spark的算子
spark的算子

1.spark的单Value算子
Spark中的单Value算子是指对一个RDD中的每个元素进行操作,并返回一个新的RDD。下面详细介绍一些常用的单Value算子及其功能:
- map:逐条映射,将RDD中的每个元素通过指定的函数转换成另一个值,最终返回一个新的RDD。
rdd = sc.parallelize([1, 2, 3, 4, 5])
result = rdd.map(lambda x: x * 2)
# result: [2, 4, 6, 8, 10]
- flatMap: 扁平化映射,将RDD中的每个元素通过指定的函数转换成多个值,并将这些值展开为一个新的RDD。
rdd = sc.parallelize([1, 2, 3, 4, 5])
result = rdd.flatMap(lambda x: range(x, x+3))
# result: [1, 2, 3, 2, 3, 4, 3, 4, 5, 4, 5, 6, 5, 6, 7]
- glom:将一个分区中的多个单条数据转换为相同类型的单个数组进行处理。返回一个新的RDD,其中每个元素是一个数组。
rdd = sc.parallelize([1, 2, 3, 4, 5], 2) # 两个分区
result = rdd.glom().collect()
# result: [[1, 2], [3, 4, 5]]
- groupBy: 将RDD中的元素按照指定条件分组,返回一个键值对RDD,其中的每个元素是一个(key, iterator)对,key为分组的条件,iterator为对应分组的元素迭代器。
rdd = sc.parallelize(['apple', 'banana', 'cherry', 'date'])
result = rdd.groupBy(lambda x: x[0])
# result: [('a', ['apple']), ('b', ['banana']), ('c', ['cherry']), ('d', ['date'])]
- filter:根据指定的规则过滤出符合条件的元素,返回一个新的RDD。
rdd = sc.parallelize([1, 2, 3, 4, 5])
result = rdd.filter(lambda x: x % 2 == 0)
# result: [2, 4]
- sample:从RDD中进行采样,返回一个包含采样结果的新的RDD。
rdd = sc.parallelize(range(10))
result = rdd.sample(False, 0.5)
# result: [0, 2, 3, 4, 5, 7]
- distinct(shuffle):去重,将RDD中重复的元素去除,返回一个由不重复元素组成的新的RDD。
rdd = sc.parallelize([1, 2, 2, 3, 3, 3])
result = rdd.distinct()
# result: [1, 2, 3]
- coalesce(shuffle):缩减分区,将RDD的分区数缩减为指定的数量。
rdd = sc.parallelize([1, 2, 3, 4, 5], 4) # 4个分区
result = rdd.coalesce(2)
# result: [1, 2, 3, 4, 5](分区数变为2)
- repartition(shuffle):扩增分区数,底层是coalesce。将RDD的分区数扩增到指定的数量。
rdd = sc.parallelize([1, 2, 3, 4, 5], 2) # 2个分区
result = rdd.repartition(4)
# result: [1, 2], [3, 4], [5](分区数变为4)
- sortBy(shuffle):根据指定的规则对数据源中的数据进行排序,默认为升序。
rdd = sc.parallelize([3, 1, 4, 2, 5])
result = rdd.sortBy(lambda x: x)
# result: [1, 2, 3, 4, 5]
这些单Value算子能够对RDD中的每个元素进行处理,并返回一个新的RDD,可以用于各种数据转换、过滤、去重等操作。
2. Spark的双Value算子
双Value算子是指对两个RDD进行操作,并返回一个新的RDD。下面介绍一些常用的双Value算子及其功能:
- union: 对两个RDD求并集,返回包含两个RDD中所有元素的新RDD。
rdd1 = sc.parallelize([1, 2, 3])
rdd2 = sc.parallelize([3, 4, 5])
result = rdd1.union(rdd2)
# result: [1, 2, 3, 3, 4, 5]
- intersection: 对两个RDD求交集,返回包含两个RDD中共有元素的新RDD。
rdd1 = sc.parallelize([1, 2, 3])
rdd2 = sc.parallelize([3, 4, 5])
result = rdd1.intersection(rdd2)
# result: [3]
- subtract: 对两个RDD求差集,返回只属于第一个RDD而不属于第二个RDD的元素的新RDD。
rdd1 = sc.parallelize([1, 2, 3])
rdd2 = sc.parallelize([3, 4, 5])
result = rdd1.subtract(rdd2)
# result: [1, 2]
- cartesian: 对两个RDD进行笛卡尔积操作,返回所有可能的元素对组成的新RDD。
rdd1 = sc.parallelize([1, 2])
rdd2 = sc.parallelize(['a', 'b'])
result = rdd1.cartesian(rdd2)
# result: [(1, 'a'), (1, 'b'), (2, 'a'), (2, 'b')]
- zip: 将两个RDD的元素按照索引位置进行配对,返回键值对组成的新RDD。
rdd1 = sc.parallelize([1, 2, 3])
rdd2 = sc.parallelize(['a', 'b', 'c'])
result = rdd1.zip(rdd2)
# result: [(1, 'a'), (2, 'b'), (3, 'c')]
- join: 对两个键值对RDD进行内连接操作,返回具有相同键的元素对组成的新RDD。
rdd1 = sc.parallelize([(1, 'apple'), (2, 'banana')])
rdd2 = sc.parallelize([(1, 'red'), (2, 'yellow')])
result = rdd1.join(rdd2)
# result: [(1, ('apple', 'red')), (2, ('banana', 'yellow'))]
- leftOuterJoin: 对两个键值对RDD进行左外连接操作,返回左侧RDD中所有元素以及与之匹配的右侧RDD中的元素对组成的新RDD。
rdd1 = sc.parallelize([(1, 'apple'), (2, 'banana')])
rdd2 = sc.parallelize([(1, 'red'), (3, 'yellow')])
result = rdd1.leftOuterJoin(rdd2)
# result: [(1, ('apple', 'red')), (2, ('banana', None))]
- rightOuterJoin: 对两个键值对RDD进行右外连接操作,返回右侧RDD中所有元素以及与之匹配的左侧RDD中的元素对组成的新RDD。
rdd1 = sc.parallelize([(1, 'apple'), (2, 'banana')])
rdd2 = sc.parallelize([(1, 'red'), (3, 'yellow')])
result = rdd1.rightOuterJoin(rdd2)
# result: [(1, ('apple', 'red')), (3, (None, 'yellow'))]
这些双Value算子能够对两个RDD进行操作,并返回一个新的RDD,可以用于求并集、交集、差集等操作,也可以进行连接操作,根据键值对进行配对。
3. Spark的Key-Value算子
Key-Value算子是指对键值对RDD进行操作的算子,这些算子主要用于处理具有键值对结构的数据,其中键位于第一列,值位于第二列。下面介绍一些常用的Key-Value算子及其功能:
- reduceByKey: 对具有相同键的元素进行聚合操作,返回一个新的键值对RDD。
rdd = sc.parallelize([(1, 2), (1, 3), (2, 4), (2, 5)])
result = rdd.reduceByKey(lambda x, y: x + y)
# result: [(1, 5), (2, 9)]
- groupByKey: 对具有相同键的元素进行分组操作,返回一个新的键值对RDD。
rdd = sc.parallelize([(1, 2), (1, 3), (2, 4), (2, 5)])
result = rdd.groupByKey()
# result: [(1, <pyspark.resultiterable.ResultIterable object at 0x7f3128a3e370>), (2, <pyspark.resultiterable.ResultIterable object at 0x7f3128a3e3d0>)]
- sortByKey: 按照键的顺序对RDD进行排序操作,默认升序排列。
rdd = sc.parallelize([(3, 'apple'), (1, 'banana'), (2, 'orange')])
result = rdd.sortByKey()
# result: [(1, 'banana'), (2, 'orange'), (3, 'apple')]
- mapValues: 对键值对RDD中的值进行操作,返回一个新的键值对RDD。
rdd = sc.parallelize([(1, 'apple'), (2, 'banana')])
result = rdd.mapValues(lambda x: 'fruit ' + x)
# result: [(1, 'fruit apple'), (2, 'fruit banana')]
- flatMapValues: 对键值对RDD中的值进行扁平化操作,返回一个新的键值对RDD。
rdd = sc.parallelize([(1, 'hello world'), (2, 'goodbye')])
result = rdd.flatMapValues(lambda x: x.split())
# result: [(1, 'hello'), (1, 'world'), (2, 'goodbye')]
- keys: 返回所有键组成的一个新的RDD。
rdd = sc.parallelize([(1, 'apple'), (2, 'banana')])
result = rdd.keys()
# result: [1, 2]
- values: 返回所有值组成的一个新的RDD。
rdd = sc.parallelize([(1, 'apple'), (2, 'banana')])
result = rdd.values()
# result: ['apple', 'banana']
除了上述提到的常用Key-Value算子,还有一些其他常见的Key-Value算子,它们在处理键值对RDD时也非常有用。以下是其中几个:
- countByKey: 统计每个键出现的次数,返回一个字典。
rdd = sc.parallelize([(1, 'apple'), (1, 'banana'), (2, 'orange'), (2, 'banana')])
result = rdd.countByKey()
# result: {1: 2, 2: 2}
- collectAsMap: 将键值对RDD转换为字典形式。
rdd = sc.parallelize([(1, 'apple'), (2, 'banana')])
result = rdd.collectAsMap()
# result: {1: 'apple', 2: 'banana'}
- lookup: 查找具有给定键的所有值,并返回一个列表。
rdd = sc.parallelize([(1, 'apple'), (2, 'banana'), (1, 'orange')])
result = rdd.lookup(1)
# result: ['apple', 'orange']
- foldByKey: 对具有相同键的元素进行折叠操作,类似于reduceByKey,但可以指定初始值。
rdd = sc.parallelize([(1, 2), (1, 3), (2, 4), (2, 5)])
result = rdd.foldByKey(0, lambda x, y: x + y)
# result: [(1, 5), (2, 9)]
- aggregateByKey: 对具有相同键的元素进行聚合操作,可以指定初始值和两个函数:一个用于局部聚合,另一个用于全局聚合。
rdd = sc.parallelize([(1, 2), (1, 3), (2, 4), (2, 5)])
result = rdd.aggregateByKey(0, lambda x, y: x + y, lambda x, y: x + y)
# result: [(1, 5), (2, 9)]
这些Key-Value算子能够对键值对RDD进行操作,实现聚合、分组、排序、映射等功能。使用这些算子可以更方便地处理具有键值对结构的数据。
相关文章:
spark的算子
spark的算子 1.spark的单Value算子 Spark中的单Value算子是指对一个RDD中的每个元素进行操作,并返回一个新的RDD。下面详细介绍一些常用的单Value算子及其功能: map:逐条映射,将RDD中的每个元素通过指定的函数转换成另一个值&am…...

【科技素养】蓝桥杯STEMA 科技素养组模拟练习试卷7
1、一袋小球中有15个白球,3个红球和2个黑球。在随机从袋子中拿出至少()个小球后,才可以保证至少拿出了5个白球 A、5 B、10 C、8 D、15 答案:B 2、以下选项中,数值最接近十进制数114的是( &…...
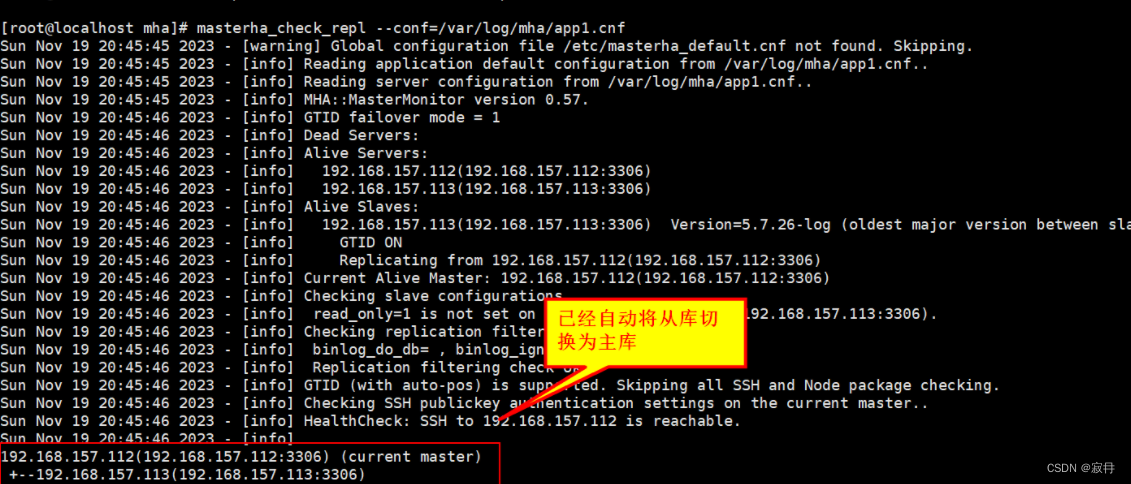
MySQL MHA高可用架构搭建
快捷查看指令 ctrlf 进行搜索会直接定位到需要的知识点和命令讲解(如有不正确的地方欢迎各位小伙伴在评论区提意见,博主会及时修改) MySQL MHA高可用架构搭建 MHA(Master HA)是一款开源的 MySQL 的高可用程序…...

UE小计:顶部工具栏按钮添加下拉列表,大纲列表、资源管理窗口右键添加按键
下拉列表 void FYouPluginsModule::StartupModule() {FYouToolStyle::Initialize();FYouToolStyle::ReloadTextures();FYouToolCommands::Register();PluginCommands MakeShareable(new FUICommandList);PluginCommands->MapAction(FYouToolCommands::Get().PackByCloudAc…...
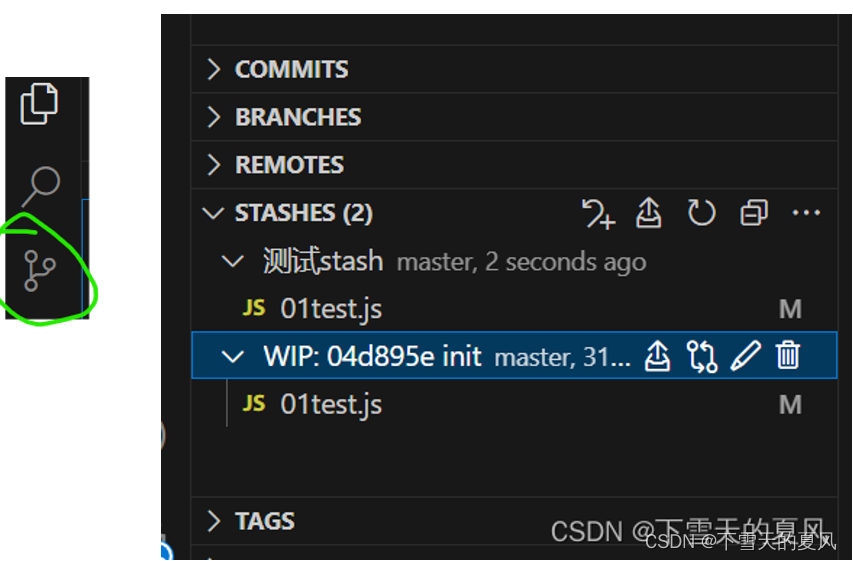
git stash 用法总结
目录 1,介绍场景1:场景2: 2,常用命令2.1,基础2.2,进阶1,存储时指定备注2,通过索引来操作指定的存储3,修改存储规则 2.3,查看 stash 修改的具体内容 1…...
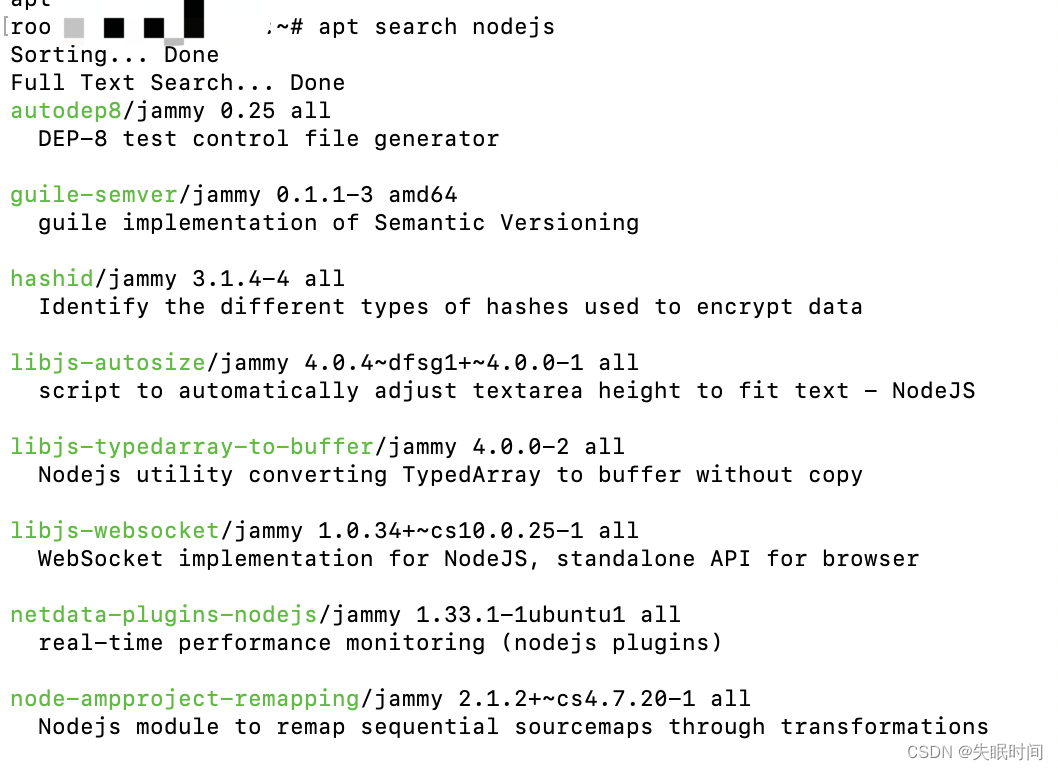
Linux操作系统之apt常用命令记录
文章目录 apt 命令apt 语法apt 常用命令列出所有可更新的软件清单命令升级软件包列出可更新的软件包及版本信息升级软件包,升级前先删除需要更新软件包安装指定的软件命令:安装多个软件包:更新指定的软件命令显示软件包具体信息,例如…...
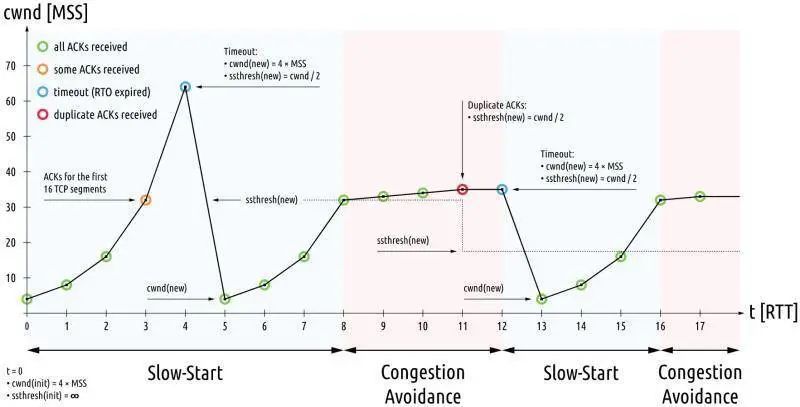
TCP 重传、滑动窗口、流量控制、拥塞控制的剖析
TCP 是一个可靠传输的协议,那它是如何保证可靠的呢? 为了实现可靠性传输,需要考虑很多事情,例如数据的破坏、丢包、重复以及分片顺序混乱等问题。如不能解决这些问题,也就无从谈起可靠传输。 那么,TCP 是…...
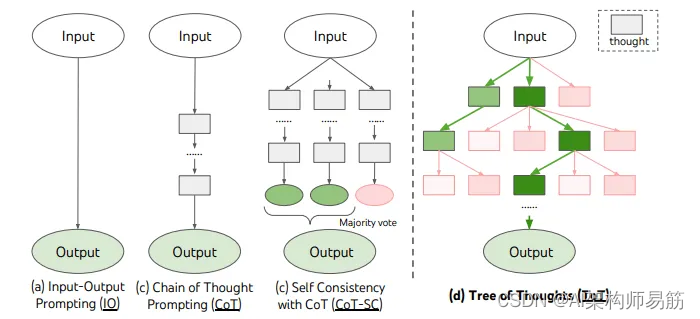
LangChain 11实现思维树Implementing the Tree of Thoughts in LangChain’s Chain
思维之树( Tree of Thoughts ToT)是一个算法,它结合了普林斯顿大学和谷歌DeepMind在本文中提出的大型语言模型(LLMs)和启发式搜索。看起来这个算法正在被实现到谷歌正在开发的多模式生成AI Gemini中。 现在࿰…...

Drools 7 Modify 和对象直接赋值差异
modify代表修改fact,会再次触发符合条件的rule对象直接修改只是java 操作,不会会再次触发符合条件的rule 以下为测试代码-drl部分 package org.drools.learnimport org.drools.learn.ModifyTest.Message;global java.util.List listrule "Stateles…...
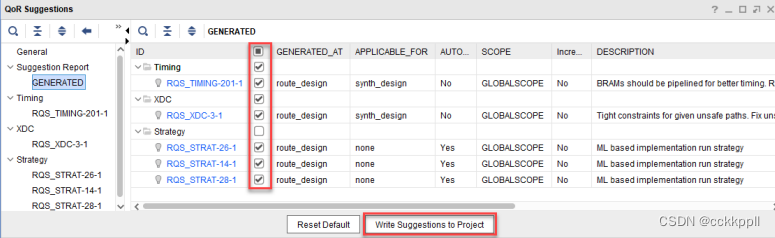
vivado产生报告阅读分析21
其他命令选项 • -of_objects <suggestion objects> : 启用特定建议的报告。在此模式下运行时 , report_qor_suggestions 不会生成新建议。此命令可快速执行 , 读取 RQS 文件后 , 此命令可用于查看其中包 含的建议。其…...

9.Docker的虚悬镜像-Dangling Image
1.虚悬镜像的概念 虚悬镜像 (Dangling Image) 指的是仓库名 (镜像名) 和标签 TAG 都是 的镜像。 2.构建本地虚悬镜像 这里我以unbuntu为例来说明。 2.1 编写Dockerfile文件 FROM ubuntu:22.042.2 根据Dockerfile文件构建虚悬镜像 docker build .上面这段命令,…...

02- OpenCV:加载、修改、保存图像
目录 1、加载图像(cv::imread) 2、显示图像 (cv::namedWindos 与cv::imshow) 3、修改图像 (cv::cvtColor) 4、保存图像(cv::imwrite) 5、代码演示 1、加载图像(cv::imread) cv::imread 是 OpenCV 库中用于读取图像文件的函数…...

4面试题--数据库(mysql)
执⾏⼀条 select / update 语句,在 MySQL 中发⽣了什么? Server 层负责建⽴连接、分析和执⾏ SQL。MySQL ⼤多数的核⼼功能模块都在这实现,主要包括 连接器,查询缓存(8.0版本去除,因为每次更新将会清空该…...

【LeeCode】283.移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 解【做的有点呆,额外设置了计数器变量统计0的个数再从后往前赋0】:…...
OSG粒子系统与阴影-自定义粒子系统示例<2>(5)
自定义粒子系统示例(二) 目前自定义粒子的方法有很多,在OSG 中使用的是 Billboard 技术与色彩融合技术。色彩融合是一种高级的渲染技术,如果读者有兴趣,可参看 OSG 粒子系统实现的源代码。这里采用简单的布告牌技术(osg::Billboard)与动画来实…...
微软 Edge 浏览器目前无法支持 avif 格式
avif 格式在微软 Edge 浏览器中还是没有办法支持。 如果你希望能够查看 avif 格式,那么只能通过浏览器打开,然后浏览器将会把这个文件格式下载到本地。 avif 格式已经在其他的浏览器上得到了广泛的支持,目前不支持的可能就只有 Edge 浏览器。…...

用python实现文字转语音的5个较好用的模块
文章目录 一. 用 gtts 模块二. 用pyttsx3模块基本使用直接朗读更改语音、速率和音量 三. baidu-aip四. pywin32五. speech 一. 用 gtts 模块 参考文档:https://gtts.readthedocs.io/en/latest/ 使用前需要先安装:pip3 install gtts ,样例如…...
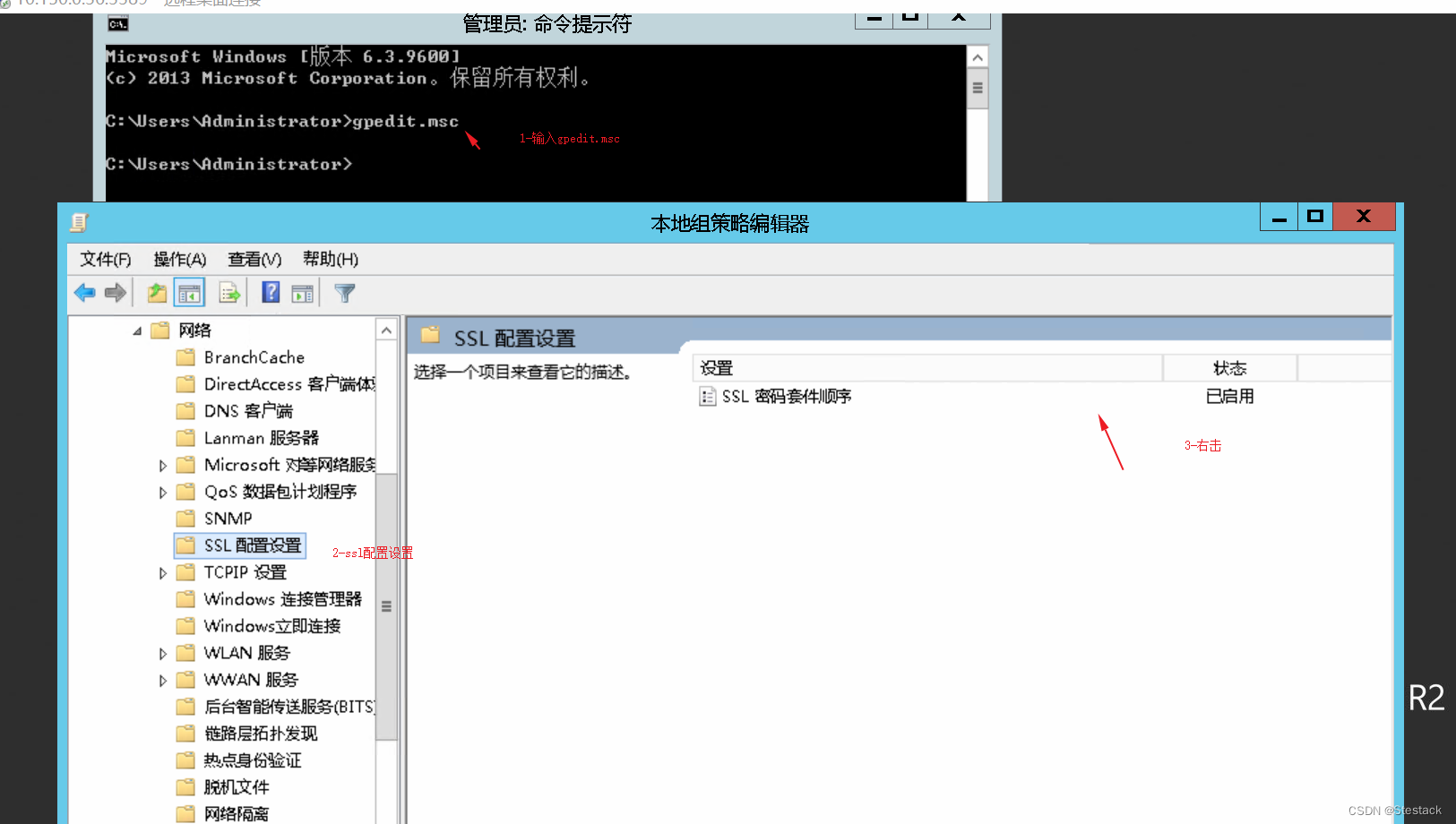
Windows Server 2012R2 修复CVE-2016-2183(SSL/TLS)漏洞的办法
一、漏洞说明 Windows server 2012R2远程桌面服务SSL加密默认是开启的,且有默认的CA证书。由于SSL/ TLS自身存在漏洞缺陷,当开启远程桌面服务,使用漏洞扫描工具扫描,发现存在SSL/TSL漏洞。远程主机支持的SSL加密算法提供了中等强度的加密算法,目前,使用密钥长度大于等于5…...

python统计字符串中大小写字符个数的性能实测与分析
给定一个字符串,统计字符串中大写字符个数,有如下三种方法: # method1 s1 len(re.findall(r[A-Z],content)) # method2 s2 sum(1 for c in content if c.isupper()) # method3 s3 0 for c in content:if c.isupper()True:s31经过多次实测…...

时间序列预测实战(十九)魔改Informer模型进行滚动长期预测(科研版本)
论文地址->Informer论文地址PDF点击即可阅读 代码地址-> 论文官方代码地址点击即可跳转下载GIthub链接 个人魔改版本地址-> 文章末尾 一、本文介绍 在之前的文章中我们已经讲过Informer模型了,但是呢官方的预测功能开发的很简陋只能设定固定长度去预测未…...

【GitHub项目推荐--Plane:开源版 JIRA,让项目管理回归“有序”】⭐⭐⭐
GitHub 地址:https://github.com/makeplane/plane 简介 Plane 是一个现代化的开源项目管理平台,被广泛认为是 JIRA、Linear 和 Asana 的开源替代品。它专为追求效率的研发和产品团队设计,将问题跟踪、敏捷迭代、文档协作和产品路线图统一在…...

《苍穹外卖》实战:从零到一构建高并发外卖系统核心笔记
1. 公共字段自动填充的工程化实践 第一次看到《苍穹外卖》项目里那些重复出现的创建人、创建时间、修改人、修改时间字段时,我就意识到这绝对是个需要优化的地方。每个实体类都手动维护这些字段,不仅容易出错,后期维护更是噩梦。好在Spring A…...
)
从B+到C+++:手把手教你根据传输距离选对GPON光模块(附实战配置案例)
从B到C:手把手教你根据传输距离选对GPON光模块(附实战配置案例) 光纤到户(FTTH)的普及让GPON技术成为宽带接入网的主流选择。作为一名经常需要部署OLT设备的工程师,我深刻体会到光模块选型对网络质量的影响…...

ByteTrack目标跟踪实战:C++版从部署到优化全流程解析
ByteTrack目标跟踪实战:C版从部署到优化全流程解析 在计算机视觉领域,目标跟踪技术正逐渐成为智能监控、自动驾驶等场景的核心组件。而ByteTrack作为ECCV 2022提出的创新算法,以其简洁的设计思路和出色的性能表现,正在工业界获得广…...

OBS Studio实战:SRT推流配置全解析与性能优化
1. SRT协议与OBS推流基础认知 第一次接触SRT协议是在去年帮一个电竞战队调试直播系统时。当时他们需要把比赛画面从上海传到洛杉矶的服务器,普通RTMP推流延迟高达3秒,选手操作和海外观众看到的画面完全不同步。换成SRT后延迟直接降到800毫秒以内…...

Doris Catalog实战指南:从创建到多源数据联邦查询
1. Doris Catalog核心概念解析 Doris Catalog是Apache Doris实现多源数据联邦查询的核心组件,简单理解它就像是数据世界的"图书馆管理员"。想象一下,你走进一个巨大的图书馆,里面有来自不同出版社(数据源)的…...

Python趣味编程实战:从数学谜题到数据处理
1. 数学谜题的Python解法 数学谜题是编程入门的绝佳练习素材。我刚开始学Python时,就特别喜欢用代码解决各种数学问题。比如这个经典题目:找出所有百位是3、十位是6,且能被2和3整除的四位数。 numbers range(1000, 10000) result [] for nu…...

【多模态大模型容灾备份黄金标准】:20年AI基础设施专家亲授3层异构备份架构与RTO<2分钟实战方案
第一章:多模态大模型容灾备份策略 2026奇点智能技术大会(https://ml-summit.org) 多模态大模型(如融合视觉、语音、文本与结构化数据的统一架构)在训练与推理过程中对存储一致性、状态可恢复性及跨模态特征对齐提出了远超单模态模型的容灾要…...
)
图解UEFI启动时,PCIe的‘根’与‘桥’是如何长出来的(以EDK2代码为例)
从树根到枝叶:EDK2中PCIe拓扑结构的可视化构建指南 1. PCIe拓扑结构的生物学隐喻 想象一下,当你观察一棵大树的生长过程时,首先看到的是深埋地下的根系,它们为整棵树提供支撑和养分输送通道。PCIe子系统在计算机系统中的角色与这棵…...

抛弃“精度迷信”!2026电力现货“绞肉机”中,只有“可执行功率”才是新能源的救命稻草
“我们的预测系统精度已经做到了95%,为什么在现货市场中还是亏钱?”2026年,随着宁夏、陕西、南方区域等电力市场正式进入连续结算试运行,我发现了一个扎心的现实:很多新能源场长陷入了 “精度迷信” 的怪圈。大家砸重金…...