指定训练使用的GPU个数,没有指定定gpu id,训练在其中两个gpu上执行,但是线程id分布在所有4个gpu上,为什么?如何解决?
目录
问题背景
1 线程id分布在所有gpu(包括未启用的gpu)上原因:
2 在解决这个问题时,可以采取以下步骤:
3 修正深度学习框架默认使用所有可见 GPU 的问题
1 TensorFlow:
2 PyTorch:
3 Keras:
问题背景
多GUP训练深度学习模型时指定训练使用的GPU个数,没有指定gpu id,训练在其中两个gpu上执行,但是线程id分布在所有4个gpu上,如下图
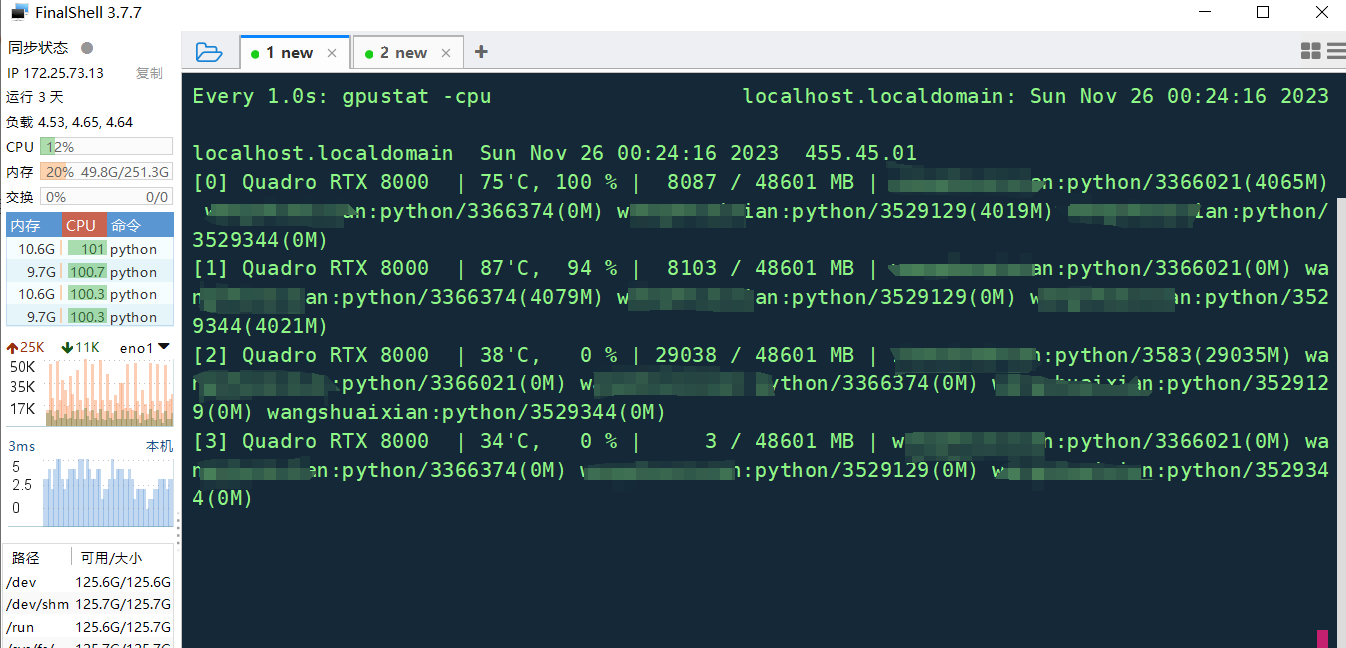
1 线程id分布在所有gpu(包括未启用的gpu)上原因:
深度学习框架默认使用所有可见GPU: 一些深度学习框架在初始化时默认会使用所有可见的GPU。即使你在代码中明确指定了两个GPU,框架仍可能会在所有四个GPU上启动线程。这是一种默认行为,你需要通过框架的配置来明确指定使用的GPU。
并行计算框架的默认设置: 如果你使用了并行计算框架(例如MPI),它们可能会默认使用所有可见的GPU。在这种情况下,需要查看并行框架的配置,确保只在指定的GPU上进行计算。
未正确设置GPU环境变量: 确保你在代码执行之前正确设置了GPU环境变量。例如,在使用CUDA的情况下,使用
CUDA_VISIBLE_DEVICES环境变量可以指定可见的GPU。查看代码中的设置: 检查你在代码中指定GPU的设置是否正确。有时候,代码中的设置可能被其他部分的配置或默认设置覆盖。
检查框架版本和文档: 确保你使用的深度学习框架的版本是最新的,并查看框架的文档,以了解正确的GPU设置方式。
2 在解决这个问题时,可以采取以下步骤:
在代码中正确设置 GPU 个数: 使用框架提供的设置来确保代码在指定数量的 GPU 上运行。有些框架提供了类似
torch.cuda.set_device或tf.config.experimental.set_visible_devices的函数,允许你指定 GPU 的数量而不是具体的 GPU ID。检查并行计算设置: 如果使用了并行计算框架,查看框架的文档,了解它是如何分配线程和任务的。
检查环境变量和配置文件: 查看环境变量和框架的配置文件,确保没有默认设置导致在所有 GPU 上启动线程。
查看代码中的其他设置: 检查代码中的其他设置,确保没有其他部分的配置或默认设置覆盖了你的 GPU 设置。
确保在调试和解决问题时,仔细查看相关的文档和配置信息,以确保代码按照你的预期方式运行。
3 修正深度学习框架默认使用所有可见 GPU 的问题
你需要在代码中明确指定使用的 GPU。具体的方法可能取决于你使用的深度学习框架。以下是一些常见框架的修正方法:
1 TensorFlow:
在 TensorFlow 中,可以使用 tf.config.experimental.set_visible_devices 来设置可见的 GPU 设备。同时,你可以使用 tf.config.experimental.set_memory_growth 来设置 GPU 内存的增长。以下是一个例子:
import tensorflow as tf# 选择你要使用的 GPU
gpu_ids = [0, 1] # 选择两个 GPU
tf.config.experimental.set_visible_devices(gpu_ids, 'GPU')# 设置 GPU 内存增长
for gpu_id in gpu_ids:tf.config.experimental.set_memory_growth(tf.config.list_physical_devices('GPU')[gpu_id], True)
这将确保 TensorFlow 只在指定的 GPU 上启动线程。
2 PyTorch:
在 PyTorch 中,可以使用 torch.cuda.set_device 来设置当前设备。以下是一个例子:
import torch# 选择你要使用的 GPU
gpu_ids = [0, 1] # 选择两个 GPU
torch.cuda.set_device(gpu_ids[0]) # 设置当前设备# 在这之后,PyTorch 的操作将在指定的 GPU 上执行
这将确保 PyTorch 只在指定的 GPU 上启动线程。
3 Keras:
如果你使用 Keras,可以结合使用 TensorFlow 的配置来控制 GPU 的使用。以下是一个例子:
import tensorflow as tf
from keras import backend as K# 选择你要使用的 GPU
gpu_ids = [0, 1] # 选择两个 GPU
tf.config.experimental.set_visible_devices(gpu_ids, 'GPU')# 设置 GPU 内存增长
for gpu_id in gpu_ids:tf.config.experimental.set_memory_growth(tf.config.list_physical_devices('GPU')[gpu_id], True)# 设置 Keras 使用的后端为 TensorFlow
K.set_session(tf.compat.v1.Session())
确保在设置 GPU 之前初始化框架的配置。这样,你就可以明确指定使用的 GPU,而不会默认使用所有可见的 GPU。
相关文章:
指定训练使用的GPU个数,没有指定定gpu id,训练在其中两个gpu上执行,但是线程id分布在所有4个gpu上,为什么?如何解决?
目录 问题背景 1 线程id分布在所有gpu(包括未启用的gpu)上原因: 2 在解决这个问题时,可以采取以下步骤: 3 修正深度学习框架默认使用所有可见 GPU 的问题 1 TensorFlow: 2 PyTorch: 3 K…...
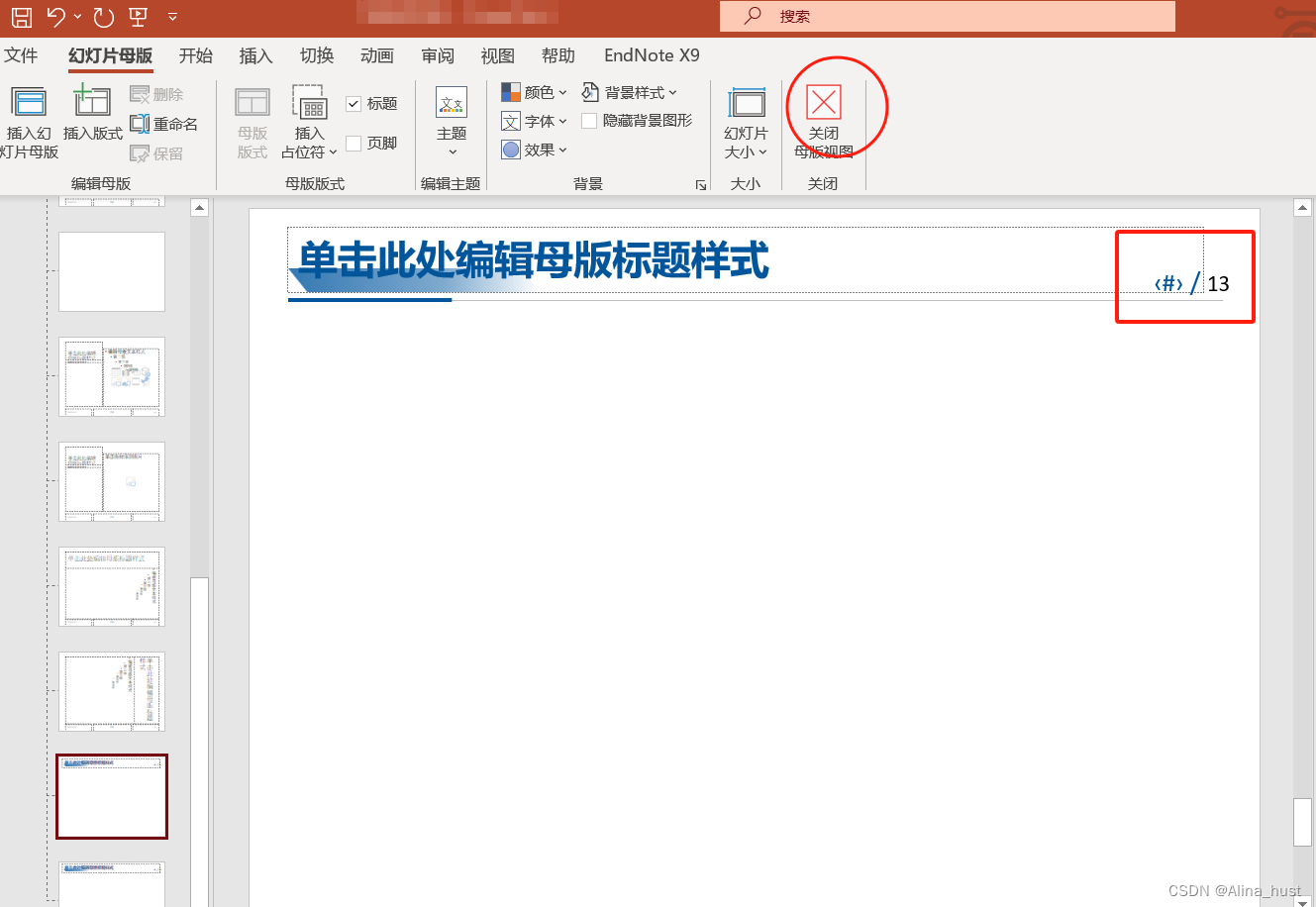
PPT 遇到问题总结(修改页码统计)
PPT常见问题 1. 修改页码自动计数 1. 修改页码自动计数 点击 视图——>幻灯片母版——>下翻找到计数页直接修改——>关闭母版视图...
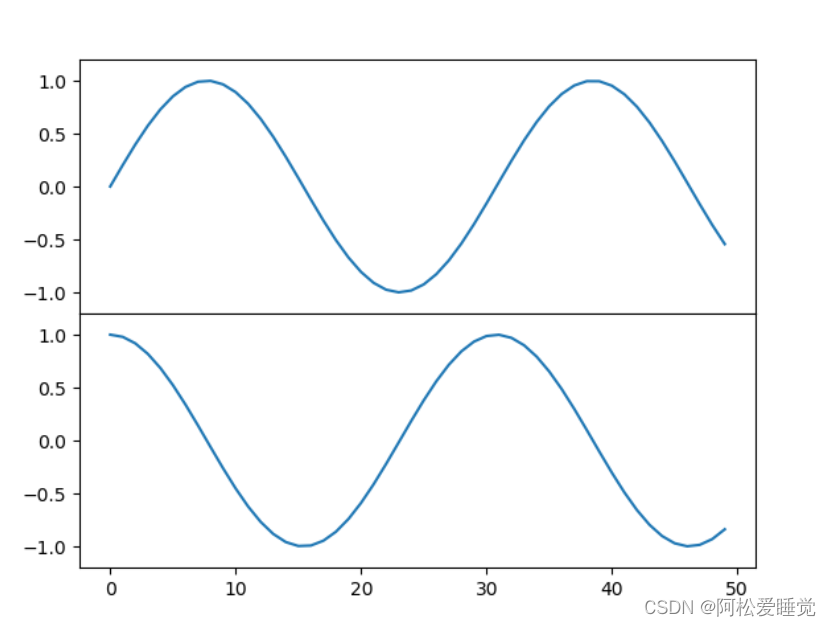
Matplotlib子图的创建_Python数据分析与可视化
Matplotlib子图的创建 plt.axes创建子图fig.add_axes()创建子图 plt.axes创建子图 前面已经介绍过plt.axes函数,这个函数默认配置是创建一个标准的坐标轴,填满整张图。 它还有一个可选的参数,由图形坐标系统的四个值构成。这四个值表示为坐…...
VM虚拟机中Ubuntu14.04安装VM tools后仍不能全屏显示
1、查看Ubuntu所支持的分辨率大小。 在终端处输入: xrandr,回车 2、输入你想设置的分辨率参数。 我设置的为1360x768,大家可以根据自己的具体设备设置。 在终端输入:xrandr -s 1360x768 注意:这里1360后边是字母 x 且…...

聊聊httpclient的connect
序 本文主要研究一下httpclient的connect HttpClientConnectionOperator org/apache/http/conn/HttpClientConnectionOperator.java public interface HttpClientConnectionOperator {void connect(ManagedHttpClientConnection conn,HttpHost host,InetSocketAddress loca…...

处理视频的新工具:UniFab 2.0.0.4 Crack
UniFab这是一个用于处理视频的新工具,可以帮助您像专业人士一样获得结果,事实上,它可以确保在项目的任何设备上完美播放,所以,来认识一下 UniFab - 一款功能强大且方便的视频编辑器和转换器,但另一方面&…...

设计模式—开闭原则
1.背景 伯特兰迈耶一般被认为是最早提出开闭原则这一术语的人,在他1988年发行的《面向对象软件构造》中给出。这一想法认为一旦完成,一个类的实现只应该因错误而修改,新的或者改变的特性应该通过新建不同的类实现。新建的类可以通过继承的方…...

【开源】基于Vue和SpringBoot的学校热点新闻推送系统
项目编号: S 047 ,文末获取源码。 \color{red}{项目编号:S047,文末获取源码。} 项目编号:S047,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 新闻类型模块2.2 新闻档案模块2.3 新…...

Java,File类与IO流,处理流:缓冲流、转换流、数据流、对象流
目录 处理流之一:缓冲流 四种缓冲流: 缓冲流的作用: 使用的方法: 处理文本文件的字符流: 处理非文本文件的字节流: 操作步骤: 处理流之二:转换流 转换流的使用: …...

【电路笔记】-分压器
分压器 文章目录 分压器1、概述2、负载分压器3、分压器网络4、无功分压器4.1 电容分压器4.2 感应分压器 5、总结 有时,需要精确的电压值作为参考,或者仅在需要较少功率的电路的特定阶段之前需要。 分压器是解决此问题的一个简单方法,因为它们…...

音视频5、libavformat-3
8、设置I/O中断机制 在 demux 时,我们首先需要调用 avformat_open_input() 打开一个输入,然后循环调用 av_read_frame() 函数来读取输入。 我们要注意的是: avformat_open_input() 和 av_read_frame() 都是阻塞函数,如果不能读取到足够的数据,那么它们将会一直阻塞…...

前端 HTML 和 JavaScript 的基础知识有哪些?
前端开发是Web开发的一个重要领域,涉及到HTML(Hypertext Markup Language)和JavaScript两个主要的技术。HTML用于定义网页的结构和内容,而JavaScript用于实现网页的交互和动态效果。以下是前端HTML和JavaScript的基础知识…...
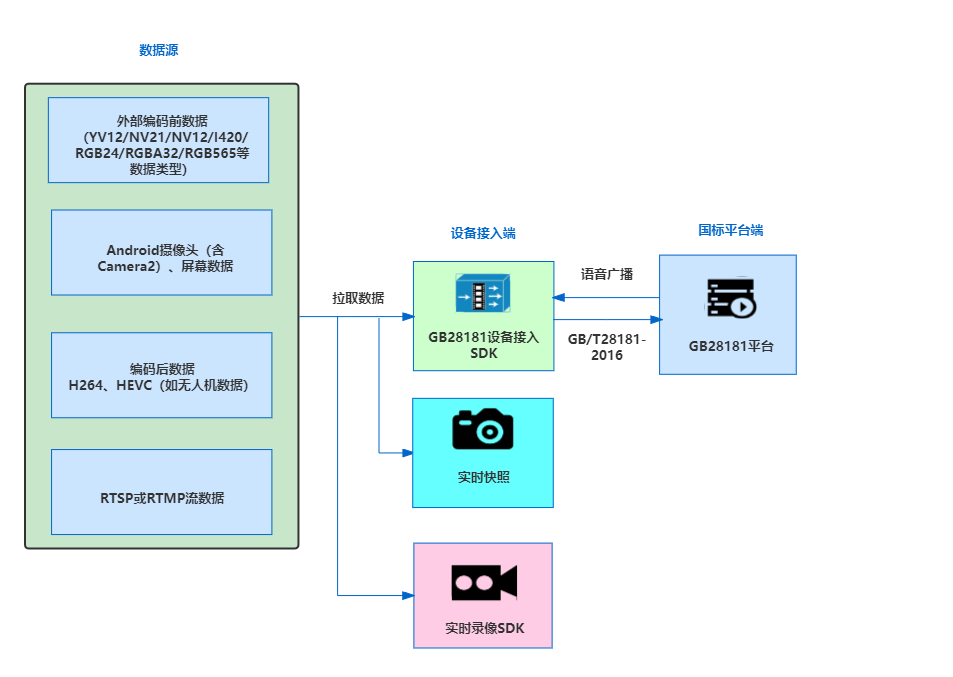
Android平台GB28181设备接入模块开发填坑指南
技术背景 为什么要开发Android平台GB28181设备接入模块?这个问题不再赘述,在做Android平台GB28181客户端的时候,媒体数据这块,我们已经有了很好的积累,因为在此之前,我们就开发了非常成熟的RTMP推送、轻量…...

我叫:希尔排序【JAVA】
1.我兄弟存在的问题 2.毛遂自荐 希尔排序提希尔(Donald Shell)于1959年提出的一种排序算法。 希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。 希尔排序是基于插入排序的以下两点性质而提出改进方法的&…...

Spring Cloud Gateway 网关跨域问题解决
0、版本说明 Spring Cloud Version:Spring Cloud 2021.0.4 Spring Cloud Gateway Version:3.1.4 Spring Boot Version:2.6.11 1、网关跨域问题说明 关于跨域的相关原理和理论,网上有大量文章对此进行说明,因此博主在这…...
C++局域网从服务器获取已连接用户的列表(linux to linux)
目录 服务器端 代码 客户端 代码解析 服务器端 原理 遇到的阻碍以及解决办法 客户端 原理 遇到的阻碍以及解决办法 运行结果截图 总结 服务器端 代码 #include <sys/types.h> #include <sys/socket.h> #include <stdio.h> #include <netinet…...

c++11新特性篇-可调用对象包装器, 绑定器
可调用对象包装器, 绑定器 可调用对象 可调用对象是指在 C 中能够像函数一样被调用的实体。它包括了多种类型的对象,使得它们能够像函数一样被调用,可以是函数、函数指针、函数对象、Lambda 表达式等。在C中,具有以下特征之一的实体都被认为…...

论文阅读:“Appearance Capture and Modeling of Human Teeth”
文章目录 AbstractIntroductionMethod OverviewTeeth Appearance ModelEnamelDentinGingiva and oral cavity Data AcquisitionImage captureGeometry capture ResultsReferences Abstract 如果要为电影,游戏或其他类型的项目创建在虚拟环境中显示的人类角色&#…...

初学vue3与ts:路由跳转带参数
index-router <!-- 路由跳转 --> <template><div><div class"title-sub flex"><div>1、用router-link跳转带参数id1:</div><router-link to"./link?id1"><button>点我跳转</button>&…...

JAVAEE---多线程
线程安全 这段代码执行结果就就是一个不确定的数,就存在线程安全问题。 为了解决这样的问题我们可以对count进行打包,我们知道count本质上应该是由三个指令完成,我们可以对其打包。 这样的代码结果就是正确的。我们对对象就进行了加锁&#…...

基于STM32的智能温控系统设计与物联网集成
1. 从零搭建智能温控系统的核心思路 第一次接触STM32温控项目时,我被各种专业术语搞得头晕眼花。后来发现只要抓住三个关键点:精准测温、智能调控、远程操控。就像给房间装空调,首先得知道当前温度(传感器),…...

NaViL-9B医疗影像初筛:X光片描述生成+异常区域提示案例
NaViL-9B医疗影像初筛:X光片描述生成异常区域提示案例 1. 医疗影像AI助手简介 在医疗影像诊断领域,医生每天需要处理大量X光片、CT等影像资料。传统人工阅片方式存在效率瓶颈,特别是在基层医疗机构,专业放射科医生资源更为紧缺。…...
到服务上线全生命周期)
Graphormer保姆级教程:从服务器选购(RTX4090)到服务上线全生命周期
Graphormer保姆级教程:从服务器选购(RTX4090)到服务上线全生命周期 1. 项目概述 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该…...

FLUX.2-Klein-9B-NVFP4快速上手:3步完成人像换装,效果惊艳
FLUX.2-Klein-9B-NVFP4快速上手:3步完成人像换装,效果惊艳 1. 为什么选择FLUX.2-Klein-9B-NVFP4? 你是否遇到过这样的困扰:想给照片中的人物换件衣服,要么需要复杂的PS技巧,要么使用AI工具效果不自然&…...

IndexTTS 2.0功能体验:音色情感自由组合,解锁语音合成新玩法
IndexTTS 2.0功能体验:音色情感自由组合,解锁语音合成新玩法 你有没有遇到过这样的烦恼?想给自己的视频配个旁白,但自己的声音不够好听,或者录出来的效果总是不满意。想找个配音演员,价格不菲不说…...

CLIP-GmP-ViT-L-14图文匹配测试工具学术写作:使用LaTeX撰写技术报告与论文
CLIP-GmP-ViT-L-14图文匹配测试工具学术写作:使用LaTeX撰写技术报告与论文 当你辛辛苦苦跑完了CLIP-GmP-ViT-L-14模型的实验,拿到了不错的图文匹配测试结果,下一步是不是有点头疼?怎么把这些图表、数据、算法逻辑,整理…...

深入解析:使用Apache POI与Hutool高效提取WPS Excel中的嵌入式图片
1. 为什么需要提取Excel中的嵌入式图片? 在日常工作中,我们经常会遇到需要处理包含图片的Excel文件。比如电商平台的产品数据报表里嵌入了商品图片,财务系统中保存了带有签名的报销单,或者数据分析报告里包含了图表截图。这些图片…...

亚洲美女-造相Z-Turbo效果可视化:同一提示词下不同采样步数与CFG Scale影响分析
亚洲美女-造相Z-Turbo效果可视化:同一提示词下不同采样步数与CFG Scale影响分析 想用AI生成一张好看的亚洲美女图片,是不是经常遇到这样的困惑:明明提示词写得挺详细,但出来的图要么模糊不清,要么表情僵硬,…...

亲测口碑好的物联网开发生产厂家分享
亲测口碑好的物联网开发生产厂家分享行业痛点分析在当前物联网开发领域,存在着诸多技术挑战。首先,设备兼容性难题突出,不同品牌、型号的物联网设备通信协议和接口各异,导致系统集成困难。数据表明,约 60%的物联网项目…...

从平面到空间:Depth-Anything-3如何为视觉模型注入“空间感知”超能力
1. 当视觉模型突然学会"看空间"会发生什么? 想象一下你家的扫地机器人突然能像人类一样理解房间的立体结构——它不再撞到桌腿,能准确判断沙发底下能不能钻进去,甚至记得你昨天挪动的茶几位置。这就是Depth-Anything-3(…...