Kafka(一):在WSL单机搭建Kafka伪集群
目录
- 1 运行Kafka单实例
- 1.1 Windws
- 1.1.1 安装包下载
- 1.1.2 修改环境变量
- 1.1.3 修改配置文件
- 1.1.4 启动Kafka单机版
- 1.2 Linux
- 1.2.1 安装包下载
- 1.2.2 创建目录
- 1.2.3 添加环境变量
- 1.2.4 修改配置文件
- 1.2.5 运行Kafka
- 1.2.6 停止Kafka
- 2 搭建Kafka集群
- 2.1 搭建Zookeeper集群
- 2.2 搭建Kafka集群
- 2.2.1 新建集群目录
- 2.2.2 配置环境变量
- 2.2.3 创建节点目录
- 2.2.4 修改配置
- 2.2.5 启动集群
- 2.2.6 停止集群
1 运行Kafka单实例
1.1 Windws
环境:Windows 11
1.1.1 安装包下载
官网下载地址:https://kafka.apache.org/downloads,截至此文,最新版本是3.5.1。
压缩包解压至本地目录,例如:D:\00_programming\kafka_2.12-3.5.1。
1.1.2 修改环境变量
KAFKA_HOME=D:\00_programming\kafka_2.12-3.5.1
修改Path变量:%KAFKA_HOME%\bin
1.1.3 修改配置文件
新建目录:D:\00_programming\kafka_2.12-3.5.1\kafka-logs
修改Kafka配置文件:D:\00_programming\kafka_2.12-3.5.1\config\server.properties
log.dirs=/00_programming/kafka_2.12-3.5.1/kafka-logs
修改Zookeeper配置文件:D:\00_programming\kafka_2.12-3.5.1\config\zookeeper.properties
dataDir=/00_programming/kafka_2.12-3.5.1/zookeeper
1.1.4 启动Kafka单机版
依次运行如下命令,每次新打开一个命令行窗口:
启动Zookeeper:
zookeeper-server-start.bat %KAFKA_HOME%\config\zookeeper.properties
启动Kafka:
kafka-server-start.bat %KAFKA_HOME%\config\server.properties
新建Topic:
kafka-topics.bat --create --bootstrap-server localhost:9092 --topic test --partitions 1 --replication-factor 1
启动生产者:
kafka-console-producer.bat --broker-list localhost:9092 --topic test
启动消费者:
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test
简单测试:
在生产者命令行输入:
Hello, Kafka!
在消费者控制台收到消息:
Hello, Kafka!
1.2 Linux
环境:Windows 11 WSL2
Linux发行版本:Ubuntu 22.04.2 LTS
1.2.1 安装包下载
下载安装包
wget https://downloads.apache.org/kafka/3.6.0/kafka_2.13-3.6.0.tgz
解压
tar xvf kafka_2.13-3.6.0.tgz -C /usr/local/bin
1.2.2 创建目录
创建数据和日志目录:
sudo mkdir $KAFKA_HOME/kafka-logs
sudo chmod -R o+w $KAFKA_HOME/kafka-logssudo mkdir $KAFKA_HOME/logs
sudo chmod -R o+w $KAFKA_HOME/logs
1.2.3 添加环境变量
vim ~/.bashrc
添加以下内容:
export KAFKA_HOME=/usr/local/bin/kafka_2.13-3.6.0
export PAHT=$PAHT:${KAFKA_HOME}/bin
加载环境变量:
source ~/.bashrc
1.2.4 修改配置文件
首先查看本机IP:
ip addr
修改配置:
vim $KAFKA_HOME/config/server.properties
修改以下内容:
listeners=PLAINTEXT://172.26.143.96:9092
advertised.listeners=PLAINTEXT://172.26.143.96:9092
log.dirs=/usr/local/bin/kafka_2.13-3.6.0/kafka-logs
1.2.5 运行Kafka
zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties
kafka-server-start.sh $KAFKA_HOME/config/server.properties
1.2.6 停止Kafka
kafka-server-stop.sh
zookeeper-server-stop.sh
2 搭建Kafka集群
2.1 搭建Zookeeper集群
过程参考:
在WSL单机搭建Zookeeper伪集群
2.2 搭建Kafka集群
2.2.1 新建集群目录
创建集群目录:
cd /usr/local/bin
sudo mkdir kafka-cluster
2.2.2 配置环境变量
vim ~/.bashrc
添加:
export KAFKA_CLUSTER_HOME=/usr/local/bin/kafka-cluster
source ~/bashrc
2.2.3 创建节点目录
将Kafka安装目录复制3份:
sudo cp -rf kafka_2.13-3.6.0 kafka-cluster/kafka-1
sudo cp -rf kafka_2.13-3.6.0 kafka-cluster/kafka-2
sudo cp -rf kafka_2.13-3.6.0 kafka-cluster/kafka-3
清理之前单实例产生的数据:
sudo rm -rf kafka-cluster/kafka-1/kafka-logs
sudo rm -rf kafka-cluster/kafka-2/kafka-logs
sudo rm -rf kafka-cluster/kafka-3/kafka-logssudo mkdir kafka-cluster/kafka-1/kafka-logs
sudo mkdir kafka-cluster/kafka-2/kafka-logs
sudo mkdir kafka-cluster/kafka-3/kafka-logssudo chmod -R 777 kafka-cluster/kafka-1/kafka-logs
sudo chmod -R 777 kafka-cluster/kafka-2/kafka-logs
sudo chmod -R 777 kafka-cluster/kafka-3/kafka-logssudo rm -rf kafka-cluster/kafka-1/logs
sudo rm -rf kafka-cluster/kafka-2/logs
sudo rm -rf kafka-cluster/kafka-3/logssudo mkdir kafka-cluster/kafka-1/logs
sudo mkdir kafka-cluster/kafka-2/logs
sudo mkdir kafka-cluster/kafka-3/logssudo chmod -R 777 kafka-cluster/kafka-1/logs
sudo chmod -R 777 kafka-cluster/kafka-2/logs
sudo chmod -R 777 kafka-cluster/kafka-3/logs
2.2.4 修改配置
分别修改3个节点的配置
sudo vim $KAFKA_CLUSTER_HOME/kafka-1/config/server.properties
broker.id=0
listeners=PLAINTEXT://172.26.143.96:9092
advertised.listeners=PLAINTEXT://172.26.143.96:9092
log.dirs=$KAFKA_CLUSTER_HOME/kafka-1/kafka-logs
zookeeper.connect=172.26.143.96:2181,172.26.143.96:2182,172.26.143.96:2183
sudo vim $KAFKA_CLUSTER_HOME/kafka-2/config/server.properties
broker.id=1
listeners=PLAINTEXT://172.26.143.96:9093
advertised.listeners=PLAINTEXT://172.26.143.96:9093
log.dirs=$KAFKA_CLUSTER_HOME/kafka-2/kafka-logs
zookeeper.connect=172.26.143.96:2181,172.26.143.96:2182,172.26.143.96:2183
sudo vim $KAFKA_CLUSTER_HOME/kafka-3/config/server.properties
broker.id=1
listeners=PLAINTEXT://172.26.143.96:9094
advertised.listeners=PLAINTEXT://172.26.143.96:9094
log.dirs=$KAFKA_CLUSTER_HOME/kafka-3/kafka-logs
zookeeper.connect=172.26.143.96:2181,172.26.143.96:2182,172.26.143.96:2183
2.2.5 启动集群
$KAFKA_CLUSTER_HOME/kafka-1/bin/kafka-server-start.sh $KAFKA_CLUSTER_HOME/kafka-1/config/server.properties
$KAFKA_CLUSTER_HOME/kafka-2/bin/kafka-server-start.sh $KAFKA_CLUSTER_HOME/kafka-2/config/server.properties
$KAFKA_CLUSTER_HOME/kafka-3/bin/kafka-server-start.sh $KAFKA_CLUSTER_HOME/kafka-3/config/server.properties
创建Topic并查看:
$KAFKA_CLUSTER_HOME/kafka-1/bin/kafka-topics.sh --create --bootstrap-server 172.26.143.96:9092 --topic test --partitions 10 --replication-factor 3
$KAFKA_CLUSTER_HOME/kafka-1/bin/kafka-topics.sh --bootstrap-server 172.26.143.96:9092 --describe --topic test
Topic: test TopicId: yhX-1uT2SAaYj-HrreKEPw PartitionCount: 10 ReplicationFactor: 3 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: test Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test Partition: 2 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test Partition: 3 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: test Partition: 4 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: test Partition: 5 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
Topic: test Partition: 6 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: test Partition: 7 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test Partition: 8 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test Partition: 9 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
2.2.6 停止集群
$KAFKA_CLUSTER_HOME/kafka-1/bin/kafka-server-stop.sh
$KAFKA_CLUSTER_HOME/kafka-2/bin/kafka-server-stop.sh
$KAFKA_CLUSTER_HOME/kafka-3/bin/kafka-server-stop.sh
相关文章:
:在WSL单机搭建Kafka伪集群)
Kafka(一):在WSL单机搭建Kafka伪集群
目录 1 运行Kafka单实例1.1 Windws1.1.1 安装包下载1.1.2 修改环境变量1.1.3 修改配置文件1.1.4 启动Kafka单机版 1.2 Linux1.2.1 安装包下载1.2.2 创建目录1.2.3 添加环境变量1.2.4 修改配置文件1.2.5 运行Kafka1.2.6 停止Kafka 2 搭建Kafka集群2.1 搭建Zookeeper集群2.2 搭建…...

mysql1124实验七索引管理
实验任务七 索引管理实验任务书 1. 实验目的 掌握在MySQL中使用MySQL Workbench或者SQL语句创建和使用索引的方法(以SQL命令为重点)。 掌握在MySQL中使用MySQL Workbench或者SQL语句查看和删除索引的方法(以SQL命令为重点)。 …...

[带余除法寻找公共节点]二叉树
二叉树 题目描述 如上图所示,由正整数1, 2, 3, ...组成了一棵无限大的二叉树。从某一个结点到根结点(编号是1的结点)都有一条唯一的路径,比如从10到根结点的路径是(10, 5, 2, 1),从4到根结点的路径是(4, 2, 1)&#x…...

详解Rust编程中的生命周期
1.摘要 生命周期在Rust编程中是一个重要概念, 它能确保引用像预期的那样一直有效。在Rust语言中, 每一个引用都有其生命周期, 通俗讲就是每个引用在程序执行的过程中都有其自身的作用域, 一旦离开其作用域, 其生命周期也宣告结束, 值不再有效。幸运的是, 在绝大多数时间里, 生…...

【实践】Deployer 发布到search head : local OR default
1: 背景: search head deployer 上的 /opt/splunk/etc/schcluster/apps 下面的local, 还有default 派发到 search head 到app 下面是怎么工作的,这个过程,实践了一下: 参考Use the deployer to distribute apps and configuration updates - Splunk Documentation 2: 实…...
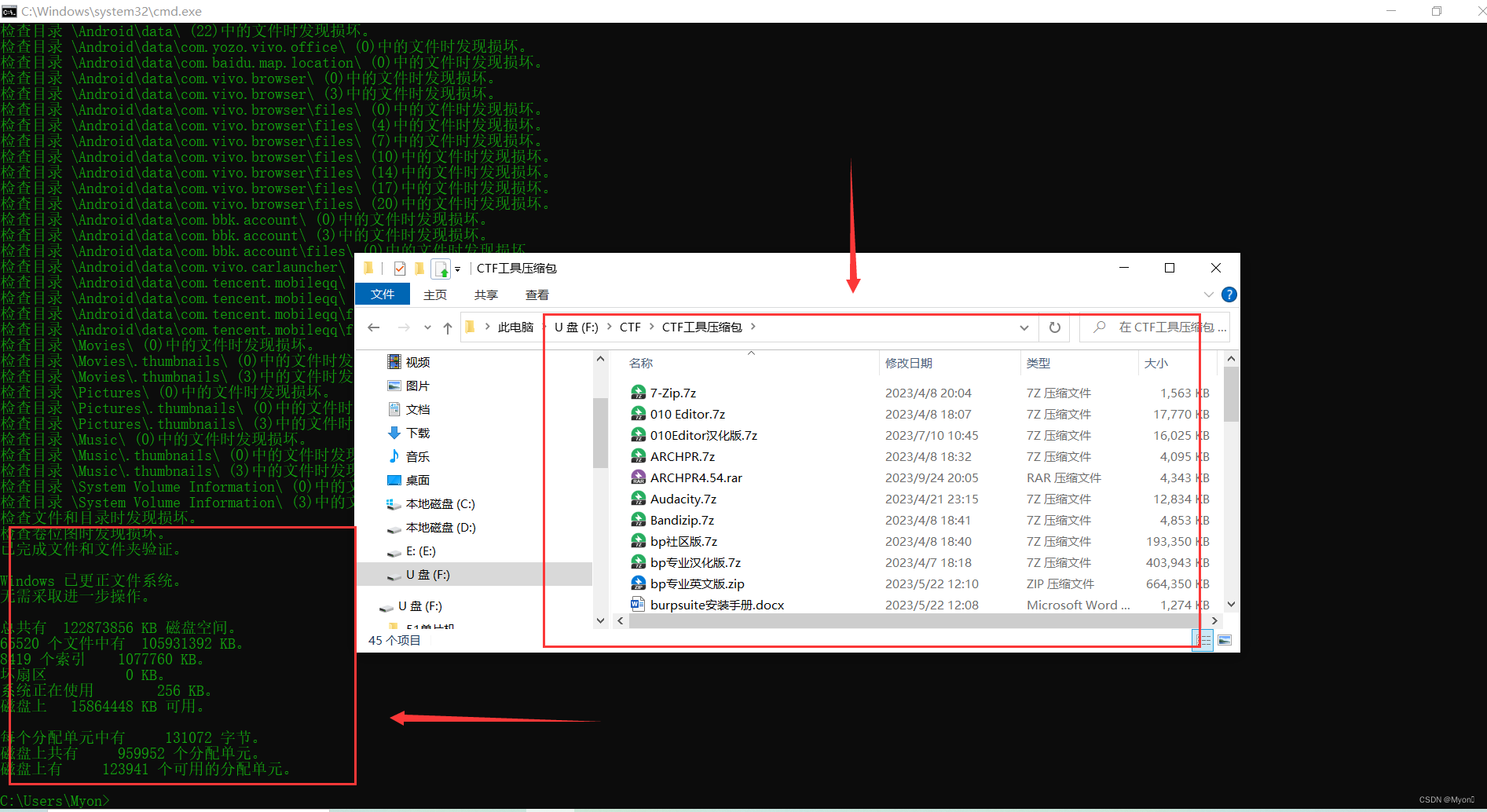
U盘报错无法访问文件或目录损坏且无法读取的解决办法
使用电脑打开U盘的部分文件时提示无法访问,文件或目录损坏且无法读取 报错内容如下图: 因为我这个U盘是那种双接口的 Type-C和USB,前段时间被我摔了一下 看网上说这种双接口的U盘USB接口容易坏掉 尝试在手机上使用OTG打开,先测试…...
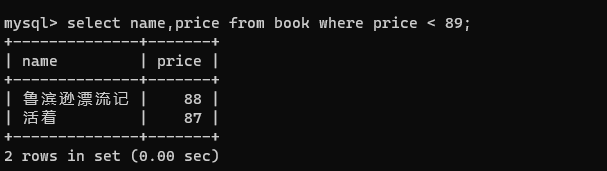
【MySQL】数据库基础操作
👑专栏内容:MySQL⛪个人主页:子夜的星的主页💕座右铭:前路未远,步履不停 目录 一、数据库操作1、创建数据库2、查看所有数据库3、选定指定数据库4、删除数据库 二、数据表操作1、创建数据表2、查看所有表3、…...

2023年微软开源八个人工智能项目
自2001年软件巨头微软前首席执行官史蒂夫鲍尔默对开源(尤其是Linux)发表尖刻言论以来,微软正在开源方面取得了长足的进步。继ChatGPT于去年年底发布了后,微软的整个2023年,大多数技术都是面向开发人员和研究人员公开发…...
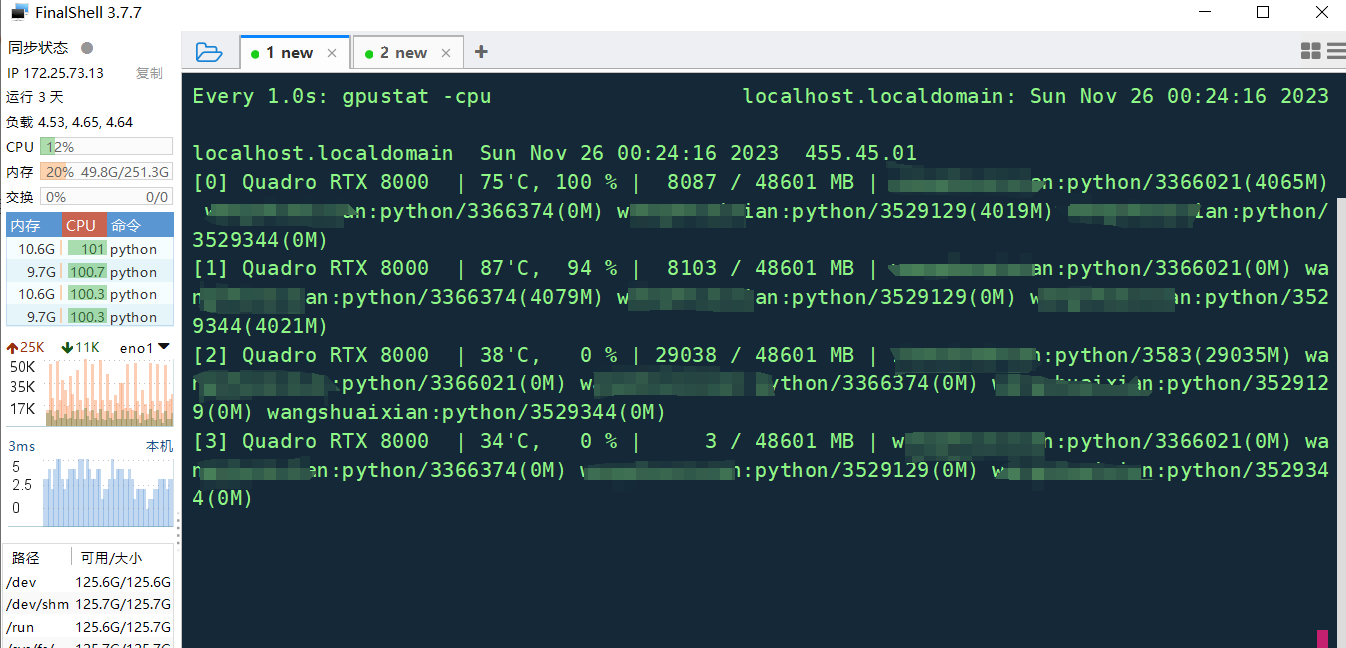
指定训练使用的GPU个数,没有指定定gpu id,训练在其中两个gpu上执行,但是线程id分布在所有4个gpu上,为什么?如何解决?
目录 问题背景 1 线程id分布在所有gpu(包括未启用的gpu)上原因: 2 在解决这个问题时,可以采取以下步骤: 3 修正深度学习框架默认使用所有可见 GPU 的问题 1 TensorFlow: 2 PyTorch: 3 K…...
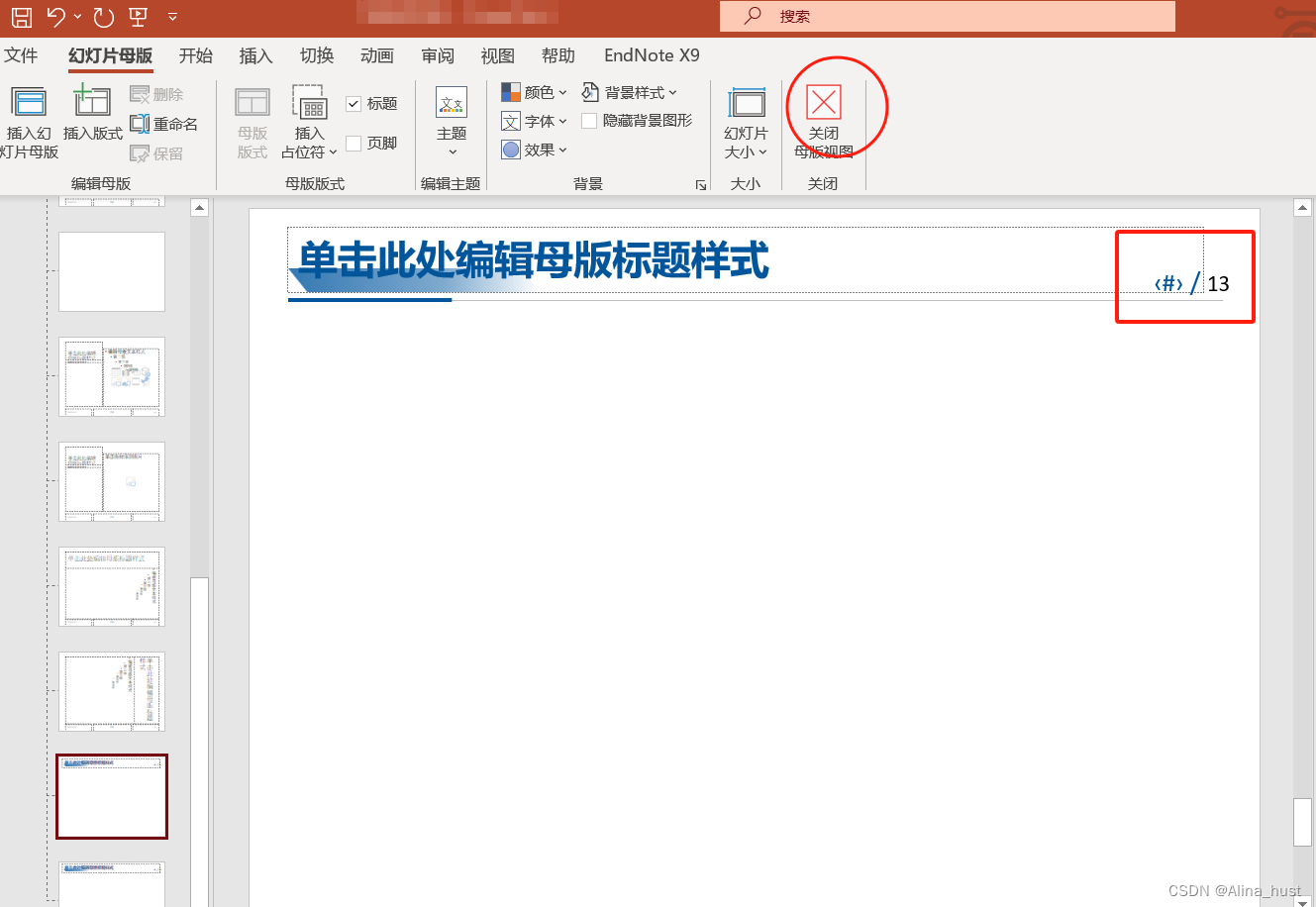
PPT 遇到问题总结(修改页码统计)
PPT常见问题 1. 修改页码自动计数 1. 修改页码自动计数 点击 视图——>幻灯片母版——>下翻找到计数页直接修改——>关闭母版视图...
Matplotlib子图的创建_Python数据分析与可视化
Matplotlib子图的创建 plt.axes创建子图fig.add_axes()创建子图 plt.axes创建子图 前面已经介绍过plt.axes函数,这个函数默认配置是创建一个标准的坐标轴,填满整张图。 它还有一个可选的参数,由图形坐标系统的四个值构成。这四个值表示为坐…...
VM虚拟机中Ubuntu14.04安装VM tools后仍不能全屏显示
1、查看Ubuntu所支持的分辨率大小。 在终端处输入: xrandr,回车 2、输入你想设置的分辨率参数。 我设置的为1360x768,大家可以根据自己的具体设备设置。 在终端输入:xrandr -s 1360x768 注意:这里1360后边是字母 x 且…...

聊聊httpclient的connect
序 本文主要研究一下httpclient的connect HttpClientConnectionOperator org/apache/http/conn/HttpClientConnectionOperator.java public interface HttpClientConnectionOperator {void connect(ManagedHttpClientConnection conn,HttpHost host,InetSocketAddress loca…...

处理视频的新工具:UniFab 2.0.0.4 Crack
UniFab这是一个用于处理视频的新工具,可以帮助您像专业人士一样获得结果,事实上,它可以确保在项目的任何设备上完美播放,所以,来认识一下 UniFab - 一款功能强大且方便的视频编辑器和转换器,但另一方面&…...

设计模式—开闭原则
1.背景 伯特兰迈耶一般被认为是最早提出开闭原则这一术语的人,在他1988年发行的《面向对象软件构造》中给出。这一想法认为一旦完成,一个类的实现只应该因错误而修改,新的或者改变的特性应该通过新建不同的类实现。新建的类可以通过继承的方…...

【开源】基于Vue和SpringBoot的学校热点新闻推送系统
项目编号: S 047 ,文末获取源码。 \color{red}{项目编号:S047,文末获取源码。} 项目编号:S047,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 新闻类型模块2.2 新闻档案模块2.3 新…...

Java,File类与IO流,处理流:缓冲流、转换流、数据流、对象流
目录 处理流之一:缓冲流 四种缓冲流: 缓冲流的作用: 使用的方法: 处理文本文件的字符流: 处理非文本文件的字节流: 操作步骤: 处理流之二:转换流 转换流的使用: …...

【电路笔记】-分压器
分压器 文章目录 分压器1、概述2、负载分压器3、分压器网络4、无功分压器4.1 电容分压器4.2 感应分压器 5、总结 有时,需要精确的电压值作为参考,或者仅在需要较少功率的电路的特定阶段之前需要。 分压器是解决此问题的一个简单方法,因为它们…...

音视频5、libavformat-3
8、设置I/O中断机制 在 demux 时,我们首先需要调用 avformat_open_input() 打开一个输入,然后循环调用 av_read_frame() 函数来读取输入。 我们要注意的是: avformat_open_input() 和 av_read_frame() 都是阻塞函数,如果不能读取到足够的数据,那么它们将会一直阻塞…...

前端 HTML 和 JavaScript 的基础知识有哪些?
前端开发是Web开发的一个重要领域,涉及到HTML(Hypertext Markup Language)和JavaScript两个主要的技术。HTML用于定义网页的结构和内容,而JavaScript用于实现网页的交互和动态效果。以下是前端HTML和JavaScript的基础知识…...

Fish Speech 1.5开发者案例:集成至微信小程序实现语音播报功能
Fish Speech 1.5开发者案例:集成至微信小程序实现语音播报功能 1. 项目背景与需求 在实际的微信小程序开发中,语音播报功能已经成为提升用户体验的重要特性。无论是新闻阅读、教育学习、还是电商导购场景,高质量的语音合成都能让应用更加生…...

Ubuntu系统优化:Qwen2.5-32B-Instruct给出的专业建议
Ubuntu系统优化:Qwen2.5-32B-Instruct给出的专业建议 1. 引言 作为一名长期使用Ubuntu系统的开发者,我深知系统优化的重要性。一个经过精心调优的Ubuntu系统不仅能提升工作效率,还能让日常使用体验更加流畅。最近,我有机会体验了…...

基于51单片机与SHT11的智能温室环境仿真系统设计
1. 系统设计背景与核心功能 想象一下你正在经营一个小型温室种植园,每天最头疼的就是不知道什么时候该开窗通风、什么时候该启动加湿器。传统的人工记录方式不仅费时费力,还经常因为反应不及时导致作物减产。这就是为什么我们需要一个智能温室环境监控系…...

开尔文连接:精密测量里的“误差消除神器”
在高精度电子测量与芯片测试领域,开尔文连接(Kelvin Connection)是绕不开的核心技术,它也被称作四线制测量/四端检测,由威廉汤姆森开尔文勋爵于1861年发明,最初用于低电阻测量,如今已成为低阻测…...
的源代码)
gma中计算CWDI(作物水分亏缺指数)的源代码
这次是干货 作物水分亏缺指数 作物水分亏缺指数(Crop Water Deficit Index,CWDI,%)从农田水分平衡出发,引入了作物系数,考虑了作物需水特性,能很好好的反应作物缺水状况。计算公式如下ÿ…...

手把手教你用F1C200s驱动正点原子7寸LCD屏:完整配置流程与LVGL测试
从零构建F1C200s嵌入式GUI系统:正点原子7寸屏驱动与LVGL实战指南 在嵌入式开发领域,显示界面的人机交互体验越来越受到重视。F1C200s作为一款性价比极高的国产ARM9芯片,搭配正点原子7寸LCD屏,能够构建出性能稳定、成本可控的嵌入式…...

【我的Android进阶之旅】解决MediaPlayer播放音乐的时候报错: Should have subtitle controller already set
文章目录 一、错误描述 二、错误解决 解决方法一 解决方法二 一、错误描述 刚用MediaPlayer播放Music的时候,看到Log打印台总是会打印一条错误日志,MediaPlayer: Should have subtitle controller already set,虽然程序运行不会出问题,但是看起来红色的日志很显眼,因此决…...

ICML 2025 | 时间序列预测与生成模型前沿进展全景解读
1. 时间序列预测与生成模型的2025技术风向标 ICML 2025收录的63篇时间序列相关论文,清晰地勾勒出该领域三大技术演进路径:扩散模型的高阶应用、基础模型的领域适配以及多模态融合的范式创新。从工业界实际应用的角度来看,今年最显著的变化是研…...

Android离屏渲染:从原理到性能优化的全景解析
1. 什么是Android离屏渲染? 离屏渲染(Offscreen Rendering)是图形处理中的一个重要概念。简单来说,当系统无法直接在屏幕上绘制某些复杂视觉效果时,会先在内存中创建一个临时缓冲区进行绘制,然后再将这个缓…...

C语言内存释放:何时需要手动释放内存
c语言为什么要释放内存 释放内存是什么意思 C语言:什么情况下需要释放内存?C管理内存大致可以理解为两种,一种是在堆栈上分配的,另一种是在堆上分配的。临时变量,动态变量,分布在堆栈上,运行时…...