ElasticSearch01
ElasticSearch
版本:7.8 学习视频:尚硅谷
笔记:https://zgtsky.top/
ElasticSearch介绍
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ElasticSearch的官方地址: https://www.elastic.co/products/elasticsearch
ElasticSearch的使用案例
-
2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”
-
维基百科:启动以elasticsearch为基础的核心搜索架构
-
SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
-
百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
-
新浪使用ES 分析处理32亿条实时日志
-
阿里使用ES 构建挖财自己的日志采集和分析体系
相关知识
全文检索:
-
数据分类
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
- 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件
-
结构化数据搜索
常见的结构化数据也就是数据库中的数据。在数据库中搜索很容易实现,通常都是使用sql语句进行查询,而且能很快的得到查询结果。
为什么数据库搜索很容易?
因为数据库中的数据存储是有规律的,有行有列而且数据格式、数据长度都是固定的。
-
非结构化数据查询方法
(1)顺序扫描法
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。
(2)全文检索
将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如:字典。字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
正向索引(forward index)
在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。
问题:当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
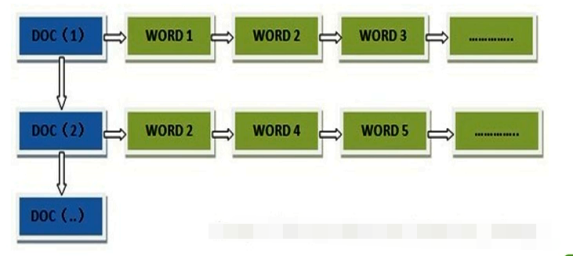
反向索引(inverted index)
更熟悉的名字是倒排索引
搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。

全文检索的实现:可以使用Lucene实现全文检索。Lucene是apache下的一个开放源代码的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
应用场景:对于数据量大、数据结构不固定的数据可采用全文检索方式搜索,比如:百度、Google等搜索引擎、论坛站内搜索、电商网站站内搜索等。
索引和搜索流程图

1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容 —->采集文档—->创建文档—->分析文档—->索引文档
2、红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面—->创建查询—>执行搜索,从索引库搜索—>渲染搜索结果
全文检索大体分两个过程,索引创建 (Indexing) 和搜索索引 (Search) 。
-
索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
-
搜索索引:得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
创建索引
对文档索引的过程,将用户要搜索的文档内容进行索引,索引存储在索引库(index)中。
索引里面究竟需要存些什么呢?
首先我们来看为什么顺序扫描的速度慢:
其实是由于我们想要搜索的信息和非结构化数据中所存储的信息不一致造成的。
非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。
而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。
两者恰恰相反。于是如果索引总能够保存从字符串到文件的映射,则会大大提高搜索速度。
1) 创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容),如下图:

注意:每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field(域名和域值都相同)
每个文档都有一个唯一的编号,就是文档id。
2) 分析文档
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析成为一个一个的单词。
原文档内容:
vivo X23 8GB+128GB 幻夜蓝 全网通4G手机
华为 HUAWEI 麦芒7 6G+64G 亮黑色 全网通4G手机
分析后得到的词:
vivo, x23, 8GB, 128GB, 幻夜, 幻夜蓝, 全网, 全网通, 网通, 4G, 手机, 华为, HUAWEI, 麦芒7。。。。
切分后得到的词用来做成索引(目录)。
3) 创建索引
索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
注意:创建索引是对语汇单元索引,通过词语找文档,这种索引的结构叫倒排索引结构。

传统方法是根据文件找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢。
倒排索引结构是根据内容(词语)找文档,如下图:
正排索引:

转化成倒排索引:
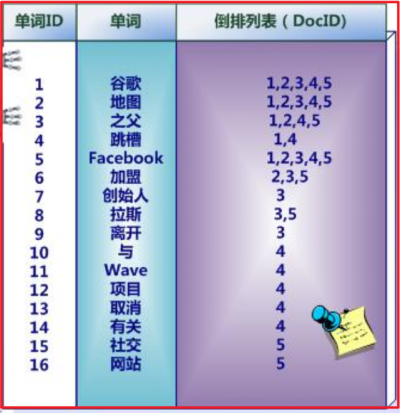
说明:
-
“单词ID”一栏记录了每个单词的单词编号;
-
第二栏是对应的单词;
-
第三栏即每个单词对应的倒排列表;
-
比如单词“谷歌”,其单词编号为1,倒排列表为{1,2,3,4,5},说明文档集合中每个文档都包含了这个单词。
而事实上,索引系统还可以记录除此之外的更多信息,在单词对应的倒排列表中不仅记录了文档编号,还记载了单词频率信息(TF),即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。
倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。

Elasticsearch与mysql的区别
响应时间:
MySQL
背景:当数据库中的文档数仅仅上万条时,关键词查询就比较慢了。如果一旦到企业级的数据,响应速度就会更加不可接受。
原因:在数据库做模糊查询时,如LIKE语句,它会遍历整张表,同时进行字符串匹配。
例如,在数据库查询“手机”时,数据库会在每一条记录去匹配“手机”这两字是否出现。实际上,并不是所有记录都包含“手机”,所以做了很多无用功。
这个步骤都不高效,而且随着数据量的增大,消耗的资源和时间都会线性的增长。
Elasticsearch
提升:小张使用了ES搜索服务后,发现这个问题被很好解决,TB级数据在毫秒级就能返回检索结果,很好地解决了痛点。
原因:Elasticsearch是基于倒排索引的,例子如下。

当搜索“手机”时,Elasticsearch就会立即返回文档F,G,H。这样就不用花多余的时间在其他文档上了,因此检索速度得到了数量级的提升。
分词:
MySQL
背景:在做中文搜索时,组合词检索在数据库是很难完成的。
例如,当用户在搜索框输入“四川火锅”时,数据库通常只能把这四个字去进行全部匹配。可是在文本中,可能会出现“推荐四川好吃的火锅”,这时候就没有结果了。
原因:数据库并不支持分词。如果人工去开发分词功能,费时费精力。
Elasticsearch
提升:使用ES搜索服务后,就不用太过于关注分词了,因为Elasticsearch支持中文分词插件,很好地解决了问题。
原因:当用户使用Elasticsearch时进行搜索时,Elasticsearch就自动分好词了。
例如 输入“四川火锅”时,Elasticsearch会自动做下面两件事
(1) 将“四川火锅”分词成“四川”和“火锅”
(2) 查找包含这两个词的文档
相关性
MySQL
背景:在用数据库做搜索时,结果经常会出现一系列不匹配的文档。思考:
· 到底什么文档是用户真正想要的呢?
· 怎么才能把用户想看的文档放在搜索列表最前面呢?
原因:数据库并不支持相关性搜索。
例如,当用户搜索“咖啡厅”的时候,他很可能更想知道附近哪里可以喝咖啡,而不是怎么开咖啡厅。
Elasticsearch
提升:使用了ES搜索服务后,发现Elasticsearch能很好地支持相关性评分。通过合理的优化,ES搜索服务能够返回精准的结果,满足用户的需求。
原因:Elasticsearch支持全文搜索和相关度评分。这样在返回结果就会根据分数由高到低排列。分数越高,意味着和查询语句越相关。
例如,当用户搜索“星巴克咖啡”,带有“星巴克咖啡”的信息就要比只包含“咖啡”的信息靠前。
总结
1.传统数据库在全文检索方面很鸡肋,海量数据下的查询很慢,对非结构化文本数据的不支持,ES支持非结构化数据的存储和查询。
2.ES支持分布式文档存储。
3.ES是分布式实时搜索,并且响应时间比关系型数据库快。
4.ES在分词方面比关系型好,能做到精确分词。
5.ES对已有的数据,在数据匹配性方面比关系型数据库好, 例如:搜索“星巴克咖啡”,ES会优先返回带有“星巴克咖啡”的数据,不会优先返回带有“咖啡”的数据。
ElasticSearch和MySql分工不同,MySQL负责存储数据,ElasticSearch负责搜索数据。
ElasticSearch安装与启动
ElasticSearch分为Linux和Window版本,基于我们主要学习ElasticSearch的Java客户端的使用,所以我们课程中使用的是安装较为简便的Window版本,项目上线后,公司的运维人员会安装Linux版的ES供我们连接使用。
ElasticSearch的官方地址: https://www.elastic.co/products/elasticsearch
ElasticSearch7.8 的官方文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.8/getting-started.html
需要的资源:

安装服务:
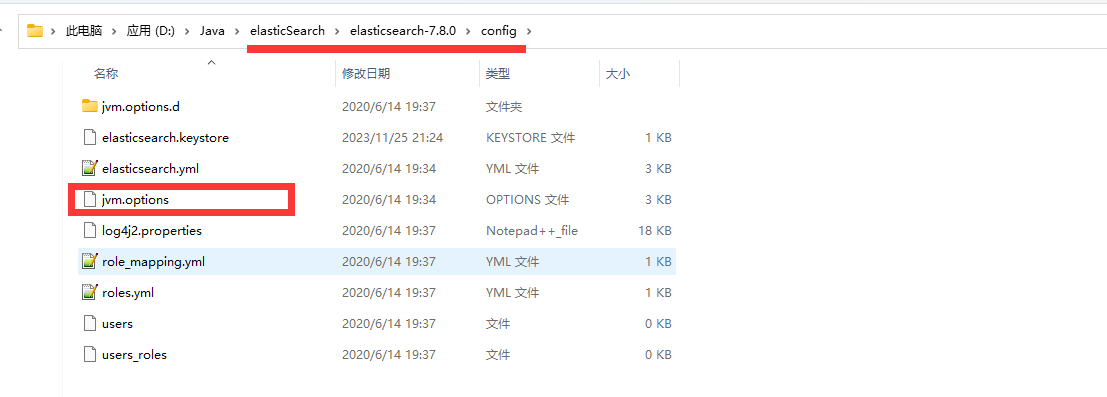
Window版的ElasticSearch的安装很简单,解压开即安装完毕,解压后的ElasticSearch的目录结构如下:

安装IK分词器插件:在plugin目录下创建ik文件夹,将elasticsearch-analysis-ik-7.8.0.zip内容解压到ik目录下:

点击ElasticSearch下的bin目录下的elasticsearch.bat启动,控制台显示的日志信息如下:

注意:9300是tcp通讯端口,集群间和TCPClient都执行该端口,9200是http协议的RESTful接口 。
通过浏览器访问ElasticSearch服务器:http://localhost:9200

注意事项一:ElasticSearch是使用java开发的,且本版本的es需要的jdk版本要是1.8以上,所以安装ElasticSearch之前保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败。
注意事项二:出现闪退,通过路径访问发现“空间不足”
【解决方案】
修改jvm.options文件的22行23行, Elasticsearch启动的时候占用1个G的内存,可改成512m:
-Xmx512m:设置JVM最大可用内存为512M。
-Xms512m:设置JVM初始内存为512m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
Kibana客户端(Windows版)
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。
解压kibana-7.8.0-windows-x86_64.zip

进入config目录修改kibana.yml第2、28行,配置自身端口和连接的ES服务器地址。
server.port: 5601
elasticsearch.hosts: [“http://localhost:9200”]
进入kibana的bin目录,双击kibana.bat启动:注:es不可以关闭

访问:http://localhost:5601,出现以下界面即完成安装。

界面是英文的,如果希望是中文,可以修改kibana.yml第115行:i18n.locale: “zh-CN”
Elasticsearch head客户端
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等。
将ElasticSearch-head-Chrome-0.1.5-Crx4Chrome.crx用压缩工具解压,打开Chrome扩展程序,点” 加载已解压的扩展程序”按钮,找到解压目录即可。


点击head图标,输入ES服务器地址:http://localhost:9200

使用IK分词器
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
1)采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
2)采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
3)对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同时是支持个人词条的优化的词典存储,更小的内存占用。
4)支持用户词典扩展定义。
5)针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
在没有使用IK分词器时,默认是standard方式分词,这种方式分词就是一个字就是一个词。
而IK分词器有两种分词模式:ik_max_word和ik_smart模式。
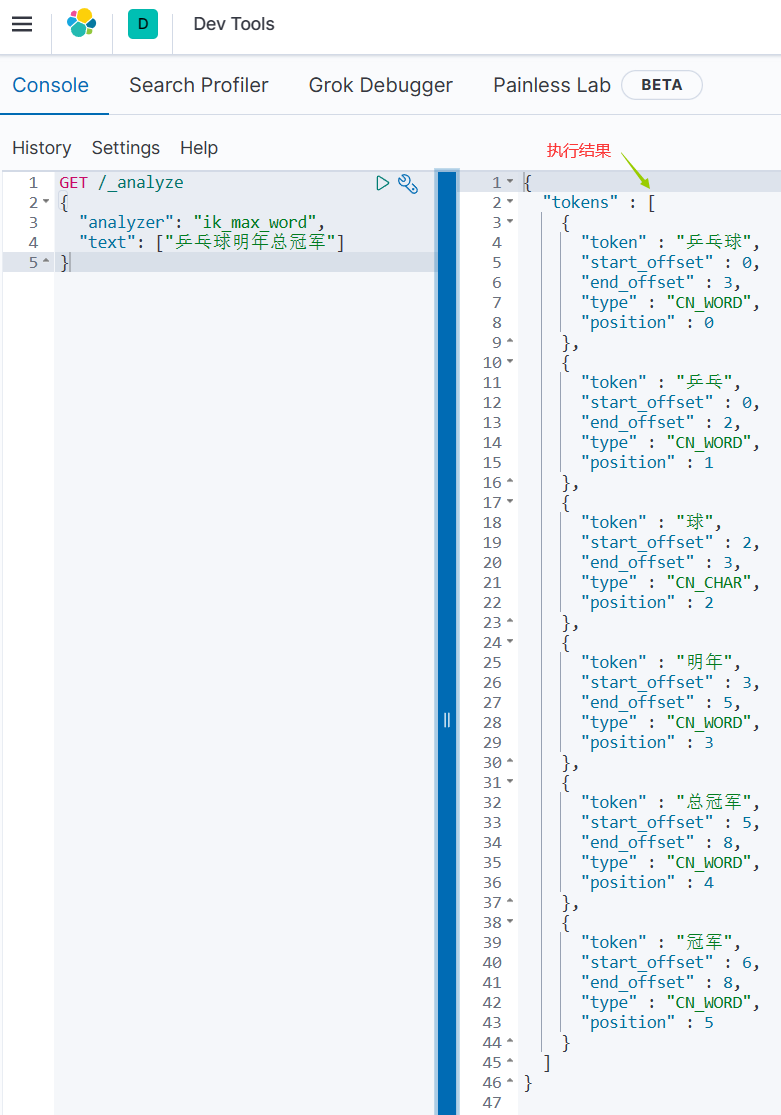
ik_max_word :会将文本做最细粒度的拆分,比如会将“乒乓球明年总冠军”拆分为“乒乓球、乒乓、球、明年、总冠军、冠军。
#方式一ik_max_word
GET /_analyze
{"analyzer": "ik_max_word","text": "乒乓球明年总冠军"
}#分词器执行结果:
{"tokens" : [{"token" : "乒乓球","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "乒乓","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 1},{"token" : "球","start_offset" : 2,"end_offset" : 3,"type" : "CN_CHAR","position" : 2},{"token" : "明年","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 3},{"token" : "总冠军","start_offset" : 5,"end_offset" : 8,"type" : "CN_WORD","position" : 4},{"token" : "冠军","start_offset" : 6,"end_offset" : 8,"type" : "CN_WORD","position" : 5}]
}
ik_smart: 会做粗粒度的拆分,比如会将“乒乓球明年总冠军”拆分为乒乓球、明年、总冠军。
#ik_smart方式
GET /_analyze
{"analyzer": "ik_smart","text": ["乒乓球明年总冠军"]
}#结果:
{"tokens" : [{"token" : "乒乓球","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "明年","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 1},{"token" : "总冠军","start_offset" : 5,"end_offset" : 8,"type" : "CN_WORD","position" : 2}]
}
ElasticSearch相关概念(术语)
Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{"name" : "jack","sex" : "Male","age" : 25,"birthDate": "1990/05/01","about" : "I love to go rock climbing","interests": [ "sports", "music" ]
}
Elasticsearch可以看成是一个数据库,只是和关系型数据库比起来数据格式和功能不一样而已

索引 Index
文档存储的地方,类似于MySQL数据库中的数据库概念
类型 Type
如果按照关系型数据库中的对应关系,还应该有表的概念。ES中没有表的概念,这是ES和数据库的一个区别,在我们建立索引之后,可以直接往 索引 中写入文档。
在6.0版本之前,ES中有Type的概念,可以理解成关系型数据库中的表,但是官方说这是一个设计上的失误,所以在6.0版本之后Type就被废弃了。
字段 Field
相当于是数据表的字段,字段在ES中可以理解为JSON数据的键,下面的JSON数据中,name 就是一个字段。
{"name":"jack"
}
映射 Mapping
映射 是对文档中每个字段的类型进行定义,每一种数据类型都有对应的使用场景。
每个文档都有映射,但是在大多数使用场景中,我们并不需要显示的创建映射,因为ES中实现了动态映射。
我们在索引中写入一个下面的JSON文档,在动态映射的作用下,name会映射成text类型,age会映射成long类型。
{"name":"jack","age":18,
}
自动判断的规则如下:
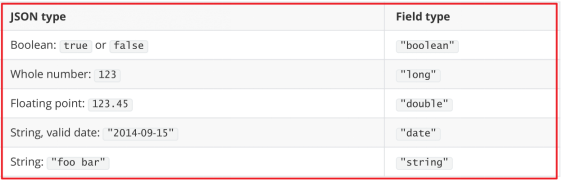
Elasticsearch中支持的类型如下:

-
string类型在ElasticSearch 旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代。(已经废弃)
-
text 类型,需要分词设置text类型,比如Email内容、产品描述,应该使用text类型。
-
keyword类型 ,不需要分词设置keyword类型,比如email地址、主机名、状态码和标签。
-
复杂数据类型:
-
数组:[]
-
对象:{}

文档 Document
文档 在ES中相当于传统数据库中的行的概念,ES中的数据都以JSON的形式来表示,在MySQL中插入一行数据和ES中插入一个JSON文档是一个意思。下面的JSON数据表示,一个包含3个字段的文档。
{"name":"jack","age":18,"gender":1
}
一个文档不只有数据。它还包含了元数据(metadata)——关于文档的信息。三个必须的元数据节点是:
| 节点 | 说明 |
|---|---|
| _index | 文档存储的地方 |
| _type | 文档代表的对象的类 |
| _id | 文档的唯一标识 |
| _score | 文档的评分 |
相关文章:
ElasticSearch01
ElasticSearch 版本:7.8 学习视频:尚硅谷 笔记:https://zgtsky.top/ ElasticSearch介绍 Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;…...

GPT、GPT-2、GPT-3论文精读笔记
视频:GPT,GPT-2,GPT-3 论文精读【论文精读】_哔哩哔哩_bilibili MAE论文:把bert用回计算机视觉领域 CLIP论文:打通文本和图像 GPT 论文:Improving Language Understanding by Generative Pre-Training …...

深度学习八股文:混合精度训练过程出nan怎么办
其实如果是FP32的训练,基本的调试方法还是差不多,这里就讲一下混合精度训练过程中的nan。 混合精度训练使用较低的数值精度(通常是半精度浮点数,例如FP16)来加速模型训练,但在一些情况下,可能会…...

竞赛选题 题目:基于卷积神经网络的手写字符识别 - 深度学习
文章目录 0 前言1 简介2 LeNet-5 模型的介绍2.1 结构解析2.2 C1层2.3 S2层S2层和C3层连接 2.4 F6与C5层 3 写数字识别算法模型的构建3.1 输入层设计3.2 激活函数的选取3.3 卷积层设计3.4 降采样层3.5 输出层设计 4 网络模型的总体结构5 部分实现代码6 在线手写识别7 最后 0 前言…...
Cesium-terrain-builder编译入坑详解
本以为编译cesium-terrian-tools编译应该没那么难,不想问题重重,不想后人重蹈覆辙,也记录下点点滴滴。 目前网上存在的cesium代码版本主要有两个分支: 原始网站【不能生成layer文件,且经久不更新,使用gdal…...

3.1 CPU内部结构与时钟与指令
CPU内部结构 总线一些自定义部件总线图内存指令执行流程:取指令,译码,执行pc做的事内存地址寄存器内存缓存寄存器指令寄存器,译码第一步指令寄存器传递地址到内存地址寄存器指令MOV_A的过程(译码第二步)第一条指令执行完毕第三条指令的执行第四条指令第四条指令不同的执行流程…...
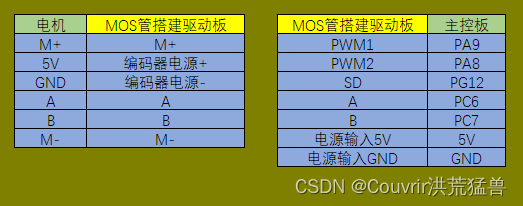
电机应用-直流有刷电机多环控制实现
目录 直流有刷电机多环控制实现 硬件设计 直流电机三环(速度环、电流环、位置环)串级PID控制-位置式PID 编程要点 配置ADC可读取电流值 配置基本定时器6产生定时中断读取当前电路中驱动电机的电流值并执行PID运算 配置定时器1输出PWM控制电机 配…...
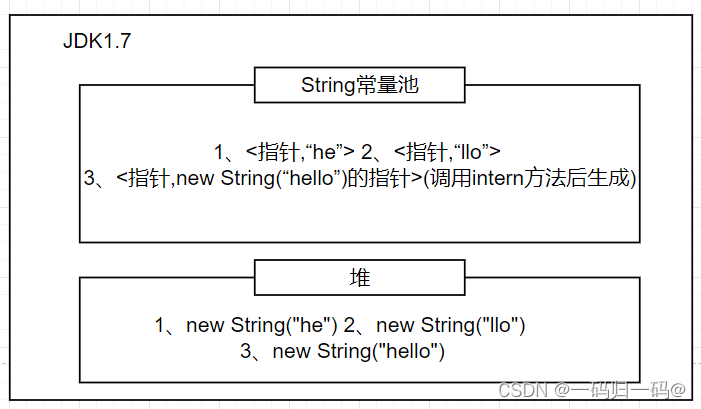
Java常量池理论篇:Class常量池、运行时常量池、String常量池、基本类型常量池,intern方法1.6、1.7的区别
文章目录 Class常量池运行时常量池String常量池基本类型常量池Integer 常量池Long 常量池 加餐部分 Class常量池 每个Class字节码文件中包含类常量池用来存放字面量以及符号引用等信息。 运行时常量池 java文件被编译成class文件之后,也就是会生成我上面所说的 …...

module java.base does not “opens java.io“ to unnamed module
环境 如上图所示, Runtime version的版本是JAVA 17 项目所需要JDK版本为JAVA 8 解决...
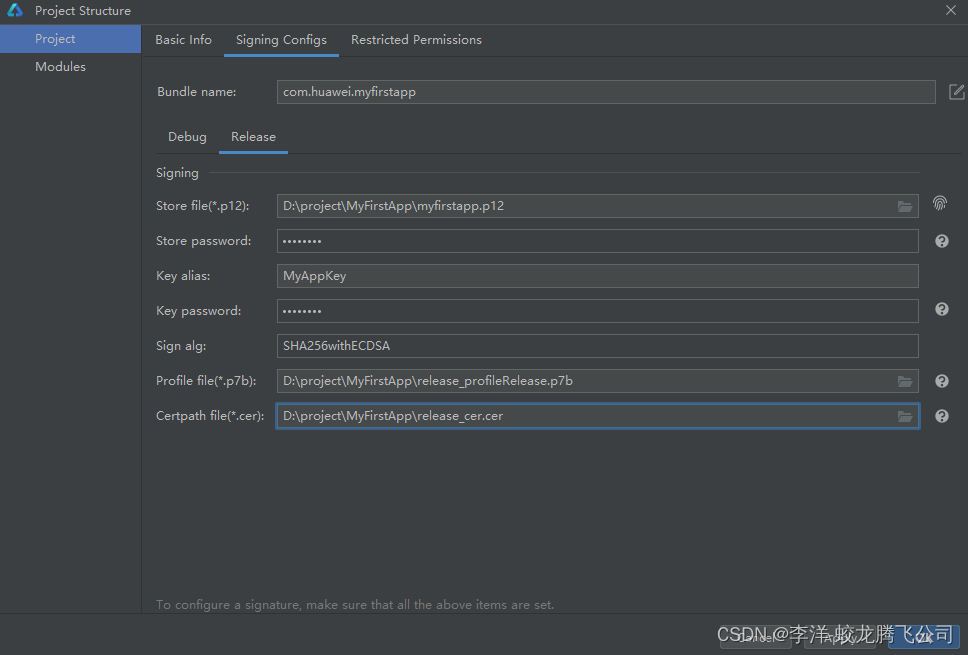
鸿蒙原生应用/元服务开发-AGC分发如何配置签名信息
使用制作的私钥(.p12)文件、在AGC申请的证书文件和Profile(.p7b)文件,在DevEco Studio配置工程的签名信息,以构建携带发布签名信息的APP。 1.打开DevEco Studio,菜单选择“File > Project S…...
】)
【HTML5-webscoket实时通信(web)】
websocket是什么? 就是用来创建网络聊天室,实时通信websocket的方法有哪些? https://developer.mozilla.org/zh-CN/docs/Web/API/WebSockets如何实现:(以下实现流程) 前端: // 直播中// 聊天web…...
如何在Android平板上远程连接Ubuntu服务器code-server进行代码开发?
文章目录 1.ubuntu本地安装code-server2. 安装cpolar内网穿透3. 创建隧道映射本地端口4. 安卓平板测试访问5.固定域名公网地址6.结语 1.ubuntu本地安装code-server 准备一台虚拟机,Ubuntu或者centos都可以,这里以VMwhere ubuntu系统为例 下载code serve…...

SAP Smartforms打印报错Error in spool C call : spool overflow
处理方式: SAP打印时提示: Error in spool C call : spool overflow (假脱机请求溢出,通俗一点打印池已满) 解决办法: SE38 首先运行程序RSPO1041 再运行RSPO1043,话不多说上图。...

SQL 中的运算符与别名:使用示例和语法详解
SQL中的IN运算符 IN运算符允许您在WHERE子句中指定多个值,它是多个OR条件的简写。 示例:获取您自己的SQL Server 返回所有来自’Germany’、France’或’UK’的客户: SELECT * FROM Customers WHERE Country IN (Germany, France, UK);语…...

3.2 CPU的自动化
CPU的自动化 改造1-使用2进制导线改造2根据整体流程开始改造指令分析指令MOV_A的开关2进制表格手动时钟gif自动时钟gif 根据之前的CPU内部结构改造,制造一个cpu控制单元 改造一 之前的CPU全由手动开关自己控制,极度繁琐,而开关能跟二进制一一对应, 开:1, 关:0图1是之前的, …...

深入理解@Resource与@Autowired:用法与区别解析
Resource: Resource 是Java EE提供的注解,也可以在Spring中使用。它是按照名称进行注入的,默认通过属性名(通常是类名的小驼峰命名方式)或者name属性来匹配。如果找不到符合名称的bean,则会抛出异常。在使…...

高级驾驶辅助系统 (ADAS)介绍
随着汽车技术持续快速发展,推动更安全、更智能、更高效的驾驶体验一直是汽车创新的前沿。高级驾驶辅助系统( ADAS ) 是这场技术革命的关键参与者,是 指集成到现代车辆中的一组技术和功能,用于增强驾驶员安全、改善驾驶体验并协助完成各种驾驶任务。它使用传感器、摄像头、雷…...
2 使用React构造前端应用
文章目录 简单了解React和Node搭建开发环境React框架JavaScript客户端ChallengeComponent组件的主要结构渲染与应用程序集成 第一次运行前端调试将CORS配置添加到Spring Boot应用使用应用程序部署React应用程序小结 前端代码可从这里下载: 前端示例 后端使用这里介…...
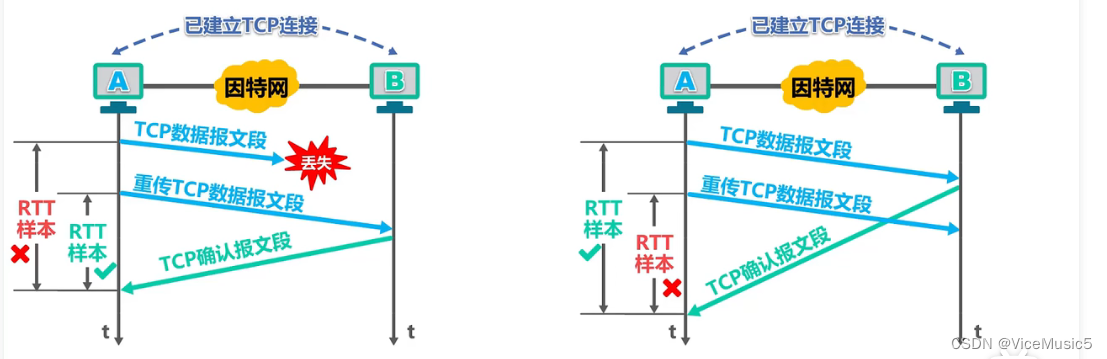
[计算机网络]运输层概述
虽然我自己也不知道写在前面和前言有什么区别..... 这个系列其实是针对<深入浅出计算机网络>的简单总结,加入了一点个人的理解和浅薄见识,如果您有一些更好的意见和见解,欢迎随时协助我改正,感激不尽啦. 最近心态平和了不少, 和过去也完全做了个割舍吧,既然痛苦和压力的…...
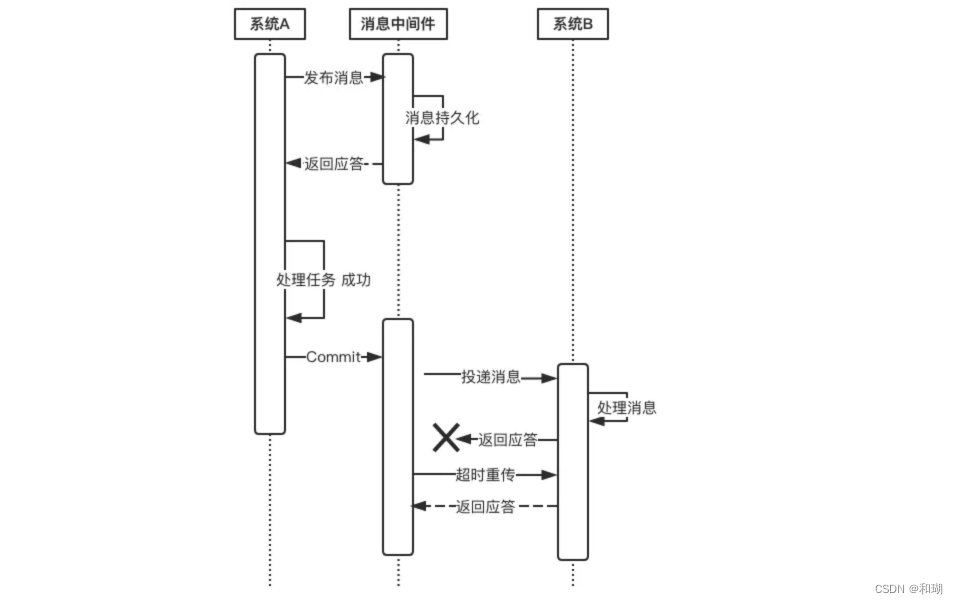
【分布式】分布式事务及其解决方案
目录 一、分布式事务二、分布式事务的解决方案1. 全局事务(1)DTP模型(2) 两阶段提交协议(2PC)原理二阶段提交的缺点 (3)三阶段提交协议(3PC)原理 2. 基于可靠…...

芯片行业为什么还不能把研发全托付给Agent
芯片行业有一个词叫"良率",指的是生产出来的芯片中符合规格的比例。现在AI研发流程里,有一个类似的问题我觉得可以叫做AI流程良率:Agent自动化执行一个完整流程,最终得到符合预期结果的概率是多少?一个Agent…...

手机拍照忽明忽暗?一文拆解ISP里AE震荡和Flicker的幕后元凶与调试技巧
手机拍照忽明忽暗?深度解析ISP中AE震荡与Flicker的成因与优化策略 你是否遇到过这样的场景:用手机拍摄室内灯光下的文档时,画面突然出现明暗交替的条纹,或是视频录制中亮度频繁跳动?这些现象背后,是图像信…...

MelonLoader终极指南:Unity游戏模组加载器快速上手教程
MelonLoader终极指南:Unity游戏模组加载器快速上手教程 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 核心关键词&…...
)
航顺HK32F030MF4P6实战:SWD引脚复用成普通IO或ADC的完整配置流程(附代码)
航顺HK32F030MF4P6开发实战:SWD引脚功能复用全解析与代码实现 在嵌入式开发中,IO资源紧张是工程师们经常面临的挑战。当项目需求超出芯片默认提供的GPIO数量时,如何合理复用特殊功能引脚就成为了解决问题的关键。航顺HK32F030MF4P6作为一款性…...

QMCDump:QQ音乐加密文件转换的终极免费解决方案
QMCDump:QQ音乐加密文件转换的终极免费解决方案 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾经遇…...

Hunyuan-MT-7B翻译模型在医疗系统中的应用:病历多语言翻译实战
Hunyuan-MT-7B翻译模型在医疗系统中的应用:病历多语言翻译实战 1. 医疗翻译的痛点与解决方案 在跨国医疗协作和少数民族地区医疗服务中,语言障碍一直是影响诊疗效率的关键因素。某三甲医院曾统计,因病历翻译不准确导致的误诊率高达3.7%&…...

08 论火箭回收的逆向思维落地方法 风险篇:全维度风险预判、分级防控与应急兜底方案
论火箭回收的逆向思维落地方法 风险篇:全维度风险预判、分级防控与应急兜底方案(总12篇第8篇) 摘要 本文承接第七篇混沌变量管控体系,结合火箭回收三级逆向拆解节点与分系统技术指标,对火箭回收全流程技术风险、工程风…...

WSL Ubuntu 24.04 GPU 加速环境完整安装指南
WSL Ubuntu 24.04 GPU 加速环境完整安装指南 环境版本总览 软件版本说明Ubuntu24.04.4 LTSWSL2Python3.12.3系统自带NVIDIA 驱动595.79Windows 主机驱动nvidia-utils590.48.01WSL 内 nvidia-smi 工具CUDA Toolkit13.2.78 12.9.86双版本共存(可选)cuDN…...

揭秘GitHub Copilot Enterprise级代码合并:2026奇点大会首发的DiffGPT引擎如何将PR审核效率提升417%?
第一章:2026奇点智能技术大会:AI代码合并 2026奇点智能技术大会(https://ml-summit.org) 在2026奇点智能技术大会上,“AI代码合并”成为核心议题之一,聚焦于大语言模型驱动的跨仓库、多分支、语义感知型Pull Request自动化处理。…...
