深度学习图像风格迁移 - opencv python 计算机竞赛
文章目录
- 0 前言
- 1 VGG网络
- 2 风格迁移
- 3 内容损失
- 4 风格损失
- 5 主代码实现
- 6 迁移模型实现
- 7 效果展示
- 8 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学习图像风格迁移 - opencv python
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
图片风格迁移指的是将一个图片的风格转换到另一个图片中,如图所示:

原图片经过一系列的特征变换,具有了新的纹理特征,这就叫做风格迁移。
1 VGG网络
在实现风格迁移之前,需要先简单了解一下VGG网络(由于VGG网络不断使用卷积提取特征的网络结构和准确的图像识别效率,在这里我们使用VGG网络来进行图像的风格迁移)。
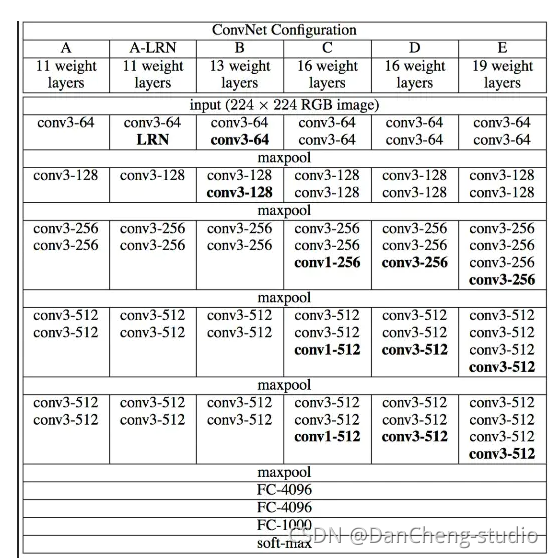
如上图所示,从A-
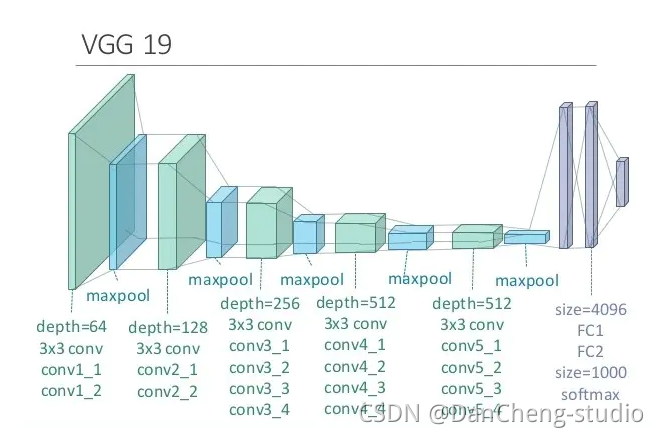
E的每一列都表示了VGG网络的结构原理,其分别为:VGG-11,VGG-13,VGG-16,VGG-19,如下图,一副图片经过VGG-19网络结构可以最后得到一个分类结构。
2 风格迁移
对一副图像进行风格迁移,需要清楚的有两点。
- 生成的图像需要具有原图片的内容特征
- 生成的图像需要具有风格图片的纹理特征
根据这两点,可以确定,要想实现风格迁移,需要有两个loss值:
一个是生成图片的内容特征与原图的内容特征的loss,另一个是生成图片的纹理特征与风格图片的纹理特征的loss。
而对一张图片进行不同的特征(内容特征和纹理特征)提取,只需要使用不同的卷积结构进行训练即可以得到。这时我们需要用到两个神经网络。
再回到VGG网络上,VGG网络不断使用卷积层来提取特征,利用特征将物品进行分类,所以该网络中提取内容和纹理特征的参数都可以进行迁移使用。故需要将生成的图片经过VGG网络的特征提取,再分别针对内容和纹理进行特征的loss计算。
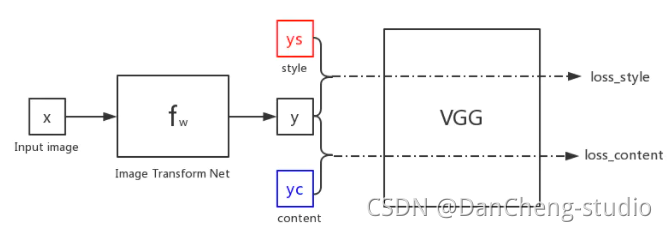
如图,假设初始化图像x(Input image)是一张随机图片,我们经过fw(image Transform Net)网络进行生成,生成图片y。
此时y需要和风格图片ys进行特征的计算得到一个loss_style,与内容图片yc进行特征的计算得到一个loss_content,假设loss=loss_style+loss_content,便可以对fw的网络参数进行训练。
现在就可以看网上很常见的一张图片了:
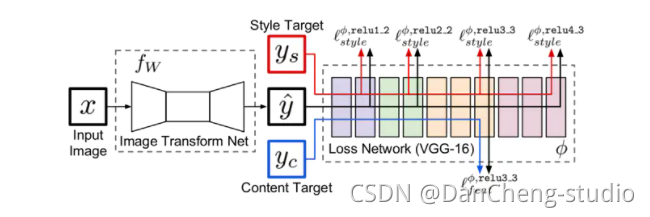
相较于我画的第一张图,这即对VGG内的loss求值过程进行了细化。
细化的结果可以分为两个方面:
- (1)内容损失
- (2)风格损失
3 内容损失
由于上图中使用的模型是VGG-16,那么即相当于在VGG-16的relu3-3处,对两张图片求得的特征进行计算求损失,计算的函数如下:
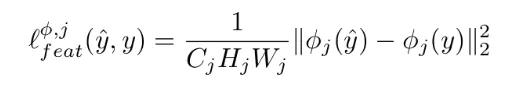
简言之,假设yc求得的特征矩阵是φ(y),生成图片求得的特征矩阵为φ(y^),且c=φ.channel,w=φ.weight,h=φ.height,则有:
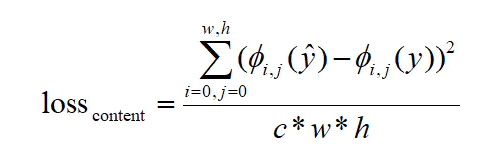
代码实现:
def content_loss(content_img, rand_img):content_layers = [('relu3_3', 1.0)]content_loss = 0.0# 逐个取出衡量内容损失的vgg层名称及对应权重for layer_name, weight in content_layers:# 计算特征矩阵p = get_vgg(content_img, layer_name)x = get_vgg(rand_img, layer_name)# 长x宽xchannelM = p.shape[1] * p.shape[2] * p.shape[3]# 根据公式计算损失,并进行累加content_loss += (1.0 / M) * tf.reduce_sum(tf.pow(p - x, 2)) * weight# 将损失对层数取平均content_loss /= len(content_layers)return content_loss
4 风格损失
风格损失由多个特征一同计算,首先需要计算Gram Matrix
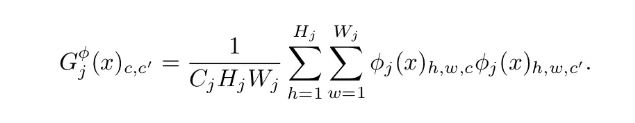
Gram Matrix实际上可看做是feature之间的偏心协方差矩阵(即没有减去均值的协方差矩阵),在feature
map中,每一个数字都来自于一个特定滤波器在特定位置的卷积,因此每个数字就代表一个特征的强度,而Gram计算的实际上是两两特征之间的相关性,哪两个特征是同时出现的,哪两个是此消彼长的等等,同时,Gram的对角线元素,还体现了每个特征在图像中出现的量,因此,Gram有助于把握整个图像的大体风格。有了表示风格的Gram
Matrix,要度量两个图像风格的差异,只需比较他们Gram Matrix的差异即可。 故在计算损失的时候函数如下:
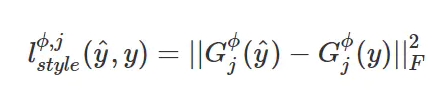
在实际使用时,该loss的层级一般选择由低到高的多个层,比如VGG16中的第2、4、7、10个卷积层,然后将每一层的style loss相加。
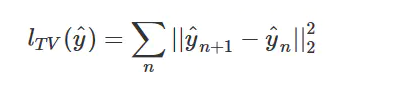
第三个部分不是必须的,被称为Total Variation
Loss。实际上是一个平滑项(一个正则化项),目的是使生成的图像在局部上尽可能平滑,而它的定义和马尔科夫随机场(MRF)中使用的平滑项非常相似。
其中yn+1是yn的相邻像素。
代码实现以上函数:
# 求gamm矩阵
def gram(x, size, deep):x = tf.reshape(x, (size, deep))g = tf.matmul(tf.transpose(x), x)return gdef style_loss(style_img, rand_img):style_layers = [('relu1_2', 0.25), ('relu2_2', 0.25), ('relu3_3', 0.25), ('reluv4_3', 0.25)]style_loss = 0.0# 逐个取出衡量风格损失的vgg层名称及对应权重for layer_name, weight in style_layers:# 计算特征矩阵a = get_vgg(style_img, layer_name)x = get_vgg(rand_img, layer_name)# 长x宽M = a.shape[1] * a.shape[2]N = a.shape[3]# 计算gram矩阵A = gram(a, M, N)G = gram(x, M, N)# 根据公式计算损失,并进行累加style_loss += (1.0 / (4 * M * M * N * N)) * tf.reduce_sum(tf.pow(G - A, 2)) * weight# 将损失对层数取平均style_loss /= len(style_layers)return style_loss
5 主代码实现
代码实现主要分为4步:
-
1、随机生成图片
-
2、读取内容和风格图片
-
3、计算总的loss
-
4、训练修改生成图片的参数,使得loss最小
* def main():# 生成图片rand_img = tf.Variable(random_img(WIGHT, HEIGHT), dtype=tf.float32)with tf.Session() as sess:content_img = cv2.imread('content.jpg')style_img = cv2.imread('style.jpg')# 计算loss值cost = ALPHA * content_loss(content_img, rand_img) + BETA * style_loss(style_img, rand_img)optimizer = tf.train.AdamOptimizer(LEARNING_RATE).minimize(cost)sess.run(tf.global_variables_initializer())for step in range(TRAIN_STEPS):# 训练sess.run([optimizer, rand_img])if step % 50 == 0:img = sess.run(rand_img)img = np.clip(img, 0, 255).astype(np.uint8)name = OUTPUT_IMAGE + "//" + str(step) + ".jpg"cv2.imwrite(name, img)6 迁移模型实现
由于在进行loss值求解时,需要在多个网络层求得特征值,并根据特征值进行带权求和,所以需要根据已有的VGG网络,取其参数,重新建立VGG网络。
注意:在这里使用到的是VGG-19网络:
在重建的之前,首先应该下载Google已经训练好的VGG-19网络,以便提取出已经训练好的参数,在重建的VGG-19网络中重新利用。

下载得到.mat文件以后,便可以进行网络重建了。已知VGG-19网络的网络结构如上述图1中的E网络,则可以根据E网络的结构对网络重建,VGG-19网络:

进行重建即根据VGG-19模型的结构重新创建一个结构相同的神经网络,提取出已经训练好的参数作为新的网络的参数,设置为不可改变的常量即可。
def vgg19():layers=('conv1_1','relu1_1','conv1_2','relu1_2','pool1','conv2_1','relu2_1','conv2_2','relu2_2','pool2','conv3_1','relu3_1','conv3_2','relu3_2','conv3_3','relu3_3','conv3_4','relu3_4','pool3','conv4_1','relu4_1','conv4_2','relu4_2','conv4_3','relu4_3','conv4_4','relu4_4','pool4','conv5_1','relu5_1','conv5_2','relu5_2','conv5_3','relu5_3','conv5_4','relu5_4','pool5')vgg = scipy.io.loadmat('D://python//imagenet-vgg-verydeep-19.mat')weights = vgg['layers'][0]network={}net = tf.Variable(np.zeros([1, 300, 450, 3]), dtype=tf.float32)network['input'] = netfor i,name in enumerate(layers):layer_type=name[:4]if layer_type=='conv':kernels = weights[i][0][0][0][0][0]bias = weights[i][0][0][0][0][1]conv=tf.nn.conv2d(net,tf.constant(kernels),strides=(1,1,1,1),padding='SAME',name=name)net=tf.nn.relu(conv + bias)elif layer_type=='pool':net=tf.nn.max_pool(net,ksize=(1,2,2,1),strides=(1,2,2,1),padding='SAME')network[name]=netreturn network
由于计算风格特征和内容特征时数据都不会改变,所以为了节省训练时间,在训练之前先计算出特征结果(该函数封装在以下代码get_neck()函数中)。
总的代码如下:
import tensorflow as tfimport numpy as npimport scipy.ioimport cv2import scipy.miscHEIGHT = 300WIGHT = 450LEARNING_RATE = 1.0NOISE = 0.5ALPHA = 1BETA = 500TRAIN_STEPS = 200OUTPUT_IMAGE = "D://python//img"STYLE_LAUERS = [('conv1_1', 0.2), ('conv2_1', 0.2), ('conv3_1', 0.2), ('conv4_1', 0.2), ('conv5_1', 0.2)]CONTENT_LAYERS = [('conv4_2', 0.5), ('conv5_2',0.5)]def vgg19():layers=('conv1_1','relu1_1','conv1_2','relu1_2','pool1','conv2_1','relu2_1','conv2_2','relu2_2','pool2','conv3_1','relu3_1','conv3_2','relu3_2','conv3_3','relu3_3','conv3_4','relu3_4','pool3','conv4_1','relu4_1','conv4_2','relu4_2','conv4_3','relu4_3','conv4_4','relu4_4','pool4','conv5_1','relu5_1','conv5_2','relu5_2','conv5_3','relu5_3','conv5_4','relu5_4','pool5')vgg = scipy.io.loadmat('D://python//imagenet-vgg-verydeep-19.mat')weights = vgg['layers'][0]network={}net = tf.Variable(np.zeros([1, 300, 450, 3]), dtype=tf.float32)network['input'] = netfor i,name in enumerate(layers):layer_type=name[:4]if layer_type=='conv':kernels = weights[i][0][0][0][0][0]bias = weights[i][0][0][0][0][1]conv=tf.nn.conv2d(net,tf.constant(kernels),strides=(1,1,1,1),padding='SAME',name=name)net=tf.nn.relu(conv + bias)elif layer_type=='pool':net=tf.nn.max_pool(net,ksize=(1,2,2,1),strides=(1,2,2,1),padding='SAME')network[name]=netreturn network# 求gamm矩阵def gram(x, size, deep):x = tf.reshape(x, (size, deep))g = tf.matmul(tf.transpose(x), x)return gdef style_loss(sess, style_neck, model):style_loss = 0.0for layer_name, weight in STYLE_LAUERS:# 计算特征矩阵a = style_neck[layer_name]x = model[layer_name]# 长x宽M = a.shape[1] * a.shape[2]N = a.shape[3]# 计算gram矩阵A = gram(a, M, N)G = gram(x, M, N)# 根据公式计算损失,并进行累加style_loss += (1.0 / (4 * M * M * N * N)) * tf.reduce_sum(tf.pow(G - A, 2)) * weight# 将损失对层数取平均style_loss /= len(STYLE_LAUERS)return style_lossdef content_loss(sess, content_neck, model):content_loss = 0.0# 逐个取出衡量内容损失的vgg层名称及对应权重for layer_name, weight in CONTENT_LAYERS:# 计算特征矩阵p = content_neck[layer_name]x = model[layer_name]# 长x宽xchannelM = p.shape[1] * p.shape[2]N = p.shape[3]lss = 1.0 / (M * N)content_loss += lss * tf.reduce_sum(tf.pow(p - x, 2)) * weight# 根据公式计算损失,并进行累加# 将损失对层数取平均content_loss /= len(CONTENT_LAYERS)return content_lossdef random_img(height, weight, content_img):noise_image = np.random.uniform(-20, 20, [1, height, weight, 3])random_img = noise_image * NOISE + content_img * (1 - NOISE)return random_imgdef get_neck(sess, model, content_img, style_img):sess.run(tf.assign(model['input'], content_img))content_neck = {}for layer_name, weight in CONTENT_LAYERS:# 计算特征矩阵p = sess.run(model[layer_name])content_neck[layer_name] = psess.run(tf.assign(model['input'], style_img))style_content = {}for layer_name, weight in STYLE_LAUERS:# 计算特征矩阵a = sess.run(model[layer_name])style_content[layer_name] = areturn content_neck, style_contentdef main():model = vgg19()content_img = cv2.imread('D://a//content1.jpg')content_img = cv2.resize(content_img, (450, 300))content_img = np.reshape(content_img, (1, 300, 450, 3)) - [128.0, 128.2, 128.0]style_img = cv2.imread('D://a//style1.jpg')style_img = cv2.resize(style_img, (450, 300))style_img = np.reshape(style_img, (1, 300, 450, 3)) - [128.0, 128.2, 128.0]# 生成图片rand_img = random_img(HEIGHT, WIGHT, content_img)with tf.Session() as sess:# 计算loss值content_neck, style_neck = get_neck(sess, model, content_img, style_img)cost = ALPHA * content_loss(sess, content_neck, model) + BETA * style_loss(sess, style_neck, model)optimizer = tf.train.AdamOptimizer(LEARNING_RATE).minimize(cost)sess.run(tf.global_variables_initializer())sess.run(tf.assign(model['input'], rand_img))for step in range(TRAIN_STEPS):print(step)# 训练sess.run(optimizer)if step % 10 == 0:img = sess.run(model['input'])img += [128, 128, 128]img = np.clip(img, 0, 255).astype(np.uint8)name = OUTPUT_IMAGE + "//" + str(step) + ".jpg"img = img[0]cv2.imwrite(name, img)img = sess.run(model['input'])img += [128, 128, 128]img = np.clip(img, 0, 255).astype(np.uint8)cv2.imwrite("D://end.jpg", img[0])main()7 效果展示

8 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
深度学习图像风格迁移 - opencv python 计算机竞赛
文章目录 0 前言1 VGG网络2 风格迁移3 内容损失4 风格损失5 主代码实现6 迁移模型实现7 效果展示8 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习图像风格迁移 - opencv python 该项目较为新颖,适合作为竞赛课题…...

提高SQL语句执行效率的8个方法
提高SQL语句执行效率的8个方法 在日常的数据库操作中,如何提高SQL语句的执行效率是每个程序员都需要关注的问题,SQL语句的执行效率对系统的性能有着重要影响,本文将介绍8种提高SQL语句执行效率的方法。 合理使用索引 索引介绍 索引是数据…...

C语言,通过数组实现循环队列
实现循环队列最难的地方就在于如何判空和判满,只要解决了这两点循环队列的设计就没有问题。接下来我们将会使用数组来实现循环队列。 接下来,为了模拟实现一个容量为4的循环队列,我们创建一个容量为4 1 的数组。 接下来我们将会对这个数组…...
python+pygame+opencv+gpt实现虚拟数字人直播(一)
AI技术突飞猛进,不断的改变着人们的工作和生活。数字人直播作为新兴形式,必将成为未来趋势,具有巨大的、广阔的、惊人的市场前景。它将不断融合创新技术和跨界合作,提供更具个性化和多样化的互动体验,成为未来的一种趋…...
c语言:模拟实现各种字符串函数(2)
strncpy函数: 功能:拷贝指定长度的字符串a到字符串b中 代码模拟实现: //strncpy char* my_strncpy(char* dest, char* str,size_t num) {char* ret dest;assert(dest && str);//断言,如果其中有一个为空指针ÿ…...

【Proteus仿真】【STM32单片机】感应水龙头设计
文章目录 一、功能简介二、软件设计三、实验现象联系作者 一、功能简介 本项目使用Proteus8仿真STM32单片机控制器,使用LCD1602液晶模块、HCSR04超声波等。 主要功能: 系统运行后,LCD1602显示超声波模块检测的距离,若检测距离小…...
P15 C++ 枚举
The ChenPi 前言 今天我们要讲的是 C 中的枚举。 enum 是 enumeration 的缩写,基本上可以说,它就是一个数值集合。如果你想要给枚举一个更实际的定义,它们是给一个值命名的一种方法。 所以我们不用一堆叫做 A、B、C 的整数。我们可以有一个…...
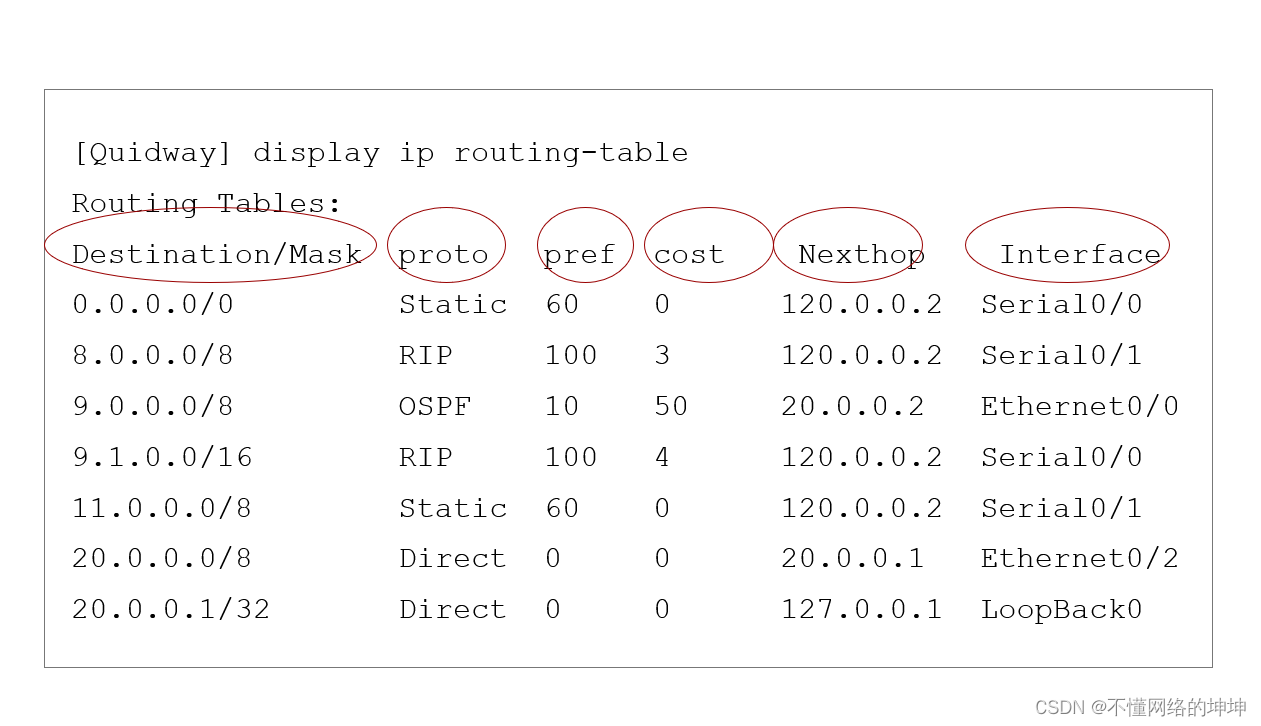
深入理解路由协议:从概念到实践
路由技术是Internet得以持续运转的关键所在,路由是极其有趣而又复杂的课题,永远的话题。 SO:这是一个解析路由协议的基础文章。 目录 前言路由的概念路由协议的分类数据包在网络中的路由过程理解路由表的结构路由器关键功能解析 前言 在互联…...

Qt 串口编程-从入门到实战
1. Qt 串口通信流程解析 1.1 串行通信和并行通信对比 并行通信适合距离较短的通信,且信号容易受干扰,成本高串口通讯-设备(蓝牙, wifi, gprs, gps) 1.2 Qt 串口通信具体流程 1. 创建 QSerial…...

如何获得微软MVP徽章
要成为微软MVP,需要在特定领域成为专家,并积极参与社区,为其他人提供帮助和支持。以下是一些步骤可以帮助你成为MVP: 在特定领域成为专家:要成为MVP,需要在某个领域具有专业知识和经验。这可以通过阅读相关…...

Java架构师软件架构开发
目录 1 基于架构的软件开发导论2 ABSD架构方法论3 ABSD方法论具体实现4 ABSD金融业案例5 基于特定领域的软件架构开发导论6 DSSA领域分析7 DSSA领域设计和实现8 DSSA国际电商平台架构案例9 架构思维方法论概述10 AT方法论和案例想学习架构师构建流程请跳转:Java架构师系统架构…...

西南科技大学数字电子技术实验一(数字信号基本参数与逻辑门电路功能测试及FPGA 实现 )预习报告
手写报告稍微认真点写,80+随便有 目录 一、计算/设计过程 1、通过虚拟示波器观察和测量信号 2、通过实际电路(电阻、开关、发光二极管)模拟逻辑门电路 二、画出并填写实验指导书上的预表...

Java八股文面试全套真题【含答案】- SpringMVC篇
以下是一些关于Spring MVC语言的经典面试题以及它们的答案: 什么是Spring MVC框架?它的特点是什么? Spring MVC是基于Java的一种Web应用框架,用于开发基于MVC(模型-视图-控制器)模式的Web应用程序。它的特…...

Spring第二课响应的完全,如何理解前后端互联
目录 一、响应 Control,RestController 1.Controller的源码,代表什么意思 2.返回数据 Responsebody 3.返回HTML片段 4.返回JSON 5.那么假如我们使用集合会怎么样呢 设置状态码,虽然不影响展示,但是确实显示起来也就是401的情况。 2.我…...

html实现各种瀑布流(附源码)
文章目录 1.设计来源1.1 动态响应瀑布流1.2 分页瀑布流1.3 响应瀑布流 2.效果和源码2.1 动态效果2.2 源代码 源码下载 作者:xcLeigh 文章地址:https://blog.csdn.net/weixin_43151418/article/details/134613121 html实现各种瀑布流(附源码),…...
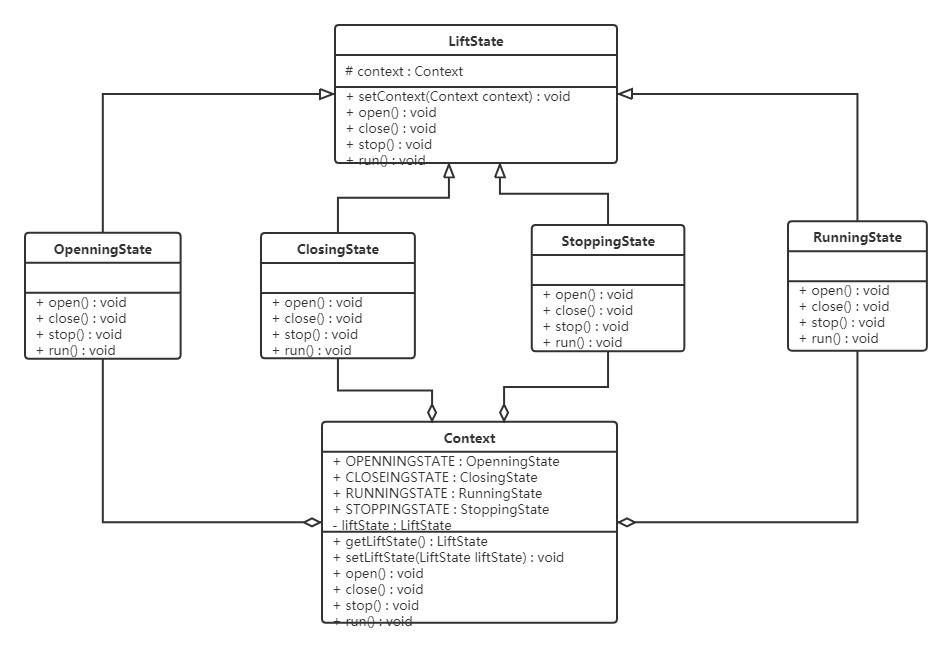
万字解析设计模式之责任链模式、状态模式
目录 一、责任链模式 1.1概述 1.2结构 1.3实现 1.4 优缺点 1.5应用场景 1.6源码解析 二、状态模式 2.1概述 2.2结构 2.3实现 2.4优缺点 2.5应用场景 三、责任链模式实验 任务描述 实现方式 编程要求 测试说明 四、状态模式实验 任务描述 实现方式 编程要…...

二十三种设计模式全面解析-深入探讨状态模式的高级应用技术:释放对象行为的无限可能
在软件开发中,状态管理是一个常见的挑战。当对象的行为随着内部状态的变化而变化时,有效地管理对象的状态和相应的行为变得至关重要。在这方面,状态模式提供了一种优雅而灵活的解决方案。它允许对象在运行时根据内部状态的改变而改变其行为&a…...
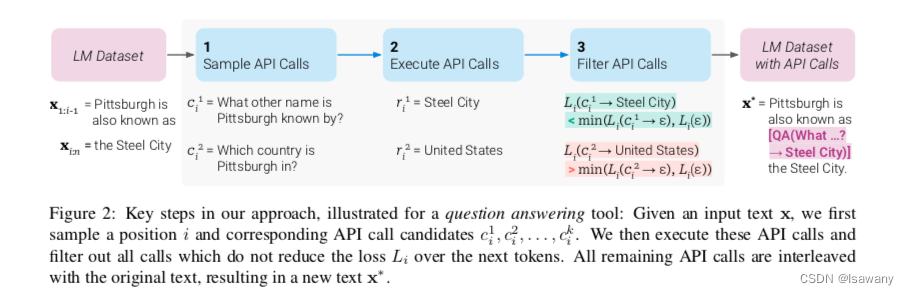
论文笔记--Toolformer: Language Models Can Teach Themselves to Use Tools
论文笔记--Toolformer: Language Models Can Teach Themselves to Use Tools 1. 文章简介2. 文章概括3 文章重点技术3.1 Toolformer3.2 APIs 4. 文章亮点5. 原文传送门 1. 文章简介 标题:Toolformer: Language Models Can Teach Themselves to Use Tools作者&#…...
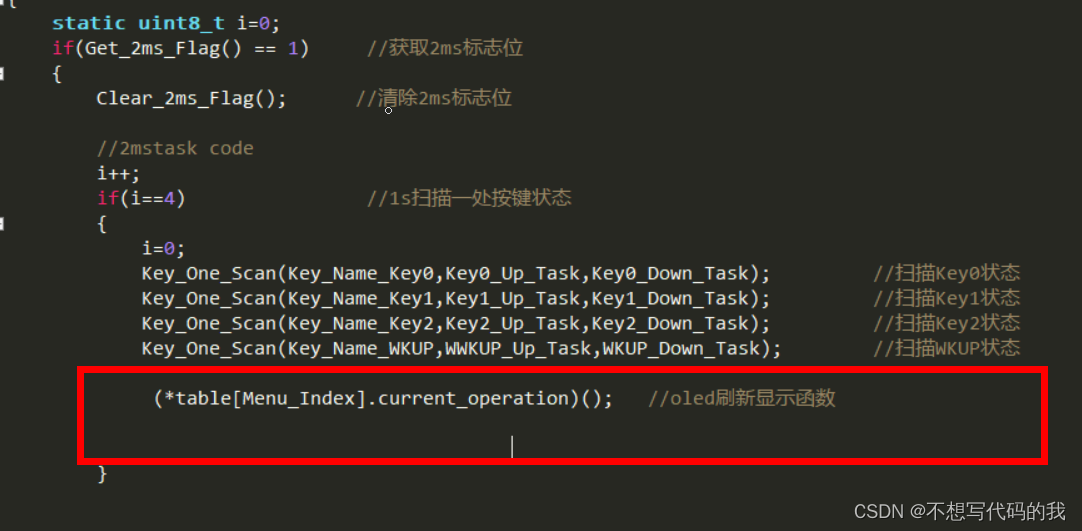
stm32实现0.96oled图片显示,菜单功能
stm32实现0.96oled图片显示,菜单功能 功能展示简介代码介绍oled.coled.holedfont.h(字库文件)main函数 代码思路讲解 本期内容,我们将学习0.96寸oled的进阶使用,展示图片,实现菜单切换等功能,关…...

sqlite外键约束 保证数据一致性
1. 外键约束 在SQLite中,可以通过使用外键(Foreign Key)约束和CASCADE选项来实现通过外键删除相关信息。 CASCADE选项是指在主键表中删除记录时,相应的外键表中的相关记录也将被自动删除。 -- 创建主键表 CREATE TABLE Persons…...

OurStreets项目动画架构解析:animation-samples中的地图动画最佳实践
OurStreets项目动画架构解析:animation-samples中的地图动画最佳实践 【免费下载链接】animation-samples Multiple samples showing the best practices in animation on Android. 项目地址: https://gitcode.com/gh_mirrors/an/animation-samples 想要在An…...

BalenaEtcher在Arch Linux上的零失败部署方案:3大场景化解决方案
BalenaEtcher在Arch Linux上的零失败部署方案:3大场景化解决方案 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher BalenaEtcher是一款开源的镜像烧录工…...

QWEN-AUDIO企业实操:金融产品语音说明书自动化生成
QWEN-AUDIO企业实操:金融产品语音说明书自动化生成 你有没有想过,金融产品那些复杂的说明书,如果能用语音讲给客户听,该有多好?客户不用再费力阅读密密麻麻的条款,开车、做家务时就能轻松了解产品。但问题…...

OpenClaw异常处理设计:Qwen3.5-9B图片任务失败自动恢复方案
OpenClaw异常处理设计:Qwen3.5-9B图片任务失败自动恢复方案 1. 为什么需要异常处理机制? 上周我尝试用OpenClawQwen3.5-9B实现证件照自动裁剪时,遇到了典型的"三连击"问题:网络波动导致图片上传中断、模型响应超时、输…...

别再死记硬背UART帧格式了!用Arduino UNO和逻辑分析仪,5分钟带你‘看见’数据流
别再死记硬背UART帧格式了!用Arduino UNO和逻辑分析仪,5分钟带你‘看见’数据流 记得第一次接触UART通信时,对着教科书上的帧格式图发呆了半小时——起始位、数据位、校验位、停止位,这些概念就像天书一样。直到有一天,…...

都是微软亲儿子,WPF凭啥干不掉WinForm?这3个场景说明白了
大家好,我是码农刚子。 前两天有个刚入行的兄弟问我:“现在学桌面开发,是学WinForm还是WPF?我看网上也有人问都是基于.NET平台,WPF能取代Winform吗?” 我听完笑了笑。这个问题吧,就跟“C#能不能取代Java”一…...

恩雅吉他琴颈变形维修保养指南,正规维修机构实力评测
琴颈是吉他手感的 “灵魂”,恩雅吉他的琴颈采用了专属的 BT 接柄技术,搭配碳纤维加固钢筋,在出厂时就调试到了最佳的演奏状态。但日常存放中,温湿度剧变、长期不规范上弦、意外磕碰,都很容易导致琴颈变形,出…...

内存泄漏的定位技巧:以Java应用为例
在复杂的软件系统中,内存泄漏犹如一颗隐形的定时炸弹,其破坏力随着系统运行时间的增长而累积。对于软件测试从业者而言,掌握高效、精准的内存泄漏定位技巧,不仅是保障系统稳定性的关键,更是提升测试深度与专业性的重要…...
)
C++27异常处理增强配置(ISO/IEC 14882:2027草案第12.8节深度解密)
第一章:C27异常处理增强配置的标准化演进脉络C27标准委员会在异常处理机制上引入了关键性配置抽象,旨在统一跨编译器、跨平台的异常行为语义。核心演进方向聚焦于将异常传播策略、栈展开控制与诊断信息生成三者解耦,并通过标准化属性和编译期…...
 Matlab代码)
【独家原创】基于分位数回归PSO-QRLightGBM多变量时序预测-区间预测(多输入单输出) Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。👇 关注我领取海量matlab电子书和数学建模资料🍊个人信条:格物致知,完整Matl…...