【腾讯云云上实验室-向量数据库】Tencent Cloud VectorDB在实战项目中替换Milvus测试
为什么尝试使用Tencent Cloud VectorDB替换Milvus向量库?
亮点:Tencent Cloud VectorDB支持Embedding,免去自己搭建模型的负担(搭建一个生产环境的模型实在耗费精力和体力)。
腾讯云向量数据库是什么?
腾讯云向量数据库是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。
Milvus是什么?
Milvus是在2019年创建的,其唯一目标是存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。作为一个专门设计用于处理输入向量查询的数据库,它能够处理万亿级别的向量索引。与现有的关系型数据库主要处理遵循预定义模式的结构化数据不同,Milvus从底层设计用于处理从非结构化数据转换而来的嵌入向量。
项目展示
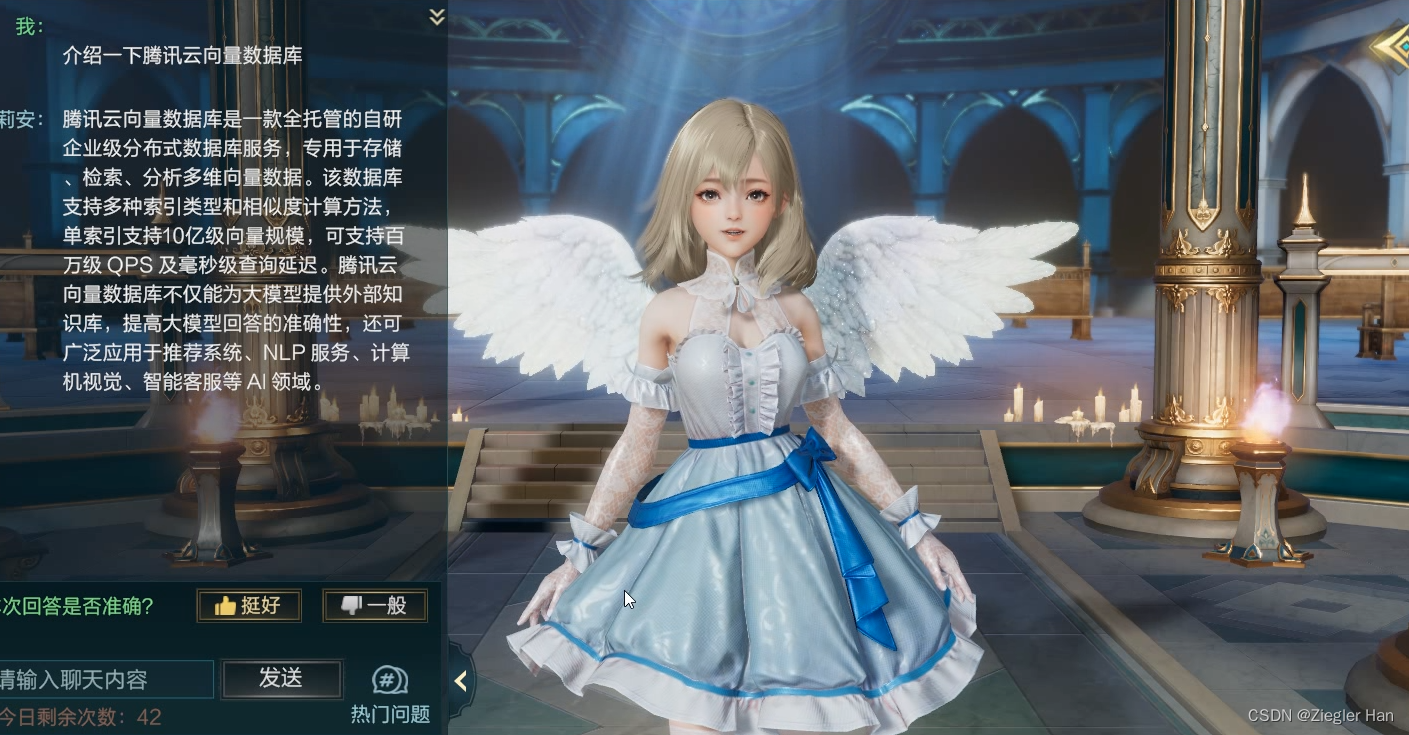
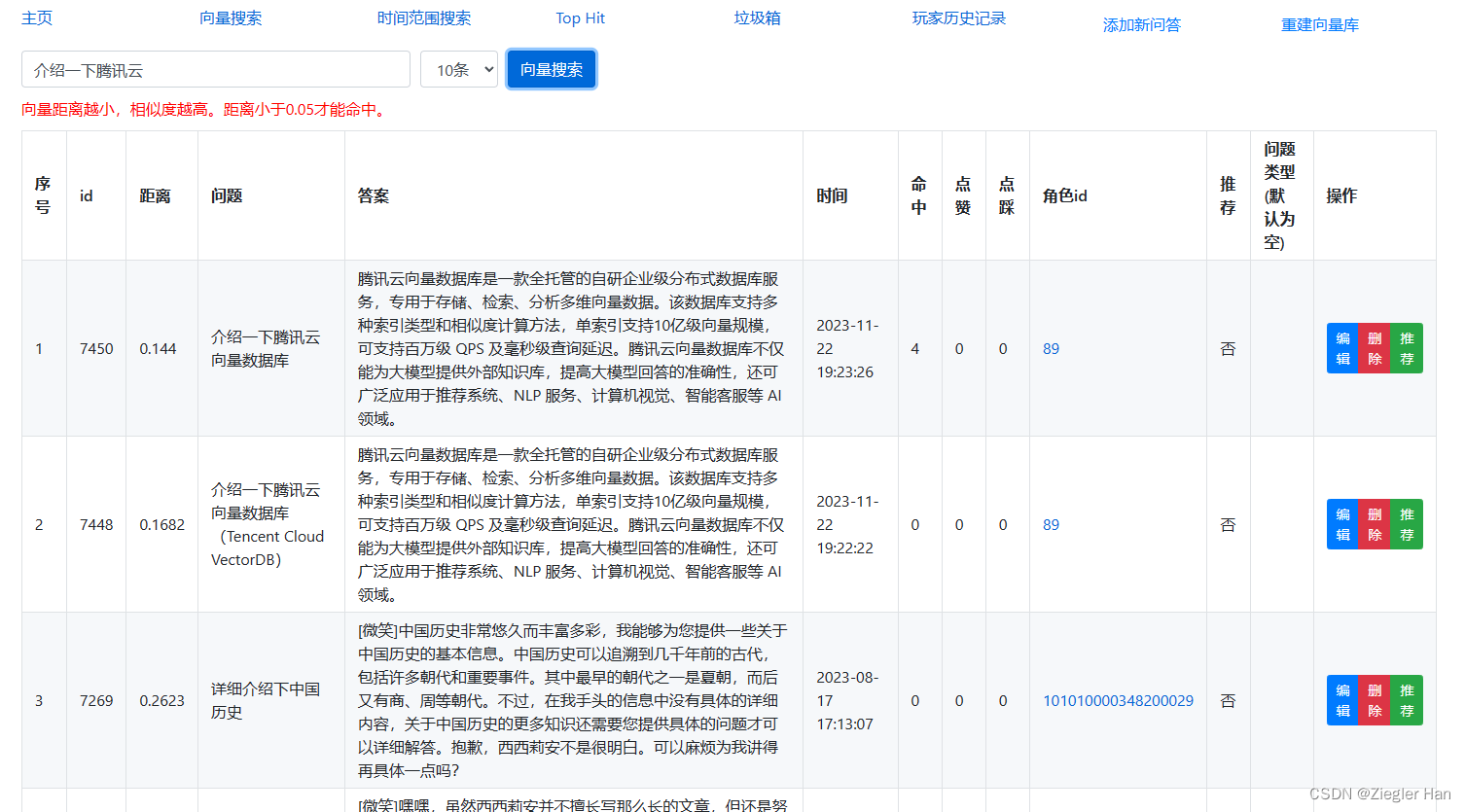
项目介绍游戏内部接入ChatGPT的智能NPC,可以与她进行语音交流。可以回答与游戏相关的问题(这个专业问题是为了编写这个文章,专门添加到问答缓存库中的,游戏内会拒绝回答此类问题)。为了加快ChatGPT的回复速度和降低ChatGPT的费用,增加问答缓存机制。这里运用向量数据库的相似文本相似度高的特性,通过向量搜索,匹配相似度大于一定值,例如:0.95。搜索到相似问题,直接返回答案,不在进行ChatGPT访问。
其次,存在缓存,针对相似问题,还可以给予特定回复答案。例如上面示例,当提问“介绍一下腾讯向量数据库”,直接回复“腾讯云向量数据库是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持10亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、NLP 服务、计算机视觉、智能客服等 AI 领域。”
为什么使用向量数据库?
重点:速度
向量相似度匹配是很长的数组,例如:bge-large-zh模型文本转向量,生成的是768维的float数组。拿问题文本转换为的768维向量与缓存的所有问题的向量进行相似性计算,然后获取最相似的几条数据,这个运算量非常大,速度非常慢。
测试代码:
与300个768维向量进行相似比对,获取最相似的一条数据,耗时几秒钟。按照这个速度,如果与几千上万条数据进行这么计算,简直无法忍受。
这时就必须使用向量数据库了,向量数据库可以支持毫秒级检索上百万行数据。本人曾使用Milvus数据库,分别插入1000行数数据和插入10万行数据,然后进行搜索对比,都在几十毫秒返回结果,数据量的增多,对检索速度几乎没有任何影响。
本项目哪里需要使用向量数据库?
- 玩家提问:玩家提问先通过embedding转换为向量,在向量库检索相似的问题,满足匹配条件,直接返回对应的答案。
- 后台相似问题检索:后台通过向量检索相似问题,以便对特定问题进行增删改查。
使用腾讯云向量数库(Tencent Cloud VectorDB)的优点?
- 支持Embedding:腾讯云向量数据库(Tencent Cloud VectorDB)提供将非结构化数据转换为向量数据的能力,目前已支持文本 Embedding 模型,能够覆盖多种主流语言的向量转换,包括但不限于中文、英文。对于小型项目这是一个非常大的优势。可以降低自己搭建embedding模型或者使用第三方embedding模型的成本。
- FilterIndex的field_type支持数据类型简单:只有String和Uint64,使用起来非常省心。而Milvus数据支持10几种类型,对于初学者不友好,还要研究具体如何使用。
指定 Filter 字段的数据类型。取值如下:
String:字符型。若 name 为 id,则该参数固定为 FieldType.String。
Uint64:指无符号整数,该参数可设置为 FieldType.Uint64。
研究Tencent Cloud VectorDB,测试并封装代码库my_tc_vector_db.py
if __name__ == '__main__':# 初始化myTcVectorDB = MyTcVectorDB("http://****************.tencentclb.com:30000", "root","2epSOV3HK6tiyALo6UqE3mGV**************")# 删除数据库myTcVectorDB.drop_collection("db-qa", "question_768")myTcVectorDB.drop_database("db-qa")# 创建数据库myTcVectorDB.create_database("db-qa")# 创建索引和embedding,并创建集合index = Index(FilterIndex(name='id', field_type=FieldType.String, index_type=IndexType.PRIMARY_KEY),FilterIndex(name='question', field_type=FieldType.String, index_type=IndexType.FILTER),VectorIndex(name='vector', dimension=768, index_type=IndexType.HNSW,metric_type=MetricType.COSINE, params=HNSWParams(m=16, efconstruction=200)))embedding = Embedding(vector_field='vector', field='text', model=EmbeddingModel.BGE_BASE_ZH)collection = myTcVectorDB.create_collection("db-qa", "question_768", index, embedding)# 批量插入myTcVectorDB.upsert("db-qa", "question_768", [Document(id='0001', text='罗贯中', question='罗贯中'),Document(id='0002', text='吴承恩', question='吴承恩'),Document(id='0003', text='曹雪芹', question='曹雪芹'),Document(id='0004', text='郭富城', question='郭富城')])# 单条插入myTcVectorDB.upsert_one("db-qa", "question_768", id='0005', text='周杰伦', question='周杰伦')myTcVectorDB.upsert_one("db-qa", "question_768", id='0006', text='林俊杰', question='林俊杰')# 删除0003myTcVectorDB.delete_by_id("db-qa", "question_768", "0003")# 文本搜索(无需向量转换)text = myTcVectorDB.search_by_text("db-qa", "question_768", "郭富城")# 打印结果print_object(text)# 仅打印idif len(text[0]) > 0:for i in text[0]:print(i['id'])
解释代码功能:
-
初始化:传入tcVectorDB的url、username和key,创建myTcVectorDB.
-
删除数据库db-qa下的数据集question_768,然后删除数据库db-qa
-
重新创建数据库db-qa
-
指定索引和embedding,并创建集合question_768:这里指定id为主键、question为FilterIndex标量索引,vector为VectorIndex向量索引(注意官方文档说明:指定向量索引字段名,固定为 vector。)因为使用中文检索,Embedding使用BGE_BASE_ZH。

-
批量插入测试数据
-
单行插入测试数据
-
测试删除单行数据
-
测试文本搜索,并打印结果
MyTcVectorDB库代码
import jsonimport tcvectordb
from tcvectordb.model.collection import Embedding
from tcvectordb.model.document import Document, SearchParams
from tcvectordb.model.enum import ReadConsistency, MetricType, FieldType, IndexType, EmbeddingModel
from tcvectordb.model.index import Index, FilterIndex, VectorIndex, HNSWParamsclass MyTcVectorDB:def __init__(self, url: str, username: str, key: str, timeout: int = 30):self._client = tcvectordb.VectorDBClient(url=url, username=username, key=key,read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=timeout)def create_database(self, database_name: str):"""Create a database:param database_name: database name:return: database"""return self._client.create_database(database_name=database_name)def drop_database(self, database_name: str):"""Drop a database:param database_name: database name:return: result"""return self._client.drop_database(database_name=database_name)def create_collection(self, db_name: str, collection_name: str, index: Index, ebd: Embedding):db = self._client.database(db_name)# 第二步,创建 Collectioncoll = db.create_collection(name=collection_name,shard=1,replicas=0,description='this is a collection of question embedding',index=index,embedding=ebd)return colldef drop_collection(self, db_name: str, collection_name: str):"""Drop a collection:param db_name: db name:param collection_name: collection name:return: result"""db = self._client.database(db_name)return db.drop_collection(collection_name)def upsert_one(self, db_name: str, collection_name: str, **kwargs):"""Upsert one document to collection:param db_name : db name:param collection_name: collection name:param document: Document:return: result"""db = self._client.database(db_name)coll = db.collection(collection_name)res = coll.upsert(documents=[Document(**kwargs)])return resdef upsert(self, db_name: str, collection_name: str, documents):"""Upsert documents to collection:param db_name : db name:param collection_name: collection name:param documents: list of Document:return: result"""db = self._client.database(db_name)coll = db.collection(collection_name)res = coll.upsert(documents=documents)return resdef search_by_text(self, db_name: str, collection_name: str, text: str, limit: int = 10):"""Search documents by text:param db_name : db name:param collection_name: collection name:param text: text:return: result"""db = self._client.database(db_name)coll = db.collection(collection_name)# searchByText 返回类型为 Dict,接口查询过程中 embedding 可能会出现截断,如发生截断将会返回响应 warn 信息,如需确认是否截断可以# 使用 "warning" 作为 key 从 Dict 结果中获取警告信息,查询结果可以通过 "documents" 作为 key 从 Dict 结果中获取res = coll.searchByText(embeddingItems=[text],params=SearchParams(ef=200),limit=limit)return res.get('documents')def delete_by_id(self, db_name: str, collection_name: str, document_id):"""Delete document by id:param db_name : db name:param collection_name: collection name:param document_id: document id:return: result"""db = self._client.database(db_name)coll = db.collection(collection_name)res = coll.delete(document_ids=[document_id])return resdef print_object(obj):"""Print object"""for elem in obj:# ensure_ascii=False 保证中文不乱码if hasattr(elem, '__dict__'):print(json.dumps(vars(elem), indent=4, ensure_ascii=False))else:print(json.dumps(elem, indent=4, ensure_ascii=False))
开始动手使用Tencent Cloud VectorDB在项目中替换Milvus
1、创建问题库db-qa和集合question_768
与测试代码基本一致
# 初始化myTcVectorDB = MyTcVectorDB("http://****tencentclb.com:30000", "root","2epSOV3HK6tiyALo6UqE3mGVMbpP*******")# 创建数据库myTcVectorDB.create_database("db-qa")# 创建索引和embedding,并创建集合index = Index(FilterIndex(name='id', field_type=FieldType.String, index_type=IndexType.PRIMARY_KEY),FilterIndex(name='question', field_type=FieldType.String, index_type=IndexType.FILTER),VectorIndex(name='vector', dimension=768, index_type=IndexType.HNSW,metric_type=MetricType.COSINE, params=HNSWParams(m=16, efconstruction=200)))embedding = Embedding(vector_field='vector', field='text', model=EmbeddingModel.BGE_BASE_ZH)collection = myTcVectorDB.create_collection("db-qa", "question_768", index, embedding)
2、游戏端和后台文本向量搜索,用MyTcVectorDB替换Milvus
两处代码基本一致。这里去掉文本转向量的步骤,因为TcVectorDB支持Embedding
# 获取问题转换后的向量# success, vector = get_vector_from_text(question)# if not success:# return {"code": -1, "id": 0, "answer": "向量计算失败"}# results = questionCollection.search(vector, limit)results = myVectorDB.search_by_text("db-qa", "question_768", question, limit)...
上面代码需要注意一点,腾讯向量数据的search结果与milvus的搜索结果是不一样的,需要做一下适配。
3、重建向量数据库
问答缓存的数据保存在mysql数据库,向量数据库主要作用是向量搜索。如果更换向量库,只需要重建向量库即可。下面代码:
- 从mysql中获取所有的问题
- 遍历所有问答
- 把问题作为向量索引,问答的id为标量索引插入向量库中
当前mysql数据库中有大几千条数据,重新构建向量就耗时10分钟左右。
def rebuild_vector():# 查找所有的数据select_all = qaTable.select_all_qa()# 遍历所有的数据for qa in select_all:insertId = qa[0]question = qa[1]timestamp = int(time.time())print(question)# 计算向量# 更新向量# success, vector = get_vector_from_text(question)# if not success:# # 向量计算失败,question# logging.error("向量计算失败,insertId:%s, question:%s", insertId, question)# continue# # 删除原有的向量# questionCollection.delete_question(insertId)# # 插入新的向量# questionCollection.insert_question(insertId, vector, question, timestamp)myVectorDB.delete_by_id("db-qa", "question_768", str(insertId))myVectorDB.upsert_one("db-qa", "question_768", id=str(insertId), text=question, question=question)return "重建向量库成功"
4、修改后台展示,看下修改后的效果图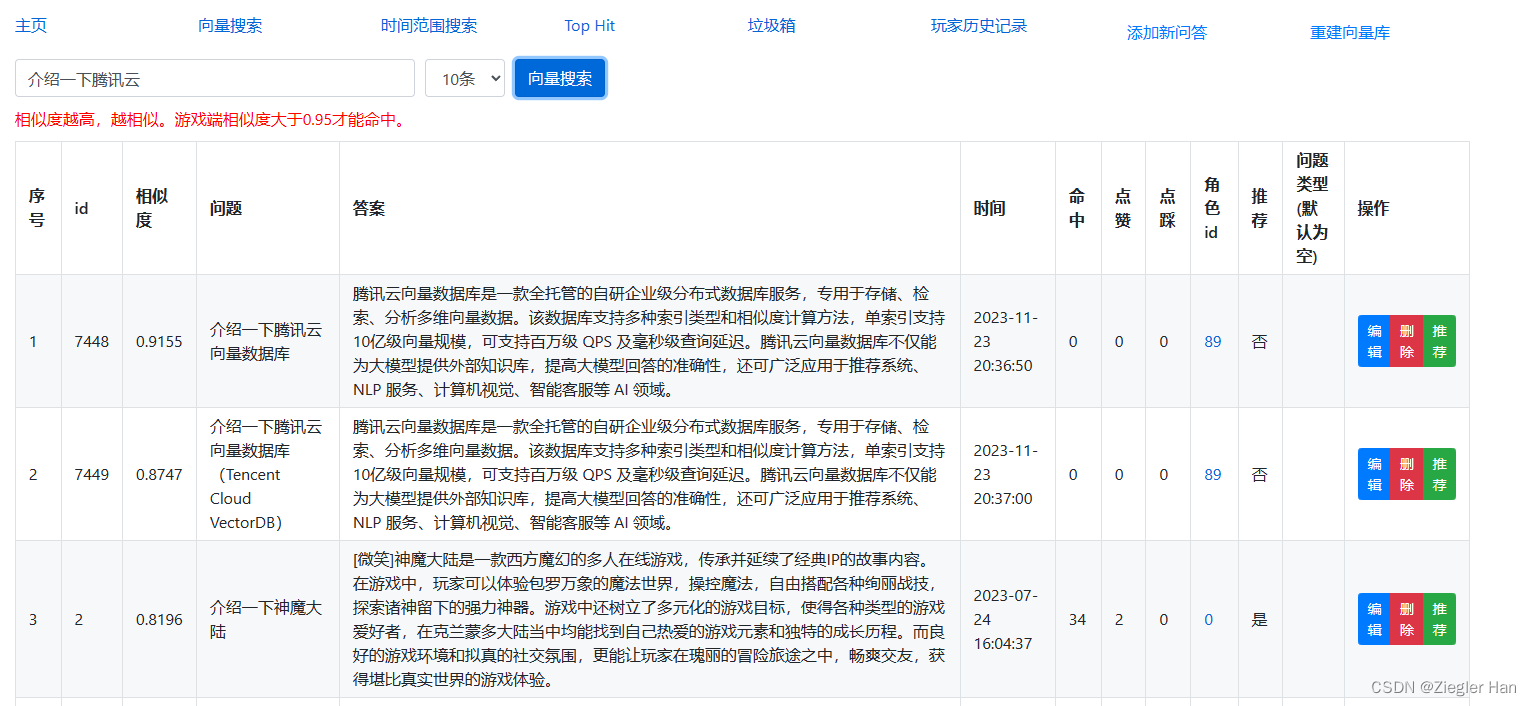
- 使用的文本转向量的模型是:BGE_BASE_ZH
- 向量索引是:VectorIndex(name=‘vector’, dimension=768, index_type=IndexType.HNSW, metric_type=MetricType.COSINE, params=HNSWParams(m=16, efconstruction=200))
- 搜索文本返回结果代表的是相似度,保存在score中。
总结:
- 使用腾讯向量数据库要比使用Milvus更加简单易用,无需自己部署服务器。
- 腾讯云向量库支持主流Embedding,直接支持文本向量搜索,避免自己部署Embedding模型,并避免调用文本转向量的过程。对于开发者来说非常便利。
如果是个人,或者小型项目开发,非常值得使用腾讯云数据库。如果是大型项目,不缺钱的话也非常推荐使用腾讯云数据库,稳定、高效且安全。
相关文章:
【腾讯云云上实验室-向量数据库】Tencent Cloud VectorDB在实战项目中替换Milvus测试
为什么尝试使用Tencent Cloud VectorDB替换Milvus向量库? 亮点:Tencent Cloud VectorDB支持Embedding,免去自己搭建模型的负担(搭建一个生产环境的模型实在耗费精力和体力)。 腾讯云向量数据库是什么? 腾…...
git clone -mirror 和 git clone 的区别
目录 前言两则区别git clone --mirrorgit clone 获取到的文件有什么不同瘦身仓库如何选择结语开源项目 前言 Git是一款强大的版本控制系统,通过Git可以方便地管理代码的版本和协作开发。在使用Git时,常见的操作之一就是通过git clone命令将远程仓库克隆…...

基于51单片机的公交自动报站系统
**单片机设计介绍, 基于51单片机的公交自动报站系统 文章目录 一 概要公交自动报站系统概述工作原理应用与优势 二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 很高兴为您介绍基于51单片机的公交自动报站系统: 公交自动报…...

NextJS开发:Image组件的使用及缺陷
Next.js 中的 Image 组件相比于传统的 img 标签有以下几个优点: 懒加载:Image 组件自带懒加载,当页面滚动到 Image 组件所在位置时才会加载图片,从而加快页面的渲染速度。自动优化:Image 组件会自动将图片压缩、转换格…...

网络安全面试经历
2023-11-22 X亭安全服务实习生面试 一面: 工作方向:偏蓝队 总结:实习蓝队面试没有什么难度,没有什么技术上的细节问题,之前准备的细节问题没有考 最后和面试官聊了聊对网安的认识,聊了聊二进制的知识…...
 - 数据类型)
Rust语言入门教程(四) - 数据类型
标量类型(Scalar Types) 在Rust中,一共有4中标量类型, 也就是基本数据类型,分别是: 整型(Integers)浮点型(Floats)布尔型(Boolean)字符型(Chara…...
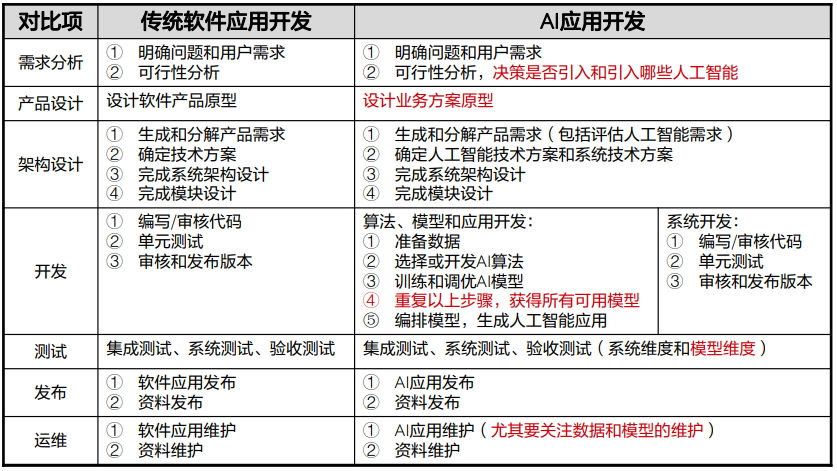
华为云人工智能入门级开发者认证学习笔记
人工智能入门级开发者认证 人工智能定义 定义 人工智能 (Artificial Intelligence) 是研究、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 强人工智能 vs 弱人工智能 强人工智能:强人工智能观点认为有可能制造出真正能推理(…...

腾讯云发布新一代基于AMD处理器的星星海云服务器实例SA5
基础设施的硬实力,愈发成为云厂商的核心竞争力。 11月24日,腾讯云发布了全新一代星星海服务器。基于自研服务器的高密设计与硬件升级,对应云服务器SA5是全球首家搭载第四代AMD EPYC处理器(Bergamo)的公有云实例&#…...

算法通关村-----数论问题解析
最大公约数和最小公倍数 概念描述 最大公约数(GCD)是指两个或多个整数共有约数中的最大值。 最小公倍数(LCM)是指两个或多个整数共有的倍数中的最小值 方法介绍 碾转相除法 一种用于计算两个整数的最大公约数(GCD…...

wpf prism当中 发布订阅 IEventAggregator
先订阅后发布 private readonly IEventAggregator _eventAggregator; public LoginViewModel(ILoginService iloginService, IEventAggregator eventAggregator) {_iloginService iloginService;_eventAggregator eventAggregator;_eventAggregator.GetEvent<MessageEven…...

Angular中的getter函数
Angular 中的 getter 函数每次被调用时会返回一个新对象时,这些新对象并不使用同一个堆内存。详细解释一下: Getter 函数的作用是获取某个属性的值。在 Angular 中,getter 函数通常用于获取响应式数据(例如 Observables 或 Signal…...
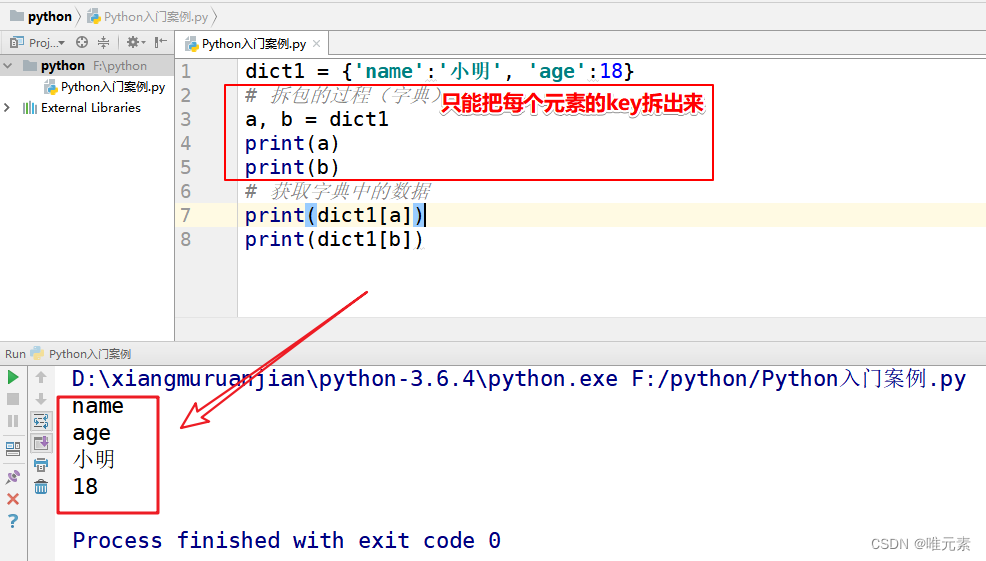
Python----函数的数据 拆包(元组和字典)
Python拆包: 就是把元组或字典中的数据单独的拆分出来,然后赋予给其他的变量。 拆包: 对于函数中的多个返回数据, 去掉 元组, 列表 或者字典 直接获取里面数据的过程。 元组的拆包过程 def func():# 经过一系列操作返回一个元组return 100, 200 …...

vim翻页快捷键
Vim翻页 整页 Ctrlf向下翻页,下一页,相当于Page DownCtrlb向上翻页,上一页,相当于Page Up 半页 Ctrld向下半页,下一半页,光标下移Ctrlu向上半页,上衣半页,光标上移 按行 Ctrle…...
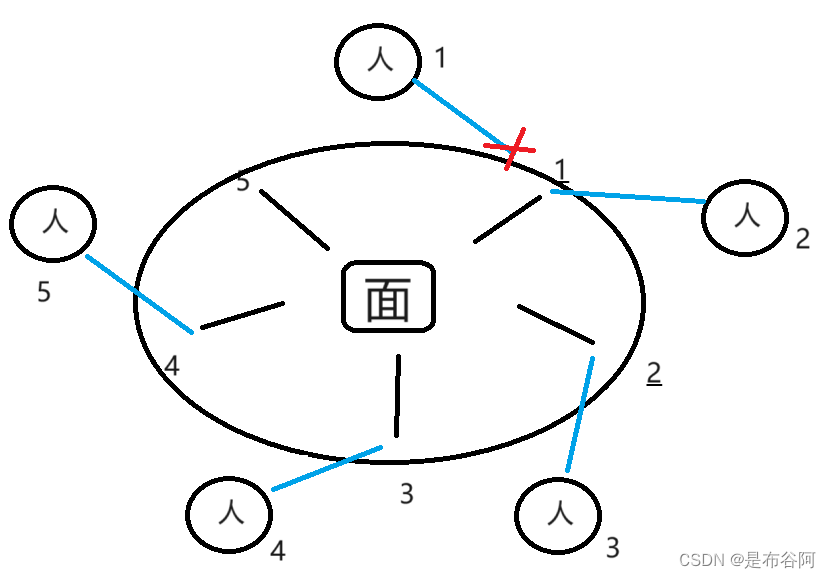
死锁是什么?死锁是如何产生的?如何破除死锁?
1. 死锁是什么 多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。 2. 死锁的三种典型情况 一个线程, 一把锁, 是不可重入锁, 该线程针对这个锁连续加锁两次, 就会出现死锁. 两个线程…...

给虚拟机配置静态id地址
1.令人头大的原因 当连接虚拟机的时候 地址不一会就改变,每次都要重新输入 2.配置虚拟机静态id地址 打开命令窗口执行 : vim /etc/sysconfig/network-scripts/ifcfg-ens33 按下面操作修改 查看自己子网掩码 3.重启网络 命令行输入 systemctl restart netwo…...
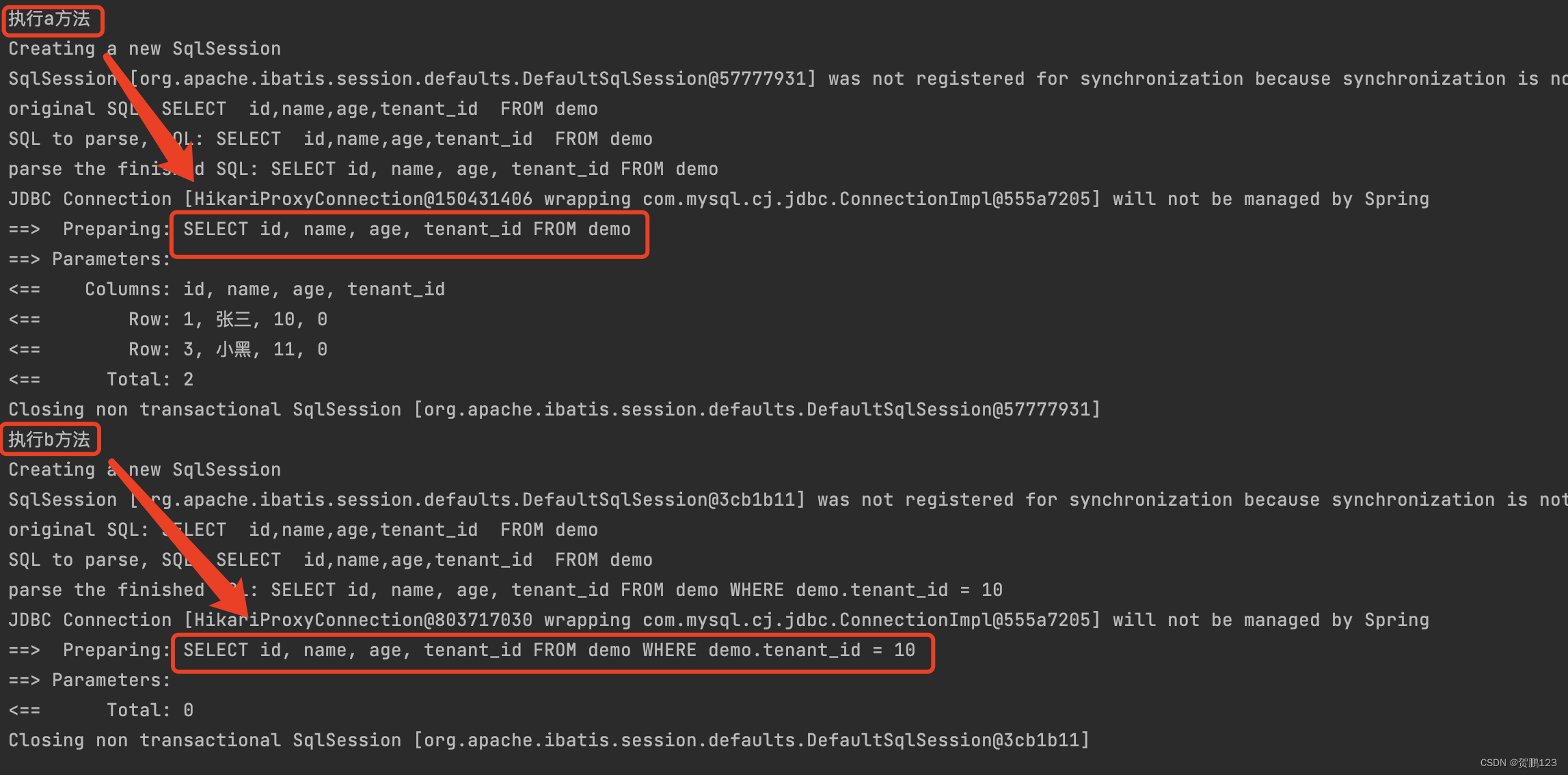
Mybatis-Plus 租户使用
Mybatis-Plus 租户使用 文章目录 Mybatis-Plus 租户使用一. 前言1.1 租户存在的意义1.2 租户框架 二. Mybatis-plus 租户2.1 租户处理器2.2 前置准备1. 依赖2. 表及数据准备3. 代码生成器 2.3 使用 三. 深入使用3.1 前言3.2 租户主体设值,取值3.3 部分表全量db操作3…...

vue el-table (固定列+滚动列)【横向滚动条】确定滚动条是在列头还是列尾
效果图: 代码实现: html: <script src"//unpkg.com/vue2/dist/vue.js"></script> <script src"//unpkg.com/element-ui2.15.14/lib/index.js"></script> <div id"app" style&quo…...

⑦【Redis GEO 】Redis常用数据类型:GEO [使用手册]
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ Redis GEO ⑦Redis GEO 基本操作命令1.geoadd …...

LeetCode 2304. 网格中的最小路径代价:DP
【LetMeFly】2304.网格中的最小路径代价:DP 力扣题目链接:https://leetcode.cn/problems/minimum-path-cost-in-a-grid/ 给你一个下标从 0 开始的整数矩阵 grid ,矩阵大小为 m x n ,由从 0 到 m * n - 1 的不同整数组成。你可以…...

c 实用化的文本终端实时显示摄像头视频
因为采用yuv格式,帧率都很低。图像会拖影。把图像尺寸尽量缩小,能大大改善。现在最麻烦的是图像上有黑色的闪影,不知是为啥?如是framebuffer引起的就无解了。终于找到问题了,是在显示前加了一条用黑色清屏造成的&#…...

Windows右键菜单的“数字园艺师“:ContextMenuManager深度解析与实战手册
Windows右键菜单的"数字园艺师":ContextMenuManager深度解析与实战手册 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾想过&…...
)
农产品销售|基于springboot + vue农产品销售系统(源码+数据库+文档)
农产品销售系统 目录 基于springboot vue农产品销售系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue农产品销售系统 一、前言 博主介绍&#x…...

基于Node.js与TypeScript的快速项目生成工具potato-comp实战指南
1. 为什么你需要potato-comp? 每次启动新项目时,你是不是也受够了重复搭建基础框架?从配置TypeScript到安装ORM,从初始化路由到设置热更新,这些机械性工作至少会消耗半天时间。我去年统计过,在中小型项目中…...

如何高效使用Python-miio:5个实战场景完整指南
如何高效使用Python-miio:5个实战场景完整指南 【免费下载链接】python-miio Python library & console tool for controlling Xiaomi smart appliances 项目地址: https://gitcode.com/gh_mirrors/py/python-miio Python-miio是一个强大的开源工具&…...

用global关键字解决UnboundLocalError?先别急,这里有更Pythonic的3种写法
告别global关键字:3种更优雅的Python变量作用域解决方案 在Python开发中,遇到UnboundLocalError时,很多开发者会条件反射地使用global关键字解决问题。虽然这种方法确实能让代码运行起来,但它往往带来更多隐患——命名空间污染、难…...

Obsidian Dataview完全指南:3步将笔记库变成智能数据库的终极秘籍
Obsidian Dataview完全指南:3步将笔记库变成智能数据库的终极秘籍 【免费下载链接】obsidian-dataview A data index and query language over Markdown files, for https://obsidian.md/. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-dataview 还…...

LLM集成失败率高达67%?SITS2026技术委员会披露4类高危架构模式与2套合规交付 checklist
第一章:SITS2026总结:生成式AI应用的落地之道 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026大会上,工业界与学术界共同验证了一个关键共识:生成式AI的价值不在模型参数规模,而在闭环落地能力——即从提示…...

从配置文件到配置类:Spring Boot Security 的权限控制演进
1. Spring Security 的配置文件时代 记得我第一次用 Spring Security 是在五年前的一个内部管理系统项目上。当时为了快速上线,直接在 application.yml 里写死了用户名密码,就像这样: spring:security:user:name: adminpassword: 123456roles…...
Translumo:打破语言壁垒的终极解决方案——实时屏幕翻译工具深度解析
Translumo:打破语言壁垒的终极解决方案——实时屏幕翻译工具深度解析 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translum…...

终极FanControl中文配置指南:3步实现Windows智能风扇控制
终极FanControl中文配置指南:3步实现Windows智能风扇控制 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...