机器学习——多元线性回归升维
机器学习升维
- 升维
- 使用sklearn库实现特征升维
- 实现天猫年度销量预测
- 实现中国人寿保险预测
升维
定义:将原始的数据表示从低维空间映射到高维空间。在线性回归中,升维通常是通过引入额外的特征来实现的,目的是为了更好地捕捉数据的复杂性,特别是当数据之间的关系是非线性的时候。
目的:解决欠拟合问题,提高模型的准确率。为解决因对预测结果考虑因素比较少,而无法准确计算出模型参数问题。
常用方法:将已知维度进行自乘(或相乘)来构建新的维度。
本文主要记录的是线性回归中遇到数据呈现非线性特征时,该如何处理!
切记:对训练集特征升维后也要对测试集、验证集特征数据进行升维操作
数据准备如下:

如果对其直接进行线性回归,则拟合后的模型如下:

从上述两图可知,对于具有非线性特征的图像,不对其使用特使的处理,则无法对其产生比较好的模型拟合。
上述图像生成代码:
# 导包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 创建数据
X = np.linspace(-1,11,100)
y = (X - 5)**2 + 3*X + 12 + np.random.randn(100)
X = X.reshape(-1,1)
# display(X.shape,y.shape)
plt.scatter(X,y)# 不升维直接用线性回归解决
model = LinearRegression()
model.fit(X,y)
X_test = np.linspace(-2,12,300).reshape(-1,1)
y_test = model.predict(X_test)
plt.scatter(X,y)
plt.plot(X_test,y_test,color = 'red')
为了使得可以对具有非线性特征的数据进行处理,生成一个较好的模型,可是实现预测的任务,于是便有了升维操作,下举例升维和不升维的区别:
不升维:二维数据x1, x2若不对其进行升维操作,则其拟合的多元线性回归公式为:
y = w 1 ∗ x 1 + w 2 ∗ x 2 + w 0 y = w_1*x_1 + w_2*x_2 + w_0 y=w1∗x1+w2∗x2+w0
升维:若对二维数据x1,x2进行升维操作,则其可有5个维度(以自乘为例):x1、x2、x12,x22、x1*x2,在加上一个偏置项w0,一共有六个参数,则其拟合后的多元线性回归公式为:
y = w 0 + w 1 ∗ x 1 + w 2 ∗ x 2 + w 3 ∗ x 1 2 + w 4 ∗ x 2 2 + w 5 ∗ x 1 ∗ x 2 y= w_0+w_1*x_1+w_2*x_2+w_3*x_1^2+w_4*x_2^2+w_5*x_1*x_2 y=w0+w1∗x1+w2∗x2+w3∗x12+w4∗x22+w5∗x1∗x2
若这样,则由原本的一维线性方程转换成了二维函数(最直观的表现),则原本的数据集则可以拟合成下图所示的模型:

上图生成代码如下:
# 导包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
X = np.linspace(-1,11,100)
y = (X - 5)**2 + 3*X + 12 + np.random.randn(100)
X = X.reshape(-1,1)# 升维,可以解决多项式的问题,直观表现为可以让直线进行拐弯
np.set_printoptions(suppress=True)
X2 = np.concatenate([X,X**2], axis= 1)
# 注:只需要对特征进行升维,不需要对目标值进行升维# 生成测试数据
X_test = np.linspace(-2,12,300).reshape(-1,1)
model2 = LinearRegression()
model2.fit(X2,y)
X_test2 = np.concatenate([X_test,X_test**2],axis=1)
y_test2 = model2.predict(X_test2)
print('所求的w是\n',model2.coef_)
print('所求的截距b是\n',model2.intercept_)# 绘制图像的时候要用没升维的数据进行绘制
plt.scatter(X,y,color='green')
plt.plot(X_test,y_test2,color = 'red')
使用sklearn库实现特征升维
在sklearn中具有很多封装好的工具,可以直接调用。
from sklearn.preprocessing import PolynomialFeatures # (多项式)升维的python库
使用方法:
# 特征和特征之间相乘
poly = PolynomialFeatures(interaction_only=True)
A = [[3,2]]
poly.fit_transform(A)
# 生成结果:array([[1., 3., 2., 6.]])#特征之间乘法,自己和自己自乘(在上述情况下加上自己的乘法)
poly = PolynomialFeatures(interaction_only=False)
A = [[3,2,5]]
poly.fit_transform(A)
# 生成结果:array([[ 1., 3., 2., 5., 9., 6., 15., 4., 10., 25.]])# 可以通过degree来提高升维的大小
poly = PolynomialFeatures(degree=4,interaction_only=False)# 特征和特征之间相乘
A = [[3,2,5]]
poly.fit_transform(A)
# 生成结果:
# array([[ 1., 3., 2., 5., 9., 6., 15., 4., 10., 25., 27.,
# 18., 45., 12., 30., 75., 8., 20., 50., 125., 81., 54.,
# 135., 36., 90., 225., 24., 60., 150., 375., 16., 40., 100.,
# 250., 625.]])
实现天猫年度销量预测
实现代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor# 创建数据
X = np.arange(2009,2020).reshape(-1,1) - 2008
y = np.array([0.5,9.36,52,191,350,571,912,1207,1682,2135,2684])
plt.scatter(X,y)
# 创建测试数据
X_test = np.linspace(2009,2020,100).reshape(-1,1) - 2008# 数据升维
ploy = PolynomialFeatures(degree=2, interaction_only=False)
X2 = ploy.fit_transform(X)
X_test2 = ploy.fit_transform(X_test)# 模型创建LinearRegression
model = LinearRegression(fit_intercept=False)
model.fit(X2,y)
y_pred = model.predict(X_test2)
print('参数w为:',model.coef_)
print('参数b为:',model.intercept_)plt.scatter(X,y,color='green')
plt.plot(X_test,y_pred,color='red')
# 使用SGD进行梯度下降,必须要归一化,否则效果会非常不好
# 创建测试数据
X_test = np.linspace(2009,2019,100).reshape(-1,1) - 2008# 数据升维
ploy = PolynomialFeatures(degree=2, interaction_only=False)
X2 = ploy.fit_transform(X)
X_test2 = ploy.fit_transform(X_test)#对数据进行归一化操作
standard = StandardScaler()
X2_norm = standard.fit_transform(X2)
X_test2_norm = standard.fit_transform(X_test2)# 模型创建SGDRegression
model = SGDRegressor(eta0=0.3, max_iter=5000)
model.fit(X2_norm,y)
y_pred = model.predict(X_test2_norm)
print('参数w为:',model.coef_)
print('参数b为:',model.intercept_)plt.scatter(X,y,color='green')
plt.plot(X_test,y_pred,color='red')
这里需要说明一下情况,如果第二段代码不进行归一化,则呈现的是下图:

如果进行了归一化,则产生的和法一LinearRegession是一样的图形(基本相同):

这是什么原因?
- 线性回归(Linear Regression)和随机梯度下降(SGD)在处理特征尺度不同的问题上有一些不同之处,导致线性回归相对于特征尺度的敏感性较低。
- SGD的更新规则涉及学习率(η)和梯度。如果不同特征的尺度相差很大,梯度的大小也会受到这种尺度差异的影响。因此在引入高次项或其他非线性特征,需要注意特征的尺度,避免数值上的不稳定性。
- SGD中的正则化项通常依赖于权重的大小。通过归一化,可以使得正则化项对所有特征的影响更加平衡。
实现中国人寿保险预测
import pandas as pd
import seaborn as sns
import numpy as np
from sklearn.linear_model import LinearRegression,ElasticNet
from sklearn.metrics import mean_squared_error,mean_squared_log_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures# 读取数据
data_renshou = pd.read_excel('your_path/中国人寿.xlsx')
# 可以通过下式生成图像,查看那些数据是好数据那些是不好的数据——好特征:差别大,容易区分
#sns.kdeplot(data=data_renshou, x="charges",hue="sex",shade=True)
#sns.kdeplot(data=data_renshou, x="charges",hue="smoker",shade=True)
#sns.kdeplot(data=data_renshou, x="charges",hue="region",shade=True)
#sns.kdeplot(data=data_renshou, x="charges",hue="children",shade=True)# 特征工程,对数据进行处理
data_renshou = data_renshou.drop(['region','sex'],axis = 1) # 删除不好的特征# 体重指数,离散化转换,体重两种情况:标准,fat
def conver(df,bmi):df['bmi'] = 'fat' if df['bmi'] >= bmi else 'standard'return df
data_renshou = data_renshou.apply(conver, axis=1,args=(30,))# 特征提取,离散转数值型数据
data_renshou = pd.get_dummies(data_renshou)
data_renshou.head()#特征和目标值提取
# 训练数据
x = data_renshou.drop('charges', axis=1)
# 目标值
y = data_renshou['charges']# 划分数据
X_train,X_test,y_train,y_test = train_test_split(x,y,test_size=0.2)# 特征升维(导致了他下面的参数biandu)
poly = PolynomialFeatures(degree=2, include_bias=False)
X_train_poly = poly.fit_transform(X_train)
X_test_poly = poly.fit_transform(X_test)
# 模型训练与评估
np.set_printoptions(suppress=True)
model = LinearRegression()
model.fit(X_train_poly,y_train)
print('测试数据得分:',model.score(X_train_poly,y_train))
print('预测数据得分:',model.score(X_test_poly,y_test))
print('测试数据均方误差:',np.sqrt(mean_squared_error(y_test,model.predict(X_test_poly))))
print('训练数据均方误差:',np.sqrt(mean_squared_error(y_train,model.predict(X_train_poly))))
print('测试数据对数误差:',np.sqrt(mean_squared_log_error(y_test,model.predict(X_test_poly))))
print('训练数据对数误差:',np.sqrt(mean_squared_log_error(y_train,model.predict(X_train_poly))))
print('获得的参数为:',model.coef_.round(2),model.intercept_.round(2))
相关文章:
机器学习——多元线性回归升维
机器学习升维 升维使用sklearn库实现特征升维实现天猫年度销量预测实现中国人寿保险预测 升维 定义:将原始的数据表示从低维空间映射到高维空间。在线性回归中,升维通常是通过引入额外的特征来实现的,目的是为了更好地捕捉数据的复杂性&#…...
[C/C++]用堆实现TopK算法
一:引入 思考一个问题: 怎么在100个数中找到前10个最大的数? way1: 相信大多数人想到的方法是先把100个数放到数组中从大到小排序,再打印前10个数 way2: 前一文中我们讲了堆结构,那么就可以把这100个数建为大堆,再依次pop10次 这种方法虽然再这个问题下可行,但是如果是再1亿…...
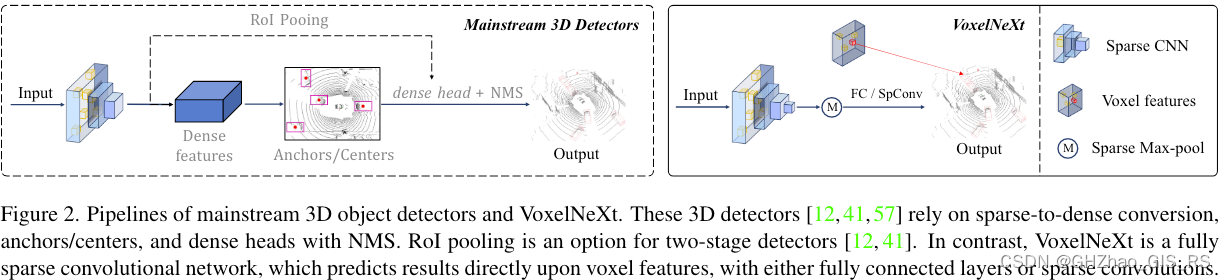
3D点云目标检测:VoxelNex解读(带源码/未完)
VoxelNext 通用vsVoxelNext一、3D稀疏卷积模块1.1、额外的两次下采样1.2、稀疏体素删减 二、高度压缩三、稀疏池化四、head五、waymo数据集训练六、训练自己的数据集bug修改 通用vsVoxelNext 一、3D稀疏卷积模块 1.1、额外的两次下采样 使用通用的3D sparse conv,…...
【Docker】从零开始:11.Harbor搭建企业镜像仓库
【Docker】从零开始:11.Harbor搭建企业镜像仓库 1. Harbor介绍2. 软硬件要求(1). 硬件要求(2). 软件要求 3.Harbor优势4.Harbor的误区5.Harbor的几种安装方式6.在线安装(1).安装composer(2).配置内核参数,开启路由转发(3).下载安装包并解压(4).创建并修改配置文件(5…...

使用conan包 - 工作流程
使用conan包 - 工作流程 主目录 conan Using packages1 Single configuration2 Multi configuration 本文是基于对conan官方文档Workflows的翻译而来, 更详细的信息可以去查阅conan官方文档。 This section shows how to setup your project and manage dependenci…...

【LeeCode】59.螺旋矩阵II
给定一个正整数 n,生成一个包含 1 到 n^2 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。 示例: 输入: 3 输出: [ [ 1, 2, 3 ], [ 8, 9, 4 ], [ 7, 6, 5 ] ] 解: class Solution {public int[][] generateMatrix(int n) {int[][] ar…...
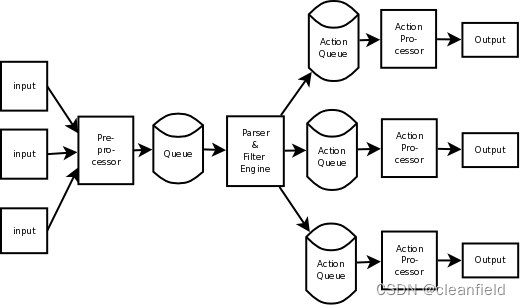
rsyslog学习
rsyslog是什么 RSYSLOG(Remote System Logging)是一个开源的日志处理工具,用于在 Linux 和 Unix 系统上收集、处理和转发日志。它是一个健壮且高性能的日志处理程序,可以替换 Syslogd 作为标准的系统日志程序。RSYSLOG 提供了许多…...
Navicat 技术指引 | GaussDB服务器对象的创建/设计(编辑)
Navicat Premium(16.2.8 Windows版或以上) 已支持对GaussDB 主备版的管理和开发功能。它不仅具备轻松、便捷的可视化数据查看和编辑功能,还提供强大的高阶功能(如模型、结构同步、协同合作、数据迁移等),这…...

有哪些可信的SSL证书颁发机构?
目前市面上所显示的SSL证书颁发机构可所谓不计其数,类型也是多样,就好比我们同样是买一件T恤,却有百家不同类型的店铺一个道理。根据CA里面看似很多,但能拿到99%浏览器及设备信任度的寥寥无几,下面小编整理出几家靠谱可…...
MidJourney笔记(4)-settings
前面已经大概介绍了MidJourney的基础知识,后面我主要是基于实操来分享自己的笔记。可能内容顺序会有点乱,请大家理解。 这次主要是想讲讲settings这个命令。我们只需在控制台输入/settings,然后回车,就可以执行这个命令。 (2023年11月26日版本界面) 可能有些朋友出来的界…...
前端开发学习 (三) 列表功能
一、列表功能 1、列表功能 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><meta http-equiv"X-UA-Compa…...
win11渗透武器库,囊括所有渗透工具
开箱即用,最全的武器库,且都是2023年11月最新版,后续自己还可以再添加,下载地址:https://download.csdn.net/download/weixin_59679023/88565739 服务连接 信息收集工具 端口扫描 代理抓包 漏洞扫描 指纹识别 webshel…...

13-21-普通数组、矩阵
LeetCode 热题 100 文章目录 LeetCode 热题 100普通数组13. 中等-最大子数组和14. 中等-合并区间15. 中等-轮转数组16. 中等-除自身以外数组的乘积17. 困难-缺失的第一个正数 矩阵18. 中等-矩阵置零19. 中等-螺旋矩阵20. 中等-旋转图像21. 中等-搜索二维矩阵II 本文存储我刷题的…...
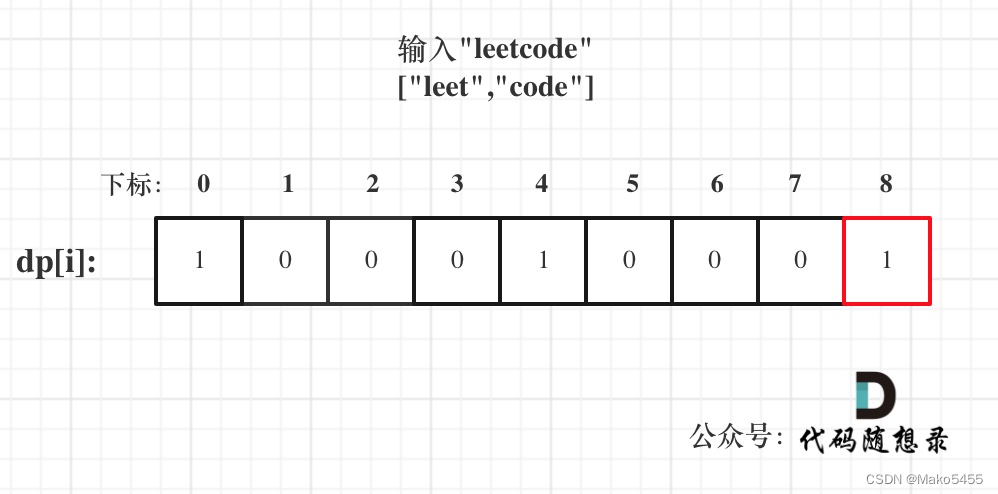
代码随想录算法训练营第四十六天【动态规划part08】 | 139.单词拆分、背包总结
139.单词拆分 题目链接: 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 求解思路: 单词是物品,字符串s是背包,单词能否组成字符串s,就是问物品能不能把背包装满。 动规五部曲 确定dp数…...

go语言基础 break和contine区别
背景 break和continue是编程语言的标准语法,几乎在所有的语言都有类似的用法。 go语言及所有其他编程语言for循环或者其他循环 区别 for i : 0; i < 10; i {if i 5 {continue}fmt.Println(i)for j : 0; j < 3; j {fmt.Println(strconv.Itoa(j) "a&q…...
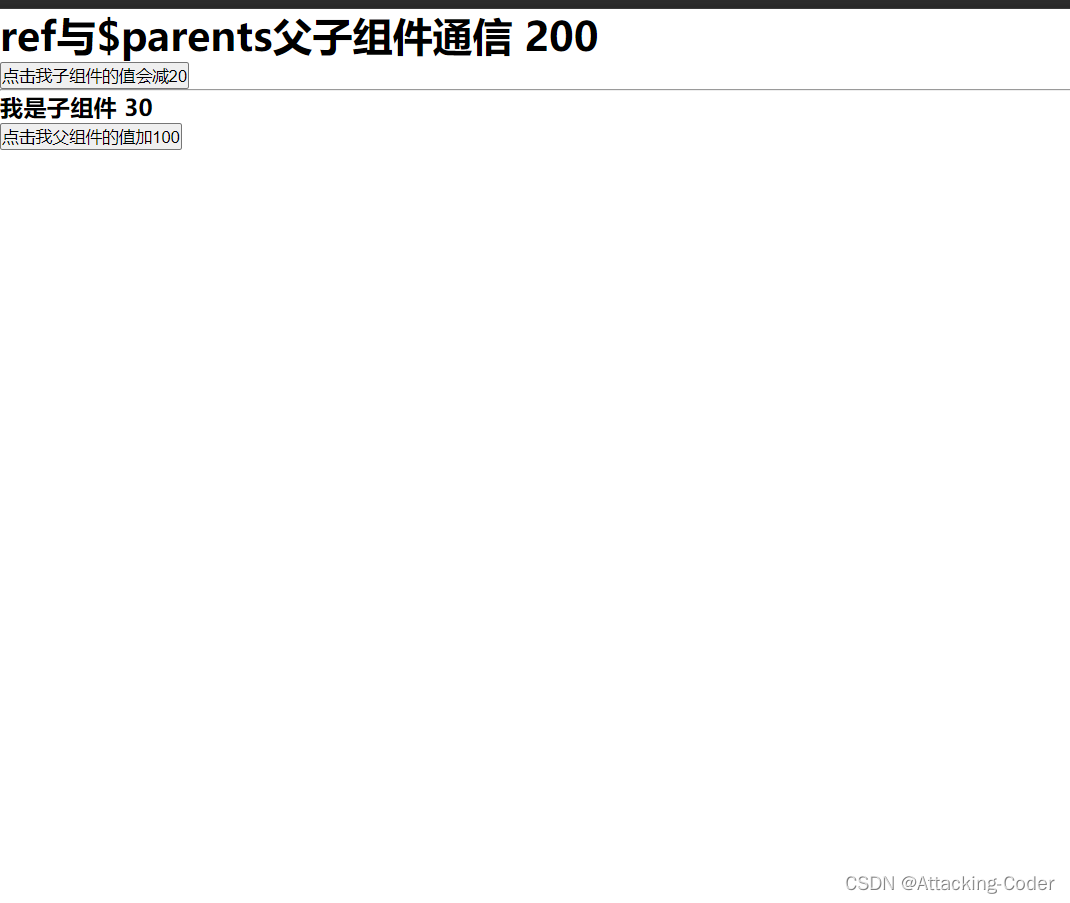
vue3父子组件通过$parent与ref通信
父组件 <template><div><h1>ref与$parents父子组件通信 {{ parentMoney }}</h1><button click"handler">点击我子组件的值会减20</button><hr><child ref"children"></child></div> </te…...

PHP中的常见的超全局变量
PHP是一种广泛使用的服务器端脚本语言,它被用于开发各种Web应用程序。在PHP中,有一些特殊的全局变量,被称为超全局变量。超全局变量在整个脚本中都是可用的,无需使用global关键字来访问它们。在本文中,我们将深入了解P…...
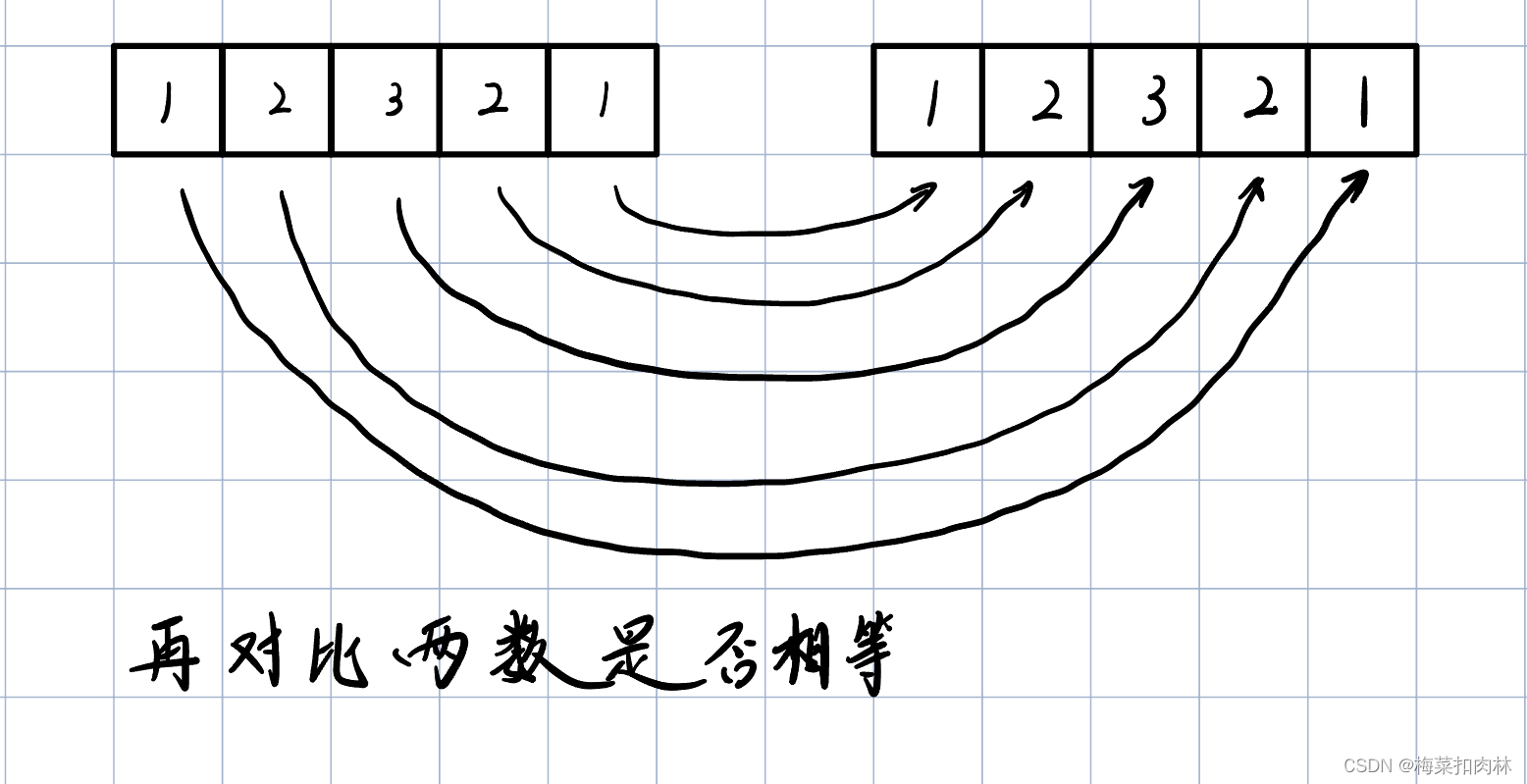
leetcode9.回文数
回文数 0.题目1.WJQ的思路2.实现过程2.0 原始值怎么一个个取出来?2.1 取出来的数如何存到新的数字后面?2.2完整的反转得到新数的过程 3.完整的代码4.可运行的代码5.算法还可以优化的部分 0.题目 给你一个整数 x ,如果 x 是一个回文整数&…...
)
springboot(ssm大学生二手电子产品交易平台 跳蚤市场系统Java(codeLW)
springboot(ssm大学生二手电子产品交易平台 跳蚤市场系统Java(code&LW) 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或…...
关于微信小程序中如何实现数据可视化-echarts动态渲染
移动端设备中,难免会涉及到数据的可视化展示、数据统计等等,本篇主要讲解原生微信小程序中嵌入echarts并进行动态渲染,实现数据可视化功能。 基础使用 首先在GitHub上下载echarts包 地址:https://github.com/ecomfe/echarts-for…...

科研不秃头!谁还不知道这个零代码生信神器
各位深陷生信泥潭的科研宝子们,集合啦!📢你是否也经历过这样的绝望:❌ 导师甩来一组单细胞数据,你却连 Linux 怎么登录都不知道?❌ 好不容易装好了 R 语言,结果包版本冲突报错到怀疑人生&#x…...

OpenClaw+Qwen3-14b_int4_awq内容创作:从大纲生成到公众号发布全自动
OpenClawQwen3-14b_int4_awq内容创作:从大纲生成到公众号发布全自动 1. 为什么需要全自动内容创作 作为一个技术博主,我经常面临一个困境:有太多想写的内容,但时间总是不够用。从构思大纲到完成写作,再到排版发布&am…...

滨会生物冲刺港股:年亏1.2亿 乐普生物与扬子江药业是股东
雷递网 雷建平 4月5日武汉滨会生物科技股份有限公司(简称:“滨会生物”)日前更新招股书,准备在港交所上市。滨会生物总计募资超10亿元,其中,2021年2月完成募资6亿元,2022年7月完成募资2.4亿元&a…...

OpenClaw云端体验指南:无需本地安装快速测试Phi-3-vision-128k-instruct
OpenClaw云端体验指南:无需本地安装快速测试Phi-3-vision-128k-instruct 1. 为什么选择云端体验OpenClaw 作为一个长期折腾本地AI部署的技术爱好者,我完全理解那种"想先试试再决定是否投入"的心态。去年尝试在MacBook Pro上部署Llama 2时&am…...

【2026 CVPR】Asking like Socrates: Socrates helps VLMs understand remote sensing images
RS-EoT (Remote Sensing Evidence-of-Thought) 研究旨在解决视觉语言模型(VLM)在处理遥感图像时的“虚假推理”问题 。 文章目录 核心问题 核心思想 核心方法 A. 数据合成:SocraticAgent Data Statistics B. 训练策略:两阶段渐进式强化学习 (RL) C. 训练策略 实验验证 主要…...

不要让接口过早失去可选项
这,是一个采用C精灵库编写的程序,它画了一幅漂亮的图形: 复制代码 #include "sprites.h" //包含C精灵库 Sprite turtle; //建立角色叫turtle void draw(int d){for(int i0;i<5;i)turtle.fd(d).left(72); } int main(){ …...
实现方案详解)
STM32远程固件升级(FOTA)实现方案详解
1. STM32远程升级方案概述在嵌入式设备开发中,远程固件升级(FOTA)是一项至关重要的功能。当设备部署在难以物理接触的场所时,通过无线或有线方式实现固件更新可以大幅降低维护成本。STM32系列单片机凭借其灵活的存储布局和丰富的通信接口,非常…...
 模块,可以直接加载和运行,通过PyTorch AI框架训练好的模型,而不需要安装PyTorch AI框架)
[具身智能-229]:OpenCV 的 DNN (Deep Neural Networks) 模块,可以直接加载和运行,通过PyTorch AI框架训练好的模型,而不需要安装PyTorch AI框架
OpenCV 的 DNN (Deep Neural Networks) 模块确实是工业界和边缘计算领域非常推崇的推理引擎。它的核心定位不是“训练模型”,而是“让训练好的模型跑得更快、更轻、更通用”。它允许开发者在不依赖庞大的 TensorFlow 或 PyTorch 库的情况下,直接在生产环…...

x86汇编堆栈
x86汇编堆栈 1)堆栈操作 x86汇编中的堆栈是一块特殊的内存区域,用于存储程序运行时的数据。它遵循"后进先出LIFO的原则",主要用于函数调用时的参数传递、局部变量存储以及保存返回地址。 堆栈操作的核心指令是PUSH和POP。PUSH指令将…...

电赛赛题深度解析:从五大类别到实战备赛策略
1. 电赛赛题五大类别全解析 全国大学生电子设计竞赛(简称电赛)作为电子类专业最具影响力的赛事,其赛题设置直接反映了行业技术发展趋势。经过对近十年赛题的统计分析,所有题目可明确划分为五大类别,每类都有独特的考察…...