R数据分析:集成学习方法之随机生存森林的原理和做法,实例解析
很久很久以前给大家写过决策树,非常简单明了的算法。今天给大家写随机(生存)森林,随机森林是集成了很多个决策数的集成模型。像随机森林这样将很多个基本学习器集合起来形成一个更加强大的学习器的这么一种集成思想还是非常好的。所以今天来写写这类算法。

集成学习方法
Ensemble learning methods are made up of a set of classifiers—e.g. decision trees—and their predictions are aggregated to identify the most popular result.
所谓的集成学习方法,就是把很多的比较简单的学习算法统起来用,比如光看一个决策树,好像效果比较单调,还比较容易过拟合,我就训练好多树,把这些树的结果综合一下,结果应该会好很多,用这么样思路形成的算法就是集成学习算法Ensemble methods,就是利用很多个基础学习器形成一个综合学习器。
Basically, a forest is an example of an ensemble, which is a special type of machine learning method that averages simple functions called base learners.The resulting averaged learner is called the ensemble
集成学习方法最有名的就是bagging 和boosting 方法:
The most well-known ensemble methods are bagging, also known as bootstrap aggregation, and boosting
BAGGing
BAGGing, or Bootstrap AGGregating这个方法把自助抽样和结果合并整合在一起,包括两个步骤,一个就是自助抽样,抽很多个数据集出来,每个数据集来训练一个模型,这样就可以有很多个模型了;第二步就是将这么多模型的结果合并出来最终结果,这个最终结果相对于单个模型结果就会更加稳健。
In the bagging algorithm, the first step involves creating multiple models. These models are generated using the same algorithm with random sub-samples of the dataset which are drawn from the original dataset randomly with bootstrap sampling method
The second step in bagging is aggregating the generated models.
随机森林就可以看作是遵循了bagging方法的一个思路,只不过在每一个抽样样本中的树(模型)是不一样的:

Boosting:
Boosting为强化学习,最大的特点是可以将原来的弱模型变强,逻辑在于算法会先后训练很多模型,后面训练模型的时候会不断地给原来模型表现不好的样本增大权重,使得后面的模型越来越将学习重点放在之前模型表现差的样本上,这么一来,整体模型越来越强。就像人会从之前的错误中反省经验一个意思了。

这么一描述大家就知道,boosting方法的模型训练是有先后顺序的,并行算法就用不了了
Boosting incrementally builds an ensemble by training each model with the same dataset but where the weights of instances are adjusted according to the error of the last prediction.
Boosting方法本身也有很多,常见的如AdaBoost,Gradient Boosting(XGBoost and LightGBM),下图感兴趣的同学可以看看:

上面的算法之后再给大家写,接下来的实操部分还是以随机森林为例子给大家具体介绍:
随机森林
随机森林模型的拟合过程大概可以分为三步:
1.通过有放回的自助抽样形成ntree个抽样样本集(Bootstrap)
2.对每个抽样样本集形成一个决策树,这个树是基于mtry个预测因子的
3.将最终的模型结果就是ntree个抽样样本集得出的结果的最大票数或者均值(AGGregating)
随机森林的整个的流程就如下图:

为了方便理解“最终的模型结果就是ntree个抽样样本集得出的结果的最大票数或者均值”我们用例子做个解释,先看下图:

我们有一个水果集,然后我训练一个3棵树组成的随机森林来判断每一个水果到底是何种类,有两棵树都告诉我是某一个水果是苹果,一棵树告诉我是香蕉,那么最后我们随机森林就会输出该水果是香蕉的结论。
上面的过程有几个超参需要确定
- mtry: Number of variables randomly sampled as candidates at each split.
- ntree: Number of trees to grow.
mtry一般需要调参,ntree都是越大越好自己设定就行。在上面的过程中我们每棵树的节点都是不同的,叫做特征随机化,通过特征随机化我们保证了森林中树的多样性,随机森林模型也更加稳健。
Feature randomness, also known as feature bagging or “the random subspace method”, generates a random subset of features, which ensures low correlation among decision trees
随机森林实操
比如我现在有一个数据集,结局变量是class为二分类,我要适用随机森林算法就可以写出如下代码:
rf_default <- train(Class~., data=dataset, method='rf', tuneLength = 15, trControl=control)
print(rf_default)输出的结果中有随机调参的过程,共15次,最终发现超参mtry=3的时候模型最优,具体如下:

以上的随机森林模型的简单展示,接着我们再看随机生存森林。
随机生存森林
和随机森林一样,随机生存森林也是一个集成学习方法,区别在于其结局为生存资料。
示例文章
依然我们来看一篇发表在Cancer Med.上的文章,名字如下:
Prognostic risk factor of major salivary gland carcinomas and survival prediction model based on random survival forests
作者用cox进行了变量筛选,使用随机生存森林进行了预测模型构建,并得到了相应的风险分,明确了风险分的最佳截断值(“maxstat” R package),对于模型的表现作者使用了c指数和time-dependent ROC来评估,文章中主要的结果报告如下,包括:
树的数量和模型误差情况,以及变量重要性的结果:

time-dependent ROC曲线结果展示和相应的AUC值:

风险分界址点确定:

高低风险组的组间生存曲线比较:

也是一篇预测模型类文章的常规套路了。挑一个算法,拟合模型后评估,做个风险分,应用风险分划分病人证明模型可用性。我们以这篇文章为例子看随机生存森林预测模型的实操。
随机生存森林实例操作
我现在的数据中ttodead,died两个变量分别是时间和生存状态,此时我想做一个随机生存森林模型就可以写出如下代码:
RF_obj <- rfsrc(Surv(ttodead,died)~., dataSet, ntree = 1000, membership = TRUE, importance=TRUE)对代码运行后生成的对象RF_obj进行plot即可出图如下,就得到了原文中的figure2:

然后我们可以画出模型的不同时间点的timeRoc曲线(下面代码中的risk_score为随机生存森林对象的预测值),就得到了原文中的figure3,figure4:
ROC_rsf<-timeROC(T=finaldata.Test$Surv_day,delta=finaldata.Test$status,marker=risk_score,cause=1,times=c(365,365*3,365*5),iid=TRUE)
plot(ROC_lasso,time=365)
plot(ROC_lasso,time=365*3,add = T,col="blue")
plot(ROC_lasso,time=365*5,add = T,col="green")
legend(.8, .3, legend=c("T=1 Year AUC=0.895", "T=3 Year AUC=0.917","T=5 Year AUC=0.926"),col=c("red", "blue","green"), lty=1, cex=0.7,bty = "n")
并且将模型预测值的截断值找出来,验证模型在不同风险组的区分能力。其中找风险分截断值的代码如下:
y.pred <- predict(RF_obj)[["predicted"]]
plot(surv_cutpoint(dataSet, time = "ttodead", event = "died",variables = c("y.pred")), "y.pred", palette = "npg")运行后得到下图(原文中的figure5),就说明我们这个模型的风险分截断值应该为43.21:

然后根据这个风险分我们就可以将原始人群分为高风险组和低风险组,再做出组间km曲线,到这儿相当于Cancer Med的这篇用随机生存森林的文章就完全复现出来了。
以上是给大家介绍的随机生存森林的内容。
相关文章:
R数据分析:集成学习方法之随机生存森林的原理和做法,实例解析
很久很久以前给大家写过决策树,非常简单明了的算法。今天给大家写随机(生存)森林,随机森林是集成了很多个决策数的集成模型。像随机森林这样将很多个基本学习器集合起来形成一个更加强大的学习器的这么一种集成思想还是非常好的。…...

transformers pipeline出现ConnectionResetError的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

代码随想录-刷题第九天
28. 找出字符串中第一个匹配项的下标 题目链接:28. 找出字符串中第一个匹配项的下标 思路1:先来写一下暴力解法。 时间复杂度O(n*m) class Solution {public int strStr(String haystack, String needle) {// 暴力解法先来一遍for (int i 0; i <…...
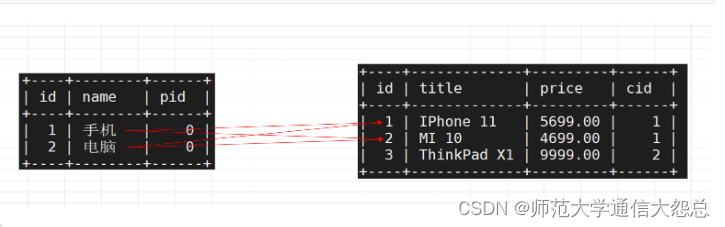
MySQL基本SQL语句(下)
MySQL基本SQL语句(下) 一、扩展常见的数据类型 1、回顾数据表的创建语法 基本语法: mysql> create table 数据表名称(字段名称1 字段类型 字段约束,字段名称2 字段类型 字段约束,...primary key(主键字段 > 不能为空、必须唯一) ) …...

【洛谷算法题】P5715-三位数排序【入门2分支结构】
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【洛谷算法题】 文章目录 【洛谷算法题】P5715-三位数排序【入门2分支结构】🌏题目描述🌏输入格式…...

上海亚商投顾:北证50指数大涨 逾百只北交所个股涨超10%
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指11月24日震荡调整,深成指、创业板指盘中跌超1%。北证50指数大涨超6%,北交所个股持…...

设计模式—依赖倒置原则(DIP)
1.概念 依赖倒置原则(Dependence Inversion Principle)是程序要依赖于抽象接口,不要依赖于具体实现。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。 通俗的讲࿱…...
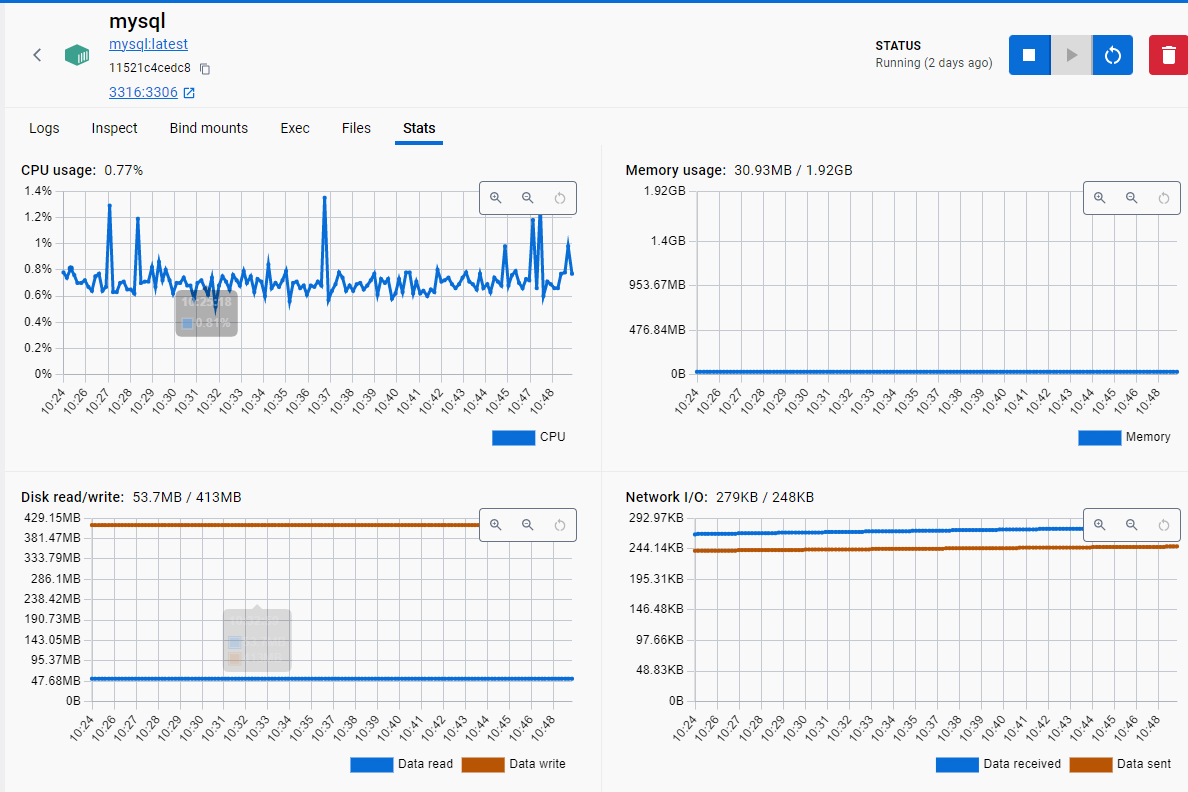
windows下docker环境搭建与运行实战
背景 学习docker使用,需要环境,今天主要的目标是在windows环境下安装docker环境。 为什么要这么搞,主要是企业内部服务器,都是跟公网隔离的,没有访问公网权限,所以镜像什么的,从公网拉取完全没…...

c# EF框架的增删改查操作
查询 /// <summary>/// 查询/// </summary>private void SQLLoad(){//linq查询,方法一//var UserInfoList from u in db.UserInfo//给个变量u,用来接收查询结果对象//select u;//查询结果对象 //db.UserInfo.Find(1);//依据主键查询,方法二…...

Element-UI Upload 手动上传文件的实现与优化
文章目录 引言第一部分:Element-UI Upload 基本用法1.1 安装 Element-UI1.2 使用 <el-upload> 组件 第二部分:手动上传文件2.1 手动触发上传2.2 手动上传时的文件处理 第三部分:性能优化3.1 并发上传3.2 文件上传限制 结语 Ἰ…...
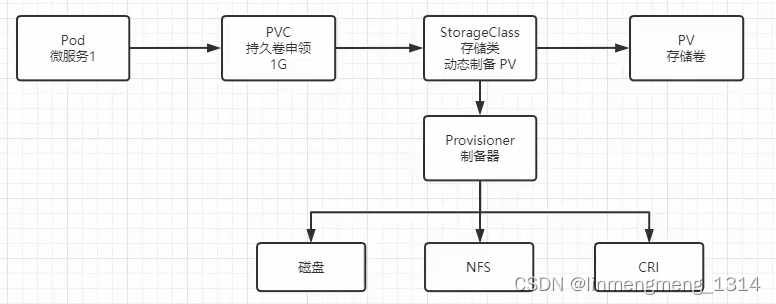
持续集成部署-k8s-配置与存储-存储类:动态创建NFS-PV案例
动态创建NFS-PV案例 1. 前置条件2. StorageClass 存储类的概念和使用3. RBAC 配置4. storageClass 配置5. 创建应用,测试 PVC 的自动配置6. 解决 PVC 为 Pending 状态问题7. 单独测试自动创建 PVC 1. 前置条件 这里使用 NFS 存储的方式,来演示动态创建 …...

jar包不挂断地运行命令
nohup java -jar wpfx.jar com.xiaobai.wpfx.WpfxApplication > ./demo.log 2>&1 &这段命令主要是用来在后台运行一个Java应用程序,并将输出日志写入到demo.log文件中。下面是每个参数的解释: nohup:表示不挂断地运行命令&…...
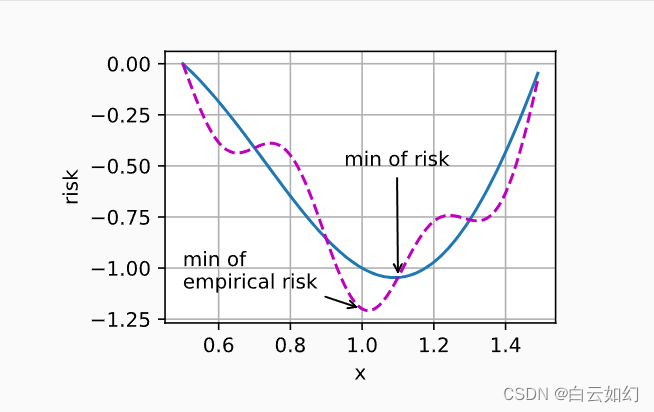
人工智能-优化算法和深度学习
优化和深度学习 对于深度学习问题,我们通常会先定义损失函数。一旦我们有了损失函数,我们就可以使用优化算法来尝试最小化损失。在优化中,损失函数通常被称为优化问题的目标函数。按照传统惯例,大多数优化算法都关注的是最小化。…...

【开源】基于Vue和SpringBoot的食品生产管理系统
项目编号: S 044 ,文末获取源码。 \color{red}{项目编号:S044,文末获取源码。} 项目编号:S044,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 加工厂管理模块2.2 客户管理模块2.3…...
洛谷P1049装箱问题 ————递归+剪枝+回溯
没没没没没没没没没错,又是一道简单的递归,只不过加了剪枝,我已经不想再多说,这道题写了一开始写了普通深搜,然后tle了一个点,后面改成剪枝,就ac了,虽然数据很水,但是不妨…...

C++通讯录管理系统
目录 系统需求 1、 创建项目 2、 菜单功能设计 3、 退出功能设计 4、 添加联系人功能设计 4.1 设计联系人结构体 4.2 设计通讯录结构体 4.3 在main函数中创建通讯录 4.4 封装添加联系人函数 4.5 添加联系人功能测试 5、 显示联系人功能设计 5.1 封装显示…...
Windows安装Python环境(V3.6)
文章目录 一:进入网址:https://www.python.org/downloads/ 二:执行安装包 默认C盘,选择自定义安装目录 记得勾选add python path 下面文件夹最好不要有 . 等特殊符号 可以创建 python36 如果安装失败Option可以选默认的&#x…...

python 如何调用GPT系列的api接口,实现想要的功能
目录 问题描述: 问题解决: 问题描述: 随着各种LLMs (Large Language Models)的出现,如何调用各种LLMs的api成为了经常会遇见的问题。 问题解决: 下面仅以生成给定sentence的复述句为例,说明…...

JS动态参数arguments与剩余参数
arguments是函数内部内置的伪数组变量,它包含了调用函数时传入的所以实参 让我为大家介绍一下arguments吧 平时我们获取实参: function fun(a, b) {console.log(a) //1console.log(b) //2}fun(1, 2)接下来我们来使用一下arguments动态获取实参 function …...

使用ListenableFuture进行异步任务执行并进行线程切换
文章目录 一、前言二、关键代码三、参考链接 一、前言 在程序中会经常需要做一些异步任务,但是由于部分操作其实很简单,仅仅是短暂的进行异步操作,然后在结果成功或失败的时候切换回主线程进行下一步处理,这期间不能阻塞主线程。…...
)
2026奇点大会唯一指定技术白皮书节选:AI-Native Runtime如何重构云原生内核?(含eBPF+MoE调度器实测性能对比)
第一章:2026奇点智能技术大会:AI原生云原生融合 2026奇点智能技术大会(https://ml-summit.org) 本届大会首次提出“AI原生云原生融合”范式,标志着基础设施层与智能层的深度耦合进入工程化落地阶段。传统云原生以容器、微服务、声明式API为…...

用JVS小龙虾审计18个skills,百项检查,10分钟跑完
3 月初,安全圈被一条消息炸了锅:OpenClaw 的插件中心 ClawHub 上被曝出 340 多个恶意 Skill 插件,代号“ClawHavoc”。这些插件伪装成“天气查询”“一键排版”之类的实用工具,实际上内部混淆了键盘记录器、凭据窃取器等恶意代码。…...

UndertaleModTool终极指南:从零开始制作Undertale游戏MOD
UndertaleModTool终极指南:从零开始制作Undertale游戏MOD 【免费下载链接】UndertaleModTool The most complete tool for modding, decompiling and unpacking Undertale (and other GameMaker games!) 项目地址: https://gitcode.com/gh_mirrors/un/UndertaleMo…...

Altium Designer实战:从零开始设计STM32最小系统PCB
1. 准备工作与环境搭建 在开始设计STM32最小系统PCB之前,我们需要做好充分的准备工作。首先确保你的电脑上已经安装了Altium Designer软件,建议使用较新的版本(如AD20或更高),因为新版本在稳定性和功能上都有显著提升…...

ML307R编译环境搭建:从官方文档到实战避坑指南
1. 为什么需要这份实战指南? 第一次接触ML307R开发板时,我按照官方文档搭建编译环境,结果花了整整两天时间才搞定。官方文档虽然简洁,但很多关键细节都没提到,比如Python版本选择、环境变量配置、依赖库安装等。这些问…...
仿真配置全流程)
从软体机器人到鞋垫分析:Abaqus超弹性材料(Ogden模型)仿真配置全流程
从实验数据到高效求解:Abaqus超弹性材料Ogden模型实战指南 在柔性结构设计和生物力学仿真领域,超弹性材料的精确建模一直是工程师面临的挑战。当我们需要模拟橡胶密封件在压缩状态下的应力松弛、运动鞋垫在行走过程中的能量反馈,或是医疗植入…...

10个r.js优化技巧:大幅提升JavaScript应用性能
10个r.js优化技巧:大幅提升JavaScript应用性能 【免费下载链接】r.js Runs RequireJS in Node and Rhino, and used to run the RequireJS optimizer 项目地址: https://gitcode.com/gh_mirrors/rj/r.js 想要大幅提升你的JavaScript应用性能吗?r.…...

13.2软件架构风格
一、软件架构风格 00:10 1. 软件体系结构风格概述 01:101)软件体系结构风格定义 01:16 领域特定模式:描述特定应用领域中系统组织方式的惯用模式,如穿衣风格(日系/韩系/中式)或建…...

GLM-4.1V-9B-Base与Proteus联调:可视化电路仿真结果分析
GLM-4.1V-9B-Base与Proteus联调:可视化电路仿真结果分析 1. 硬件调试的新思路 在电子工程领域,电路调试一直是个耗时费力的过程。工程师们需要盯着示波器上的波形,手动比对预期与实际结果,这个过程不仅容易出错,还特…...
)
行李包安检的设计(论文+CAD图纸+proe三维+SolidWorks三维图+ANSYS源文件+论文答辩PPT)
行李包安检系统是保障公共安全的关键环节,其设计需兼顾检测效率、结构稳定性与操作便捷性。通过系统整合CAD图纸、ProE三维模型、SolidWorks三维图及ANSYS源文件,可实现从二维布局到三维结构再到力学性能的全方位优化。CAD图纸用于精准规划设备整体轮廓与…...