[PyTorch][chapter 64][强化学习-DQN]
前言:
DQN 就是结合了深度学习和强化学习的一种算法,最初是 DeepMind 在 NIPS 2013年提出,它的核心利润包括马尔科夫决策链以及贝尔曼公式。
Q-learning的核心在于Q表格,通过建立Q表格来为行动提供指引,但这适用于状态和动作空间是离散且维数不高时,当状态和动作空间是高维连续时Q表格将变得十分巨大,对于维护Q表格和查找都是不现实的。
1: DQN 历史
2: DQN 网络参数配置
3:DQN 网络模型搭建
一 DQN 历史
DQN 跟机器学习的时序差分学习里面的Q-Learning 算法相似
1.1 Q-Learning 算法


在Q Learning 中,我们有个Q table ,记录不同状态下,各个动作的Q 值
我们通过Q table 更新当前的策略
Q table 的作用: 是我们输入S,通过查表返回能够获得最大Q值的动作A.
但是很多场景状态S 并不是离散的,很难去定义
1.2 DQN 发展史
Deep network+Q-learning = DQN
DQN 和 Q-tabel 没有本质区别:
Q-table: 内部维护 Q Tabel
DQN: 通过神经网络 , 替代了 Q Tabel

二 网络模型
2.1 DQN 算法



2.1 模型

模型参数
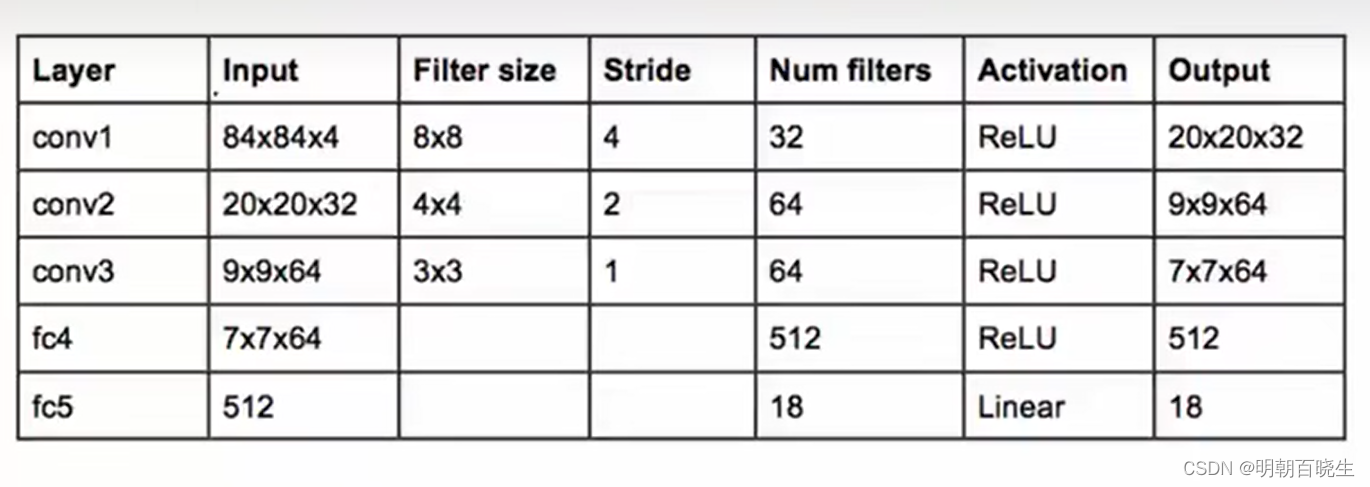
三 代码实现:
5.1 main.py
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 17 16:53:02 2023@author: chengxf2
"""import numpy as np
import torch
import gym
import random
from Replaybuffer import Replay
from Agent import DQN
import rl_utils
import matplotlib.pyplot as plt
from tqdm import tqdm #生成进度条lr = 5e-3
hidden_dim = 128
num_episodes = 500
minimal_size = 500
gamma = 0.98
epsilon =0.01
target_update = 10
buffer_size = 10000
mini_size = 500
batch_size = 64
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")if __name__ == "__main__":env_name = 'CartPole-v0'env = gym.make(env_name)random.seed(0)np.random.seed(0)env.seed(0)torch.manual_seed(0)replay_buffer = Replay(buffer_size)state_dim = env.observation_space.shape[0]action_dim = env.action_space.nagent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,target_update, device)return_list = []for i in range(10):with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:for i_episode in range(int(num_episodes / 10)):episode_return = 0state = env.reset()done = Falsewhile not done:action = agent.take_action(state)next_state, reward, done, _ = env.step(action)replay_buffer.add(state, action, reward, next_state, done)state = next_stateepisode_return += reward# 当buffer数据的数量超过一定值后,才进行Q网络训练if replay_buffer.size() > minimal_size:b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)transition_dict = {'states': b_s,'actions': b_a,'next_states': b_ns,'rewards': b_r,'dones': b_d}agent.update(transition_dict)return_list.append(episode_return)if (i_episode + 1) % 10 == 0:pbar.set_postfix({'episode':'%d' % (num_episodes / 10 * i + i_episode + 1),'return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)episodes_list = list(range(len(return_list)))plt.figure(1) plt.subplot(1, 2, 1) # fig.1是一个一行两列布局的图,且现在画的是左图plt.plot(episodes_list, return_list,c='r')plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('DQN on {}'.format(env_name))plt.figure(1) # 当前要处理的图为fig.1,而且当前图是fig.1的左图plt.subplot(1, 2, 2) # 当前图变为fig.1的右图mv_return = rl_utils.moving_average(return_list, 9)plt.plot(episodes_list, mv_return,c='g')plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('DQN on {}'.format(env_name))plt.show()
5.2 Agent.py
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 17 16:00:46 2023@author: chengxf2
"""import random
import numpy as np
from torch import nn
import torch
import torch.nn.functional as Fclass QNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(QNet, self).__init__()self.net = nn.Sequential(nn.Linear(state_dim, hidden_dim),nn.Linear(hidden_dim, action_dim))def forward(self, state):qvalue = self.net(state)return qvalueclass DQN:def __init__(self,state_dim, hidden_dim, action_dim,learning_rate,discount, epsilon, target_update, device):self.action_dim = action_dimself.q_net = QNet(state_dim, hidden_dim, action_dim).to(device)self.target_q_net = QNet(state_dim, hidden_dim, action_dim).to(device)#Adam 优化器self.optimizer = torch.optim.Adam(self.q_net.parameters(),lr=learning_rate)self.gamma = discount #折扣因子self.epsilon = epsilon # e-贪心算法self.target_update = target_update # 目标网络更新频率self.device = deviceself.count = 0 #计数器def take_action(self, state):rnd = np.random.random() #产生随机数if rnd <self.epsilon:action = np.random.randint(0, self.action_dim)else:state = torch.tensor([state], dtype=torch.float).to(self.device)qvalue = self.q_net(state)action = qvalue.argmax().item()return actiondef update(self, data):states = torch.tensor(data['states'],dtype=torch.float).to(self.device)actions = torch.tensor(data['actions']).view(-1, 1).to(self.device)rewards = torch.tensor(data['rewards'],dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(data['next_states'],dtype=torch.float).to(self.device)dones = torch.tensor(data['dones'],dtype=torch.float).view(-1, 1).to(self.device)#从完整数据中按索引取值[64]#print("\n actions ",actions,actions.shape)q_value = self.q_net(states).gather(1,actions) #Q值#下一个状态的Q值max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1,1)q_targets = rewards + self.gamma * max_next_q_values * (1 - dones)loss = F.mse_loss(q_value, q_targets)loss = torch.mean(loss)self.optimizer.zero_grad()loss.backward()self.optimizer.step()if self.count %self.target_update ==0:#更新目标网络self.target_q_net.load_state_dict(self.q_net.state_dict())self.count +=15.3 Replaybuffer.py
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 17 15:50:07 2023@author: chengxf2
"""import collections
import random
import numpy as np
class Replay:def __init__(self, capacity):#双向队列,可以在队列的两端任意添加或删除元素。self.buffer = collections.deque(maxlen = capacity)def add(self, state, action ,reward, next_state, done):#数据加入bufferself.buffer.append((state,action,reward, next_state, done))def sample(self, batch_size):#采样数据data = random.sample(self.buffer, batch_size)state,action, reward, next_state,done = zip(*data)return np.array(state), action, reward, np.array(next_state), donedef size(self):return len(self.buffer)5.4 rl_utils.py
from tqdm import tqdm
import numpy as np
import torch
import collections
import randomclass ReplayBuffer:def __init__(self, capacity):self.buffer = collections.deque(maxlen=capacity) def add(self, state, action, reward, next_state, done): self.buffer.append((state, action, reward, next_state, done)) def sample(self, batch_size): transitions = random.sample(self.buffer, batch_size)state, action, reward, next_state, done = zip(*transitions)return np.array(state), action, reward, np.array(next_state), done def size(self): return len(self.buffer)def moving_average(a, window_size):cumulative_sum = np.cumsum(np.insert(a, 0, 0)) middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_sizer = np.arange(1, window_size-1, 2)begin = np.cumsum(a[:window_size-1])[::2] / rend = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]return np.concatenate((begin, middle, end))def train_on_policy_agent(env, agent, num_episodes):return_list = []for i in range(10):with tqdm(total=int(num_episodes/10), desc='Iteration %d' % i) as pbar:for i_episode in range(int(num_episodes/10)):episode_return = 0transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}state = env.reset()done = Falsewhile not done:action = agent.take_action(state)next_state, reward, done, _ = env.step(action)transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)state = next_stateepisode_return += rewardreturn_list.append(episode_return)agent.update(transition_dict)if (i_episode+1) % 10 == 0:pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})pbar.update(1)return return_listdef train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size):return_list = []for i in range(10):with tqdm(total=int(num_episodes/10), desc='Iteration %d' % i) as pbar:for i_episode in range(int(num_episodes/10)):episode_return = 0state = env.reset()done = Falsewhile not done:action = agent.take_action(state)next_state, reward, done, _ = env.step(action)replay_buffer.add(state, action, reward, next_state, done)state = next_stateepisode_return += rewardif replay_buffer.size() > minimal_size:b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)transition_dict = {'states': b_s, 'actions': b_a, 'next_states': b_ns, 'rewards': b_r, 'dones': b_d}agent.update(transition_dict)return_list.append(episode_return)if (i_episode+1) % 10 == 0:pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})pbar.update(1)return return_listdef compute_advantage(gamma, lmbda, td_delta):td_delta = td_delta.detach().numpy()advantage_list = []advantage = 0.0for delta in td_delta[::-1]:advantage = gamma * lmbda * advantage + deltaadvantage_list.append(advantage)advantage_list.reverse()return torch.tensor(advantage_list, dtype=torch.float)DQN 算法
遇强则强(八):从Q-table到DQN - 知乎使用Pytorch实现强化学习——DQN算法_dqn pytorch-CSDN博客
https://www.cnblogs.com/xiaohuiduan/p/12993691.html
https://www.cnblogs.com/xiaohuiduan/p/12945449.html
强化学习第五节(DQN)【个人知识分享】_哔哩哔哩_bilibili
CSDN
组会讲解强化学习的DQN算法_哔哩哔哩_bilibili
3-ε-greedy_ReplayBuffer_FixedQ-targets_哔哩哔哩_bilibili
4-代码实战DQN_Agent和Env整体交互_哔哩哔哩_bilibili
DQN基本概念和算法流程(附Pytorch代码) - 知乎
CSDN
DQN 算法
相关文章:
[PyTorch][chapter 64][强化学习-DQN]
前言: DQN 就是结合了深度学习和强化学习的一种算法,最初是 DeepMind 在 NIPS 2013年提出,它的核心利润包括马尔科夫决策链以及贝尔曼公式。 Q-learning的核心在于Q表格,通过建立Q表格来为行动提供指引,但这适用于状态…...
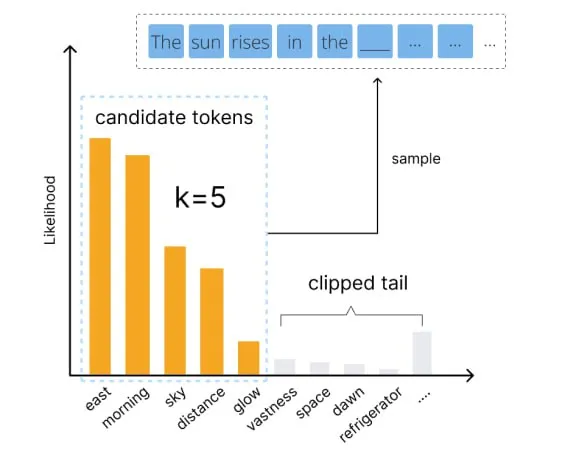
用好语言模型:temperature、top-p等核心参数解析
编者按:我们如何才能更好地控制大模型的输出? 本文将介绍几个关键参数,帮助读者更好地理解和运用 temperature、top-p、top-k、frequency penalty 和 presence penalty 等常见参数,以优化语言模型的生成效果。 文章详细解释了这些参数的作用…...

python之pycryptodome模块,加密算法库
一、简介 PyCryptodome是PyCrypto库的一个分支,它是Python中最受欢迎的密码学库之一。PyCryptodome提供了许多密码学算法和协议的实现,包括对称加密、非对称加密、消息摘要、密码哈希、数字签名等。它还提供了一些其他功能,如密码学安全随机…...

IDEA如何将本地项目推送到GitHub上?
大家好,我是G探险者。 IntelliJ IDEA 是一个强大的集成开发环境(IDE),它支持多种编程语言和工具。它也内置了对Git和GitHub的支持,让开发者可以轻松地将本地项目推送到GitHub上。以下是一个操作手册,描述了…...
Leetcode—45.跳跃游戏II【中等】
2023每日刷题(四十) Leetcode—45.跳跃游戏II 贪心法思想 实现代码 #define MAX(a, b) (a > b ? (a) : (b))int jump(int* nums, int numsSize) {int start 0;int end 1;int ans 0;int maxStride 0;while(end < numsSize) {maxStride 0;fo…...

基于Vue+SpringBoot的木马文件检测系统
项目编号: S 041 ,文末获取源码。 \color{red}{项目编号:S041,文末获取源码。} 项目编号:S041,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 木马分类模块2.3 木…...

springboot内置Tomcat流程
1、org.springframework.boot.SpringApplication#initialize setInitializers((Collection) getSpringFactoriesInstances(ApplicationContextInitializer.class));加载了org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext 2、spring refres…...

Android修行手册-溢出父布局的按钮实现点击
Unity3D特效百例案例项目实战源码Android-Unity实战问题汇总游戏脚本-辅助自动化Android控件全解手册再战Android系列Scratch编程案例软考全系列Unity3D学习专栏蓝桥系列ChatGPT和AIGC 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分…...
Transformer——decoder
上一篇文章,我们介绍了encoder,这篇文章我们将要介绍decoder Transformer-encoder decoder结构: 如果看过上一篇文章的同学,肯定对decoder的结构不陌生,从上面框中可以明显的看出: 每个Decoder Block有两个…...

基于 STM32 的温度测量与控制系统设计
本文介绍了如何基于 STM32 微控制器设计一款温度测量与控制系统。首先,我们将简要介绍 STM32 微控制器的特点和能力。接下来,我们将详细讨论温度传感器的选择与接口。然后,我们将介绍如何使用 STM32 提供的开发工具和相关库来进行温度测量和控…...
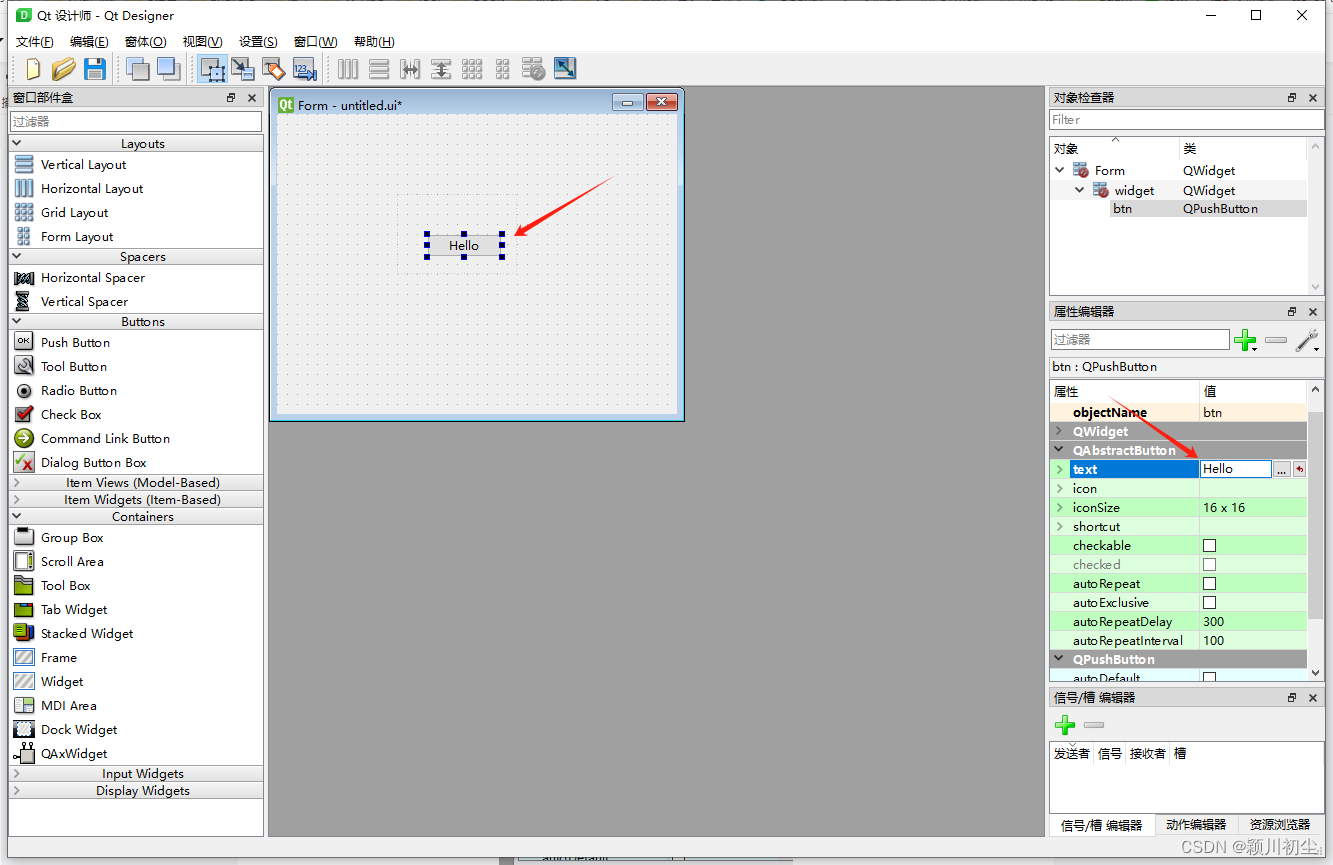
python之pyqt专栏3-QT Designer
从前面两篇文章python之pyqt专栏1-环境搭建与python之pyqt专栏2-项目文件解析,我们对QT Designer有基础的认识。 QT Designer用来创建UI界面,保存的文件是"xxx.ui"文件,"xxx.ui"可以被pyuic转换为"xxx.py",而&…...

【鸿蒙应用ArkTS开发系列】- 云开发入门实战二 实现省市地区三级联动地址选择器组件(下)
文章目录 概述端云调用流程端侧集成AGC SDK端侧省市地区联动的地址选择器组件开发创建省市数据模型创建省市地区视图UI子组件创建页面UI视图Page文件 打包测试总结 概述 我们在前面的课程,对云开发的入门做了介绍,以及使用一个省市地区联动的地址选择器…...
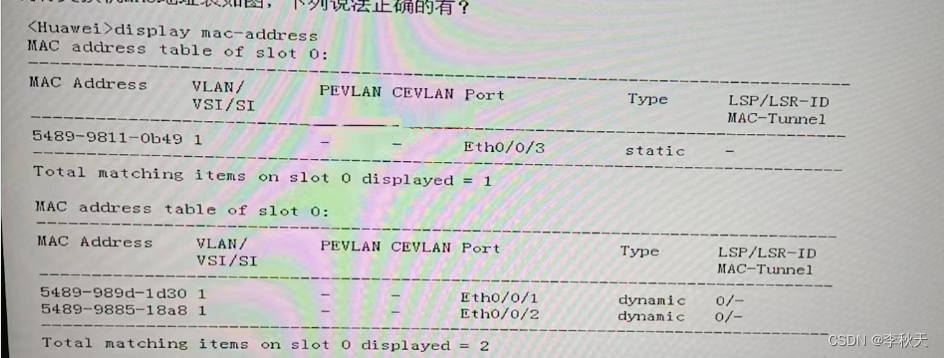
HCIA题目解析(1)
1、【多选题】关于动态 MAC 地址表说法正确的是? A、通过报文中的源MAC地址学习获得的动态MAC表项会老化 B、通过查看指定动态MAC地址表项的个数,可以获取接口下通信的用户数 C、在设备重启后,之前的动态表项会丢失 D、在设备重启后&…...

运维高级-day02
一、编写系统服务启动脚本 RHEL6风格 1、Linux运行级别 Linux运行有七个级别 级别 描述 0 停机状态,系统默认运行级别不能设置为0,否则系统不能正常启动。使用init0命令,可关闭系统 1 单用户状态,此状态仅root用户可登录。用…...
——实时通信系统的需求)
虹科分享 | 平衡速度和优先级:为多样化的实时需求打造嵌入式网络(2)——实时通信系统的需求
现代实时应用的复杂性和需求不断增加,需要强大而可靠的通信系统。正如本系列第一部分所述,这些应用涵盖从秒到毫秒的广泛响应时间要求,它们的成功通常取决于其响应的精确时间。因此,所选的通信系统必须能够满足这些严格的时序限制…...

佳易王各行业收银管理系统软件,企业ERP管理软件,企业或个体定制开发软件以及软件教程资源下载总目录,持续更新,可关注收藏查阅
系统简介 1、佳易王软件功能实用、操作简单、软件绿色免安装,解压即可使用,软件已经内置数据库,不需再安装其他数据库文件。 2、佳易王软件,已经形成系列,上百款管理系统软件涵盖多个行业。 3、已为多个企业个体定制…...

C_4练习题
一、单项选择题(本大题共20小题,每小题2分,共40分。在每小题给出的四个备选项中选出一个正确的答案,并将所选项前的字母填写在答题纸的相应位置上。) 定义如下变量和数组: int i; int x[3][3]{1,2,3,4,5,6,7,8,9}; 则下面语句的输…...

自动化测试-Selenium
一. Selenium介绍 selenium 是用来做web自动化测试的框架,支持各种浏览器,各种,支持各种语言 原理: 二. 元素定位 2.1 XPath 定位 绝对路径: /html/head/title 相对路径以双斜杠开头,常见的相对路径定位有以下几种: <1>相对路径索引: 索引是从1开始的 <2>相…...

基于单片机的温湿度检测系统设计
目录 摘 要... 2 第一章 绪论... 5 1.1 研究课题背景... 5 1.2 国内外发展概况... 7 1.3 课题研究的目的... 8 1.4 课题的研究内容及章节安排... 8 第二章 温湿度检测系统控制系统的设计方案... 10 2.1 设计任务及要求... 10 2.2 温湿度检测系统总体设计方…...

C# 关于异常处理 try-catch语句的使用
在实际应用中,比如涉及文件读写、网络通信时,会因为文件不存在、权限不够、网络异常等原因引发异常,或者对数据库连接、查询、更新等操作,会因为连接超时、语法错误、唯一约束冲突等引发异常。 看过去的代码,当进行上…...

锐捷交换机VSU配置实战:从基础到高可用部署
1. 锐捷交换机VSU功能初探 第一次接触锐捷交换机的VSU功能时,我完全被它的设计理念吸引了。简单来说,VSU(Virtual Switching Unit)就像把两台物理交换机"合体"成一个逻辑设备。想象一下,你家的双胞胎兄弟突…...
实战:从概念到UI交互的“标签”艺术)
Qt 动态属性(Dynamic Property)实战:从概念到UI交互的“标签”艺术
1. 动态属性:Qt界面开发的"智能标签" 第一次接触Qt动态属性时,我把它想象成便利贴。就像我们会在办公桌上给文件贴便利贴做标记一样,动态属性就是给Qt控件贴的"智能标签"。这个标签可以随时贴上、撕下,完全不…...

Spring Boot 3 整合 GraalVM 原生镜像:启动快 10 倍,内存省一半
本文基于一个真实电商订单查询服务的 Native Image 改造过程,从环境搭建到生产部署,包含所有踩坑细节与最终性能数据。版本环境: Spring Boot 3.2.4 GraalVM CE 21.0.2 Maven 3.9.6 Docker 24 CentOS 7背景:一个启动 12 秒的微…...
)
别再裸奔了!给若依前后端分离项目加上AES接口加密(Vue3 + Spring Boot保姆级配置)
若依框架前后端分离项目AES接口加密实战指南 在当今数据安全日益重要的环境下,企业级应用开发中接口传输的安全性已成为不可忽视的一环。许多开发者在使用若依这类优秀框架时,往往只关注功能实现而忽略了数据传输过程中的安全隐患。本文将带您从零开始&a…...

源码解读:拿下顶会最佳论文的重建式VLA,是如何实现的!
“如果模型能重建它,就说明它真正注意到了它” ——源码级解析 目录 01 问题的起点:为什么 VLA 需要“重建”? 02 系统架构总览 03 核心技术一:DiT 扩散去噪与 adaLN-Zero 条件注入 条件的构建与融合 adaLN-Zero 注入逻…...

嵌入式系统设计实践
嵌入式系统设计实践:连接数字与现实的桥梁 在智能设备无处不在的时代,嵌入式系统作为硬件与软件的完美结合体,悄然驱动着从智能家居到工业控制的各个领域。它不仅是技术的核心,更是创新应用的基石。本文将带你深入嵌入式系统设计…...

豆包大模型API实战:从零构建智能对话应用
1. 豆包大模型API初探:为什么选择它? 第一次接触豆包大模型时,我和很多开发者一样好奇:市面上大模型API这么多,为什么偏偏要选它?实测几个月后,我发现了三个真香定律:响应速度快得像…...
)
别再硬算拉格朗日乘子了!用Python+CMDP搞定带约束的强化学习任务(附代码)
用Python实战CMDP:避开数学陷阱的工程化实现指南 在资源分配、机器人控制等实际场景中,我们常常需要在特定约束条件下优化目标函数。传统强化学习虽然擅长寻找最优策略,但面对"总功耗不超过100W"或"平均响应时间必须小于200ms…...

新手避坑指南:超声波探伤仪A扫波形图到底怎么看?从杂波识别到缺陷定级的实战解析
新手避坑指南:超声波探伤仪A扫波形图到底怎么看?从杂波识别到缺陷定级的实战解析 第一次面对超声波探伤仪屏幕上跳动的波形时,那种茫然感我至今记忆犹新。屏幕上那些高低起伏的尖峰就像一道难以破解的密码,让人无从下手。作为过来…...
ABIDE数据集实战:从下载到预处理流程解析)
医学图像处理(三)ABIDE数据集实战:从下载到预处理流程解析
1. ABIDE数据集:自闭症脑成像研究的金钥匙 第一次接触ABIDE数据集时,我正为一个自闭症儿童脑功能连接项目犯愁。这个由纽约大学医学院牵头、全球17个研究中心共同构建的宝藏,包含了1112名受试者(539名自闭症患者573名正常对照&…...