01、Tensorflow实现二元手写数字识别
01、Tensorflow实现二元手写数字识别(二分类问题)
开始学习机器学习啦,已经把吴恩达的课全部刷完了,现在开始熟悉一下复现代码。对这个手写数字实部比较感兴趣,作为入门的素材非常合适。
基于Tensorflow 2.10.0
1、识别目标
识别手写仅仅是为了区分手写的0和1,所以实际上是一个二分类问题。
2、Tensorflow算法实现
STEP1:导入相关包
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import warnings
import logging
from sklearn.metrics import accuracy_score
import numpy as np:这是引入numpy库,并为其设置一个缩写np。Numpy是Python中用于大规模数值计算的库,它提供了多维数组对象及一系列操作这些数组的函数。
import tensorflow as tf:这是引入tensorflow库,并为其设置一个缩写tf。TensorFlow是一个开源的深度学习框架,它被广泛用于各种深度学习应用。
from keras.models import Sequential:这是从Keras库中引入Sequential模型。Keras是一个高级神经网络API,它可以运行在TensorFlow之上。Sequential模型是Keras中的线性堆栈模型,允许你简单地堆叠多个网络层。
from keras.layers import Dense:这是从Keras库中引入Dense层。Dense层是神经网络中的全连接层,每个输入节点与输出节点都是连接的。
from sklearn.model_selection import train_test_split:这是从scikit-learn库中引入train_test_split函数。这个函数用于将数据分割为训练集和测试集。
import matplotlib.pyplot as plt:这是引入matplotlib的pyplot模块,并为其设置一个缩写plt。Matplotlib是Python中的绘图库,而pyplot是其中的一个模块,用于绘制各种图形和图像。
import warnings:这是引入Python的标准警告库,它可以用来发出警告,或者过滤掉不需要的警告。
import logging:这是引入Python的标准日志库,用于记录日志信息,方便追踪和调试代码。
from sklearn.metrics import accuracy_score:这是从scikit-learn库中引入accuracy_score函数。这个函数用于计算分类准确率,常用于评估分类模型的性能。
STEP2:屏蔽无用警告并允许中文
logging.getLogger("tensorflow").setLevel(logging.ERROR)
tf.autograph.set_verbosity(0)
warnings.simplefilter(action='ignore', category=FutureWarning)
# 支持中文显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
logging.getLogger(“tensorflow”).setLevel(logging.ERROR):这行代码用于设置 TensorFlow 的日志级别为 ERROR。这意味着只有当 TensorFlow 中发生错误时,才会在日志中输出相关信息。较低级别的日志信息(如 WARNING、INFO、DEBUG)将被忽略。
tf.autograph.set_verbosity(0):这行代码用于设置 TensorFlow 的自动图形(Autograph)日志的冗长级别为 0。这意味着在将 Python 代码转换为 TensorFlow 图形代码时,将不会输出任何日志信息。这有助于减少日志噪音,使日志更加干净。
warnings.simplefilter(action=‘ignore’,category=FutureWarning):这行代码用于忽略所有 FutureWarning 类型的警告。在 Python中,当使用某些即将过时或未来版本中可能发生变化的特性时,通常会发出 FutureWarning。通过设置action=‘ignore’,代码将不会输出这类警告,使控制台输出更加干净。
plt.rcParams[‘font.sans-serif’]=[‘SimHei’]:这行代码用于设置 matplotlib 中的默认无衬线字体为 SimHei。SimHei 是一种常用于显示中文的字体,这样设置后,matplotlib 将在绘图时使用 SimHei 字体来显示中文,从而避免中文乱码问题。
plt.rcParams[‘axes.unicode_minus’]=False:这行代码用于解决 matplotlib
中负号显示异常的问题。默认情况下,matplotlib 可能无法正确显示负号,将其设置为 False 可以使用 ASCII字符作为负号,从而正常显示。
STEP3:导入并划分数据集
划分10%作为测试:
X, y = load_data()
print('The shape of X is: ' + str(X.shape))
print('The shape of y is: ' + str(y.shape))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
STEP4:模型构建与训练
# 构建模型,三层模型进行分类,第一层输入100个神经元...
model = Sequential([tf.keras.Input(shape=(400,)), #specify input size### START CODE HERE ###Dense(100, activation='sigmoid'),Dense(10, activation='sigmoid'),Dense(1, activation='sigmoid')### END CODE HERE ###], name = "my_model"
)
# 打印三层模型的参数
model.summary()
# 模型设定,学习率0.001,因为是分类,使用BinaryCrossentropy损失函数
model.compile(loss=tf.keras.losses.BinaryCrossentropy(),optimizer=tf.keras.optimizers.Adam(0.001),
)
# 开始训练,训练循环20
model.fit(X_train,y_train,epochs=20
)STEP5:结果可视化与打印准确度信息
原始的输入的数据集是400 * 1000的数组,共包含1000个手写数字的数据,其中400为20*20像素的图片,因此对每个400的数组进行reshape((20, 20))可以得到原始的图片进而绘图。
# 绘制测试集的预测结果,绘制64个
fig, axes = plt.subplots(8, 8, figsize=(8, 8))
fig.tight_layout(pad=0.1, rect=[0, 0.03, 1, 0.92]) # [left, bottom, right, top]
for i, ax in enumerate(axes.flat):# Select random indicesrandom_index = np.random.randint(X_test.shape[0])# Select rows corresponding to the random indices and# reshape the imageX_random_reshaped = X_test[random_index].reshape((20, 20)).T# Display the imageax.imshow(X_random_reshaped, cmap='gray')# Predict using the Neural Networkprediction = model.predict(X_test[random_index].reshape(1, 400))if prediction >= 0.5:yhat = 1else:yhat = 0# Display the label above the imageax.set_title(f"{y_test[random_index, 0]},{yhat}")ax.set_axis_off()
fig.suptitle("真实标签, 预测的标签", fontsize=16)
plt.show()# 给出预测的测试集误差
y_pred=model.predict(X_test)
print("测试数据集准确率为:", accuracy_score(y_test, np.round(y_pred)))
3、运行结果
按照最初的划分,数据集包含1000个数据,划分10%为测试集,也就是100个数据。结果可视化随机选择其中的64个数据绘图,每个图像的上方标明了其真实标签和预测的结果,这个是一个非常简单的示例,准确度还是非常高的。


4、工程下载与全部代码
工程链接:Tensorflow实现二元手写数字识别(二分类问题)
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import warnings
import logging
from sklearn.metrics import accuracy_scorelogging.getLogger("tensorflow").setLevel(logging.ERROR)
tf.autograph.set_verbosity(0)
warnings.simplefilter(action='ignore', category=FutureWarning)
# 支持中文显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False# load dataset
def load_data():X = np.load("Handwritten_Digit_Recognition_data/X.npy")y = np.load("Handwritten_Digit_Recognition_data/y.npy")X = X[0:1000]y = y[0:1000]return X, y# 加载数据集,查看数据集大小,可以看到有1000个数据集,每个输入是20*20=400大小的图片
X, y = load_data()
print('The shape of X is: ' + str(X.shape))
print('The shape of y is: ' + str(y.shape))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)# # 下面画图,随便从原数据取出几个画图,可以注释
# m, n = X.shape
# fig, axes = plt.subplots(8, 8, figsize=(8, 8))
# fig.tight_layout(pad=0.1)
# for i, ax in enumerate(axes.flat):
# # Select random indices
# random_index = np.random.randint(m)
# # Select rows corresponding to the random indices and
# # 将1*400的数据转换为20*20的图像格式
# X_random_reshaped = X[random_index].reshape((20, 20)).T
# # Display the image
# ax.imshow(X_random_reshaped, cmap='gray')
# # Display the label above the image
# ax.set_title(y[random_index, 0])
# ax.set_axis_off()
# plt.show()# 构建模型,三层模型进行分类,第一层输入25个神经元...
model = Sequential([tf.keras.Input(shape=(400,)), #specify input size### START CODE HERE ###Dense(100, activation='sigmoid'),Dense(10, activation='sigmoid'),Dense(1, activation='sigmoid')### END CODE HERE ###], name = "my_model"
)
# 打印三层模型的参数
model.summary()
# 模型设定,学习率0.001,因为是分类,使用BinaryCrossentropy损失函数
model.compile(loss=tf.keras.losses.BinaryCrossentropy(),optimizer=tf.keras.optimizers.Adam(0.001),
)
# 开始训练,训练循环20
model.fit(X_train,y_train,epochs=20
)# 绘制测试集的预测结果,绘制64个
fig, axes = plt.subplots(8, 8, figsize=(8, 8))
fig.tight_layout(pad=0.1, rect=[0, 0.03, 1, 0.92]) # [left, bottom, right, top]
for i, ax in enumerate(axes.flat):# Select random indicesrandom_index = np.random.randint(X_test.shape[0])# Select rows corresponding to the random indices and# reshape the imageX_random_reshaped = X_test[random_index].reshape((20, 20)).T# Display the imageax.imshow(X_random_reshaped, cmap='gray')# Predict using the Neural Networkprediction = model.predict(X_test[random_index].reshape(1, 400))if prediction >= 0.5:yhat = 1else:yhat = 0# Display the label above the imageax.set_title(f"{y_test[random_index, 0]},{yhat}")ax.set_axis_off()
fig.suptitle("真实标签, 预测的标签", fontsize=16)
plt.show()# 给出预测的测试集误差
y_pred=model.predict(X_test)
print("测试数据集准确率为:", accuracy_score(y_test, np.round(y_pred)))
相关文章:
01、Tensorflow实现二元手写数字识别
01、Tensorflow实现二元手写数字识别(二分类问题) 开始学习机器学习啦,已经把吴恩达的课全部刷完了,现在开始熟悉一下复现代码。对这个手写数字实部比较感兴趣,作为入门的素材非常合适。 基于Tensorflow 2.10.0 1、…...
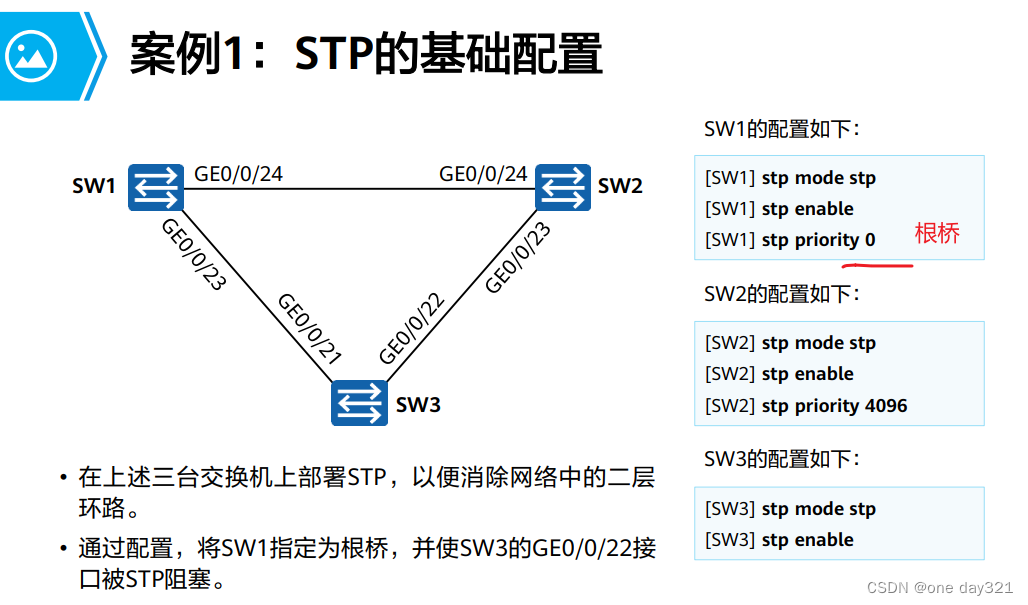
HCIA-Datacom跟官方路线学习第二部分
接着前面第六章,通过VLAN技术, 可以将物理的局域网划分成多个广播域, 实现同一VLAN内的网络设备可以直接进行二层通信, 不同VLAN内的设备不可以直接进行二层通信。 第七章 生成树 在以太网交换网络会使用冗余链路, 但…...

BIO、NIO和AIO的区别
一、基础知识: I/O 模型的简单理解: 1.BIO(Blocking I/O):同步阻塞,一个线程处理一个通道上的事件。 2.NIO(Non-blocking I/O):同步非阻塞,使用选择器&…...

makefile 学习(5)完整的makefile模板
参考自: (1)深度学习部署笔记(二): g, makefile语法,makefile自己的CUDA编程模板(2)https://zhuanlan.zhihu.com/p/396448133(3) 一个挺好的工程模板,(https://github.com/shouxieai/cpp-proj-template) 1. c 编译流…...

专业远程控制如何塑造安全体系?向日葵“全流程安全闭环”解析
安全是远程控制的重中之重,作为国民级远程控制品牌,向日葵远程控制就极为注重安全远控服务的塑造。近期向日葵发布了以安全和核心的新版“向日葵15”以及同步发布《贝锐向日葵远控安全标准白皮书》(下简称《白皮书》),…...

node.js解决输出中文乱码问题
个人简介 👨🏻💻个人主页:九黎aj 🏃🏻♂️幸福源自奋斗,平凡造就不凡 🌟如果文章对你有用,麻烦关注点赞收藏走一波,感谢支持! 🌱欢迎订阅我的…...

CentOS 7 使用异步网络框架Libevent
CentOS 7 安装Libevent库 libevent github地址:https://github.com/libevent/libevent 步骤1:首先,你需要下载libevent的源代码。你可以从github或者源代码官方网站下载。并上传至/usr/local/source_code/ 步骤2:下载完成后&…...

枚举 B. Lorry
Problem - B - Codeforces 题目大意:给物品数量 n n n,体积为 v ( 0 ≤ v ≤ 1 e 9 ) v_{(0 \le v \le 1e9)} v(0≤v≤1e9),第一行读入 n , v n, v n,v,之后 n n n行,读入 n n n个物品,之后每行依次是体…...
ON1 Photo RAW 2024 for Mac——专业照片编辑的终极利器
ON1 Photo RAW 2024 for Mac是一款专为Mac用户打造的照片编辑器,以其强大的功能和易用的操作,让你的照片编辑工作变得轻松愉快。 一、强大的RAW处理能力 ON1 Photo RAW 2024支持大量的RAW格式照片,能够让你在编辑过程中获得更多的自由度和更…...

从word复制内容到wangEditor富文本框的时候会把html标签也复制过来,如果只想实现直接复制纯文本,有什么好的实现方式
从word复制内容到wangEditor富文本框的时候会把html标签也复制过来,如果只想实现直接复制纯文本,有什么好的实现方式? 将 Word 中的内容复制到富文本编辑器时,常常会带有大量的 HTML 标签和样式,这可能导致不必要的格式…...
项目中如何配置数据可视化展现
在现今数据驱动的时代,可视化已逐渐成为数据分析的主要途径,可视化大屏的广泛使用便应运而生。很多公司及政务机构,常利用大屏的手段展现其实力或演示业务,可视化的效果能让观者更快速的理解结果并直观的看到数据展现。因此&#…...

ArkUI开发进阶—@Builder函数@BuilderParam装饰器的妙用与场景应用
ArkUI开发进阶—@Builder函数@BuilderParam装饰器的妙用与场景应用 HarmonyOS,作为一款全场景分布式操作系统,为了推动更广泛的应用开发,采用了一种先进而灵活的编程语言——ArkTS。ArkTS是在TypeScript(TS)的基础上发展而来,为HarmonyOS提供了丰富的应用开发工具,使开…...
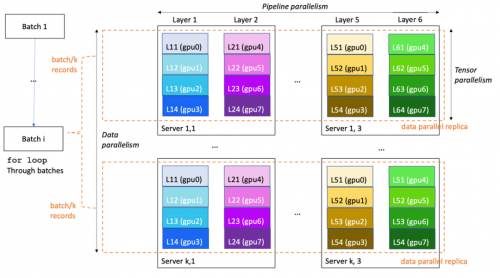
大语言模型概述(三):基于亚马逊云科技的研究分析与实践
上期介绍了基于亚马逊云科技的大语言模型相关研究方向,以及大语言模型的训练和构建优化。本期将介绍大语言模型训练在亚马逊云科技上的最佳实践。 大语言模型训练在亚马逊云科技上的最佳实践 本章节内容,将重点关注大语言模型在亚马逊云科技上的最佳训…...

键入网址到网页显示,期间发生了什么?
文章目录 键入网址到网页显示,期间发生了什么?1. HTTP2. 真实地址查询 —— DNS3. 指南好帮手 —— 协议栈4. 可靠传输 —— TCP5. 远程定位 —— IP6. 两点传输 —— MAC7. 出口 —— 网卡8. 送别者 —— 交换机9. 出境大门 —— 路由器10. 互相扒皮 —…...
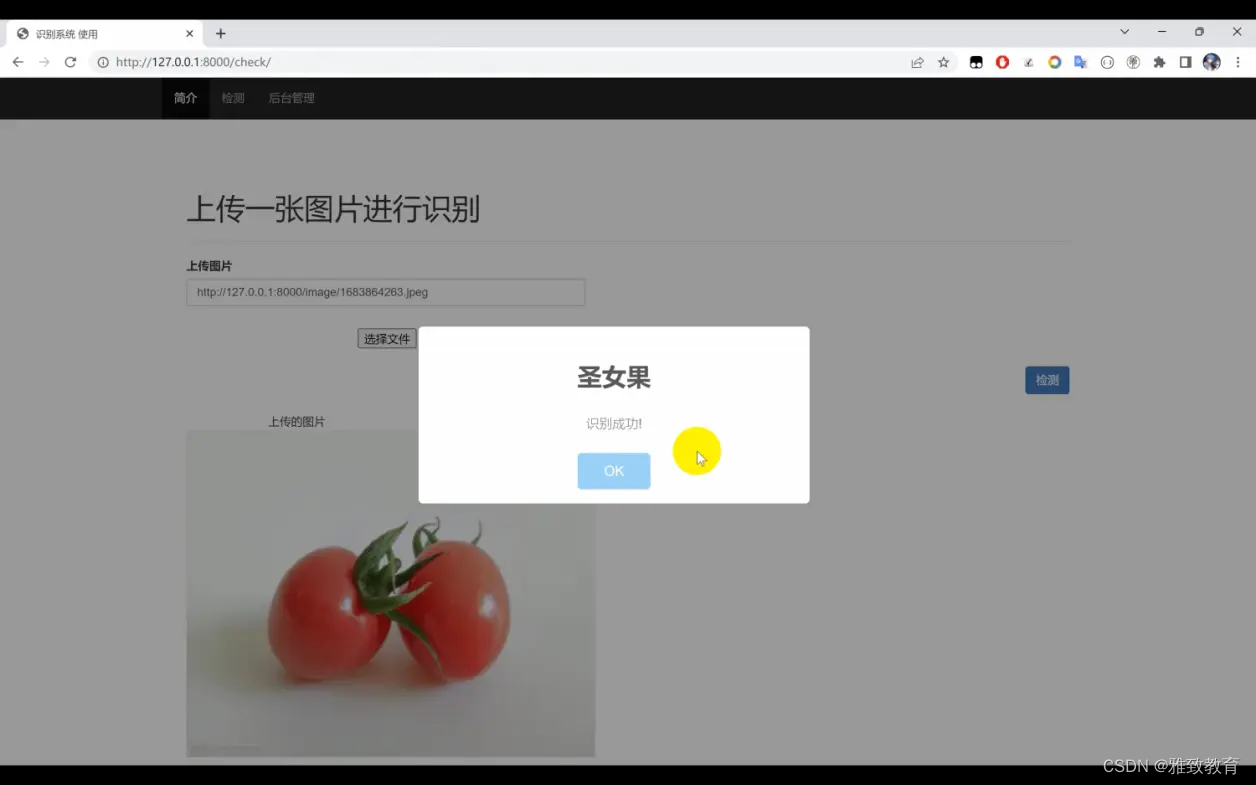
深度学习基于Python+TensorFlow+Django的水果识别系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介简介技术组合系统功能使用流程 二、功能三、系统四. 总结 一项目简介 # 深度学习基于PythonTensorFlowDjango的水果识别系统介绍 简介 该水果识别系统基于…...

vs动态库生成过程中还存在静态库
为什么VS生成动态库dll同时还会生成lib静态库 动态库与静态库(Windows环境下) 动态库和静态库都是一种可执行代码的二进制形式,可以被操作系统载入内存执行。 静态库实际上是在链接时被链接到exe的,编译后,静态…...
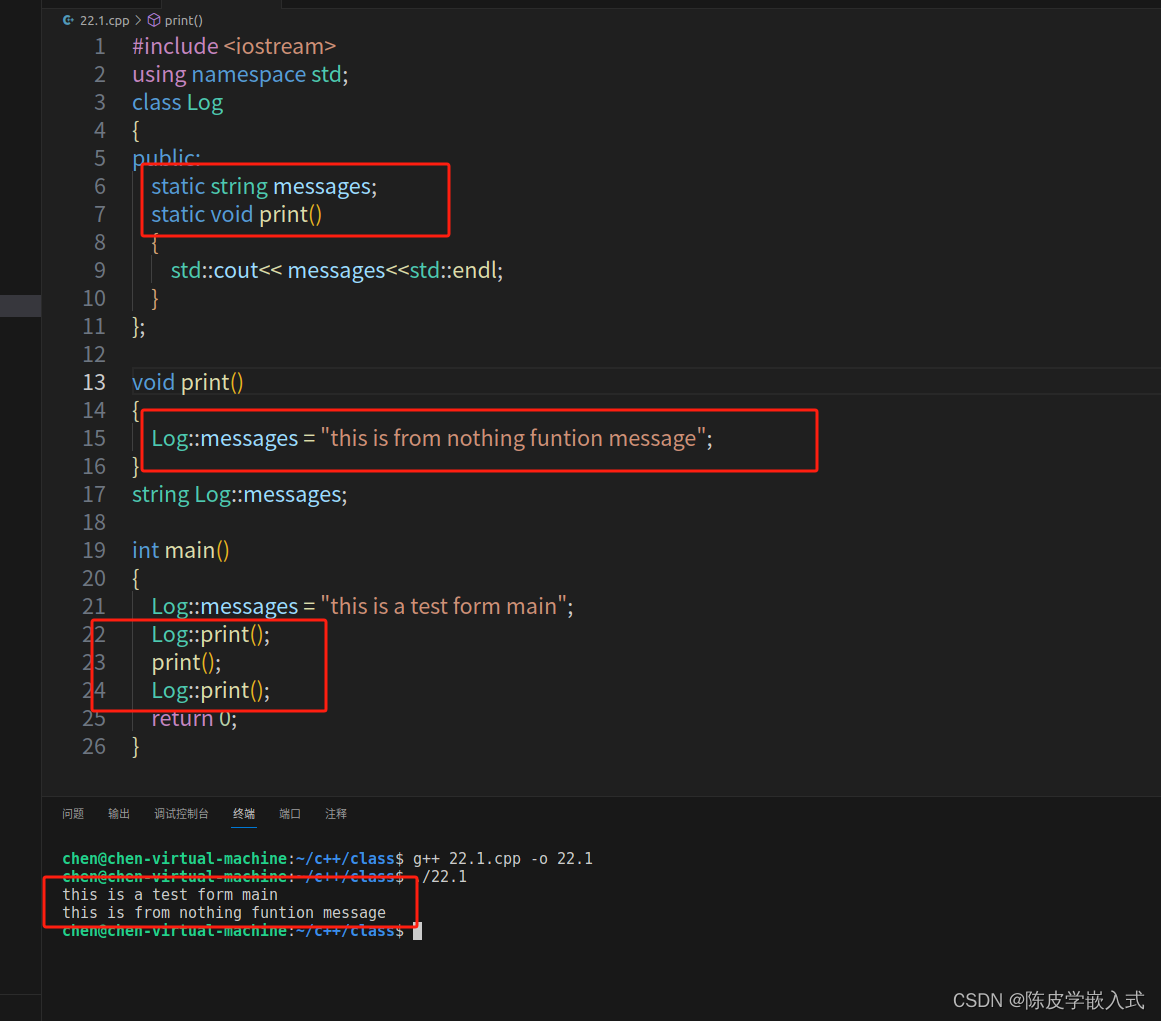
P13 C++ 类 | 结构体内部的静态static
目录 01 前言 02 类内部创建静态变量的例子 03 在类的内部创建静态变量的作用 04 最后的话 01 前言 本期我们讨论 static 在一个类或一个结构体中的具体情况。 在几乎所有面向对象的语言中,静态在一个类中意味着特定的东西。这意味着在类的所有实例中ÿ…...
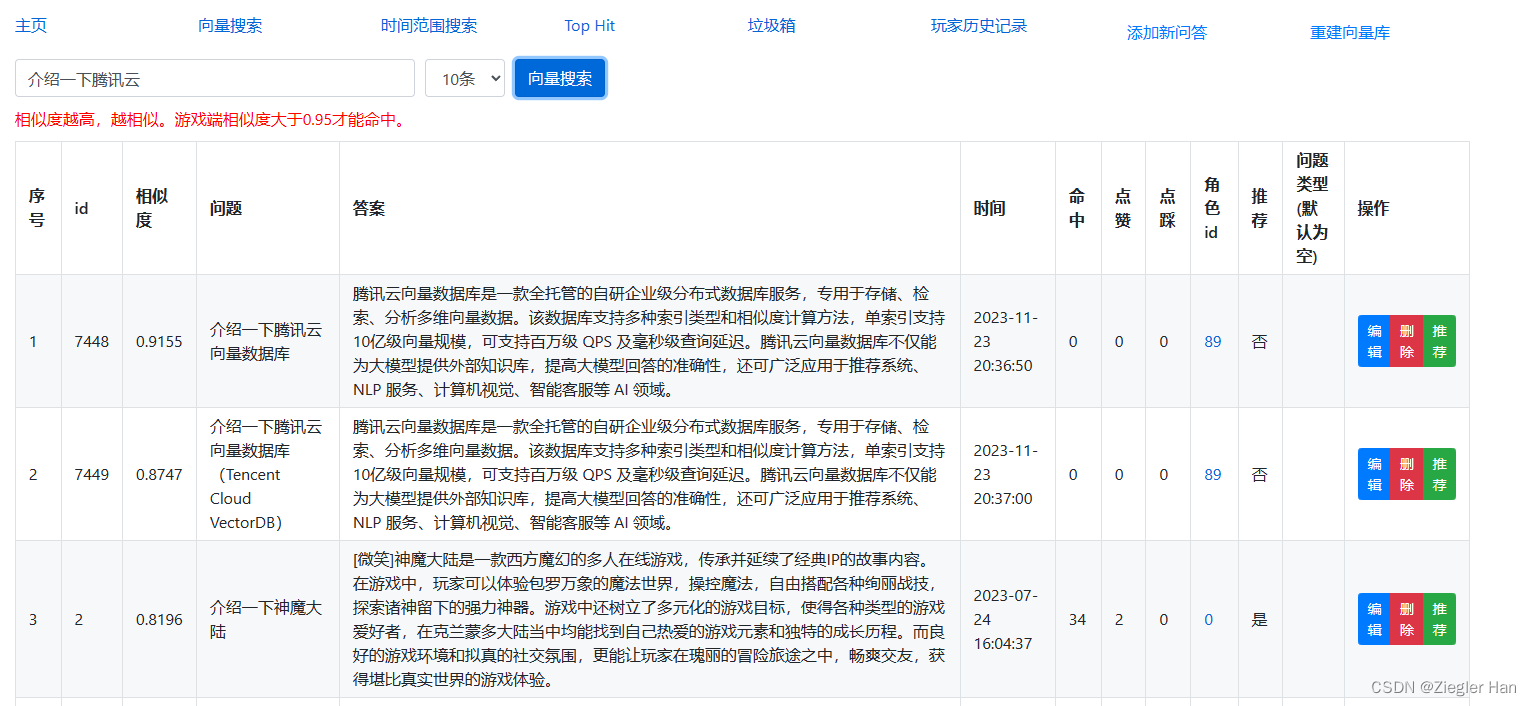
【腾讯云云上实验室-向量数据库】Tencent Cloud VectorDB在实战项目中替换Milvus测试
为什么尝试使用Tencent Cloud VectorDB替换Milvus向量库? 亮点:Tencent Cloud VectorDB支持Embedding,免去自己搭建模型的负担(搭建一个生产环境的模型实在耗费精力和体力)。 腾讯云向量数据库是什么? 腾…...
git clone -mirror 和 git clone 的区别
目录 前言两则区别git clone --mirrorgit clone 获取到的文件有什么不同瘦身仓库如何选择结语开源项目 前言 Git是一款强大的版本控制系统,通过Git可以方便地管理代码的版本和协作开发。在使用Git时,常见的操作之一就是通过git clone命令将远程仓库克隆…...

基于51单片机的公交自动报站系统
**单片机设计介绍, 基于51单片机的公交自动报站系统 文章目录 一 概要公交自动报站系统概述工作原理应用与优势 二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 很高兴为您介绍基于51单片机的公交自动报站系统: 公交自动报…...

从对齐失败到安全上线,AGI验证全流程拆解,含3类必测对抗样本集与21项核心指标
第一章:AGI的测试与验证方法 2026奇点智能技术大会(https://ml-summit.org) AGI系统因其目标导向性、跨域泛化能力与自主推理机制,无法沿用传统AI模型的静态指标(如准确率、F1值)进行充分验证。必须构建覆盖认知鲁棒性、价值对齐…...

SMAPI高级编程技巧:5个提升模组性能的核心方法
SMAPI高级编程技巧:5个提升模组性能的核心方法 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语的官方模组开发框架…...

终极RPG Maker解密指南:三分钟提取游戏资源
终极RPG Maker解密指南:三分钟提取游戏资源 【免费下载链接】RPGMakerDecrypter Tool for decrypting and extracting RPG Maker XP, VX and VX Ace encrypted archives and MV and MZ encrypted files. 项目地址: https://gitcode.com/gh_mirrors/rp/RPGMakerDec…...

五分钟掌握OpenPLC Editor:免费开源的工业自动化编程终极指南
五分钟掌握OpenPLC Editor:免费开源的工业自动化编程终极指南 【免费下载链接】OpenPLC_Editor 项目地址: https://gitcode.com/gh_mirrors/ope/OpenPLC_Editor 你是否曾为昂贵的PLC编程软件而烦恼?是否在寻找一款既专业又完全免费的工业自动化开…...

如何实现飞书文档批量导出:一个命令搞定海量文档迁移
如何实现飞书文档批量导出:一个命令搞定海量文档迁移 【免费下载链接】feishu-doc-export 飞书文档导出服务 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 还在为团队协作平台切换而烦恼吗?面对成百上千的飞书文档,…...
模型越强,检测越假?深度剖析Transformer嵌入空间下的语义克隆盲区,及3步可落地的对抗校验法
第一章:模型越强,检测越假?深度剖析Transformer嵌入空间下的语义克隆盲区,及3步可落地的对抗校验法 2026奇点智能技术大会(https://ml-summit.org) 当LLM生成文本在语义层面无限趋近人类表达时,基于余弦相似度或BERT…...

2026年2款HR系统横评:红海云与用友谁更适合制造业?
制造业选HR系统,真正拉开差距的往往不是人事流程是否在线,而是倒班与综合工时能否稳、计件与绩效能否准、与MES和ERP数据能否顺畅闭环,以及集团多工厂规则差异能否统一管控。红海云与用友都覆盖主流HCM模块,但产品侧重点不同&…...

用NumPy玩转蒙特卡洛模拟:手把手教你用随机数估算圆周率π和期权价格
用NumPy玩转蒙特卡洛模拟:手把手教你用随机数估算圆周率π和期权价格 蒙特卡洛模拟就像一场数学魔术表演——通过随机撒点就能算出圆周率,通过模拟股票走势就能预测期权价格。这种将概率游戏变成科学计算利器的技术,正在金融工程、物理仿真等…...

西门子1200 PLC罐装线项目:博图编程实践与精彩解析
西门子1200plc罐装线项目,程序包括modbus通讯,模拟量输入输出,西门子程序画面精彩,程序编辑分类清晰,非常具有参考学习意义,支持博图V13及以上版本打开在自动化控制领域,西门子1200 PLC以其强大…...

【数字乡村+智慧农业合集】1800余份智慧农业、数字乡村、乡村振兴、田园综合体方案报告合集
乡村振兴是总纲领,数字乡村与田园综合体是实现路径:前者以数字技术赋能乡村全域,后者以三产融合激活乡村经济。数字农业作为数字乡村的核心,聚焦农业生产智能化,共同支撑产业兴旺与乡村全面发展。乡村振兴是总目标&…...