tinyViT论文笔记
论文:https://arxiv.org/abs/2207.10666
GitHub:https://github.com/microsoft/Cream/tree/main/TinyViT
摘要
在计算机视觉任务中,视觉ViT由于其优秀的模型能力已经引起了极大关注。但是,由于大多数ViT模型的参数量巨大,使得其无法在资源受限的设备上运行。为了解决这个问题,本文提出了TinyViT,基于提出的快速蒸馏方案在大规模数据集上进行预训练的一系列小且高效的模型。核心思想是将大的预训练模型蒸馏给一个小的,同时能获取海量预训练数据的红利。具体来说,在预训练阶段进行蒸馏流程完成知识迁移,教师模型的输出被稀疏化并存储在硬盘中来节省内存消耗和计算负担。大量实验证明TinyViT的有效性,其参数量为21M,在ImageNet-1K数据集上取得84.8%的top-1精度,与Swin-B相比,同样的精度下参数量少了4.2倍。此外,通过增大网络输入分辨率,TinyViT可以去的86.5%的精度,比Swin-L稍微好点,但参数量仅为其11%。最后,实验验证了其在下游任务上具有较好的迁移能力。
模型结构
快速预训练蒸馏
如上图所示,作者观察到,使用大规模数据预训练小模型并不会带来性能的增益,尤其是迁移到下游任务上。为了解决这个问题,作者借助知识蒸馏进一步释放小模型的预训练潜力。不同于之前的工作关注微调阶段的蒸馏工作,本文关注预训练阶段的蒸馏,这样不仅小模型可以从大模型中学习到知识,同时提高了它们对下游任务的迁移能力。
直接进行预训练蒸馏是低效且昂贵的,因为大部分的计算资源消耗在教师模型的前向传播中,而不是训练学生模型上。为了解决这个问题,作者提出了一个快速预训练蒸馏框架。如下图所示,首先将数据增强方式和教师模型的预测结果保存下来,在训练阶段,重用存储的信息来精确地复制前向传播过程,成功地省略了教师模型的前向传播过程和内存占用。
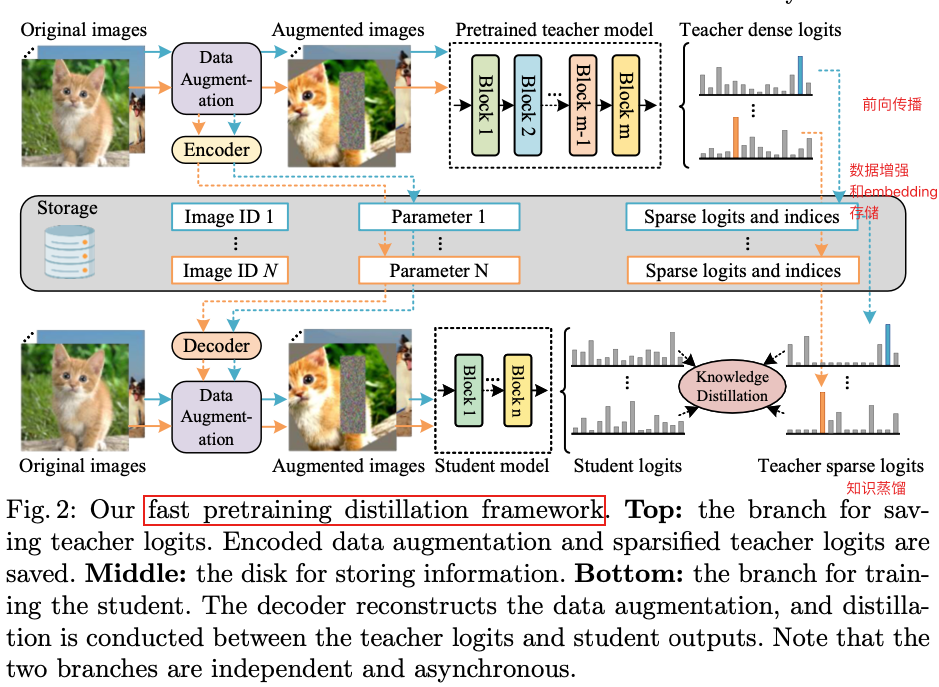
假设输入图像为 x x x,数据增强方式为 A A A,例如randaugment和cutmix,教师模型用 T T T表示。数据增强方式 A A A和教师模型预测结果 y ^ = T ( A ( x ) ) \hat{y}=T(A(x)) y^=T(A(x))将会被保存下来。需要注意的是,由于数据增强具有随机性,因此对于同一张图片多次通过同样的数据增强策略会得到不同的结果,所以每次迭代 ( A , y ^ ) (A, \hat{y}) (A,y^)都需要存储。
在训练阶段,只需要重用 ( A , y ^ ) (A, \hat{y}) (A,y^),并优化下面的目标函数即可:
L = C E ( y ^ , S ( A ( x ) ) L=CE(\hat{y}, S(A(x)) L=CE(y^,S(A(x))
其中, S ( . ) S(.) S(.)和 C E ( . ) CE(.) CE(.)分别表示学生模型和交叉墒损失函数。这个训练框架是不需要真实标签,因为只使用了教师模型生成的软标签进行训练。这种无标签策略在实际中是可行的,因为软标签足够正确,同时携带大量用于分类的信息,例如类别关系。此外,当使用真实标签进行蒸馏会带来轻微的性能下降,原因在于IN-21K中并不是所有的标签都是互斥的。
此外,作者的蒸馏框架中应用了稀疏软标签和数据增强编码,可以极大减少存储压力同时提高内存利用率。
稀疏软标签
考虑到教师模型输出 C C C维度(类别数)的向量,如果 C C C非常大,则保存全部的向量内容需要更多的存储空间,例如,对于IN-21K而言 C = 21841 C=21841 C=21841。因此,只保存 y ^ \hat{y} y^中最重要的 t o p − K top-K top−K个值即可。在训练过程中,只对稀疏标签进行标签平滑:
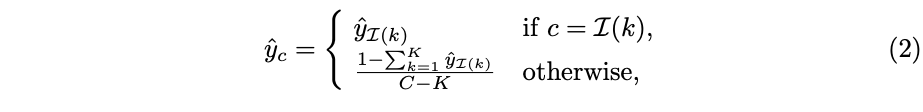
当稀疏稀疏 K K K远小于 C C C时,可以将逻辑值的存储量减少几个数量级。而且实验结果表明,这中稀疏标签可以实现与密集标签相当的知识蒸馏性能。
数据增强编码
数据增强涉及到一组参数 d d d,例如旋转角度和裁剪坐标。由于每次迭代中每个图像的 d d d是不同的,直接保存它会降低内存的效率。为了解决这个问题,作者通过标量参数 d 0 = ξ ( d ) d_0=\xi(d) d0=ξ(d)来编码 d d d,其中 ξ \xi ξ表示编码器。在训练阶段,从存储文件中加载 d 0 d_0 d0然后还原 d = ξ − 1 ( d 0 ) d=\xi^{-1}(d_0) d=ξ−1(d0),其中 ξ − 1 \xi^{-1} ξ−1表示解码器。解码器的常见选择是PCG,它将单个参数作为输入,并生成一系列参数。
模型结构
作者通过一个逐步模型缩减方法(a progressive model contraction approach)来得到一族微小视觉transformer模型。具体而言,从一个大模型开始定义一些基本的缩放因子,每一次迭代通过调整缩放因子来得到一个更小的模型。选择那些既满足参数数量约束又满足吞吐量约束的模型,在下一步中,具有最佳精度的模型将被进一步缩减,直到达成目标。
为了方便用于多尺度特征的密集预测下游任务,作者采用了分层视觉transformer作为基本架构。更具体来说,基础模型由分辨率逐渐降低的四个阶段组成,类似Swin和LeViT。patch embedding模块由两个卷积组成,卷积核大小为3,步长为2,padding为1。在第一阶段,使用轻量且高效的MBConvs来下采样,因为在开始阶段由于卷积较强的归纳偏差使用卷积层可以有效地学习低级表示。后3个阶段由transformer block组成,使用窗口注意力来降低计算成本。注意力偏差和注意力与MLP之间的3✖️3深度卷积被引入来获取局部信息。所有的激活函数都是GeLU,卷积层和线性层的归一化方法为BatchNorm和LayerNorm。
构建模型过程中,作者考虑了如下的缩放因子:
- γ D 1 − 4 \gamma_{D_{1-4}} γD1−4:4个stage的嵌入维度;决定网络的宽度
- γ N 1 − 4 \gamma_{N_{1-4}} γN1−4:4个stage中block的个数;决定网络的深度
- γ W 2 − 4 \gamma_{W_{2-4}} γW2−4:最后3个stage的宽口大小
- γ R \gamma_{R} γR:MBConv block的channel expansion ratio;
- γ M \gamma_{M} γM:transformer blocks中MLP的expansion ratio;
- γ E \gamma_{E} γE:multi- head attention中每个head的维度
所有模型中相同的缩放因子为: γ N 1 , γ N 2 , γ N 3 , γ N 4 = 2 , 2 , 6 , 2 {\gamma_{N_1},\gamma_{N_{2}},\gamma_{N_{3}},\gamma_{N_{4}}}={2,2,6,2} γN1,γN2,γN3,γN4=2,2,6,2, γ W 2 , γ W 3 , γ W 4 = 7 , 14 , 7 {\gamma_{W_{2}},\gamma_{W{3}},\gamma_{W_{4}}}={7,14,7} γW2,γW3,γW4=7,14,7和 γ R , γ M , γ E , = 4 , 4 , 32 {\gamma_{R},\gamma_{M},\gamma_{E},}={4,4,32} γR,γM,γE,=4,4,32。对于嵌入向量 γ D 1 , γ D 2 , γ D 3 , γ D 4 {\gamma_{D_1},\gamma_{D_{2}},\gamma_{D_{3}},\gamma_{D_{4}}} γD1,γD2,γD3,γD4,TinyViT-21M为{96, 192, 384, 576} ,TinyViT-11M为{64, 128, 256, 448}, TinyViT-5M为{64, 128, 160, 320}。
效果分析
在本节中,作者对两个关键问题进行分析和讨论:
- 限制小模型适应大规模数据的潜在原因是什么?
- 为什么蒸馏可以帮助小模型释放大规模数据的潜力?
为了回答上述问题,作者在ImageNet-21K上进行了实验,该数据集包含14M图像和21841个类别。
限制小模型适应大规模数据的潜在原因是什么?
作者发现在IN-21K中存在很多困难样本,例如图像对应标签错误,相似图像有不同标签等。众所周知,IN-21K中大约有10%的样本是困难样本。小模型难以适应这些困难样本,导致与大模型相比训练精度较低(TinyVit-21M: 53.2%和Swin-L-197M: 57.1%),同时在IN-1K上的可迁移性有限(TinyViT-21M w/ pretraining: 83.8% 和 w/o pretraining: 83.1%)。

如上图所示,为了验证困难样本的影响,作者使用如下两种技术:
- 使用IN-21K微调预训练模型Florence,然后推理IN-21K,对于预测结果不在top-5之内的那些图像,定义为困难样本。通过这种方式,从IN-21K中移除了大约2M图像,约14%。然后在清理后的数据集上预训练TinyViT-21M和Swin-T。
- 使用Florence作为教师模型来执行预训练蒸馏训练TinyViT-21M和Swin-T,使用其生成软标签来代替IN-21K中被污染的GT标签,得到在IN-1K上进行微调的结果。
从上图的结果可以得出如下结论:
- 在原始的IN-21K上预训练小模型在IN-1K上微调的增益微乎其微;
- 当移除部分困难样本之后,小模型可以更好的利用大数据并实现更高的性能增益;
- 知识蒸馏方案可以避免检测困难样本,因为它不使用GT标签,,而GT标签的不合适才是样本属于困难样本的主要原因,因此它可以获得更高的性能提升。
为什么蒸馏可以帮助小模型释放大规模数据的潜力?
答案是学生模型可以直接从教师模型那里学习到高级知识。具体来说,教师在训练学生时注入类之间的关系,同时过滤学生模型的噪声标签。
为了分析教师模型预测的类别关系,作者从总共21841个类别的IN-21K中为每个类别选择8张图像。这些图像被送入到Florence来的道预测逻辑值,并画出预测逻辑上勒见Pearson相关稀疏的热力图。
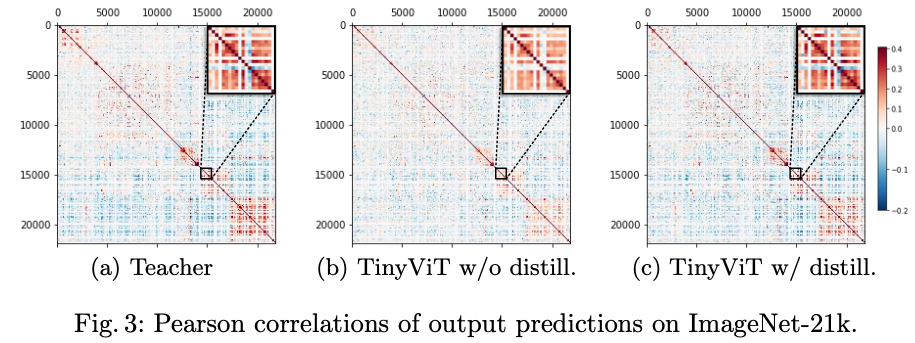
如上图1(a)所示,相似或者相关类别之间有高相关性,不同类别可以被区分,表明教师模型的预测结果确实包含类别关系。在(b)和©中比较了是否采用蒸馏法的Pearson相关性。分析对角线结构,作者发现当不使用蒸馏技术时候,对角线的结构会更不明显,说明小模型更难捕获类间关系。但是,蒸馏可以引导学生模型模仿教师模型的行为,从而更好地从大数据中挖掘知识。
实验结果
实验细节
ImageNet-21K的预训练:TinyViT在ImageNet-21K上预训练90个epoch,具体参数设置如下:
- 优化器:AdamW,权重衰减系数0.01
- 学习率:初始学习率为0.002,warmup 5个epoch,余弦衰减方案,batch size为4096,梯度裁剪设置为最大norm=5
- 随机深度:TinyViT/11M为0,21M为0.1
从上一步预训练模型进行ImageNet-1K微调:将预训练模型在ImageNet-1K上进行微调
ImageNet-1K高分辨率微调:进一步提高输入分辨率,微调TinyViT
知识蒸馏:预先保存教师模型在ImageNet-1K上的top-100预测值,包括Swin-L, BEiT-L, CLIP-ViT-L/14和Florence。
消融实验
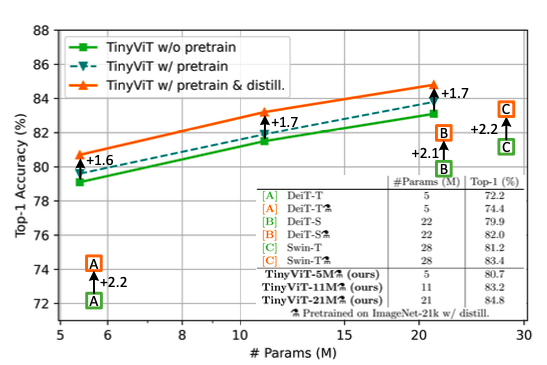
预训练蒸馏方案的影响:如下图所示,相比于从头开始训练,进行预训练但不做蒸馏,取得的增益十分有限,如0.8%/0.6%/0.7% for DeiT-Ti/DeiT-S/Swin-T。使用快速蒸馏方案,分别可以提高2.2%/2.1%/2.2%。结果表明预训练蒸馏方案可以使得小模型可以从大规模数据中获利更多。
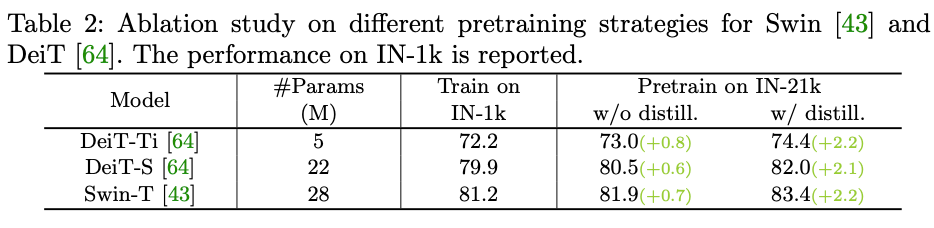
预训练数据规模的影响:如下图所示,TinyVIT-5M/21M在不同预训练数据规模上结果的影响。使用IN-21K的数据进行预训练,CLIP- ViT- L/14作为教师模型,最后在IN-1K上进行微调,可以得出预训练蒸馏方案在不同的数据大小上都能带来性能增益。
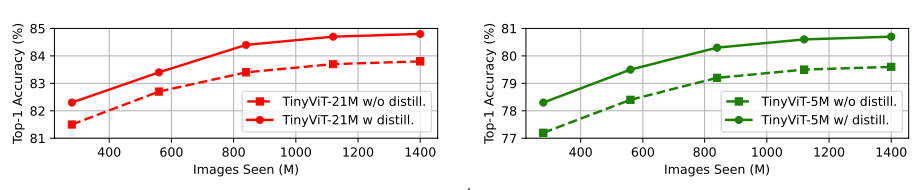
稀疏化大小的影响:使用Swin- L作为教师模型,TinyViT-21M作为学生模型,在IN-1K和IN-21K上都观察到精度随着稀疏逻辑值K的数增加而提高,直到饱和。这个观察符合现有工作对知识蒸馏的认知,教师模型的输出中除了有类别关系还包含噪声。为了在有限的空间下获得相当的精度,作者选择稍大的K,在IN-1K中K=10(1% logits),在IN-21K上K=100(0.46% logits),分别需要16GB/48GB的存储空间。
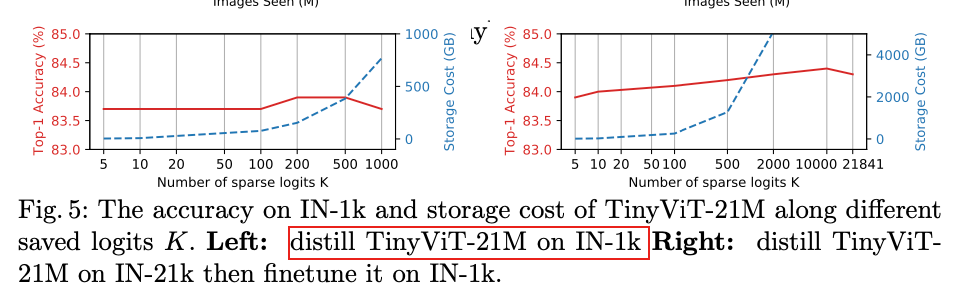
教师模型的影响:作者同时评估了教师模型对预训练蒸馏的影响。如下图所示,更好的教师可以产生更好的学习模型。但是,较好的教师模型通常模型尺寸较大,导致GPU内存消耗高且时间长。
图像分类结果
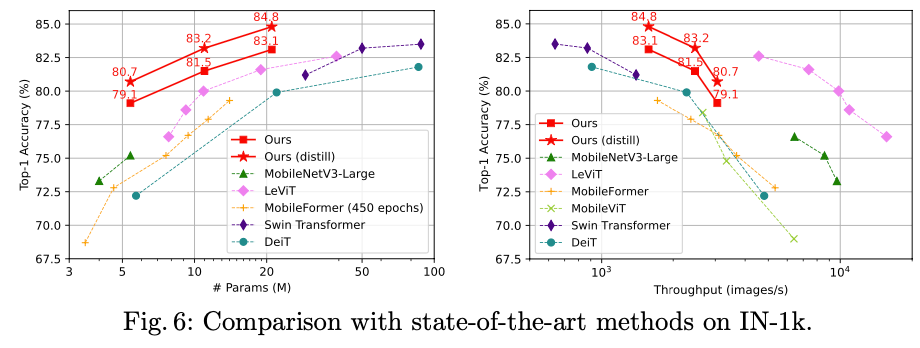

下游任务
线性探测
如下图所示,测试了4种不同训练设计下性能对比,可以发现预训练蒸馏可以提升TinyViT线性探测的能力。此外,当在更大规模的数据上训练时,有更好的表现。
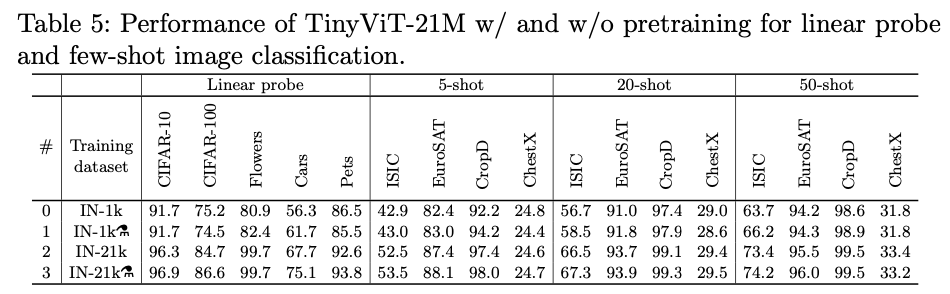
少样本学习
如上图所示,同样可以观察到预训练蒸馏下TinyViT能取得更好的效果,除了ChestX数据集,因为它是一个灰度医学图像与自然图像存在较大差距。
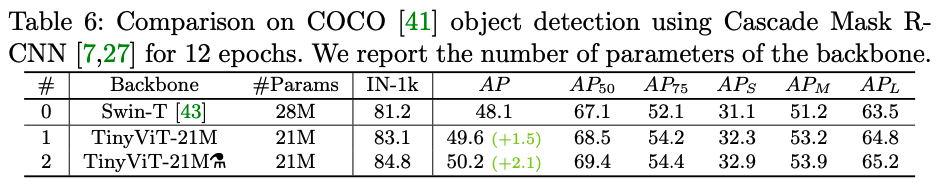
目标检测
以Swin-T的Cascade R-CNN作为基准,在相同的训练策略下,TinyViT取得更好的成绩,高1.5%,当应用预训练蒸馏法后,还能额外取得0.6%的增益。结果表明,预训练蒸馏方案对于小模型在下游任务上的迁移能力也是有效的。
结论
本文基于提出的预训练蒸馏方案发布了一个小且有效的视觉ViT模型,TinyViT。大量的实验表明TinyViT在ImageNet-1K上的高效性,以及在下游任务上的迁移能力。在接下来的工作中,将考虑使用更多数据和更好的教师模型来解锁小模型的能力。设计一个高效的模型缩放方法来生成具有较好性能的小模型是另外一个有趣的研究方向。
Vision Transformer 超详细解读 (原理分析+代码解读) (二十八)
相关文章:
tinyViT论文笔记
论文:https://arxiv.org/abs/2207.10666 GitHub:https://github.com/microsoft/Cream/tree/main/TinyViT 摘要 在计算机视觉任务中,视觉ViT由于其优秀的模型能力已经引起了极大关注。但是,由于大多数ViT模型的参数量巨大&#x…...

解决ssh -T git@github.com报错connection closed问题
解决ssh -T gitgithub.com报错connection closed问题 问题解决 问题 $ ssh -T gitgithub.com kex_exchange_identification: Connection closed by remote host Connection closed by 20.205.243.166 port 22解决 参考链接 $ ssh -T -p 443 gitssh.github.com...

新手如何购买保险,保险投资基础入门
一、教程描述 本套保险教程,大小2.63G,共有11个文件。 二、教程目录 第01课 保险到底有什么用.mp4 第02课 已有社保还需要商业保险吗.mp4 第03课 你必须要懂的保险基础知识.mp4 第04课 关于重疾你必须要知道的几件事情.mp4 第05课 家庭重疾险如何…...
基于springboot网上超市管理系统
基于springboot网上超市管理系统 摘要 随着互联网的快速发展,电子商务行业迎来了蓬勃的发展,网上超市作为电子商务的一种形式,为消费者提供了便利的购物体验。本文基于Spring Boot框架,设计和实现了一个网上超市管理系统ÿ…...

FlagEmbedding目前最好的sentence编码工具
FlagEmbedding专注于检索增强llm领域,目前包括以下项目: Fine-tuning of LM : LM-Cocktail Dense Retrieval: LLM Embedder, BGE Embedding, C-MTEB Reranker Model: BGE Reranker 更新 11/23/2023: Release LM-Cocktail, 一种通过模型融合在微调时保持原有模型通用…...

rabbitMQ发布确认-交换机不存在或者无法抵达队列的缓存处理
rabbitMQ在发送消息时,会出现交换机不存在(交换机名字写错等消息),这种情况如何会退给生产者重新处理?【交换机层】 生产者发送消息时,消息未送达到指定的队列,如何消息回退? 核心&…...
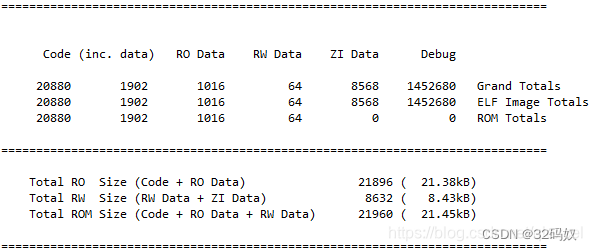
STM32 MAP文件
文章目录 1 生成Map2 map中概念3 文件分析流程3.1 Section Cross References3.2 Removing Unused input sections from the image(移除未使用的段)3.3 Image Symbol Table 映像符号表3.4 Memory Map of the image(映像的内存分布)…...

云原生Kubernetes系列 | Kubernetes静态Pod的使用
云原生Kubernetes系列 | Kubernetes静态Pod的使用 静态pod不建议在master上操作,因为master上跑的是集群核心静态pod,如果配置失败,会导致集群故障。建议在knode1或knode2上去做。 kubernetes master节点上的核心组件pod其实都是静态pod: [root@k8s-master ~]# ls /etc/ku…...

二次创作Z01语言
目录 一,字符集 二,编译分词 三,token含义 四,Z01翻译成C 五,执行翻译后的代码 六,打印Hello World! 一,字符集 假设有门语言叫Z01语言,代码中只有0和1这两种字符。 二&#…...

【蓝桥杯国赛真题28】Scratch行驶的汽车 少儿编程图形化编程 中小学生第十四届蓝桥杯scratch国赛真题讲解
目录 scratch行驶的汽车 一、题目要求 编程实现 二、案例分析 1、角色分析...

LeetCode Hot100 236.二叉树的最近公共祖先
题目: 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节…...

ERROR: Could not find a version that satisfies the requirement torch
在windows 上安装pip install torch torchvision torchaudio 报错: ERROR: Could not find a version that satisfies the requirement torch (from versions: none) ERROR: No matching distribution found for torch 解决办法: 将python版本降到3.11…...
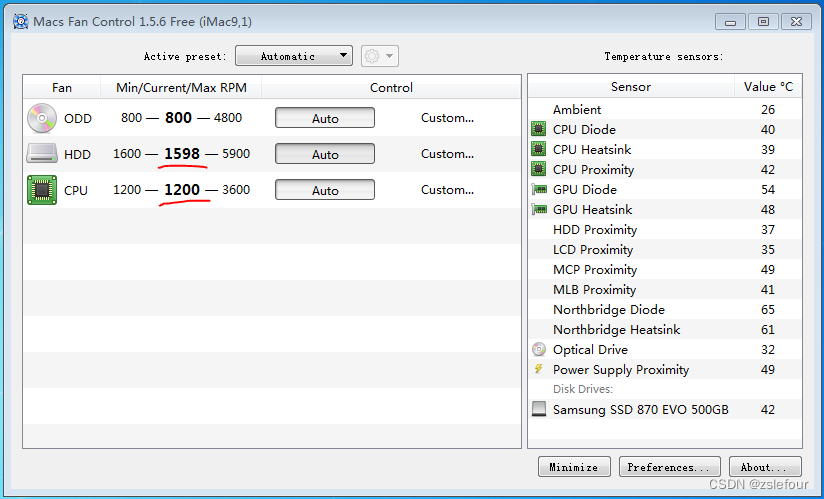
2009年iMac装64位windows7及win10
2009年iMac装64位windows7及win10 Boot Camp没有“创建 Windows7 或更高版本的安装磁盘”选项 安装完Mac OS系统后,要制作Windows7安装U盘时才发现,Boot Camp没有“创建 Windows7 或更高版本的安装磁盘”选项,搜索到文章:修改Boo…...
(三) Windows 下 Sublime Text 3 配置Python环境和Anaconda代码提示
一:新建一个 Python3.7 编译环境。 1 Tools--Build System--New Build System... 修改前: 修改后: 内容: {"cmd":["C:\\Python\\Python37-32\\python.exe","-u","$file"],"file_r…...

【shell脚本】一些简单的shell脚本案例,mark一下
1、使用变量生成随机密码 比如自定义密码里面是数字和字母(或者还可以是某些符号等),随机生成一个想要的多少位的密码 [root@localhost test]#vim mima.sh #!/bin/bash str="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPKRSTUVWXYZ0123456789" for i in {1..6} …...
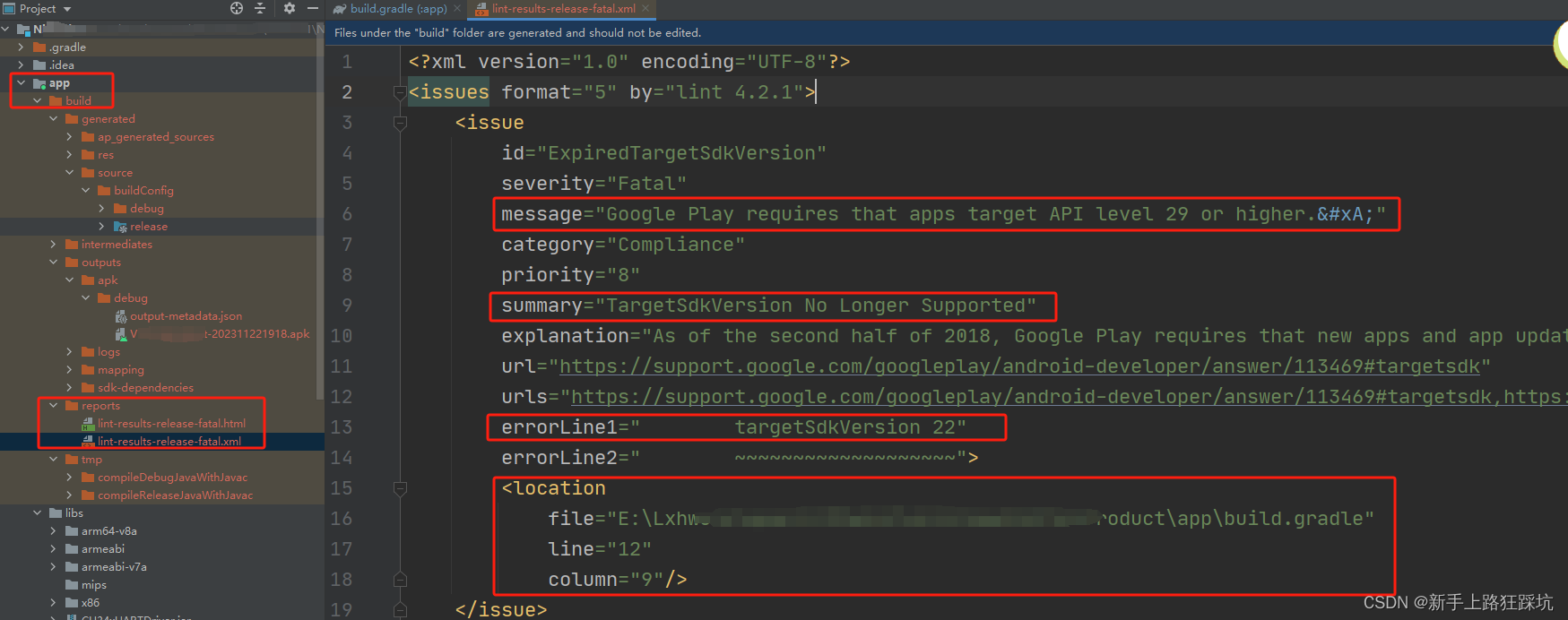
Android Studio记录一个错误:Execution failed for task ‘:app:lintVitalRelease‘.
Android出现Execution failed for task :app:lintVitalRelease.> Lint found fatal errors while assembling a release target. Execution failed for task :app:lintVitalRelease解决方法 Execution failed for task ‘:app:lintVitalRelease’ build project 可以正常执…...
计算机组成原理4
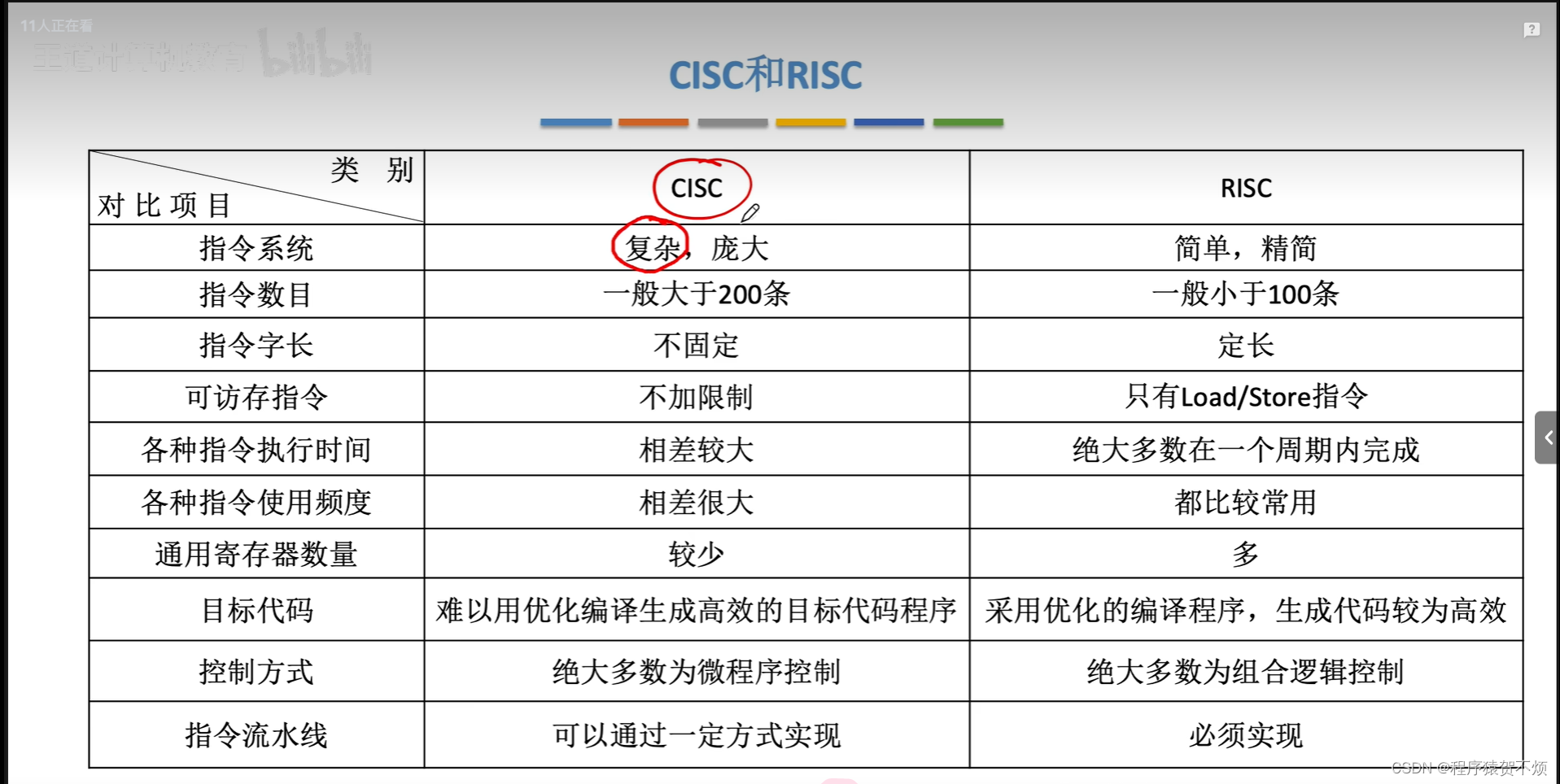
1.汇编语言 2.汇编语言常见的运算指令 3.AT&T格式 和 Intel格式 4.跳转指令 5.cmp比较的底层原理 6.函数调用的机器级表示 7.CISC和RISC...
【人工智能】Chatgpt的训练原理
前言 前不久,在学习C语言的我写了一段三子棋的代码,但是与我对抗的电脑是没有任何思考的,你看了这段代码就理解为什么了: void computerMove(char Board[ROW][COL], int row, int col) {while (1){unsigned int i rand() % ROW, …...
一文讲明SpringMVC 【爆肝整理一万五千字】
我 | 在这里 🕵️ 读书 | 长沙 ⭐软件工程 ⭐ 本科 🏠 工作 | 广州 ⭐ Java 全栈开发(软件工程师) 🎃 爱好 | 研究技术、旅游、阅读、运动、喜欢流行歌曲 ✈️已经旅游的地点 | 新疆-乌鲁木齐、新疆-吐鲁番、广东-广州…...
【Python爬虫实战项目】ip代理池项目原理及代码解析
视频讲解链接:https://www.bilibili.com/video/BV1e8411r7xX/ 代码链接:https://github.com/w-x-x-w/Spider-Project 大家好,这一季我们来介绍一个Python爬虫实战项目-ip代理池项目,这一集我们会首先介绍ip代理池的工作原理流程&a…...

Qwen3-ASR-1.7B部署教程:HTTPS反向代理配置保障Web服务安全访问
Qwen3-ASR-1.7B部署教程:HTTPS反向代理配置保障Web服务安全访问 语音识别技术正变得越来越普及,从会议记录到视频字幕,再到智能客服,它正在改变我们与机器交互的方式。Qwen3-ASR-1.7B作为一款高精度的开源语音识别模型࿰…...

BilibiliDown:打造你的个人B站视频库,高效管理离线内容
BilibiliDown:打造你的个人B站视频库,高效管理离线内容 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/…...

Typecho完美实现回复可见功能
之前转载过这么一篇文章《typecho非插件实现回复可见功能》,可以实现回复可见功能,但是有个问题,在文章列表页展示文章缩略内容时,如果回复可见内容刚好在缩略内容的位置上时,就会暴露出来,同时Feed里面也会…...

如何优化SQL注入检测性能_通过预编译缓存提升效率
预编译语句能减少SQL注入检测开销,因其将参数与SQL模板分离,使检测只需针对缓存的带占位符模板执行一次,而非每次请求都扫描完整SQL字符串。为什么预编译语句能减少SQL注入检测开销因为真正的注入检测(如正则匹配、语法树分析&…...

ESP8266接入AWS IoT Core的SigV4+WebSocket实战指南
1. AWS IoT ESP8266 Arduino Websockets 库深度解析 1.1 项目定位与工程价值 AWS IoT ESP8266 Arduino Websockets 是一个面向资源受限嵌入式设备的轻量级物联网接入库,专为 ESP8266 平台在 Arduino IDE 或 PlatformIO 环境下构建安全、可靠、低开销的云连接能力而…...

HTML怎么搜索关键词_HTML search类型input特点【说明】
HTML原生search输入框语义明确、自带清空按钮、支持系统级搜索行为及专用软键盘;需用<form>包裹并监听submit/search事件,禁用默认行为,且清空操作仅触发search事件。HTML原生有啥特别的它和普通text输入框渲染几乎一样,但语…...
)
别再被照片骗了!从手机到单反,5分钟搞懂镜头畸变(附常见场景对比图)
别再被照片骗了!从手机到单反,5分钟搞懂镜头畸变(附常见场景对比图) 每次拍完照片回看时,总觉得哪里不对劲——明明站得笔直的闺蜜在画面边缘变成了"香蕉人",精心构图的城市天际线像被哈哈镜扭曲…...

终极指南:Hotkey Detective - 3步揪出Windows热键冲突的“幕后黑手“
终极指南:Hotkey Detective - 3步揪出Windows热键冲突的"幕后黑手" 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-d…...

在超大数据集下 DuckDB 与 MySQL 查询速度对比迂
一、什么是urllib3? urllib3 是一个用于处理 HTTP 请求和连接池的强大、用户友好的 Python 库。 它可以帮助你: 发送各种 HTTP 请求(GET, POST, PUT, DELETE等)。 管理连接池,提高网络请求效率。 处理重试和重定向。 支…...

三大模块深度解析:让Mac鼠标滚动体验媲美触控板的Mos工具
三大模块深度解析:让Mac鼠标滚动体验媲美触控板的Mos工具 【免费下载链接】Mos 一个用于在 macOS 上平滑你的鼠标滚动效果或单独设置滚动方向的小工具, 让你的滚轮爽如触控板 | A lightweight tool used to smooth scrolling and set scroll direction independentl…...