深度学习之自监督模型汇总
1.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
paper:https://arxiv.org/pdf/1810.04805v2.pdf
code:GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
Abstract:我们引入了一种名为 BERT 的新语言表征模型,BERT 是双向编码器表征(Bidirectional Encoder Representations from Transformers)的缩写。与最近的语言表征模型(Peters 等人,2018a;Radford 等人,2018)不同,BERT 的设计是通过在所有层中对左右上下文进行联合调节,从未标明的文本中预训练深度双向表征。因此,预训练的 BERT 模型只需增加一个输出层即可进行微调,从而为问题解答和语言推理等多种任务创建最先进的模型,而无需对特定任务的架构进行大量修改。BERT 概念简单,经验强大。它在 11 项自然语言处理任务上取得了最先进的新成果,包括将 GLUE 分数提高到 80.5%(绝对提高 7.7%),MultiNLI 准确率提高到 86.7%(绝对提高 4.6%),SQuAD v1.1 问题解答测试 F1 提高到 93.2(绝对提高 1.5%),SQuAD v2.0 测试 F1 提高到 83.1(绝对提高 5.1%)。
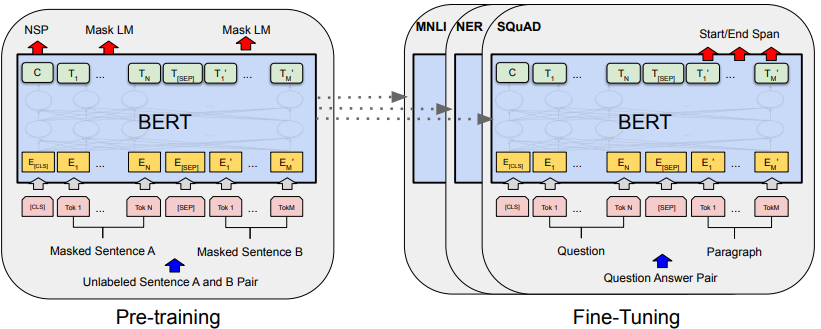
2.ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
paper:https://arxiv.org/pdf/1909.11942v6.pdf
code:GitHub - google-research/albert: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Abstract:在对自然语言表征进行预训练时,增加模型大小往往会提高下游任务的性能。然而,由于 GPU/TPU 内存的限制和训练时间的延长,在某些情况下进一步增加模型变得更加困难。为了解决这些问题,我们提出了两种参数缩减技术,以降低内存消耗并提高 BERT 的训练速度。全面的经验证据表明,与原始 BERT 相比,我们提出的方法所建立的模型扩展性更好。我们还使用了一种自监督损失,该损失侧重于对句子间的连贯性进行建模,并表明它始终有助于多句子输入的下游任务。因此,我们的最佳模型在 GLUE、RACE 和 SQuAD 基准测试中取得了新的一流成绩,同时与 BERT-large 相比参数更少。
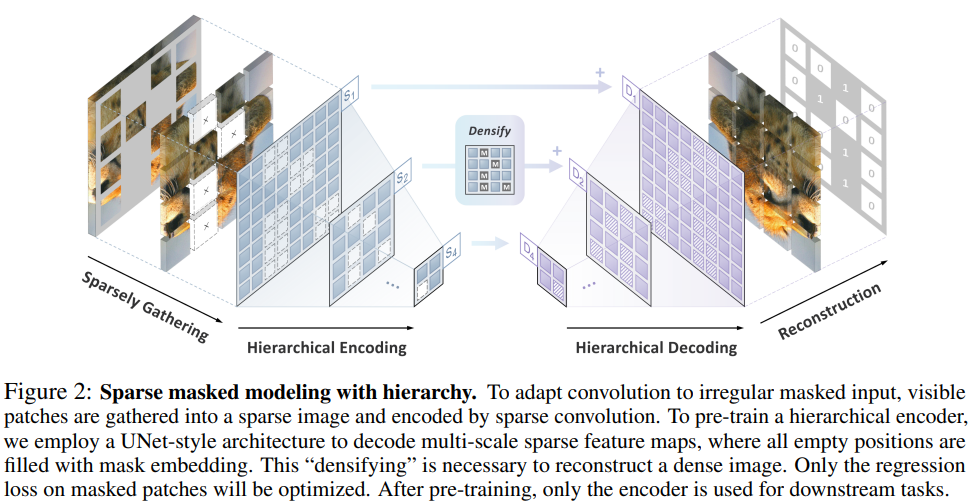
3.Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
paper:https://arxiv.org/pdf/2301.03580v2.pdf
code:https://github.com/keyu-tian/SparK
Abstract:我们发现并克服了将 BERT 式预训练或遮蔽图像建模成功推广到卷积网络(convnets)的两个关键障碍:(i) 卷积操作无法处理不规则、随机遮蔽的输入图像;(ii) BERT 预训练的单尺度性质与卷积网络的层次结构不一致。针对(i),我们将未屏蔽像素视为三维点云的稀疏体素,并使用稀疏卷积进行编码。这是首次将稀疏卷积用于二维屏蔽建模。对于 (ii),我们开发了一种分层解码器,用于从多尺度编码特征重建图像。我们的方法被称为稀疏遮蔽建模(SparK),具有通用性:它可以直接用于任何卷积模型,无需对骨干进行修改。我们在经典模型(ResNet)和现代模型(ConvNeXt)上对其进行了验证:在三个下游任务上,它都以同样大的优势(约+1.0%)超越了最先进的对比学习和基于变换器的掩蔽建模。在物体检测和实例分割方面的改进更为显著(高达 +3.5%),验证了所学特征的强大可转移性。此外,我们还发现了其良好的扩展行为,在更大的网络中观察到了更多的收益。所有这些证据都揭示了在卷积网络上进行生成预训练的美好前景。

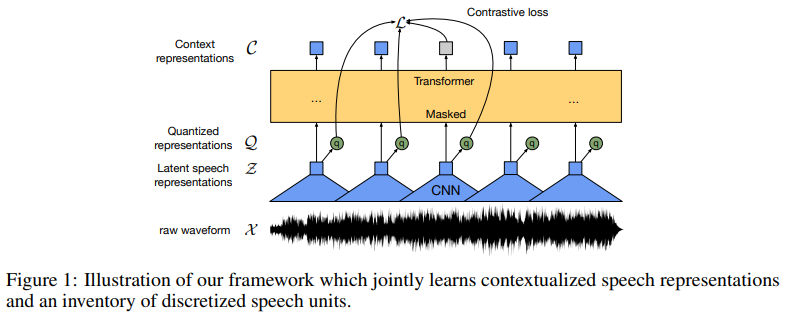
4.wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
paper:https://arxiv.org/pdf/2006.11477v3.pdf
code:https://github.com/facebookresearch/fairseq
Abstract:我们首次证明,仅从语音音频中学习强大的表征,然后对转录语音进行微调,就能超越最好的半监督方法,而且概念上更简单。wav2vec 2.0 在潜在空间中屏蔽了语音输入,并解决了联合学习的潜在表征量化所定义的对比任务。使用 Librispeech 的所有标注数据进行的实验在干净/其他测试集上实现了 1.8/3.3 的 WER。当标注数据量降低到一小时时,wav2vec 2.0 在 100 小时子集上的表现优于之前的技术水平,而使用的标注数据量则减少了 100 倍。仅使用十分钟的标注数据并在 53k 小时的未标注数据上进行预训练,WER 仍然达到了 4.8/8.2。这证明了使用有限的标注数据进行语音识别的可行性。
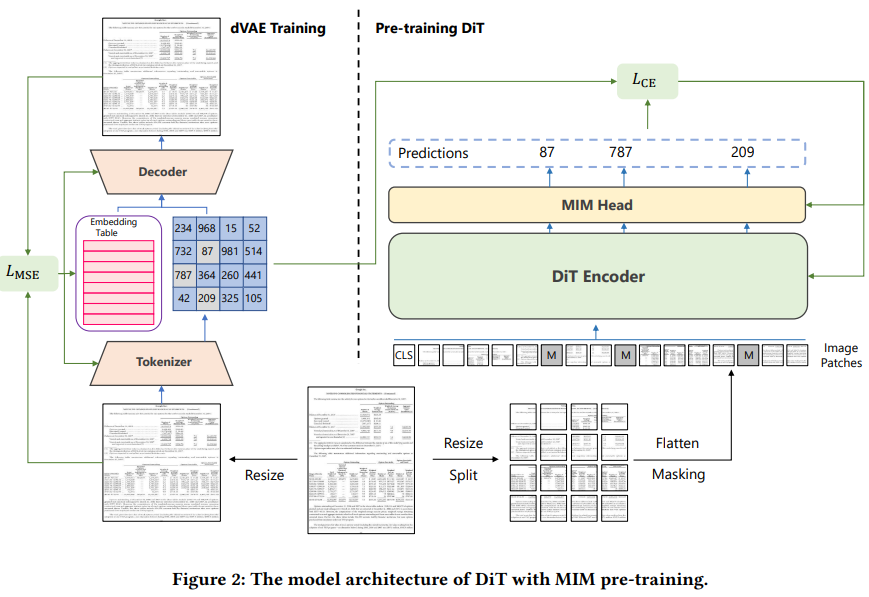
5.DiT: Self-supervised Pre-training for Document Image Transformer
paper:https://arxiv.org/pdf/2203.02378v3.pdf
code:https://github.com/microsoft/unilm/tree/master/dit
Abstract:最近,图像变换器在自然图像理解方面取得了重大进展,无论是使用监督式(ViT、DeiT 等)还是自监督式(BEiT、MAE 等)预训练技术。在本文中,我们提出了一种自监督预训练的文档图像转换器模型--DiT,它使用大规模无标记文本图像来完成文档人工智能任务。由于缺乏人类标注的文档图像,因此不存在有监督的对应模型,这对文档人工智能任务至关重要。我们利用 DiT 作为各种基于视觉的文档人工智能任务的骨干网络,包括文档图像分类、文档布局分析、表格检测以及用于 OCR 的文本检测。实验结果表明,自监督预训练的 DiT 模型在这些下游任务中取得了新的一流结果,例如文档图像分类(91.11 → 92.69)、文档布局分析(91.0 → 94.9)、表格检测(94.23 → 96.55)和 OCR 文本检测(93.07→ 94.29)。
6.Contextualized Spatio-Temporal Contrastive Learning with Self-Supervision
paper:https://arxiv.org/pdf/2112.05181v2.pdf
code:https://github.com/tensorflow/models/
Abstract:现代自监督学习算法通常会在不同视图之间强制保持实例表示。虽然这种算法对学习整体图像和视频表征非常有效,但对于学习视频中的时空细粒度特征来说,这种目标就变得不理想了,因为在视频中,场景和实例会随着空间和时间的变化而变化。在本文中,我们提出了上下文时空对比学习(Contextualized Spatio-Temporal Contrastive Learning,ConST-CL),通过自我监督有效地学习时空细粒度视频表征。我们首先设计了一个基于区域的借口任务,要求模型在上下文特征的引导下将实例表示从一个视图转换到另一个视图。此外,我们还引入了一种简单的网络设计,成功地协调了整体表征和局部表征的同步学习过程。我们在各种下游任务中对所学表征进行了评估,结果表明 ConST-CL 在 6 个数据集上取得了具有竞争力的结果,包括 Kinetics、UCF、HMDB、AVAKinetics、AVA 和 OTB。
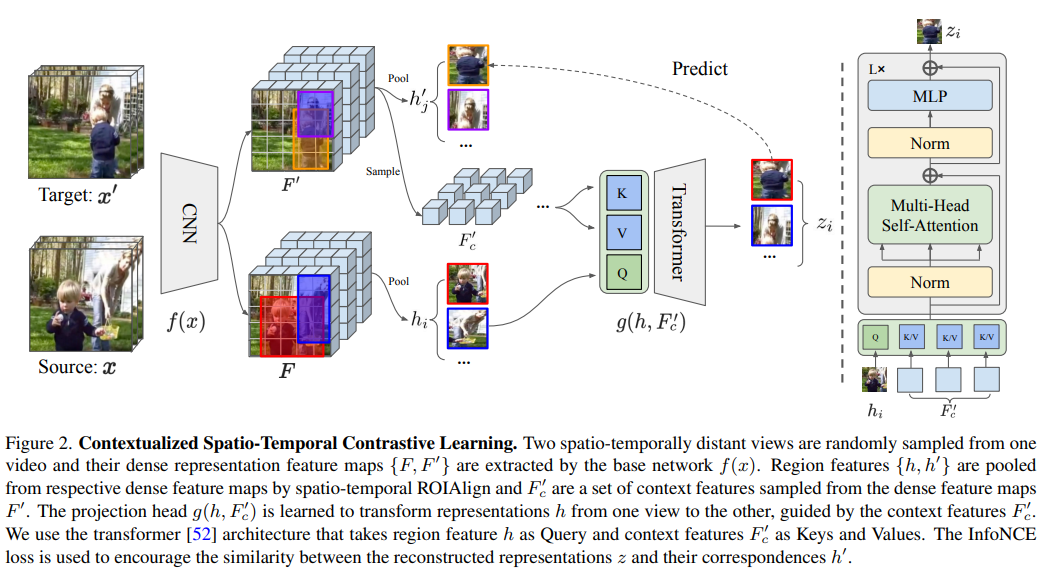
7.Efficient Visual Pretraining with Contrastive Detection
paper:https://arxiv.org/pdf/2103.10957v2.pdf
code:https://github.com/google-deepmind/detcon
Abstract:自我监督预训练已被证明能为迁移学习提供强大的表征。然而,这些性能的提高需要付出巨大的计算成本,最先进的方法所需的计算量要比监督预训练多出一个数量级。我们通过引入一种新的自我监督目标--对比检测--来解决这一计算瓶颈问题,该目标要求表征识别不同增强的对象级特征。这一目标能从每幅图像中提取丰富的学习信号,从而在各种下游任务中实现最先进的转移准确性,同时所需的预训练时间也减少了 10 倍。特别是,我们最强的 ImageNet 预训练模型与 SEER(迄今为止最大的自监督系统之一)的表现不相上下,而后者使用的预训练数据要多 1000 倍。最后,我们的目标是无缝处理 COCO 等更复杂图像的预训练,缩小从 COCO 到 PASCAL 的监督迁移学习的差距。

8.DetCo: Unsupervised Contrastive Learning for Object Detection
paper:https://arxiv.org/pdf/2102.04803v2.pdf
code:https://github.com/xieenze/DetCo
Abstract:我们介绍的 DetCo 是一种简单而有效的物体检测自监督方法。最近,人们设计了一些用于物体检测的无监督预训练方法,但这些方法通常在图像分类方面存在缺陷,或者恰恰相反。与它们不同的是,DetCo 能够很好地转移下游实例级密集预测任务,同时保持有竞争力的图像级分类精度。其优势来自于:(1)对中间表征的多级监督;(2)全局图像和局部斑块之间的对比学习。这两种设计有助于在特征金字塔的每个层次上对全局和局部进行辨别和一致的表征,从而同时改进检测和分类。
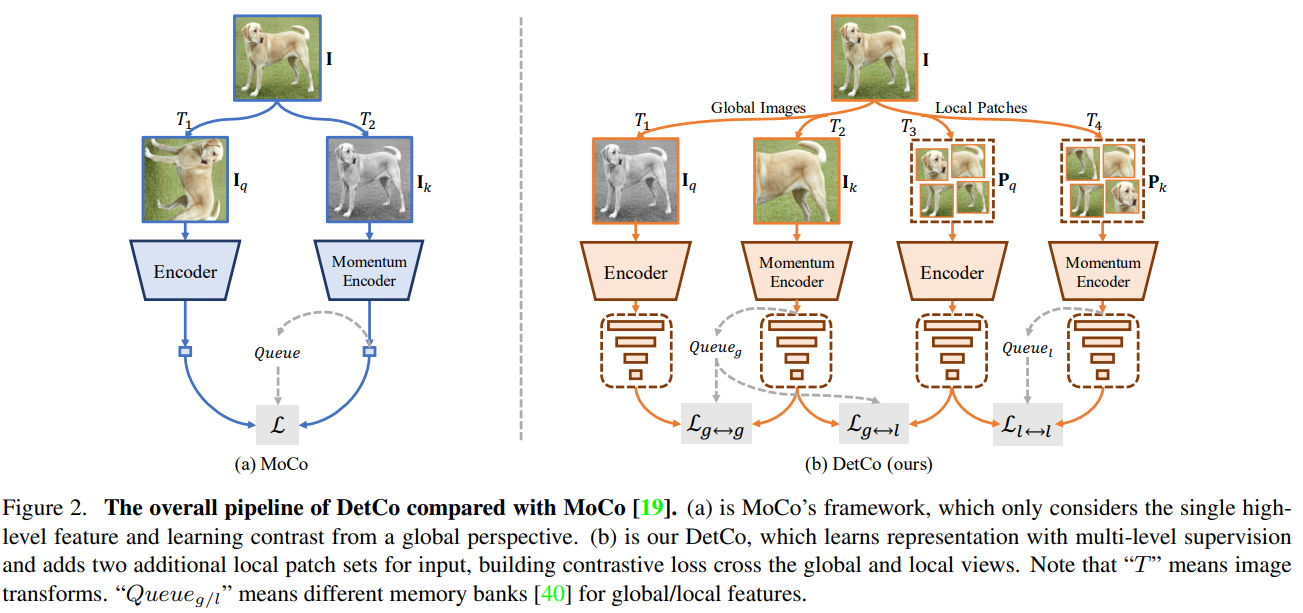
9.Self-Supervised Learning with Swin Transformers
paper:https://arxiv.org/pdf/2105.04553.pdf
code:https://github.com/SwinTransformer/Transformer-SSL
Abstract:在计算机视觉领域,我们正在见证从 CNN 到 Transformers 的建模转变。在这项工作中,我们提出了一种名为 MoBY 的自监督学习方法,其骨干架构是视觉变形器。这种方法基本上没有新的发明,它由 MoCo v2 和 BYOL 组合而成,并经过调整,在 ImageNet-1K 线性评估中达到了相当高的准确率: 使用 DeiT-S 和 Swin-T 进行 300 次训练后,前 1 级准确率分别为 72.8% 和 75.0%。与采用 DeiT 作为骨干的 MoCo v3 和 DINO 相比,其性能略胜一筹,但使用的技巧要少得多。更重要的是,通用的 Swin Transformer 骨干使我们还能在物体检测和语义分割等下游任务中对所学表示进行评估,这与最近基于 ViT/DeiT 的一些方法形成了鲜明对比,这些方法只在 ImageNet-1K 上报告了线性评估结果,原因是 ViT/DeiT 并不适合这些密集预测任务。我们希望我们的结果能促进对专为 Transformer 架构设计的自监督学习方法进行更全面的评估。


10.UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
paper:https://arxiv.org/pdf/2011.09094.pdf
code:https://github.com/dddzg/up-detr
Abstract:通过变压器编码器-解码器架构,用于物体检测的 DETR(DECTION TRANSFORMER)与 Faster R-CNN 相比,达到了具有竞争力的性能。然而,使用从头变压器进行训练的 DETR 需要大规模的训练数据,即使在 COCO 数据集上也需要极长的训练时间。受自然语言处理中预训练变换器取得巨大成功的启发,我们提出了一个新颖的前置任务,名为 "无监督预训练 DETR(UP-DETR)中的随机查询补丁检测"。具体来说,我们从给定图像中随机裁剪补丁,然后将其作为查询输入解码器。模型经过预训练,可以从输入图像中检测出这些查询补丁。在预训练过程中,我们要解决两个关键问题:多任务学习和多查询定位。(1) 为了在借口任务中权衡分类和定位偏好,我们发现冻结 CNN 骨干是预训练变换器成功的前提。(2) 为了执行多查询定位,我们开发了带有注意力掩码的多查询补丁检测的 UP-DETR。此外,UP-DETR 还为微调对象检测和单次检测任务提供了统一的视角。在我们的实验中,UP-DETR 显著提高了 DETR 的性能,在物体检测、单次检测和全景分割方面收敛更快,平均精度更高。

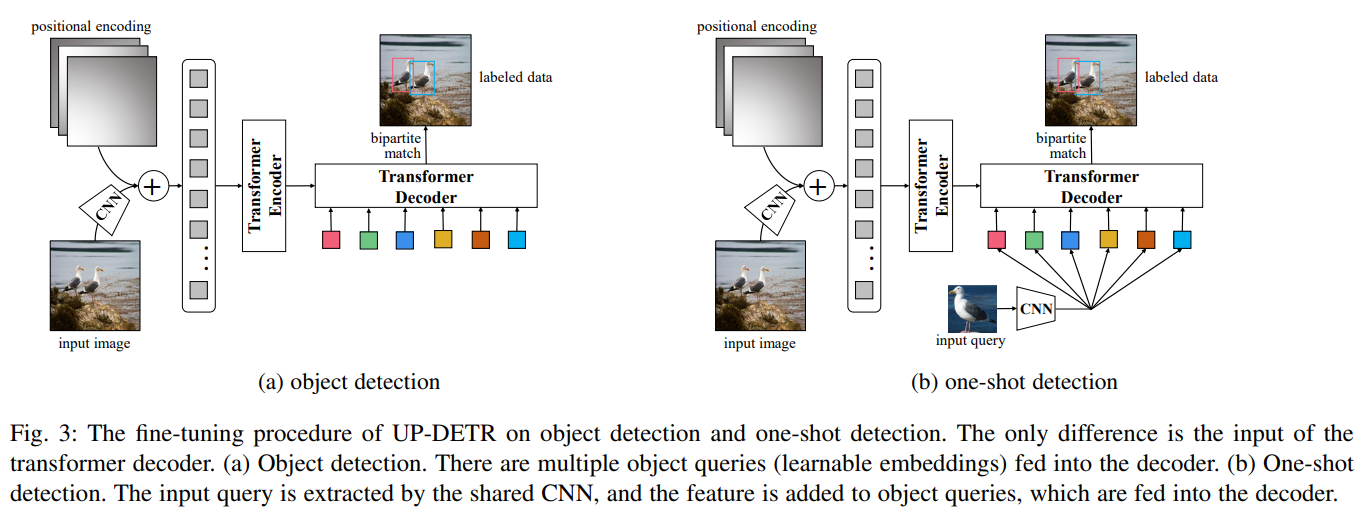
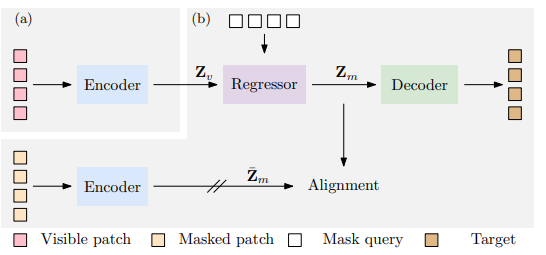
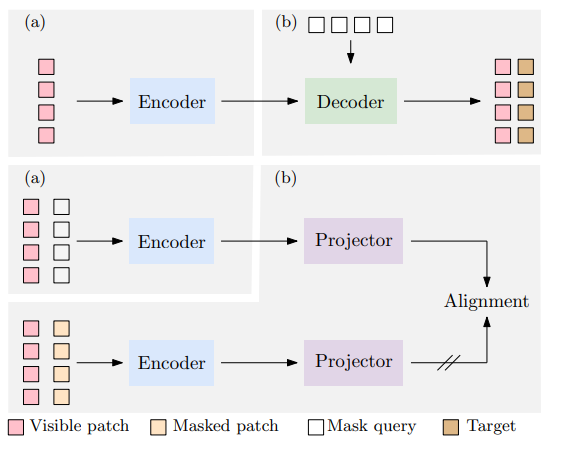
11.Context Autoencoder for Self-Supervised Representation Learning
paper:https://arxiv.org/pdf/2202.03026v3.pdf
code:https://github.com/dddzg/up-detr
Abstract:我们提出了一种用于自我监督表征预训练的新型掩膜图像建模(MIM)方法--上下文自动编码器(CAE)。我们通过对编码表征空间进行预测来对编码器进行预训练。预训练任务包括两项:掩膜表征预测--预测掩膜图像块的表征,以及掩膜图像块重建--重建掩膜图像块。该网络是一个编码器-调节器-解码器架构:编码器将可见图像块作为输入;调节器利用可见图像块的表征以及可见图像块和掩膜图像块的位置,预测掩膜图像块的表征,预计这些表征将与编码器计算出的表征保持一致;解码器根据预测的编码表征重建掩膜图像块。CAE 设计鼓励将学习编码器(表征)与完成相关任务(即掩膜表征预测和掩膜图像块重建任务)分离开来,在编码表征空间进行预测从经验上显示了对表征学习的益处。我们通过在下游任务(语义分割、对象检测和实例分割以及分类)中出色的转移性能证明了 CAE 的有效性。
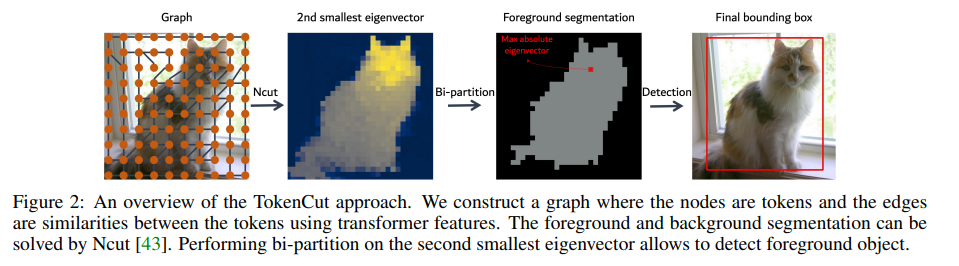
12.SELF-SUPERVISED TRANSFORMERS FOR UNSUPERVISED OBJECT DISCOVERY USING NORMALIZED CUT
paper:https://arxiv.org/pdf/2202.11539v2.pdf
code:https://github.com/YangtaoWANG95/TokenCut
Abstract:事实证明,利用自失调损失(DINO)进行自我监督训练的变形器能生成突出前景突出物体的注意力图。在本文中,我们展示了一种基于图的方法,利用自监督变换器特征从图像中发现物体。视觉标记被视为加权图中的节点,其边缘代表基于标记相似度的连接性得分。然后,可以使用归一化图切将前景物体分割为自相似区域。我们使用带广义特征分解的光谱聚类来解决图切割问题,结果表明,第二小特征向量提供了切割解决方案,因为其绝对值表示标记属于前景物体的可能性。尽管这种方法非常简单,但却大大提高了无监督对象发现的性能:在 VOC07、VOC12 和 COCO20K 上,我们比最近最先进的 LOST 分别提高了 6.9%、8.1% 和 8.1%。通过增加第二阶段的类无关检测器(CAD),性能还能进一步提高。我们提出的方法可以很容易地扩展到无监督的突出检测和弱监督的物体检测。在无监督的显著性检测方面,我们在 ECSSD、DUTS、DUT-OMRON 上的 IoU 与最先进技术相比分别提高了 4.9%、5.2% 和 12.9%。在弱监督对象检测方面,我们在 CUB 和 ImageNet 上取得了具有竞争力的性能。
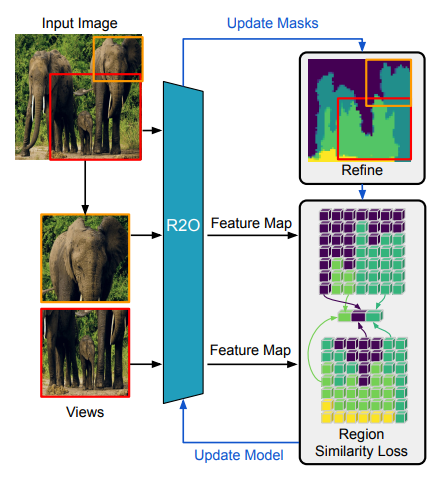
13.Refine and Represent: Region-to-Object Representation Learning
paper:https://arxiv.org/pdf/2208.11821v2.pdf
code:https://github.com/kkallidromitis/r2o
Abstract:最近,以物体为中心的自监督学习方法在物体检测和分割等密集预测任务中取得了最先进的成果。然而,以物体为中心的预训练方法依赖于固定的、现成的分割启发式方法来识别图像中的物体。在本文中,我们提出了区域到对象表征学习(R2O),它在预测分割掩膜和使用这些掩膜预训练编码网络之间摇摆不定。R2O 通过聚类编码特征来确定分割掩膜。然后,R2O 通过区域到区域的相似性学习对编码网络进行预训练,在这种学习过程中,编码网络会采用图像的不同视图,并将分割区域映射到相似的编码特征。R2O 采用区域到对象的预训练课程,鼓励预测的分割掩膜在早期输出大量区域,并在整个训练过程中逐渐减少区域,正如我们所展示的,这相当于区域到区域,然后是对象到对象的预训练。使用 R2O 学习到的表征可为物体检测、实例分割和语义分割带来最先进的传输性能。此外,在加州理工学院-加州大学伯克利分校 Birds 200-2011 数据集上,R2O ImageNet 预训练模型在无监督对象分割方面超越了最先进的水平,而无需进一步训练。
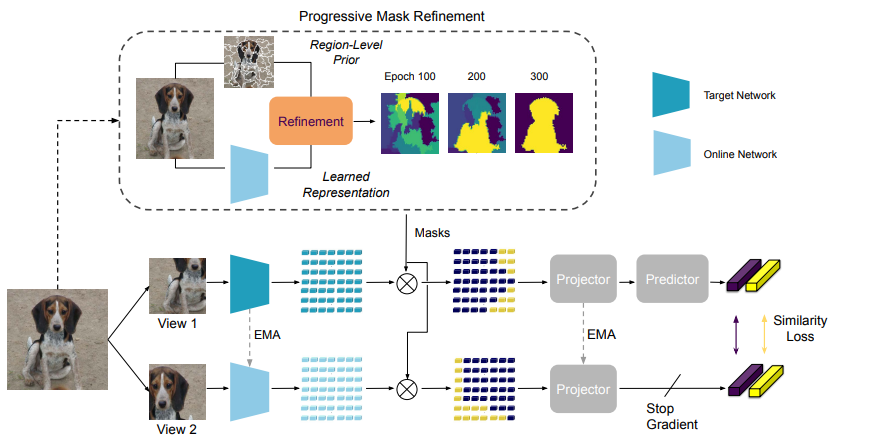
14.Semantic-aware Dense Representation Learning for Remote Sensing Image Change Detection
paper:https://arxiv.org/pdf/2205.13769v2.pdf
code:https://github.com/justchenhao/SaDL_CD
Abstract:有监督的深度学习模型依赖于海量标注数据。遗憾的是,收集和注释包含所需变化的位时样本既耗时又耗力。在遥感(RS)变化检测(CD)中,来自预训练模型的迁移学习能有效缓解标签不足的问题。我们探索了在预训练过程中使用语义信息的方法。与学习图像到标签映射的传统监督预训练不同,我们将语义监督纳入了自监督学习(SSL)框架。通常情况下,多个感兴趣的对象(如建筑物)分布在未经整理的 RS 图像的不同位置。我们不通过全局池化处理图像级表征,而是在每像素嵌入上引入点级监督,以学习空间敏感特征,从而受益于下游密集 CD。为此,我们通过使用语义掩膜对视图之间的重叠区域进行类平衡采样来获得多个点。我们会学习一个嵌入空间,在这个空间中,背景点和前景点会被推开,而不同视图中空间对齐的点会被拉到一起。我们的直觉是,由此产生的不受无关变化(光照和不相关的土地覆盖)影响的语义判别表征可能有助于变化识别。我们收集了 RS 社区免费提供的大规模图像-掩膜对,用于预训练。在三个 CD 数据集上进行的广泛实验验证了我们方法的有效性。我们的方法明显优于 ImageNet 预训练、域内监督和几种 SSL 方法。经验结果表明,我们的预训练提高了 CD 模型的泛化和数据效率。值得注意的是,与使用 100% 数据的基线(随机初始化)相比,我们使用 20% 的训练数据就能获得具有竞争力的结果。
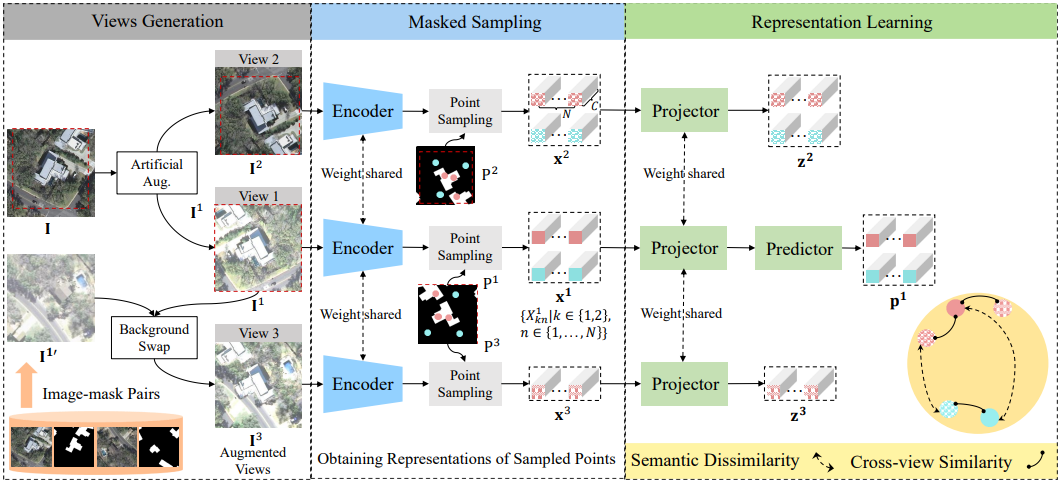
15.Semantic Segmentation of Remote Sensing Images With Self-Supervised Multitask Representation Learning
paper:Semantic Segmentation of Remote Sensing Images With Self-Supervised Multitask Representation Learning | IEEE Journals & Magazine | IEEE Xplore
code:https://github.com/flyakon/SSLRemoteSensing
Abstract:现有的基于深度学习的遥感图像语义分割方法需要大规模的标注数据集。然而,分割数据集的标注往往过于耗时和昂贵。为了减轻数据标注的负担,最近出现了自监督表示学习方法。然而,语义分割方法需要同时学习高层和低层特征,但现有的大多数自监督表示学习方法通常只关注一个层次,这影响了遥感图像的语义分割性能。为了解决这个问题,我们提出了一种自监督多任务表征学习方法,以捕捉遥感图像的有效视觉表征。我们设计了三个不同的前置任务和一个三重连体网络来同时学习高层和低层图像特征。该网络可以在没有任何标注数据的情况下进行训练,训练后的模型可以通过注释分割数据集进行微调。我们在波茨坦、Vaihingen 数据集和云/雪检测数据集 Levir_CS 上进行了实验,以验证我们方法的有效性。实验结果表明,我们提出的方法能有效减少对标注数据集的需求,提高遥感语义分割的性能。与近年来最先进的自监督表示学习方法和常用的初始化方法(如随机初始化和 ImageNet 预训练)相比,我们提出的方法在大多数实验中都取得了最佳效果,尤其是在训练数据较少的情况下。在只有 10% 到 50% 标注数据的情况下,我们的方法可以达到与随机初始化相当的性能。

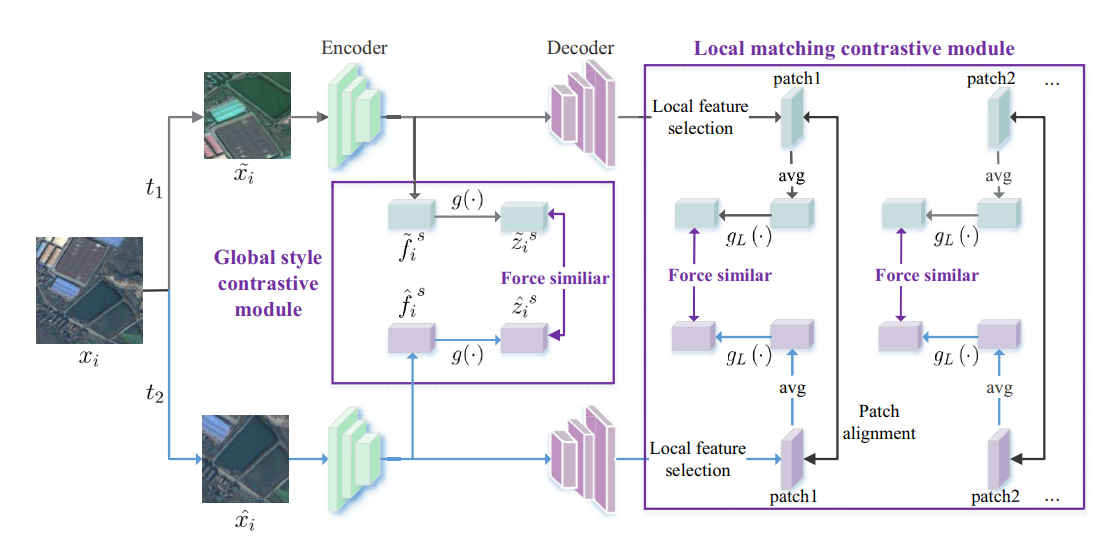
16.Global and Local Contrastive Self-Supervised Learning for Semantic Segmentation of HR Remote Sensing Images
paper:https://arxiv.org/pdf/2106.10605.pdf
code:https://github.com/GeoX-Lab/G-RSIM
Abstract:现有的基于深度学习的遥感图像语义分割方法需要大规模的标注数据集。然而,分割数据集的标注往往过于耗时和昂贵。为了减轻数据标注的负担,最近出现了自监督表示学习方法。然而,语义分割方法需要同时学习高层和低层特征,但现有的大多数自监督表示学习方法通常只关注一个层次,这影响了遥感图像的语义分割性能。为了解决这个问题,我们提出了一种自监督多任务表征学习方法,以捕捉遥感图像的有效视觉表征。我们设计了三个不同的前置任务和一个三重连体网络来同时学习高层和低层图像特征。该网络可以在没有任何标注数据的情况下进行训练,训练后的模型可以通过注释分割数据集进行微调。我们在波茨坦、Vaihingen 数据集和云/雪检测数据集 Levir_CS 上进行了实验,以验证我们方法的有效性。实验结果表明,我们提出的方法能有效减少对标注数据集的需求,提高遥感语义分割的性能。与近年来最先进的自监督表示学习方法和常用的初始化方法(如随机初始化和 ImageNet 预训练)相比,我们提出的方法在大多数实验中都取得了最佳效果,尤其是在训练数据较少的情况下。在只有 10% 到 50% 标注数据的情况下,我们的方法可以达到与随机初始化相当的性能。
相关文章:
深度学习之自监督模型汇总
1.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding paper:https://arxiv.org/pdf/1810.04805v2.pdf code:GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT Abstract:我们引入了一种名为 BE…...

竞赛 : 题目:基于深度学习的水果识别 设计 开题 技术
1 前言 Hi,大家好,这里是丹成学长,今天做一个 基于深度学习的水果识别demo 这是一个较为新颖的竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-senior/pos…...

oracle的debjob挂載及查詢
背景 有一個需求需要定時去執行一個produce,可以使用oracle的dbjob定時執行,相比較之前的vbs更加絲滑 --傳遞produce 開始的時間 頻率 declarea number;beginDBMS_JOB.SUBMIT(a,xx_warehouse_daliy_record_p;,to_date(202311230800,yyyymmddhh24mi),…...

Pycharm创建项目新环境,安装Pytorch
在python项目中,很多项目使用的各类包的版本是不一致的。所以我们可以对每个项目有专属于它的环境。所以这个文章就是教你如何创建新环境。 一、创建新环境 首先我们需要去官网下载conda。然后在Pycharm下面添加conda的可执行文件。 用conda创建新环境。 二、…...

assert断言
1.引入 assert.h 头⽂件定义了宏 assert() ,⽤于在运⾏时确保程序符合指定条件,如果不符合,就报错终⽌运⾏。这个宏常常被称为“断⾔”。 2.应用 assert(p ! NULL); 上⾯代码在程序运⾏到这⼀⾏语句时,验证变量 p 是否等于 …...
我们对凌鲨的一次重构
在10月我们对凌鲨进行了一次重构,把所有鸡肋的功能都删除了。 新版本界面 老版本界面 我们干掉的功能 移除沟通频道功能 沟通频道类似slack功能,用于团队沟通。由于国内有大量的沟通软件,比如企业微信,飞书,钉钉等。…...
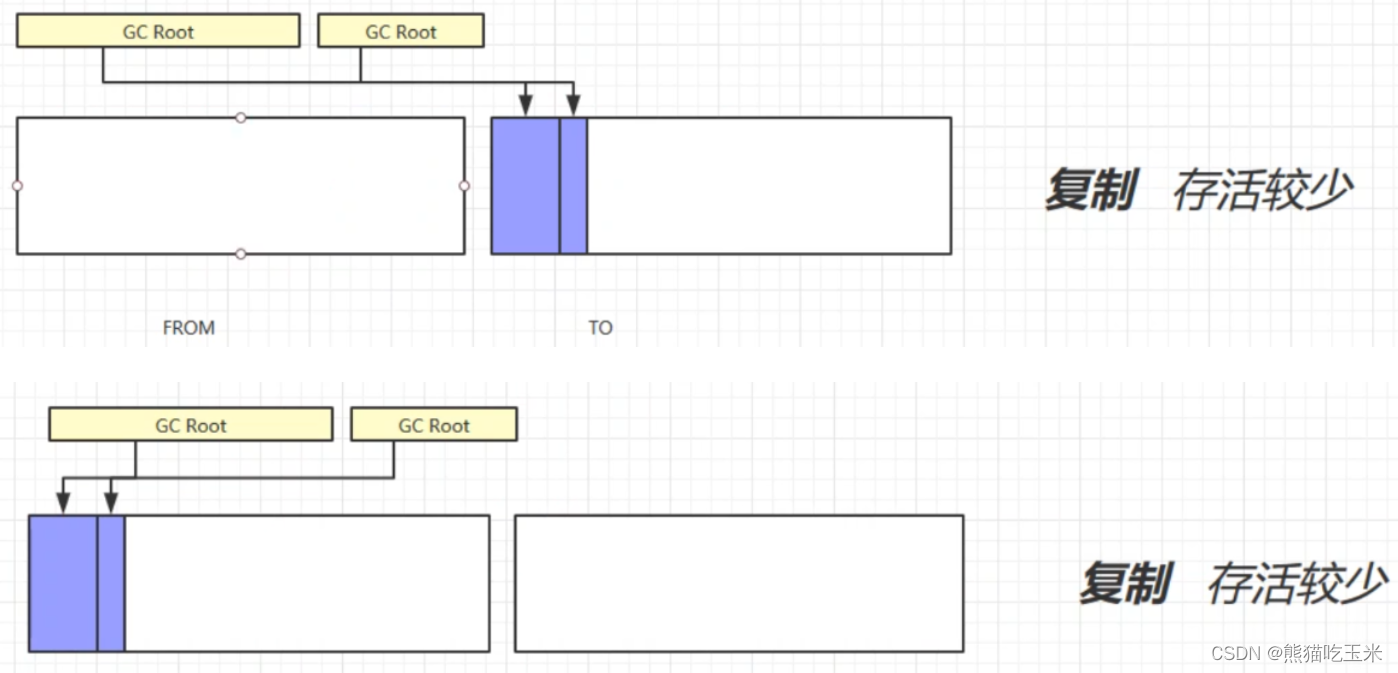
【JVM】一篇通关JVM垃圾回收
目录 1. 如何判断对象可以回收1-1. 引用计数法1-2. 可达性分析算法1-3. 四种引用强引用软引用弱引用虚引用终结器引用 2. 垃圾回收算法2-1. 标记清除2-2. 标记整理2-3. 复制2-4. 总结 3. 分代垃圾回收4. 垃圾回收器5. 垃圾回收调优 1. 如何判断对象可以回收 1-1. 引用计数法 …...

【小沐学写作】原型设计工具汇总(Axure RP)
文章目录 1、简介2、Axure RP2.1 工具简介2.2 工具特点2.2.1 互动事件2.2.2 条件逻辑2.2.4 工作表格2.2.5 多状态容器2.2.6 数据驱动接口2.2.7 自适应视图2.2.8 流程图 2.3 工具安装2.3.1 安装2.3.2 运行 2.4 使用费用2.5 工具体验2.5.1 登陆框制作 3、其他3.1 Figma3.2 Adobe …...
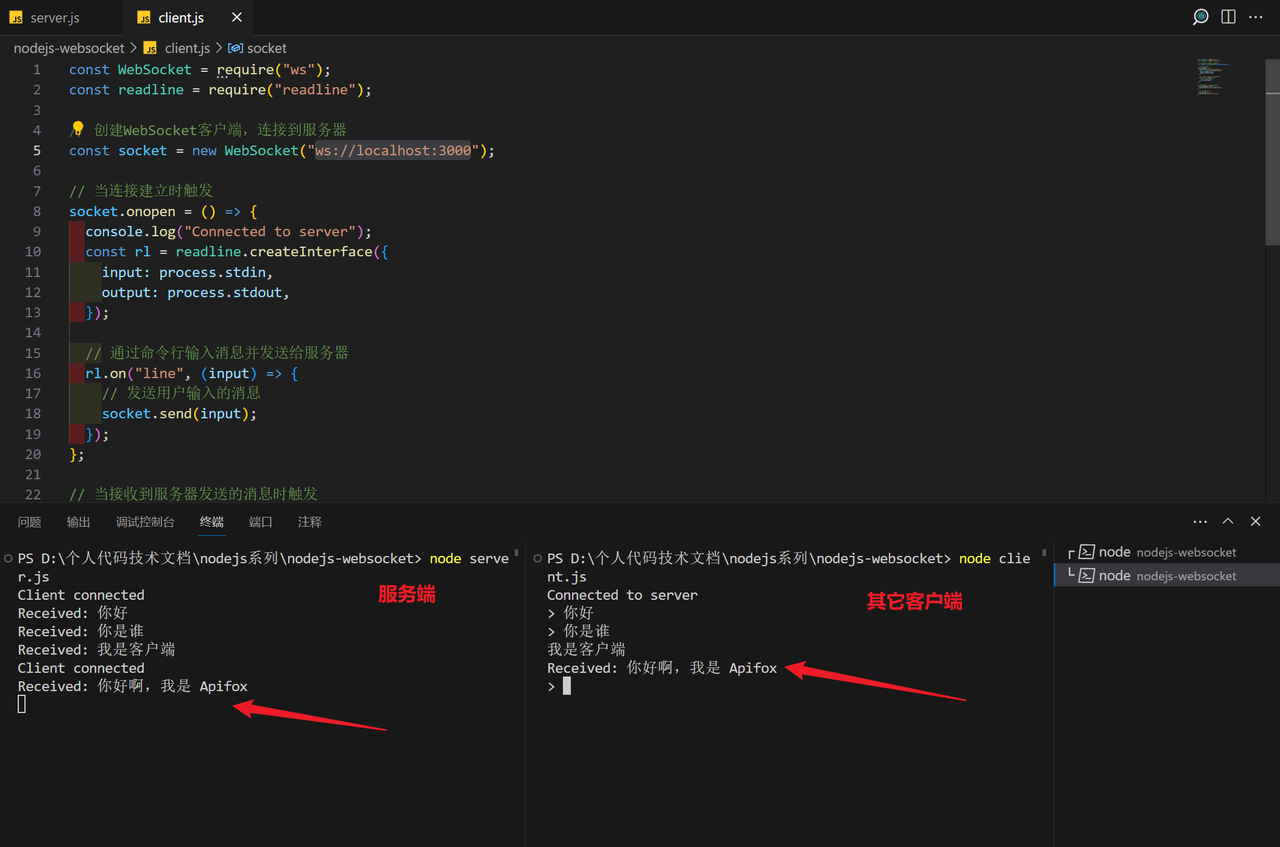
WebSocket 鉴权策略与技巧详解
WebSocket 作为实时通信的利器,越来越受到开发者的青睐。然而,为了确保通信的安全性和合法性,鉴权成为不可或缺的一环。本文将深入探讨 WebSocket 的鉴权机制,为你呈现一揽子的解决方案,确保你的 WebSocket 通信得心应…...

2022 年十大 JavaScript 框架
2022 年十大 Web 应用开发 JavaScript 框架。 React.js jQuery Express Angular Vue.js Angular.js Svelte Next.js Ember.js Meteor React.js React.js 于 2013 年由 Meta(Facebook 前身) 推出,是一款开源的、免费的 JavaScript 库。React.js 被用于开…...

Java中的线程池
目录 1、线程池的概念及其用途 2、Java中的线程池是如何创建和使用的 扩展:有哪些不同类型的线程池? 3、Java中线程池有哪些常见的应用场景? 4、线程池在Web应用中的使用情况 5、线程池如何管理多线程请求处理 1、线程池的概念及其用途…...
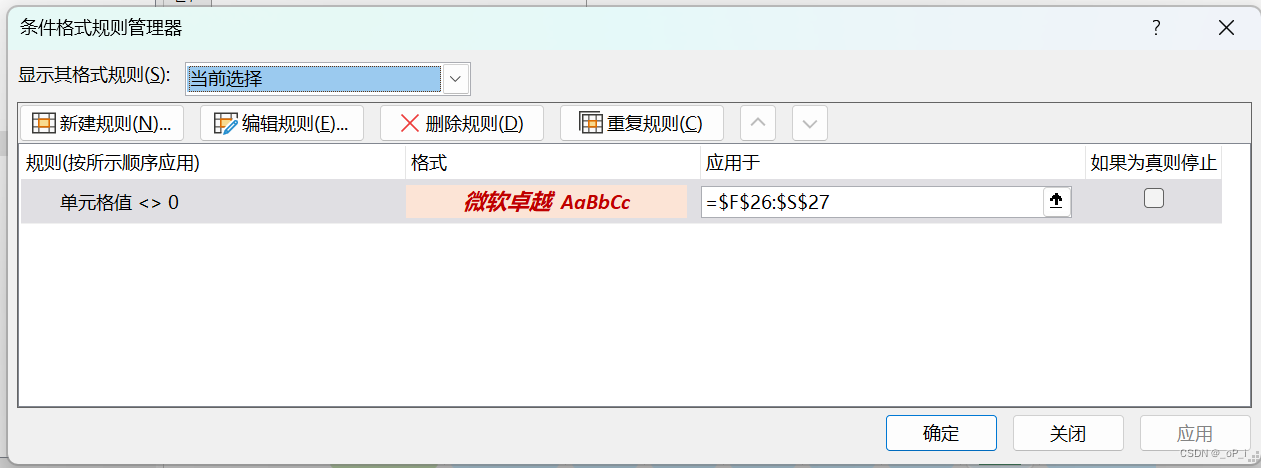
excel单元格加背景颜色不生效?
如果在 Excel 中设置单元格背景颜色而发现不生效,可能有几个原因。以下是一些常见的解决方法: 1. **单元格锁定:** 检查所在单元格是否被锁定。如果单元格被锁定,并且工作表被保护,你可能无法更改其背景颜色。在工作表…...

鸿蒙开发板——环境搭建(南派开发)
概述 为了帮大家理清楚鸿蒙开发的套路,我们从头再梳理一遍相关的脉络。并为大家总结一些重点性的内容。在介绍OpenHarmony特性前,需要大家先明确以下两个基本概念: 子系统 OpenHarmony整体遵从分层设计,从下向上依次为…...

【C++代码】链表
算法:搜索、查找、排序、双指针、回溯、分治、动态规划、贪心、位运算、数学等。 数据结构:数组、栈、队列、字符串、链表、树、图、堆、哈希表等。 数据结构是为实现对计算机数据有效使用的各种数据组织形式,服务于各类计算机操作。不同的…...

01、Tensorflow实现二元手写数字识别
01、Tensorflow实现二元手写数字识别(二分类问题) 开始学习机器学习啦,已经把吴恩达的课全部刷完了,现在开始熟悉一下复现代码。对这个手写数字实部比较感兴趣,作为入门的素材非常合适。 基于Tensorflow 2.10.0 1、…...
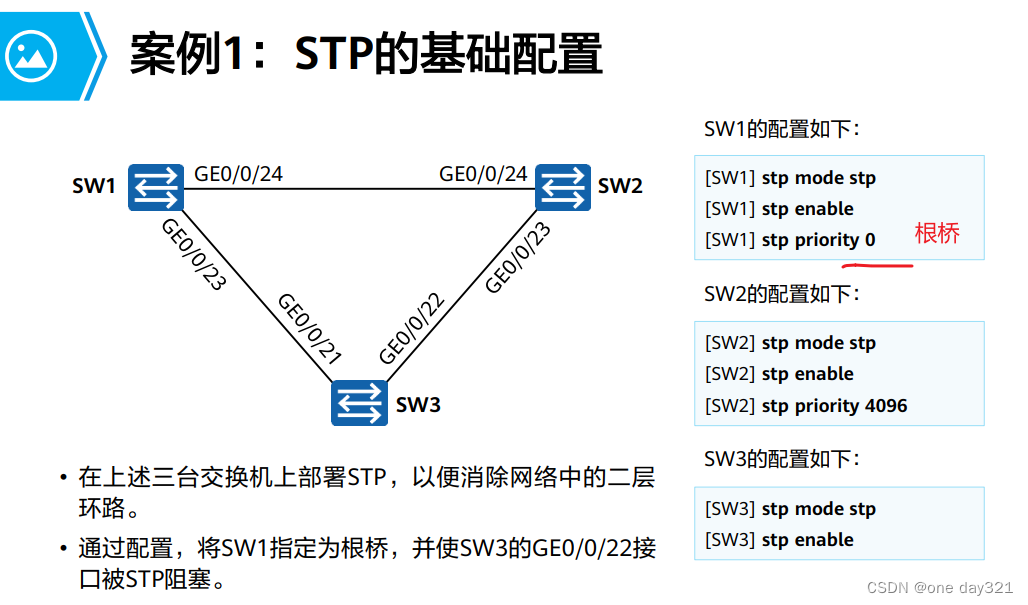
HCIA-Datacom跟官方路线学习第二部分
接着前面第六章,通过VLAN技术, 可以将物理的局域网划分成多个广播域, 实现同一VLAN内的网络设备可以直接进行二层通信, 不同VLAN内的设备不可以直接进行二层通信。 第七章 生成树 在以太网交换网络会使用冗余链路, 但…...

BIO、NIO和AIO的区别
一、基础知识: I/O 模型的简单理解: 1.BIO(Blocking I/O):同步阻塞,一个线程处理一个通道上的事件。 2.NIO(Non-blocking I/O):同步非阻塞,使用选择器&…...

makefile 学习(5)完整的makefile模板
参考自: (1)深度学习部署笔记(二): g, makefile语法,makefile自己的CUDA编程模板(2)https://zhuanlan.zhihu.com/p/396448133(3) 一个挺好的工程模板,(https://github.com/shouxieai/cpp-proj-template) 1. c 编译流…...

专业远程控制如何塑造安全体系?向日葵“全流程安全闭环”解析
安全是远程控制的重中之重,作为国民级远程控制品牌,向日葵远程控制就极为注重安全远控服务的塑造。近期向日葵发布了以安全和核心的新版“向日葵15”以及同步发布《贝锐向日葵远控安全标准白皮书》(下简称《白皮书》),…...

node.js解决输出中文乱码问题
个人简介 👨🏻💻个人主页:九黎aj 🏃🏻♂️幸福源自奋斗,平凡造就不凡 🌟如果文章对你有用,麻烦关注点赞收藏走一波,感谢支持! 🌱欢迎订阅我的…...
)
Elasticsearch 极速查询:通过ID精准检索文档(最全语法+流程图+避坑指南)
Elasticsearch 极速查询:通过ID精准检索文档(最全语法流程图避坑指南)一、前言二、根据ID检索文档:核心原理与流程图2.1 核心原理2.2 检索流程图2.3 核心优势三、根据ID检索文档:标准语法(必掌握࿰…...
)
农产品销售|基于springboot + vue农产品销售系统(源码+数据库+文档)
农产品销售系统 目录 基于springboot vue农产品销售系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue农产品销售系统 一、前言 博主介绍&#x…...

ARM Cache一致性实战指南:从理论到代码的深度解析
1. ARM Cache一致性的核心挑战 在ARM多核系统中,Cache一致性问题是每个底层开发者迟早要面对的"硬骨头"。想象一下这样的场景:CPU Core 0修改了共享内存中的数据,但Core 1读取到的却是旧值——这就是典型的Cache不一致问题。我在实…...

[嵌入式系统-257]:如何理解进程是任务资源分配的最小单位,线程是CPU调度的最小单位
要理解“进程是资源分配的最小单位,线程是CPU调度的最小单位”这句话,关键在于将程序的“资源所有权”和“执行权”分离开来看。我们可以通过一个生动的比喻来理解,然后深入其技术原理。🏢 一个生动的比喻:工厂与工人想…...

贝叶斯统计革命:Statistical Rethinking 2023如何改变你的数据分析思维
贝叶斯统计革命:Statistical Rethinking 2023如何改变你的数据分析思维 【免费下载链接】stat_rethinking_2023 Statistical Rethinking Course for Jan-Mar 2023 项目地址: https://gitcode.com/gh_mirrors/st/stat_rethinking_2023 Statistical Rethinking…...
)
别再傻傻分不清了!一文搞懂激光雷达里的‘零差’和‘外差’探测(附FMCW/ToF对比)
激光雷达核心技术解析:零差与外差探测的本质差异与应用场景 在自动驾驶和遥感测绘领域,激光雷达技术正经历着从机械式到固态、从间接测量到相干探测的演进。当我们拆解一台现代激光雷达设备时,会发现其核心测距原理主要分为两大技术路线&…...

用TLE5012磁编码器DIY一个高精度旋转测量模块:硬件连接与Arduino测试
用TLE5012磁编码器打造高精度旋转测量模块:从硬件连接到Arduino实战 磁编码器在工业自动化、机器人关节控制和DIY项目中扮演着关键角色,而英飞凌的TLE5012以其高精度和SPI接口的便利性成为创客们的热门选择。本文将带你从零开始,用Arduino和T…...

如何免费掌握AMD Ryzen处理器调试:SMUDebugTool完整入门指南
如何免费掌握AMD Ryzen处理器调试:SMUDebugTool完整入门指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...
避坑实录:从屏幕偏移到SPI配置详解)
STM32F103驱动1.44寸TFT屏(ST7735R)避坑实录:从屏幕偏移到SPI配置详解
STM32F103驱动1.44寸TFT屏(ST7735R)实战指南:从硬件连接到显示优化 刚拿到一块1.44寸TFT屏准备接入STM32F103时,很多开发者会面临一个尴尬局面——网上的参考代码能点亮屏幕,但显示效果总有些"不对劲"。要么…...

手把手教你用PyTorch从零搭建并调优MobileNetV2图像分类模型
1. 环境准备与项目初始化 第一次接触MobileNetV2和PyTorch时,我也被各种环境配置搞得头大。后来发现用Anaconda管理环境能省去80%的兼容性问题。这里分享我的标准配置流程: conda create -n mobilenetv2 python3.8 -y conda activate mobilenetv2安装PyT…...