用SQL语法进行数据查询**
- 10.1 简介
- 10.2 常见应用场景
- 10.3 示例代码
- 10.4 示例代码 - 多表联合查询
- 总结
1. openpyxl - Excel文件的掌控者
1.1 简介
openpyxl是一个功能强大的Python库,专为处理Excel文件而设计。它提供了丰富的功能,包括读写Excel文件、格式设置、图表插入等,使得开发人员能够高效地操作电子表格数据。该库支持.xlsx格式,是现代Excel文件的标准。
1.2 常见应用场景
- 数据导入导出到Excel: 将数据从其他数据源导入到Excel,或将处理过的数据导出为Excel文件,是许多项目中常见的任务。
- Excel文件的自动化处理: 在自动化脚本中使用
openpyxl可以实现诸如生成报表、批量修改数据等任务,极大地提高工作效率。
1.3 示例代码 - 基础操作
from openpyxl import Workbook# 创建一个新的Excel工作簿
workbook = Workbook()# 选择默认的活动工作表
sheet = workbook.active# 在单元格A1中写入数据
sheet['A1'] = 'Hello'# 保存工作簿到文件
workbook.save('example.xlsx')
1.4 示例代码 - 添加图表
from openpyxl import Workbook
from openpyxl.chart import BarChart, Reference# 创建一个新的Excel工作簿
workbook = Workbook()# 选择默认的活动工作表
sheet = workbook.active# 添加数据
data = [['Category', 'A', 'B', 'C'],['Data 1', 3, 6, 9],['Data 2', 4, 8, 12],
]for row in data:sheet.append(row)# 创建柱状图
chart = BarChart()
chart.add_data(Reference(sheet, min_col=2, min_row=1, max_col=4, max_row=3), titles_from_data=True)# 将图表插入到工作表
sheet.add_chart(chart, "E5")# 保存工作簿到文件
workbook.save('chart_example.xlsx')
在这个示例代码中,我们展示了如何使用openpyxl创建一个包含图表的Excel文件。首先,我们创建了一个新的工作簿和工作表,然后添加了数据。最后,通过BarChart类创建了一个柱状图,并将其插入到工作表中。这展示了openpyxl在处理Excel文件时的灵活性和强大功能。
1.5 示例代码 - 数据合并与样式设置
from openpyxl import Workbook
from openpyxl.styles import Alignment# 创建一个新的Excel工作簿
workbook = Workbook()# 选择默认的活动工作表
sheet = workbook.active# 合并单元格
sheet.merge_cells('A1:D1')# 设置合并后单元格的文本和居中
sheet['A1'] = 'Merged Cell'
sheet['A1'].alignment = Alignment(horizontal='center')# 设置单元格样式
sheet['A2'].font = sheet['B2'].font = sheet['C2'].font = sheet['D2'].font = sheet['A2'].font.copy(size=14, bold=True)
sheet['A2'] = 'Styled Cell'# 保存工作簿到文件
workbook.save('merged_and_styled_cells.xlsx')
这个示例代码演示了如何使用openpyxl进行更高级的操作,包括合并单元格和设置单元格样式。我们合并了A1到D1的单元格,并在合并后的单元格中心写入了文本。接着,我们对A2到D2的单元格进行了样式设置,包括设置字体大小和粗体。这展示了openpyxl在创建具有复杂结构和样式的Excel文件时的灵活性。
1.6 示例代码 - 读取Excel文件
from openpyxl import load_workbook# 打开现有的Excel文件
workbook = load_workbook('example.xlsx')# 选择默认的活动工作表
sheet = workbook.active# 读取单元格A1的数据
data = sheet['A1'].valueprint(f'Data in A1: {data}')
在这个示例中,我们使用openpyxl的load_workbook函数打开了一个已存在的Excel文件,并读取了A1单元格的数据。这展示了如何使用openpyxl读取已有的Excel文件,为后续的数据处理提供了基础。
通过这些示例代码,读者将更全面地了解openpyxl库的基础和高级用法,为在实际项目中应用提供了实用的参考。
2. pandas - 数据分析的黄金利器
2.1 简介
pandas是Python中用于数据分析和操作的核心库之一。它引入了两个主要的数据结构:Series和DataFrame,其中DataFrame特别适用于电子表格类的数据。pandas提供了丰富的函数和工具,使得数据的清洗、转换、分析和可视化变得更加高效。
2.2 常见应用场景
- 数据清洗和转换:
pandas提供了各种方法用于处理缺失值、重复项、异常值等,使得数据清洗变得简单而高效。 - 数据分析和统计:
pandas支持多种统计和分析操作,包括均值、中位数、标准差等,为用户提供了深入了解数据的手段。 - 数据可视化: 与其他数据可视化库(如
Matplotlib和Seaborn)结合使用,pandas能够快速生成各种图表,助力用户更直观地理解数据。
2.3 示例代码 - 创建和显示DataFrame
import pandas as pd# 创建一个简单的DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']}df = pd.DataFrame(data)# 显示DataFrame的内容
print(df)
在这个示例代码中,我们使用pandas创建了一个简单的DataFrame,并通过print函数显示了DataFrame的内容。DataFrame以表格的形式展示数据,每一列都有一个列名,每一行代表一个数据记录。这种结构使得数据的组织和处理变得非常直观和灵活。
2.4 示例代码 - 数据清洗与统计
# 添加一列新数据
df['Salary'] = [50000, 60000, 75000]# 计算年龄的平均值和工资的总和
average_age = df['Age'].mean()
total_salary = df['Salary'].sum()print(f'Average Age: {average_age}, Total Salary: {total_salary}')
在这个示例中,我们向DataFrame中添加了一列新数据(薪水),然后通过mean和sum函数分别计算了年龄的平均值和工资的总和。这展示了pandas在数据操作和统计方面的强大功能。
通过这些示例,读者将更深入地了解pandas的核心概念和基础操作,为实际应用提供了坚实的基础。
2.5 示例代码 - 数据可视化
import pandas as pd
import matplotlib.pyplot as plt# 创建一个包含随机数据的DataFrame
data = {'Score': [85, 90, 78, 92, 88, 95, 80]}
scores_df = pd.DataFrame(data)# 绘制直方图
scores_df['Score'].plot(kind='hist', bins=10, edgecolor='black')# 添加标签和标题
plt.xlabel('Score')
plt.ylabel('Frequency')
plt.title('Distribution of Scores')# 显示图表
plt.show()
在这个示例代码中,我们使用pandas创建了一个包含随机数据的DataFrame,并通过matplotlib绘制了该数据的直方图。这展示了pandas与其他数据可视化库的无缝集成,使得生成图表变得非常方便。
2.6 示例代码 - 数据筛选与分组
# 筛选年龄大于30的数据
filtered_df = df[df['Age'] > 30]# 按城市分组并计算平均年龄
grouped_df = df.groupby('City')['Age'].mean()print('Filtered DataFrame:')
print(filtered_df)
print('\nGrouped DataFrame:')
print(grouped_df)
在这个示例中,我们使用pandas对DataFrame进行了筛选操作,选取了年龄大于30的数据。接着,我们通过groupby函数按城市对数据进行了分组,并计算了每个城市的平均年龄。这展示了pandas在数据筛选和分组方面的灵活性。
通过这些高级示例,读者将更深入地了解如何在实际场景中应用pandas进行数据处理、分析和可视化。
3. xlrd - Excel数据的快速解读者
3.1 简介
xlrd是一个专门用于读取Excel文件的Python库。尽管它的主要功能是读取数据,但在许多数据分析和处理任务中,数据的快速读取是非常关键的一步。xlrd提供了简便而高效的方法,使得从Excel中提取数据变得轻松。
3.2 常见应用场景
- 快速读取Excel文件中的数据: 在数据处理过程中,通常需要从Excel文件中提取数据。
xlrd通过提供直观的接口,使得这一任务变得异常简单。 - 与其他库搭配进行数据处理: 作为数据读取的一部分,
xlrd常常与其他数据处理库(如pandas)结合使用,为整个数据分析流程提供输入。
3.3 示例代码 - 基础读取
import xlrd# 打开Excel文件
workbook = xlrd.open_workbook('example.xlsx')# 选择第一个工作表
sheet = workbook.sheet_by_index(0)# 读取单元格A1的数据
data = sheet.cell_value(0, 0)print(data)
在这个示例代码中,我们使用xlrd打开了一个Excel文件,并选择了第一个工作表。然后,通过cell_value方法读取了A1单元格的数据。这展示了xlrd在最基础的数据读取任务中的简便性。
3.4 示例代码 - 逐行读取数据
# 获取工作表的行数和列数
num_rows = sheet.nrows
num_cols = sheet.ncols# 逐行读取数据并打印
for row_index in range(num_rows):row_data = sheet.row_values(row_index)print(f'Row {row_index + 1}: {row_data}')
在这个示例中,我们扩展了代码以逐行读取整个工作表的数据,并将每一行的数据打印出来。这展示了xlrd处理大量数据的能力。
通过这些示例,读者将更深入地了解xlrd库的基本用法和如何在实际项目中高效读取Excel文件。
3.5 示例代码 - 数据类型处理
# 获取单元格的数据类型
cell_type = sheet.cell_type(1, 1)# 根据数据类型进行处理
if cell_type == xlrd.XL_CELL_TEXT:cell_data = sheet.cell_value(1, 1)print(f'Data in B2 as Text: {cell_data}')
elif cell_type == xlrd.XL_CELL_NUMBER:cell_data = sheet.cell_value(1, 1)print(f'Data in B2 as Number: {cell_data}')
else:print('Data type not recognized')
在这个示例中,我们通过cell_type方法获取B2单元格的数据类型,然后根据数据类型进行相应的处理。这对于处理不同类型的数据非常有用,例如文本和数字。
3.6 示例代码 - 数据筛选与统计
# 筛选年龄大于30的数据
filtered_data = [sheet.row_values(i) for i in range(1, num_rows) if sheet.cell_value(i, 1) > 30]# 计算年龄的平均值
average_age = sum(data[1] for data in filtered_data) / len(filtered_data)print('Filtered Data:')
for data in filtered_data:print(data)print(f'\nAverage Age of Filtered Data: {average_age}')
在这个示例中,我们使用xlrd库筛选了年龄大于30的数据,并计算了这些数据的平均年龄。这突显了xlrd在数据处理中的一些基本用法。
通过这些示例,读者将更深入地了解如何使用xlrd库进行灵活的数据读取、类型处理和基本统计操作。
4. xlsxwriter - 打造独具特色的Excel文件
4.1 简介
xlsxwriter是一个强大的Python库,专为创建和修改Excel文件而设计。它的设计理念是提供最大程度的灵活性,使用户能够定制和控制生成的Excel文件的每个细节。除了基本的数据写入功能,xlsxwriter还支持添加图表、图形、条件格式等高级特性。
4.2 常见应用场景
- 自动生成报表和图表:
xlsxwriter使得用户能够通过Python脚本生成包含各种数据和图表的报表,无需手动操作Excel。 - Excel文件的定制化生成: 用户可以通过
xlsxwriter创建满足特定需求的Excel文件,包括特殊格式、公式、图表等。
4.3 示例代码 - 基础数据写入
import xlsxwriter# 创建一个新的Excel文件
workbook = xlsxwriter.Workbook('example.xlsx')# 添加一个工作表
worksheet = workbook.add_worksheet()# 在单元格A1中写入数据
worksheet.write('A1', 'Hello')# 保存工作簿到文件
workbook.close()
在这个示例代码中,我们使用xlsxwriter创建了一个新的Excel文件,添加了一个工作表,并在A1单元格写入了数据。这展示了xlsxwriter的基础数据写入功能。
4.4 示例代码 - 添加图表
import xlsxwriter# 创建一个新的Excel文件
workbook = xlsxwriter.Workbook('chart_example.xlsx')# 添加一个工作表
worksheet = workbook.add_worksheet()# 添加数据
data = [10, 20, 30, 40, 50]
worksheet.write_column('A1', data)# 创建一个柱状图
chart = workbook.add_chart({'type': 'column'})# 配置图表数据系列
chart.add_series({'values': 'Sheet1!$A$1:$A$5'})# 将图表插入到工作表
worksheet.insert_chart('C1', chart)# 保存工作簿到文件
workbook.close()
在这个示例代码中,我们展示了如何使用xlsxwriter创建一个包含柱状图的Excel文件。通过添加数据、创建图表对象、配置数据系列等步骤,用户可以轻松地在Excel中插入各种图表。
4.5 示例代码 - 条件格式设置
import xlsxwriter# 创建一个新的Excel文件
workbook = xlsxwriter.Workbook('conditional_formatting.xlsx')# 添加一个工作表
worksheet = workbook.add_worksheet()# 添加一列示例数据
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
worksheet.write_column('A1', data)# 添加条件格式:大于5的单元格变为绿色
worksheet.conditional_format('A1:A10', {'type': 'cell', 'criteria': '>', 'value': 5, 'format': workbook.add_format({'bg_color': 'green', 'font_color': 'white'})})# 保存工作簿到文件
workbook.close()
在这个示例代码中,我们展示了如何使用xlsxwriter为Excel文件中的数据添加条件格式。在这里,我们设置了一个条件:当单元格的值大于5时,将其背景色设为绿色。这演示了xlsxwriter在创建定制化Excel文件时的灵活性。
通过这些示例,读者将更全面地了解xlsxwriter库的用法和如何应用其高级功能创建定制化的Excel文件。
4.6 示例代码 - 单元格样式设置
import xlsxwriter# 创建一个新的Excel文件
workbook = xlsxwriter.Workbook('cell_styling.xlsx')# 添加一个工作表
worksheet = workbook.add_worksheet()# 在不同单元格应用不同样式
bold_format = workbook.add_format({'bold': True})
italic_format = workbook.add_format({'italic': True})
underline_format = workbook.add_format({'underline': True})
bg_color_format = workbook.add_format({'bg_color': 'yellow'})worksheet.write('A1', 'Bold Text', bold_format)
worksheet.write('A2', 'Italic Text', italic_format)
worksheet.write('A3', 'Underlined Text', underline_format)
worksheet.write('A4', 'Yellow Background', bg_color_format)# 保存工作簿到文件
workbook.close()
在这个示例代码中,我们展示了如何使用xlsxwriter为Excel文件中的单元格应用不同的样式。通过创建不同的样式对象,并在写入单元格时应用这些样式,用户可以实现对文本格式的精细控制。
4.7 示例代码 - 多工作表操作
import xlsxwriter# 创建一个新的Excel文件
workbook = xlsxwriter.Workbook('multi_sheet_example.xlsx')# 添加第一个工作表
worksheet1 = workbook.add_worksheet()
worksheet1.write('A1', 'Sheet 1 Data')# 添加第二个工作表
worksheet2 = workbook.add_worksheet()
worksheet2.write('A1', 'Sheet 2 Data')# 保存工作簿到文件
workbook.close()
在这个示例中,我们展示了如何使用xlsxwriter创建一个包含多个工作表的Excel文件。通过多次调用add_worksheet方法,用户可以轻松地在同一Excel文件中添加多个工作表,并分别向它们写入数据。
通过这些示例,读者将更加熟悉xlsxwriter库的高级用法和如何应用这些功能创建更加丰富多彩的Excel文件。
5. pyexcel - 轻松驾驭Excel的好帮手
5.1 简介
pyexcel是一个以简单易用为设计理念的Python库,为处理Excel文件提供了直观而高效的API。它的目标是简化Excel文件的处理流程,使得用户能够通过少量的代码实现对Excel数据的导入、导出和操作。
5.2 常见应用场景
- 简化Excel文件的处理流程:
pyexcel通过提供简单的接口,使得用户能够轻松地进行Excel文件的读写,省去了复杂的操作步骤。 - 跨平台的Excel数据交互: 由于
pyexcel是基于Python的跨平台库,因此用户可以在不同操作系统上轻松使用它进行Excel数据的处理。
5.3 示例代码 - 数据写入到Excel文件
import pyexcel as pe# 创建一个包含数据的字典
data = {"Name": ["Alice", "Bob", "Charlie"],"Age": [25, 30, 35],"City": ["New York", "San Francisco", "Los Angeles"]}# 写入数据到Excel文件
pe.save_as(records=data, dest_file_name="example.xlsx")
在这个示例代码中,我们使用pyexcel创建了一个包含数据的字典,并通过save_as函数将数据写入到Excel文件。这展示了pyexcel在数据导出方面的简便性。
5.4 示例代码 - 从Excel文件读取数据
import pyexcel as pe# 从Excel文件读取数据
records = pe.get_records(file_name="example.xlsx")# 显示读取的数据
for record in records:print(record)
在这个示例中,我们使用pyexcel的get_records函数从Excel文件中读取数据,并通过循环遍历显示了读取的数据。这展示了pyexcel在数据导入方面的便捷性。
5.5 示例代码 - 数据操作与过滤
import pyexcel as pe# 从Excel文件读取数据
records = pe.get_records(file_name="example.xlsx")# 过滤年龄大于30的数据
filtered_data = [record for record in records if record['Age'] > 30]# 显示过滤后的数据
for record in filtered_data:print(record)
在这个示例中,我们使用pyexcel读取Excel文件中的数据,并通过列表推导式对数据进行筛选,仅保留年龄大于30的数据。这演示了pyexcel在数据操作和过滤方面的便捷性。
通过这些示例,读者将更加熟悉pyexcel库的基本用法和如何在实际项目中应用它进行简单而高效的Excel数据处理。
6. pandasgui - 数据探索的图形化利器
6.1 简介
pandasgui是一个基于pandas的图形用户界面库,旨在让用户通过可视化界面轻松地探索和分析pandas的DataFrame。它提供了交互式的数据探索工具,使得用户能够更直观地理解和分析数据。
6.2 常见应用场景
- 数据探索和可视化:
pandasgui为用户提供了一种无需编写代码的方式,通过可视化工具快速了解数据的结构和特征。 - 交互式数据分析: 用户可以通过界面上的交互式工具执行数据过滤、排序、统计等操作,实现即时的数据分析。
6.3 示例代码
from pandasgui import show
import pandas as pd# 创建一个简单的DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']}df = pd.DataFrame(data)# 使用pandasgui显示DataFrame
gui = show(df)
在这个示例代码中,我们首先创建了一个简单的DataFrame,然后使用pandasgui的show函数将DataFrame以图形界面的形式显示出来。这使得用户可以通过图形界面直观地查看和操作数据。
6.4 示例代码 - 数据过滤与统计
# 在图形界面中进行数据过滤
filtered_data = gui.filter('Age > 30')# 在图形界面中进行数据统计
summary_stats = gui.stats()
通过pandasgui的图形界面,用户可以使用类似SQL的语法进行数据过滤,也可以通过图形工具生成数据的统计汇总报告。这进一步展示了pandasgui在交互式数据分析方面的功能。
通过这些示例,读者将更全面地了解pandasgui库的使用方式以及如何通过图形界面进行数据探索和分析。
7. DataNitro - 将Excel变身为Python IDE
7.1 简介
DataNitro是一款将Excel变身为Python集成开发环境(IDE)的工具。它的独特之处在于允许在Excel中嵌入Python代码,从而实现更高级的数据处理和分析。这使得用户可以利用Excel的表格界面和Python的强大功能相结合,轻松执行复杂的数据分析任务。
7.2 常见应用场景
- 在Excel中嵌入Python代码:
DataNitro允许用户在Excel中直接编写和运行Python脚本,实现更灵活和高效的数据处理。 - 利用Python的强大功能扩展Excel: 用户可以通过嵌入Python代码,充分利用Python生态系统中丰富的库来处理和分析Excel中的数据。
7.3 示例代码
# 在Excel中使用Python代码
=PyRun("print('Hello DataNitro!')")
在这个示例代码中,通过在Excel中的一个单元格中嵌入PyRun函数,用户可以直接执行Python代码。这里的代码简单地打印一条消息,展示了在Excel中运行Python的基本用法。
7.4 示例代码 - 利用Python进行数据分析
# 在Excel中使用Python代码进行数据分析
=PyRun("""
import pandas as pd# 读取Excel数据
df = pd.read_excel('data.xlsx')# 执行数据分析
summary_stats = df.describe()# 将分析结果输出到Excel
summary_stats.to_excel('analysis_result.xlsx', index=False)
""")
在这个示例代码中,我们通过DataNitro嵌入Python代码,使用pandas库对Excel数据进行读取和基本的统计分析,并将分析结果输出到另一个Excel文件。这演示了DataNitro如何通过嵌入Python代码实现复杂的数据处理和分析。
通过这些示例,读者将更深入地了解DataNitro的使用方式以及如何将Excel与Python紧密结合,发挥两者的优势。
8. xlwings - 在Excel中集成Python代码
8.1 简介
xlwings是一个用于在Excel中集成Python代码的库,它提供了直接在Excel中运行Python脚本的功能。这使得用户可以充分利用Python的强大功能,并与Excel无缝集成,实现复杂的数据分析和处理。
8.2 常见应用场景
- 在Excel中运行Python脚本:
xlwings允许用户在Excel的单元格中直接编写和运行Python代码,实现即时的数据处理和分析。 - 实现复杂的数据分析和处理: 用户可以通过
xlwings结合Python库进行更复杂的数据操作,如数据清洗、统计分析等。
8.3 示例代码
# 在Excel中运行Python脚本
import xlwings as xw# 从Excel获取数据
data_range = xw.Range('Sheet1', 'A1').table
在这个示例代码中,我们使用xlwings库获取了Excel中名为’Sheet1’的工作表的数据,并将其存储在data_range变量中。这展示了通过xlwings在Excel中直接运行Python脚本的简单用法。
8.4 示例代码 - 利用Python进行高级数据分析
# 在Excel中运行Python脚本进行高级数据分析
import xlwings as xw
import pandas as pd# 从Excel获取数据
data_range = xw.Range('Sheet1', 'A1').table# 将数据转换为DataFrame
df = pd.DataFrame(data_range.value, columns=['Name', 'Age', 'City'])# 执行高级数据分析
result = df.groupby('City')['Age'].mean()# 将分析结果输出到Excel
xw.Range('Sheet2', 'A1').value = result.reset_index().values
在这个示例代码中,我们利用xlwings将Excel中的数据转换为pandas的DataFrame,并执行了一个简单的高级数据分析,计算了每个城市的平均年龄,并将结果输出到名为’Sheet2’的工作表。这演示了xlwings如何与pandas等库协同工作,实现更复杂的数据处理和分析。
通过这些示例,读者将更全面地了解xlwings库的使用方式以及如何通过在Excel中运行Python代码实现灵活的数据处理。
9. pandas-profiling - 自动生成数据分析报告
9.1 简介
pandas-profiling是一个基于pandas的库,用于生成数据分析报告。该报告包括数据概览、缺失值、相关性等信息,帮助用户更全面地了解数据集的整体情况。
9.2 常见应用场景
- 自动生成数据分析报告:
pandas-profiling通过简单的调用,可以生成包含各种数据统计和可视化信息的详细报告。 - 了解数据集的整体情况: 通过报告,用户可以迅速了解数据的基本特征、存在的问题以及潜在的数据质量问题。
9.3 示例代码
from pandas_profiling import ProfileReport# 创建数据分析报告
report = ProfileReport(df)# 将报告保存为HTML文件
report.to_file("data_analysis_report.html")
在这个示例代码中,我们使用pandas-profiling创建了一个数据分析报告。通过调用ProfileReport构造函数,它会自动分析输入的数据集(这里假设为DataFrame df),并生成一个包含详细分析结果的报告。最后,通过to_file方法将报告保存为HTML文件。
9.4 示例代码 - 通过报告进行数据可视化
# 使用pandas-profiling报告进行数据可视化
report.to_widgets()
除了保存为文件,pandas-profiling还支持通过to_widgets方法直接在Jupyter Notebook或JupyterLab中显示报告。这使得用户可以通过交互式方式查看数据分析的结果。
通过这些示例,读者将更深入地了解pandas-profiling库的使用方式以及如何通过自动生成的报告全面了解数据集的情况。
10. pandasql - 使用SQL语法进行数据查询
10.1 简介
pandasql是一个将SQL语法应用于pandas DataFrame的库,它允许用户使用类似SQL的查询语言进行数据查询和操作。这为熟悉SQL语法的用户提供了一种熟悉的数据分析方式。
10.2 常见应用场景
- 使用SQL语法进行数据查询:
pandasql允许用户通过熟悉的SQL语法进行数据过滤、排序和聚合。 - 借助熟悉的SQL语法进行数据分析: 对于习惯使用SQL语言的用户,
pandasql提供了一种无缝的数据分析体验。
10.3 示例代码
from pandasql import sqldf# 创建一个pandasql环境
pysql = sqldf(globals())# 使用SQL语法查询DataFrame
result = pysql("SELECT * FROM df WHERE Age > 30")
在这个示例代码中,我们首先通过sqldf函数创建了一个pandasql环境,然后使用SQL语法查询了DataFrame df中年龄大于30的数据。
10.4 示例代码 - 多表联合查询
# 多表联合查询
result = pysql("SELECT df1.Name, df1.Age, df2.City FROM df1 JOIN df2 ON df1.ID = df2.ID")
pandasql还支持多表联合查询,通过类似SQL的语法,用户可以方便地执行复杂的数据关联操作。上面的示例演示了如何在两个DataFrame df1和 df2之间进行基于ID的联合查询。
通过这些示例,读者将更了解pandasql库的使用方式以及如何通过SQL语法在pandas中进行灵活的数据查询和操作。
总结
通过本文的介绍,读者将对在Python中进行电子表格处理有了全面的认识。从基础的Excel文件读写到图形化数据探索,再到自动生成数据分析报告和使用SQL语法进行数据查询,这些工具和库为数据科学家和分析师提供了丰富而灵活的工具箱。在未来的数据探险中,这些工具将成为您的得力助手,助您更轻松地掌控和分析数据。
相关文章:

【Python百宝箱】Python数据探险:Excel与数据科学的完美结合
前言 在当今信息爆炸的时代,数据处理和分析已经成为各行各业不可或缺的一部分。在众多数据处理工具中,Python以其简洁而强大的语法成为数据科学家和分析师的首选之一。本文将深入探讨与电子表格处理相关的Python库,介绍它们的功能、应用场景…...

外贸分享|如何从外贸小白成长为大咖?这10件事值得你坚持做
外贸成功不是一朝一夕的事,而是需要有充分的准备和持续的努力。作为一位有着丰富经验的外贸人员,我总结了成功的秘诀,分享了一个优秀的外贸人应该做好的10项工作。 1 找不到客户怎么办? 有很多各种各样的原因值得思考:…...
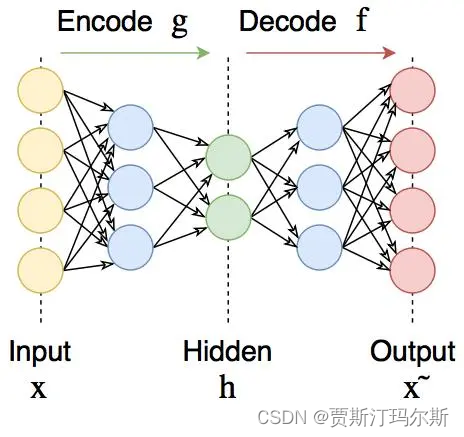
深度学习之六(自编码器--Autoencoder)
概念 自编码器(Autoencoder)是一种神经网络架构,用于无监督学习和数据的降维表示。它由两部分组成:编码器(Encoder)和解码器(Decoder)。 结构: 编码器(Encoder): 接收输入数据并将其压缩为潜在表示(latent representation),通常比输入数据的维度要低。编码器的…...
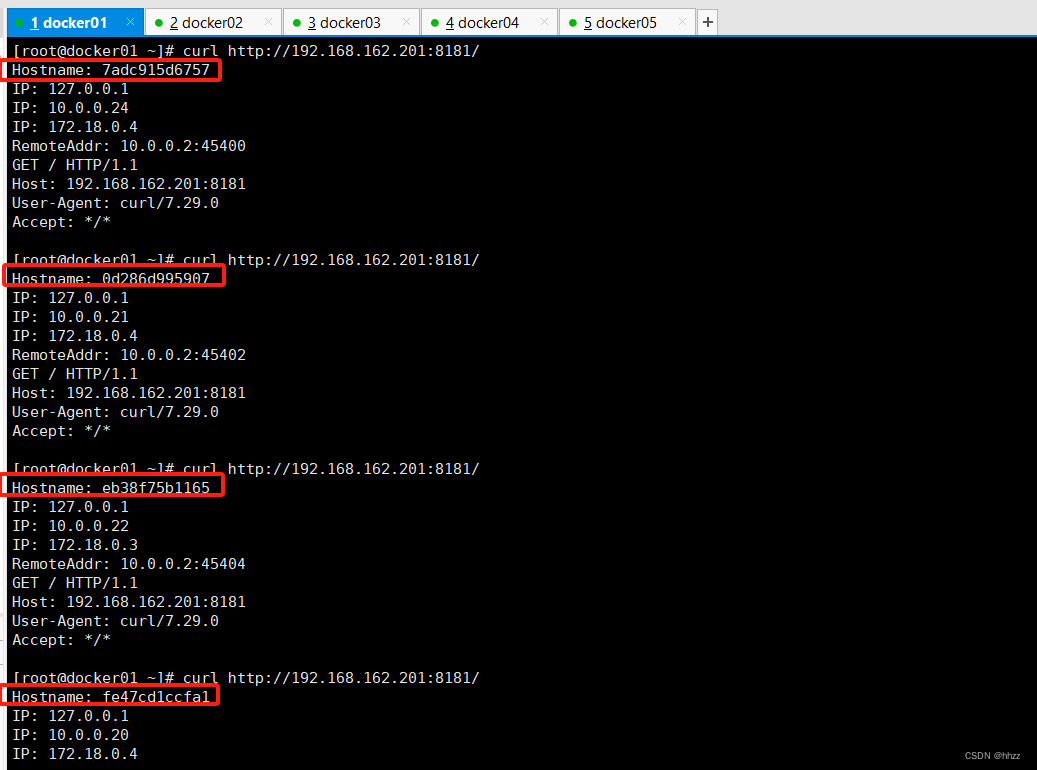
Docker Swarm总结+基础、集群搭建维护、安全以及集群容灾(1/3)
博主介绍:Java领域优质创作者,博客之星城市赛道TOP20、专注于前端流行技术框架、Java后端技术领域、项目实战运维以及GIS地理信息领域。 🍅文末获取源码下载地址🍅 👇🏻 精彩专栏推荐订阅👇🏻…...

Vim 一下日志文件,Java 进程没了?
一次端口告警,发现 java 进程被异常杀掉,而根因竟然是因为在问题机器上 vim 查看了 nginx 日志。下面我将从时间维度详细回顾这次排查,希望读者在遇到相似问题时有些许启发。 时间线 15:19 收到端口异常 odin 告警。 状态:P1故障 名称:应用端…...

C# Dictionary的使用
在 C# 中,Dictionary 是一种常用的数据结构,用于存储键值对。以下是一些常见的 Dictionary 操作: 创建和初始化一个 Dictionary 可以使用以下代码创建并初始化一个 Dictionary: Dictionary<string, int> dict new Dicti…...
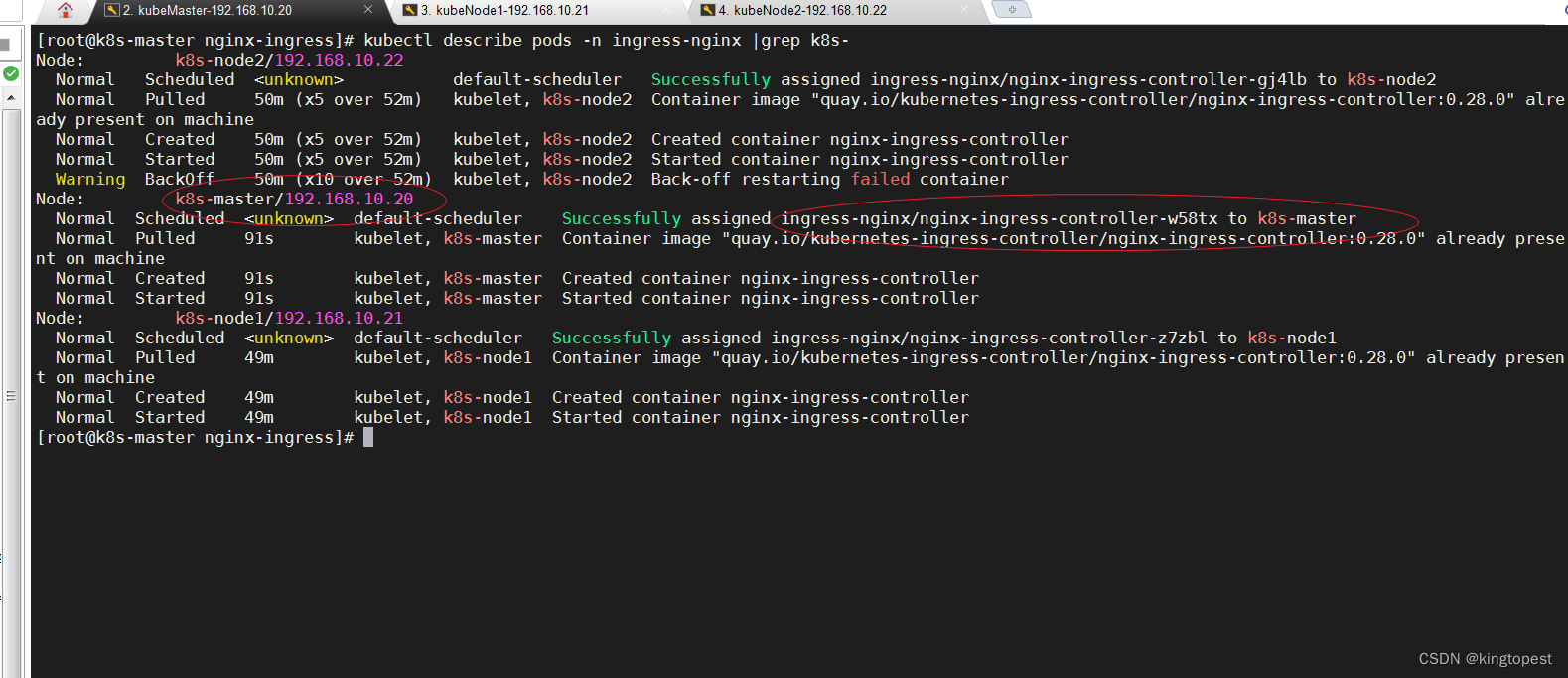
解决DaemonSet没法调度到master节点的问题
最近在kubernetes部署一个springcloud微服务项目,到了最后一步部署边缘路由:使用nginx-ingress和traefik都可以,必须使用DaemonSet部署,但是发现三个节点,却总共只有两个pod。 换句话说, DaemonSet没法调度…...
2023.11.20 关于 Spring MVC 详解
目录 MVC 工作流程 Spring MVC 掌握三个功能 创建 Spring MVC 项目 推荐安装插件 EditStarters 基础注解 RequestMapping 指定 GET 和 POST 方法类型 ResponseBody 获取参数 传递 单个 或 多个参数 参数重命名 RequestParam 接收 JSON 对象 RequestBody 获取 …...

救命~终于找到一款好看又舒适的家居服了
暖乎乎的软糯家居服 简直不要太好看太舒服了 双层舒棉绒舒适又暖和 防风收口设计,时尚与实用性兼具 经典版型不挑人穿 居家外出都可哦!!...

C#每天复习一个重要小知识day5:枚举与switch是天生一对
因为枚举一般用来表示条件和类型等等,所以它一般用条件分支来表现。所以枚举与switch是天生一对,因为很方便。(用if语句也可,但是没switch方便) 简单的举例: namespace 精细练习 {enum E_Player {Main,Ot…...
idea修改行号颜色
前言 i当idea用了深色主题后,发现行号根本看不清,或者很模糊 例如下面这样 修改行号颜色 在IntelliJ IDEA中,你可以根据自己的喜好和需求定制行号的颜色。下面是修改行号颜色的步骤: 打开 IntelliJ IDEA。 转到 “File”&…...
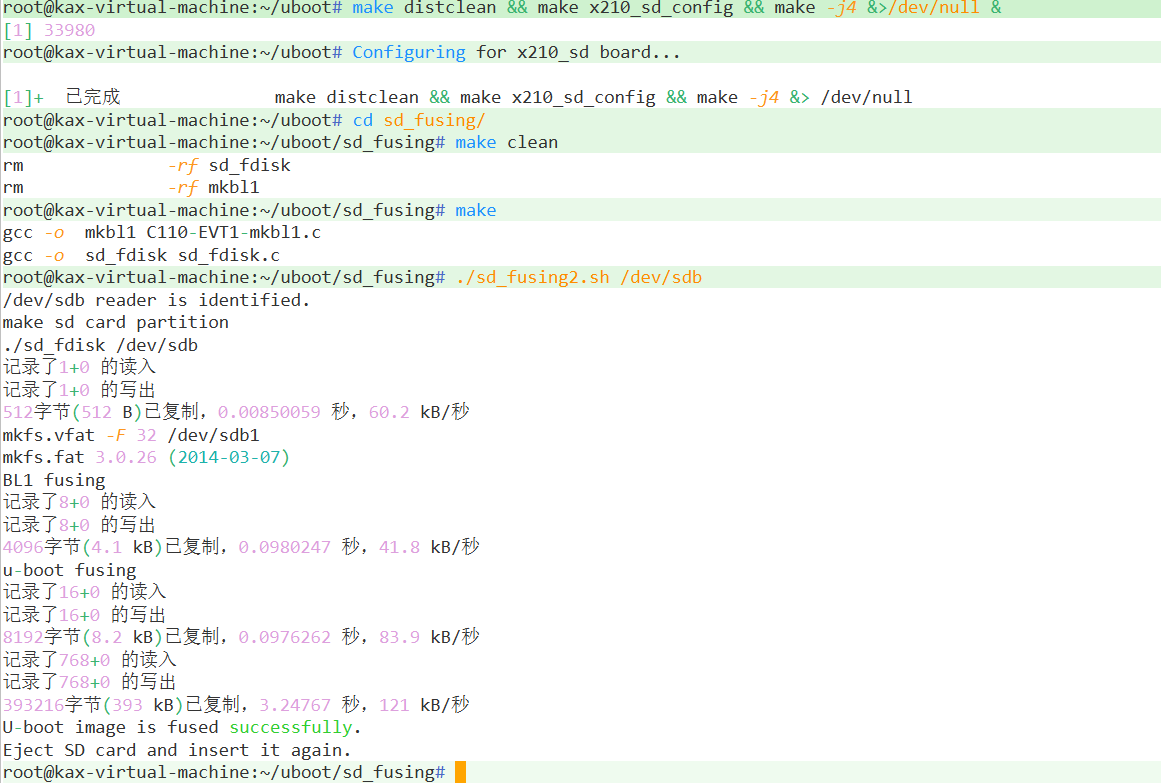
U-boot(四):start_armboot
本文主要探讨210的uboot启动的第二阶段,主要函数为start_armboot。 uboot 一阶段初始化SoC内部部件(看门狗、时钟等),初始化DDR,重定位 二阶段初始化其余硬件(iNand、网卡芯片)以及命令、环境变量等 启动打印硬件信息,进入bootdelay,读秒完后执行bootc…...

.Net面试题4
1.请解释一下泛型(Generics)在C#中的作用。 泛型是一种将数据类型参数化的机制,使得代码可以在编译时具有更强的类型安全性和灵活性。C#中的泛型可以用于类、接口、方法等的定义和实例化。泛型允许在编写代码时使用具有不同实参的类型&#x…...

python 列表插入数据的 四种方法 append insert extend 切片赋值
append insert 插入单个数据 append 加到末尾,insert 加到指定位置 extend、切片方式插入多个数据 extend 加到末尾,切片加到指定位置 my_list [1, 2, 3] my_list.append(4) print(my_list) # 输出: [1, 2, 3, 4]my_list [1, 2, 3] my_list.insert(…...

C++中std::string的=,+,+=使用过程中的问题
1. 调用构造函数时的运算符不支持int,char类型的操作数 string str1 a; //error 这是一个构造函数。C中string是一个类,内部封装了char *来管理这个字符串。 string的构造函数: string() // 创建一个空的字符串string(const char * s)…...
ruoyi-plus使用Statistic统计组件升级element-plus
原本使用的就是gitee上lionli的ruoyi-plus版本的代码。但是在使用过程中作首页数据看板时想使用elementui的Statistic统计组件。结果在浏览器控制台报错找不到组件el-statistic 于是查看elementui的历史版本,发现是在新版中才有这个组件,旧版本是没这个组…...
)
Python基础入门例程72-NP72 生成字典(字典)
最近的博文: Python基础入门例程71-NP71 喜欢的颜色(字典)-CSDN博客 Python基础入门例程70-NP70 首都(字典)-CSDN博客 Python基础入门例程69-NP69 姓名与学号(字典)-CSDN博客 目录 最近的博文: 描述...

flink的java.lang.IllegalStateException: Buffer pool is destroyed 异常
背景 最近flink的在线应用出现错误java.lang.IllegalStateException: Buffer pool is destroyed,本文记录下这个错误的原因 错误原因 详细的日志堆栈如下: Caused by: java.lang.IllegalStateException: Buffer pool is destroyed. at org.apache.flink.runtime…...

物联网AI MicroPython学习之语法 实时时钟RTC
学物联网,来万物简单IoT物联网!! RTC 介绍 模块功能: 实时时钟RTC驱动模块 接口说明 RTC - 构建RTC对象 函数原型:RTC()参数说明: 无 返回值: 构建的RTC对象。 datetime - RTC时钟操作 函数原型&a…...
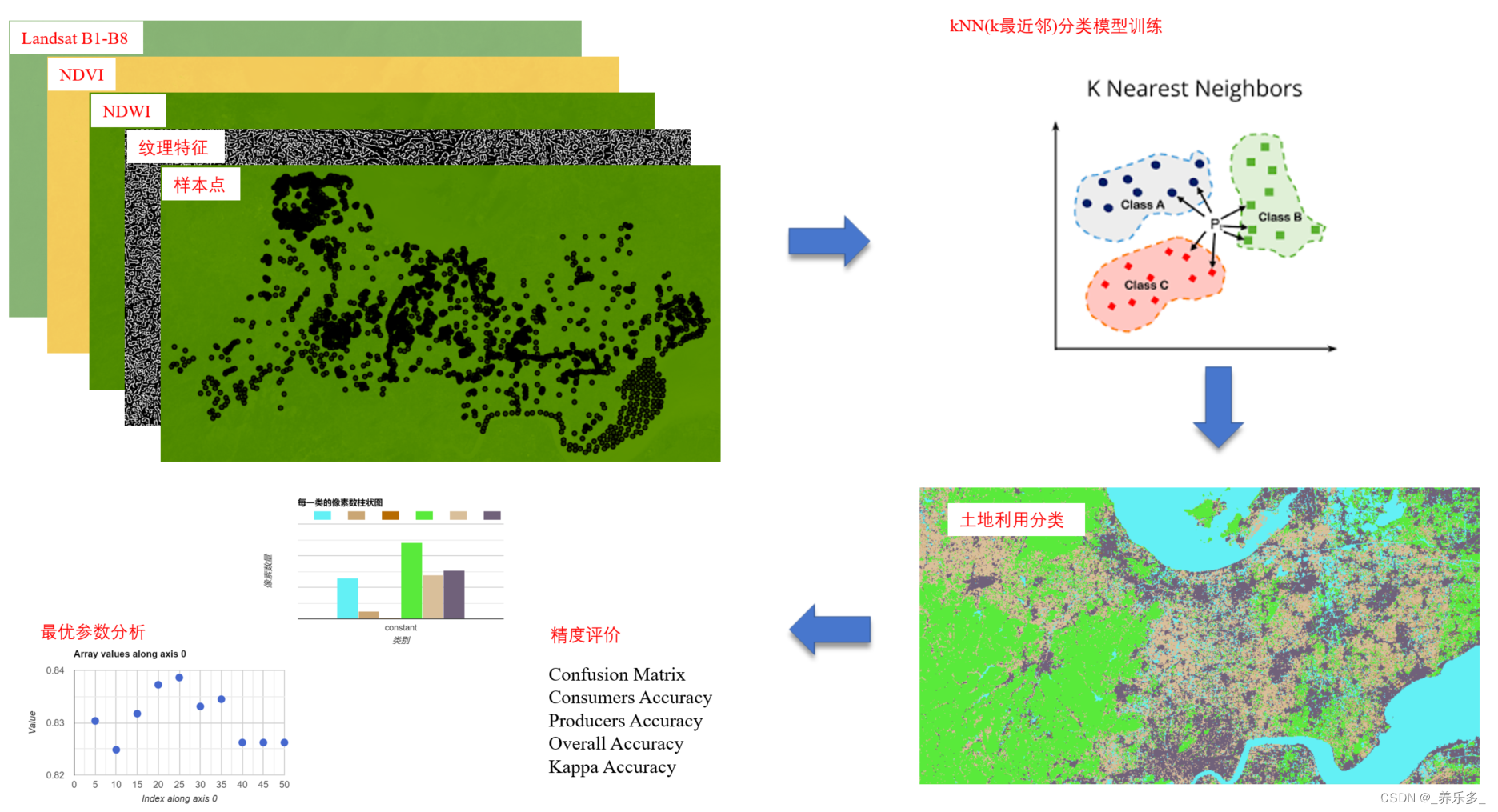
GEE:kNN(k-最近邻)分类教程(样本制作、特征添加、训练、精度、最优参数、统计面积)
作者:CSDN @ _养乐多_ 本文将介绍在Google Earth Engine (GEE)平台上进行kNN(k-最近邻)分类的方法和代码,其中包括制作样本点教程(本地、在线和本地在线混合制作样本点,合并样本点等),加入特征变量(各种指数、纹理特征、时间序列特征、物候特征等),运行kNN(k-最近…...

你的竞争对手已经用 AI 实现规模化复制,你还在靠个人能力撑着? 2026企业数字化转型避坑指南
站在2026年这个节点回望,AI早已跨越了“技术尝鲜”的门槛。 现在的商业竞争,本质上是“硅基劳动力”规模与密度的竞争。 当你的竞争对手通过构建智能体(Agent)矩阵,实现24小时不间断的业务流转、秒级的市场响应和极低的…...

【万字文档+PPT+源码】基于Java的平价汽车租赁系统-计算机专业项目设计分享
【万字文档PPT源码】基于Java的平价汽车租赁系统-计算机专业项目设计分享 【万字文档PPT源码】基于Java的平价汽车租赁系统-可用于计算机毕设-课程设计-练手学习【万字文档PPT源码】基于Java的平价汽车租赁系统-计算机专业项目设计分享 摘 要 众所周知,平价平价汽车…...

大数据开发中常见的排序算法
大数据处理中,排序算法需兼顾效率与可扩展性。 主流方案包括: 1)Timsort作为混合排序算法,适应Spark等分布式场景; 2)外部排序通过分片归并解决内存限制; 3)基数排序适合固定长度数据; 4)BitonicSort专为并…...
)
别再手动登录了!用VBS脚本自动打开Chrome并填写表单(附完整代码)
解放双手:用VBS脚本实现Chrome自动化表单填写全攻略 每次打开浏览器、输入网址、填写账号密码、点击登录...这些重复性操作是否让你感到厌倦?对于测试工程师、运维人员或经常需要处理批量表单的行政人员来说,这类机械操作不仅耗时耗力&#x…...

D3KeyHelper:暗黑破坏神3自动化战斗宏工具完全指南
D3KeyHelper:暗黑破坏神3自动化战斗宏工具完全指南 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款基于AutoHotkey开发…...
)
C# Winform项目实战:给你的桌面应用加个‘点赞’悬浮按钮(MaterialFloatingActionButton全解析)
C# Winform项目实战:打造智能悬浮按钮的完整交互方案 在桌面应用开发中,那些看似微小的交互细节往往决定了用户体验的成败。想象一下,当用户完成一项重要操作后,一个精致的悬浮按钮轻轻弹出,邀请他们为内容点赞——这种…...

哔咔漫画下载器终极指南:打造个人离线漫画图书馆的简单方法
哔咔漫画下载器终极指南:打造个人离线漫画图书馆的简单方法 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.co…...
)
别再手动调间距了!用Matlab的tiledlayout函数搞定论文级多图排版(附代码)
告别繁琐排版:用Matlab tiledlayout打造学术级多图布局 还在为论文中的多图排版焦头烂额?每次调整subplot位置都要耗费半小时?Matlab R2019b引入的tiledlayout功能彻底改变了这一局面。这个被严重低估的工具,能让你的科研图表排版…...

从Qt 5.7到C++17:一文搞懂qAsConst的来龙去脉与实战应用
从Qt 5.7到C17:深入解析qAsConst的设计哲学与工程实践 在Qt框架的演进历程中,qAsConst函数的引入标志着Qt与C标准的一次重要融合。这个看似简单的工具函数背后,蕴含着Qt容器设计哲学与C现代语法特性的精妙平衡。本文将带您穿越技术迷雾&#…...
)
STM32CubeMX配置LwIP内存参数,实测TCP速度提升5倍(附JPerf测速教程)
STM32CubeMX调优LwIP内存配置:实测TCP吞吐量提升500%的工程实践 当我们在STM32平台上开发网络应用时,LwIP协议栈的性能往往成为瓶颈。许多工程师发现,即使硬件支持百兆以太网,实际TCP传输速度却只能达到1-2Mbps。这背后隐藏着怎样…...