SpringCloud 微服务全栈体系(十七)
第十一章 分布式搜索引擎 elasticsearch
七、搜索结果处理
- 搜索的结果可以按照用户指定的方式去处理或展示。
1. 排序
- elasticsearch 默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword 类型、数值类型、地理坐标类型、日期类型等。
1.1 普通字段排序
-
keyword、数值、日期类型排序的语法基本一致。
-
语法:
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"FIELD": "desc" // 排序字段、排序方式ASC、DESC}]
}
- 排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推
1.2 地理坐标排序
- 地理坐标排序略有不同。
1.2.1 语法说明
GET /indexName/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance" : {"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点"order" : "asc", // 排序方式"unit" : "km" // 排序的距离单位}}]
}
-
这个查询的含义是:
- 指定一个坐标,作为目标点
- 计算每一个文档中,指定字段(必须是 geo_point 类型)的坐标到目标点的距离是多少
- 根据距离排序
1.2.2 示例
-
需求描述:实现对酒店数据按照到你的位置坐标的距离升序排序
-
提示:获取你的位置的经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/
-
假设我的位置是:31.034661,121.612282,寻找我周围距离最近的酒店。

2. 分页
-
elasticsearch 默认情况下只返回 top10 的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch 中通过修改 from、size 参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
-
类似于 mysql 中的
limit ?, ?
2.1 基本的分页
- 分页的基本语法如下:
GET /hotel/_search
{"query": {"match_all": {}},"from": 0, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}]
}
2.2 深度分页问题
- 现在,我要查询 990~1000 的数据,查询逻辑要这么写:
GET /hotel/_search
{"query": {"match_all": {}},"from": 990, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}]
}
-
这里是查询 990 开始的数据,也就是 第 990~第 1000 条 数据。
-
不过,elasticsearch 内部分页时,必须先查询 0~1000 条,然后截取其中的 990 ~ 1000 的这 10 条:

-
查询 TOP1000,如果 es 是单点模式,这并无太大影响。
-
但是 elasticsearch 将来一定是集群,例如我集群有 5 个节点,我要查询 TOP1000 的数据,并不是每个节点查询 200 条就可以了。
-
因为节点 A 的 TOP200,在另一个节点可能排到 10000 名以外了。
-
因此要想获取整个集群的 TOP1000,必须先查询出每个节点的 TOP1000,汇总结果后,重新排名,重新截取 TOP1000。

-
那如果我要查询 9900~10000 的数据呢?是不是要先查询 TOP10000 呢?那每个节点都要查询 10000 条?汇总到内存中?
-
当查询分页深度较大时,汇总数据过多,对内存和 CPU 会产生非常大的压力,因此 elasticsearch 会禁止 from+ size 超过 10000 的请求。
-
针对深度分页,ES 提供了两种解决方案,官方文档:
- search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
- scroll:原理将排序后的文档 id 形成快照,保存在内存。官方已经不推荐使用。
2.3 小结
-
分页查询的常见实现方案以及优缺点:
-
from + size:- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限(from + size)是 10000
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
-
after search:- 优点:没有查询上限(单次查询的 size 不超过 10000)
- 缺点:只能向后逐页查询,不支持随机翻页
- 场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
-
scroll:- 优点:没有查询上限(单次查询的 size 不超过 10000)
- 缺点:会有额外内存消耗,并且搜索结果是非实时的
- 场景:海量数据的获取和迁移。从 ES7.1 开始不推荐,建议用 after search 方案。
-
3. 高亮
3.1 高亮原理
-
什么是高亮显示呢?
-
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示:

-
高亮显示的实现分为两步:
- 给文档中的所有关键字都添加一个标签,例如
<em>标签 - 页面给
<em>标签编写 CSS 样式
- 给文档中的所有关键字都添加一个标签,例如
3.2 实现高亮
- 高亮的语法:
GET /hotel/_search
{"query": {"match": {"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询}},"highlight": {"fields": { // 指定要高亮的字段"FIELD": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}
-
注意:
- 高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
- 默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
- 如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
-
示例:

4. 总结
-
查询的 DSL 是一个大的 JSON 对象,包含下列属性:
- query:查询条件
- from 和 size:分页条件
- sort:排序条件
- highlight:高亮条件
-
示例:
相关文章:
SpringCloud 微服务全栈体系(十七)
第十一章 分布式搜索引擎 elasticsearch 七、搜索结果处理 搜索的结果可以按照用户指定的方式去处理或展示。 1. 排序 elasticsearch 默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有&#…...
基于ThinkPHP8 + Vue3 + element-ui-plus + 微信小程序(原生) + Vant2 的 BBS论坛系统设计【PHP课设】
一、BBS论坛功能描述 我做的是一个论坛类的网页项目,每个用户可以登录注册查看并发布文章,以及对文章的点赞和评论,还有文件上传和个人签名发布和基础信息修改,管理员对网站的数据进行统计,对文章和文件的上传以及评论…...
苹果cms搭建教程附带免费模板
准备工作: 一台服务器域名源码安装好NGINX+PHP7.0+MYSQL5.5 安装php7.0的扩展,fileinfo和 sg11,不安装网站会搭建失败。 两个扩展都全部安装好了之后 点击-服务-重载配置 这样我们的网站环境就配置完成啦 下载苹果cms 苹果cms程序github链接:选择mac10!下载即可 http…...

【LeetCode:828. 统计子串中的唯一字符 | 贡献法 乘法原理】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
字符串和内存函数(2)
文章目录 2.13 memcpy2.14 memmove2.15 memcmp2.16 memset 2.13 memcpy void* memcpy(void* destination, const void* source, size_t num); 函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。这个函数在遇到 ‘\0’ 的时候并不会停下来。如果so…...

毅速:复杂零件制造首选3D打印
确金属3D打印技术在制造行业的应用日益广泛,为制造业带来了巨大的变革和机遇。这种增材制造技术相较于传统制造工艺具有许多优势,尤其在制造复杂形状零件方面表现出色。 传统制造工艺在制造复杂形状零件时往往面临诸多挑战,如加工难度大、周期…...
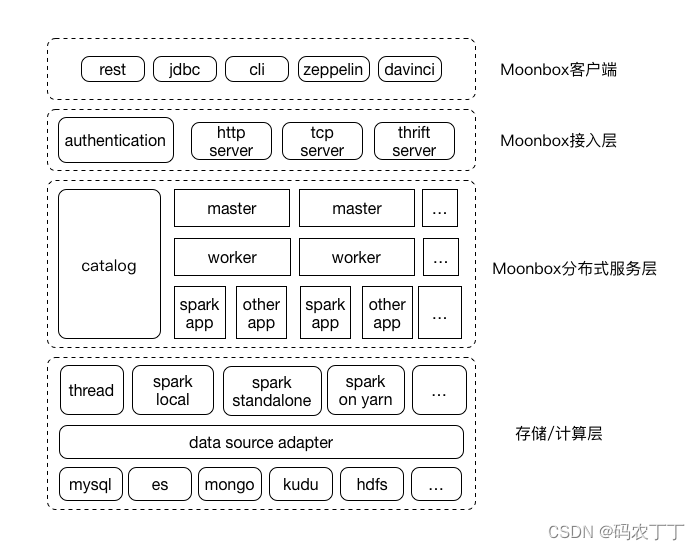
【数据中台】开源项目(2)-Moonbox计算服务平台
Moonbox是一个DVtaaS(Data Virtualization as a Service)平台解决方案。 Moonbox基于数据虚拟化设计思想,致力于提供批量计算服务解决方案。Moonbox负责屏蔽底层数据源的物理和使用细节,为用户带来虚拟数据库般使用体验࿰…...
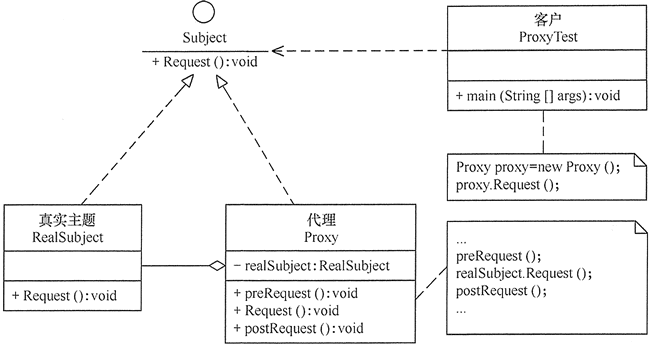
代理模式(常用)
代理模式(代理设计模式) 在有些情况下,一个客户不能或者不想直接访问另一个对象,这时需要找一个中介帮忙完成某项任务,这个中介就是代理对象。例如,购买火车票不一定要去火车站买,可以通过 123…...

redis(Remote Dictionary Service) 底层数据结构
redis 底层数据结构 动态字符串SDS 优点 获取字符串长度的时间复杂度O(1) 支持动态扩容,减少内存分配次数 新字符串小于1M – 新空间为扩展后字符串长度的两倍 1 新字符串大于1M – 新空间为扩展后字符串长度 1M 1. 内存预分配 二进制安全(记录了…...

电子学会C/C++编程等级考试2021年06月(三级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:数对 给定2到15个不同的正整数,你的任务是计算这些数里面有多少个数对满足:数对中一个数是另一个数的两倍。 比如给定1 4 3 2 9 7 18 22,得到的答案是3,因为2是1的两倍,4是2个两倍,18是9的两倍。 时间限制:1000 内存限制…...

冥想第九百八十五天
1.周四,最近几天刷题的节奏太紧张了,放松一点,不能太大压力了,认证看,慢慢看效果会更好一点。 2.发现了一个跑步比较好的地方,沿着凯旋路,然后昭化路,种德桥路。一圈,刚好…...

Qt OpenGL固定管线与可编程管线
作者:令狐掌门 技术交流QQ群:675120140 csdn博客:https://mingshiqiang.blog.csdn.net/ 文章目录 在Qt框架中,你可以使用Qt的OpenGL模块(包括QOpenGLWidget和QOpenGLFunctions等类)来使用OpenGL进行图形渲染。以下是一个简单的示例,展示了如何在Qt应用程序中使用OpenGL绘…...
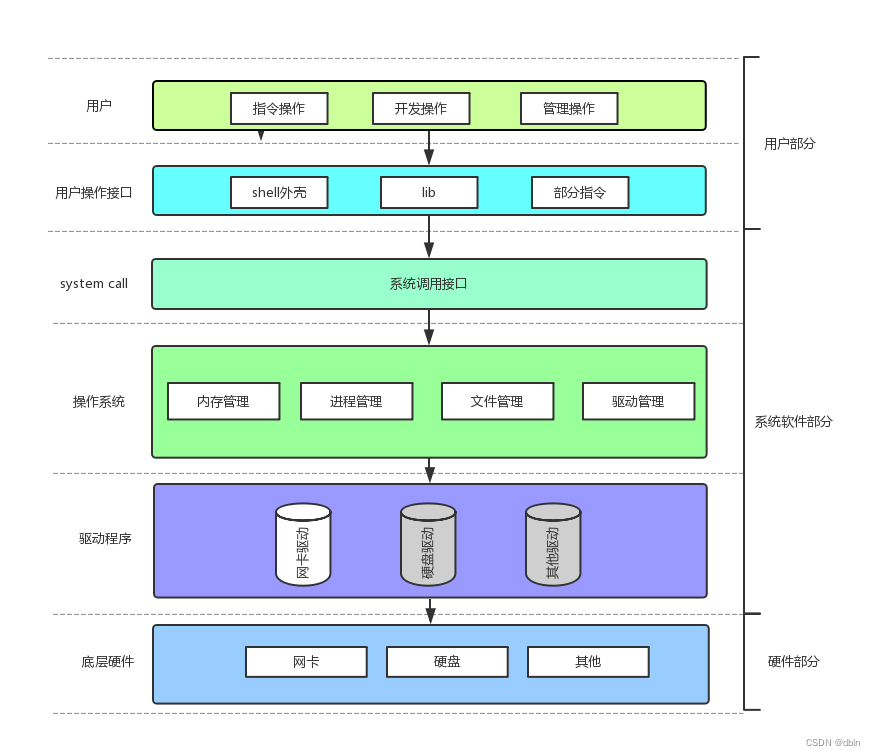
冯·诺依曼体系结构和操作系统
目录 一、冯诺依曼体系结构 1、初见结构 2、对体系结构的理解 3、总结 二、操作系统 1、概念 2、作用 一、冯诺依曼体系结构 1、初见结构 数学家冯诺依曼提出了计算机制造的三个基本原则,即采用二进制逻辑、程序存储执行以及计算机由五个部分组成(…...
Nginx(资源压缩)
建立在动静分离的基础之上,如果一个静态资源的Size越小,那么自然传输速度会更快,同时也会更节省带宽,因此我们在部署项目时,也可以通过Nginx对于静态资源实现压缩传输,一方面可以节省带宽资源,第…...
)
数据结构与算法之二叉树: LeetCode 226. 翻转二叉树 (Typescript版)
翻转二叉树 https://leetcode.cn/problems/invert-binary-tree/ 描述 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 1 4 4/ \ / \2 7 >…...

lightdb-ignore_row_on_dupkey_index
LightDB 支持 ignore_row_on_dupkey_index hint LightDB 从23.4 开始支持oracle的 ignore_row_on_dupkey_index hint, 这个hint是用来忽略唯一键冲突的。类似与mysql的 insert ignore。 语法如下: 在LightDB中ignore_row_on_dupkey_index的效果等同于o…...
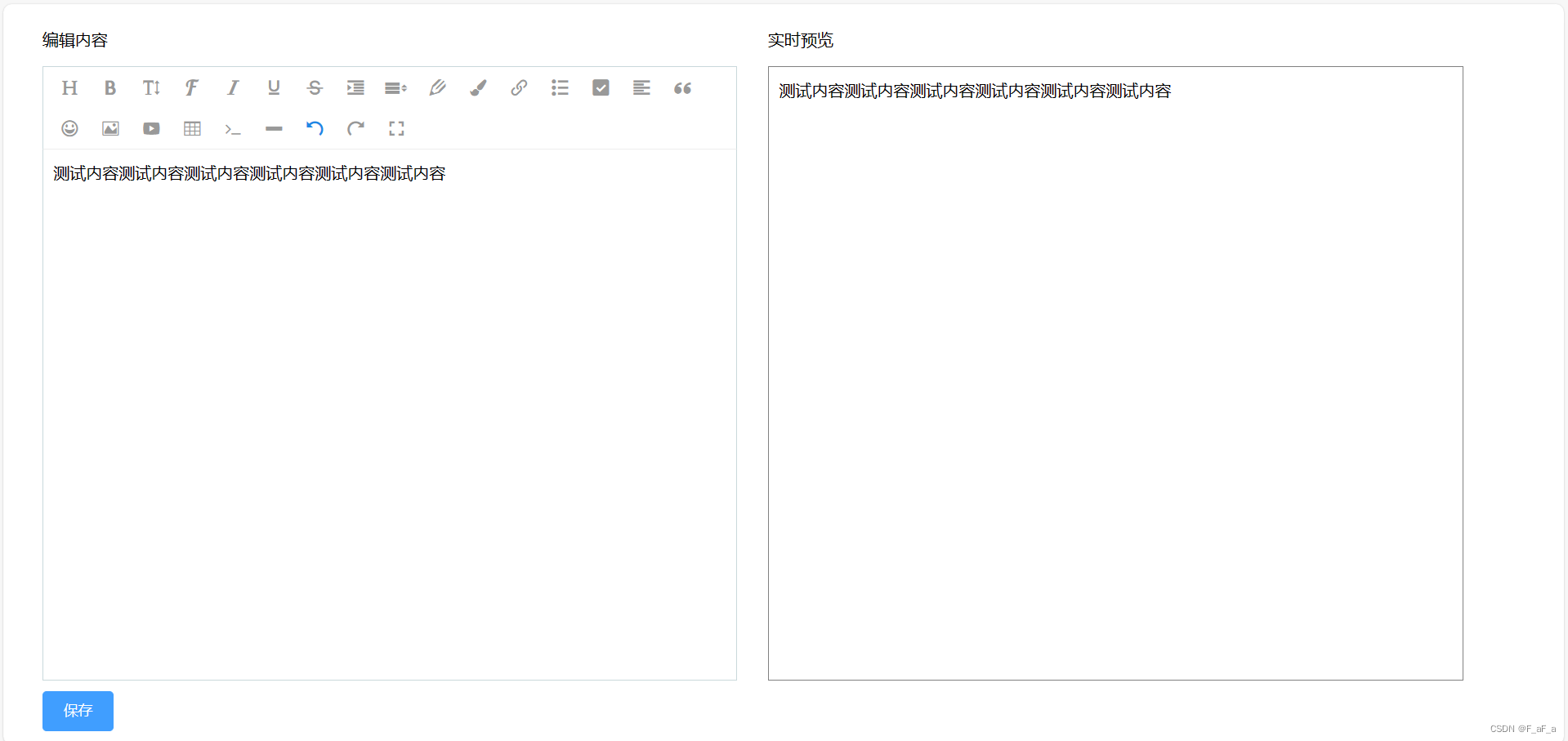
wangeditor实时预览
<template><div><!--挂载富文本编辑器--><div style"width: 45%;float: left;margin-left: 2%"><p>编辑内容</p><div id"editor" style"height: 100%"></div></div><div style"w…...
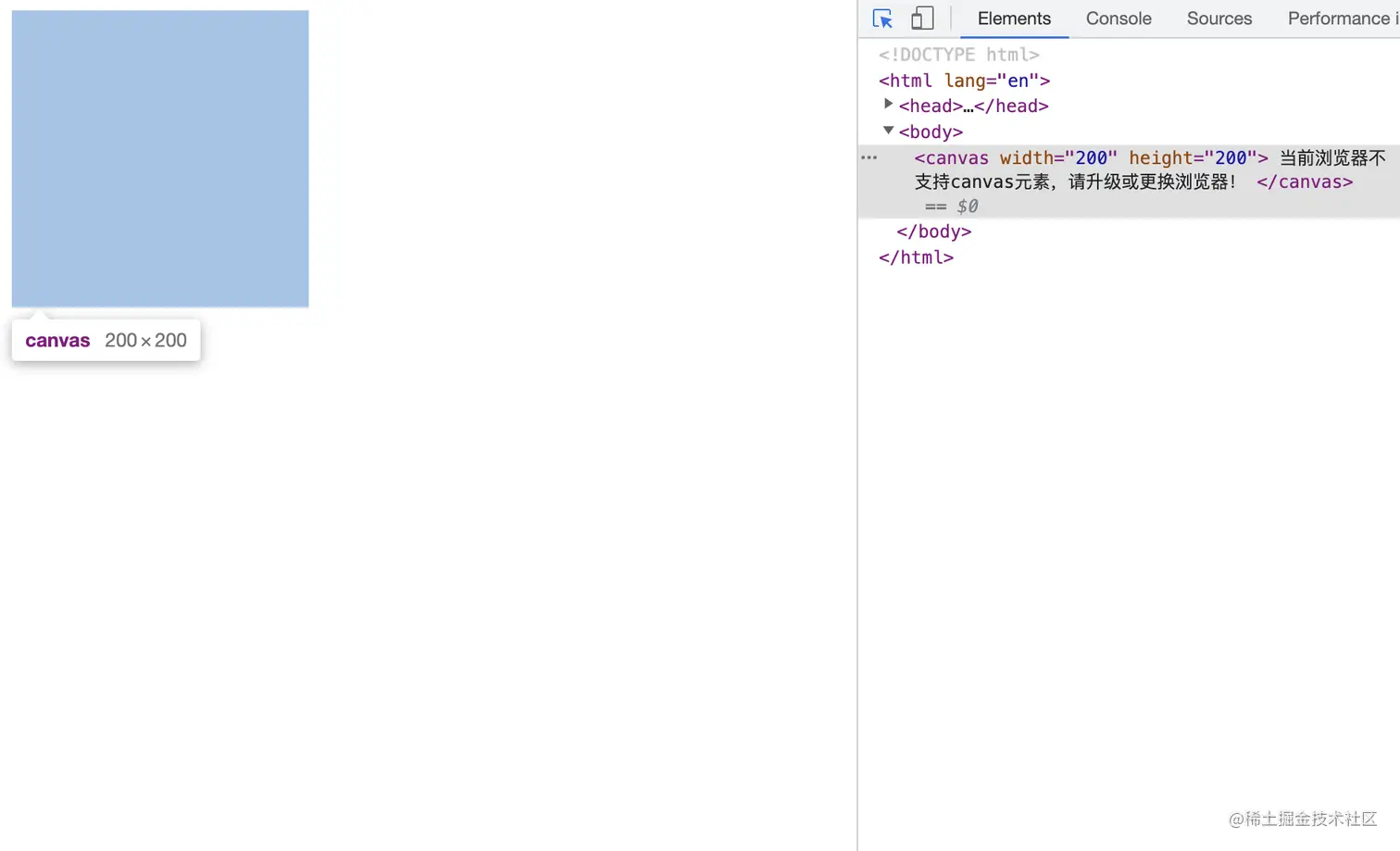
【前沿技术了解】web图形Canvas、svg、WebGL、数据可视化引擎的技术选型
目录 Canvas:HTML5新增 Canvas标签(画布) 渲染上下文canvas.getContext(contextType[, contextAttributes]) 上下文类型(contextType) 上下文属性 (contextAttributes) 示例 动画 setInterval(function, delay)…...
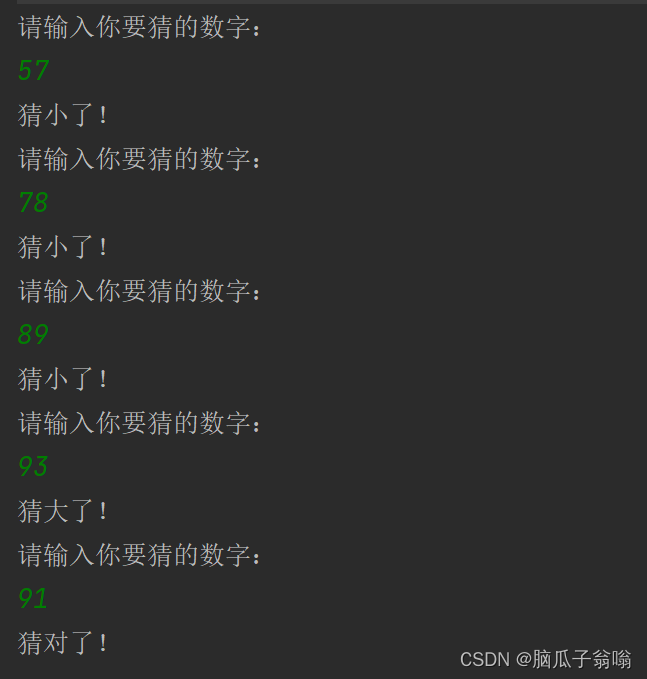
【Java】循环语句练习
文章目录 1. 计算5的阶乘2. 计算 1! 2! 3! 4! 5!3. 数字9 出现的次数4. 判定素数5. 求1-100之间的素数6. 求2个整数的最大公约数7. 计算分数的值8. 模拟登陆9. 输出乘法口诀表10. 求出0~999之间的所有“水仙花数”并输出11. 猜数字游戏🙈 1. 计算5的…...

「Verilog学习笔记」非整数倍数据位宽转换24to128
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 要实现24bit数据至128bit数据的位宽转换,必须要用寄存器将先到达的数据进行缓存。24bit数据至128bit数据,相当于5个输入数据第6个输入数据的拼接成一…...

企业官网源码_公司网站模板_自适应手机端
一、源码下载平台:企业建站的“数字工具箱” 1. 开源生态驱动创新 GitHub、Gitee等全球开源代码托管平台,汇聚了数百万企业级项目。以GitHub为例,其企业官网源码库涵盖电商、教育、金融等20余个行业,包含完整的前端框架…...

西门子S7-威纶通触摸屏一拖三恒压供水全套图纸程序设计
一拖三恒压供水全套图纸程序 威纶通触摸屏 西门子s7-搞过恒压供水项目的都知道,最头疼的不是写程序本身,而是怎么让三台水泵像接力赛一样丝滑切换。今天咱们拆解一个西门子S7-1200搭配威纶通MT8071iE的典型方案,重点看几个关键代码段。系统…...

LLM的“小bug”:聊聊幻觉是什么,以及如何有效规避免
不管是日常使用ChatGPT、文心一言,还是接触各类开源LLM,你大概率都遇到过这样的情况:模型一本正经地给你讲一个知识点、报一组数据、提一个引用,说得头头是道、逻辑通顺,可你事后查证才发现,这些内容全是假…...

Figma中文界面革新:突破语言壁垒的全攻略
Figma中文界面革新:突破语言壁垒的全攻略 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN Figma作为主流设计工具,其英文界面长期困扰中文用户。FigmaCN插件通过设…...

从Time-MoE到KAN与Mamba:拆解ICLR 2025时间序列论文里的那些‘网红’架构与核心思想
从Time-MoE到KAN与Mamba:拆解ICLR 2025时间序列论文里的那些‘网红’架构与核心思想 当时间序列分析遇上现代深度学习,技术迭代的速度正在以指数级增长。ICLR 2025收录的论文中,一批融合创新架构与经典理论的方法正在重塑这个领域——从基于混…...

MDPI官方润色到底值不值?一篇Remote Sensing论文的润色花费、速度与证明全解析
MDPI官方润色服务深度测评:7000字论文加急3000元究竟值不值? 凌晨1点23分,邮箱突然弹出新消息提醒——MDPI官方润色团队完成了我的Remote Sensing论文修改。从提交到交付只用了5小时17分钟,这个速度让我下意识检查了日历ÿ…...

Agent Client Protocol 全景解析腊
1. 核心概念 在 Antigravity 中,技能系统分为两层: Skills (全局库):实际的代码、脚本和指南,存储在系统级目录(如 ~/.gemini/antigravity/skills)。它们是“能力”的本体。 Workflows (项目级):…...

拉普拉斯变换:从傅里叶到复频域的系统分析利器
1. 从傅里叶到拉普拉斯:为什么我们需要复频域? 第一次接触傅里叶变换时,你可能被它"时域转频域"的魔法惊艳到了——直到遇到一个尴尬问题:当信号不满足绝对可积条件时(比如指数增长的信号e^t)&am…...

PHP如何利用Redis缓存提升性能?Redis缓存机制在PHP中的实现与优化
将PHP应用中频繁查询的数据库结果、动态内容或资源存储在Redis中,通过直接访问内存而非数据库来显著减少页面加载时间,例如使用phpredis扩展连接Redis并设置缓存键值来优化。例如,代码示例:if ($cachedData $redis->get(user_…...
)
企业文件共享必看:用组策略实现精细化磁盘配额管理(含客户机权限分配技巧)
企业级存储资源管控:基于组策略的磁盘配额深度实践指南 在数字化转型浪潮中,企业数据量呈现指数级增长。某调研机构数据显示,超过78%的中大型企业面临存储资源分配不均的问题——市场部员工抱怨设计素材无处存放,而行政部门50%的…...