sql语句的优化
sql优化
优化数据访问
- 查询性能低下最基本的原因是访问的数据太多,大部分性能低下的查询都可以通过减少访问的数据量来优化
- 所以关于低效的查询,需要确认是否检索了大量不需要的数据,以及mysql服务器层是否在分析大量不需要的数据
- 因为有些查询会请求超过实际需要的数据,然后这些多余数据又会被程序丢弃,这会带来额外的负担,并增加网络开销,最简单的解决办法就是加上limit
- 还有就是select * 返回全部列,会让优化器无法完成覆盖索引等优化,还会带来额外的I/O、内存和CPU消耗
- 再比如,如果重复查询相同的数据,最好能将这个数据缓存起来
衡量查询开销的三个指标:
- 响应时间,又分为服务时间和排队时间
- 扫描的行数
- 返回的行数
- 理想情况下,扫描的行数和返回的行数应该是相等的,但是实际上往往是不同的
- 如果发现查询需要扫描大量的行,却只返回少量的数据,
- 可以使用索引覆盖,把所有需要用到的列放在索引中
- 或者重写sql,让sql语句更加合理
一个复杂查询和多个简单查询:
-
在其他条件都相同的时候,尽可能少的查询当然更好,
-
但是将一个复杂的sql,分解为多个简单的sql能够将压力分散到一个时间段内,降低对服务器的影响
-
对于关联查询,也可以对每一个表进行一次单表查询,然后将结果在程序中关联,这种操作的好处有:
-
分解查询后,执行单个查询可以减少锁的竞争
-
而且很方便缓存单表的数据,如果这个表很少改变,基于这个表的查询就可以重复利用缓存结果,提高缓存的效率 ,
-
另外在应用层做关联,一条数据只需要查询一次,而在数据库查询,可能需要重复的访问一部分数据,查询本身的效率可能会有所提升
-
优化排序:
- 排序是成本很高的操作,从性能角度考虑,应该尽可能避免排序
- mysql排序有两种:一种是排序操作,一种是按索引顺序扫描
-
索引排序:
-
索引排序同样要满足最左前缀,而且只有当索引的列顺序和order by 字句的顺序完全一样,并且列的排序方向都一样时,才能使用索引来排序
-
而且如果查询关联了多张表,只有order by 字句引用的字段全部为第一张表时,才能使用索引做排序
-
扫描索引是很高效的,但是如果索引不能覆盖查询所需要的列,就需要回表去查询对应的列,这基本上就是随机i/o,这种比顺序全表扫描还慢
-
-
排序操作
- 当不能使用索引生成排序结果的时候,就需要自己进行排序,mysql将这个过程统一称为文件排序
- 如果数据量小于 “排序缓冲区” 就会在内存中进行快速排序,
- 如果数据量大内存不够就会先将数据分块,对每个独立的块使用快速排序,然后将每个块的排序结果放在磁盘上,接着将排序好的块进行合并,最后返回排序结果。
- mysql的排序算法有两种:
- 两次传输排序:
- 先只读取需要排序的字段,对其进行排序,然后根据排序结果,在读取所需要的行数据
- 这样需要进行两次数据传输,而且第二次会产生大量的随机i/o,传输成本很高,但是这样在排序的时候,可以让排序缓冲区尽可能容纳更多的行数进行排序
- 单词传输排序:
- 读取查询需要的所有列,再进行排序,最后直接返回排序结果
- 这个算法只需要一次顺序i/o,避免了随机i/o的产生
- 但是,如果返回的列非常多,非常大,会有很多列对于排序来说没有任何作用,而且还会额外占用大量的空间,就可能会有更多的排序块需要合并
- 两次传输排序:
- mysql在进行文件排序的时候,需要使用的临时存储空间可能会非常大,因为每一个排序记录,都会分配一个足够长的定长空间来存放
-
union(合并)
- 如果希望union的各个字句,先排好序再合并结果集的话,就需要再各个子句中分别使用这些字句,分页也是同里
- 除非一定要消除重复的行,否则一定要使用 union all ,如果没有all关键字,mysql会给临时表加上distinct选项,这回导致对整个临时表数据做唯一性检查,代价很高
count():
-
可以用于count(*)统计某个列值的数量,也可以count(列名)统计行数,统计列值时,要求列值是非空的
-
如果想要统计的是结果集的行数,count(*)会忽略所有的列,直接统计行数,语义清晰,性能也会很好,MyISAM保存了表的行数,直接使用 count( *)会很快,但是前提是没有where条件
-
如果统计列值时,mysql知道某列不可能为空,mysql会将count(某列)转换为count(*)
-
count(*) 、count(1)
- 有主键或联合主键的情况下,count(*)略比count(1)快一些。
- 没有主键的情况下count(1)比count(*)快一些。
优化关联查询:
- 确保ON或者USING的列上有索引,一般来说只需要再关联顺序的第二张表的对应字段上创建索引
- 确保order by 和 group by 字句中只涉及一个表中的列
对于子查询,最好使用关联查询替代
group by和distinct:
- 两种操作都可以使用索引来优化,这也是最有效的优化方式
相关文章:

sql语句的优化
sql优化 优化数据访问 查询性能低下最基本的原因是访问的数据太多,大部分性能低下的查询都可以通过减少访问的数据量来优化所以关于低效的查询,需要确认是否检索了大量不需要的数据,以及mysql服务器层是否在分析大量不需要的数据 因为有些查…...

Shell脚本之——自动安装JDK
目录 1.修改主机名 2.创建文件,单独存放Shell脚本 3.编写Shell脚本 4.Shell脚本命令简介 (1)文件头 (2)打印命令 (3)设置全局变量 (4)条件判断 (5)解压 (6)文件重命名 (7)在/etc/profile指定行插入 5.完整脚本内容 6.重启环境变量 7.判断java是否配置…...
大数据---Hadoop安装Hadoop简易版
编写自动安装Hadoop的shell脚本 完整流程: 大数据—Hadoop安装教程(二) 文章目录编写自动安装Hadoop的shell脚本上传压缩包编写shell脚本vim hadoopautoinstall.sh运行上传压缩包 在opt目录下创建连个目录install和soft 将压缩包上传到install目录下 …...
)
Spring框架中使用到的设计模式以及对应的类(方法)
模板方法--->postProcessBeanFactory,onFresh、initPropertySource装饰器模式--->BeanWrapper委托者模式--->BeanDefinitionParseDelegate策略模式--->ClassPathXmlApplicationContext、FileSystemApplicationContext、XMLBeanDefinitionReader、Proper…...

类和类的定义
6.2 类和类的定义 面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如学生类,而实例是根据类创建出来的一个个具体的对象,每个对象都拥有相同的方法&…...

丝绸之路——NFT 系列来袭!
丝绸之路的经历讲述了汉朝时代的一个重要历史事件。该系列中的 NFT 带有中国这段黄金时代令人愉悦的视觉元素,使其成为值得收藏的物品。 NFT 系列介绍 敦煌女神像01(左);汉代士兵(中);敦煌女神像…...

配置CMAKE编译环境:VSCODE + MinGW
一. MinGW安装 MinGW(Minimalist GNU For Windows)是个精简的Windows平台C/C、ADA及Fortran编译器,相比Cygwin而言,体积要小很多,使用较为方便。 MinGW最大的特点就是编译出来的可执行文件能够独立在Windows上运行。 MinGW的组成ÿ…...
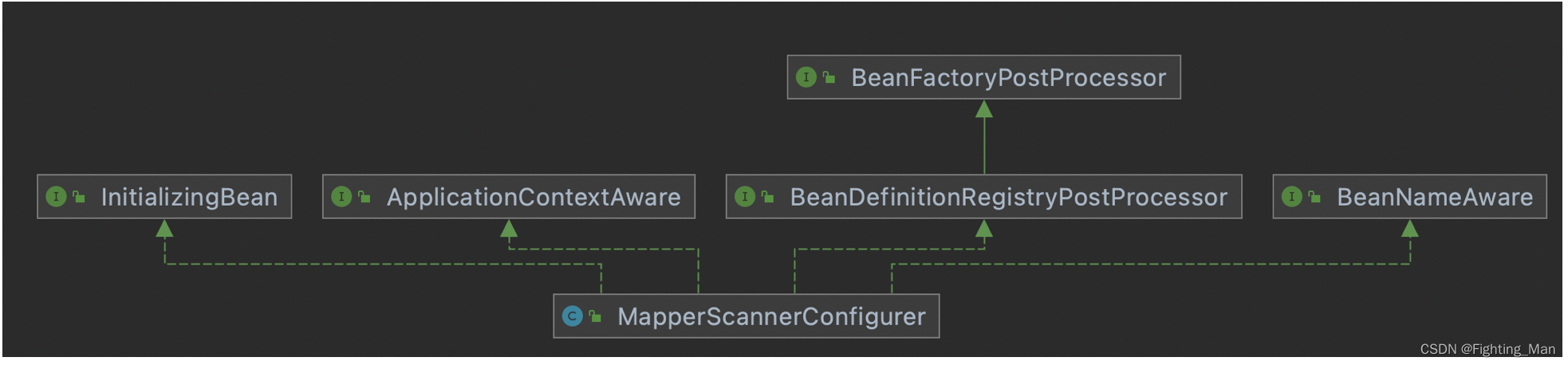
六、mybatis与spring的整合
Spring整合Mybaits的步骤 引入依赖 在Spring整合Mybaits的时候需要引入一个中间依赖包mybatis-spring <dependency><groupId>org.mybatis</groupId><artifactId>mybatis</artifactId><version>3.5.5</version> </dependency&g…...
JavaWeb--JDBC
JDBC1 JDBC概述1.1 JDBC概念1.2 JDBC本质1.3 JDBC好处2 JDBC快速入门2.1 编写代码步骤2.2 具体操作3 JDBC API详解3.1 DriverManager3.2 Connection3.2.1 获取执行对象3.2.2 事务管理3.3 Statement3.3.1 概述3.3.2 代码实现3.4 ResultSet3.4.1 概述3.4.2 代码实现3.5 案例3.6 P…...

大数据框架之Hadoop:入门(四)Hadoop运行模式
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。 Hadoop官方网站:http://hadoop.apache.org/ 4.1本地运行模式 4.1.1官方Grep案例 1.创建在hadoop文件夹下面创建一个input文件夹 [roothdp101 hadoop]# mkdir input2.将Hadoop的xml配…...

《爆肝整理》保姆级系列教程python接口自动化(十一)--发送post【data】(详解
简介 前面登录的是传 json 参数,由于其登录机制的改变没办法演示,然而在工作中有些登录不是传 json 的,如 jenkins 的登录,这里小编就以jenkins 登录为案例,传 data 参数,给各位童鞋详细演练一下。 一、…...

【微服务】Nacos注册中心
🚩本文已收录至专栏:微服务探索之旅 👍希望您能有所收获 👍Nacos和Eureka一样也可以充当服务的注册中心,让我们一起看看有何区别? 点击跳转👉【微服务】Eureka注册中心 👍Nacos除了可…...

跟开发打了半个月后,我终于get报bug的正确姿势了
在测试人员提需求的时候,大家经常会看到,测试员和开发一言不合就上BUG。然后开发一下就炸了,屡试不爽,招招致命。 曾经看到有个段子这么写道: 不要对程序员说,你的代码有BUG。他的第一反应是:…...

js万能类型检测Object.prototype.toString.call——定制Object.prototype.toString.call的检测结果
javascript的类型检测 1、typeof typeof操作符可以检测js的基础数据类型,包括number、string、boolean、undefined。因为null在二进制存储的值与object相同,所以typeof检测null会返回object。此为特例 2、instanceof instanceof操作符可以检测某个对…...
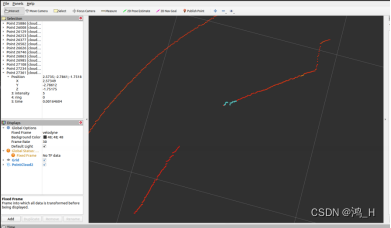
激光slam学习笔记2--激光点云数据结构特点可视化查看
背景:不同厂商的激光点云结果存在一定差异,比如有些只有xyz,有些包含其他,如反光率、时间戳、ring等。如何快速判断是个值得学习的点 概要:对于rosbag类型的激光点云,介绍使用rviz快速查看点云结构特点 如…...
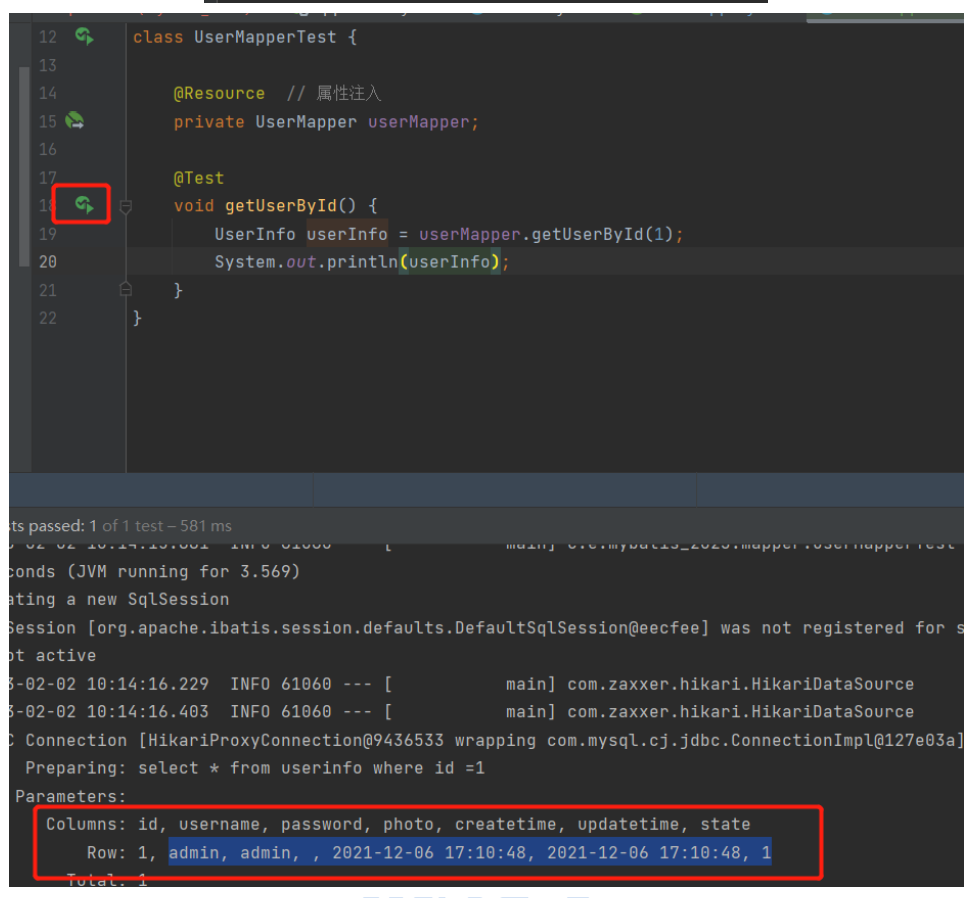
SpringBoot笔记【JavaEE】
SpringBoot概念、创建和运行 1.什么是SpringBoot?为什么学习SpringBoot? Spring Boot 就是 Spring 框架的脚⼿架,它就是为了快速开发 Spring 框架⽽诞⽣的。 2.Spring Boot优点 快速集成框架【提供启动添加依赖的功能】内容运行容器【无需…...

目标检测算法之voxelNet与pointpillars对比
算法对比 3D目标检测发展简史 点云目标检测目前发展历经VoxelNet、SECOND、PointPillars、PV-RCNN。 2017年苹果提出voxelnet,是最早的一篇将点云转成voxel体素进行3D目标检测的论文。 然后2018年重庆大学的一个研究生Yan Yan在自动驾驶公司主线科技实习的时候将vo…...
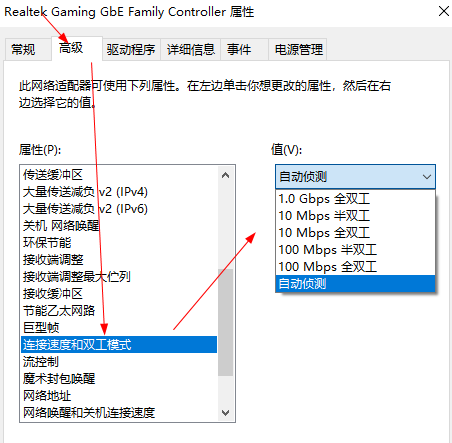
电脑里的连接速度双工模式是什么?怎么设置
双工模式包括全双工、半双工模式。1.半双工1、半双工数据传输允许数据在两个方向上传输,但是,在某一时刻,只允许数据在一个方向上传输,它实际上是一种切换方向的单工通信。所谓半双工就是指一个时间段内只有一个动作发生。早期的对…...
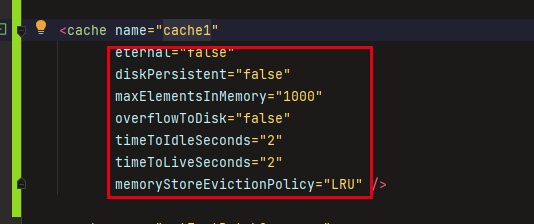
springboot整合单机缓存ehcache
区别于redis的分布式缓存,ehcache是纯java进程内的单机缓存,根据不同的场景可选择使用,以下内容主要为springboot整合ehcache以及注意事项添加pom引用<dependency><groupId>net.sf.ehcache</groupId><artifactId>ehc…...

在阿里干了2年的测试,总结出来的划水经验
测试新人 我的职业生涯开始和大多数测试人一样,开始接触都是纯功能界面测试。那时候在一家电商公司做测试,做了一段时间,熟悉产品的业务流程以及熟练测试工作流程规范之后,效率提高了,工作比较轻松,这样我…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...