跟着chatgpt一起学|1.spark入门之MLLib
chatgpt在这一章表现的不好,所以我主要用它来帮我翻译文章+提炼信息
1.前言
首先找到spark官网里关于MLLib的链接
spark内一共有2种支持机器学习的包,
一种是spark.ml,基于DataFrame的,也是目前主流的
另一种则是spark.mllib,是基于RDD的,在维护,但不增加新特性了
所以这一节的学习以spark.ml中的pipeline为主。其他的和sklearn里的非常像,大家可以自己去看。
2.Pipeline介绍
基于DataFrame创建pipeline,对数据进行清洗/转换/训练。
2.1 Pipeline的构成
Pipeline主要分为:
1.Transformer,人如其名,就是对数据做转换的
2.Estimators,使用fit函数对数据做拟合,
2.2 Pipeline如何工作
pipeline是由一系列stage构成,而每一个stage则是由一个transformer或者是estimator构成。这些stage按顺序执行,将输入的DataFrame按相应的方式转换:Transformer对应的stage调用transform()函数,而Estimator对应的stage则调用fit函数取创建一个Transformer,(它成为PipelineModel或已拟合的Pipeline的一部分),然后在DataFrame上调用该Transformer的transform()方法。
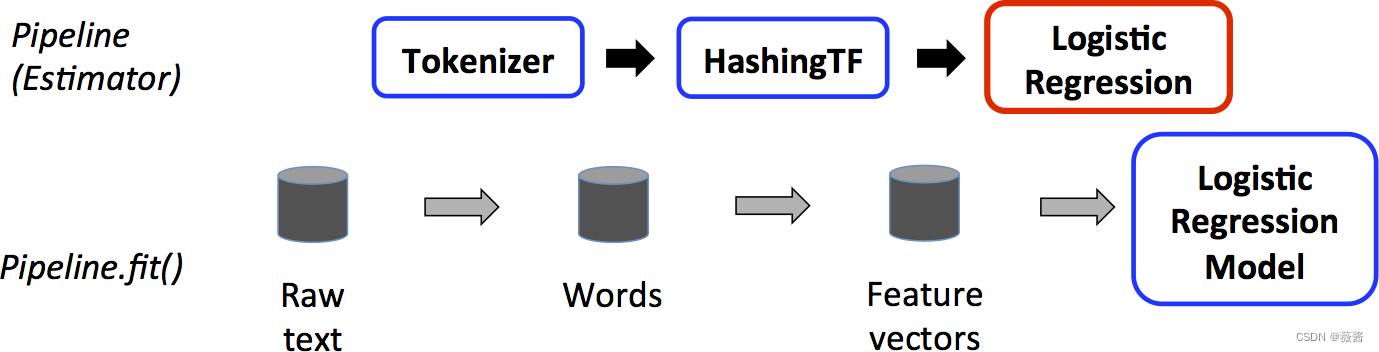
有些绕,可以看看下面这张图:
对训练数据进行pipeline操作,对应的红框表示Estimator,使用训练数据拟合LR
而对测试数据,对应的LR变成了蓝框,此时LR也成为了Transformer,对测试数据进行transform()操作。
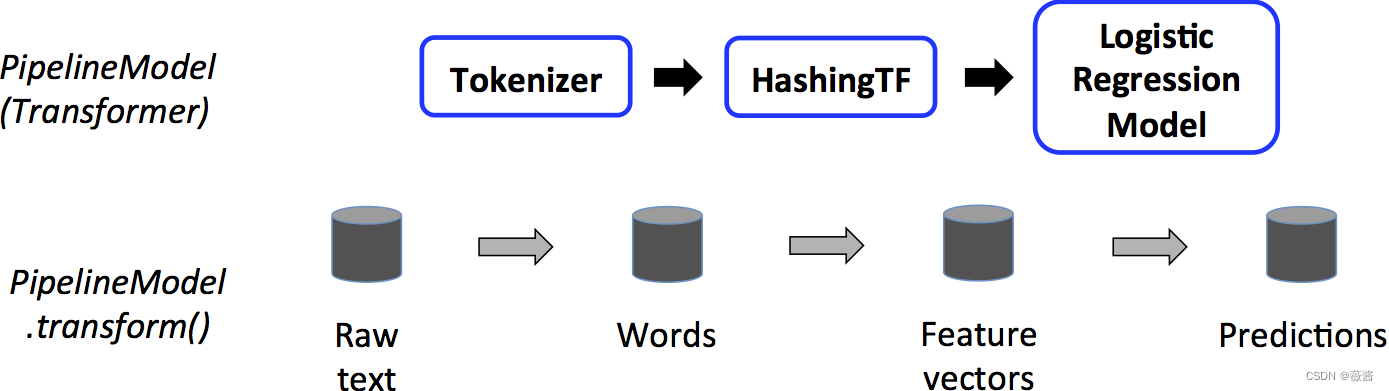
3.注意项
1.执行DAG图
上面展示的顺序执行pipeline的方式,实际上满足无环拓扑图也可以使用pipeline
2.参数
- 可以直接设置
lr.setMaxIter(10) - 在调用transform()或者fit时传入ParamMap
3.兼容性
不同版本的MLlib兼容性其实并不完全能保证的
主要版本:不能保证,但会尽力兼容。
小版本和补丁版本:是的,它们是向后兼容的。
4.代码参考:
4.1 Estimator, Transformer, and Param代码参考
from pyspark.ml.linalg import Vectors
from pyspark.ml.classification import LogisticRegression# Prepare training data from a list of (label, features) tuples.
training = spark.createDataFrame([(1.0, Vectors.dense([0.0, 1.1, 0.1])),(0.0, Vectors.dense([2.0, 1.0, -1.0])),(0.0, Vectors.dense([2.0, 1.3, 1.0])),(1.0, Vectors.dense([0.0, 1.2, -0.5]))], ["label", "features"])# Create a LogisticRegression instance. This instance is an Estimator.
lr = LogisticRegression(maxIter=10, regParam=0.01)
# Print out the parameters, documentation, and any default values.
print("LogisticRegression parameters:\n" + lr.explainParams() + "\n")# Learn a LogisticRegression model. This uses the parameters stored in lr.
model1 = lr.fit(training)# Since model1 is a Model (i.e., a transformer produced by an Estimator),
# we can view the parameters it used during fit().
# This prints the parameter (name: value) pairs, where names are unique IDs for this
# LogisticRegression instance.
print("Model 1 was fit using parameters: ")
print(model1.extractParamMap())# We may alternatively specify parameters using a Python dictionary as a paramMap
paramMap = {lr.maxIter: 20}
paramMap[lr.maxIter] = 30 # Specify 1 Param, overwriting the original maxIter.
# Specify multiple Params.
paramMap.update({lr.regParam: 0.1, lr.threshold: 0.55}) # type: ignore# You can combine paramMaps, which are python dictionaries.
# Change output column name
paramMap2 = {lr.probabilityCol: "myProbability"}
paramMapCombined = paramMap.copy()
paramMapCombined.update(paramMap2) # type: ignore# Now learn a new model using the paramMapCombined parameters.
# paramMapCombined overrides all parameters set earlier via lr.set* methods.
model2 = lr.fit(training, paramMapCombined)
print("Model 2 was fit using parameters: ")
print(model2.extractParamMap())# Prepare test data
test = spark.createDataFrame([(1.0, Vectors.dense([-1.0, 1.5, 1.3])),(0.0, Vectors.dense([3.0, 2.0, -0.1])),(1.0, Vectors.dense([0.0, 2.2, -1.5]))], ["label", "features"])# Make predictions on test data using the Transformer.transform() method.
# LogisticRegression.transform will only use the 'features' column.
# Note that model2.transform() outputs a "myProbability" column instead of the usual
# 'probability' column since we renamed the lr.probabilityCol parameter previously.
prediction = model2.transform(test)
result = prediction.select("features", "label", "myProbability", "prediction") \.collect()for row in result:print("features=%s, label=%s -> prob=%s, prediction=%s"% (row.features, row.label, row.myProbability, row.prediction))4.2 Pipeline 代码参考
from pyspark.ml import Pipeline
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer# Prepare training documents from a list of (id, text, label) tuples.
training = spark.createDataFrame([(0, "a b c d e spark", 1.0),(1, "b d", 0.0),(2, "spark f g h", 1.0),(3, "hadoop mapreduce", 0.0)
], ["id", "text", "label"])# Configure an ML pipeline, which consists of three stages: tokenizer, hashingTF, and lr.
tokenizer = Tokenizer(inputCol="text", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.001)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])# Fit the pipeline to training documents.
model = pipeline.fit(training)# Prepare test documents, which are unlabeled (id, text) tuples.
test = spark.createDataFrame([(4, "spark i j k"),(5, "l m n"),(6, "spark hadoop spark"),(7, "apache hadoop")
], ["id", "text"])# Make predictions on test documents and print columns of interest.
prediction = model.transform(test)
selected = prediction.select("id", "text", "probability", "prediction")
for row in selected.collect():rid, text, prob, prediction = rowprint("(%d, %s) --> prob=%s, prediction=%f" % (rid, text, str(prob), prediction # type: ignore))相关文章:
跟着chatgpt一起学|1.spark入门之MLLib
chatgpt在这一章表现的不好,所以我主要用它来帮我翻译文章提炼信息 1.前言 首先找到spark官网里关于MLLib的链接 spark内一共有2种支持机器学习的包, 一种是spark.ml,基于DataFrame的,也是目前主流的 另一种则是spark.mllib,是基于RDD的…...

JAVA后端开发技术报告
JAVA后端开发技术报告 一、引言 随着互联网技术的不断发展,JAVA作为一门成熟的后端开发语言,应用范围广泛。本报告旨在介绍JAVA后端开发的相关技术,包括JAVA语言基础、Spring框架、数据库技术以及性能优化等方面,帮助开发者更好…...

销售心理学 如何了解客户的购买心理激发客户购买兴趣
销售心理学 如何了解客户的购买心理激发客户购买兴趣 在销售的世界里,掌握客户的购买心理,如同一把神奇的钥匙,能够解锁客户内心的需求和兴趣。如何巧妙地运用销售心理学,激发客户的购买欲望呢?以下是一些建议&#x…...
霍夫丁不等式(Hoeffding‘s inequality)
参考资料:Hoeffdings inequality | encyclopedia article by TheFreeDictionary 霍夫丁不等式(Hoeffdings inequality)描述了随机变量的和、与和的期望之差的上限;或者表述为:随机变量的均值、与均值的期望之差的上限。…...
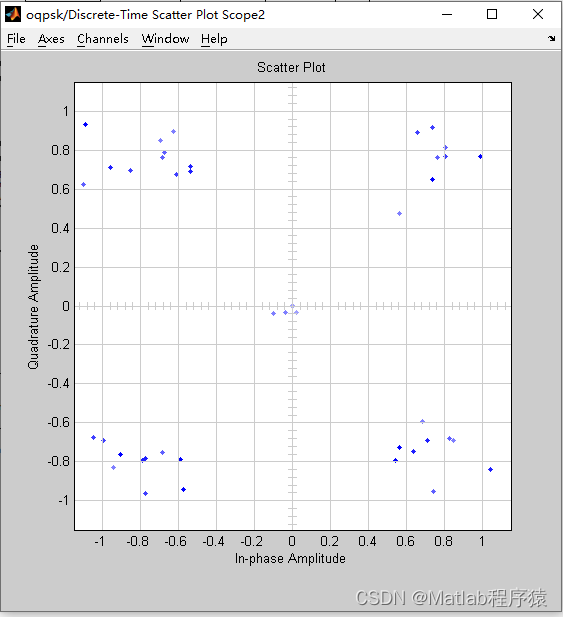
【MATLAB源码-第90期】基于matlab的OQPSKsimulink仿真,对比初始信号和解调信号输出星座图。
操作环境: MATLAB 2022a 1、算法描述 正交偏移二进制相移键控(OQPSK, Orthogonal Quadrature Phase Shift Keying)是一种数字调制技术,主要用于高效无线数据传输。它是传统二进制相移键控(BPSK)的一个变…...

自动驾驶芯片指标AI算力TOPS和CPU算力DMIPS
自动驾驶芯片指标AI算力TOPS和CPU算力DMIPS 文章目录 自动驾驶芯片指标AI算力TOPS和CPU算力DMIPS智能驾驶芯片CPU GPU NPU算力单位TOPS乘积累加运算MACTOPS计算公式GPU算力TFLOPSTFLOPS与TOPS的换算CPU算力DMIPS 智能驾驶芯片 根据地平线数据, L2级自动驾驶的算力…...
海外Leads Generation产业:中国出海群体的行业大机会
Leads Generation(简称LeadsGen)指的是集中精力吸引和开发潜在客户的营销策略。通过引导式的营销策略,企业分发内容吸引潜在客户,引导客户留下电话/邮件/姓名等信息。基于这些信息,企业可建立潜在客户数据库࿰…...
SQL sever2008中的游标
目录 一、游标概述 二、游标的实现 三、优缺点 3.1优点: 3.2缺点: 四、游标类型 4.1静态游标 4.2动态游标 4.3只进游标 4.4键集驱动游标 4.5显示游标: 4.6隐式游标 五、游标基本操作 5.1声明游标 5.1.1.IS0标准语法 5.1.1.1语…...
和解压)
在linux中进行文件的打包(打压缩)和解压
1.".tar " 格式(打包不会压缩) ".tar" 格式的打包和解打包都使用 tar 命令,区别只是选项不同。 ".tar" 格式打包命令: tar [选项] [-f 压缩包名] 源文件或目录 选项: -cÿ…...
mysql8下载与安装教程
文章目录 1. MySQL下载2. 方式一:msi文件安装2.1 安装2.2 添加环境变量2.3 登录mysql 3. 方式二:zip文件安装3.1 安装3.2 配置文件3.3 加入环境变量3.4 初始化mysql3.5 登录mysql 1. MySQL下载 以下两个网址二选一 官网:https://downloads.…...
ubuntu22.04在线安装redis,可选择版本
安装脚本7.0.5版本 在线安装脚本,默认版本号是7.0.5,可以根据需要选择需要的版本进行下载编译安装 sudo apt-get install gcc -y sudo apt-get install pkg-config -y sudo apt-get install build-essential -y#安装redis rm -rf ./tmp.log systemctl …...
)
MYSQL加密和压缩函数详解和实战(含示例)
MySQL提供了多种加密和压缩方式,可以帮助保护数据库中的敏感数据。以下是一些常见的MySQL加密和压缩方法参考: 建议收藏以备后续用到查阅参考。 目录 一、AES_ENCRYPT AES加密 二、AES_DECRYPT AES解密 三、COMPRESS 压缩字符串 四、UNCOMPRESS 解压…...
redis Redis::geoAdd 无效,phpstudy 如何升级redis版本
redis 查看当前版本命令 INFO SERVERwindows 版redis 进入下载 geoadd 功能在3.2之后才有的,但是phpstudy提供的最新的版本也是在3.0,所以需要升级下 所以想出一个 挂狗头,卖羊肉的方法,下载windows 的程序,直接替…...
2024重庆大学计算机考研分析
24计算机考研|上岸指南 重庆大学 重庆大学计算机考研招生学院是计算机学院和大数据与软件学院。目前均已出拟录取名单。 重庆大学计算机学院是我国高校最早开展计算机研究的基地之一,1978年和1986年获西南地区首个硕士和博士点,1998年成立计算机学院&a…...

二、Lua数据类型
文章目录 一、数据类型nil二、数据类型boolean三、数据类型number四、数据类型String(一)用单引号或双引号:(二)可以包含换行的字符串(三)字符串与数字做数学运算时,优先将字符串转换…...

Grabcut算法在图片分割中的应用
GrabCut算法原理 Grabcut是基于图割(graph cut)实现的图像分割算法,它需要用户输入一个bounding box作为分割目标位置,实现对目标与背景的分离/分割,与KMeans与MeanShift等图像分割方法不同。 Grabcut分割速度快,效果好࿰…...

常用的Linux的指令
目录 常用指令 1、文件和目录操作: 2、文件查看和编辑 3、系统信息 4、进程管理 5、用户和权限 6、网络操作 7、压缩和解压 8、软件包管理 常用指令 1、文件和目录操作: ls:列出目录内容 cd: 切换目录 pwd:显…...
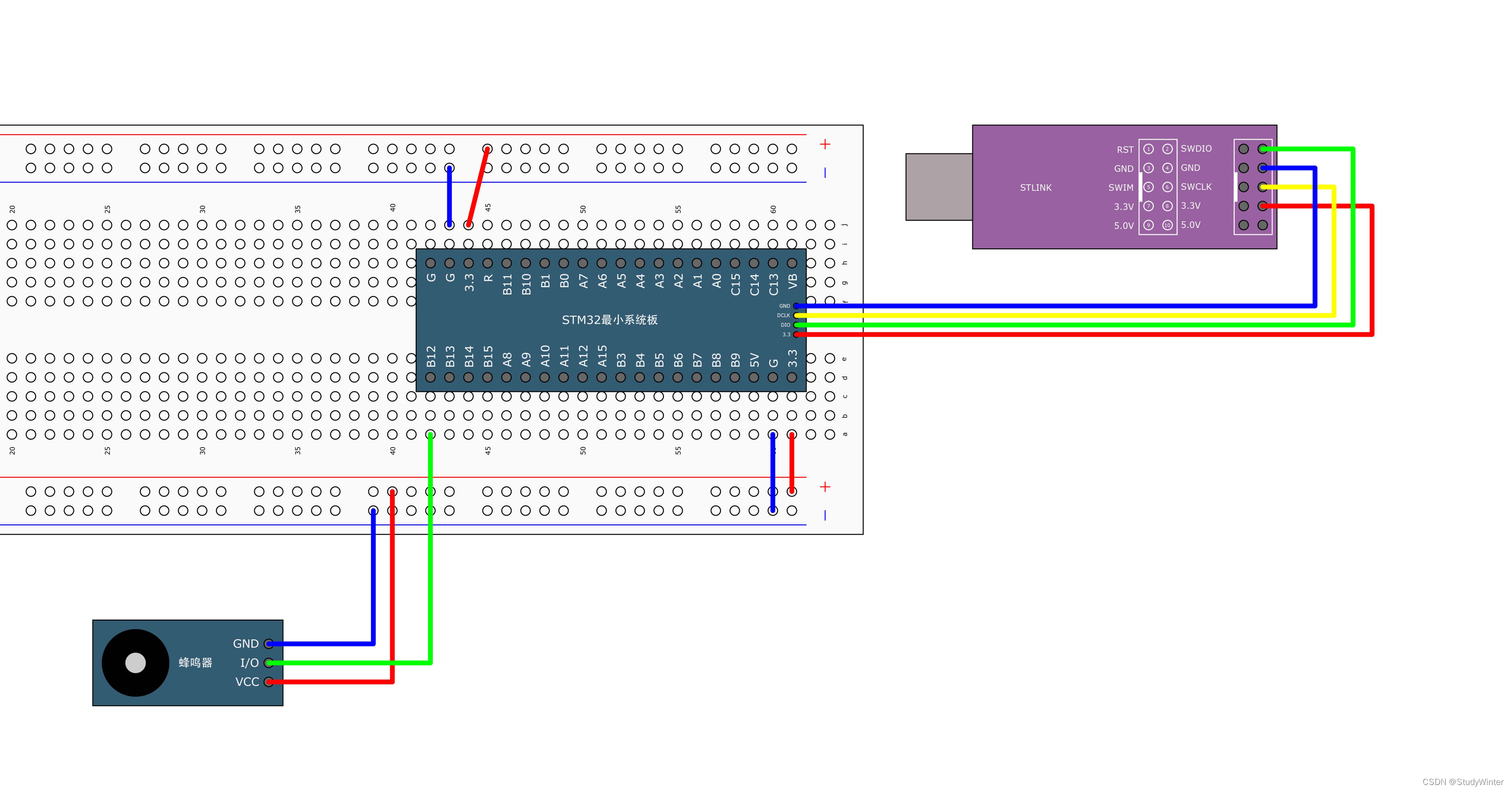
【STM32】GPIO输出
1 GPIO简介 (1)GPIO(General Purpose Input Output)通用输入输出口 (2)可配置为8种输入输出模式 (3)引脚电平:0V~3.3V,部分引脚可容忍5V(可以输…...

【Go语言从入门到实战】反射编程、Unsafe篇
反射编程 reflect.TypeOf vs reflect.ValueOf func TestTypeAndValue(t *testing.T) {var a int64 10t.Log(reflect.TypeOf(a), reflect.ValueOf(a))t.Log(reflect.ValueOf(a).Type()) }判断类型 - Kind() 当我们需要对反射回来的类型做判断时,Go 语言内置了一个…...
)
vue实现对话框指定某个对话内容的滚动到指定位置(滚动到可视区域的中间位置)
1、使用el-scrollbar实现定位滚动(elementui组件库) 如何滚动:参考链接 比如说指定某条对话内容滚动到可视区域的中间 html结构: <div class"chat-list" id"chat-list"><el-scrollbar ref"scro…...

从付费软件到自主开发:我用AI和FFmpeg实现了一个录屏工具杖
我为什么会发出这个疑问呢?是因为我研究Web开发中的一个问题时,HTTP请求体在 Filter(过滤器)处被读取了之后,在 Controller(控制层)就读不到值了,使用 RequestBody 的时候。 无论是字…...

Pyfa:EVE Online舰船配置的离线解决方案
Pyfa:EVE Online舰船配置的离线解决方案 【免费下载链接】Pyfa Python fitting assistant, cross-platform fitting tool for EVE Online 项目地址: https://gitcode.com/gh_mirrors/py/Pyfa 在EVE Online的浩瀚宇宙中,舰船配置是决定战斗胜负的关…...

C语言中的泛型尝试:void_ + 函数指针
文章目录C语言中的泛型尝试:void* 函数指针 🧪什么是泛型?🤔C语言中的工具:void* 和函数指针 🛠️代码示例:泛型排序函数 📝进阶示例:泛型链表 📚优缺点分析…...

如何释放CPU全部潜能:CPUDoc智能优化工具完全指南
如何释放CPU全部潜能:CPUDoc智能优化工具完全指南 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 你是否经常感觉电脑性能未能充分发挥?明明配置不错的硬件,却在运行大型软件或游戏时出现卡顿…...

0408晨间日记
- 关键词- - 上午- batam新的案子的评估- 资料全不全- 钢网层- 坐标档- bom的查询- 查询每个材料形状- 能不能生产- 细节 -材料特性- 制作炉温曲线- bom提取的方案- pdf转excel- 人工再核对一下- ai搜索再次纠错- 数字的1和字母的l是区分不出来的- cad坐标提取- 资料确实没有c…...

如何使用HS2-HF_Patch优化Honey Select 2游戏体验:完整指南
如何使用HS2-HF_Patch优化Honey Select 2游戏体验:完整指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是一款专为《Honey Select …...

爬虫实践——selenium、bs4
目录 一、浏览器的一般设置 二、打开网页并获取网页源码的方式 1、基于requests库 2、基于urlib库 3、基于selenium 三、HTML解析 1、BeautifulSoup 2、Selenium动态渲染爬虫:模拟动态操作网页,加载JS(webdriver) 1) 8种find_element定位元素的方法: 2)frame、window切换:…...

突破Cursor使用限制:智能解决方案实现Pro功能持续访问
突破Cursor使用限制:智能解决方案实现Pro功能持续访问 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tri…...

gitru:一个由 Rust 打造的零依赖 Git 提交信息校验工具蚕
一、项目背景与核心价值 1. 解决的核心痛点 Navicat的数据库连接密码并非明文存储,而是通过AES算法加密后写入.ncx格式的XML配置文件中。一旦用户忘记密码,常规方式只能重新配置连接,效率极低。本项目只作为学习研究使用,不做其他…...

UCLA与多所顶尖大学携手破解折纸生成难题
这项由UCLA牵头,联合德克萨斯A&M大学、犹他大学等多所知名学府共同完成的突破性研究,于2025年2月发表在计算机图形学顶级会议论文集中,论文编号为arXiv:2603.29585v1。有兴趣深入了解的读者可以通过该编号查询完整论文。想象一下…...