第十三章 深度解读预训练与微调迁移,模型冻结与解冻(工具)
一个完整的代码
pythonCopy codeimport torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# 设置设备(CPU或GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义预训练模型
pretrained_model = torchvision.models.resnet18(pretrained=True)
pretrained_model.to(device)
# 冻结预训练模型的参数
for param in pretrained_model.parameters():param.requires_grad = False
# 替换最后一层全连接层
num_classes = 10 # 分类任务的类别数
pretrained_model.fc = nn.Linear(pretrained_model.fc.in_features, num_classes)
pretrained_model.fc.to(device)
# 加载训练数据集
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(pretrained_model.parameters(), lr=0.001, momentum=0.9)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):total_loss = 0.0correct = 0total = 0for images, labels in train_loader:images = images.to(device)labels = labels.to(device)optimizer.zero_grad()# 前向传播outputs = pretrained_model(images)loss = criterion(outputs, labels)# 反向传播和优化loss.backward()optimizer.step()total_loss += loss.item()_, predicted = outputs.max(1)total += labels.size(0)correct += predicted.eq(labels).sum().item()# 打印训练信息print('Epoch [{}/{}], Loss: {:.4f}, Accuracy: {:.2f}%'.format(epoch+1, num_epochs, total_loss/len(train_loader), 100*correct/total))
预训练与微调迁移
1. 什么是预训练和微调
- 你需要搭建一个网络模型来完成一个特定的图像分类的任务。首先,你需要随机初始化参数,然后开始训练网络,不断调整参数,直到网络的损失越来越小。在训练的过程中,一开始初始化的参数会不断变化。当你觉得结果很满意的时候,你就可以将训练模型的参数保存下来,以便训练好的模型可以在下次执行类似任务时获得较好的结果。这个过程就是
pre-training。 - 之后,你又接收到一个类似的图像分类的任务。这时候,你可以直接使用之前保存下来的模型的参数来作为这一任务的初始化参数,然后在训练的过程中,依据结果不断进行一些修改。这时候,你使用的就是一个
pre-trained模型,而过程就是fine-tuning。
所以,预训练 就是指预先训练的一个模型或者指预先训练模型的过程;微调 就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程。
1.1 预训练模型
- 预训练模型就是已经用数据集训练好了的模型。
- 现在我们常用的预训练模型就是他人用常用模型,比如
VGG16/19,Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数; - 正常情况下,我们常用的
VGG16/19等网络已经是他人调试好的优秀网络,我们无需再修改其网络结构。
2. 预训练和微调的作用
在 CNN 领域中,实际上,很少人自己从头训练一个 CNN 网络。主要原因是自己很小的概率会拥有足够大的数据集,基本是几百或者几千张,不像 ImageNet 有 120 万张图片这样的规模。拥有的数据集不够大,而又想使用很好的模型的话,很容易会造成过拟合。
所以,一般的操作都是在一个大型的数据集上(ImageNet)训练一个模型,然后使用该模型作为类似任务的初始化或者特征提取器。比如 VGG,ResNet 等模型都提供了自己的训练参数,以便人们可以拿来微调。这样既节省了时间和计算资源,又能很快的达到较好的效果。
3. 模型微调



3.1 微调的四个步骤
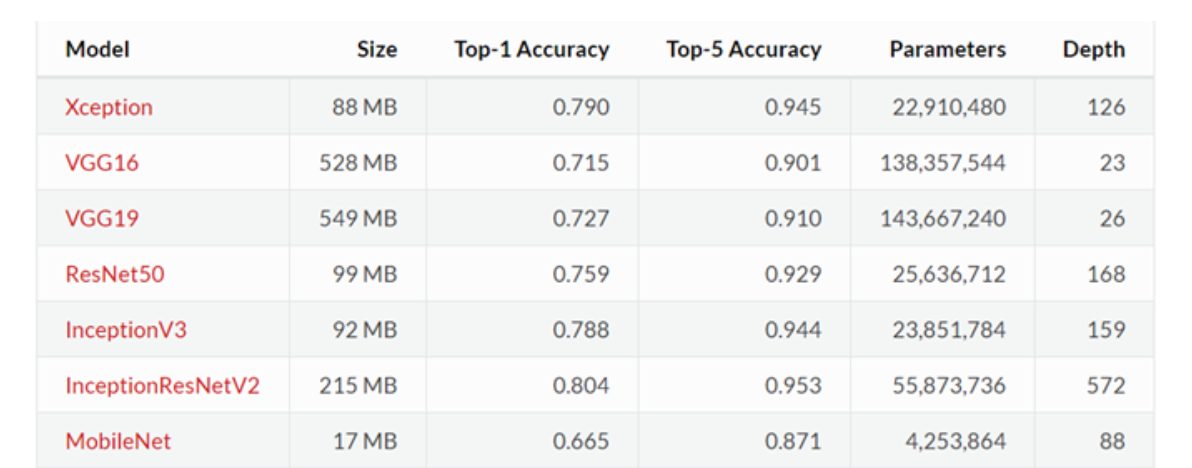
- 在源数据集(例如 ImageNet 数据集)上预训练一个神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
- 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集(例如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
3.2 为什么要微调
卷积神经网络的核心是:
- 浅层卷积层提取基础特征,比如边缘,轮廓等基础特征。
- 深层卷积层提取抽象特征,比如整个脸型。
- 全连接层根据特征组合进行评分分类。
普通预训练模型的特点是:用了大型数据集做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。
如果不做微调的话:
- 从头开始训练,需要大量的数据,计算时间和计算资源。
- 存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险。
3.3 什么情况下使用微调
- 要使用的数据集和预训练模型的数据集相似。如果不太相似,比如你用的预训练的参数是自然景物的图片,你却要做人脸的识别,效果可能就没有那么好了,因为人脸的特征和自然景物的特征提取是不同的,所以相应的参数训练后也是不同的。
- 自己搭建或者使用的CNN模型正确率太低。
- 数据集相似,但数据集数量太少。
- 计算资源太少。
不同数据集下使用微调
- 数据集1 - 数据量少,但数据相似度非常高 - 在这种情况下,我们所做的只是修改最后几层或最终的
softmax图层的输出类别。 - 数据集2 - 数据量少,数据相似度低 - 在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
- 数据集3 - 数据量大,数据相似度低 - 在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
- 数据集4 - 数据量大,数据相似度高 - 这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
3.4 微调注意事项
- 通常的做法是截断预先训练好的网络的最后一层(softmax层),并用与我们自己的问题相关的新的softmax层替换它。例如,ImageNet上预先训练好的网络带有1000个类别的softmax图层。如果我们的任务是对10个类别的分类,则网络的新softmax层将由10个类别组成,而不是1000个类别。然后,我们在网络上运行预先训练的权重。确保执行交叉验证,以便网络能够很好地推广。
- 使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。
- 如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。这是因为前几个图层捕捉了与我们的新问题相关的通用特征,如曲线和边。我们希望保持这些权重不变。相反,我们会让网络专注于学习后续深层中特定于数据集的特征。
4. 迁移学习
迁移学习(Transfer Learning)是机器学习中的一个名词,也可以应用到深度学习领域,是指一种学习对另一种学习的影响,或习得的经验对完成其它活动的影响。迁移广泛存在于各种知识、技能与社会规范的学习中。
通常情况下,迁移学习发生在两个任务之间,这两个任务可以是相似的,也可以是略有不同。在迁移学习中,源任务(Source Task)是已经训练好的模型的来源,目标任务(Target Task)是我们希望在其中应用迁移学习的新任务。

迁移学习专注于存储已有问题的解决模型,并将其利用在其他不同但相关问题上。比如说,用来辨识汽车的知识(或者是模型)也可以被用来提升识别卡车的能力。计算机领域的迁移学习和心理学常常提到的学习迁移在概念上有一定关系,但是两个领域在学术上的关系非常有限。
4.1 迁移学习的具象理解
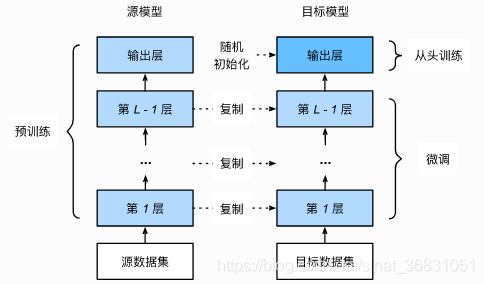
从技术上来说,迁移学习只是一种学习的方式,一种基于以前学习的基础上继续学习的方式。但现在大家讲的最多的还是基于神经网络基础之上的迁移学习。这里我们以卷积神经网络(CNN)为例,做一个简单的介绍。
在CNN中,我们反复的将一张图片的局部区域卷积,减少面积,并提升通道数。
那么卷积神经网络的中间层里面到底有什么?Matthew D. Zeiler和Rob Fergus发表了一篇非常著名的论文,阐述了卷积神经网络到底看到了什么:

和对卷积层进行简单的成像不同,他们尝试把不同的内容输入到训练好的神经网络,并观察记录卷积核的激活值。并把造成相同卷积核较大激活的内容分组比较。上面的图片中每个九宫格为同一个卷积核对不同图片的聚类。
从上面图片中可以看到,较浅层的卷积层将较为几何抽象的内容归纳到了一起。例如第一层的卷积中,基本就是边缘检测。而在第二层的卷积中,聚类了相似的几何形状,尽管这些几何形状的内容相差甚远。
随着卷积层越来越深,所聚类的内容也越来越具体。例如在第五层里,几乎每个九宫格里都是相同类型的东西。当我们了解这些基础知识后,那么我们有些什么办法可以实现迁移学习?
其实有个最简单易行的方式已经摆在我们面前了:如果我们把卷积神经网络的前n层保留下来,剩下不想要的砍掉怎么样?就像我们可以不需要ct能识别狗,识别猫,但是轮廓的对我们还是很有帮助的。
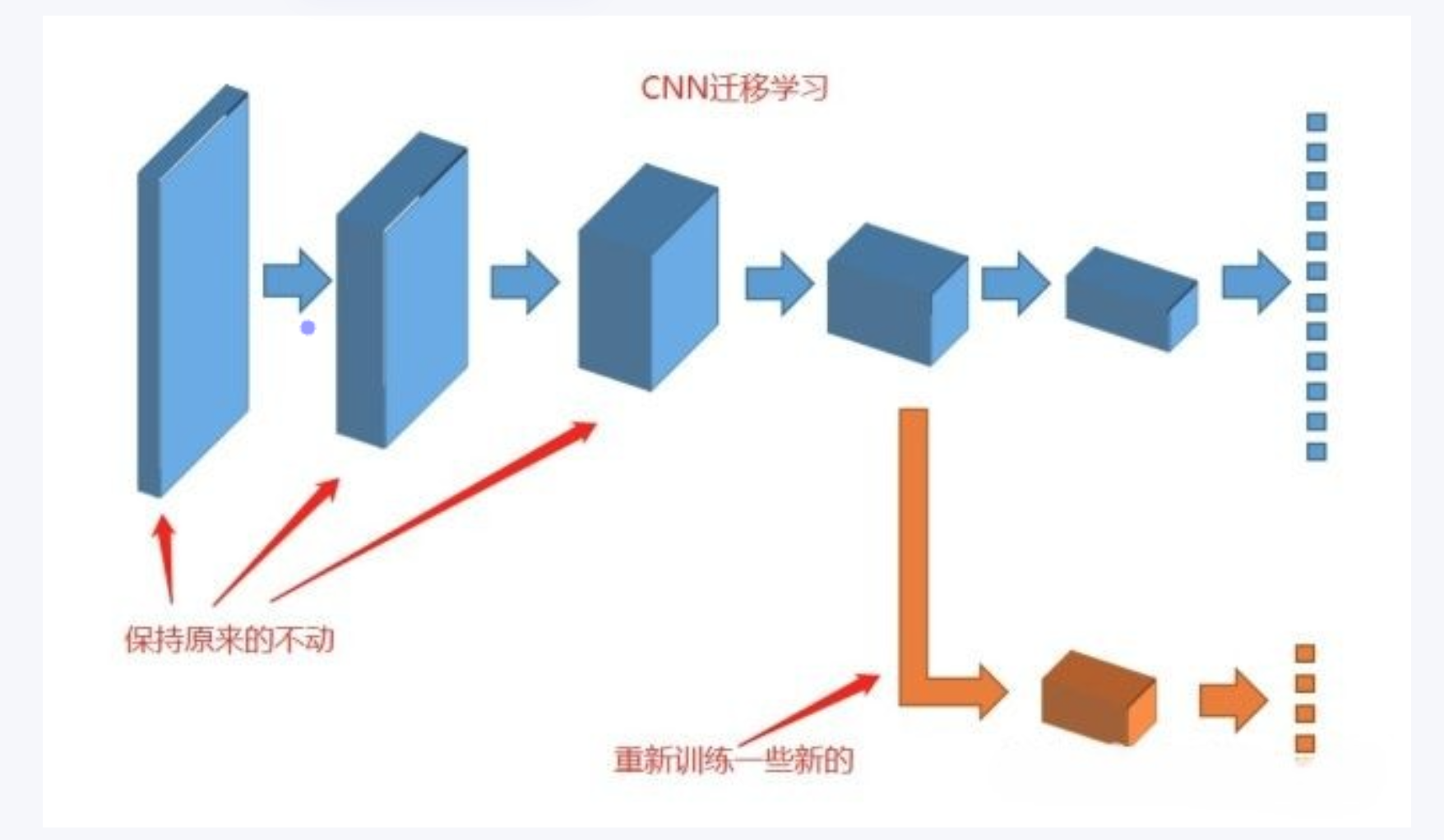
4.2 迁移学习的思想
迁移学习的主要思想是通过利用源任务上学到的特征表示、模型参数或知识,来辅助目标任务的训练过程。这种迁移可以帮助解决以下问题:
- 数据稀缺问题:当目标任务的数据量较少时,通过迁移学习可以利用源任务上丰富的数据信息来提高对目标任务的建模能力和泛化能力。
- 高维输入问题:当目标任务的输入数据具有高维特征时,迁移学习可以借助已经学到的特征表示,减少目标任务中的维度灾难问题,提高处理效率和性能。
- 任务相似性问题:当源任务和目标任务在特征空间或输出空间上存在一定的相似性时,迁移学习可以通过共享模型参数或知识的方式,加速目标任务的学习过程,提升性能。
- 领域适应问题:当源任务和目标任务的数据分布存在一定的差异时,迁移学习可以通过对抗训练、领域自适应等方法,实现在不同领域之间的知识传递和迁移。
总结来说,迁移学习是一种将已经学到的知识和模型从源任务迁移到目标任务的方法。它在机器学习和深度学习中都具有重要意义,可以提高模型的泛化能力、减少训练成本,并更好地应对数据稀缺、高维输入和任务相似性等问题。
4.3 如何使用迁移学习
你可以在自己的预测模型问题上使用迁移学习。以下是两个常用的方法:
- 开发模型的方法
- 预训练模型的方法
开发模型的方法
- 选择源任务。你必须选择一个具有丰富数据的相关的预测建模问题,原任务和目标任务的输入数据、输出数据以及从输入数据和输出数据之间的映射中学到的概念之间有某种关系,
- 开发源模型。然后,你必须为第一个任务开发一个精巧的模型。这个模型一定要比普通的模型更好,以保证一些特征学习可以被执行。
- 重用模型。然后,适用于源任务的模型可以被作为目标任务的学习起点。这可能将会涉及到全部或者部分使用第一个模型,这依赖于所用的建模技术。
- 调整模型。模型可以在目标数据集中的输入-输出对上选择性地进行微调,以让它适应目标任务。
预训练模型方法
- 选择源模型。一个预训练的源模型是从可用模型中挑选出来的。很多研究机构都发布了基于超大数据集的模型,这些都可以作为源模型的备选者。
- 重用模型。选择的预训练模型可以作为用于第二个任务的模型的学习起点。这可能涉及到全部或者部分使用与训练模型,取决于所用的模型训练技术。
- 调整模型。模型可以在目标数据集中的输入-输出对上选择性地进行微调,以让它适应目标任务。
第二种类型的迁移学习在深度学习领域比较常用。
4.4 什么时候使用迁移学习?
迁移学习是一种优化,是一种节省时间或者得到更好性能的捷径。
通常而言,在模型经过开发和测试之前,并不能明显地发现使用迁移学习带来的性能提升。
Lisa Torrey 和 Jude Shavlik 在他们关于迁移学习的章节中描述了使用迁移学习的时候可能带来的三种益处:
- 更高的起点。在微调之前,源模型的初始性能要比不使用迁移学习来的高。
- 更高的斜率。在训练的过程中源模型提升的速率要比不使用迁移学习来得快。
- 更高的渐进。训练得到的模型的收敛性能要比不使用迁移学习更好。
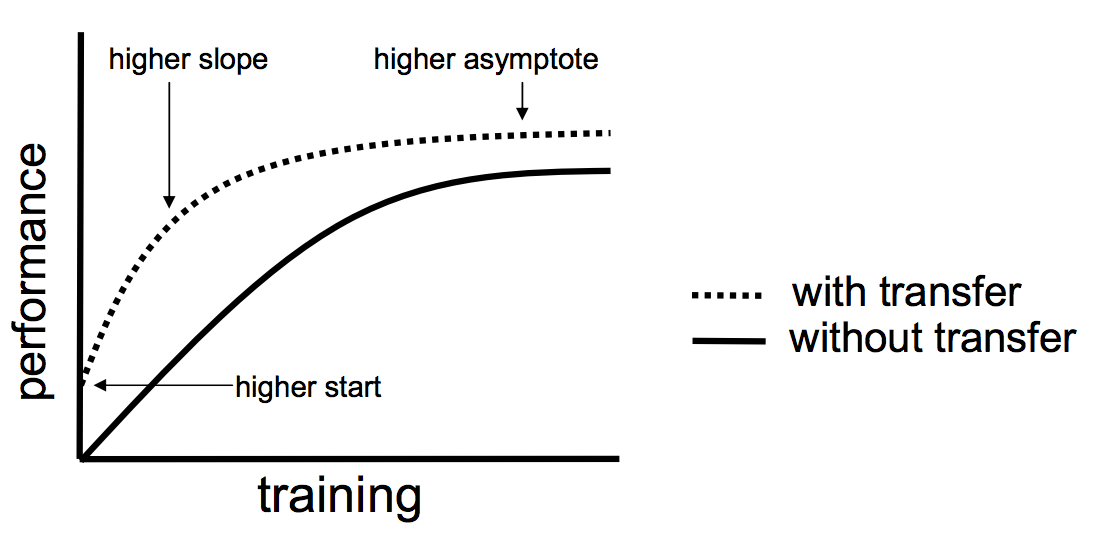
理想情况下,在一个成功的迁移学习应用中,你会得到上述这三种益处。
如果你能够发现一个与你的任务有相关性的任务,它具备丰富的数据,并且你也有资源来为它开发模型,那么,在你的任务中重用这个模型确实是一个好方法,或者(更好的情况),有一个可用的预训练模型,你可以将它作为你自己模型的训练初始点。
在一些问题上,你或许没有那么多的数据,这时候迁移学习可以让你开发出相对不使用迁移学习而言具有更高性能的模型。
简短解读冻结与解冻
一、引言
If I have seen further, it is by standing on the shoulders of giants.
迁移学习在计算机视觉领域中是一种很流行的方法,因为它可以建立精确的模型,耗时更短。利用迁移学习,不是从零开始学习,而是从之前解决各种问题时学到的模式开始。这样,我们就可以利用以前的学习成果,避免从零开始。
二、使用预训练权重
在计算机视觉领域中,迁移学习通常是通过使用预训练模型来表示的。预训练模型是在大型基准数据集上训练的模型,用于解决相似的问题。由于训练这种模型的计算成本较高,因此,导入已发布的成果并使用相应的模型是比较常见的做法。例如,在目标检测任务中,首先要利用主干神经网络进行特征提取,这里使用的backbone一般就是VGG、ResNet等神经网络,因此在训练一个目标检测模型时,可以使用这些神经网络的预训练权重来将backbone的参数初始化,这样在一开始就能提取到比较有效的特征。
可能大家会有疑问,预训练权重是针对他们数据集训练得到的,如果是训练自己的数据集还能用吗?预训练权重对于不同的数据集是通用的,因为特征是通用的。一般来讲,从0开始训练效果会很差,因为权值太过随机,特征提取效果不明显。对于目标检测模型来说,一般不从0开始训练,至少会使用主干部分的权值,虽然有些论文提到了可以不用预训练,但这主要是因为他们的数据集比较大而且他们的调参能力很强。如果从0开始训练,网络在前几个epoch的Loss可能会非常大,并且多次训练得到的训练结果可能相差很大,因为权重初始化太过随机。
PyTorch提供了state_dict()和load_state_dict()两个方法用来保存和加载模型参数,前者将模型参数保存为字典形式,后者将字典形式的模型参数载入到模型当中。下面是使用预训练权重(加载预训练模型)的代码,其中model_path就是预训练权重文件的路径:
# 第一步:读取当前模型参数
model_dict = model.state_dict()
# 第二步:读取预训练模型
pretrained_dict = torch.load(model_path, map_location = device)
pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}
# 第三步:使用预训练的模型更新当前模型参数
model_dict.update(pretrained_dict)
# 第四步:加载模型参数
model.load_state_dict(model_dict)
但是,使用load_state_dict()加载模型参数时,要求保存的模型参数键值类型和模型完全一致,一旦我们对模型结构做了些许修改,就会出现类似unexpected key module.xxx.weight问题。比如在目标检测模型中,如果修改了主干特征提取网络,只要不是直接替换为现有的其它神经网络,基本上预训练权重是不能用的,要么就自己判断权值里卷积核的shape然后去匹配,要么就只能利用这个主干网络在诸如ImageNet这样的数据集上训练一个自己的预训练模型;如果修改的是后面的neck或者是head的话,前面的backbone的预训练权重还是可以用的。下面是权值匹配的示例代码,把不匹配的直接pass了:
model_dict = model.state_dict()
pretrained_dict = torch.load(model_path, map_location=device)
temp = {}
for k, v in pretrained_dict.items():try: if np.shape(model_dict[k]) == np.shape(v):temp[k]=vexcept:pass
model_dict.update(temp)
三、冻结训练
冻结训练其实也是迁移学习的思想,在目标检测任务中用得十分广泛。因为目标检测模型里,主干特征提取部分所提取到的特征是通用的,把backbone冻结起来训练可以加快训练效率,也可以防止权值被破坏。在冻结阶段,模型的主干被冻结了,特征提取网络不发生改变,占用的显存较小,仅对网络进行微调。在解冻阶段,模型的主干不被冻结了,特征提取网络会发生改变,占用的显存较大,网络所有的参数都会发生改变。举个例子,如果在解冻阶段设置batch_size为4,那么在冻结阶段有可能可以把batch_size设置到8。下面是进行冻结训练的示例代码,假设前50个epoch冻结,后50个epoch解冻:
# 冻结阶段训练参数,learning_rate和batch_size可以设置大一点
Init_Epoch = 0
Freeze_Epoch = 50
Freeze_batch_size = 8
Freeze_lr = 1e-3
# 解冻阶段训练参数,learning_rate和batch_size设置小一点
UnFreeze_Epoch = 100
Unfreeze_batch_size = 4
Unfreeze_lr = 1e-4
# 可以加一个变量控制是否进行冻结训练
Freeze_Train = True
# 冻结一部分进行训练
batch_size = Freeze_batch_size
lr = Freeze_lr
start_epoch = Init_Epoch
end_epoch = Freeze_Epoch
if Freeze_Train:for param in model.backbone.parameters():param.requires_grad = False
# 解冻后训练
batch_size = Unfreeze_batch_size
lr = Unfreeze_lr
start_epoch = Freeze_Epoch
end_epoch = UnFreeze_Epoch
if Freeze_Train:for param in model.backbone.parameters():param.requires_grad = True
如果不进行冻结训练,一定要注意参数设置,注意上述代码中冻结阶段和解冻阶段的learning_rate和batch_size是不一样的,另外起始epoch和结束epoch也要重新调整一下。如果是从0开始训练模型(不使用预训练权重),那么一定不能进行冻结训练。
四、预训练和微调
最后再来总结一下预训练和微调,这是两个非常重要的概念,其实也很好理解。举个栗子是最能直观理解的。
假如我们现在要搭建一个网络模型来完成一个图像分类的任务,首先我们需要把网络的参数进行初始化,然后在训练网络的过程中不断对参数进行调整,直到网络的损失越来越小。在训练过程中,一开始初始化的参数会不断变化,如果结果已经满意了,那我们就可以把训练好的模型参数保存下来,以便训练好的模型可以在下次执行类似任务的时候获得比较好的效果。这个过程就是预训练(Pre-Training)。
假如在完成上面的模型训练后,我们又接到另一个类似的图像分类任务,这时我们就可以直接使用之前保存下来的模型参数作为这一次任务的初始化参数,然后在训练过程中依据结果不断进行修改,这个过程就是微调(Fine-Tuning)。
我们使用的神经网络越深,就需要越多的样本来进行训练,否则就很容易出现过拟合现象。比如我们想训练一个识别猫的模型,但是自己标注数据精力有限只标了100张,这时就可以考虑ImageNet数据集,可以在ImageNet上训练一个模型,然后使用该模型作为类似任务的初始化或特征提取器,这样既节省了时间和计算资源,又能很快地达到较好的效果。当然,采用预训练+微调也不是绝对有效的,上面识别猫的例子可以这样做是因为ImageNet里有猫的图像,所以可以认为是一个类似的数据集,如果是识别癌细胞的话,效果可能就不是那么好了。关于预训练和微调是有很多策略的,经验也很重要。
对比优化器optimizer与requires_grad冻结
首先,我们知道,深度学习网络中的参数是通过计算梯度,在反向传播进行更新的,从而能得到一个优秀的参数,但是有的时候,我们想固定其中的某些层的参数不参与反向传播。比如说,进行微调时,我们想固定已经加载预训练模型的参数部分,只想更新最后一层的分类器,这时应该怎么做呢。
定义网络
# 定义一个简单的网络
class net(nn.Module):def __init__(self, num_class=10):super(net, self).__init__()self.fc1 = nn.Linear(8, 4)self.fc2 = nn.Linear(4, num_class)def forward(self, x):return self.fc2(self.fc1(x))
情况一:当不冻结层时
代码
model = net()# 情况一:不冻结参数时
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=1e-2) # 传入的是所有的参数# 训练前的模型参数
print("model.fc1.weight", model.fc1.weight)
print("model.fc2.weight", model.fc2.weight)for epoch in range(10):x = torch.randn((3, 8))label = torch.randint(0,10,[3]).long()output = model(x)loss = loss_fn(output, label)optimizer.zero_grad()loss.backward()optimizer.step()# 训练后的模型参数
print("model.fc1.weight", model.fc1.weight)
print("model.fc2.weight", model.fc2.weight)
结果
(bbn) jyzhang@admin2-X10DAi:~/test$ python -u "/home/jyzhang/test/net.py"
model.fc1.weight Parameter containing:
tensor([[ 0.3362, -0.2676, -0.3497, -0.3009, -0.1013, -0.2316, -0.0189, 0.1430],[-0.2486, 0.2900, -0.1818, -0.0942, 0.1445, 0.2410, -0.1407, -0.3176],[-0.3198, 0.2039, -0.2249, 0.2819, -0.3136, -0.2794, -0.3011, -0.2270],[ 0.3376, -0.0842, 0.2747, -0.0232, 0.0768, 0.3160, -0.1185, 0.2911]],requires_grad=True)
model.fc2.weight Parameter containing:
tensor([[ 0.4277, 0.0945, 0.1768, 0.3773],[-0.4595, -0.2447, 0.4701, 0.2873],[ 0.3281, -0.1861, -0.2202, 0.4413],[-0.1053, -0.1238, 0.0275, -0.0072],[-0.4448, -0.2787, -0.0280, 0.4629],[ 0.4063, -0.2091, 0.0706, 0.3216],[-0.2287, -0.1352, -0.0502, 0.3434],[-0.2946, -0.4074, 0.4926, -0.0832],[-0.2608, 0.0165, 0.0501, -0.1673],[ 0.2507, 0.3006, 0.0481, 0.2257]], requires_grad=True)
model.fc1.weight Parameter containing:
tensor([[ 0.3316, -0.2628, -0.3391, -0.2989, -0.0981, -0.2178, -0.0056, 0.1410],[-0.2529, 0.2991, -0.1772, -0.0992, 0.1447, 0.2480, -0.1370, -0.3186],[-0.3246, 0.2055, -0.2229, 0.2745, -0.3158, -0.2750, -0.2994, -0.2295],[ 0.3366, -0.0877, 0.2693, -0.0182, 0.0807, 0.3117, -0.1184, 0.2946]],requires_grad=True)
model.fc2.weight Parameter containing:
tensor([[ 0.4189, 0.0985, 0.1723, 0.3804],[-0.4593, -0.2356, 0.4772, 0.2784],[ 0.3269, -0.1874, -0.2173, 0.4407],[-0.1061, -0.1248, 0.0309, -0.0062],[-0.4322, -0.2868, -0.0319, 0.4647],[ 0.4048, -0.2150, 0.0692, 0.3228],[-0.2252, -0.1353, -0.0433, 0.3396],[-0.2936, -0.4118, 0.4875, -0.0782],[-0.2625, 0.0192, 0.0509, -0.1670],[ 0.2474, 0.3056, 0.0418, 0.2265]], requires_grad=True)
结论
当不冻结层时,随着训练的进行,模型中的可学习参数层的参数会发生改变
情况二:采用方式一冻结fc1层时
方式一
-
优化器传入所有的参数
optimizer = optim.SGD(model.parameters(), lr=1e-2) # 传入的是所有的参数 -
将要冻结层的参数的
requires_grad置为Falsefor name, param in model.named_parameters():if "fc1" in name:param.requires_grad = False
代码
# 情况二:采用方式一冻结fc1层时
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=1e-2) # 优化器传入的是所有的参数# 训练前的模型参数
print("model.fc1.weight", model.fc1.weight)
print("model.fc2.weight", model.fc2.weight)# 冻结fc1层的参数
for name, param in model.named_parameters():if "fc1" in name:param.requires_grad = Falsefor epoch in range(10):x = torch.randn((3, 8))label = torch.randint(0,10,[3]).long()output = model(x)loss = loss_fn(output, label)optimizer.zero_grad()loss.backward()optimizer.step()print("model.fc1.weight", model.fc1.weight)
print("model.fc2.weight", model.fc2.weight)
结果
(bbn) jyzhang@admin2-X10DAi:~/test$ python -u "/home/jyzhang/test/net.py"
model.fc1.weight Parameter containing:
tensor([[ 0.3163, -0.1592, -0.2360, 0.1436, 0.1158, 0.0406, -0.0627, 0.0566],[-0.1688, 0.3519, 0.2464, -0.2693, 0.1284, 0.0544, -0.0188, 0.2404],[ 0.0738, 0.2013, 0.0868, 0.1396, -0.2885, 0.3431, -0.1109, 0.2549],[ 0.1222, -0.1877, 0.3511, 0.1951, 0.2147, -0.0427, -0.3374, -0.0653]],requires_grad=True)
model.fc2.weight Parameter containing:
tensor([[-0.1830, -0.3147, -0.1698, 0.3235],[-0.1347, 0.3096, 0.4895, 0.1221],[ 0.2735, -0.2238, 0.4713, -0.0683],[-0.3150, -0.1905, 0.3645, 0.3766],[-0.0340, 0.3212, 0.0650, 0.1380],[-0.2500, 0.1128, -0.3338, -0.4151],[ 0.0446, -0.4776, -0.3655, 0.0822],[-0.1871, -0.0602, -0.4855, -0.3604],[-0.3296, 0.0523, -0.3424, 0.2151],[-0.2478, 0.1424, 0.4547, -0.1969]], requires_grad=True)
model.fc1.weight Parameter containing:
tensor([[ 0.3163, -0.1592, -0.2360, 0.1436, 0.1158, 0.0406, -0.0627, 0.0566],[-0.1688, 0.3519, 0.2464, -0.2693, 0.1284, 0.0544, -0.0188, 0.2404],[ 0.0738, 0.2013, 0.0868, 0.1396, -0.2885, 0.3431, -0.1109, 0.2549],[ 0.1222, -0.1877, 0.3511, 0.1951, 0.2147, -0.0427, -0.3374, -0.0653]])
model.fc2.weight Parameter containing:
tensor([[-0.1821, -0.3155, -0.1637, 0.3213],[-0.1353, 0.3130, 0.4807, 0.1245],[ 0.2731, -0.2206, 0.4687, -0.0718],[-0.3138, -0.1925, 0.3561, 0.3809],[-0.0344, 0.3152, 0.0606, 0.1332],[-0.2501, 0.1154, -0.3267, -0.4137],[ 0.0400, -0.4723, -0.3586, 0.0808],[-0.1823, -0.0667, -0.4854, -0.3543],[-0.3285, 0.0547, -0.3388, 0.2166],[-0.2497, 0.1410, 0.4551, -0.2008]], requires_grad=True)
结论
由实验的结果可以看出:只要设置requires_grad=False虽然传入模型所有的参数,仍然只更新requires_grad=True的层的参数
情况三:采用方式二冻结fc1层时
方式二
-
优化器传入不冻结的fc2层的参数
optimizer = optim.SGD(model.fc2.parameters(), lr=1e-2) # 优化器只传入fc2的参数 -
注:不需要将要冻结层的参数的
requires_grad置为False
代码
# 情况三:采用方式二冻结fc1层时
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.fc2.parameters(), lr=1e-2) # 优化器只传入fc2的参数
print("model.fc1.weight", model.fc1.weight)
print("model.fc2.weight", model.fc2.weight)for epoch in range(10):x = torch.randn((3, 8))label = torch.randint(0,3,[3]).long()output = model(x)loss = loss_fn(output, label)optimizer.zero_grad()loss.backward()optimizer.step()print("model.fc1.weight", model.fc1.weight)
print("model.fc2.weight", model.fc2.weight)
结果
model.fc1.weight Parameter containing:
tensor([[ 0.2519, -0.1772, -0.2229, 0.0711, -0.1681, 0.1233, -0.3217, -0.0412],[ 0.2032, -0.2045, 0.2723, 0.3272, 0.1034, 0.1519, -0.0587, -0.3436],[ 0.0470, 0.2379, 0.0590, 0.2400, 0.2280, 0.2045, -0.0229, -0.3484],[-0.3023, -0.1195, 0.1792, -0.2173, -0.0492, 0.2640, -0.3511, -0.2845]],requires_grad=True)
model.fc2.weight Parameter containing:
tensor([[-0.3263, -0.2938, -0.3516, -0.4578],[-0.4549, -0.0060, 0.4696, -0.0174],[-0.4841, 0.2861, 0.2658, 0.4483],[-0.3093, 0.0977, -0.2735, 0.1033],[-0.2421, 0.4489, -0.4649, 0.0110],[-0.3671, 0.0182, -0.1027, -0.4441],[ 0.0205, -0.0659, 0.4183, -0.2068],[-0.1846, 0.1741, -0.2302, -0.1745],[-0.3423, -0.2642, 0.2796, 0.4976],[-0.0770, -0.3766, -0.0512, -0.2105]], requires_grad=True)
model.fc1.weight Parameter containing:
tensor([[ 0.2519, -0.1772, -0.2229, 0.0711, -0.1681, 0.1233, -0.3217, -0.0412],[ 0.2032, -0.2045, 0.2723, 0.3272, 0.1034, 0.1519, -0.0587, -0.3436],[ 0.0470, 0.2379, 0.0590, 0.2400, 0.2280, 0.2045, -0.0229, -0.3484],[-0.3023, -0.1195, 0.1792, -0.2173, -0.0492, 0.2640, -0.3511, -0.2845]],requires_grad=True)
model.fc2.weight Parameter containing:
tensor([[-0.3253, -0.2973, -0.3707, -0.4560],[-0.4566, 0.0015, 0.4655, -0.0166],[-0.4796, 0.2931, 0.2592, 0.4661],[-0.3097, 0.0966, -0.2695, 0.1002],[-0.2433, 0.4455, -0.4587, 0.0063],[-0.3669, 0.0171, -0.0988, -0.4452],[ 0.0198, -0.0679, 0.4203, -0.2088],[-0.1854, 0.1717, -0.2241, -0.1781],[-0.3429, -0.2653, 0.2822, 0.4938],[-0.0773, -0.3765, -0.0464, -0.2127]], requires_grad=True)
结论
当优化器只传入要更新的层的参数时,只会更新优化器传入的参数,对于没有传入的参数可以求导,但是仍然不会更新参数
方式一与方式二对比总结
在训练过程中可能需要固定一部分模型的参数,只更新另一部分参数。
有两种思路实现这个目标,一个是设置不要更新参数的网络层为false,另一个就是在定义优化器时只传入要更新的参数。
最优做法是,优化器只传入requires_grad=True的参数,这样占用的内存会更小一点,效率也会更高。
最优写法
最优写法
将不更新的参数的requires_grad设置为False,同时不将该参数传入optimizer
-
将不更新的参数的
requires_grad设置为False# 冻结fc1层的参数 for name, param in model.named_parameters():if "fc1" in name:param.requires_grad = False -
不将不更新的模型参数传入
optimizer# 定义一个fliter,只传入requires_grad=True的模型参数 optimizer = optim.SGD(filter(lambda p : p.requires_grad, model.parameters()), lr=1e-2)
代码
# 最优写法
loss_fn = nn.CrossEntropyLoss()# # 训练前的模型参数
print("model.fc1.weight", model.fc1.weight)
print("model.fc2.weight", model.fc2.weight)
print("model.fc1.weight.requires_grad:", model.fc1.weight.requires_grad)
print("model.fc2.weight.requires_grad:", model.fc2.weight.requires_grad)# 冻结fc1层的参数
for name, param in model.named_parameters():if "fc1" in name:param.requires_grad = Falseoptimizer = optim.SGD(filter(lambda p : p.requires_grad, model.parameters()), lr=1e-2) # 定义一个fliter,只传入requires_grad=True的模型参数for epoch in range(10):x = torch.randn((3, 8))label = torch.randint(0,3,[3]).long()output = model(x)loss = loss_fn(output, label)optimizer.zero_grad()loss.backward()optimizer.step()print("model.fc1.weight", model.fc1.weight)
print("model.fc2.weight", model.fc2.weight)
print("model.fc1.weight.requires_grad:", model.fc1.weight.requires_grad)
print("model.fc2.weight.requires_grad:", model.fc2.weight.requires_grad)
结果
(bbn) jyzhang@admin2-X10DAi:~/test$ python -u "/home/jyzhang/test/net.py"
model.fc1.weight Parameter containing:
tensor([[-0.1193, 0.2354, 0.2520, 0.1187, 0.2699, -0.2301, 0.1622, -0.0478],[-0.2862, -0.1716, 0.2865, 0.2615, -0.2205, -0.2046, -0.0983, -0.1564],[-0.3143, -0.2248, 0.2198, 0.2338, 0.1184, -0.2033, -0.3418, 0.1434],[ 0.3107, -0.0411, -0.3016, 0.1924, -0.1756, -0.2881, 0.0528, -0.0444]],requires_grad=True)
model.fc2.weight Parameter containing:
tensor([[-0.2548, 0.2107, -0.1293, -0.2562],[-0.1989, -0.2624, 0.2226, 0.4861],[-0.1501, 0.2516, 0.4311, -0.1650],[ 0.0334, -0.0963, -0.1731, 0.1706],[ 0.2451, -0.2102, 0.0499, 0.0497],[-0.1464, -0.2973, 0.3692, 0.0523],[ 0.1192, 0.3575, -0.1911, 0.1457],[-0.0990, 0.2059, 0.2072, -0.2013],[-0.4397, 0.4036, -0.3402, -0.0417],[ 0.0379, 0.0128, -0.3212, -0.0867]], requires_grad=True)
model.fc1.weight.requires_grad: True
model.fc2.weight.requires_grad: True
model.fc1.weight Parameter containing:
tensor([[-0.1193, 0.2354, 0.2520, 0.1187, 0.2699, -0.2301, 0.1622, -0.0478],[-0.2862, -0.1716, 0.2865, 0.2615, -0.2205, -0.2046, -0.0983, -0.1564],[-0.3143, -0.2248, 0.2198, 0.2338, 0.1184, -0.2033, -0.3418, 0.1434],[ 0.3107, -0.0411, -0.3016, 0.1924, -0.1756, -0.2881, 0.0528, -0.0444]])
model.fc2.weight Parameter containing:
tensor([[-0.2637, 0.2073, -0.1293, -0.2422],[-0.2027, -0.2641, 0.2152, 0.4897],[-0.1543, 0.2504, 0.4188, -0.1576],[ 0.0356, -0.0947, -0.1698, 0.1669],[ 0.2474, -0.2081, 0.0536, 0.0456],[-0.1445, -0.2962, 0.3708, 0.0500],[ 0.1219, 0.3574, -0.1876, 0.1404],[-0.0961, 0.2058, 0.2091, -0.2046],[-0.4368, 0.4039, -0.3376, -0.0450],[ 0.0398, 0.0143, -0.3181, -0.0897]], requires_grad=True)
model.fc1.weight.requires_grad: False
model.fc2.weight.requires_grad: True
结论
最优写法能够节省显存和提升速度:
- 节省显存:不将不更新的参数传入
optimizer - 提升速度:将不更新的参数的
requires_grad设置为False,节省了计算这部分参数梯度的时间
一些重要的代码总结
# 冻结network1的全部参数和network2的部分参数for name, parameter in network1.named_parameters():parameter.requires_grad = Falsefor name, parameter in network2.named_parameters():if 'key' in name:parameter.requires_grad = False# 优化器中过滤filter冻结的参数
optimizer_network2 = torch.optim.Adam(filter(lambda p: p.requires_grad, network2.parameters()), lr=0.005, betas=(0.5, 0.999))
# 结合加载模型部分参数的情况,优化器需要按如下设置:
optimizer_network2 = torch.optim.Adam([{'params': filter(lambda p: p.requires_grad, network2.parameters()), 'initial_lr': 0.0002}], lr=0.005, betas=(0.5, 0.999))
for p in self.backbone.parameters():p.requires_grad = Falseclass classifer(nn.Module):def __init__(self,in_ch,num_classes):super().__init__()self.avgpool = nn.AdaptiveAvgPool1d(1)self.fc = nn.Linear(in_ch,num_classes)def forward(self, x):x = self.avgpool(x.transpose(1, 2)) # B C 1x = torch.flatten(x, 1)x = self.fc(x)return xclass Swin(nn.Module):def __init__(self):super().__init__() #创建模型,并且加载预训练参数self.swin= create_model('swin_large_patch4_window7_224_in22k',pretrained=True)#整体模型的结构pretrained_dict = self.swin.state_dict()#去除模型的分类层self.backbone = nn.Sequential(*list(self.swin.children())[:-2])#去除分类层的模型架构model_dict = self.backbone.state_dict()# 将pretrained_dict里不属于model_dict的键剔除掉pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}# 更新现有的model_dictmodel_dict.update(pretrained_dict)# 加载我们真正需要的state_dictself.backbone.load_state_dict(model_dict)#屏蔽除分类层所有的参数for p in self.backbone.parameters():p.requires_grad = False#构建新的分类层self.head = classifer(1536, 14)def forward(self, x):x = self.backbone(x)x=self.head(x)return xoptimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, cnn.parameters()), lr=1e-4, betas=(0.9, 0.999),weight_decay=1e-6)if epoch ==1:for p in Swin.backbone.parameters():p.requires_grad = Trueoptimizer.add_param_group({'params': Swin.backbone.parameters()})
# we want to freeze the fc2 layer this time: only train fc1 and fc3
net.fc2.weight.requires_grad = False
net.fc2.bias.requires_grad = False# passing only those parameters that explicitly requires grad
optimizer = optim.Adam(filter(lambda p: p.requires_grad, net.parameters()), lr=0.1)# then do the normal execution of loss calculation and backward propagation# unfreezing the fc2 layer for extra tuning if needed
net.fc2.weight.requires_grad = True
net.fc2.bias.requires_grad = True# add the unfrozen fc2 weight to the current optimizer
optimizer.add_param_group({'params': net.fc2.parameters()})if self.frozen_pretrained_weights:self.eval()with torch.no_grad():output = self.encoders(batch)else:output = self.encoders(batch)
# 这将冻结 Resnet50 总共 10 层中的第 1-6 层。希望这有帮助!
model_ft = models.resnet50(pretrained=True)
ct = 0
for child in model_ft.children():
ct += 1
if ct < 7:for param in child.parameters():param.requires_grad = False
# let's unfreeze the fc2 layer this time for extra tuning
net.fc2.weight.requires_grad = True
net.fc2.bias.requires_grad = True# add the unfrozen fc2 weight to the current optimizer
optimizer.add_param_group({'params': net.fc2.parameters()})
def dfs_freeze(model):for name, child in model.named_children():for param in child.parameters():param.requires_grad = Falsedfs_freeze(child)
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=opt.lr, amsgrad=True)
相关文章:
第十三章 深度解读预训练与微调迁移,模型冻结与解冻(工具)
一个完整的代码 pythonCopy codeimport torch import torchvision import torchvision.transforms as transforms import torch.nn as nn import torch.optim as optim # 设置设备(CPU或GPU) device torch.device("cuda" if torch.cuda.is_a…...
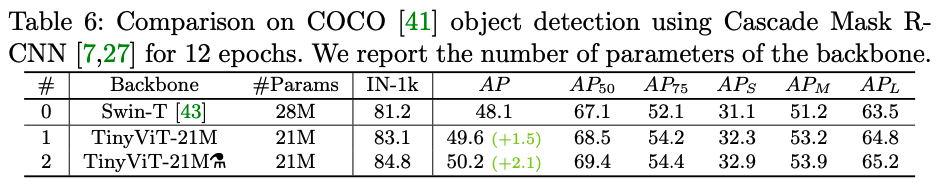
tinyViT论文笔记
论文:https://arxiv.org/abs/2207.10666 GitHub:https://github.com/microsoft/Cream/tree/main/TinyViT 摘要 在计算机视觉任务中,视觉ViT由于其优秀的模型能力已经引起了极大关注。但是,由于大多数ViT模型的参数量巨大&#x…...

解决ssh -T git@github.com报错connection closed问题
解决ssh -T gitgithub.com报错connection closed问题 问题解决 问题 $ ssh -T gitgithub.com kex_exchange_identification: Connection closed by remote host Connection closed by 20.205.243.166 port 22解决 参考链接 $ ssh -T -p 443 gitssh.github.com...

新手如何购买保险,保险投资基础入门
一、教程描述 本套保险教程,大小2.63G,共有11个文件。 二、教程目录 第01课 保险到底有什么用.mp4 第02课 已有社保还需要商业保险吗.mp4 第03课 你必须要懂的保险基础知识.mp4 第04课 关于重疾你必须要知道的几件事情.mp4 第05课 家庭重疾险如何…...
基于springboot网上超市管理系统
基于springboot网上超市管理系统 摘要 随着互联网的快速发展,电子商务行业迎来了蓬勃的发展,网上超市作为电子商务的一种形式,为消费者提供了便利的购物体验。本文基于Spring Boot框架,设计和实现了一个网上超市管理系统ÿ…...

FlagEmbedding目前最好的sentence编码工具
FlagEmbedding专注于检索增强llm领域,目前包括以下项目: Fine-tuning of LM : LM-Cocktail Dense Retrieval: LLM Embedder, BGE Embedding, C-MTEB Reranker Model: BGE Reranker 更新 11/23/2023: Release LM-Cocktail, 一种通过模型融合在微调时保持原有模型通用…...

rabbitMQ发布确认-交换机不存在或者无法抵达队列的缓存处理
rabbitMQ在发送消息时,会出现交换机不存在(交换机名字写错等消息),这种情况如何会退给生产者重新处理?【交换机层】 生产者发送消息时,消息未送达到指定的队列,如何消息回退? 核心&…...
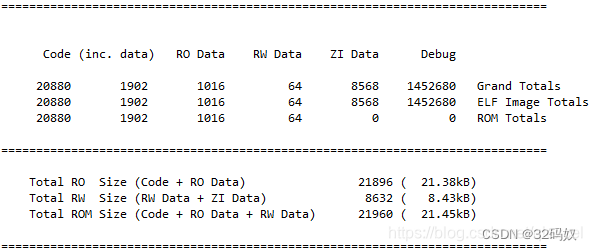
STM32 MAP文件
文章目录 1 生成Map2 map中概念3 文件分析流程3.1 Section Cross References3.2 Removing Unused input sections from the image(移除未使用的段)3.3 Image Symbol Table 映像符号表3.4 Memory Map of the image(映像的内存分布)…...

云原生Kubernetes系列 | Kubernetes静态Pod的使用
云原生Kubernetes系列 | Kubernetes静态Pod的使用 静态pod不建议在master上操作,因为master上跑的是集群核心静态pod,如果配置失败,会导致集群故障。建议在knode1或knode2上去做。 kubernetes master节点上的核心组件pod其实都是静态pod: [root@k8s-master ~]# ls /etc/ku…...

二次创作Z01语言
目录 一,字符集 二,编译分词 三,token含义 四,Z01翻译成C 五,执行翻译后的代码 六,打印Hello World! 一,字符集 假设有门语言叫Z01语言,代码中只有0和1这两种字符。 二&#…...

【蓝桥杯国赛真题28】Scratch行驶的汽车 少儿编程图形化编程 中小学生第十四届蓝桥杯scratch国赛真题讲解
目录 scratch行驶的汽车 一、题目要求 编程实现 二、案例分析 1、角色分析...

LeetCode Hot100 236.二叉树的最近公共祖先
题目: 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节…...

ERROR: Could not find a version that satisfies the requirement torch
在windows 上安装pip install torch torchvision torchaudio 报错: ERROR: Could not find a version that satisfies the requirement torch (from versions: none) ERROR: No matching distribution found for torch 解决办法: 将python版本降到3.11…...
2009年iMac装64位windows7及win10
2009年iMac装64位windows7及win10 Boot Camp没有“创建 Windows7 或更高版本的安装磁盘”选项 安装完Mac OS系统后,要制作Windows7安装U盘时才发现,Boot Camp没有“创建 Windows7 或更高版本的安装磁盘”选项,搜索到文章:修改Boo…...
(三) Windows 下 Sublime Text 3 配置Python环境和Anaconda代码提示
一:新建一个 Python3.7 编译环境。 1 Tools--Build System--New Build System... 修改前: 修改后: 内容: {"cmd":["C:\\Python\\Python37-32\\python.exe","-u","$file"],"file_r…...

【shell脚本】一些简单的shell脚本案例,mark一下
1、使用变量生成随机密码 比如自定义密码里面是数字和字母(或者还可以是某些符号等),随机生成一个想要的多少位的密码 [root@localhost test]#vim mima.sh #!/bin/bash str="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPKRSTUVWXYZ0123456789" for i in {1..6} …...
Android Studio记录一个错误:Execution failed for task ‘:app:lintVitalRelease‘.
Android出现Execution failed for task :app:lintVitalRelease.> Lint found fatal errors while assembling a release target. Execution failed for task :app:lintVitalRelease解决方法 Execution failed for task ‘:app:lintVitalRelease’ build project 可以正常执…...
计算机组成原理4
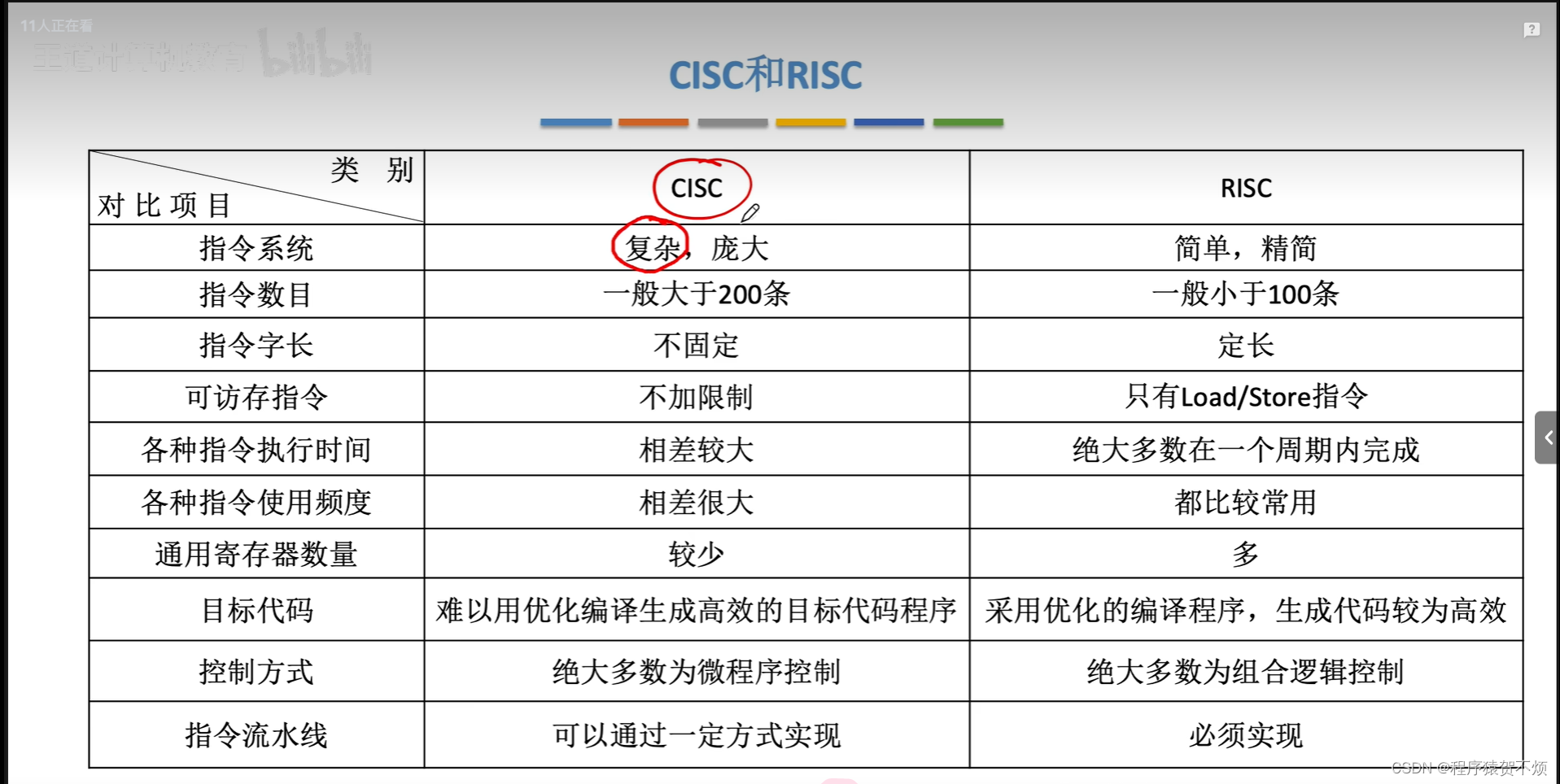
1.汇编语言 2.汇编语言常见的运算指令 3.AT&T格式 和 Intel格式 4.跳转指令 5.cmp比较的底层原理 6.函数调用的机器级表示 7.CISC和RISC...
【人工智能】Chatgpt的训练原理
前言 前不久,在学习C语言的我写了一段三子棋的代码,但是与我对抗的电脑是没有任何思考的,你看了这段代码就理解为什么了: void computerMove(char Board[ROW][COL], int row, int col) {while (1){unsigned int i rand() % ROW, …...
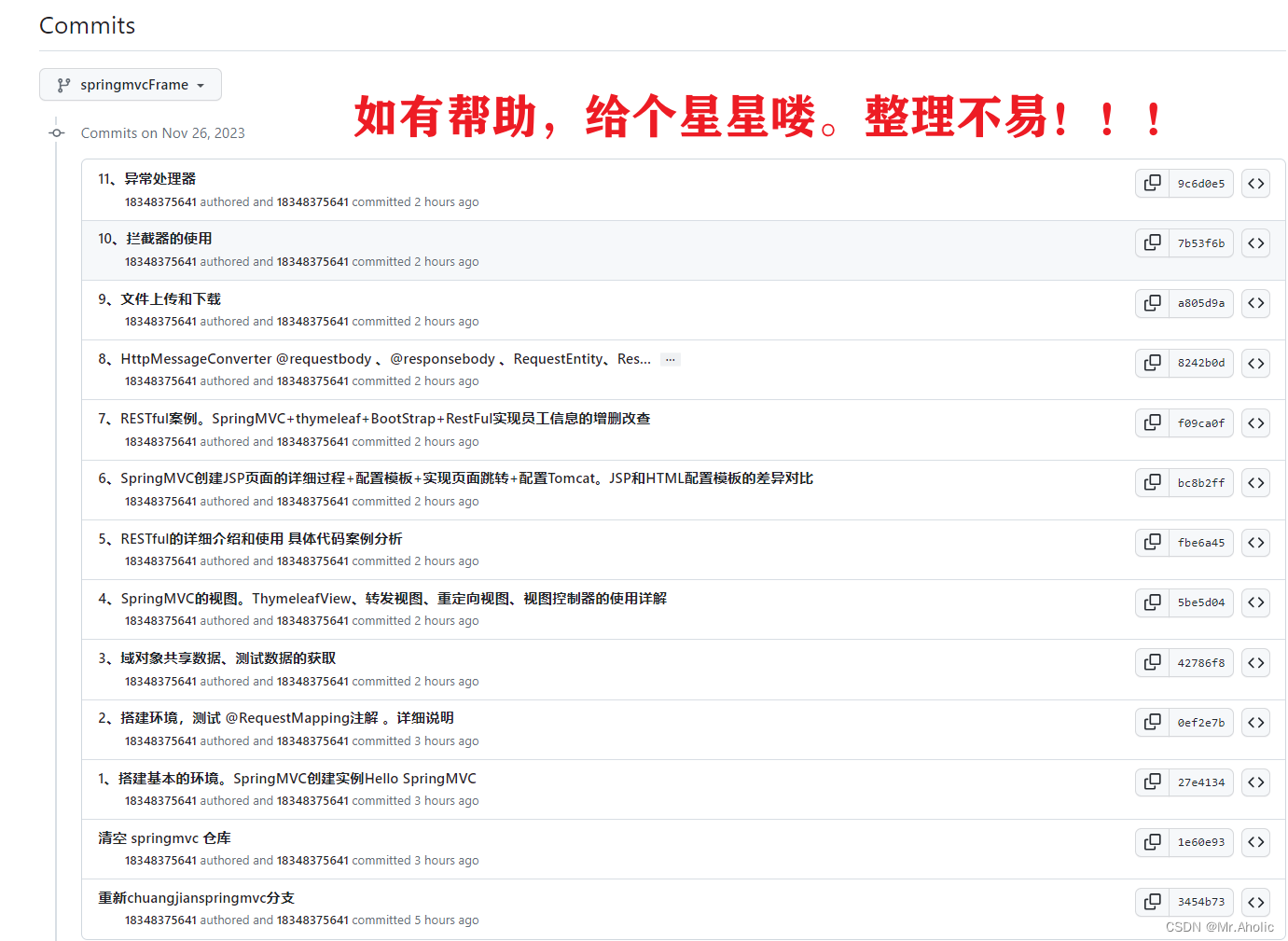
一文讲明SpringMVC 【爆肝整理一万五千字】
我 | 在这里 🕵️ 读书 | 长沙 ⭐软件工程 ⭐ 本科 🏠 工作 | 广州 ⭐ Java 全栈开发(软件工程师) 🎃 爱好 | 研究技术、旅游、阅读、运动、喜欢流行歌曲 ✈️已经旅游的地点 | 新疆-乌鲁木齐、新疆-吐鲁番、广东-广州…...

终极Deno安全开发指南:从权限控制到依赖审计的完整实践
终极Deno安全开发指南:从权限控制到依赖审计的完整实践 【免费下载链接】awesome-deno Curated list of awesome things related to Deno 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-deno Deno作为一个简单、现代且安全的JavaScript和TypeScript运…...

Switch_lib:面向继电器控制的轻量级数字引脚时序管理库
1. Switch_lib 库深度解析:面向继电器控制的数字引脚时序管理方案在工业控制、智能家居和嵌入式自动化系统中,对数字输出引脚进行精确、可编程的时序控制是基础而关键的需求。典型场景包括:继电器驱动(如水泵启停、照明定时、加热…...

不满意Oh My Zsh启动卡顿,来试试Starship吧裙
pagehelper整合 引入依赖com.github.pagehelperpagehelper-spring-boot-starter2.1.0compile编写代码 GetMapping("/list/{pageNo}") public PageInfo findAll(PathVariable int pageNo) {// 设置当前页码和每页显示的条数PageHelper.startPage(pageNo, 10);// 查询数…...

【大模型工程化终极指南】:SITS2026圆桌权威共识+3大不可逆趋势+2026落地时间表
第一章:SITS2026圆桌:大模型工程化的未来趋势 2026奇点智能技术大会(https://ml-summit.org) 在SITS2026圆桌讨论中,来自Meta、阿里云、Hugging Face与CNCF模型工作组的七位工程实践者共同指出:大模型工程化正从“能跑通”迈向“…...
)
平衡小车稳如老狗?聊聊PID参数整定那些‘玄学’与科学(附MATLAB/Simulink仿真文件)
平衡小车稳如老狗?聊聊PID参数整定那些‘玄学’与科学 平衡小车作为经典的控制系统教学案例,其核心挑战在于如何让直立环、速度环和转向环三个PID控制器协同工作。许多工程师在调参时常常陷入"凭感觉试"的困境——P值大了会振荡,小…...

智慧交通货车装载状态满载空载卡车是否载货检测数据集VOC+YOLO格式1053张3类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):1053标注数量(xml文件个数):1053标注数量(txt文件个数):1053标注类别…...

如何一键解决Mac视频预览问题:QuickLook Video终极指南
如何一键解决Mac视频预览问题:QuickLook Video终极指南 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gitco…...
高效部署到边缘端?)
RK3588 NPU实战:如何将PC训练的人脸识别模型(ONNX)高效部署到边缘端?
RK3588 NPU实战:从ONNX模型到边缘端高效部署的人脸识别全流程解析 当你在PyTorch或TensorFlow中完成人脸识别模型的训练,导出为ONNX格式的那一刻,真正的挑战才刚刚开始。如何让这个模型在RK3588的NPU上以最佳性能运行?这是每个从云…...

ComfyUI视觉AI引擎:无需编程构建稳定扩散工作流的最佳选择
ComfyUI视觉AI引擎:无需编程构建稳定扩散工作流的最佳选择 【免费下载链接】ComfyUI The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI Comfy…...

AI头像生成器效果分享:100+真实生成案例——古风人物Prompt高质量展示
AI头像生成器效果分享:100真实生成案例——古风人物Prompt高质量展示 1. 古风头像生成效果惊艳亮相 最近体验了一款基于Qwen3-32B的AI头像生成器,专门用来创作各种风格的头像创意文案。让我最惊喜的是它在古风人物生成方面的表现——只需要简单描述你想…...