MIT 6.824 -- MapReduce Lab
MIT 6.824 -- MapReduce Lab
- 环境准备
- 实验背景
- 实验要求
- 测试说明
- 流程说明
- 实验实现
- GoLand 配置
- 代码实现
- 对象介绍
- 协调器启动
- 工作线程启动
- Map阶段
- 分配任务
- 执行任务
- Reduce 阶段
- 分配任务
- 执行任务
- 终止阶段
- 崩溃恢复
- 注意事项
- 并发安全
- 文件转换
- golang 知识点
- 测试
环境准备
- 从官方git仓库拉取分支
git clone git://g.csail.mit.edu/6.824-golabs-2020 6.824lab
- 笔者码云仓库
https://gitee.com/DaHuYuXiXi/mit-6.824.git
Golang 环境安装,IDE建议选择GoLand,此过程省略搭建过程。
实验背景
- MapReduce实验文档
- MapReduce论文
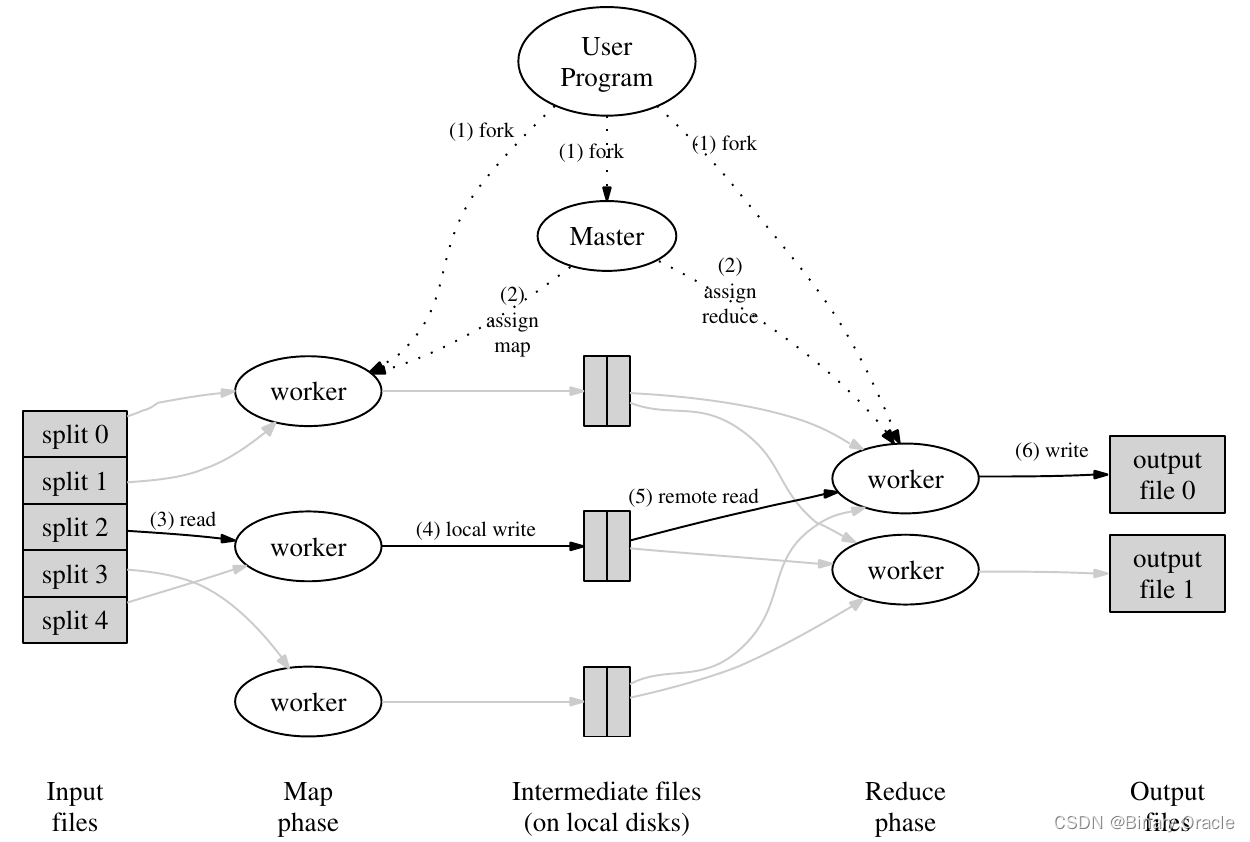
MapReduce 整体流程图如上所示,输入数据以文件形式进入系统,一些进程运行map任务,拆分了原任务,产生了一些中间体,这些中间体可能以键值对的形式存在。一些进程运行reduce任务,利用中间体产生了最终输出,master进程用于分配任务,调整各个worker进程。
输入数据能够产生中间体,这说明原任务是可拆的,也就才有了写成分布式的可能性。若原问题不是可拆的,MapReduce也就无从谈起。
中间体应均匀地分配给各个reduce任务,每个reduce任务整合这些中间体,令中间体个数减少,直至无法再减少,从中整合出最终结果。
输入数据以什么形式进入系统,原任务应如何拆分,中间体如何保存和传输,master和worker之间如何通信和调度,中间体如何转化为最终输出。这些都是设计的考量,没有一定之规。
实验要求
MapReduce Lab 要求我们实现一个和MapReduce论文类似的机制,也就是数单词个数Word Count。在正式开始写分布式代码之前,我们先理解一下任务和已有的代码。
用于测试的文件在src/main目录下,以pg-.txt形式命名。每个pg-.txt文件都是一本电子书,非常长。我们的任务是统计出所有电子书中出现过的单词,以及它们的出现次数。
这个任务非常简单,官方已经默认给我们提供了一个串行的实现 , 在src/main/mrsequential.go中。
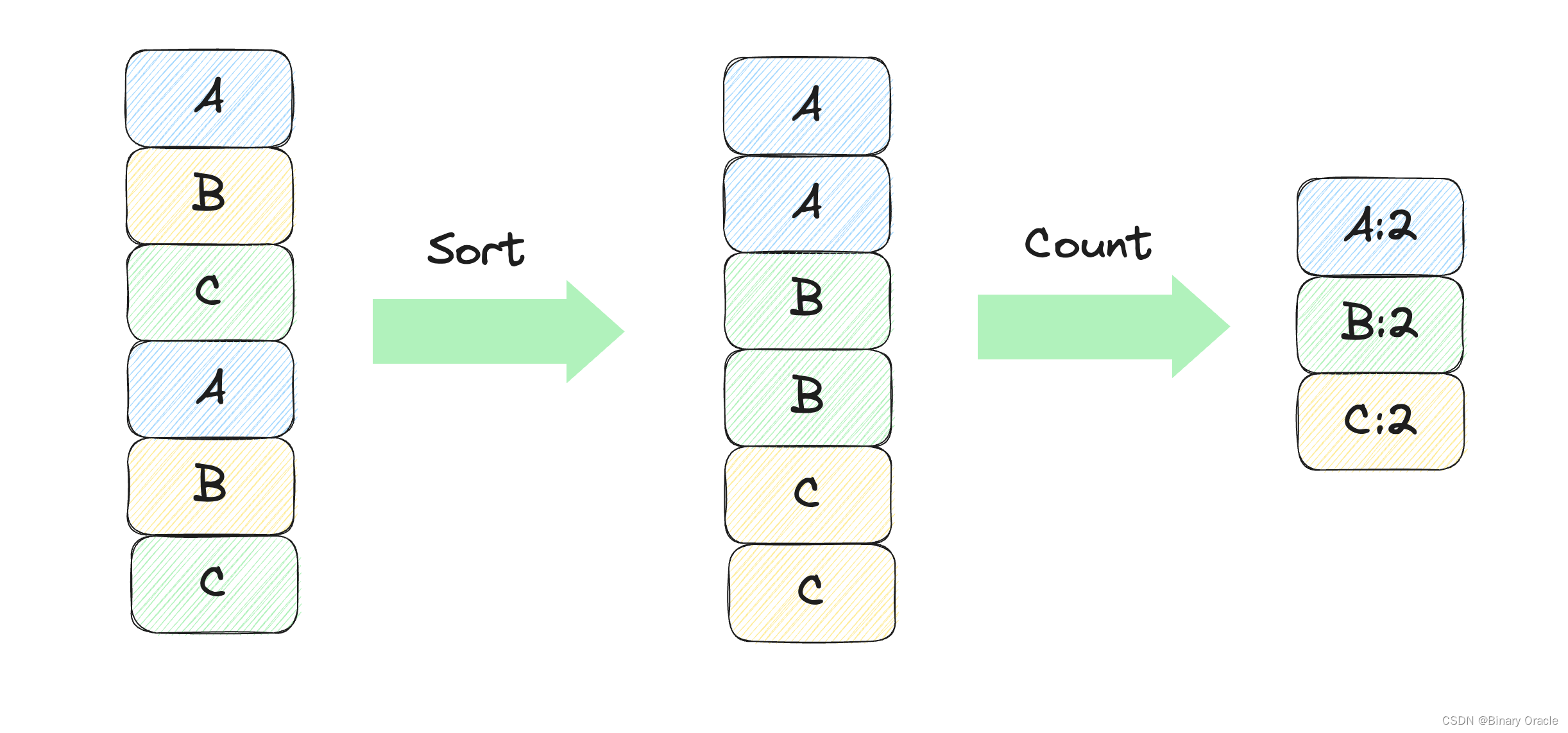
将所有文章中的单词分出,保存到一个类似数组的结构中。将这些单词排序,从而相同单词在数组中连续地出现在一起。排序完成后,遍历这个数组,由于相同的单词相邻地出现,统计单词个数就很简单了。
尝试运行mrsequential.go,看看最终的输出是什么样子的。
cd src/main
go build -buildmode=plugin ../mrapps/wc.go
go run mrsequential.go wc.so pg*.txt
输出文件在src/main/mr-out-0,文件中每一行标明了单词和出现次数。
go run mrsequential.go之后的两项是传给mrsequential的命令行参数,分别是一个动态库和所有电子书。电子书不需要解释。
在进入Go程序之后,动态库由代码主动加载进来。在src/main目录下命名为mr*.go的几个代码文件中,都有loadPlugin函数。如果你使用Goland作为主要IDE,编辑器会提示重复函数声明。在这里,我们给mrsequential加载的是在src/mrapps目录下的wc.go编译得到的动态库。
文件wc.go以及mrapps目录下的其它几个文件,都定义了名为map, reduce的函数,这两个函数在mrsequential.go中加载并调用。给mrsequential绑定不同的*.so文件,也就会加载不同的map, reduce函数。如此实现某种程度上的动态绑定。
mrsequential实现的是非分布式的Word Count,采用的算法就是上面描述的。这个文件的输出将作为之后测试的标准,分布式版本应给出和这个输出完全相同的输出。
测试说明
我们的代码主要写在src/mr目录下的几个文件,这几个文件由src/main目录下两个文件mrcoordinator.go, mrworker.go调用。这两个文件的作用是启动进程、加载map, reduce动态库,并进入定义在src/mr目录下的主流程。
上面展示了执行mrsequential的办法。要执行我们自己写的代码,需要执行mrcoordinator.go, mrworker.go。其中,要给mrcoordinator.go输入电子书文件列表pg-*.txt,给mrworker.go指定动态库wc.so。由于mrcoordinator不需要动态库,worker不需要电子书文件名,两者接受的命令行参数是不一样的。
go run mrcoordinator.go pg-*.txt
go run mrworker.go wc.so
现在还什么也没写,所以什么也运行不出来。每次这样的运行,都启动了一个新的进程,进程之间不能直接相互访问对方的变量,必须通过一定的进程间通信机制才能实现。我们使用的进程间通信是rpc。
流程说明
测试时,启动一个master和多个worker,也就是运行一次mrcoordinator.go、运行多次mrworker.go。
master进程启动一个rpc服务器,每个worker进程通过rpc机制向Master要任务。任务可能包括map和reduce过程,具体如何给worker分配取决于master。
每个单词和它出现的次数以key-value键值对形式出现。map进程将每个出现的单词机械地分离出来,并给每一次出现标记为1次。很多单词在电子书中重复出现,也就产生了很多相同键值对。还没有对键值对进行合并,故此时产生的键值对的值都是1。此过程在下图中mapper伸出箭头表示。
已经分离出的单词以键值对形式分配给特定reduce进程,reduce进程个数远小于单词个数,每个reduce进程都处理一定量单词。相同的单词应由相同的reduce进程处理。处理的方式和上面描述的算法类似,对单词排序,令单词在数组中处在相邻位置,再统计单词个数。最终,每个reduce进程都有一个输出,合并这些输出,就是Word Count结果。此过程在下图中箭头进入reducer、以及后面的合并表示。
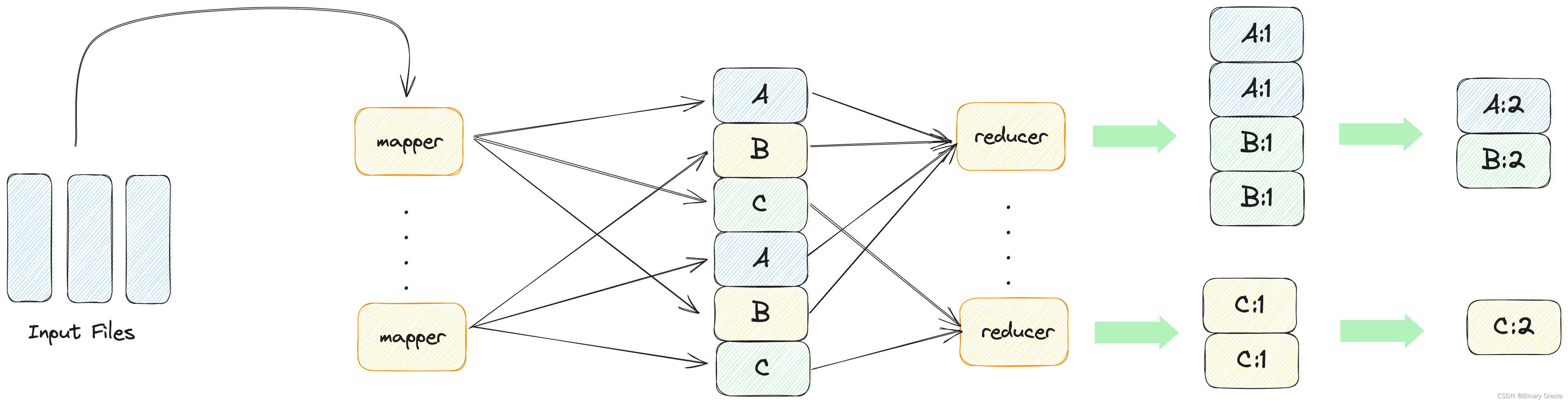
图中,相同的单词由相同reducer处理。如第一个reducer接受单词A, B,最后一个reducer接受单词C。
测试流程要求,输出的文件个数和参数nReduce相同,即每个输出文件对应一个reduce任务,格式和mrsequential的输出格式相同,命名为mr-out*。我们的代码应保留这些文件,不做进一步合并,测试脚本将进行这一合并。合并之后的最终完整输出,必须和mrsequential的输出完全相同。
查看测试脚本test-mr.sh,可以看到合并每个输出mr-out*的指令如下,将每个输出文件的每一行按行首单词排序,输出到最终文件mr-wc-all中。
sort mr-out* | grep . > mr-wc-all
故每个reduce任务不能操作相同的单词,在map流程中分离出的相同单词键值对应由同一个reduce流程处理。
实验实现
GoLand 配置
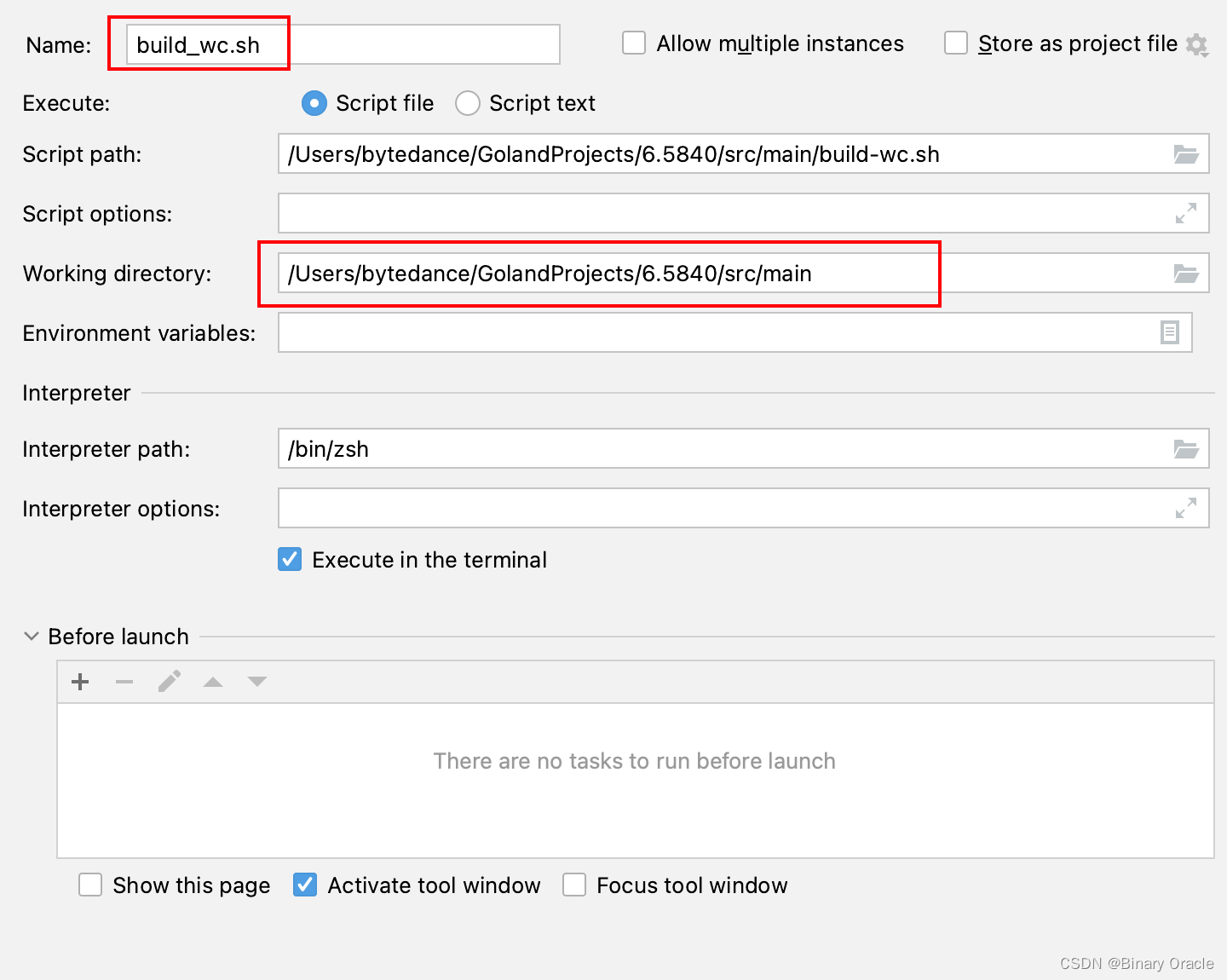
为了避免每次都通过命令行启动,我们可以对GoLand进行一番配置,方便我们利用IDE断点进行调试。
主要是在配置中封装几个go run指令,需要注意一下几点:
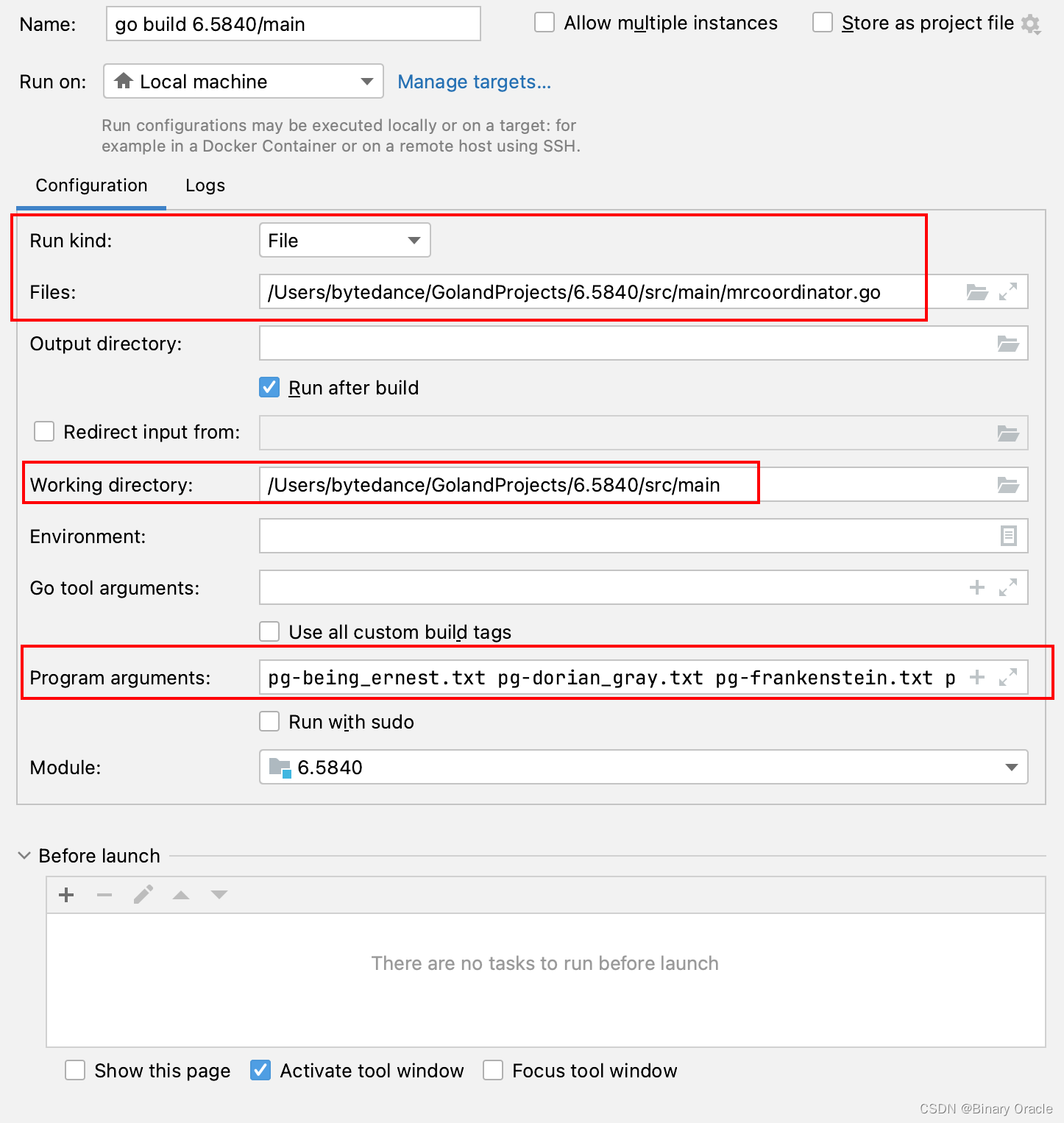
- 工作目录Working Directory要设置成src/main。
- 要给进程传一定命令行参数,如电子书文件名和动态库等。
- Program Arguments中写*星号,不会被当作通配符处理,故需要手动输入所有电子书文件名。
具体配置如下:
- build_wc.sh 配置
# rm -f mr-out*
# mrworker执行前完成wc.so动态库的构建
go build -buildmode=plugin ../mrapps/wc.go
- mrworker.go 启动配置
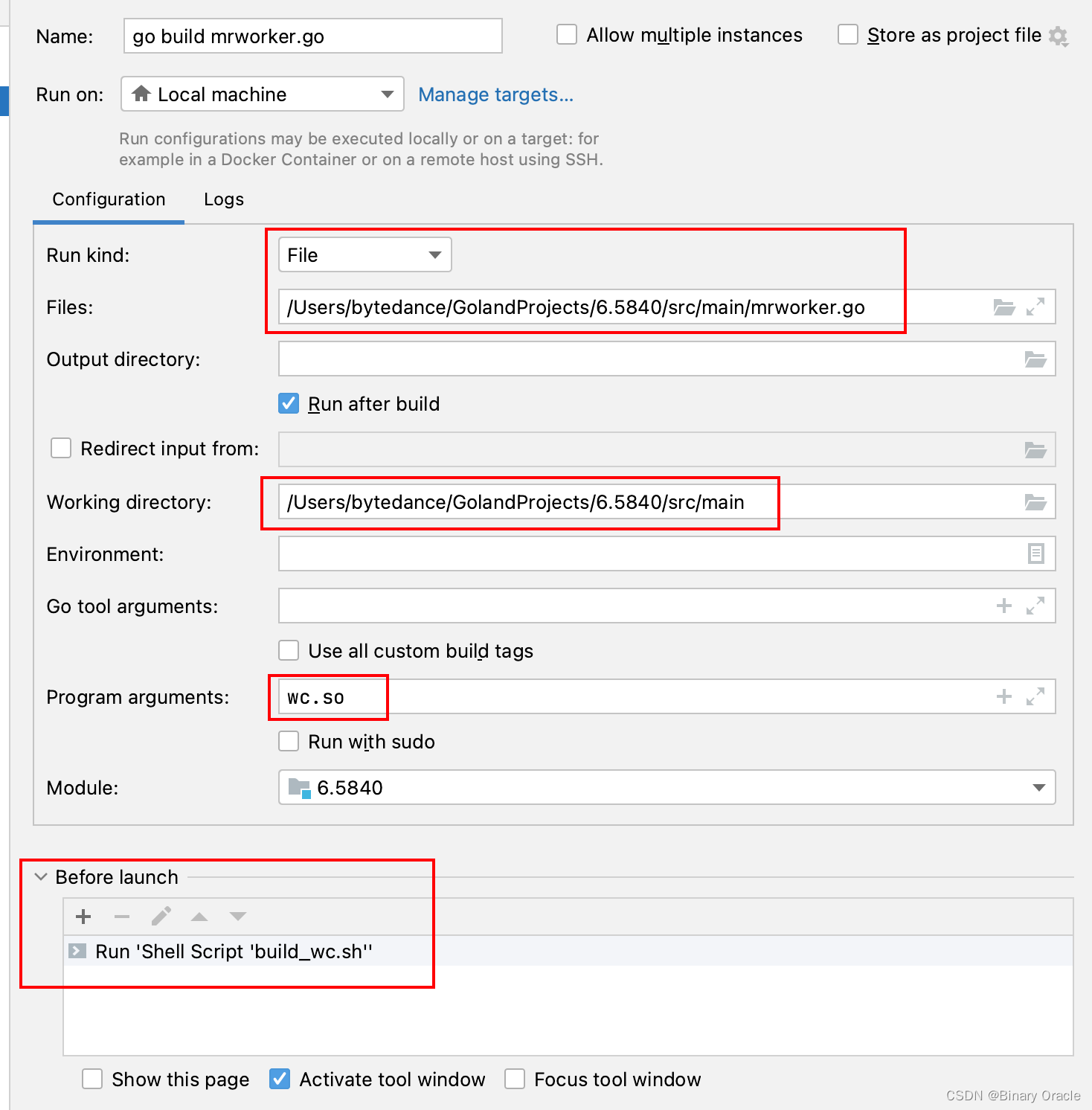
- mrcoordinator.go 启动配置
代码实现
代码实现部分只会介绍核心代码,其余代码大家可拉取笔者仓库,切换到lab1分支自行阅读
对象介绍
我们先来看看协调器中涉及到的相关对象:
- Job : 用于承载任务上下文信息,包括任务需要的数据,任务状态等
// Job 任务对象
type Job struct {JobType JobType // 任务类型: 正在执行map任务,reduce任务,等待被执行或者执行完毕JobStatus JobStatus // 任务执行状态InputFiles []string // 输入文件列表JobId string // 任务idReduceNum int // reduce任务数量StartTime time.Time // 任务开始时间
}
- Job 任务相关的枚举值
type JobType int // 任务类型type JobStatus int // 任务状态// 任务类型
const (MapJob = iotaReduceJobWaitingJobKillJob
)// 任务执行状态
const (JobWorking = iota // 任务执行中JobWaiting // 任务待执行 JobDone // 任务执行完毕
)
- Coordinator : 用于承载协调器上下文数据,包括任务队列,任务集合,协调器状态,任务ID生成器等
// Coordinator 协调器
type Coordinator struct {mu sync.MutexMapJobChannel chan *JobReduceJobChannel chan *JobReduceNum intMapNum intPhase PhaseJobIdGen id.JobIdGeneratorJobHolder map[string]*JobOpts *Options
}
协调器启动
协调器启动时,会读取命令行参数列表传入的map文件列表,然后初始化map任务:
// main 协调器
func main() {// 参数列表是需要处理的文件列表if len(os.Args) < 2 {fmt.Fprintf(os.Stderr, "Usage: mrcoordinator inputfiles...\n")os.Exit(1)}// 实例化协调器,传入文件列表和reduce任务数量m := mr.MakeCoordinator(os.Args[1:], 10)// 停止信号没收到,就一直轮询for m.Done() == false {time.Sleep(time.Second)}custom_log.Info("所有任务都已经结束了...")time.Sleep(time.Second)
}func MakeCoordinator(files []string, nReduce int) *Coordinator {c := Coordinator{MapJobChannel: make(chan *Job, len(files)),ReduceJobChannel: make(chan *Job, nReduce),ReduceNum: nReduce,MapNum: len(files),Phase: MapPhase,JobHolder: make(map[string]*Job),JobIdGen: &id.IncrJobIdGen{},Opts: &Options{Address: "127.0.0.1:" + DefaultPort},}// 初始化map任务列表c.initMapJobs(files)// 启动服务器c.server()// 启动崩溃恢复处理器go c.CrashHandler()return &c
}func (c *Coordinator) initMapJobs(files []string) {jobIdGen := c.JobIdGenfor _, f := range files {job := &Job{JobId: jobIdGen.Generator(),JobType: MapJob,JobStatus: JobWaiting,ReduceNum: c.ReduceNum,InputFiles: []string{f},}c.JobHolder[job.JobId] = job// 将每一个初始化得到的map任务都加入map任务队列中c.MapJobChannel <- jobcustom_log.Info("初始化得到的map任务信息为: %v", *job)}custom_log.Info("map任务集合初始化完毕")
}
初始化完map任务列表后,代码就是启动rpc server了:
func (c *Coordinator) server() {custom_log.Debug("协调器启动")rpc.Register(c)rpc.HandleHTTP()sockName := coordinatorSock()os.Remove(sockName)l, e := net.Listen("unix", sockName)// l, e := net.Listen("tcp", c.Opts.Address)if e != nil {custom_log.Error("listen error: %v", e)return}go http.Serve(l, nil)
}
此时协调器服务就启动成功了,等待接受来自worker的请求,然后给worker派发任务,接收worker完成任务的通知,循环往复,直到所有任务执行完毕。
崩溃恢复处理器后文展开叙述,此处大家可以不必关心。
工作线程启动
工作线程启动后会从命令行参数里面取出动态库地址,然后加载动态库获取map和reduce函数具体的实现 :
func main() {if len(os.Args) != 2 {custom_log.Error("Usage: mrworker xxx.so , 参数列表: %v\n", os.Args)os.Exit(1)}mapf, reducef := LoadPlugin(os.Args[1])mr.Worker(mapf, reducef, "w1")
}
随后工作线程会在一个死循环中不断向协调器索要任务,然后根据任务类型执行任务,直到接收到停止信号后,才会终止自己:
func Worker(mapF func(string, string) []KeyValue, reduceF func(string, []string) string, id string) {workerId := idalive := trueattempt := 0custom_log.Info("当前工作线程开始执行任务: %v", workerId)defer func(now time.Time) {if err := recover(); err != nil {custom_log.Error("发生error: %v", err)} else {custom_log.Info("当前工作线程【 %s 】做完了所有任务,耗时: %v", workerId, time.Now().Sub(now))}}(time.Now())for alive {attempt++custom_log.Info("%s -> worker ask %d", workerId, attempt)// 获取到分配的任务job := RequireTask(workerId)custom_log.Info("worker get job = %v", job)switch job.JobType {// 执行map任务case MapJob:DoMap(mapF, job)custom_log.Info("do map %s", job.JobId)JobIsDone(workerId, job)// 执行reduce任务case ReduceJob:if job.JobId != "" {DoReduce(reduceF, job)custom_log.Info("do reduce %s", job.JobId)// 告诉协调器自己的任务完成了JobIsDone(workerId, job)}// 等待获取任务case WaitingJob:custom_log.Info("get waiting ....")time.Sleep(time.Second)// 结束当前工作线程case KillJob:time.Sleep(time.Second)alive = falsecustom_log.Info("[Status] : %s , terminated......", workerId)}time.Sleep(time.Second)}
}
Map阶段
分配任务
协调器初始启动后,会进入map阶段,该阶段派发给worker线程的任务都是map任务,命令行中传入的每一个input file对应一个map任务 ,整体流程如下图所示:

首先是工作线程向协调器索要任务,此处会调用协调器的DistributeJob方法实现:
func RequireTask(workerId string) *Job {args := RpcRequest{}reply := Job{}// 要求获取一个任务if res := call("Coordinator.DistributeJob", &args, &reply); res == DailError {// 服务器已下线,所有任务执行结束reply.JobType = KillJob} else {custom_log.Info("RequireTask 得到的响应结果为: %v", reply)}return &reply
}
协调器处理工作线程索要任务请求,首先判断当前所处阶段,发现是Map阶段后,会从Map任务队列中获取一个任务返回 , 同时检查判断该任务的状态是否为待执行:
// DistributeJob 下发任务
func (c *Coordinator) DistributeJob(args *RpcRequest, reply *Job) error {c.mu.Lock()defer c.mu.Unlock()custom_log.Info("协调器从工作线程处获取了一个请求")custom_log.Info("当前协调器剩余map任务个数为: %d , 剩余reduce任务个数为: %d", len(c.MapJobChannel), len(c.ReduceJobChannel))if c.Phase == MapPhase {if len(c.MapJobChannel) > 0 {*reply = *<-c.MapJobChannelcustom_log.Info("派发给worker的map job任务为: %v", *reply)if !c.fireTheJob(reply.JobId) {custom_log.Info("job %d is running\n", reply.JobId)}} else {reply.JobType = WaitingJobif c.checkJobDone() {c.nextPhase()}return nil}} else if c.Phase == ReducePhase {if len(c.ReduceJobChannel) > 0 {*reply = *<-c.ReduceJobChannelcustom_log.Info("派发给worker的reduce job任务为: %v", *reply)if !c.fireTheJob(reply.JobId) {custom_log.Info("job %d is running\n", reply.JobId)}} else {reply.JobType = WaitingJobif c.checkJobDone() {c.nextPhase()}return nil}} else if c.Phase == AllDone {// 协调器进入任务终止阶段reply.JobType = KillJob}return nil
}
检查任务状态是否为待执行,如果是则更改为执行中:
func (c *Coordinator) fireTheJob(jobId string) bool {jobInfo, ok := c.JobHolder[jobId]if !ok || jobInfo.JobStatus != JobWaiting {return false}jobInfo.JobStatus = JobWorkingjobInfo.StartTime = time.Now()return true
}
当Map任务队列为空时,协调器会转变为下一个状态,即reduce状态:
// 确保当前所有map或者reduce任务都已完成
func (c *Coordinator) checkJobDone() bool {reduceDoneNum := 0mapDoneNum := 0reduceUndoneNum := 0mapUndoneNum := 0for _, v := range c.JobHolder {if v.JobType == MapJob {if v.JobStatus == JobDone {mapDoneNum++} else {mapUndoneNum++}} else {if v.JobStatus == JobDone {reduceDoneNum++} else {reduceUndoneNum++}}}custom_log.Info("%d/%d map jobs are done , %d/%d reduce job are done\n",mapDoneNum, mapDoneNum+mapUndoneNum, reduceDoneNum, reduceDoneNum+reduceUndoneNum)if (c.Phase == ReducePhase && reduceDoneNum > 0 && reduceUndoneNum == 0) || (c.Phase == MapPhase && mapDoneNum > 0 && mapUndoneNum == 0) {return true}return false
}
协调器转换为reduce状态同时,还会初始化reduce任务列表:
func (c *Coordinator) nextPhase() {if c.Phase == MapPhase {c.initReduceJobs()c.Phase = ReducePhasecustom_log.Info("从map阶段转换为reduce阶段")} else if c.Phase == ReducePhase {c.Phase = AllDonecustom_log.Info("从reduce阶段转换为all done阶段")}
}func (c *Coordinator) initReduceJobs() {jobIdGen := c.JobIdGenfor i := 0; i < c.ReduceNum; i++ {job := &Job{JobId: jobIdGen.Generator(),JobType: ReduceJob,JobStatus: JobWaiting,ReduceNum: c.ReduceNum,// 读取当前工作目录下,符合mr-tmp-*-i的文件名InputFiles: TmpFilesAssignHelper(i, "mr-tmp"),}c.JobHolder[job.JobId] = job// 将每一个初始化得到的reduce任务都加入reduce任务队列中去c.ReduceJobChannel <- jobcustom_log.Info("初始化得到的reduce任务信息为: %v", *job)}custom_log.Info("reduce任务集合初始化完毕")
}
执行任务
工作线程拿到协调器分配的map任务后,便会去执行该map任务:
// mapF 是从动态库加载得到的 , job 是协调器返回的
func DoMap(mapF func(string, string) []KeyValue, job *Job) {var intermediate []KeyValue// 拿到map文件filename := job.InputFiles[0]// 打开文件file, err := os.Open(filename)if err != nil {log.Fatalf("cannot open %v", filename)}// 从文件读取出全部内容content, err := io.ReadAll(file)if err != nil {log.Fatalf("cannot read %v", filename)}file.Close()// 调用动态库的mapF函数处理文本内容 -- 得到key-val对intermediate = mapF(filename, string(content))// 将键值对分散存储到rn个hash中rn := job.ReduceNumHashedKV := make([][]KeyValue, rn)for _, kv := range intermediate {HashedKV[ihash(kv.Key)%rn] = append(HashedKV[ihash(kv.Key)%rn], kv)}// 每个哈希内容写入一个文件中for i := 0; i < rn; i++ {oname := "mr-tmp-" + job.JobId + "-" + strconv.Itoa(i)ofile, _ := os.Create(oname)enc := json.NewEncoder(ofile)for _, kv := range HashedKV[i] {enc.Encode(kv)}ofile.Close()}
}
工作线程执行完任务后,会将执行结果告知协调器:
func JobIsDone(workerId string, job *Job) {call("Coordinator.JobIsDone", &job, &RpcResponse{})
}
协调器拿到任务执行结果后,会变更任务集合中对应任务的状态:
// JobIsDone 告知协调器任务做完
func (c *Coordinator) JobIsDone(arg *Job, reply *RpcResponse) error {c.mu.Lock()defer c.mu.Unlock()job, ok := c.JobHolder[arg.JobId]switch arg.JobType {case MapJob:if !ok {custom_log.Info("map任务不存在,接收到的map task id=%s", arg.JobId)return fmt.Errorf("map任务不存在,接收到的map task id=%s", arg.JobId)}if job.JobStatus == JobWorking {job.JobStatus = JobDonecustom_log.Info("map task id = %s completed", job.JobId)} else {custom_log.Info("重复的map任务已经完成,map task id = %s", arg.JobId)}case ReduceJob:if !ok {custom_log.Info("reduce任务不存在,接收到的reduce task id=%s", arg.JobId)return fmt.Errorf("reduce任务不存在,接收到的reduce task id=%s", arg.JobId)}if job.JobStatus == JobWorking {job.JobStatus = JobDonecustom_log.Info("reduce task id = %s completed", job.JobId)} else {custom_log.Info("重复的reduce任务已经完成,reduce task id = %s", arg.JobId)}default:return fmt.Errorf("捕获到不存在的任务ID = %s", job.JobId)}return nil
}
Reduce 阶段
分配任务
当协调器从map阶段转换为reduce阶段后,后续工作线程再索要任务时,分配给工作线程的任务就是reduce任务了:
// DistributeJob 下发任务
func (c *Coordinator) DistributeJob(args *RpcRequest, reply *Job) error {c.mu.Lock()defer c.mu.Unlock()custom_log.Info("协调器从工作线程处获取了一个请求")custom_log.Info("当前协调器剩余map任务个数为: %d , 剩余reduce任务个数为: %d", len(c.MapJobChannel), len(c.ReduceJobChannel))...if c.Phase == ReducePhase {if len(c.ReduceJobChannel) > 0 {*reply = *<-c.ReduceJobChannelcustom_log.Info("派发给worker的reduce job任务为: %v", *reply)if !c.fireTheJob(reply.JobId) {custom_log.Info("job %d is running\n", reply.JobId)}} else {reply.JobType = WaitingJobif c.checkJobDone() {c.nextPhase()}return nil}} else if c.Phase == AllDone {// 协调器进入任务终止阶段reply.JobType = KillJob}return nil
}
执行任务
工作线程拿到reduce任务后,便会调用doReduce方法处理该任务:
func DoReduce(reduceF func(string, []string) string, job *Job) {// reduce 任务的序号作为最终输出的reduce结果文件的编号reduceFileNum := job.JobId// 从传入的map文件列表中读取出所有的keyVal对intermediate := readFromLocalFile(job.InputFiles)sort.Sort(ByKey(intermediate))dir, _ := os.Getwd()// 先创建临时文件// tempFile api 的用法: https://www.twle.cn/t/383tempFile, err := ioutil.TempFile(dir, "mr-tmp-*")if err != nil {log.Fatal("Failed to create temp file", err)}i := 0// 遍历键值对for i < len(intermediate) {j := i + 1// 记录1出现的下标范围0~5for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {j++}values := []string{}// 记录a出现了 [1,1,1,1,1]for k := i; k < j; k++ {values = append(values, intermediate[k].Value)}// 每个key出现了一次: a = 5output := reduceF(intermediate[i].Key, values)// 将每个key出现次数记录到临时文件中 --> < a , 5 >fmt.Fprintf(tempFile, "%v %v\n", intermediate[i].Key, output)i = j}tempFile.Close()// 临时文件重命名oname := fmt.Sprintf("mr-out-%v", reduceFileNum)os.Rename(tempFile.Name(), oname)
}
执行完reduce任务后,会调用JobIsDone方法告知协调器任务完成,随即再由协调器将任务状态由执行中转换为执行完毕。
终止阶段
当map和reduce任务都处理完毕后,当工作线程再次索要任务时,协调器的状态会由Reduce转变为AllDone:
func (c *Coordinator) nextPhase() {if c.Phase == MapPhase {c.initReduceJobs()c.Phase = ReducePhasecustom_log.Info("从map阶段转换为reduce阶段")} else if c.Phase == ReducePhase {c.Phase = AllDonecustom_log.Info("从reduce阶段转换为all done阶段")}
}
此时,协调器会返回给工作线程终止信号:
// DistributeJob 下发任务
func (c *Coordinator) DistributeJob(args *RpcRequest, reply *Job) error {...if c.Phase == AllDone {// 协调器进入任务终止阶段reply.JobType = KillJob}return nil
}
工作线程接收到终止信号后,便会终止自己:
func Worker(mapF func(string, string) []KeyValue, reduceF func(string, []string) string, id string) {... for alive {attempt++custom_log.Info("%s -> worker ask %d", workerId, attempt)// 获取到分配的任务job := RequireTask(workerId)custom_log.Info("worker get job = %v", job)switch job.JobType {...case KillJob:time.Sleep(time.Second)alive = falsecustom_log.Info("[Status] : %s , terminated......", workerId)}time.Sleep(time.Second)}
}
协调器线程检测到状态更改为AllDone后,便会将自己也进行终止:
// main 协调器
func main() {// 参数列表是需要处理的文件列表if len(os.Args) < 2 {fmt.Fprintf(os.Stderr, "Usage: mrcoordinator inputfiles...\n")os.Exit(1)}// 实例化协调器,传入文件列表和reduce任务数量m := mr.MakeCoordinator(os.Args[1:], 10)// 停止信号没收到,就一直轮询for m.Done() == false {time.Sleep(time.Second)}custom_log.Info("所有任务都已经结束了...")time.Sleep(time.Second)
}func (c *Coordinator) Done() bool {c.mu.Lock()defer c.mu.Unlock()return c.Phase == AllDone
}
崩溃恢复
如果某个工作线程拿到任务后,执行了很长时间依然没有给协调器反馈,那么我们便认为该工作线程节点崩溃了,需要将其执行的任务进行重放:
// CrashHandler 崩溃恢复处理器
func (c *Coordinator) CrashHandler() {for {time.Sleep(time.Second * 2)c.mu.Lock()if c.Phase == AllDone {c.mu.Unlock()continue}timenow := time.Now()for _, job := range c.JobHolder {if job.JobStatus == JobWorking {custom_log.Info("job id = %s working for %v", job.JobId, timenow.Sub(job.StartTime))}// 任务超过5秒没完成就任务其出现了问题,需要重放if job.JobStatus == JobWorking && time.Now().Sub(job.StartTime) > 5*time.Second {custom_log.Info("detect a crash on job %s", job.JobId)switch job.JobType {case MapJob:c.MapJobChannel <- jobjob.JobStatus = JobWaitingcase ReduceJob:c.ReduceJobChannel <- jobjob.JobStatus = JobWaiting}}}c.mu.Unlock()}
}
这里的实现比较简单,就是单独开了一个协程定时轮询所有任务,将执行时间超过5秒到任务重新放入对应的任务队列中去,从而交付给其他工作线程重新执行。
注意事项
并发安全
此处的临界区主要集中在协调器对象中的任务集合和协调器本身的Phase状态变更上,因此针对这两个属性进行操作时,需要加锁,防止并发安全问题发生。
文件转换
我们将所有待处理文件通过命令行参数的形式传递给了协调器,协调器为每个文件生成一个map任务 ;
工作线程接收到一个map任务后,会读取出map文件中所有单词,简单的将每个单词出现次数记录为1,得到一个keyVal集合;
然后工作线程会遍历该集合,为每个keyVal对进行取模运算,计算其应该存放在哪个reduce文件中,然后将其写入对应的reduce文件,reduce文件名为: mr-tmp-map任务编号-reduce任务编号。
reduce文件数量等于协调器对象中ReduceNum的值,该值是固定的,每个工作线程都会将一个map文件经过处理后,拆分为ReduceNum个reduce文件。
当进入reduce阶段后,协调器会初始化reduce任务列表,每一个reduce任务初始化时都会读取当前工作目录下所有文件,获取所有文件命名符合mr-tmp-*-当前reduce任务编号的文件的名字,作为inputFiles属性的值。
当工作线程接收到一个reduce任务后,会取出inputFiles列表中所有map文件,依次处理每个map文件,读取出文件中所有KeyVal键值对,统计每个key出现次数,然后写入名为mr-out-reduce任务编号的文件中。
golang 知识点
本实验中涉及到的golang知识点主要是net/rpc库的使用 , socket 套接字文件的用法 , 临时文件创建API用法:
- go rpc 库用法
- 临时文件API
测试
写好代码之后,运行测试脚本test-mr.sh,应通过所有测试。
测试脚本可能输出过多,不便阅读,可以将输出重定向到一个文件。
./test-mr.sh > test-mr.out
如果正确理解了任务,采用了正确的设计,应该能通过第一个测试wc test。如果你使用了上面介绍过的临时文件机制,应该能通过第三个测试crash test。如果你适当给一些数据结构加锁,应该能通过第二个测试parallelism test。
通过全部测试用例的截图如下:

相关文章:
MIT 6.824 -- MapReduce Lab
MIT 6.824 -- MapReduce Lab 环境准备实验背景实验要求测试说明流程说明 实验实现GoLand 配置代码实现对象介绍协调器启动工作线程启动Map阶段分配任务执行任务 Reduce 阶段分配任务执行任务 终止阶段 崩溃恢复 注意事项并发安全文件转换golang 知识点 测试 环境准备 从官方gi…...

创新研报|顺应全球数字化,能源企业以“双碳”为目标的转型迫在眉睫
能源行业现状及痛点分析 挑战一:数字感知能力较弱 挑战二:与业务的融合度低 挑战三:决策响应速度滞后 挑战四:价值创造有待提升 挑战五:安全风险如影随形 能源数字化转型定义及架构 能源行业数字化转型体系大体…...
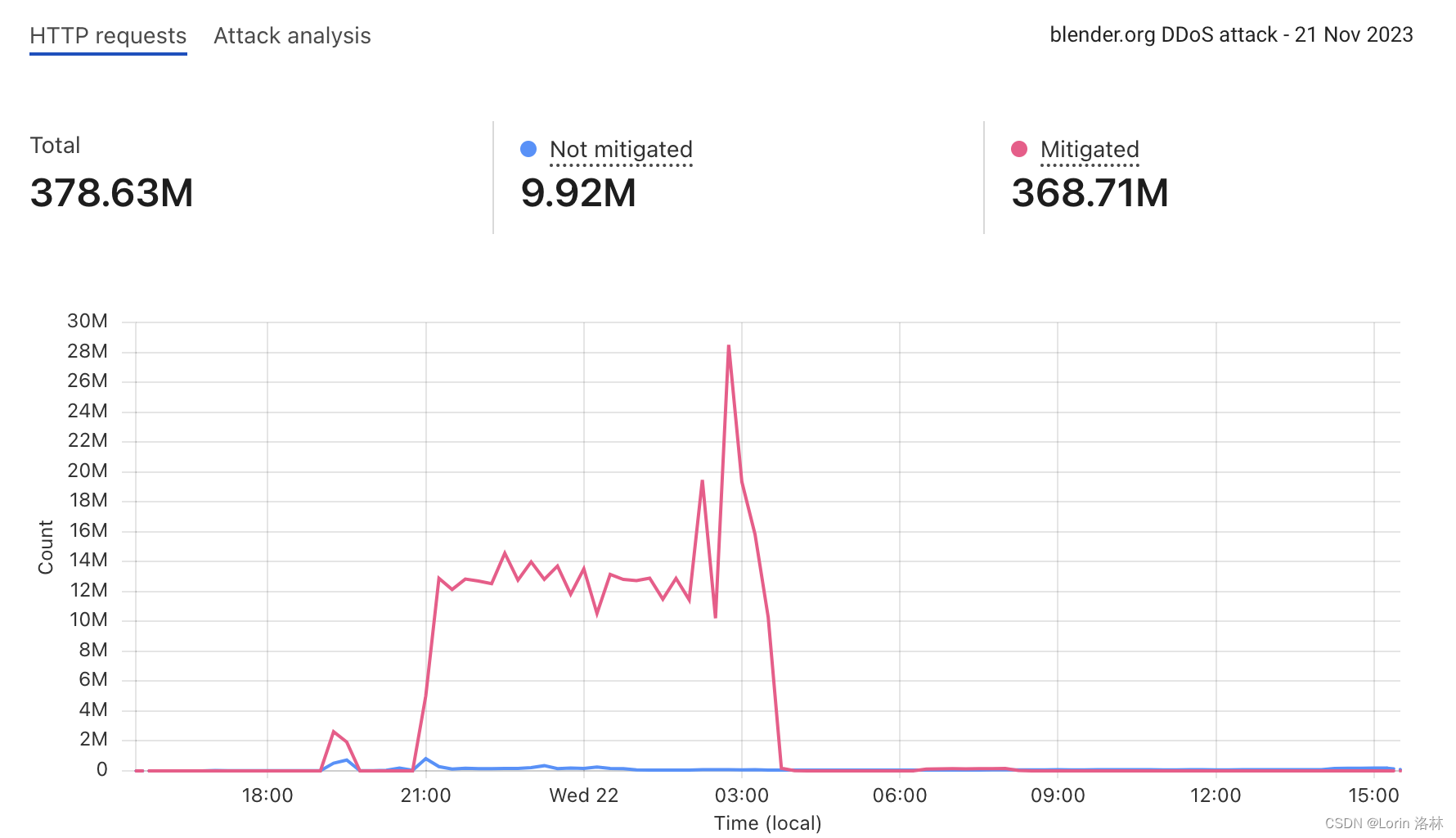
Blender 连续 5 天遭受大规模 DDoS 攻击
Blender 发布公告指出,在2023年11月18日至23日期间,blender.org 网站遭受了持续的分布式拒绝服务(DDoS)攻击,攻击者通过不断发送请求导致服务器超载,使网站运营严重中断。此次攻击涉及数百个 IP 地址的僵尸…...

Python 获取本地和广域网 IP
Python 获取本地IP ,使用第三方库,比如 netifaces import netifaces as nidef get_ip_address():try:# 获取默认网络接口(通常是 eth0 或 en0)default_interface ni.gateways()[default][ni.AF_INET][1]# 获取指定网络接口的IP地…...
静态路由配置过程
静态路由 静态路由简介 路由器在转发数据时,要先在路由表(Routing Table)中在找相应的路由,才能知道数据包应该从哪个端口转发出去。路由器建立路由表基本上有以下三种途径。 (1)直连路由:路由…...
基于OGG实现MySQL实时同步
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

【计算机网络笔记】多路访问控制(MAC)协议——轮转访问MAC协议
系列文章目录 什么是计算机网络? 什么是网络协议? 计算机网络的结构 数据交换之电路交换 数据交换之报文交换和分组交换 分组交换 vs 电路交换 计算机网络性能(1)——速率、带宽、延迟 计算机网络性能(2)…...

什么是好的FPGA编码风格?(3)--尽量不要使用锁存器Latch
前言 在FPGA设计中,几乎没人会主动使用锁存器Latch,但有时候不知不觉中你的设计莫名其妙地就生成了一堆Latch,而这些Latch可能会给你带来巨大的麻烦。 什么是锁存器Latch? Latch,锁存器,一种可以存储电路…...

从0开始学习JavaScript--构建强大的JavaScript图片库
在现代Web开发中,图像是不可或缺的一部分,而构建一个强大的JavaScript图片库能够有效地管理、展示和操作图像,为用户提供更丰富的视觉体验。本文将深入探讨构建JavaScript图片库的实用技巧,并通过丰富的示例代码演示如何实现各种功…...

linux复习笔记05(小滴课堂)
hell脚本与crontab定时器的运用 查看状态: 关闭服务: 开启服务: 重启服务: crontab定时器的使用: 我们可以看到没有任何任务。 编辑: 我们可以看到这个任务了。 删除所有任务: 这代表着每分钟…...
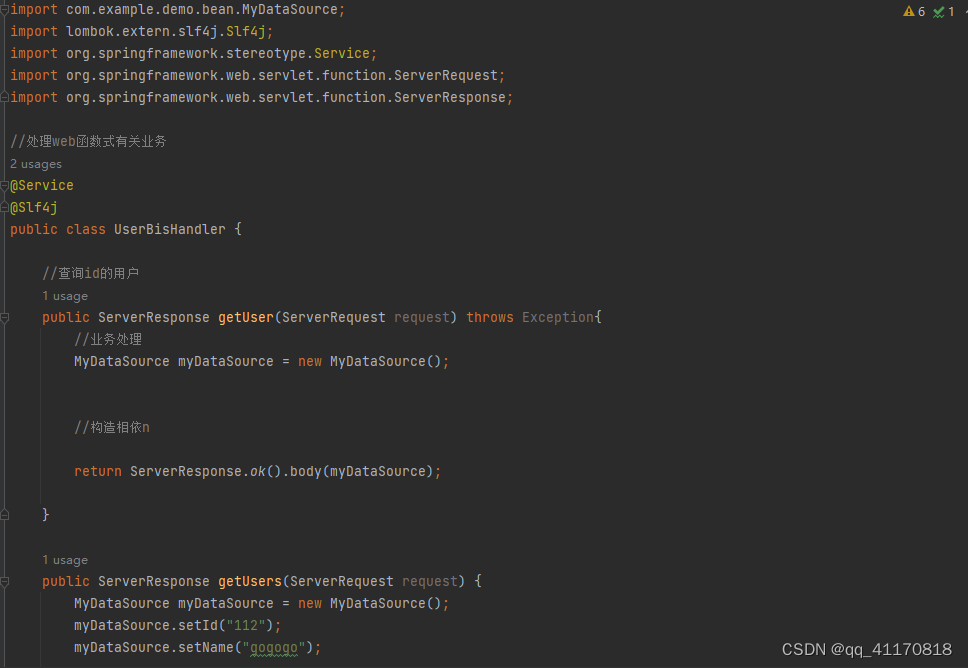
springboot函数式web
1.通常是路由(请求路径)业务 2.函数式web:路由和业务分离 一个configure类 配置bean 路由等 实现业务逻辑 这样实现了业务和路由的分离...
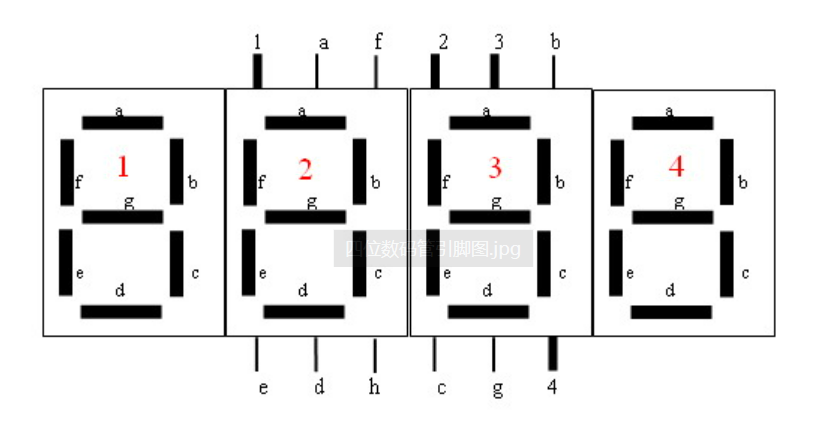
常见的1/2/3位数码管接线详解
今天玩数码管的时候接触到了数码管的接线,分享一下供刚开始接触的童鞋参考 首先了解什么是数码管 数码管是一种可以显示数字和其他信息的电子设备,是显示屏其中一类, 通过对其不同的管脚输入相对的电流,会使其发亮,从而…...

C++模板介绍
定义 C模板是一种编程技术,它允许程序员在编译时生成具有特定类型的函数或类,而无需在运行时进行类型检查。模板是一种泛型编程的方式,它使得程序员可以编写可适用于多种数据类型的代码,提高了代码的重用性和灵活性。 C模板可以…...

kafka kraft 集群搭建保姆级教学 包含几个踩坑点
一.为啥弃用zookeeper kafka 弃用 ZooKeeper 而采用 KRaft 的主要原因是为了改进 Kafka 集群的可靠性和可管理性。 在传统的 Kafka 架构中,ZooKeeper 用于存储和管理集群的元数据、配置信息和状态。然而,使用 ZooKeeper 作为协调服务存在一些限制和挑战…...

html实现360度产品预览(附源码)
文章目录 1.设计来源1.1 拖动汽车产品旋转1.2 汽车产品自动控制 2.效果和源码2.1 动态效果2.2 源代码 源码下载 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/134613931 html实现360度产品预览(附源码&…...

11-23 SSM4
Ajax 同步请求 :全局刷新的方式 -> synchronous请求 客户端发一个请求,服务器响应之后你客户端才能继续后续操作,请求二响应完之后才能发送后续的请求,依次类推 有点:服务器负载较小,但是由于服务器相应…...
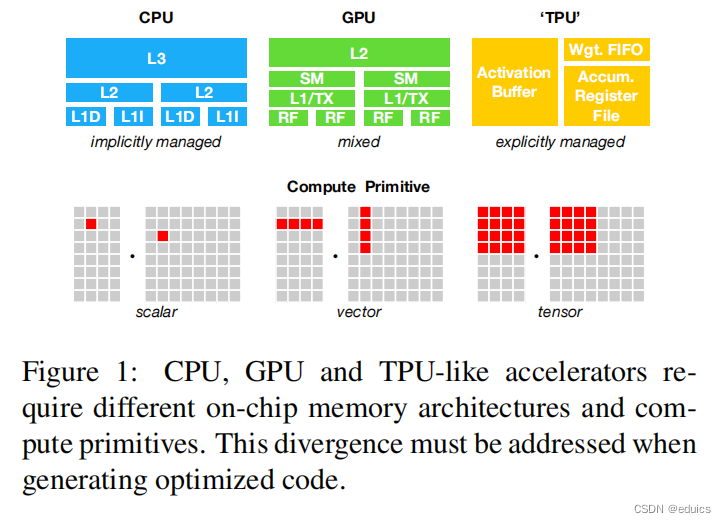
CPU、GPU、TPU内存子系统架构
文章目录 CPU、GPU、TPU内存子系统架构概要CPUGPUTPU共同点和差异: CPU、GPU、TPU内存子系统架构 概要 Memory Subsystem Architecture,图源自TVM CPU CPU(中央处理器)的内存子系统:隐式管理 主内存(…...

R数据分析:集成学习方法之随机生存森林的原理和做法,实例解析
很久很久以前给大家写过决策树,非常简单明了的算法。今天给大家写随机(生存)森林,随机森林是集成了很多个决策数的集成模型。像随机森林这样将很多个基本学习器集合起来形成一个更加强大的学习器的这么一种集成思想还是非常好的。…...

transformers pipeline出现ConnectionResetError的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

代码随想录-刷题第九天
28. 找出字符串中第一个匹配项的下标 题目链接:28. 找出字符串中第一个匹配项的下标 思路1:先来写一下暴力解法。 时间复杂度O(n*m) class Solution {public int strStr(String haystack, String needle) {// 暴力解法先来一遍for (int i 0; i <…...

现在好用的 AI 大模型,到底有哪些?怎么收费?一文整理清楚
这两年,大模型最大的变化,不是“谁最强”。 而是:已经没有一个模型,能把所有事都做成第一。 你写代码,可能会先想到 Claude。你做日常办公和综合问答,很多人会选 ChatGPT。你要多模态、生态和搜索联动&…...

VMware虚拟机安装教程:Qwen3-TTS开发环境配置
VMware虚拟机安装教程:Qwen3-TTS开发环境配置 1. 环境准备与系统要求 在开始配置Qwen3-TTS开发环境之前,我们需要先确保硬件和软件环境满足基本要求。这个环节很重要,好的开始是成功的一半。 首先来看看硬件要求。建议使用至少8GB内存的电…...

51单片机 proteus仿真 直流电机
电路仿真代码#include <reg51.h>#define uchar unsigned char #define uint unsigned int #define LCD_Data P0 sbit IN1 P3^0; sbit IN2 P3^1; sbit ENA P3^2;sbit back P2^0; sbit forword P2^1; sbit up P2^2; sbit down P2^3; sbit stop P2^4; sbit LCD_RS…...
)
告别代码复制:用GD32F3x0固件库V2.2.0优雅配置PWM互补输出(Keil MDK环境)
告别代码复制:用GD32F3x0固件库V2.2.0优雅配置PWM互补输出(Keil MDK环境) 在嵌入式开发中,PWM(脉冲宽度调制)技术广泛应用于电机控制、电源管理等领域。对于GD32F3x0系列微控制器,官方提供的固件…...

4步快速上手:用APK-Installer在Windows上轻松安装安卓应用,告别模拟器烦恼
4步快速上手:用APK-Installer在Windows上轻松安装安卓应用,告别模拟器烦恼 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑…...

Switch第三方控制器终极解决方案:sys-con完全指南
Switch第三方控制器终极解决方案:sys-con完全指南 【免费下载链接】sys-con Nintendo Switch sysmodule that allows support for third-party controllers 项目地址: https://gitcode.com/gh_mirrors/sy/sys-con 想让您的Xbox和PlayStation手柄在Switch上畅…...

如何用Bitfocus Companion将普通硬件打造成专业控制中心:开源解决方案的三大突破
如何用Bitfocus Companion将普通硬件打造成专业控制中心:开源解决方案的三大突破 【免费下载链接】companion Bitfocus Companion enables the Elgato Stream Deck and other controllers to be a professional shotbox surface for an increasing amount of differ…...

告别复杂配置!ERNIE-4.5-0.3B-PT模型vLLM部署与Chainlit调用详解
告别复杂配置!ERNIE-4.5-0.3B-PT模型vLLM部署与Chainlit调用详解 1. 快速部署ERNIE-4.5-0.3B-PT模型 ERNIE-4.5-0.3B-PT是百度推出的轻量级文本生成模型,基于专家混合(MoE)架构设计,具有300亿参数但仅激活0.3亿参数。使用vLLM部署可以大幅提…...

Llama-3.2V-11B-cot部署案例:Docker镜像免配置运行图文推理API服务
Llama-3.2V-11B-cot部署案例:Docker镜像免配置运行图文推理API服务 想体验一个能看懂图片、还能像人一样一步步思考的AI吗?今天要介绍的 Llama-3.2V-11B-cot 就是这样一个模型。它不仅能识别图片里的内容,还能把思考过程一步步拆解给你看&am…...

ContentProvider call方法:简化跨进程通信的优雅实践
1. ContentProvider call方法:跨进程通信的隐藏利器 第一次接触ContentProvider的call方法时,我正被一个跨进程通信的需求折磨得焦头烂额。当时需要在两个独立应用间频繁传递数据,传统的AIDL方案让我写了大量模板代码,而广播方式又…...