时间序列预测 — Informer实现多变量负荷预测(PyTorch)
目录
1 实验数据集
2 如何运行自己的数据集
3 报错分析
1 实验数据集
实验数据集采用数据集4:2016年电工数学建模竞赛负荷预测数据集(下载链接),数据集包含日期、最高温度℃ 、最低温度℃、平均温度℃ 、相对湿度(平均) 、降雨量(mm)、日需求负荷(KWh),时间间隔为1H。
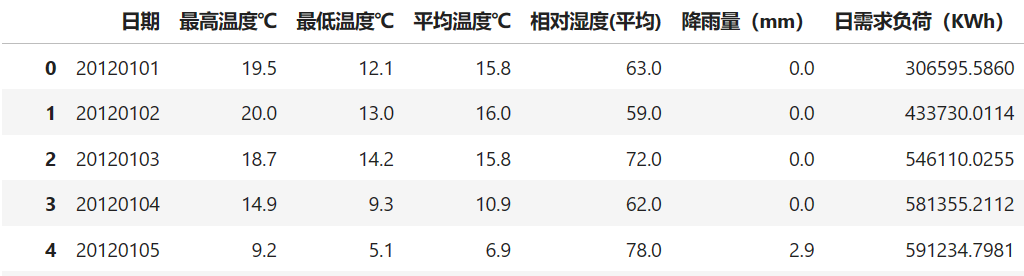
在使用数据之前相对数据进行处理,用其他数据集时也是同样的处理方法。首先读取数据,发数据不是UTF-8格式,通过添加encoding = 'gbk'读取数据,模型传入的数据必须是UTF-8格式。
df= pd.read_table('E:\\课题\\08数据集\\2016年电工数学建模竞赛负荷预测数据集\\2016年电工数学建模竞赛负荷预测数据集.txt',encoding = 'gbk')然后检查数据是否有缺失值:
df.isnull().sum()发现数据存在少量缺失值,分析数据特点,可以通过前项或后项填充填补缺失值:
df = df.fillna(method='ffill')后面需要将表格列名改为英文,时间列名为date,不然后面运行时会报错:
df.columns = ["date","max_temperature(℃)","Min_temperature(℃ )","Average_temperature(℃)","Relative_humidity(average)","Rainfall(mm)","Load"]最后将数据按UTF-8格式保存
load.to_csv('E:\\课题\\08数据集\\2016年电工数学建模竞赛负荷预测数据集\\2016年电工数学建模竞赛负荷预测数据集_处理后.csv', index=False,encoding = 'utf-8')最后可视化看一下数据:
# 可视化
load.drop(['date'], axis=1, inplace=True)
cols = list(load.columns)
fig = plt.figure(figsize=(16,6))
plt.tight_layout()
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=0.8)
for i in range(len(cols)):ax = fig.add_subplot(3,2,i+1)ax.plot(load.iloc[:,i])ax.set_title(cols[i])# plt.subplots_adjust(hspace=1)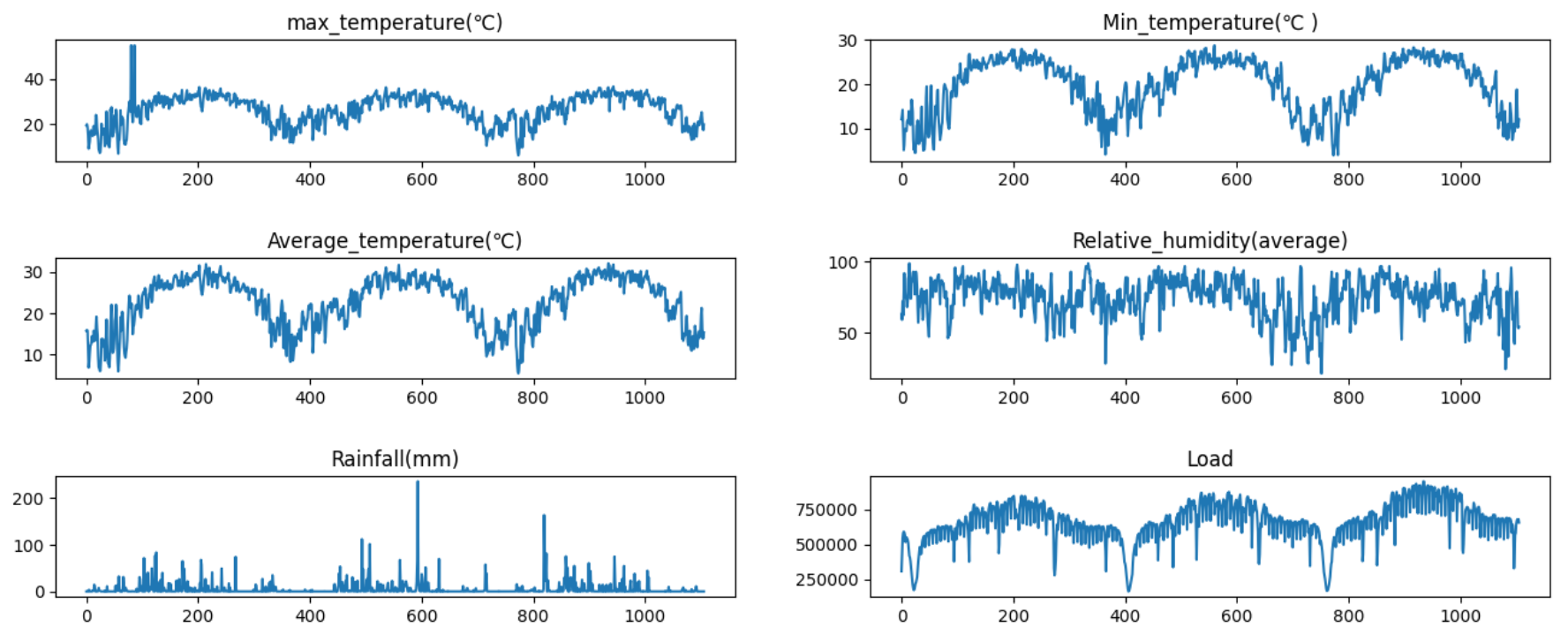
2 如何运行自己的数据集
前面两篇文章介绍了论文的原理、代码解析和官方数据集训练和运行,那么大家在利用模型训练自己的数据集的时候需要修改的几处地方。
parser.add_argument('--data', type=str, default='custom', help='data')
parser.add_argument('--root_path', type=str, default='./data/Load/', help='root path of the data file')
parser.add_argument('--data_path', type=str, default='load.csv', help='data file')
parser.add_argument('--features', type=str, default='MS', help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
parser.add_argument('--target', type=str, default='Load', help='target feature in S or MS task')
parser.add_argument('--freq', type=str, default='h', help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')- data:必须填写 default='custom',也就是改为自定义的数据
- root_path:填写数据文件夹路径
- data_path:填写具体的数据文件名
- features:前面有讲解,features有三个选项(M,MS,S),分别是多元预测多元,多元预测单元,单元预测单元,具体是看你自己的数据集。
- target:就是你数据集中你想要知道那列的预测值的列名,这里改为Load
- freq:就是你两条数据之间的时间间隔。
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length of Informer encoder')
parser.add_argument('--label_len', type=int, default=48, help='start token length of Informer decoder')
parser.add_argument('--pred_len', type=int, default=24, help='prediction sequence length')- seq_len:用过去的多少条数据来预测未来的数据
- label_len:可以裂解为更高的权重占比的部分要小于seq_len
- pred_len:预测未来多少个时间点的数据
parser.add_argument('--enc_in', type=int, default=6, help='encoder input size')
parser.add_argument('--dec_in', type=int, default=6, help='decoder input size')
parser.add_argument('--c_out', type=int, default=1, help='output size')- enc_in:你数据有多少列,要减去时间那一列,这里我是输入8列数据但是有一列是时间所以就填写7
- dec_in:同上
- c_out:这里有一些不同如果你的features填写的是M那么和上面就一样,如果填写的MS那么这里要输入1因为你的输出只有一列数据。
## 解析数据集的信息 ##
# 字典data_parser中包含了不同数据集的信息,键值为数据集名称('ETTh1'等),对应一个包含.csv数据文件名
# 目标特征、M、S和MS等参数的字典
data_parser = {'ETTh1':{'data':'ETTh1.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},'ETTh2':{'data':'ETTh2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},'ETTm1':{'data':'ETTm1.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},'ETTm2':{'data':'ETTm2.csv','T':'OT','M':[7,7,7],'S':[1,1,1],'MS':[7,7,1]},'WTH':{'data':'WTH.csv','T':'WetBulbCelsius','M':[12,12,12],'S':[1,1,1],'MS':[12,12,1]},'ECL':{'data':'ECL.csv','T':'MT_320','M':[321,321,321],'S':[1,1,1],'MS':[321,321,1]},'Solar':{'data':'solar_AL.csv','T':'POWER_136','M':[137,137,137],'S':[1,1,1],'MS':[137,137,1]},'Custom':{'data':'load.csv','T':'Load','M':[137,137,137],'S':[1,1,1],'MS':[6,6,1]},
}预测结果保存在result文件下,保存格式为numpy,可以通过下面的脚本进行可视化预测结果:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 指定.npy文件路径
file_path1 = "results/informer_ETTh1_ftM_sl96_ll48_pl24_dm512_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_0/true.npy"
file_path2 = "results/informer_ETTh1_ftM_sl96_ll48_pl24_dm512_nh8_el2_dl1_df2048_atprob_fc5_ebtimeF_dtTrue_mxTrue_test_1/pred.npy"# 使用NumPy加载.npy文件
true_value = []
pred_value = []
data1 = np.load(file_path1)
data2 = np.load(file_path2)
print(data2)
for i in range(24):true_value.append(data2[0][i][6])pred_value.append(data1[0][i][6])# 打印内容
print(true_value)
print(pred_value)#保存数据
df = pd.DataFrame({'real': true_value, 'pred': pred_value})
df.to_csv('results.csv', index=False)#绘制图形
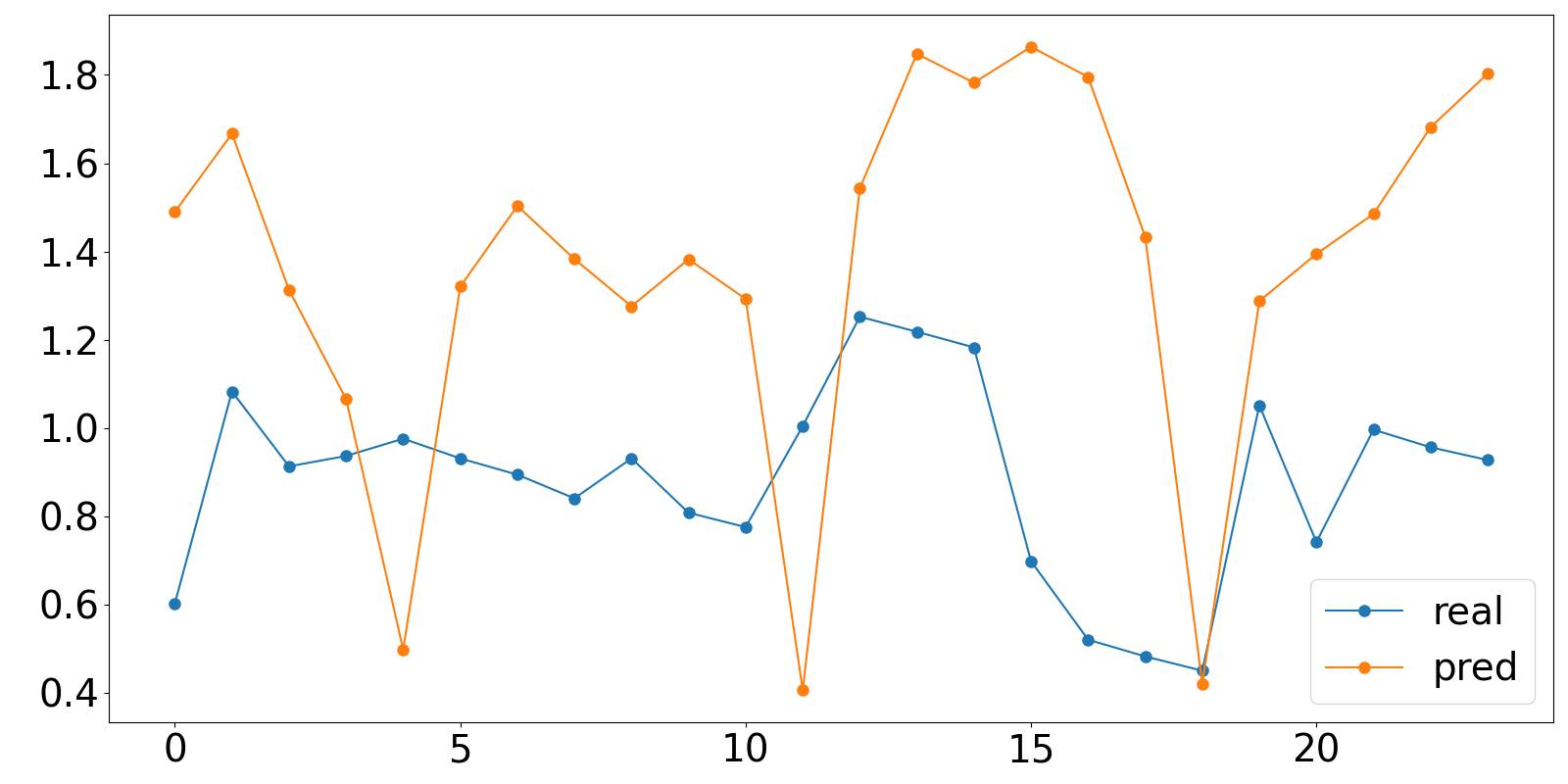
fig = plt.figure(figsize=( 16, 8))
plt.plot(df['real'], marker='o', markersize=8)
plt.plot(df['pred'], marker='o', markersize=8)
plt.tick_params(labelsize = 28)
plt.legend(['real','pred'],fontsize=28)
plt.show()最后预测的效果如下,发现并不是太好,后续看参数调优后是否能提升模型预测效果。
3 报错分析
报错1:UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 56-57: invalid continuation byte,具体来说,'utf-8' 编解码器无法解码文件中的某些字节,因为它们不符合 UTF-8 编码的规则。
File "D:\Progeam Files\python\lib\site-packages\pandas\io\parsers\c_parser_wrapper.py", line 93, in __init__self._reader = parsers.TextReader(src, **kwds)File "pandas\_libs\parsers.pyx", line 548, in pandas._libs.parsers.TextReader.__cinit__File "pandas\_libs\parsers.pyx", line 637, in pandas._libs.parsers.TextReader._get_headerFile "pandas\_libs\parsers.pyx", line 848, in pandas._libs.parsers.TextReader._tokenize_rowsFile "pandas\_libs\parsers.pyx", line 859, in pandas._libs.parsers.TextReader._check_tokenize_statusFile "pandas\_libs\parsers.pyx", line 2017, in pandas._libs.parsers.raise_parser_error
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 56-57: invalid continuation byte解决办法:
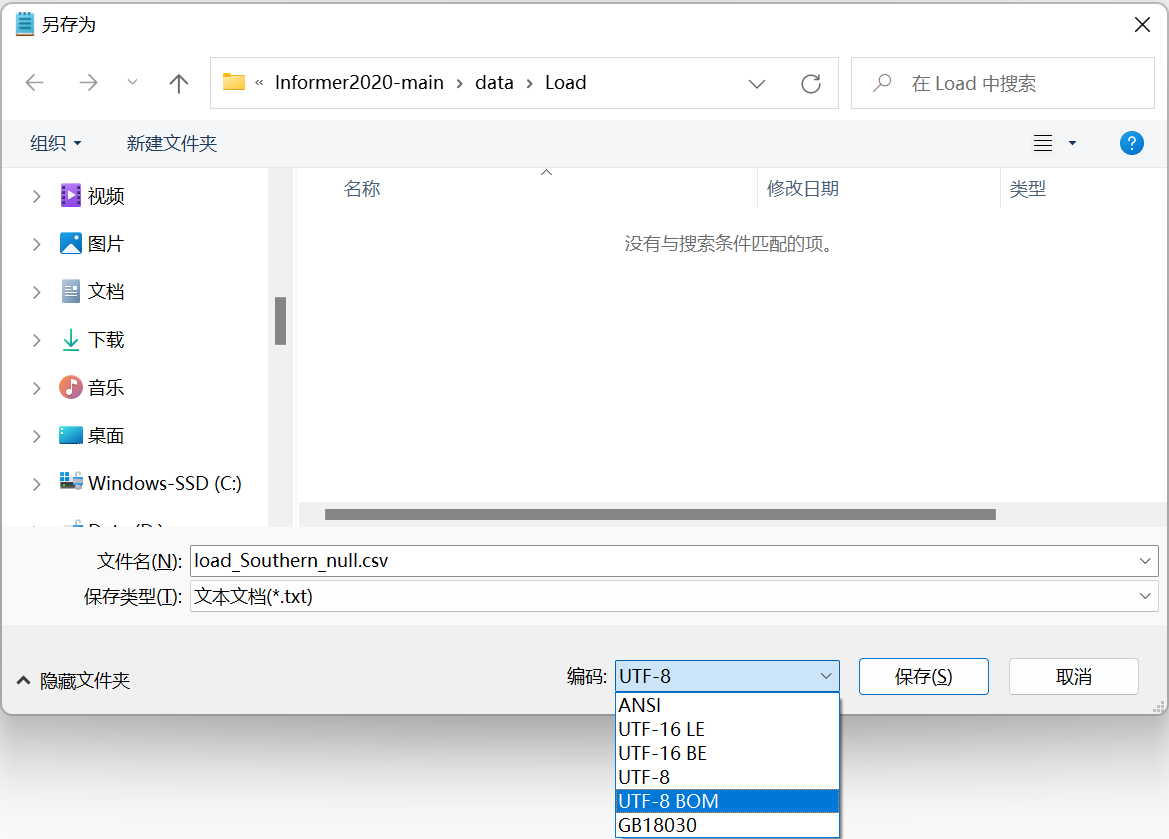
(1) 根据提示,要将数据更改'utf-8'格式,最简便的方法将数据用记事本打开,另存为是通过UTF-8格式保存
(2) 尝试使用其他编解码器(如 'latin1')来读取文件,或者在读取文件时指定正确的编码格式。
报错2:ValueError: list.remove(x): x not in list,试从列表中删除两个元素,但是这两个元素中至少有一个不在列表中。
File "E:\课题\07代码\Informer2020-main\Informer2020-main\data\data_loader.py", line 241, in __read_data__
cols = list(df_raw.columns); cols.remove(self.target); cols.remove('date')
ValueError: list.remove(x): x not in list解决办法:在没有找到具体原因的时候可以在删除元素之前先检查一下列表中是否包含要删除的元素,或者使用 try-except 语句来捕获异常,以便在元素不存在时不会导致程序中断。通过检查,数据中的列名最好改为英文,避免产生乱码。
if self.cols:cols=self.cols.copy()cols.remove(self.target)
else:# 添加调试信息cols = list(df_raw.columns)print(cols) # 输出列的内容if self.target in cols:cols.remove(self.target)else:print(f"{self.target} not in columns")if 'date' in cols:cols.remove('date')else:print("date not in columns")# 添加调试信息cols = list(df_raw.columns); cols.remove(self.target); cols.remove('date')
df_raw = df_raw[['date']+cols+[self.target]]相关文章:
时间序列预测 — Informer实现多变量负荷预测(PyTorch)
目录 1 实验数据集 2 如何运行自己的数据集 3 报错分析 1 实验数据集 实验数据集采用数据集4:2016年电工数学建模竞赛负荷预测数据集(下载链接),数据集包含日期、最高温度℃ 、最低温度℃、平均温度℃ 、相对湿度(平均) 、降雨…...

2023年金融信创行业研究报告
第一章 行业概况 1.1 定义 金融信创是指在金融行业中应用的信息技术,特别是那些涉及到金融IT基础设施、基础软件、应用软件和信息安全等方面的技术和产品。这一概念源于更广泛的“信创 (信息技术应用创新)”,即通过中国国产信息技术替换海外信息技术&a…...

51单片机按键控制LED灯亮灭的N个玩法
51单片机按键控制LED灯亮灭的N个玩法 1.概述 这篇文章介绍按键的使用,以及通过控制LED灯的小实验,发现按键中存在的问题,然后思考并解决这些问题。达到熟练使用按键控制元器件。 2.搭建硬件环境 1.硬件准备 名称型号数量单片机STC12C205…...

推荐6款本周 yyds 的开源项目
🔥🔥🔥本周GitHub项目圈选: 主要包含 链接管理、视频总结、有道音色情感合成、中文文本格式校正、GPT爬虫、深度学习推理 等热点项目。 1、Dub 一个开源的链接管理工具,可自定义域名将繁杂的长链接生成短链接,便于保…...
【Git】git 更换远程仓库地址三种方法总结分享
因为公司更改了 gitlab 的网段地址,发现全部项目都需要重新更改远程仓库的地址了,所以做了个记录,说不定以后还会用到呢。 一、不删除远程仓库修改(最方便) # 查看远端地址 git remote -v # 查看远端仓库名 git rem…...

springboot 返回problem+json
spring所有配置都在WebMvcAutoConfiguration中 其中有 ProblemDetailsExceptionHandler 容器中的一个组件 -ControllerAdvice用来集中处理异常的 -点进ResponseEntityExceptionHandler 包含这些异常,如果出现以下异常,会被springboot支持以RFC 7807规…...

AI动画制作 StableDiffusion
1.brew -v 2.安装爬虫项目包所必需的python和git等系列系统支持部件 brew install cmake protobuf rust python@3.10 git wget pod --version brew link --overwrite cocoapods 3.从github网站克隆stable-diffusion-webui爬虫项目包至本地 ssh-add /Users/haijunyan/.ssh/id_r…...

【开源】基于Vue和SpringBoot的木马文件检测系统
项目编号: S 041 ,文末获取源码。 \color{red}{项目编号:S041,文末获取源码。} 项目编号:S041,文末获取源码。 目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 木马分类模块2.3 木…...

5 动态规划解分割等和子串
来源:LeetCode第416题 难度:中等 描述:给你一个只包含正整数的非空数组nums,请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等 分析:相当于从nums数组中选取一些元素,使得他们的和为…...

file_get_contents() 函数详解与使用
概述 在PHP中,file_get_contents() 函数是一个强大的工具,它既可以用于读取本地文件的内容,也可以用于发起 HTTP 请求获取远程资源。本文将详细介绍 file_get_contents() 函数的两种主要用途,并探讨如何充分利用这个函数。 1. 文…...

某医生用 ChatGPT 在 4 个月内狂写 16 篇论文,其中 5 篇已发表,揭密ChatGPT进行论文润色与改写的秘籍
如果写过学术论文,想必会有这样的感受: 绞尽脑汁、茶饭不思、夜不能寐、废寝忘食、夜以继日,赶出一篇论文,然后还被导师点评,“写得就是一坨!” 可是,却有人4个月产出了16篇论文,成功…...

进程等待讲解
今日为大家分享有关进程等待的知识!希望读完本文,大家能有一定的收获! 正文开始! 进程等待的引进 既然我们今天要讲进程等待这个概念!那么只有我们把下面这三个方面搞明白,才能真正的了解进程等待&#x…...

MySQL Binlog深度解析:进阶应用与实战技巧【进阶应用】
🎏:你只管努力,剩下的交给时间 🏠 :小破站 MySQL Binlog深度解析:进阶应用与实战技巧 前言第一:Binlog事件详解第二:关于GTIDGTID的结构:GTID的作用:GTID的事…...

openpnp - 给底部相机加防尘罩
文章目录 openpnp - 给底部相机加防尘罩概述笔记END openpnp - 给底部相机加防尘罩 概述 设备标定完, 看着底部相机, 有点担心掉进去东西, 万一从吸嘴掉下去的料(或者清理设备台面时, 不小心掉进去东西)将顶部相机搞短路怎么办. 就想加个防尘罩, 如果有东西掉进去, 可以掉到机…...
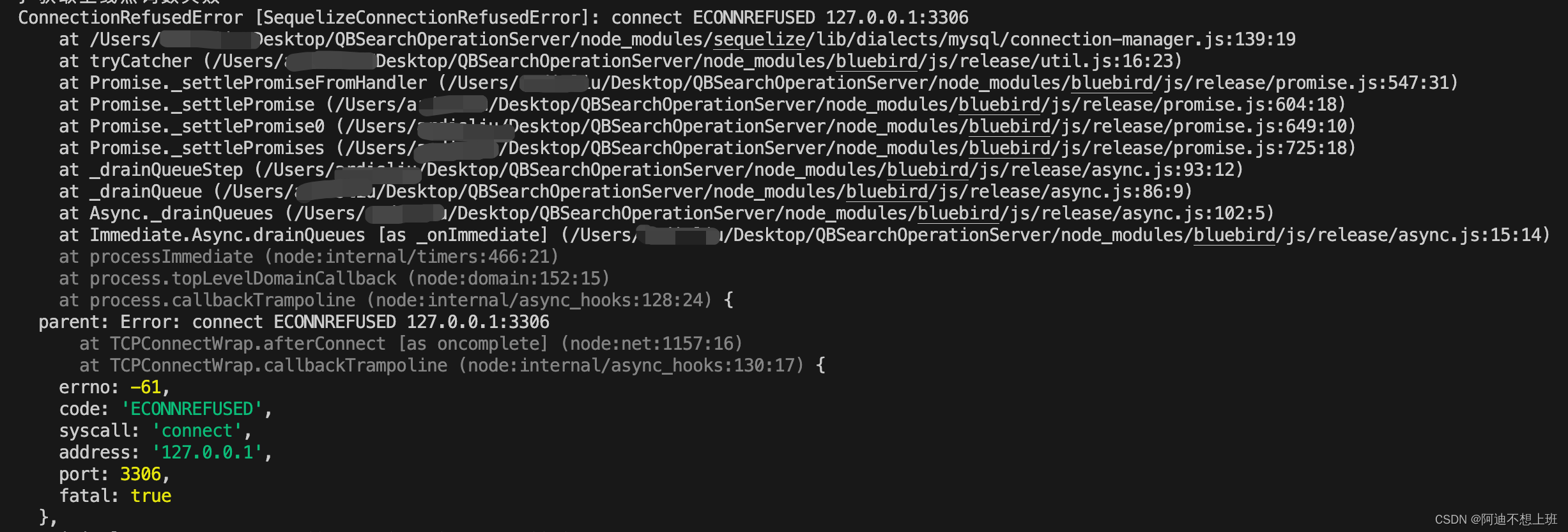
mac mysql连接中断重新启动办法
遇到如图所示问题,可以用下面的命令重启mysql服务 sudo /usr/local/mysql/support-files/mysql.server start...

【Vue3】解决Vue打包后上传服务器 资源路径加载错误
问题: 我这里在打包Vue之后将打包后的dist 上传至服务器站点根目录内子目录 名为 "adminstore" , 但是当我通过域名打开站点后发现 资源加载路径内并没有携带 子目录 "adminstore" 文件名称 错误:http://your website domain/js/app…...

u-popup组件在UniApp中的讲解
u-popup 组件是 UniApp 中一个多功能且强大的组件,UniApp 是一个使用 Vue.js 开发跨平台应用程序的框架。u-popup 组件提供了一种在应用程序的其他内容上方显示临时或浮动内容的方式。 使用方法: 要在 UniApp 项目中使用 u-popup 组件,你需要…...
drool 7 multiThread 测试
基本信息 通过option ,使用如下代码进行设置 //线程数量10MaxThreadsOption optionMaxThreadsOption.get(10);kieBaseConf.setOption(option);kieBaseConf.setOption(MultithreadEvaluationOption.YES);并发是以CompositeDefaultAgenda/Rule为颗粒度来的࿰…...

【网安AIGC专题】46篇前沿代码大模型论文、24篇论文阅读笔记汇总
网安AIGC专题 写在最前面一些碎碎念课程简介 0、课程导论1、应用 - 代码生成2、应用 - 漏洞检测3、应用 - 程序修复4、应用 - 生成测试5、应用 - 其他6、模型介绍7、模型增强8、数据集9、模型安全 写在最前面 本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,…...
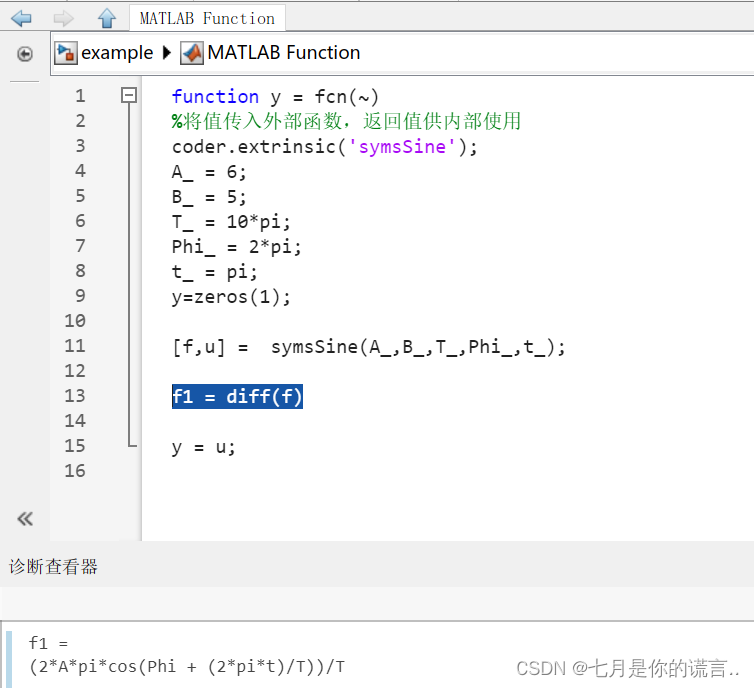
如何在Simulink中使用syms?换个思路解决报错:Function ‘syms‘ not supported for code generation.
问题描述 在Simulink中的User defined function使用syms函数,报错simulink无法使用外部函数。 具体来说: 我想在Predefined function定义如下符号函数作为输入信号,在后续模块传入函数参数赋值,以实现一次定义多次使用…...

移动端SEO优化有什么技巧
移动端SEO优化有什么技巧 在互联网时代,移动端已经成为人们获取信息和服务的主要途径。因此,如何在移动端上进行SEO优化,成为了每一个网站运营者关注的重点。本文将详细探讨移动端SEO优化的技巧,帮助你提升网站在移动端的搜索引擎…...

Python办公自动化教程 - openpyxl让Excel处理变得轻松
Python办公自动化教程 - openpyxl让Excel处理变得轻松适用人群:零基础办公人员、想提高工作效率的非IT专业人士 学习目标:掌握使用Python处理Excel文件,实现日常办公自动化 前置知识:不需要任何编程基础,只要会操作电脑…...

如何用MVP.css快速创建响应式网站:终极完整指南
如何用MVP.css快速创建响应式网站:终极完整指南 【免费下载链接】mvp MVP.css — Minimalist classless CSS stylesheet for HTML elements 项目地址: https://gitcode.com/gh_mirrors/mv/mvp MVP.css是一个极简主义的无类CSS样式表,专为快速创建…...

RWKV7-1.5B-G1A快速部署:基于Docker和VS Code的远程开发环境搭建
RWKV7-1.5B-G1A快速部署:基于Docker和VS Code的远程开发环境搭建 1. 引言 如果你正在寻找一种高效的方式来搭建RWKV7-1.5B-G1A模型的开发环境,这篇教程正是为你准备的。我们将使用Docker和VS Code的远程开发功能,在星图GPU平台上快速搭建一…...

s2-pro开源TTS价值:填补中文专业级开源语音合成模型空白
s2-pro开源TTS价值:填补中文专业级开源语音合成模型空白 1. 为什么我们需要专业级中文TTS 在语音技术领域,中文语音合成(TTS)长期面临一个尴尬局面:虽然商业解决方案众多,但高质量的开源模型却寥寥无几。这种状况直到s2-pro的出…...
)
ComfyUI 高频报错排查与修复指南(实战经验总结)
1. ComfyUI环境依赖冲突的终极解决方案 第一次打开ComfyUI就遇到红色报错提示?八成是环境依赖出了问题。我见过太多开发者在这个环节卡住好几天,其实大部分问题都有固定解法。先别急着重装系统,跟着我的排查清单一步步来。 最常见的环境冲突往…...

MT5文本改写工具5分钟上手:零基础学会用AI一键扩写句子
MT5文本改写工具5分钟上手:零基础学会用AI一键扩写句子 1. 工具简介:你的智能句子改写助手 你是否经常遇到这些情况: 写文章时反复修改同一句话,却总觉得表达不够丰富需要为机器学习模型准备训练数据,但原始文本数量…...
)
低功耗设计必看:PrimeTime生成.lib文件时PG引脚的正确配置方法(附实例代码)
低功耗设计必看:PrimeTime生成.lib文件时PG引脚的正确配置方法(附实例代码) 在当今数字IC设计中,低功耗已成为与性能、面积同等重要的关键指标。电源管理架构的复杂性使得时序库中的电源地(PG)引脚信息变得…...

HG-ha/MTools实操手册:利用开发辅助功能提高编码效率
HG-ha/MTools实操手册:利用开发辅助功能提高编码效率 1. 开箱即用的全能开发助手 你是不是经常在开发过程中遇到这样的困扰:需要频繁切换不同工具来处理图片、编辑音视频、调试代码?HG-ha/MTools 可能就是你要找的解决方案。 这是一款功能…...

告别复杂配置:AI股票分析师daily_stock_analysis开箱即用实战体验
告别复杂配置:AI股票分析师daily_stock_analysis开箱即用实战体验 1. 引言:为什么选择这个AI股票分析师? 作为一名金融从业者或投资爱好者,你可能经常面临这样的困扰:想要快速了解一只股票的基本情况,却需…...