竞赛选题 题目:基于卷积神经网络的手写字符识别 - 深度学习
文章目录
- 0 前言
- 1 简介
- 2 LeNet-5 模型的介绍
- 2.1 结构解析
- 2.2 C1层
- 2.3 S2层
- S2层和C3层连接
- 2.4 F6与C5层
- 3 写数字识别算法模型的构建
- 3.1 输入层设计
- 3.2 激活函数的选取
- 3.3 卷积层设计
- 3.4 降采样层
- 3.5 输出层设计
- 4 网络模型的总体结构
- 5 部分实现代码
- 6 在线手写识别
- 7 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
基于卷积神经网络的手写字符识别
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate

1 简介
该设计学长使用python基于TensorFlow设计手写数字识别算法,并编程实现GUI界面,构建手写数字识别系统。
这是学长做的深度学习demo,大家可以用于竞赛课题。
这里学长不会以论文的形式展现,而是以编程实战完成深度学习项目的角度去描述。
项目要求:主要解决的问题是手写数字识别,最终要完成一个识别系统。
设计识别率高的算法,实现快速识别的系统。
2 LeNet-5 模型的介绍
学长实现手写数字识别,使用的是卷积神经网络,建模思想来自LeNet-5,如下图所示:

2.1 结构解析
这是原始的应用于手写数字识别的网络,我认为这也是最简单的深度网络。
LeNet-5不包括输入,一共7层,较低层由卷积层和最大池化层交替构成,更高层则是全连接和高斯连接。
LeNet-5的输入与BP神经网路的不一样。这里假设图像是黑白的,那么LeNet-5的输入是一个32*32的二维矩阵。同
时,输入与下一层并不是全连接的,而是进行稀疏连接。本层每个神经元的输入来自于前一层神经元的局部区域(5×5),卷积核对原始图像卷积的结果加上相应的阈值,得出的结果再经过激活函数处理,输出即形成卷积层(C层)。卷积层中的每个特征映射都各自共享权重和阈值,这样能大大减少训练开销。降采样层(S层)为减少数据量同时保存有用信息,进行亚抽样。
2.2 C1层
第一个卷积层(C1层)由6个特征映射构成,每个特征映射是一个28×28的神经元阵列,其中每个神经元负责从5×5的区域通过卷积滤波器提取局部特征。一般情况下,滤波器数量越多,就会得出越多的特征映射,反映越多的原始图像的特征。本层训练参数共6×(5×5+1)=156个,每个像素点都是由上层5×5=25个像素点和1个阈值连接计算所得,共28×28×156=122304个连接。
2.3 S2层
S2层是对应上述6个特征映射的降采样层(pooling层)。pooling层的实现方法有两种,分别是max-pooling和mean-
pooling,LeNet-5采用的是mean-
pooling,即取n×n区域内像素的均值。C1通过2×2的窗口区域像素求均值再加上本层的阈值,然后经过激活函数的处理,得到S2层。pooling的实现,在保存图片信息的基础上,减少了权重参数,降低了计算成本,还能控制过拟合。本层学习参数共有1*6+6=12个,S2中的每个像素都与C1层中的2×2个像素和1个阈值相连,共6×(2×2+1)×14×14=5880个连接。
S2层和C3层连接
S2层和C3层的连接比较复杂。C3卷积层是由16个大小为10×10的特征映射组成的,当中的每个特征映射与S2层的若干个特征映射的局部感受野(大小为5×5)相连。其中,前6个特征映射与S2层连续3个特征映射相连,后面接着的6个映射与S2层的连续的4个特征映射相连,然后的3个特征映射与S2层不连续的4个特征映射相连,最后一个映射与S2层的所有特征映射相连。
此处卷积核大小为5×5,所以学习参数共有6×(3×5×5+1)+9×(4×5×5+1)+1×(6×5×5+1)=1516个参数。而图像大小为28×28,因此共有151600个连接。
S4层是对C3层进行的降采样,与S2同理,学习参数有16×1+16=32个,同时共有16×(2×2+1)×5×5=2000个连接。
C5层是由120个大小为1×1的特征映射组成的卷积层,而且S4层与C5层是全连接的,因此学习参数总个数为120×(16×25+1)=48120个。
2.4 F6与C5层
F6是与C5全连接的84个神经元,所以共有84×(120+1)=10164个学习参数。
卷积神经网络通过通过稀疏连接和共享权重和阈值,大大减少了计算的开销,同时,pooling的实现,一定程度上减少了过拟合问题的出现,非常适合用于图像的处理和识别。
3 写数字识别算法模型的构建
3.1 输入层设计
输入为28×28的矩阵,而不是向量。

3.2 激活函数的选取
Sigmoid函数具有光滑性、鲁棒性和其导数可用自身表示的优点,但其运算涉及指数运算,反向传播求误差梯度时,求导又涉及乘除运算,计算量相对较大。同时,针对本文构建的含有两层卷积层和降采样层,由于sgmoid函数自身的特性,在反向传播时,很容易出现梯度消失的情况,从而难以完成网络的训练。因此,本文设计的网络使用ReLU函数作为激活函数。
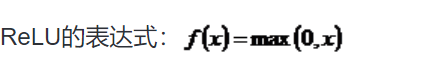
3.3 卷积层设计
学长设计卷积神经网络采取的是离散卷积,卷积步长为1,即水平和垂直方向每次运算完,移动一个像素。卷积核大小为5×5。
3.4 降采样层
学长设计的降采样层的pooling方式是max-pooling,大小为2×2。
3.5 输出层设计
输出层设置为10个神经网络节点。数字0~9的目标向量如下表所示:

4 网络模型的总体结构

5 部分实现代码
使用Python,调用TensorFlow的api完成手写数字识别的算法。
注:我的程序运行环境是:Win10,python3.。
当然,也可以在Linux下运行,由于TensorFlow对py2和py3兼容得比较好,在Linux下可以在python2.7中运行。
#!/usr/bin/env python2# -*- coding: utf-8 -*-#import modulesimport numpy as npimport matplotlib.pyplot as plt#from sklearn.metrics import confusion_matriximport tensorflow as tfimport timefrom datetime import timedeltaimport mathfrom tensorflow.examples.tutorials.mnist import input_datadef new_weights(shape):return tf.Variable(tf.truncated_normal(shape,stddev=0.05))def new_biases(length):return tf.Variable(tf.constant(0.1,shape=length))def conv2d(x,W):return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')def max_pool_2x2(inputx):return tf.nn.max_pool(inputx,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')#import datadata = input_data.read_data_sets("./data", one_hot=True) # one_hot means [0 0 1 0 0 0 0 0 0 0] stands for 2print("Size of:")print("--Training-set:\t\t{}".format(len(data.train.labels)))print("--Testing-set:\t\t{}".format(len(data.test.labels)))print("--Validation-set:\t\t{}".format(len(data.validation.labels)))data.test.cls = np.argmax(data.test.labels,axis=1) # show the real test labels: [7 2 1 ..., 4 5 6], 10000valuesx = tf.placeholder("float",shape=[None,784],name='x')x_image = tf.reshape(x,[-1,28,28,1])y_true = tf.placeholder("float",shape=[None,10],name='y_true')y_true_cls = tf.argmax(y_true,dimension=1)# Conv 1layer_conv1 = {"weights":new_weights([5,5,1,32]),"biases":new_biases([32])}h_conv1 = tf.nn.relu(conv2d(x_image,layer_conv1["weights"])+layer_conv1["biases"])h_pool1 = max_pool_2x2(h_conv1)# Conv 2layer_conv2 = {"weights":new_weights([5,5,32,64]),"biases":new_biases([64])}h_conv2 = tf.nn.relu(conv2d(h_pool1,layer_conv2["weights"])+layer_conv2["biases"])h_pool2 = max_pool_2x2(h_conv2)# Full-connected layer 1fc1_layer = {"weights":new_weights([7*7*64,1024]),"biases":new_biases([1024])}h_pool2_flat = tf.reshape(h_pool2,[-1,7*7*64])h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat,fc1_layer["weights"])+fc1_layer["biases"])# Droupout Layerkeep_prob = tf.placeholder("float")h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob)# Full-connected layer 2fc2_layer = {"weights":new_weights([1024,10]),"biases":new_weights([10])}# Predicted classy_pred = tf.nn.softmax(tf.matmul(h_fc1_drop,fc2_layer["weights"])+fc2_layer["biases"]) # The output is like [0 0 1 0 0 0 0 0 0 0]y_pred_cls = tf.argmax(y_pred,dimension=1) # Show the real predict number like '2'# cost function to be optimizedcross_entropy = -tf.reduce_mean(y_true*tf.log(y_pred))optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(cross_entropy)# Performance Measurescorrect_prediction = tf.equal(y_pred_cls,y_true_cls)accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))with tf.Session() as sess:init = tf.global_variables_initializer()sess.run(init)train_batch_size = 50def optimize(num_iterations):total_iterations=0start_time = time.time()for i in range(total_iterations,total_iterations+num_iterations):x_batch,y_true_batch = data.train.next_batch(train_batch_size)feed_dict_train_op = {x:x_batch,y_true:y_true_batch,keep_prob:0.5}feed_dict_train = {x:x_batch,y_true:y_true_batch,keep_prob:1.0}sess.run(optimizer,feed_dict=feed_dict_train_op)# Print status every 100 iterations.if i%100==0:# Calculate the accuracy on the training-set.acc = sess.run(accuracy,feed_dict=feed_dict_train)# Message for printing.msg = "Optimization Iteration:{0:>6}, Training Accuracy: {1:>6.1%}"# Print it.print(msg.format(i+1,acc))# Update the total number of iterations performedtotal_iterations += num_iterations# Ending timeend_time = time.time()# Difference between start and end_times.time_dif = end_time-start_time# Print the time-usageprint("Time usage:"+str(timedelta(seconds=int(round(time_dif)))))test_batch_size = 256def print_test_accuracy():# Number of images in the test-set.num_test = len(data.test.images)cls_pred = np.zeros(shape=num_test,dtype=np.int)i = 0while i < num_test:# The ending index for the next batch is denoted j.j = min(i+test_batch_size,num_test)# Get the images from the test-set between index i and jimages = data.test.images[i:j, :]# Get the associated labelslabels = data.test.labels[i:j, :]# Create a feed-dict with these images and labels.feed_dict={x:images,y_true:labels,keep_prob:1.0}# Calculate the predicted class using Tensorflow.cls_pred[i:j] = sess.run(y_pred_cls,feed_dict=feed_dict)# Set the start-index for the next batch to the# end-index of the current batchi = jcls_true = data.test.clscorrect = (cls_true==cls_pred)correct_sum = correct.sum()acc = float(correct_sum) / num_test# Print the accuracymsg = "Accuracy on Test-Set: {0:.1%} ({1}/{2})"print(msg.format(acc,correct_sum,num_test))# Performance after 10000 optimization iterationsoptimize(num_iterations=10000)print_test_accuracy()savew_hl1 = layer_conv1["weights"].eval()saveb_hl1 = layer_conv1["biases"].eval()savew_hl2 = layer_conv2["weights"].eval()saveb_hl2 = layer_conv2["biases"].eval()savew_fc1 = fc1_layer["weights"].eval()saveb_fc1 = fc1_layer["biases"].eval()savew_op = fc2_layer["weights"].eval()saveb_op = fc2_layer["biases"].eval()np.save("savew_hl1.npy", savew_hl1)np.save("saveb_hl1.npy", saveb_hl1)np.save("savew_hl2.npy", savew_hl2)np.save("saveb_hl2.npy", saveb_hl2)np.save("savew_hl3.npy", savew_fc1)np.save("saveb_hl3.npy", saveb_fc1)np.save("savew_op.npy", savew_op)np.save("saveb_op.npy", saveb_op)运行结果显示:测试集中准确率大概为99.2%。

查看混淆矩阵

6 在线手写识别
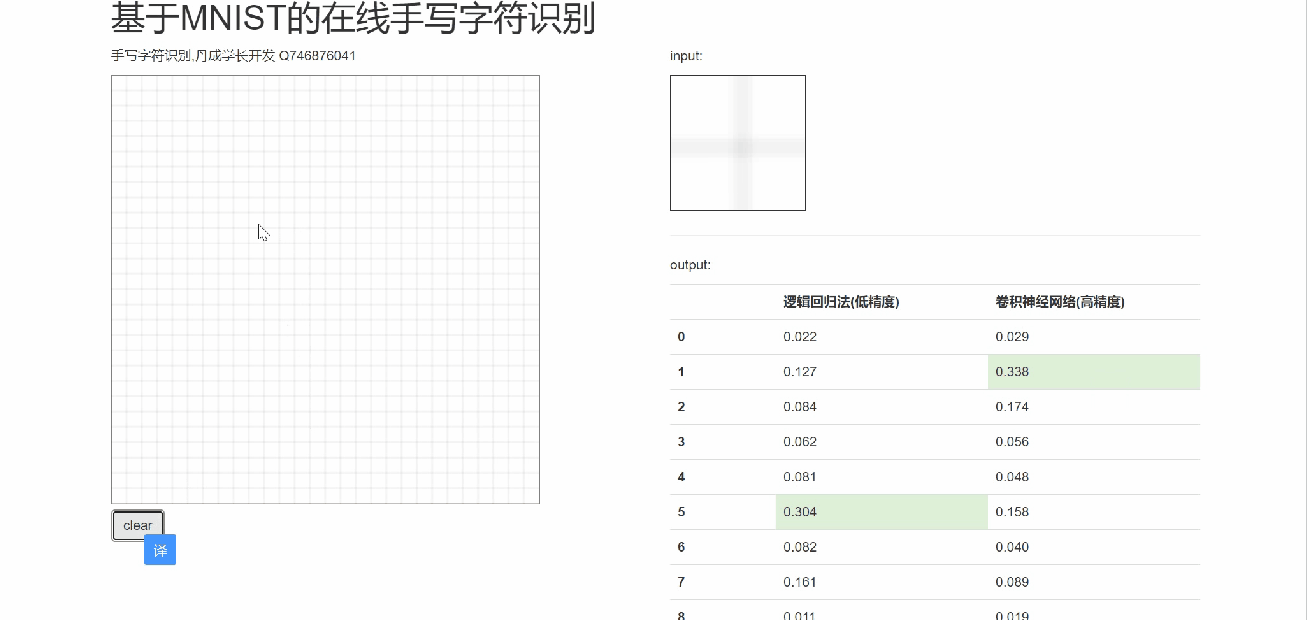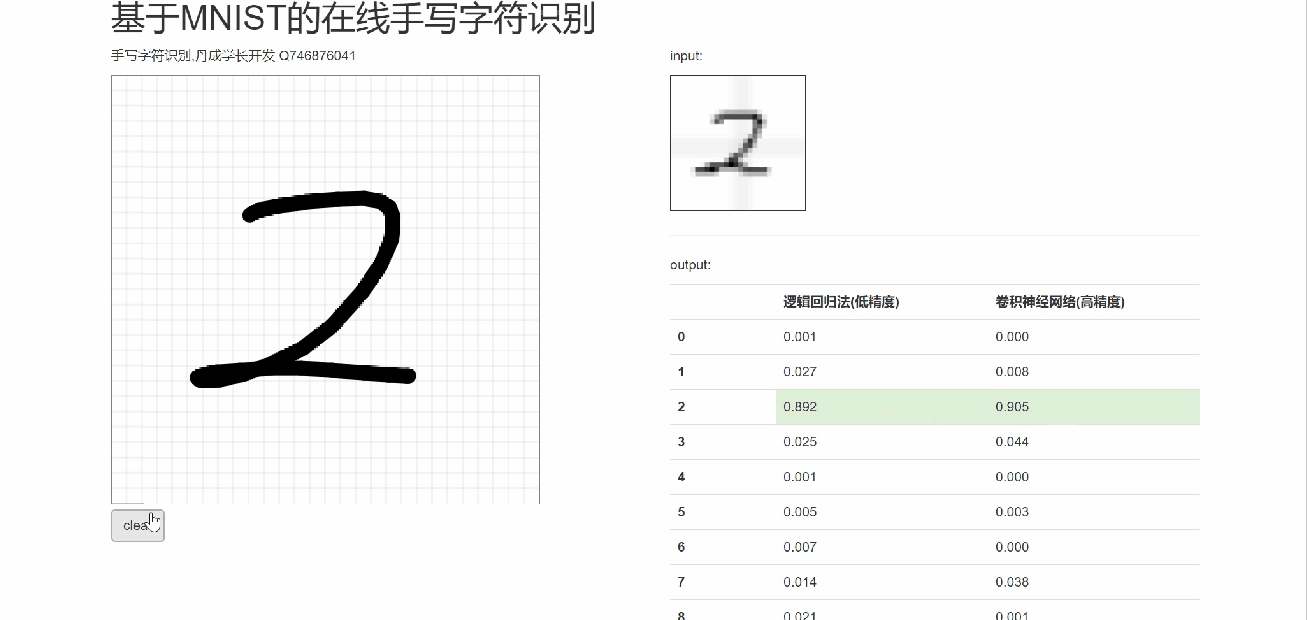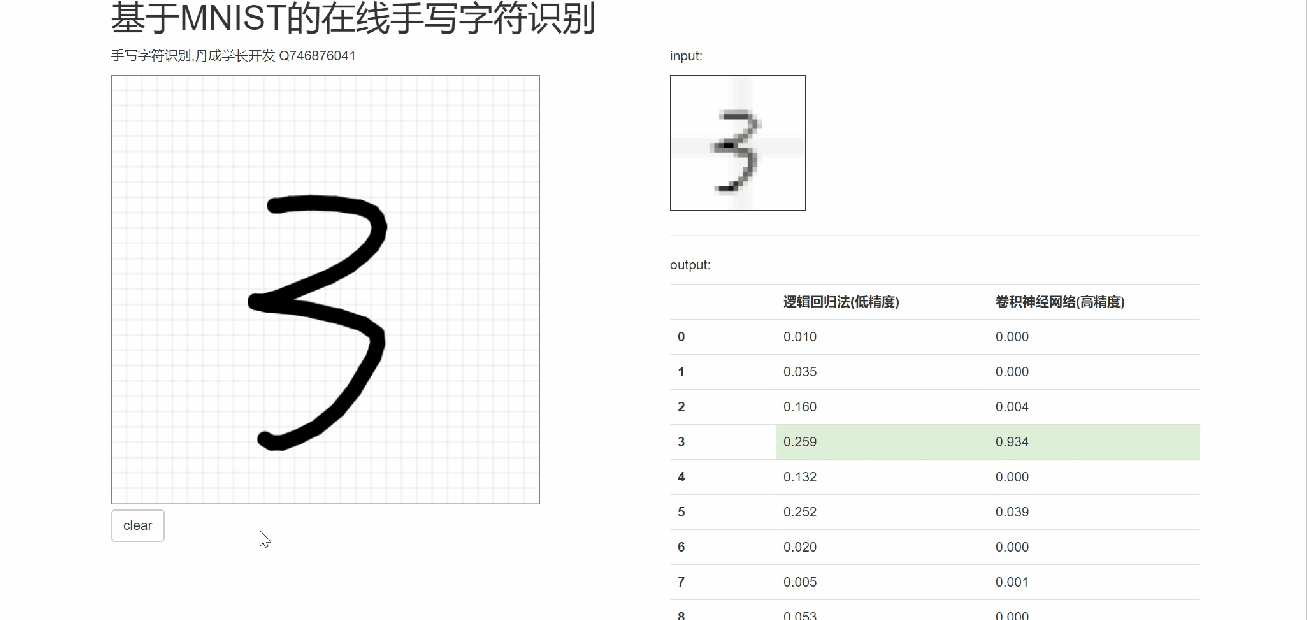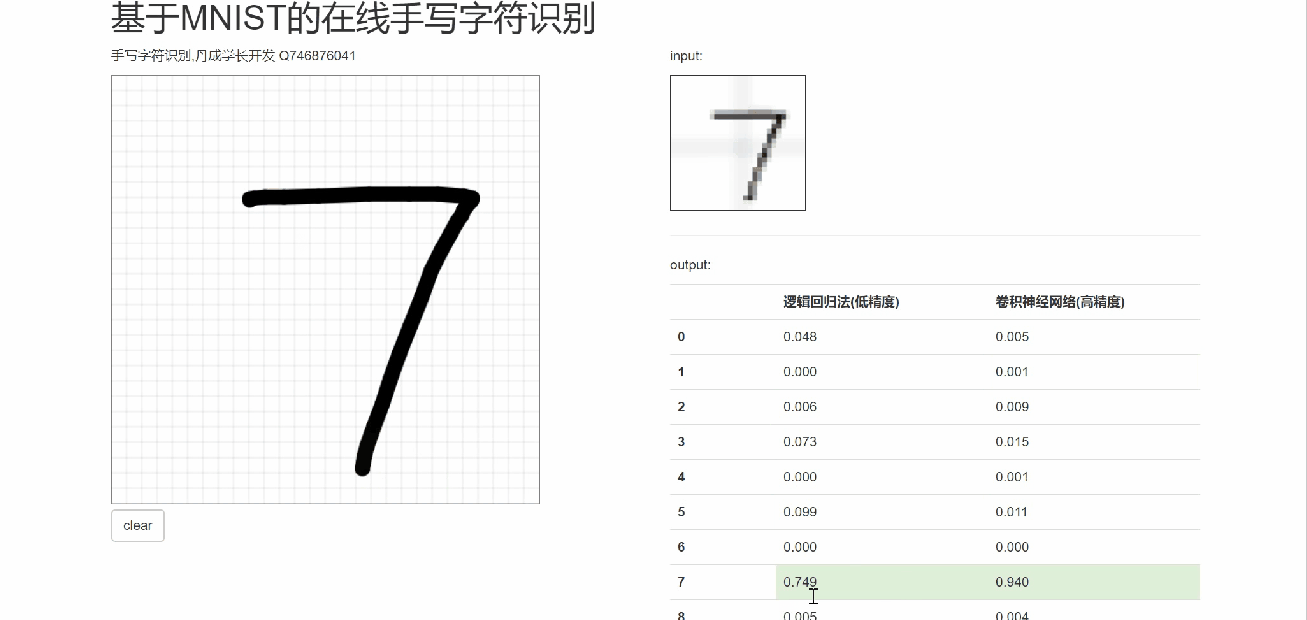
7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛选题 题目:基于卷积神经网络的手写字符识别 - 深度学习
文章目录 0 前言1 简介2 LeNet-5 模型的介绍2.1 结构解析2.2 C1层2.3 S2层S2层和C3层连接 2.4 F6与C5层 3 写数字识别算法模型的构建3.1 输入层设计3.2 激活函数的选取3.3 卷积层设计3.4 降采样层3.5 输出层设计 4 网络模型的总体结构5 部分实现代码6 在线手写识别7 最后 0 前言…...
Cesium-terrain-builder编译入坑详解
本以为编译cesium-terrian-tools编译应该没那么难,不想问题重重,不想后人重蹈覆辙,也记录下点点滴滴。 目前网上存在的cesium代码版本主要有两个分支: 原始网站【不能生成layer文件,且经久不更新,使用gdal…...

3.1 CPU内部结构与时钟与指令
CPU内部结构 总线一些自定义部件总线图内存指令执行流程:取指令,译码,执行pc做的事内存地址寄存器内存缓存寄存器指令寄存器,译码第一步指令寄存器传递地址到内存地址寄存器指令MOV_A的过程(译码第二步)第一条指令执行完毕第三条指令的执行第四条指令第四条指令不同的执行流程…...
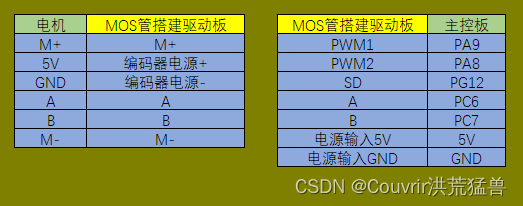
电机应用-直流有刷电机多环控制实现
目录 直流有刷电机多环控制实现 硬件设计 直流电机三环(速度环、电流环、位置环)串级PID控制-位置式PID 编程要点 配置ADC可读取电流值 配置基本定时器6产生定时中断读取当前电路中驱动电机的电流值并执行PID运算 配置定时器1输出PWM控制电机 配…...
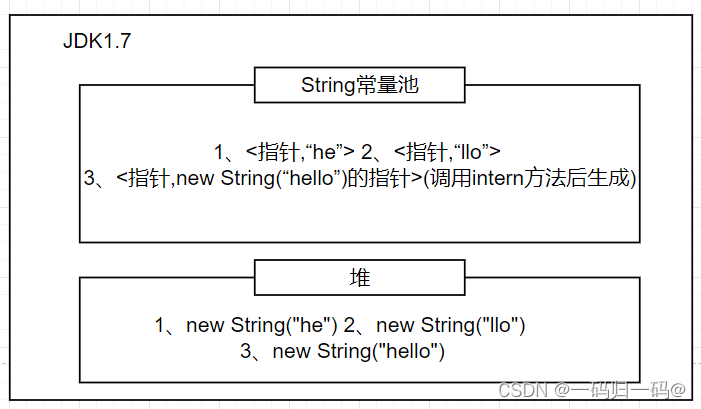
Java常量池理论篇:Class常量池、运行时常量池、String常量池、基本类型常量池,intern方法1.6、1.7的区别
文章目录 Class常量池运行时常量池String常量池基本类型常量池Integer 常量池Long 常量池 加餐部分 Class常量池 每个Class字节码文件中包含类常量池用来存放字面量以及符号引用等信息。 运行时常量池 java文件被编译成class文件之后,也就是会生成我上面所说的 …...

module java.base does not “opens java.io“ to unnamed module
环境 如上图所示, Runtime version的版本是JAVA 17 项目所需要JDK版本为JAVA 8 解决...
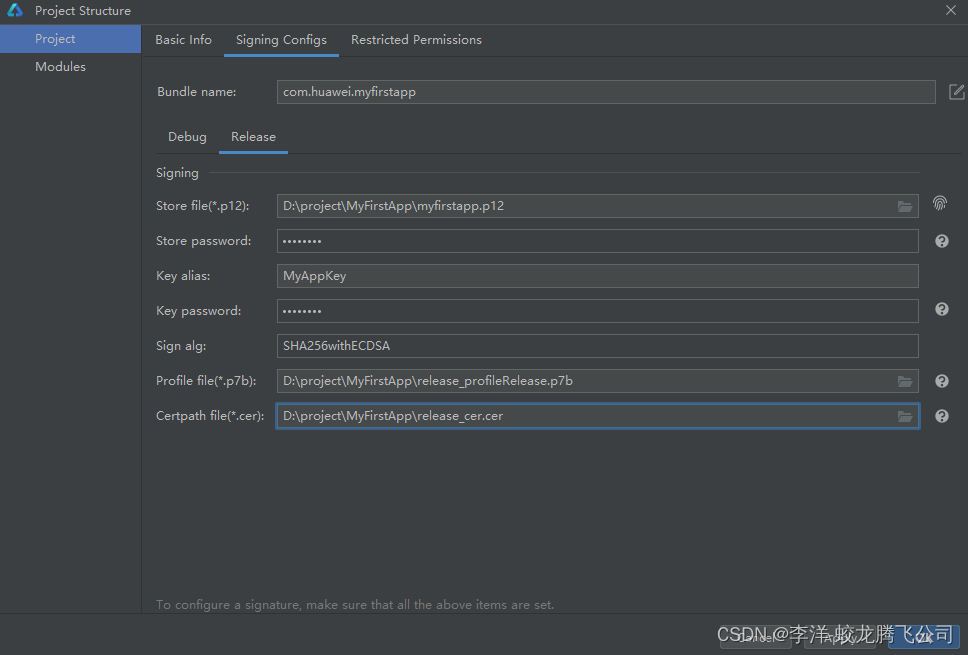
鸿蒙原生应用/元服务开发-AGC分发如何配置签名信息
使用制作的私钥(.p12)文件、在AGC申请的证书文件和Profile(.p7b)文件,在DevEco Studio配置工程的签名信息,以构建携带发布签名信息的APP。 1.打开DevEco Studio,菜单选择“File > Project S…...
】)
【HTML5-webscoket实时通信(web)】
websocket是什么? 就是用来创建网络聊天室,实时通信websocket的方法有哪些? https://developer.mozilla.org/zh-CN/docs/Web/API/WebSockets如何实现:(以下实现流程) 前端: // 直播中// 聊天web…...
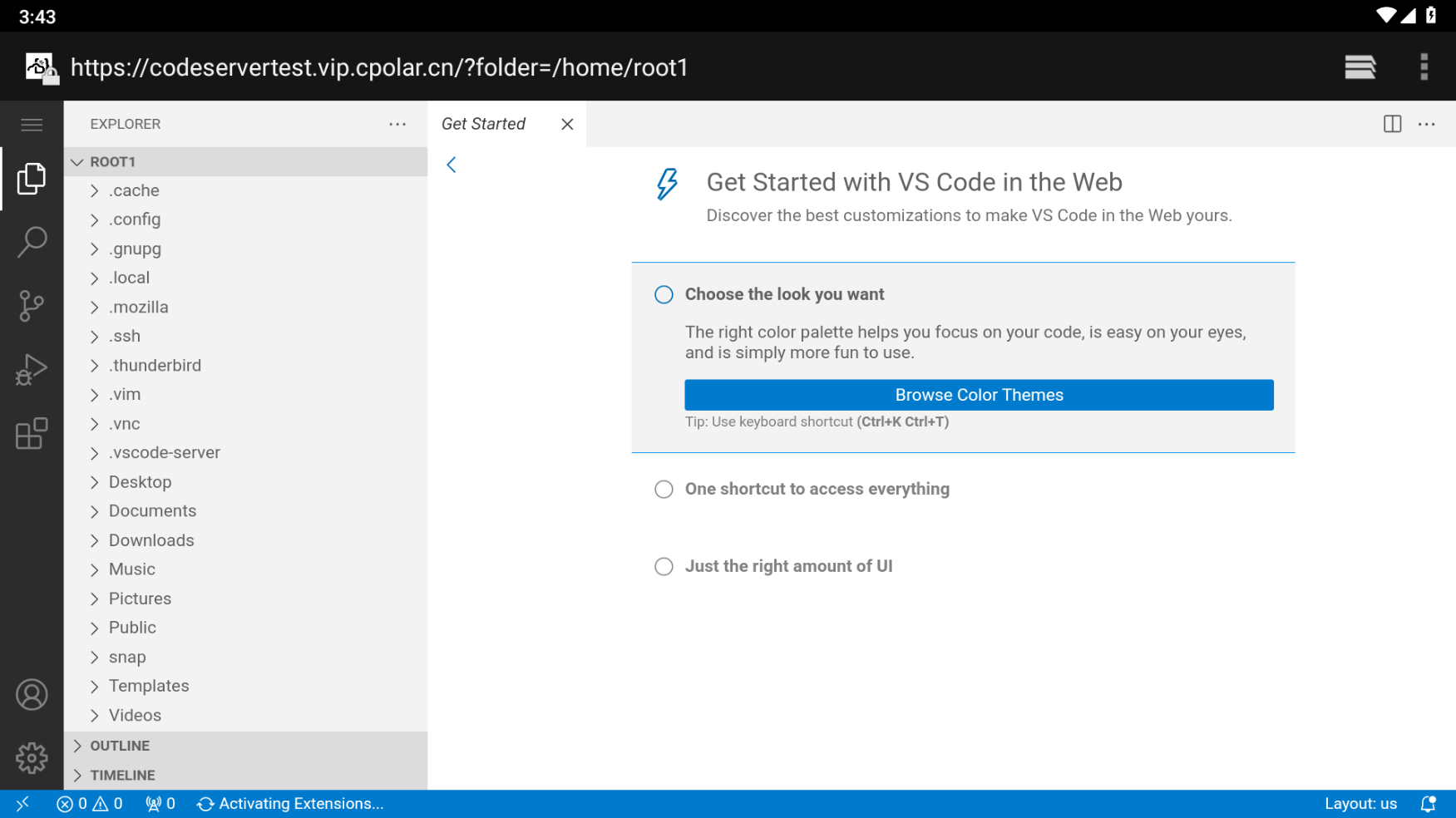
如何在Android平板上远程连接Ubuntu服务器code-server进行代码开发?
文章目录 1.ubuntu本地安装code-server2. 安装cpolar内网穿透3. 创建隧道映射本地端口4. 安卓平板测试访问5.固定域名公网地址6.结语 1.ubuntu本地安装code-server 准备一台虚拟机,Ubuntu或者centos都可以,这里以VMwhere ubuntu系统为例 下载code serve…...

SAP Smartforms打印报错Error in spool C call : spool overflow
处理方式: SAP打印时提示: Error in spool C call : spool overflow (假脱机请求溢出,通俗一点打印池已满) 解决办法: SE38 首先运行程序RSPO1041 再运行RSPO1043,话不多说上图。...

SQL 中的运算符与别名:使用示例和语法详解
SQL中的IN运算符 IN运算符允许您在WHERE子句中指定多个值,它是多个OR条件的简写。 示例:获取您自己的SQL Server 返回所有来自’Germany’、France’或’UK’的客户: SELECT * FROM Customers WHERE Country IN (Germany, France, UK);语…...

3.2 CPU的自动化
CPU的自动化 改造1-使用2进制导线改造2根据整体流程开始改造指令分析指令MOV_A的开关2进制表格手动时钟gif自动时钟gif 根据之前的CPU内部结构改造,制造一个cpu控制单元 改造一 之前的CPU全由手动开关自己控制,极度繁琐,而开关能跟二进制一一对应, 开:1, 关:0图1是之前的, …...

深入理解@Resource与@Autowired:用法与区别解析
Resource: Resource 是Java EE提供的注解,也可以在Spring中使用。它是按照名称进行注入的,默认通过属性名(通常是类名的小驼峰命名方式)或者name属性来匹配。如果找不到符合名称的bean,则会抛出异常。在使…...

高级驾驶辅助系统 (ADAS)介绍
随着汽车技术持续快速发展,推动更安全、更智能、更高效的驾驶体验一直是汽车创新的前沿。高级驾驶辅助系统( ADAS ) 是这场技术革命的关键参与者,是 指集成到现代车辆中的一组技术和功能,用于增强驾驶员安全、改善驾驶体验并协助完成各种驾驶任务。它使用传感器、摄像头、雷…...
2 使用React构造前端应用
文章目录 简单了解React和Node搭建开发环境React框架JavaScript客户端ChallengeComponent组件的主要结构渲染与应用程序集成 第一次运行前端调试将CORS配置添加到Spring Boot应用使用应用程序部署React应用程序小结 前端代码可从这里下载: 前端示例 后端使用这里介…...
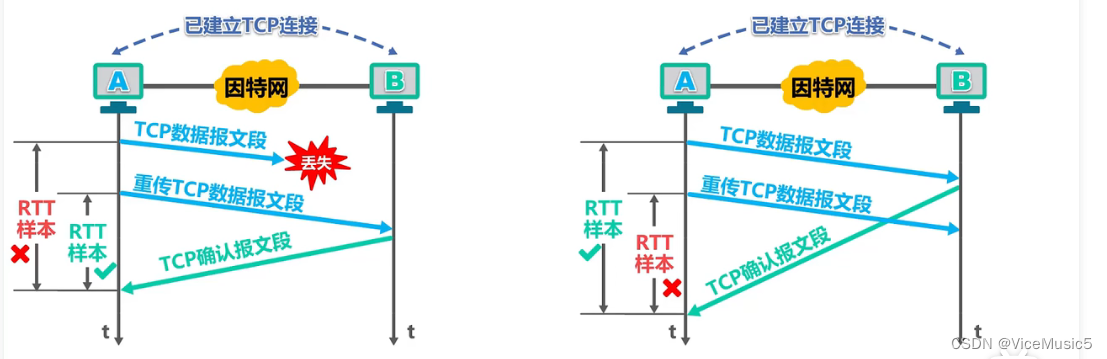
[计算机网络]运输层概述
虽然我自己也不知道写在前面和前言有什么区别..... 这个系列其实是针对<深入浅出计算机网络>的简单总结,加入了一点个人的理解和浅薄见识,如果您有一些更好的意见和见解,欢迎随时协助我改正,感激不尽啦. 最近心态平和了不少, 和过去也完全做了个割舍吧,既然痛苦和压力的…...
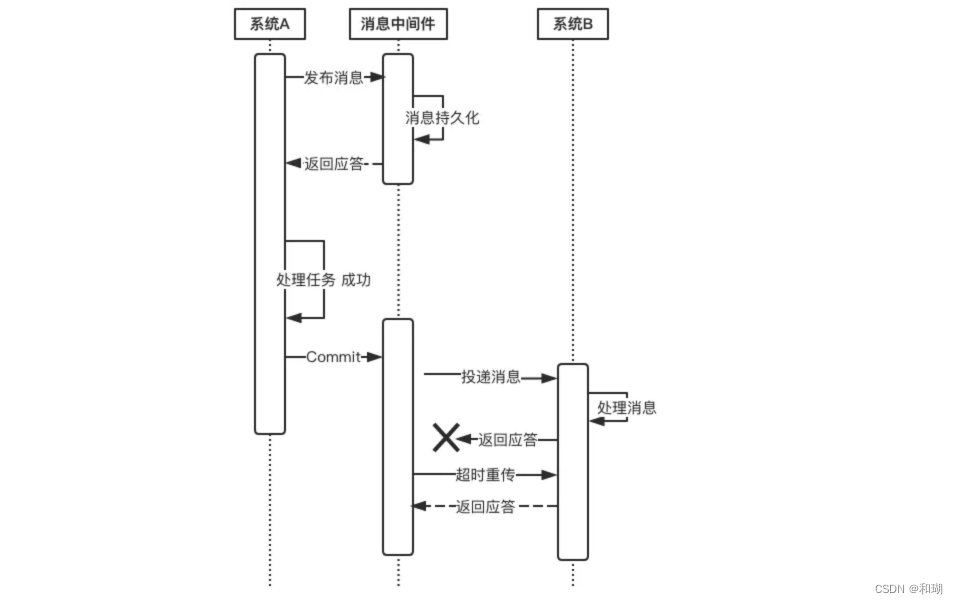
【分布式】分布式事务及其解决方案
目录 一、分布式事务二、分布式事务的解决方案1. 全局事务(1)DTP模型(2) 两阶段提交协议(2PC)原理二阶段提交的缺点 (3)三阶段提交协议(3PC)原理 2. 基于可靠…...

【文末送书】机器学习高级实践
2023年初是人工智能爆发的里程碑式的重要阶段,以OpenAI研发的GPT为代表的大模型大行其道,NLP领域的ChatGPT模型火爆一时,引发了全民热议。而最新更新的GPT-4更是实现了大型多模态模型的飞跃式提升,它能够同时接受图像和文本的输入…...
吉他初学者学习网站搭建系列(1)——目录
文章目录 背景文章目录功能网站地址网站展示展望 背景 这个系列是对我最近周末搭建的吉他工具类平台YUERGS的总结。我个人业余爱好是自学吉他,我会在这个平台中动手集成我认为很有帮助的一些工具,来提升我的吉他水平和音乐素养,希望也可以帮…...
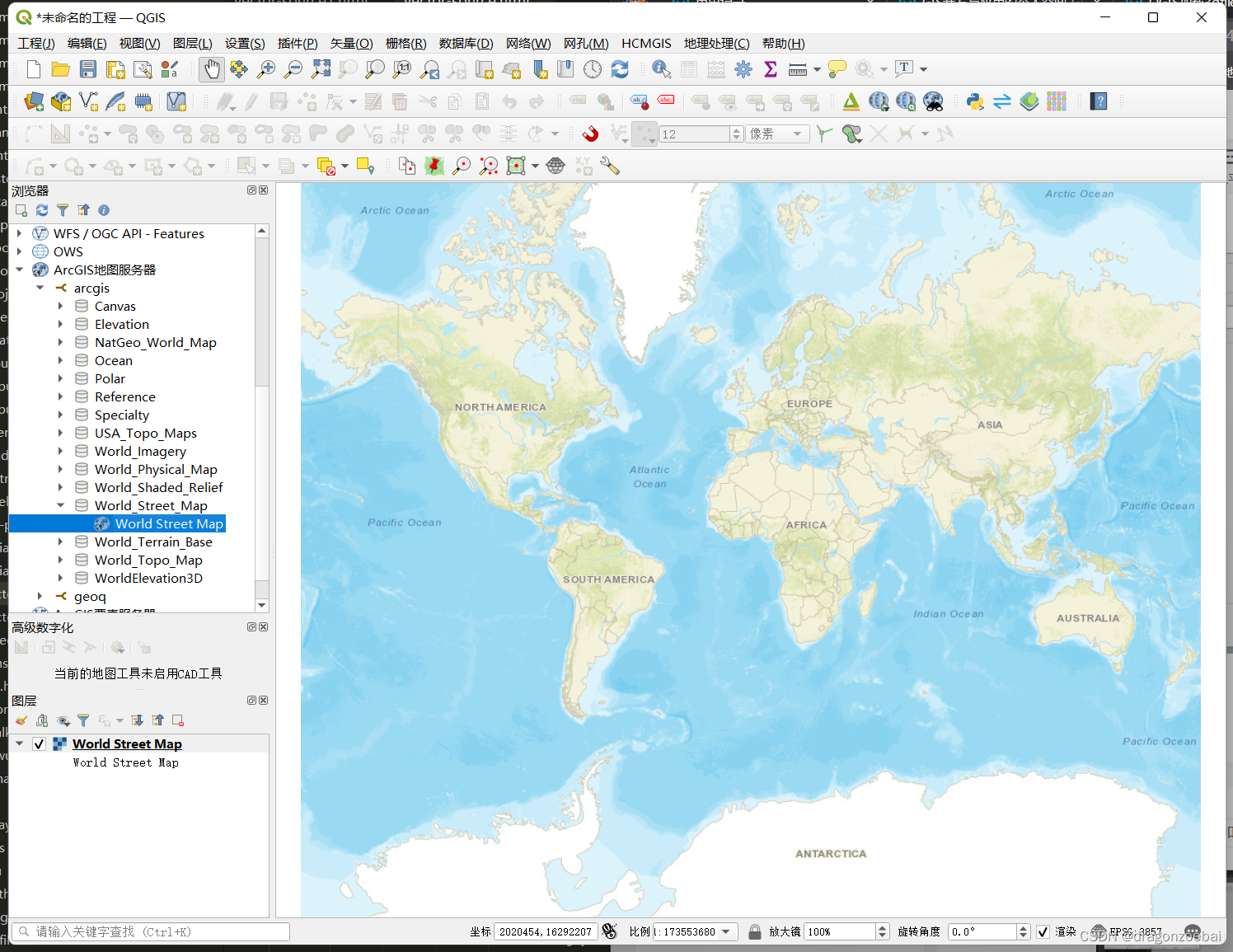
qgis添加arcgis的mapserver
左侧浏览器-ArcGIS地图服务器-右键-新建连接 Folder: / 展开-双击图层即可...

如何在Blender中实现虚幻引擎PSK/PSA文件的无缝导入导出
如何在Blender中实现虚幻引擎PSK/PSA文件的无缝导入导出 【免费下载链接】io_scene_psk_psa A Blender extension for importing and exporting Unreal PSK and PSA files 项目地址: https://gitcode.com/gh_mirrors/io/io_scene_psk_psa 你是否曾为在Blender和虚幻引擎…...

如何快速解密QQ音乐加密音频:qmcdump完整使用指南
如何快速解密QQ音乐加密音频:qmcdump完整使用指南 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾为…...

遇到识别不准确?Emotion2Vec+语音情感识别系统问题排查指南
遇到识别不准确?Emotion2Vec语音情感识别系统问题排查指南 1. 引言:当AI“听”不懂情绪时 想象一下这个场景:你满怀期待地将一段客服通话录音上传到Emotion2Vec语音情感识别系统,希望它能帮你分析客户的情绪状态。结果屏幕上却显…...

教学新工具:用MedGemma-X提升住院医师影像诊断准确率
教学新工具:用MedGemma-X提升住院医师影像诊断准确率 1. 传统影像教学面临的挑战 1.1 住院医师培养的三大痛点 在放射科住院医师规范化培训中,影像诊断教学长期存在几个关键问题: 反馈延迟:学员完成阅片后,往往需要…...

快手大模型二面:假如说要设计一个多轮对话Agent,你会怎么设计?
1. 题目分析 几乎每个人都用过多轮对话——打开 ChatGPT 聊几句就是。但是要设计一个多轮对话可不容易。多轮对话 Agent 的设计之所以难,不是因为某一个技术点特别深奥,而是因为它要求你同时想清楚好几件事情怎么协同运作:上下文怎么管、状态…...

跨平台流媒体下载终极指南:如何用N_m3u8DL-RE轻松获取加密视频内容
跨平台流媒体下载终极指南:如何用N_m3u8DL-RE轻松获取加密视频内容 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_…...

MySQL中如何利用ASCII码转换字符_MySQL ASCII函数应用
ASCII()函数仅返回字符串首字符的ASCII码值,如ASCII(ab)得97;处理多字符需配合SUBSTRING()逐位提取,且不适用于UTF-8多字节字符解析。MySQL里ASCII()函数只能取第一个字符的码值很多人以为ASCII()能处理整个字符串,结果发现ASCII(…...

开源鸿蒙 Flutter 实战|页面转场动画完整实现
🎬 开源鸿蒙 Flutter 实战|页面转场动画完整实现 欢迎加入开源鸿蒙跨平台社区→https://openharmonycrosplatform.csdn.net 【摘要】本文面向开源鸿蒙跨平台开发新手,基于 Flutter 框架实现了 7 种风格的页面转场动画,包含淡入淡…...

毕业不焦虑,百考通AI帮你高效搞定本科毕业论文
深夜的电脑屏幕前,一个大学生正对着空白的文档发呆,毕业论文的截止日期日益临近,他却连选题都还没确定。这或许是无数毕业生共同经历过的煎熬时刻。 一、毕业季的论文困境:每个本科生都懂 又到一年毕业季,校园里弥漫着…...

D2DX终极指南:如何让经典暗黑破坏神2在现代PC上焕发新生
D2DX终极指南:如何让经典暗黑破坏神2在现代PC上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 你是否曾…...