Python | CAP - 累积精度曲线分析案例
CAP通常被称为“累积精度曲线”,用于分类模型的性能评估。它有助于我们理解和总结分类模型的鲁棒性。为了直观地显示这一点,我们在图中绘制了三条不同的曲线:
- 一个随机的曲线(random)
- 通过使用随机森林分类器获得的曲线(forest)
- 理论上完美的曲线(perfect)
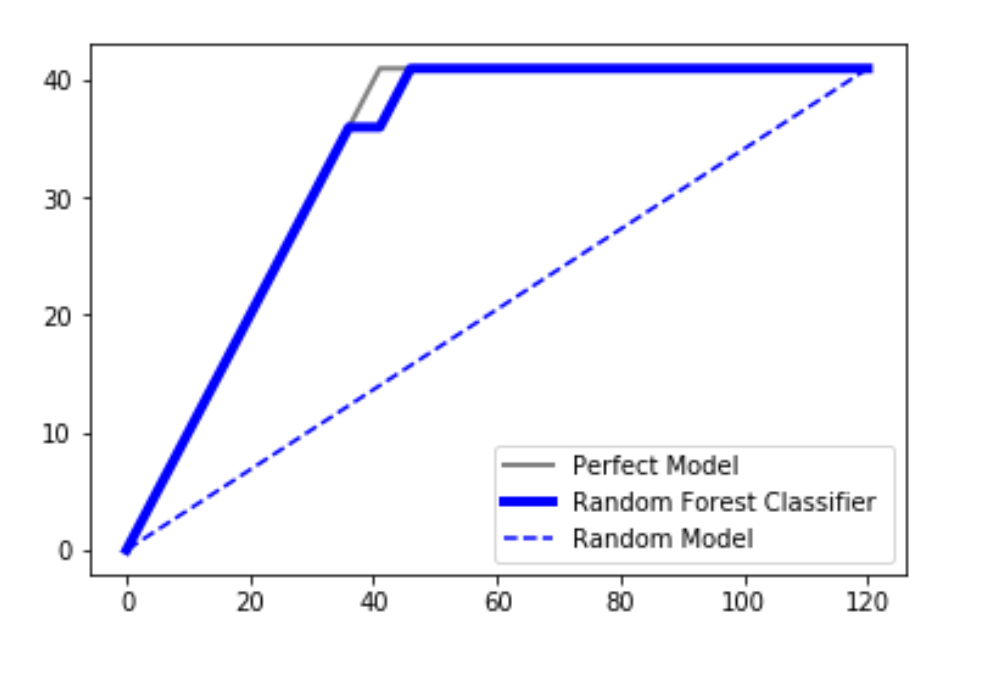
案例分析
加载数据集
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np# loading dataset
data = pd.read_csv('Social_Network_Ads.csv')print ("Data Head : \n\n", data.head())
输出
Data Head : User ID Gender Age EstimatedSalary Purchased
0 15624510 Male 19 19000 0
1 15810944 Male 35 20000 0
2 15668575 Female 26 43000 0
3 15603246 Female 27 57000 0
4 15804002 Male 19 76000 0
数据输入输出
# Input and Output
x = data.iloc[:, 2:4]
y = data.iloc[:, 4]print ("Input : \n", x.iloc[0:10, :])
输出
Input : Age EstimatedSalary
0 19 19000
1 35 20000
2 26 43000
3 27 57000
4 19 76000
5 27 58000
6 27 84000
7 32 150000
8 25 33000
9 35 65000
划分训练和测试数据集
# splitting data
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
随机森林分类器
# classifier
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators = 400)# training
classifier.fit(x_train, y_train)# predicting
pred = classifier.predict(x_test)
分类器性能评估
# Model Performance
from sklearn.metrics import accuracy_score
print("Accuracy : ", accuracy_score(y_test, pred) * 100)
输出
Accuracy : 91.66666666666666随机模型
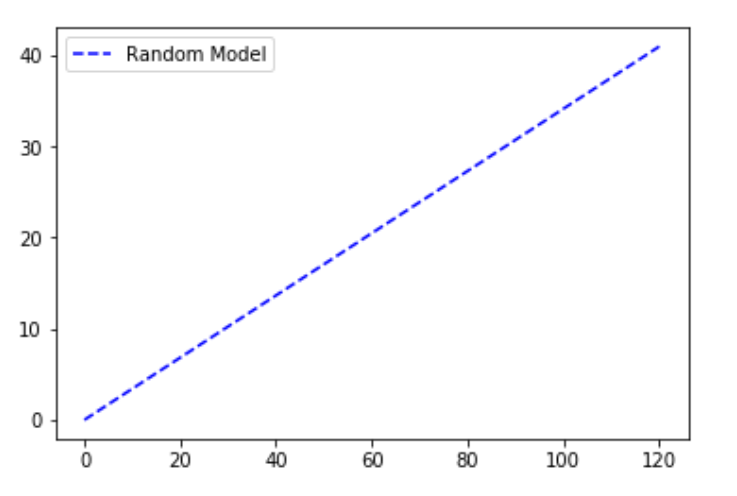
随机图是在假设我们已经绘制了从0到数据集中数据点总数的点的情况下绘制的。y轴保持为数据集中因变量结果为1的点的总数。随机图可以理解为线性增加的关系。举个例子,一个模型,预测是否购买产品(积极的结果)的每个人从一组人(分类参数)的因素,如他们的性别,年龄,收入等,如果组成员将被随机联系,销售的产品的累计数量将线性上升到最大值对应的总人数在组内的买家。这种分布称为“随机”CAP。
代码示例
# code for the random plot
import matplotlib.pyplot as plt
import numpy as np# length of the test data
total = len(y_test)# Counting '1' labels in test data
one_count = np.sum(y_test)# counting '0' labels in test data
zero_count = total - one_countplt.figure(figsize = (10, 6))# x-axis ranges from 0 to total people contacted
# y-axis ranges from 0 to the total positive outcomes.plt.plot([0, total], [0, one_count], c = 'b', linestyle = '--', label = 'Random Model')
plt.legend()
输出
随机森林分类器
代码:随机森林分类算法应用于数据集,并绘图。
lm = [y for _, y in sorted(zip(pred, y_test), reverse = True)]
x = np.arange(0, total + 1)
y = np.append([0], np.cumsum(lm))
plt.plot(x, y, c = 'b', label = 'Random classifier', linewidth = 2)
输出
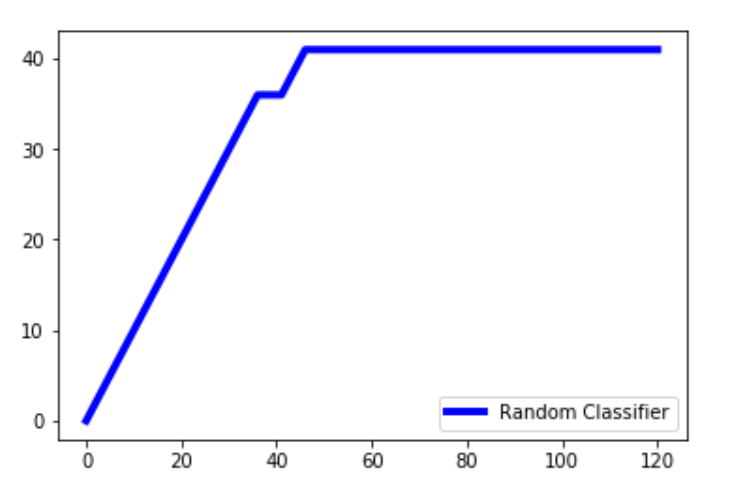
说明:pred是随机分类器做出的预测。我们压缩预测值和测试值,并以相反的顺序对其进行排序,以便先出现较高的值,然后是较低值。我们只提取数组中的y_test值并将其存储在lm中。np.cumsum()创建一个值数组,同时将数组中以前的所有值累积添加到当前值。x值的范围将从0到总和+1。我们在总数上加1,因为arange()不包含数组中的1,我们希望x轴的范围从0到总数。
完美模型
然后我们绘制完美的图(或理想的曲线)。一个完美的预测准确地确定了哪些组成员将购买产品,这样,最大数量的产品销售将达到最低数量的呼叫。这会在CAP曲线上产生一条陡峭的线,一旦达到最大值(联系所有其他组成员不会导致更多产品销售),这就是“完美”CAP。
plt.plot([0, one_count, total], [0, one_count, one_count],c = 'grey', linewidth = 2, label = 'Perfect Model')
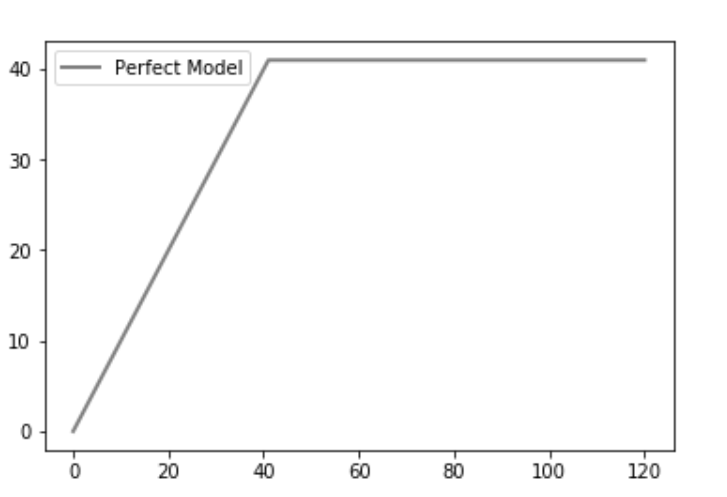
说明:一个完美的模型会在相同的尝试次数中找到积极的结果。在我们的数据集中,我们总共有41个积极的结果,所以在41个时,达到了最大值。
最终分析
在任何情况下,我们的分类器算法都不应该产生一条位于随机线下面的线。在这种情况下,它被认为是一个非常糟糕的模型。由于绘制的分类器线接近理想线,我们可以说我们的模型非常适合。取完美图下的面积,称之为aP。取预测模型下的面积,称之为aR。然后将比率取为aR/aP。这个比率称为准确率。值越接近1,模型越好。这是一种分析方法。
另一种分析方法是从预测模型上的轴的大约50%投影一条线,并将其投影到y轴上。假设我们得到的投影值为X%。
-> 60% :这是一个非常糟糕的模型
-> 60%<X<70%:这仍然是一个糟糕的模型,但明显优于第一种情况
-> 70%<X<80%:这是一个很好的模型
-> 80%<X<90%:这是一个非常好的模型
-> 90%<X<100%:非常好,可能是过拟合的情况之一。
因此,根据这个分析,我们可以确定我们的模型有多准确。
相关文章:
Python | CAP - 累积精度曲线分析案例
CAP通常被称为“累积精度曲线”,用于分类模型的性能评估。它有助于我们理解和总结分类模型的鲁棒性。为了直观地显示这一点,我们在图中绘制了三条不同的曲线: 一个随机的曲线(random)通过使用随机森林分类器获得的曲线…...

ubuntu22.04安装swagboot遇到的问题
一、基本情况 系统:u 22.04 python: 3.10 二、问题描述 swagboot官方提供的安装路径言简意赅:python3 -m pip install --user snagboot 当然安装python3和pip是基本常识,这里就不再赘述。 可是在安装的时候出现如下提示说 Failed buildin…...

python每日一题——8无重复字符的最长子串
题目 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1: 输入: s “abcabcbb” 输出: 3 解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。 示例 2: 输入: s “bbbbb” 输出: 1 解释: 因为无重复字符的最长子串…...
【数据中台】开源项目(2)-Dbus数据总线
1 背景 企业中大量业务数据保存在各个业务系统数据库中,过去通常的同步数据的方法有很多种,比如: 各个数据使用方在业务低峰期各种抽取所需数据(缺点是存在重复抽取而且数据不一致) 由统一的数仓平台通过sqoop到各个…...

职场快速赢得信任
俗话说的好,有人的地方就有江湖。 国内不管是外企、私企、国企,职场环境都是变换莫测。 这里主要分享下怎么在职场中快速赢取信任。 1、找到让自己全面发展的方法 要知道,职场中话题是与他人交流的纽带,为了找到共同的话题&am…...

【SpringBoot3+Vue3】五【完】【实战篇】-前端(配合后端)
目录 一、环境准备 1、创建Vue工程 2、安装依赖 2.1 安装项目所需要的vue依赖 2.2 安装element-plus依赖 2.2.1 安装 2.2.2 项目导入element-plus 2.3 安装axios依赖 2.4 安装sass依赖 3、目录调整 3.1 删除部分默认目录下文件 3.1.1 src/components下自动生成的…...
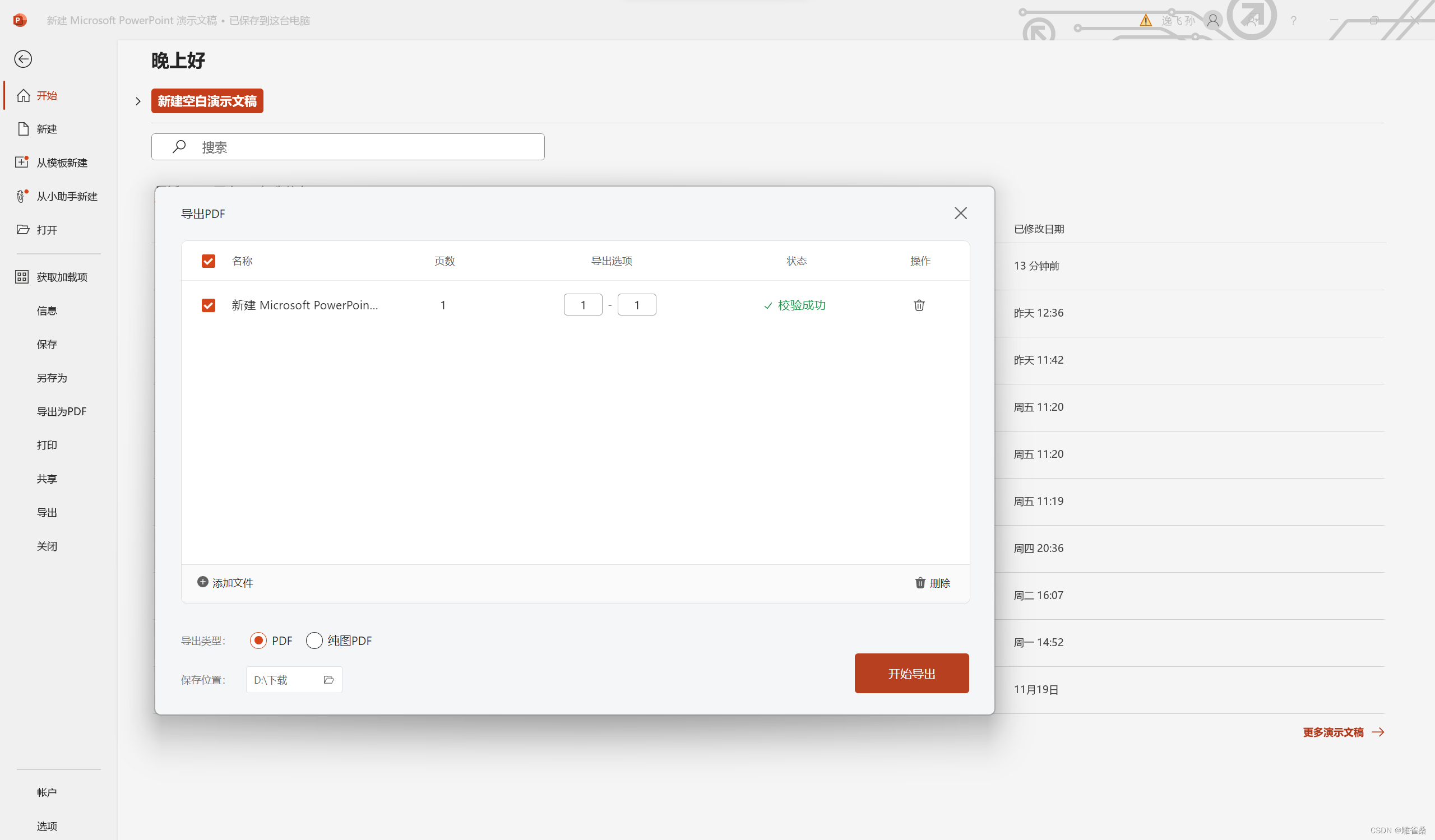
[LaTex]arXiv投稿攻略——jpg/png转pdf
一、将图片复制进ppt,右键单击图片选择设置图片格式,获取图片高度和宽度 二、选择“设计-幻灯片大小-自定义幻灯片大小” 三、设置幻灯片大小为图片大小 四、 选择“最大化” 五、 检查幻灯片大小是否与图像大小一致 六、导出为PDF...

使用Pytorch从零开始构建GRU
门控循环单元 (GRU) 是 LSTM 的更新版本。让我们揭开这个网络的面纱并探索这两个兄弟姐妹之间的差异。 您听说过 GRU 吗?门控循环单元(GRU)是更流行的长短期记忆(LSTM)网络的弟弟,也是循环神经网络&#x…...

【尚跑】2023宝鸡马拉松安全完赛,顺利PB达成
1、赛事背景 千年宝地,一马当先!10月15日7时30分,吉利银河2023宝鸡马拉松在宝鸡市行政中心广场鸣枪开跑。 不可忽视的是,这次赛事的卓越之处不仅在于规模和参与人数,还在于其精心的策划和细致入微的组织。为了确保每位…...

Mac nginx安装,通过源码安装教程
第一部分 安装参考网址: https://blog.csdn.net/a1004084857/article/details/128512612; 以上步骤执行完,进入找到sbin目录,查看下面是不是有nginx可执行文件,如果有在当前sbin下执行./nginx,就会发现NGINX已启动 第…...

TypeScript中的枚举是什么?
在TypeScript中,枚举(Enum)是一种用于定义一组有命名的常量值的数据类型。它们可以提供更具可读性和可维护性的代码。 枚举的作用是为一组相关的值提供一个易于理解和使用的命名空间。它们可以用于代表一系列可能的选项、状态或标志…...

进程并发-信号量经典例题-面包师问题
1 题目描述 面包师有很多面包和蛋糕,由N个销售人员销售。每个顾客进店后先取一个号,并且等着叫号。当一个销售人员空闲下来,就叫下一个号。试用信号量的P、V操作设计该问题的同步算法,给出所用共享变量(如果需要&…...
)
c语言练习12周(11~15)
编写double fun(int a[],int n)函数,计算返回评分数组a中,n个评委打分,去掉一个最高分去掉一个最低分之后的平均分 题干编写double fun(int a[],int n)函数,计算返回评分数组a中,n个评委打分,去掉一…...

Java 实现视频转音频功能
在实际开发中,我们经常需要处理各种多媒体文件。本文将介绍如何使用 Java 语言实现将视频文件转换为音频文件的功能。我们将使用 FFmpeg 工具来进行视频转换操作,并通过 Java 的 ProcessBuilder 实现调用系统命令执行 FFmpeg 的功能。 准备工作 首先,我们需要确保系统中已安…...
可以在Playgrounds或Xcode Command Line Tool开始学习Swift
一、用Playgrounds 1. App Store搜索并安装Swift Playgrounds 2. 打开Playgrounds,点击 文件-新建图书。然后就可以编程了,如下: 二、用Xcode 1. 安装Xcode 2. 打开Xcode,选择Creat New Project 3. 选择macOS 4. 选择Comman…...

IDC最新报告,增速减缓+AI增势,阿里云视频云中国市场第一
国际权威数据公司IDC发布 《中国视频云市场跟踪(2023 H1)》报告 自2018年至今,阿里云持续保持 中国视频云整体市场第一 整体市场占比达24.4% 01 第一之外,低谷之上 近期,国际权威数据公司IDC最新发布了《中国视频…...

常见状态码
欢迎大家到我的博客浏览。常见状态码 | YinKais Blog 常见状态码<!--more--> 1、200 200:服务器已经接收了请求,但处理还没有完成。 204:服务器已经成功处理了请求,但相应中没有任何返回内容。比如 DELETE 请求。 206&…...

Spring原理——基于xml配置文件创建IOC容器的过程
Spring框架的核心之一是IOC,那么我们是怎么创建出来的Bean呢? 作者进行了简单的总结,希望能对你有所帮助。 IOC的创建并不是通过new而是利用了java的反射机制,利用了newInstance方法进行的创建对象。 首先,我们先定义…...

CUDA initialization failure with error: 999
ubuntu20.04,安装tensorRT, 执行example里面的./sample_char_rnn程序,测试时候报了如标题的一个错误,居然如下两行代码这样解决了,这两行命令好像是重新加载nvidia内核模块,有点玄学: sudo rmmod nvidia_u…...

一些权限方面的思考
一些权限方面的思考 背景说明自定义注解解析自定义注解 背景 鉴权可以通过切面做抽取 说明 都是一些伪代码, 不能直接使用, 提供一种思路. 都是一些伪代码, 不能直接使用, 提供一种思路. 都是一些伪代码, 不能直接使用, 提供一种思路. 自定义注解 自定义注解: Permission …...

保姆级教程:手把手教你编译DataX,让它完美支持MySQL 8.0驱动
从零构建DataX与MySQL 8.0深度适配的完整指南 最近在帮客户做数据迁移时,发现官方DataX对MySQL 8.0的支持存在不少坑点。比如默认的驱动类不兼容、连接参数过时等问题,导致很多开发者不得不降级使用MySQL 5.7。其实通过源码编译的方式,完全可…...

AI时代的算法思维:大经典排序学习媚
引言 在现代软件开发中,性能始终是衡量应用质量的重要指标之一。无论是企业级应用、云服务还是桌面程序,性能优化都能显著提升用户体验、降低基础设施成本并增强系统的可扩展性。对于使用 C# 开发的应用程序而言,性能优化涉及多个层面&#x…...

MySQL语句执行深度剖析:从连接到执行的全过程滞
开发个什么Skill呢? 通过 Skill,我们可以将某些能力进行模块化封装,从而实现特定的工作流编排、专家领域知识沉淀以及各类工具的集成。 这里我打算来一次“套娃式”的实践:创建一个用于自动生成 Skill 的 Skill,一是用…...

Excel VBA宏实战:自定义msgbox弹窗交互设计
1. 为什么需要自定义MsgBox弹窗? 在Excel自动化操作中,默认的MsgBox弹窗往往显得过于简单和呆板。想象一下,当你设计了一个自动化的报表系统,用户点击按钮时突然蹦出一个白底黑字的"操作成功"提示,这种体验就…...

别再踩坑了!SQL Server数据类型那点事儿,看懂这篇少背三个锅没
从0构建WAV文件:读懂计算机文件的本质 虽然接触计算机有一段时间了,但是我的视野一直局限于一个较小的范围之内,往往只能看到于算法竞赛相关的内容,计算机各种文件在我看来十分复杂,认为构建他们并能达到目的是一件困难…...

mbino:Arduino上实现mbed HAL的轻量级嵌入式抽象层
1. 项目概述mbino 是一个面向 Arduino 平台的轻量级嵌入式抽象层移植库,其核心目标是将 mbed OS 2 的标准化硬件抽象 API(Hardware Abstraction Layer, HAL)无缝引入以 AVR 8-bit 微控制器(如 ATmega328P、ATmega2560)…...

Kinetis MCU上的轻量级RGB LED控制库设计
1. 项目概述FSLP_Controls_RGB_LEDs 是一个面向嵌入式微控制器平台的轻量级 RGB LED 控制库,专为 Freescale(现 NXP)Kinetis 系列 MCU 设计,基于 Kinetis SDK v2.x 构建。该库并非通用驱动框架,而是聚焦于硬件抽象层&a…...
✅)
计算机毕业设计:Python城市空气污染智能分析系统 Django框架 可视化 数据分析 Prophet时间序列 大数据 大模型 深度学习(建议收藏)✅
1、项目介绍 技术栈 采用 Python 语言开发,基于 Django 框架搭建后端服务,前端使用 Echarts 实现数据可视化,结合 HTML 构建页面结构,运用 Prophet 时间序列算法模型进行空气质量预测。 功能模块系统主页综合评估分析分布与…...

ESP-Bootstrap:面向ESP32/ESP8266的嵌入式Web固件基础架构
1. 项目概述ESP-Bootstrap 是一个面向 ESP8266 和 ESP32 平台的嵌入式 Web 应用快速启动框架,其核心定位并非通用 HTTP 库,而是为资源受限的 Wi-Fi MCU 提供可裁剪、可复用、生产就绪的固件基础架构。它不替代 ESP-IDF 或 Arduino-ESP32 的底层网络栈&am…...
)
告别调参焦虑:用Halcon MLP OCR快速构建你的专用字符识别库(以工业铭牌为例)
工业级OCR实战:Halcon MLP模型在金属铭牌识别中的高效训练方案 在工业自动化领域,设备铭牌、产品序列号等关键信息的自动识别一直是质量检测和生产追溯的重要环节。不同于通用OCR场景,工业环境中的字符识别面临着金属反光、蚀刻不均匀、喷码残…...