深度学习中小知识点系列(三) 解读Mosaic 数据增强
前言
Mosaic数据增强,这种数据增强方式简单来说就是把4张图片,通过随机缩放、随机裁减、随机排布的方式进行拼接。Mosaic有如下优点:
(1)丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好;
(2)减少GPU显存:直接计算4张图片的数据,使得Mini-batch大小并不需要很大就可以达到比较好的效果。
原理
思路:随机选择四张图,取其部分拼入该图,如下图所示,四种颜色代表四张样本图,超出的部分将被舍弃。

具体做法如下:
step1:新建mosaic画布,并在mosaic画布上随机生成一个点
im_size = 640
mosaic_border = [-im_size // 2, -im_size // 2]
s_mosaic = im_size * 2mosaic = np.full((s_mosaic, s_mosaic, 3), 114, dtype=np.uint8)
yc, xc = (int(random.uniform(-x, s_mosaic + x)) for x in mosaic_border)

step2:围绕随机点 (x_c, y_c) 放置4块拼图
(1)左上位置
画布放置区域: (x1a, y1a, x2a, y2a)
case1:图片不超出画布,画布放置区域为 (x_c - w , y_c - h , x_c, y_c)
case2:图片超出画布,画布放置区域为 (0 , 0 , x_c, y_c)
综合case1和case2,画布区域为:
x1a, y1a, x2a, y2a = max(x_c - w, 0), max(y_c - h, 0), x_c, y_c

图片区域 : (x1b, y1b, x2b, y2b)
case1:图片不超出画布,图片不用裁剪,图片区域为 (0 , 0 , w , h)
case2:图片超出画布,超出部分的图片需要裁剪,区域为 (w - x_c , h - y_c , w , h)
综合case1和case2,图片区域为:
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h
(2)右上位置
画布放置区域: (x1a, y1a, x2a, y2a)
case1:图片不超出画布,画布区域为 (x_c , y_c - h , x_c + w , y_c)
case2:图片超出画布,画布区域为 (x_c , 0 , s_mosaic , y_c)
综合case1和case2,画布区域为:
x1a, y1a, x2a, y2a = x_c, max(y_c - h, 0), min(x_c + w, s_mosaic), y_c

图片区域 : (x1b, y1b, x2b, y2b)
case1:图片不超出画布,图片不用裁剪,图片区域为 (0 , 0 , w , h)
case2:图片超出画布,图片需要裁剪,图片区域为 (0 , h - (y2a - y1a) , x2a - x1a , h)
综合case1和case2,图片区域为:
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
同理可实现左下和右下的拼图。
step3:更新bbox坐标
4张图片的bbox (n,4),其中n为4张图片中bbox数量,4代表四个坐标值(xmin,ymin,xmax,ymax) ,加上偏移量得到mosaic bbox坐标:
def xywhn2xyxy(x, padw=0, padh=0):# x: bbox坐标 (xmin,ymin,xmax,ymax)x = np.stack(x)y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)y[:, 0] = x[:, 0] + padw # top left xy[:, 1] = x[:, 1] + padh # top left yy[:, 2] = x[:, 2] + padw # bottom right xy[:, 3] = x[:, 3] + padh # bottom right yreturn y
完整实现代码
import cv2
import torch
import random
import os.path
import numpy as np
import matplotlib.pyplot as plt
from camvid import get_bbox, draw_box# 定义一个名为load_mosaic的函数,它接受两个参数:im_files(图像文件列表)和name_color_dict(名称和颜色的字典)
def load_mosaic(im_files, name_color_dict):# 定义图像的默认大小为640x640im_size = 640# 定义mosaic(拼接的图像)的默认大小为1280x1280(两倍的im_size)s_mosaic = im_size * 2# 定义mosaic的边框为[-im_size//2, -im_size//2],即在中心位置周围绘制一个宽度的边框mosaic_border = [-im_size // 2, -im_size // 2]# 初始化三个空的列表,用于存储标签、分割和颜色信息labels4, segments4, colors = [], [], []# 在mosaic中随机选择一个中心点的x, y坐标,这里使用uniform函数随机生成,这样可以使拼接的图像有随机性,避免总是拼接在同一个位置# mosaic center x, yy_c, x_c = (int(random.uniform(-x, s_mosaic + x)) for x in mosaic_border)# 创建一个大小为(s_mosaic, s_mosaic, 3)的numpy数组,并用114(一种灰度值)填充,创建一个全为灰度的空白图像img4 = np.full((s_mosaic, s_mosaic, 3), 114, dtype=np.uint8)# 创建一个大小为(s_mosaic, s_mosaic)的numpy数组,并用0填充,作为分割图像用,表示所有像素都不属于任何物体seg4 = np.full((s_mosaic, s_mosaic), 0, dtype=np.uint8)# 对im_files中的每个图像文件进行遍历for i, im_file in enumerate(im_files):# 使用cv2库的imread函数读取图像文件,返回一个多维的numpy数组# Load imageimg = cv2.imread(im_file)# 根据图像文件路径生成对应的分割文件路径,替换'images'为'labels',并添加'_L.png'后缀,用于获取物体的边界框信息seg_file = im_file.replace('images', 'labels')# 从分割文件路径中获取文件名(不包含路径和后缀),作为物体名称name = os.path.basename(seg_file).split('.')[0]# 根据物体名称构造新的分割文件路径(与原来的图像文件路径在同一目录下,具有相同的文件名,但后缀不同)seg_file = os.path.join(os.path.dirname(seg_file), name + '_L.png')# 调用get_bbox函数获取物体的边界框信息(返回分割后的图像、边界框列表和颜色列表)seg, boxes, color = get_bbox(seg_file, names, name_color_dict)# 把从get_bbox函数获取的颜色列表添加到全局的颜色列表中colors += color# 获取当前图像的高度、宽度和通道数(这里假设是彩色图像,所以通道数为3)h, w, _ = np.shape(img)# 定义一个变量img4,它是一个大小为(s_mosaic, s_mosaic, 3)的空数组,用于存放拼接后的图像# place img in img4if i == 0: # top left# 左上角的子图像# 计算源图像的坐标和目标图像的坐标x1a, y1a, x2a, y2a = max(x_c - w, 0), max(y_c - h, 0), x_c, y_cx1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h elif i == 1: # top right# 右上角的子图像# 计算源图像的坐标和目标图像的坐标x1a, y1a, x2a, y2a = x_c, max(y_c - h, 0), min(x_c + w, s_mosaic), y_cx1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), helif i == 2: # bottom left# 左下角的子图像# 计算源图像的坐标和目标图像的坐标x1a, y1a, x2a, y2a = max(x_c - w, 0), y_c, x_c, min(s_mosaic, y_c + h)x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)elif i == 3: # bottom right# 右下角的子图像# 计算源图像的坐标和目标图像的坐标x1a, y1a, x2a, y2a = x_c, y_c, min(x_c + w, s_mosaic), min(s_mosaic, y_c + h)x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)# 将图像img切割并拼接到img4中,同时保持每个子图像的大小和位置不变# img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b]# 将分割后的图像(seg)切割并拼接到seg4中,保持分割信息的位置不变# place seg in seg4seg4[y1a:y2a, x1a:x2a] = seg[y1b:y2b, x1b:x2b]# 更新边界框(bbox)的坐标,根据拼接的偏移量进行修正# padw为x1a-x1b,代表拼接的横向偏移量# padh为y1a-y1b,代表拼接的纵向偏移量# update bboxpadw = x1a - x1bpadh = y1a - y1bboxes = xywhn2xyxy(boxes, padw=padw, padh=padh)labels4.append(boxes)# 将所有拼接后的边界框(bbox)和标签合并为一个数组labels4 = np.concatenate(labels4, 0)# 对边界框(bbox)的坐标进行修正,防止坐标超出拼接后的图像范围# clip coordfor x in labels4[:, 1:]:np.clip(x, 0, s_mosaic, out=x) # clip coord# 绘制拼接后的图像以及边界框(bbox)信息# draw resultdraw_box(seg4, labels4, colors)# 返回拼接后的图像img4,边界框(bbox)标签labels4以及分割后的图像seg4return img4, labels4,seg4if __name__ == '__main__':names = ['Pedestrian', 'Car', 'Truck_Bus']im_files = ['camvid/images/0016E5_01440.png','camvid/images/0016E5_06600.png','camvid/images/0006R0_f00930.png','camvid/images/0006R0_f03390.png']load_mosaic(im_files, name_color_dict)


第二种实现
1. 方法介绍
Mosaic 数据增强算法将多张图片按照一定比例组合成一张图片,使模型在更小的范围内识别目标。Mosaic 数据增强算法参考 CutMix数据增强算法。CutMix数据增强算法使用两张图片进行拼接,而 Mosaic 数据增强算法一般使用四张进行拼接,但两者的算法原理是非常相似的。
方法步骤:
(1)随机选取图片拼接基准点坐标(xc,yc),另随机选取四张图片。
(2)四张图片根据基准点,分别经过 尺寸调整 和 比例缩放 后,放置在指定尺寸的大图的左上,右上,左下,右下位置。
(3)根据每张图片的尺寸变换方式,将映射关系对应到图片标签上。
(4)依据指定的横纵坐标,对大图进行拼接。处理超过边界的检测框坐标。
方法优点:
(1)增加数据多样性,随机选取四张图像进行组合,组合得到图像个数比原图个数要多。
(2)增强模型鲁棒性,混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。
(3)加强批归一化层(Batch Normalization)的效果。当模型设置 BN 操作后,训练时会尽可能增大批样本总量(BatchSize),因为 BN 原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么 BN 计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。
(4)Mosaic 数据增强算法有利于提升小目标检测性能。Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标。
2. 代码展示
2.1 加载图片及标签
我以四张图片及其标签文件为例,导入 xml.etree 库解析XML标签文件,这里我只读取检测框的左上和右下角坐标信息,我习惯使用opencv方法处理图片,当然也可以使用Image库处理。将读取的图片及其对应的坐标信息保存在同一个列表中。

代码如下:
# 主函数,获取图片路径和检测框路径
if __name__ == '__main__':# 给出图片文件夹和检测框文件夹所在的位置image_dir = 'D:/deeplearning/database/VOC2007/picture/'annotation_dir = 'D:/deeplearning/database/VOC2007/annotation/'image_list = [] # 存放每张图像和该图像对应的检测框坐标信息# 读取4张图像及其检测框信息for i in range(4):image_box = [] # 存放每张图片的检测框信息# 某张图片位置及其对应的检测框信息image_path = image_dir + str(i+1) + '.jpg'annotation_path = annotation_dir + str(i+1) + '.xml'image = cv2.imread(image_path) # 读取图像# 读取检测框信息with open(annotation_path, 'r') as new_f:# getroot()获取根节点root = ET.parse(annotation_path).getroot()# findall查询根节点下的所有直系子节点,find查询根节点下的第一个直系子节点for obj in root.findall('object'):obj_name = obj.find('name').text # 目标名称bndbox = obj.find('bndbox')left = eval(bndbox.find('xmin').text) # 左上坐标xtop = eval(bndbox.find('ymin').text) # 左上坐标yright = eval(bndbox.find('xmax').text) # 右下坐标xbottom = eval(bndbox.find('ymax').text) # 右下坐标y# 保存每张图片的检测框信息image_box.append([left, top, right, bottom]) # [[x1,y1,x2,y2],[..],[..]]# 保存图像及其对应的检测框信息image_list.append([image, image_box])# 分割、缩放、拼接图片get_random_data(image_list, input_shape=[416,416])
2.2 图像分割
输入图片的尺寸是 (iw, ih) ;指定图片的尺寸是 (w, h) ,其中w=h=416;缩放后的图片的尺寸是 (nw, nh)
(1)先通过cv2.resize()将图片尺寸从(iw, ih) 变成 (w, h);再乘以缩放比例 scale,是0.6至0.8之间的一个随机数;得到压缩后的图像尺寸 (nw, nh)
(2)生成一个尺寸为 (w, h) 的画板 np.zeros((h,w,3), np.uint8),将第一张压缩后的图片放在画板的左上方,第二张放在右上方,第三张放在左下方,第四张放在右下方。
(3)h-nh代表y轴方向上画板边界距离缩放后图片边界的距离,w-nw代表x轴方向上画板边界距离缩放后图片边界的距离
**(4)**检测框中心点坐标为 (cx, cy),坐标调整比例是 nw/iw,但需要分开调整位于不同位置的四张图的检测框。
代码如下:
def get_random_data(image_list, input_shape):h, w = input_shape # 获取图像的宽高'''设置拼接的分隔线位置'''min_offset_x = 0.4min_offset_y = 0.4 scale_low = 1 - min(min_offset_x, min_offset_y) # 0.6scale_high = scale_low + 0.2 # 0.8image_datas = [] # 存放图像信息box_datas = [] # 存放检测框信息index = 0 # 当前是第几张图#(1)图像分割for frame_list in image_list:frame = frame_list[0] # 取出的某一张图像box = np.array(frame_list[1:]) # 该图像对应的检测框坐标ih, iw = frame.shape[0:2] # 图片的宽高cx = (box[0,:,0] + box[0,:,2]) // 2 # 检测框中心点的x坐标cy = (box[0,:,1] + box[0,:,3]) // 2 # 检测框中心点的y坐标# 对输入图像缩放new_ar = w/h # 图像的宽高比scale = np.random.uniform(scale_low, scale_high) # 缩放0.6--0.8倍# 调整后的宽高nh = int(scale * h) # 缩放比例乘以要求的宽高nw = int(nh * new_ar) # 保持原始宽高比例# 缩放图像frame = cv2.resize(frame, (nw,nh))# 调整中心点坐标cx = cx * nw/iw cy = cy * nh/ih # 调整检测框的宽高bw = (box[0,:,2] - box[0,:,0]) * nw/iw # 修改后的检测框的宽高bh = (box[0,:,3] - box[0,:,1]) * nh/ih# 创建一块[416,416]的底版new_frame = np.zeros((h,w,3), np.uint8)# 确定每张图的位置if index==0: new_frame[0:nh, 0:nw] = frame # 第一张位于左上方elif index==1: new_frame[0:nh, w-nw:w] = frame # 第二张位于右上方elif index==2: new_frame[h-nh:h, 0:nw] = frame # 第三张位于左下方elif index==3: new_frame[h-nh:h, w-nw:w] = frame # 第四张位于右下方# 修正每个检测框的位置if index==0: # 左上图像box[0,:,0] = cx - bw // 2 # x1box[0,:,1] = cy - bh // 2 # y1box[0,:,2] = cx + bw // 2 # x2box[0,:,3] = cy + bh // 2 # y2 if index==1: # 右上图像box[0,:,0] = cx - bw // 2 + w - nw # x1box[0,:,1] = cy - bh // 2 # y1box[0,:,2] = cx + bw // 2 + w - nw # x2box[0,:,3] = cy + bh // 2 # y2if index==2: # 左下图像box[0,:,0] = cx - bw // 2 # x1box[0,:,1] = cy - bh // 2 + h - nh # y1box[0,:,2] = cx + bw // 2 # x2box[0,:,3] = cy + bh // 2 + h - nh # y2if index==3: # 右下图像box[0,:,2] = cx - bw // 2 + w - nw # x1box[0,:,3] = cy - bh // 2 + h - nh # y1box[0,:,0] = cx + bw // 2 + w - nw # x2box[0,:,1] = cy + bh // 2 + h - nh # y2index = index + 1 # 处理下一张# 保存处理后的图像及对应的检测框坐标image_datas.append(new_frame)box_datas.append(box)# 取出某张图片以及它对应的检测框信息, i代表图片索引for image, boxes in zip(image_datas, box_datas):# 复制一份原图image_copy = image.copy()# 遍历该张图像中的所有检测框for box in boxes[0]: # 获取某一个框的坐标x1, y1, x2, y2 = boxcv2.rectangle(image_copy, (x1,y1), (x2,y2), (0,255,0), 2)cv2.imshow('img', image_copy)cv2.waitKey(0)cv2.destroyAllWindows()
分割后的图像如下:

2.3 图像合并
首先设置拼接线,cutx代表x轴方向把图像分割成两块区域,cuty代表y轴方向把图片分割成两块。设置 (cutx, cuty) 代表四张图在何坐标下切割,如右上方的图只取 cutx左侧 且 cuty上侧 的区域。
创建一块新的画板new_image,大小为(416, 416),将切割后的四张图片组合在一起
#(2)将四张图像拼接在一起# 在指定范围中选择横纵向分割线cutx = np.random.randint(int(w*min_offset_x), int(w*(1-min_offset_x)))cuty = np.random.randint(int(h*min_offset_y), int(h*(1-min_offset_y))) # 创建一块[416,416]的底版用来组合四张图new_image = np.zeros((h,w,3), np.uint8)new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :]new_image[:cuty, cutx:, :] = image_datas[1][:cuty, cutx:, :]new_image[cuty:, :cutx, :] = image_datas[2][cuty:, :cutx, :]new_image[cuty:, cutx:, :] = image_datas[3][cuty:, cutx:, :]# 显示合并后的图像cv2.imshow('new_img', new_image)cv2.waitKey(0)cv2.destroyAllWindows()# 复制一份合并后的原图final_image_copy = new_image.copy()# 显示有检测框并合并后的图像for boxes in box_datas:# 遍历该张图像中的所有检测框for box in boxes[0]: # 获取某一个框的坐标x1, y1, x2, y2 = boxcv2.rectangle(final_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)cv2.imshow('new_img_bbox', final_image_copy)cv2.waitKey(0)cv2.destroyAllWindows()
拼接后的图像如下:

2.4 处理检测框边界
如上图,我们发现左上图的检测框伸展到了其他区域,右下图的部分检测车辆的框中没有目标。因为我们只对图片进行了拼接,而图片对应的检测框仍然是原来分割前的检测框坐标。
(1)将不在其对应图像所在区域内的检测框都剔除;如右下侧图中的检测车的框跑到左下侧图中去了。
(2)将检测框一部分在图像区域内,一部分不在图像区域内的,以该图的区域分界线(cutx, cuty)代替越界的检测框线条。如左上图人的检测框需要用边界线代替区域外的边缘线
(3)如果修正后的检测框的高度或者宽度过于小,那么就没有意义,剔除这个修正后的框
代码如下:
#(4)处理超出边缘的检测框
def merge_bboxes(bboxes, cutx, cuty):# 保存修改后的检测框merge_box = []# 遍历每张图像,共4个for i, box in enumerate(bboxes):# 每张图片中需要删掉的检测框index_list = []# 遍历每张图的所有检测框,index代表第几个框for index, box in enumerate(box[0]):# axis=1纵向删除index索引指定的列,axis=0横向删除index指定的行# box[0] = np.delete(box[0], index, axis=0) # 获取每个检测框的宽高x1, y1, x2, y2 = box# 如果是左上图,修正右侧和下侧框线if i== 0:# 如果检测框左上坐标点不在第一部分中,就忽略它if x1 > cutx or y1 > cuty:index_list.append(index) # 如果检测框右下坐标点不在第一部分中,右下坐标变成边缘点if y2 >= cuty and y1 <= cuty:y2 = cutyif y2-y1 < 5:index_list.append(index)if x2 >= cutx and x1 <= cutx:x2 = cutx# 如果修正后的左上坐标和右下坐标之间的距离过小,就忽略这个框if x2-x1 < 5:index_list.append(index) # 如果是右上图,修正左侧和下册框线if i == 1:if x2 < cutx or y1 > cuty:index_list.append(index) if y2 >= cuty and y1 <= cuty:y2 = cutyif y2-y1 < 5:index_list.append(index)if x1 <= cutx and x2 >= cutx:x1 = cutxif x2-x1 < 5:index_list.append(index) # 如果是左下图if i == 2:if x1 > cutx or y2 < cuty:index_list.append(index) if y1 <= cuty and y2 >= cuty:y1 = cutyif y2-y1 < 5:index_list.append(index) if x1 <= cutx and x2 >= cutx:x2 = cutxif x2-x1 < 5:index_list.append(index) # 如果是右下图if i == 3:if x2 < cutx or y2 < cuty:index_list.append(index) if x1 <= cutx and x2 >= cutx:x1 = cutxif x2-x1 < 5:index_list.append(index) if y1 <= cuty and y2 >= cuty:y1 = cutyif y2-y1 < 5:index_list.append(index) # 更新坐标信息bboxes[i][0][index] = [x1, y1, x2, y2] # 更新第i张图的第index个检测框的坐标# 删除不满足要求的框,并保存merge_box.append(np.delete(bboxes[i][0], index_list, axis=0))# 返回坐标信息return merge_box#(3)处理超出图像边缘的检测框
new_boxes = merge_bboxes(box_datas, cutx, cuty)# 复制一份合并后的图像
modify_image_copy = new_image.copy()# 绘制修正后的检测框
for boxes in new_boxes: # 遍历每张图像中的所有检测框for box in boxes:# 获取某一个框的坐标x1, y1, x2, y2 = boxcv2.rectangle(modify_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)
cv2.imshow('new_img_bbox', modify_image_copy)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果图如下:

3. 完整代码
from xml.etree import ElementTree as ET # xml文件解析方法
import numpy as np
import cv2#(3)处理超出边缘的检测框
def merge_bboxes(bboxes, cutx, cuty):# 保存修改后的检测框merge_box = []# 遍历每张图像,共4个for i, box in enumerate(bboxes):# 每张图片中需要删掉的检测框index_list = []# 遍历每张图的所有检测框,index代表第几个框for index, box in enumerate(box[0]):# axis=1纵向删除index索引指定的列,axis=0横向删除index指定的行# box[0] = np.delete(box[0], index, axis=0) # 获取每个检测框的宽高x1, y1, x2, y2 = box# 如果是左上图,修正右侧和下侧框线if i== 0:# 如果检测框左上坐标点不在第一部分中,就忽略它if x1 > cutx or y1 > cuty:index_list.append(index) # 如果检测框右下坐标点不在第一部分中,右下坐标变成边缘点if y2 >= cuty and y1 <= cuty:y2 = cutyif y2-y1 < 5:index_list.append(index)if x2 >= cutx and x1 <= cutx:x2 = cutx# 如果修正后的左上坐标和右下坐标之间的距离过小,就忽略这个框if x2-x1 < 5:index_list.append(index) # 如果是右上图,修正左侧和下册框线if i == 1:if x2 < cutx or y1 > cuty:index_list.append(index) if y2 >= cuty and y1 <= cuty:y2 = cutyif y2-y1 < 5:index_list.append(index)if x1 <= cutx and x2 >= cutx:x1 = cutxif x2-x1 < 5:index_list.append(index) # 如果是左下图if i == 2:if x1 > cutx or y2 < cuty:index_list.append(index) if y1 <= cuty and y2 >= cuty:y1 = cutyif y2-y1 < 5:index_list.append(index) if x1 <= cutx and x2 >= cutx:x2 = cutxif x2-x1 < 5:index_list.append(index) # 如果是右下图if i == 3:if x2 < cutx or y2 < cuty:index_list.append(index) if x1 <= cutx and x2 >= cutx:x1 = cutxif x2-x1 < 5:index_list.append(index) if y1 <= cuty and y2 >= cuty:y1 = cutyif y2-y1 < 5:index_list.append(index) # 更新坐标信息bboxes[i][0][index] = [x1, y1, x2, y2] # 更新第i张图的第index个检测框的坐标# 删除不满足要求的框,并保存merge_box.append(np.delete(bboxes[i][0], index_list, axis=0))# 返回坐标信息return merge_box#(1)对传入的四张图片数据增强
def get_random_data(image_list, input_shape):h, w = input_shape # 获取图像的宽高'''设置拼接的分隔线位置'''min_offset_x = 0.4min_offset_y = 0.4 scale_low = 1 - min(min_offset_x, min_offset_y) # 0.6scale_high = scale_low + 0.2 # 0.8image_datas = [] # 存放图像信息box_datas = [] # 存放检测框信息index = 0 # 当前是第几张图#(1)图像分割for frame_list in image_list:frame = frame_list[0] # 取出的某一张图像box = np.array(frame_list[1:]) # 该图像对应的检测框坐标ih, iw = frame.shape[0:2] # 图片的宽高cx = (box[0,:,0] + box[0,:,2]) // 2 # 检测框中心点的x坐标cy = (box[0,:,1] + box[0,:,3]) // 2 # 检测框中心点的y坐标# 对输入图像缩放new_ar = w/h # 图像的宽高比scale = np.random.uniform(scale_low, scale_high) # 缩放0.6--0.8倍# 调整后的宽高nh = int(scale * h) # 缩放比例乘以要求的宽高nw = int(nh * new_ar) # 保持原始宽高比例# 缩放图像frame = cv2.resize(frame, (nw,nh))# 调整中心点坐标cx = cx * nw/iw cy = cy * nh/ih # 调整检测框的宽高bw = (box[0,:,2] - box[0,:,0]) * nw/iw # 修改后的检测框的宽高bh = (box[0,:,3] - box[0,:,1]) * nh/ih# 创建一块[416,416]的底版new_frame = np.zeros((h,w,3), np.uint8)# 确定每张图的位置if index==0: new_frame[0:nh, 0:nw] = frame # 第一张位于左上方elif index==1: new_frame[0:nh, w-nw:w] = frame # 第二张位于右上方elif index==2: new_frame[h-nh:h, 0:nw] = frame # 第三张位于左下方elif index==3: new_frame[h-nh:h, w-nw:w] = frame # 第四张位于右下方# 修正每个检测框的位置if index==0: # 左上图像box[0,:,0] = cx - bw // 2 # x1box[0,:,1] = cy - bh // 2 # y1box[0,:,2] = cx + bw // 2 # x2box[0,:,3] = cy + bh // 2 # y2 if index==1: # 右上图像box[0,:,0] = cx - bw // 2 + w - nw # x1box[0,:,1] = cy - bh // 2 # y1box[0,:,2] = cx + bw // 2 + w - nw # x2box[0,:,3] = cy + bh // 2 # y2if index==2: # 左下图像box[0,:,0] = cx - bw // 2 # x1box[0,:,1] = cy - bh // 2 + h - nh # y1box[0,:,2] = cx + bw // 2 # x2box[0,:,3] = cy + bh // 2 + h - nh # y2if index==3: # 右下图像box[0,:,2] = cx - bw // 2 + w - nw # x1box[0,:,3] = cy - bh // 2 + h - nh # y1box[0,:,0] = cx + bw // 2 + w - nw # x2box[0,:,1] = cy + bh // 2 + h - nh # y2index = index + 1 # 处理下一张# 保存处理后的图像及对应的检测框坐标image_datas.append(new_frame)box_datas.append(box)# 取出某张图片以及它对应的检测框信息, i代表图片索引for image, boxes in zip(image_datas, box_datas):# 复制一份原图image_copy = image.copy()# 遍历该张图像中的所有检测框for box in boxes[0]: # 获取某一个框的坐标x1, y1, x2, y2 = boxcv2.rectangle(image_copy, (x1,y1), (x2,y2), (0,255,0), 2)cv2.imshow('img', image_copy)cv2.waitKey(0)cv2.destroyAllWindows()#(2)将四张图像拼接在一起# 在指定范围中选择横纵向分割线cutx = np.random.randint(int(w*min_offset_x), int(w*(1-min_offset_x)))cuty = np.random.randint(int(h*min_offset_y), int(h*(1-min_offset_y))) # 创建一块[416,416]的底版用来组合四张图new_image = np.zeros((h,w,3), np.uint8)new_image[:cuty, :cutx, :] = image_datas[0][:cuty, :cutx, :]new_image[:cuty, cutx:, :] = image_datas[1][:cuty, cutx:, :]new_image[cuty:, :cutx, :] = image_datas[2][cuty:, :cutx, :]new_image[cuty:, cutx:, :] = image_datas[3][cuty:, cutx:, :]# 显示合并后的图像cv2.imshow('new_img', new_image)cv2.waitKey(0)cv2.destroyAllWindows()# 复制一份合并后的原图final_image_copy = new_image.copy()# 显示有检测框并合并后的图像for boxes in box_datas:# 遍历该张图像中的所有检测框for box in boxes[0]: # 获取某一个框的坐标x1, y1, x2, y2 = boxcv2.rectangle(final_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)cv2.imshow('new_img_bbox', final_image_copy)cv2.waitKey(0)cv2.destroyAllWindows()# 处理超出图像边缘的检测框new_boxes = merge_bboxes(box_datas, cutx, cuty)# 复制一份合并后的图像modify_image_copy = new_image.copy()# 绘制修正后的检测框for boxes in new_boxes: # 遍历每张图像中的所有检测框for box in boxes:# 获取某一个框的坐标x1, y1, x2, y2 = boxcv2.rectangle(modify_image_copy, (x1,y1), (x2,y2), (0,255,0), 2)cv2.imshow('new_img_bbox', modify_image_copy)cv2.waitKey(0)cv2.destroyAllWindows() # 主函数,获取图片路径和检测框路径
if __name__ == '__main__':# 给出图片文件夹和检测框文件夹所在的位置image_dir = 'D:/deeplearning/database/VOC2007/picture/'annotation_dir = 'D:/deeplearning/database/VOC2007/annotation/'image_list = [] # 存放每张图像和该图像对应的检测框坐标信息# 读取4张图像及其检测框信息for i in range(4):image_box = [] # 存放每张图片的检测框信息# 某张图片位置及其对应的检测框信息image_path = image_dir + str(i+1) + '.jpg'annotation_path = annotation_dir + str(i+1) + '.xml'image = cv2.imread(image_path) # 读取图像# 读取检测框信息with open(annotation_path, 'r') as new_f:# getroot()获取根节点root = ET.parse(annotation_path).getroot()# findall查询根节点下的所有直系子节点,find查询根节点下的第一个直系子节点for obj in root.findall('object'):obj_name = obj.find('name').text # 目标名称bndbox = obj.find('bndbox')left = eval(bndbox.find('xmin').text) # 左上坐标xtop = eval(bndbox.find('ymin').text) # 左上坐标yright = eval(bndbox.find('xmax').text) # 右下坐标xbottom = eval(bndbox.find('ymax').text) # 右下坐标y# 保存每张图片的检测框信息image_box.append([left, top, right, bottom]) # [[x1,y1,x2,y2],[..],[..]]# 保存图像及其对应的检测框信息image_list.append([image, image_box])# 缩放、拼接图片get_random_data(image_list, input_shape=[416,416])
最后一种通用代码
def load_mosaic(self, index):"""将四张图片拼接在一张马赛克图像中:param self::param index: 需要获取的图像索引:return:"""# loads images in a mosaiclabels4 = [] # 拼接图像的label信息s = self.img_size# 随机初始化拼接图像的中心点坐标xc, yc = [int(random.uniform(s * 0.5, s * 1.5)) for _ in range(2)] # mosaic center x, y# 从dataset中随机寻找三张图像进行拼接indices = [index] + [random.randint(0, len(self.labels) - 1) for _ in range(3)] # 3 additional image indices# 遍历四张图像进行拼接for i, index in enumerate(indices):# load imageimg, _, (h, w) = load_image(self, index)# place img in img4if i == 0: # top left# 创建马赛克图像img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)# 计算截取的图像区域信息(以xc,yc为第一张图像的右下角坐标填充到马赛克图像中,丢弃越界的区域)x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)elif i == 1: # top right# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc# 计算截取的图像区域信息(以xc,yc为第二张图像的左下角坐标填充到马赛克图像中,丢弃越界的区域)x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), helif i == 2: # bottom left# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)# 计算截取的图像区域信息(以xc,yc为第三张图像的右上角坐标填充到马赛克图像中,丢弃越界的区域)x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, max(xc, w), min(y2a - y1a, h)elif i == 3: # bottom right# 计算马赛克图像中的坐标信息(将图像填充到马赛克图像中)x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)# 计算截取的图像区域信息(以xc,yc为第四张图像的左上角坐标填充到马赛克图像中,丢弃越界的区域)x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)# 将截取的图像区域填充到马赛克图像的相应位置img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]# 计算pad(图像边界与马赛克边界的距离,越界的情况为负值)padw = x1a - x1bpadh = y1a - y1b# Labels 获取对应拼接图像的labels信息# [class_index, x_center, y_center, w, h]x = self.labels[index]labels = x.copy() # 深拷贝,防止修改原数据if x.size > 0: # Normalized xywh to pixel xyxy format# 计算标注数据在马赛克图像中的坐标(绝对坐标)labels[:, 1] = w * (x[:, 1] - x[:, 3] / 2) + padw # xminlabels[:, 2] = h * (x[:, 2] - x[:, 4] / 2) + padh # yminlabels[:, 3] = w * (x[:, 1] + x[:, 3] / 2) + padw # xmaxlabels[:, 4] = h * (x[:, 2] + x[:, 4] / 2) + padh # ymaxlabels4.append(labels)# Concat/clip labelsif len(labels4):labels4 = np.concatenate(labels4, 0)# 设置上下限防止越界np.clip(labels4[:, 1:], 0, 2 * s, out=labels4[:, 1:]) # use with random_affine# Augment# 随机旋转,缩放,平移以及错切img4, labels4 = random_affine(img4, labels4,degrees=self.hyp['degrees'],translate=self.hyp['translate'],scale=self.hyp['scale'],shear=self.hyp['shear'],border=-s // 2) # border to removereturn img4, labels4
def load_image(self, index):# loads 1 image from dataset, returns img, original hw, resized hwimg = self.imgs[index]if img is None: # not cachedpath = self.img_files[index]img = cv2.imread(path) # BGRassert img is not None, "Image Not Found " + pathh0, w0 = img.shape[:2] # orig hw# img_size 设置的是预处理后输出的图片尺寸r = self.img_size / max(h0, w0) # resize image to img_sizeif r != 1: # if sizes are not equalinterp = cv2.INTER_AREA if r < 1 and not self.augment else cv2.INTER_LINEARimg = cv2.resize(img, (int(w0 * r), int(h0 * r)), interpolation=interp)return img, (h0, w0), img.shape[:2] # img, hw_original, hw_resizedelse:return self.imgs[index], self.img_hw0[index], self.img_hw[index] # img, hw_original, hw_resized
def random_affine(img, targets=(), degrees=10, translate=.1, scale=.1, shear=10, border=0):"""随机旋转,缩放,平移以及错切"""# torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))# https://medium.com/uruvideo/dataset-augmentation-with-random-homographies-a8f4b44830d4# 这里可以参考我写的博文: https://blog.csdn.net/qq_37541097/article/details/119420860# targets = [cls, xyxy]# 最终输出的图像尺寸,等于img4.shape / 2height = img.shape[0] + border * 2width = img.shape[1] + border * 2# Rotation and Scale# 生成旋转以及缩放矩阵R = np.eye(3) # 生成对角阵a = random.uniform(-degrees, degrees) # 随机旋转角度s = random.uniform(1 - scale, 1 + scale) # 随机缩放因子R[:2] = cv2.getRotationMatrix2D(angle=a, center=(img.shape[1] / 2, img.shape[0] / 2), scale=s)# Translation# 生成平移矩阵T = np.eye(3)T[0, 2] = random.uniform(-translate, translate) * img.shape[0] + border # x translation (pixels)T[1, 2] = random.uniform(-translate, translate) * img.shape[1] + border # y translation (pixels)# Shear# 生成错切矩阵S = np.eye(3)S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)# Combined rotation matrixM = S @ T @ R # ORDER IS IMPORTANT HERE!!if (border != 0) or (M != np.eye(3)).any(): # image changed# 进行仿射变化img = cv2.warpAffine(img, M[:2], dsize=(width, height), flags=cv2.INTER_LINEAR, borderValue=(114, 114, 114))# Transform label coordinatesn = len(targets)if n:# warp pointsxy = np.ones((n * 4, 3))xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1# [4*n, 3] -> [n, 8]xy = (xy @ M.T)[:, :2].reshape(n, 8)# create new boxes# 对transform后的bbox进行修正(假设变换后的bbox变成了菱形,此时要修正成矩形)x = xy[:, [0, 2, 4, 6]] # [n, 4]y = xy[:, [1, 3, 5, 7]] # [n, 4]xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T # [n, 4]# reject warped points outside of image# 对坐标进行裁剪,防止越界xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)w = xy[:, 2] - xy[:, 0]h = xy[:, 3] - xy[:, 1]# 计算调整后的每个box的面积area = w * h# 计算调整前的每个box的面积area0 = (targets[:, 3] - targets[:, 1]) * (targets[:, 4] - targets[:, 2])# 计算每个box的比例ar = np.maximum(w / (h + 1e-16), h / (w + 1e-16)) # aspect ratio# 选取长宽大于4个像素,且调整前后面积比例大于0.2,且比例小于10的boxi = (w > 4) & (h > 4) & (area / (area0 * s + 1e-16) > 0.2) & (ar < 10)targets = targets[i]targets[:, 1:5] = xy[i]return img, targets
x2y1
# [4*n, 3] -> [n, 8]
xy = (xy @ M.T)[:, :2].reshape(n, 8)
# create new boxes# 对transform后的bbox进行修正(假设变换后的bbox变成了菱形,此时要修正成矩形)x = xy[:, [0, 2, 4, 6]] # [n, 4]y = xy[:, [1, 3, 5, 7]] # [n, 4]xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T # [n, 4]# reject warped points outside of image# 对坐标进行裁剪,防止越界xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)w = xy[:, 2] - xy[:, 0]h = xy[:, 3] - xy[:, 1]# 计算调整后的每个box的面积area = w * h# 计算调整前的每个box的面积area0 = (targets[:, 3] - targets[:, 1]) * (targets[:, 4] - targets[:, 2])# 计算每个box的比例ar = np.maximum(w / (h + 1e-16), h / (w + 1e-16)) # aspect ratio# 选取长宽大于4个像素,且调整前后面积比例大于0.2,且比例小于10的boxi = (w > 4) & (h > 4) & (area / (area0 * s + 1e-16) > 0.2) & (ar < 10)targets = targets[i]targets[:, 1:5] = xy[i]return img, targets
相关文章:
深度学习中小知识点系列(三) 解读Mosaic 数据增强
前言 Mosaic数据增强,这种数据增强方式简单来说就是把4张图片,通过随机缩放、随机裁减、随机排布的方式进行拼接。Mosaic有如下优点: (1)丰富数据集:随机使用4张图片,随机缩放,再随…...

telnet-MISC-bugku-解题步骤
——CTF解题专栏—— 题目信息: 题目:这是一张单纯的图片 作者:未知 提示:无 解题附件: 解题思路: (⊙﹏⊙)这是个什么文件pcap文件分析_pcap文件打开-CSDN博客查了一下,但没看懂,…...

大数据Doris(二十九):数据导入(Insert Into)
文章目录 数据导入(Insert Into) 一、创建导入...
jmeter测试dubbo接口
本文讲解jmeter测试dubbo接口的实现方式,文章以一个dubbo的接口为例子进行讲解,该dubbo接口实现的功能为: 一:首先我们看服务端代码 代码架构为: 1:新建一个maven工程,pom文件为: 1…...

分类预测 | Matlab实现基于DBN-SVM深度置信网络-支持向量机的数据分类预测
分类预测 | Matlab实现基于DBN-SVM深度置信网络-支持向量机的数据分类预测 目录 分类预测 | Matlab实现基于DBN-SVM深度置信网络-支持向量机的数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.利用DBN进行特征提取,将提取后的特征放入SVM进行分类…...
android系统新特性——用户界面以及系统界面改进
用户界面改进 Android用户界面改进最明显的就是MD了。MD是Google于2014年推出的设计语言,它是一套完整的设计系统,包含了动画、样式、布局、组件等一系列与设计有关的元素。通过对这些行为的描述,让开发者设计出更符合目标的软件,…...

电量计驱动代码
外部电量计驱动代码,直接上代码了,懒,不做细节分析。。。。。 /** Fuelgauge battery driver** This package is free software; you can redistribute it and/or modify* it under the terms of the GNU General Public License version 2 as* published by the Free Soft…...
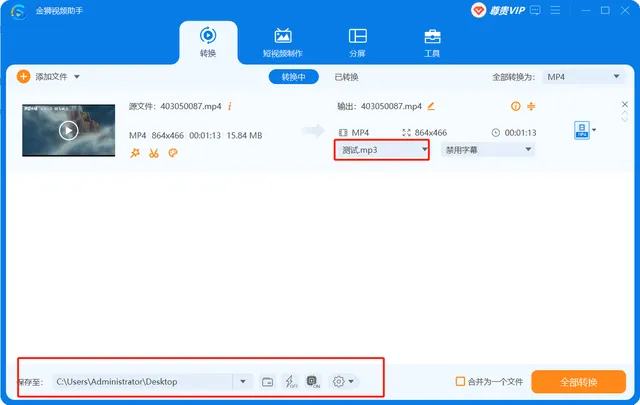
如何将音频添加到视频并替换视频中的音轨
随着视频流媒体网站的流行和便携式设备的发展,你可能越来越倾向于自己制作视频并在互联网上分享。有时,你可能还需要编辑视频并为其添加背景音乐,因为音乐总是对视频的感知起着神奇的作用。 那如何给视频添加音频呢?或者如何用新…...

Android 单元测试初体验
Android 单元测试初体验 前言一、单元测试是什么?二、简单使用1.依赖2.单元测试代码简单模版及解释 总结 前言 当初在学校学安卓的时候,老师敢教学进度,翻到单元测试这一章节的时候提了两句,没有把单元测试当重点讲,只…...

HarmonyOS—ArkTS中@Observed和@ObjectLink装饰器的嵌套类对象属性变化【鸿蒙应用开发】
文章目录 ARKTS中@Observed和@ObjectLink装饰器的嵌套类对象属性变化@Observed 类装饰器说明装饰器参数类装饰器的使用@ObjectLink 变量装饰器说明装饰器参数同步类型允许装饰的变量类型被装饰变量的初始值举例装饰器的限制条件观察变化和行为表现观察的变化框架行为使用场景1.…...

设计问卷调查问题的技巧二:确定问题的结构与顺序
上篇文章中,我们了解到设计问卷调查问卷的技巧有保持问题中立、少用开放式问题、保持全名平衡的答案集、谨慎设置单一回答。在这篇文章中,我们将继续深入探讨设计问卷调查问题的剩余5大技巧! Tip5:注意问题的顺序 虽然您可以任意…...
kubernetes使用nfs创建pvc部署mysql stateful的方法
kubernetes创建的pod默认都是无状态的,换句话说删除以后不会保留任何数据。 所以对于mysql这种有状态的应用,必须使用持久化存储作为支撑,才能部署成有状态的stateful. 最简单的方法就是使用nfs作为网络存储,因为nfs存储很容易被…...
JavaScript WebApi(二) 详解
监听事件 介绍 事件监听是一种用于在特定条件下执行代码的编程技术。在Web开发中,事件监听器可以用于捕获和响应用户与页面交互的各种操作,如点击、滚动、输入等。 事件监听的基本原理是,通过在特定元素上注册事件监听器,当事件…...
纯新手发布鸿蒙的第一个java应用
第一个java开发鸿蒙应用 1.下载和安装华为自己的app开发软件DevEco Studio HUAWEI DevEco Studio和SDK下载和升级 | HarmonyOS开发者 2.打开IDE新建工程(当前用的IDEA 3.1.1 Release) 选择第一个,其他的默认只能用(API9)版本,…...

UI自动化(selenium+python)之元素定位的三种等待方式!
前言 在UI自动化过程中,常遇到元素未找到,代码报错的情况。这种情况下,需要用等待wait。 在selenium中可以用到三种等待方式即sleep,implicitly_wait,WebDriverWait 一、固定等待(sleep) 导入time模块,设定固定的等待时间 缺…...

[C++]指针与结构体
标题 一.指针1.指针的定义和使用2.指针所占的内存空间3.空指针与野指针4.const修饰指针5.指针和数组6.指针和函数 二.结构体1.结构体的定义与使用2.结构体数组3.结构体指针4.结构体的嵌套使用5.结构体做函数参数6.结构体中const使用场景7.案例练习 一.指针 作用: 可以通过指针…...

注解原理是什么 Spring MVC常用的注解有哪些?
文章目录 注解原理是什么Spring MVC常用的注解有哪些? 通过这篇文章来和大家一起认识springMVC常用的注解,那么首先需要来了解注解。 注解原理是什么 注解本质是一个继承了Annotation的特殊接口,其具体实现类是Java运行时生成的动态代理类。…...
【数据结构】树与二叉树(廿五):树搜索指定数据域的结点(算法FindTarget)
文章目录 5.3.1 树的存储结构5. 左儿子右兄弟链接结构 5.3.2 获取结点的算法1. 获取大儿子、大兄弟结点2. 搜索给定结点的父亲3. 搜索指定数据域的结点a. 算法FindTargetb. 算法解析c. 代码实现a. 使用指向指针的指针b. 直接返回找到的节点 4. 代码整合 5.3.1 树的存储结构 5.…...

深度学习图像风格迁移 - opencv python 计算机竞赛
文章目录 0 前言1 VGG网络2 风格迁移3 内容损失4 风格损失5 主代码实现6 迁移模型实现7 效果展示8 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习图像风格迁移 - opencv python 该项目较为新颖,适合作为竞赛课题…...

提高SQL语句执行效率的8个方法
提高SQL语句执行效率的8个方法 在日常的数据库操作中,如何提高SQL语句的执行效率是每个程序员都需要关注的问题,SQL语句的执行效率对系统的性能有着重要影响,本文将介绍8种提高SQL语句执行效率的方法。 合理使用索引 索引介绍 索引是数据…...
)
【量子计算C++实战指南】:20年专家亲授,从零搭建Shor算法仿真器(含完整可运行代码)
第一章:量子计算与C编程的融合基础量子计算正从理论走向工程实践,而C凭借其零开销抽象、内存可控性与高性能特性,成为量子软件栈底层实现的关键语言。现代量子开发框架(如QPP、Q、XACC)普遍提供C原生API,使…...

如何针对不同行业制定SEO策略方案
如何针对不同行业制定SEO策略方案 在当今数字化时代,搜索引擎优化(SEO)已经成为每个企业线上推广的核心策略之一。不同行业的SEO策略并非一成不变。制定有效的SEO方案,需要对各个行业的特点、用户行为以及竞争态势有深刻的理解。…...

GEO监测是什么?2026年品牌主必须了解的AI可见度追踪工具
一、从一个真实场景说起 2026年,某消费品品牌的市场总监做了一个测试。 她打开DeepSeek,输入:"XX行业哪些品牌比较值得信赖?" AI给出了五个品牌,她们公司不在其中。 她换了一个问法,再问一次…...

网站优化过程中如何防范黑帽SEO行为
网站优化过程中如何防范黑帽SEO行为 在数字营销和网站优化领域,搜索引擎优化(SEO)是一个至关重要的环节。为了迅速提升网站排名,有些人可能会尝试使用“黑帽SEO”手段。这种行为不仅违反了搜索引擎的规则,还可能导致网…...

盘姬工具箱实用工具推荐:从文件恢复到批量重命名
在盘姬工具箱的众多功能中,有一些工具特别值得推荐。 这些工具都能切实解决用户在日常使用电脑过程中遇到的各种问题。 而且这些工具的操作都非常简单直观,不需要用户具备专业的技术知识。 无论是电脑新手还是资深用户,都能通过这些工具获…...

【Educoder实战】Python模拟冯·诺依曼机TOY2指令集全解析
1. 从零理解冯诺依曼机与TOY2模拟器 第一次接触"冯诺依曼体系结构"这个概念时,我盯着课本上的框图看了半小时还是一头雾水。直到用Python亲手实现了TOY2模拟器,才真正理解这个计算机鼻祖设计的精妙之处。简单来说,冯诺依曼机就像个…...

BLDC电机控制原理与PWM技术详解
1. BLDC电机控制基础解析无刷直流电机(BLDC)作为现代电机控制领域的重要成员,其控制原理与传统有刷电机存在本质差异。BLDC电机通过电子换向取代机械换向,这种设计带来了更高的效率和可靠性,但同时也增加了控制复杂度。…...

API调用成本优化实战:Token中转站的原理与选型建议
前言作为AI应用开发者,过去几个月我一直被一个问题困扰——API账单太贵了。特别是 Claude 3.5 Sonnet、GPT-4o 这类顶级模型,性能确实强,但价格也着实肉疼。随便跑几个测试,几十美元就没了;如果上线正式应用࿰…...

2025届学术党必备的六大降重复率助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 提高人工智能生成内容即AIGC的检测难度,关键之处在于增强文本的自然特性与个性化…...
研究)
石油干线管道关键参数稳定自动控制系统(CAP)研究
石油干线管道关键参数稳定自动控制系统(CAP)研究 摘要 石油干线管道是国家能源输送的重要基础设施,其运行过程中的压力、流量等关键参数的稳定控制直接关系到管道的安全性与经济性。本文针对石油干线管道参数控制的非线性、大滞后、强耦合等特点,设计并实现了一套关键参数…...