4面试题--数据库(mysql)
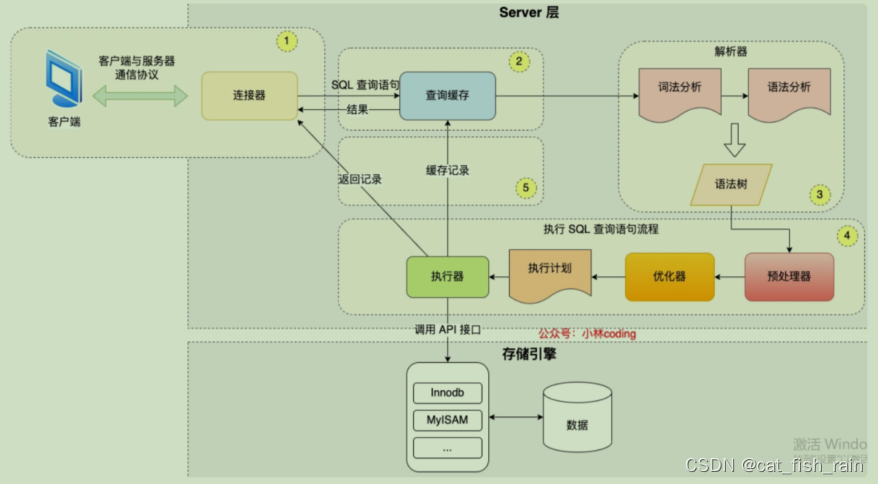
执⾏⼀条 select / update 语句,在 MySQL 中发⽣了什么?
4.1 三⼤范式
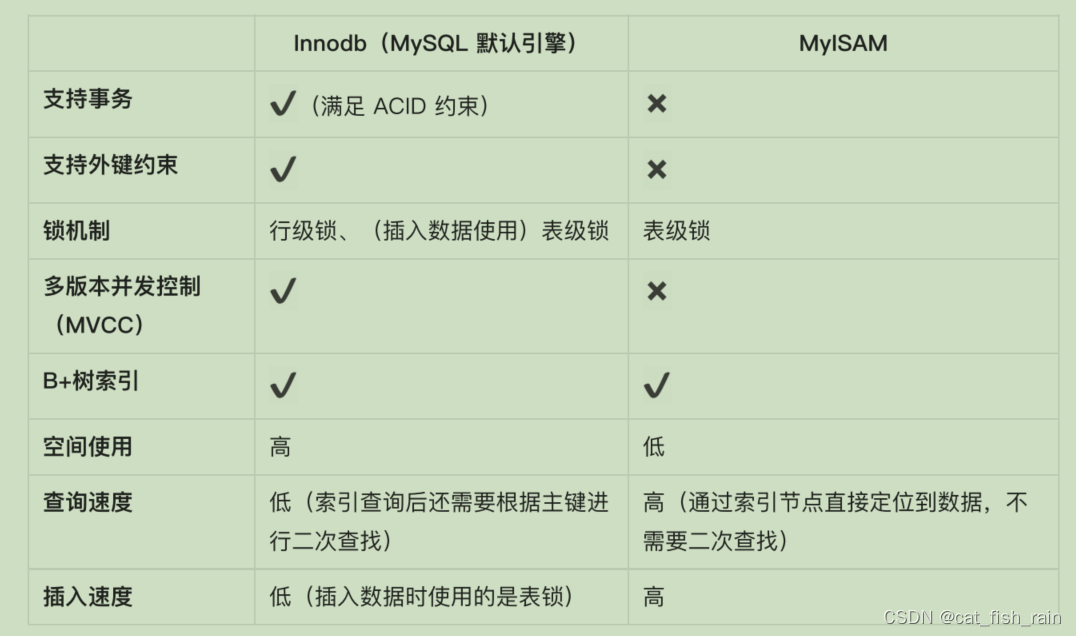
4.2 数据库引擎
Innodb
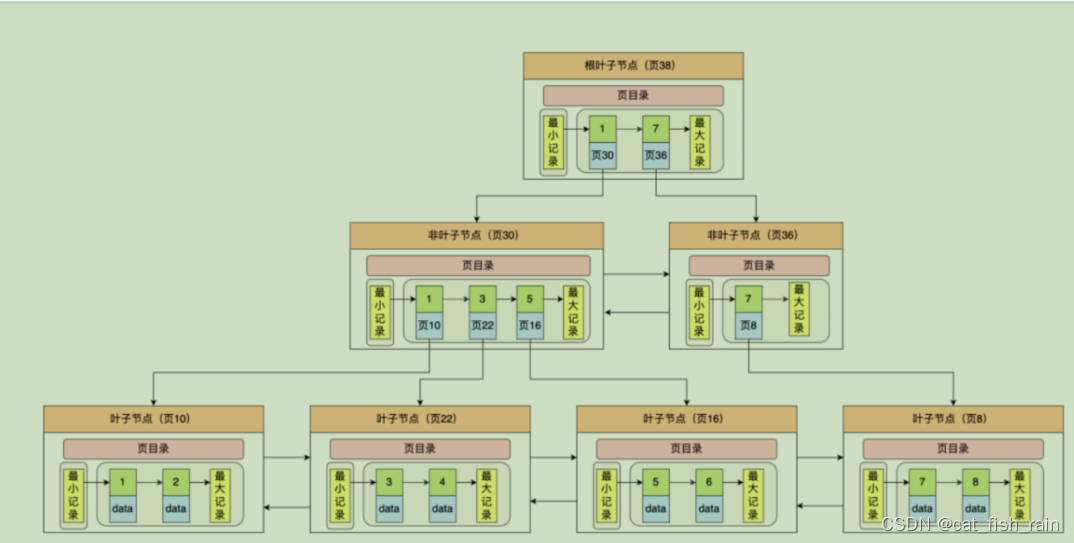
Buffer Pool
MyISAM
4.3 数据库索引
- 先查询⼆级索引(⼜叫⾮聚集索引,⼆级索引的 B+Tree 的叶⼦节点存放的是主键值,⽽不是实际数据)中的 B+Tree 的索引值,找到对应的叶⼦节点,然后获取主键值,之后再通过主键索引中的 B+Tree 树查询到对应的叶⼦节点,然后获取整⾏数据。这个过程叫「回表」,也就是说要查两个B+Tree 才能查到数据。
- 在⼆级索引的 B+Tree 就能查询到结果的⽅式就叫「覆盖索引」,也就是只需要查⼀个 B+Tree 就能找到数据。
- 全⽂索引 https://blog.csdn.net/mrzhouxiaofei/article/details/79940958
索引分类
唯⼀索引、主键的区别
索引优缺点
索引使⽤场景
优化索引⽅法
数据库为什么⽤ B+ 树做索引
B 与 B+ 树差异
联合索引与最左匹配原则

4.4 关系型数据库、⾮关系型数据库
关系型数据库(SQL)
⾮关系型数据库(NOSQL)
4.5 数据库连接池
4.6 事务
两阶段提交
相关文章:
4面试题--数据库(mysql)
执⾏⼀条 select / update 语句,在 MySQL 中发⽣了什么? Server 层负责建⽴连接、分析和执⾏ SQL。MySQL ⼤多数的核⼼功能模块都在这实现,主要包括 连接器,查询缓存(8.0版本去除,因为每次更新将会清空该…...

【LeeCode】283.移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 解【做的有点呆,额外设置了计数器变量统计0的个数再从后往前赋0】:…...
OSG粒子系统与阴影-自定义粒子系统示例<2>(5)
自定义粒子系统示例(二) 目前自定义粒子的方法有很多,在OSG 中使用的是 Billboard 技术与色彩融合技术。色彩融合是一种高级的渲染技术,如果读者有兴趣,可参看 OSG 粒子系统实现的源代码。这里采用简单的布告牌技术(osg::Billboard)与动画来实…...
微软 Edge 浏览器目前无法支持 avif 格式
avif 格式在微软 Edge 浏览器中还是没有办法支持。 如果你希望能够查看 avif 格式,那么只能通过浏览器打开,然后浏览器将会把这个文件格式下载到本地。 avif 格式已经在其他的浏览器上得到了广泛的支持,目前不支持的可能就只有 Edge 浏览器。…...

用python实现文字转语音的5个较好用的模块
文章目录 一. 用 gtts 模块二. 用pyttsx3模块基本使用直接朗读更改语音、速率和音量 三. baidu-aip四. pywin32五. speech 一. 用 gtts 模块 参考文档:https://gtts.readthedocs.io/en/latest/ 使用前需要先安装:pip3 install gtts ,样例如…...
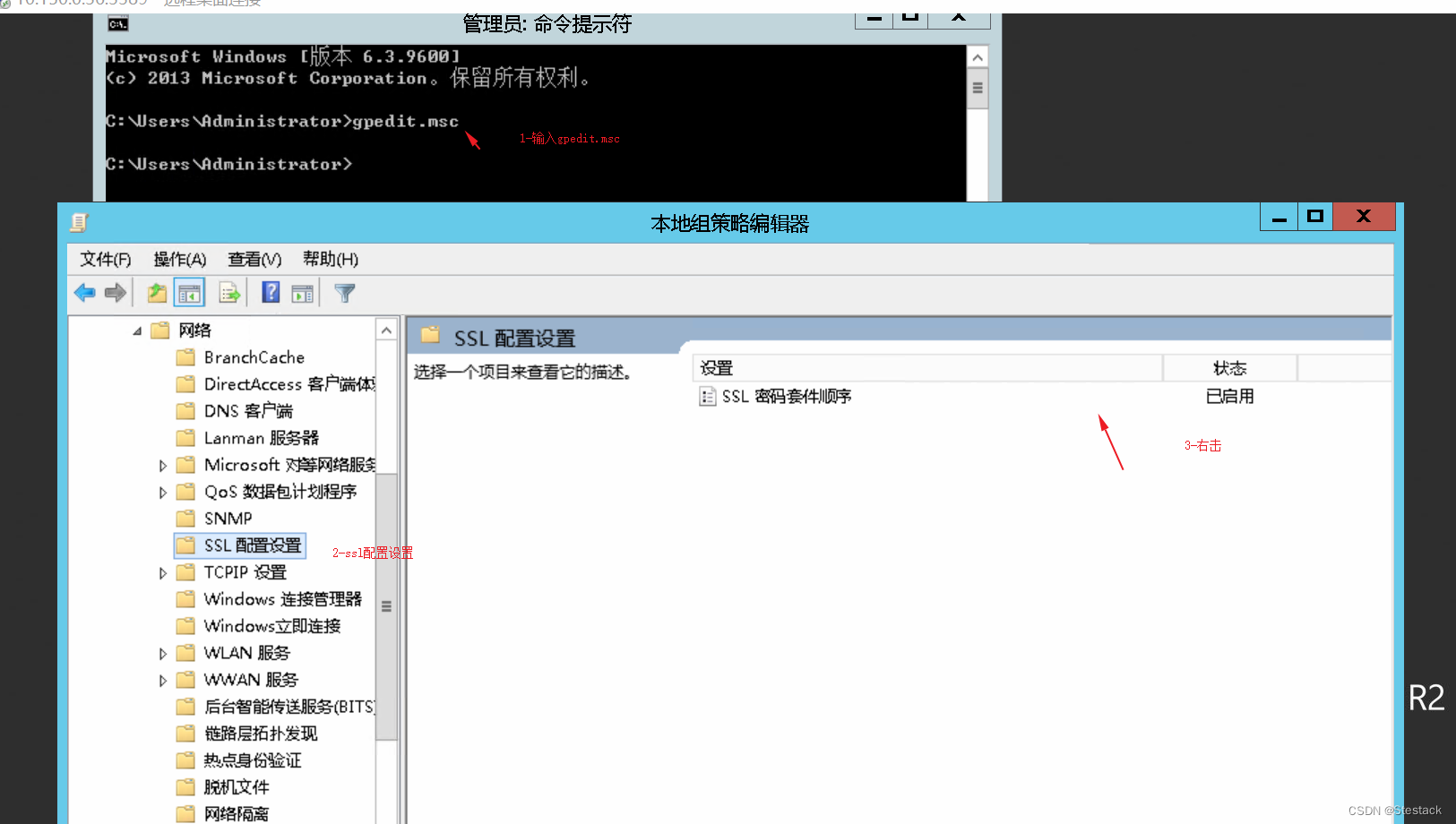
Windows Server 2012R2 修复CVE-2016-2183(SSL/TLS)漏洞的办法
一、漏洞说明 Windows server 2012R2远程桌面服务SSL加密默认是开启的,且有默认的CA证书。由于SSL/ TLS自身存在漏洞缺陷,当开启远程桌面服务,使用漏洞扫描工具扫描,发现存在SSL/TSL漏洞。远程主机支持的SSL加密算法提供了中等强度的加密算法,目前,使用密钥长度大于等于5…...

python统计字符串中大小写字符个数的性能实测与分析
给定一个字符串,统计字符串中大写字符个数,有如下三种方法: # method1 s1 len(re.findall(r[A-Z],content)) # method2 s2 sum(1 for c in content if c.isupper()) # method3 s3 0 for c in content:if c.isupper()True:s31经过多次实测…...

时间序列预测实战(十九)魔改Informer模型进行滚动长期预测(科研版本)
论文地址->Informer论文地址PDF点击即可阅读 代码地址-> 论文官方代码地址点击即可跳转下载GIthub链接 个人魔改版本地址-> 文章末尾 一、本文介绍 在之前的文章中我们已经讲过Informer模型了,但是呢官方的预测功能开发的很简陋只能设定固定长度去预测未…...
[PyTorch][chapter 64][强化学习-DQN]
前言: DQN 就是结合了深度学习和强化学习的一种算法,最初是 DeepMind 在 NIPS 2013年提出,它的核心利润包括马尔科夫决策链以及贝尔曼公式。 Q-learning的核心在于Q表格,通过建立Q表格来为行动提供指引,但这适用于状态…...
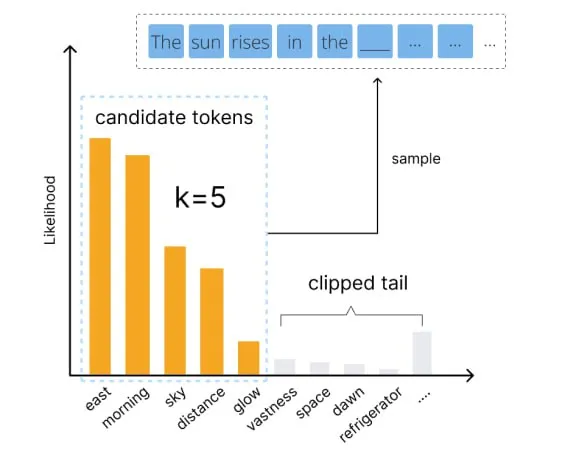
用好语言模型:temperature、top-p等核心参数解析
编者按:我们如何才能更好地控制大模型的输出? 本文将介绍几个关键参数,帮助读者更好地理解和运用 temperature、top-p、top-k、frequency penalty 和 presence penalty 等常见参数,以优化语言模型的生成效果。 文章详细解释了这些参数的作用…...

python之pycryptodome模块,加密算法库
一、简介 PyCryptodome是PyCrypto库的一个分支,它是Python中最受欢迎的密码学库之一。PyCryptodome提供了许多密码学算法和协议的实现,包括对称加密、非对称加密、消息摘要、密码哈希、数字签名等。它还提供了一些其他功能,如密码学安全随机…...

IDEA如何将本地项目推送到GitHub上?
大家好,我是G探险者。 IntelliJ IDEA 是一个强大的集成开发环境(IDE),它支持多种编程语言和工具。它也内置了对Git和GitHub的支持,让开发者可以轻松地将本地项目推送到GitHub上。以下是一个操作手册,描述了…...
Leetcode—45.跳跃游戏II【中等】
2023每日刷题(四十) Leetcode—45.跳跃游戏II 贪心法思想 实现代码 #define MAX(a, b) (a > b ? (a) : (b))int jump(int* nums, int numsSize) {int start 0;int end 1;int ans 0;int maxStride 0;while(end < numsSize) {maxStride 0;fo…...

基于Vue+SpringBoot的木马文件检测系统
项目编号: S 041 ,文末获取源码。 \color{red}{项目编号:S041,文末获取源码。} 项目编号:S041,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 木马分类模块2.3 木…...

springboot内置Tomcat流程
1、org.springframework.boot.SpringApplication#initialize setInitializers((Collection) getSpringFactoriesInstances(ApplicationContextInitializer.class));加载了org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext 2、spring refres…...

Android修行手册-溢出父布局的按钮实现点击
Unity3D特效百例案例项目实战源码Android-Unity实战问题汇总游戏脚本-辅助自动化Android控件全解手册再战Android系列Scratch编程案例软考全系列Unity3D学习专栏蓝桥系列ChatGPT和AIGC 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分…...
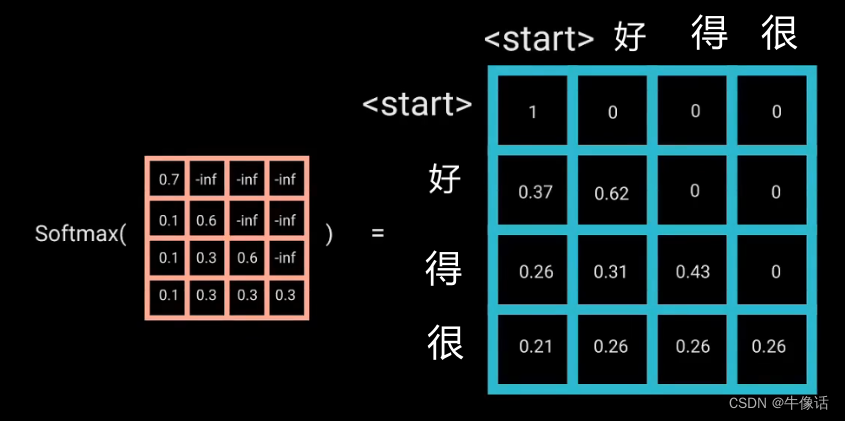
Transformer——decoder
上一篇文章,我们介绍了encoder,这篇文章我们将要介绍decoder Transformer-encoder decoder结构: 如果看过上一篇文章的同学,肯定对decoder的结构不陌生,从上面框中可以明显的看出: 每个Decoder Block有两个…...

基于 STM32 的温度测量与控制系统设计
本文介绍了如何基于 STM32 微控制器设计一款温度测量与控制系统。首先,我们将简要介绍 STM32 微控制器的特点和能力。接下来,我们将详细讨论温度传感器的选择与接口。然后,我们将介绍如何使用 STM32 提供的开发工具和相关库来进行温度测量和控…...
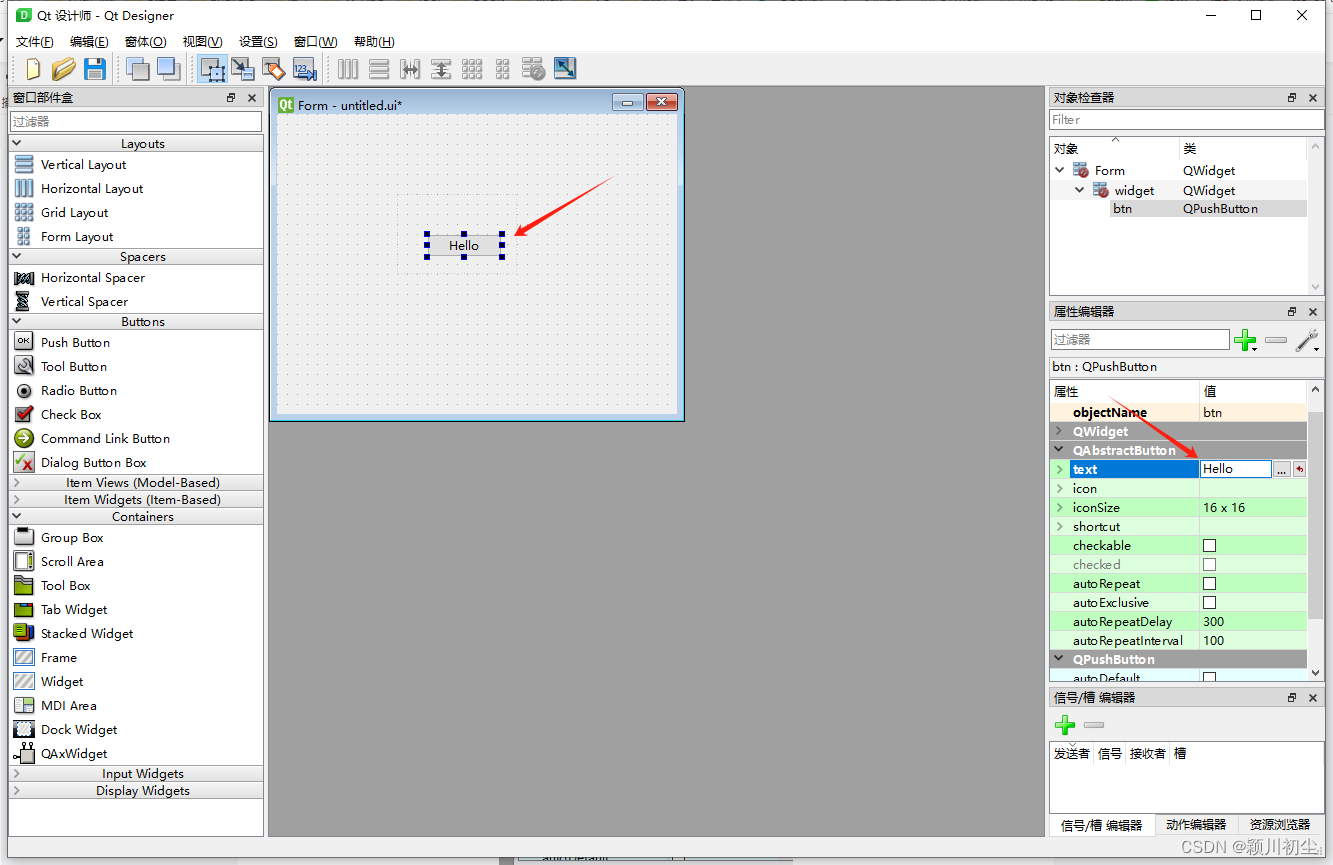
python之pyqt专栏3-QT Designer
从前面两篇文章python之pyqt专栏1-环境搭建与python之pyqt专栏2-项目文件解析,我们对QT Designer有基础的认识。 QT Designer用来创建UI界面,保存的文件是"xxx.ui"文件,"xxx.ui"可以被pyuic转换为"xxx.py",而&…...

【鸿蒙应用ArkTS开发系列】- 云开发入门实战二 实现省市地区三级联动地址选择器组件(下)
文章目录 概述端云调用流程端侧集成AGC SDK端侧省市地区联动的地址选择器组件开发创建省市数据模型创建省市地区视图UI子组件创建页面UI视图Page文件 打包测试总结 概述 我们在前面的课程,对云开发的入门做了介绍,以及使用一个省市地区联动的地址选择器…...

C 语言教程
C 语言教程C 语言是一种通用的、面向过程式的计算机程序设计语言。1972 年,为了移植与开发 UNIX 操作系统,丹尼斯里奇在贝尔电话实验室设计开发了 C 语言。 C 语言是一种广泛使用的计算机语言,它与 Java 编程语言一样普及,二者在现…...
SeaTunnel Transform插件实战:从零构建自定义JSON解析器
1. 为什么需要自定义JSON解析器 在实际的数据处理场景中,我们经常会遇到各种复杂的JSON格式数据。就拿最常见的日志处理来说,从Kafka等消息队列获取的原始数据往往包含多层嵌套的JSON结构。比如下面这个典型例子: {"path": "x…...
)
告别命令行:用ChatboxAI给本地DeepSeek模型做个漂亮GUI(Ollama篇)
告别命令行:用ChatboxAI给本地DeepSeek模型做个漂亮GUI(Ollama篇) 在探索本地大语言模型的世界时,许多技术爱好者都会遇到一个共同的痛点:虽然通过Ollama命令行成功运行了模型,但交互体验始终停留在黑底白字…...
)
P1618三连击 (暴力+枚举)
P1618 三连击(升级版) 题目描述 将 1,2,…,91, 2,\ldots, 91,2,…,9 共 999 个数分成三组,分别组成三个三位数,且使这三个三位数的比例是 A:B:CA:B:CA:B:C,试求出所有满足条件的三个三位数,若无解ÿ…...

如何用EZCard快速批量制作桌游卡牌:400%效率提升的终极指南
如何用EZCard快速批量制作桌游卡牌:400%效率提升的终极指南 【免费下载链接】CardEditor 一款专为桌游设计师开发的批处理数值填入卡牌生成器/A card batch generator specially developed for board game designers 项目地址: https://gitcode.com/gh_mirrors/ca…...

基于FPGA的蓝牙避障循迹小车设计与实现
1. 项目背景与核心功能 这个小车项目最吸引人的地方在于它把FPGA的并行处理能力和多种传感器完美结合。想象一下,你手里拿着手机用蓝牙控制小车前进,突然前方出现障碍物,小车能自动避开;或者放在地上,它能沿着黑线自动…...

07_NVIDIA Triton Java API:企业级高性能推理服务
NVIDIA Triton Java API:企业级高性能推理服务 摘要:NVIDIA Triton 是业界最先进的模型推理服务软件,支持多框架并发执行和动态批处理。本文深入解析 Triton 架构、Java API 的两种形态、TensorRT-LLM 后端集成,以及如何构建高性能…...

如何适配自定义激光雷达数据到LIO-SAM:解决ring和time参数缺失问题
非标准激光雷达与LIO-SAM的深度适配指南:从参数解析到实战优化 当开发者尝试将速腾、Livox等非Velodyne雷达接入LIO-SAM框架时,往往会遇到两个关键障碍:点云数据中缺少ring(线束编号)和time(时间戳…...

智能网络边界守护者:OpenWrt访问控制插件深度实践指南
智能网络边界守护者:OpenWrt访问控制插件深度实践指南 【免费下载链接】luci-access-control OpenWrt internet access scheduler 项目地址: https://gitcode.com/gh_mirrors/lu/luci-access-control 在万物互联的时代,家庭网络已不再是简单的上网…...
)
混合储能系统与光储微网:基于下垂控制的Simulink仿真研究(2021A版)
混合储能系统/光储微网/下垂控制/Simulink仿真 注意版本2021A以上!!!! 由光伏发电系统和混合储能系统构成直流微网。 混合储能系统由超级电容器和蓄电池构成,通过控制混合储能系统来维持直流母线电压稳定。 混合储能系…...