如何使用.pth训练模型
一.使用.pth训练模型的步骤如下:
1.导入必要的库和模型
import torch
import torchvision.models as models# 加载预训练模型
model = models.resnet50(pretrained=True)2.定义数据集和数据加载器
# 定义数据集和数据加载器
dataset = MyDataset()
dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True)3.定义损失函数和优化器
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)4.训练模型
# 训练模型
for epoch in range(10):running_loss = 0.0for i, data in enumerate(dataloader, 0):inputs, labels = dataoptimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()if i % 2000 == 1999:print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 2000))running_loss = 0.05.保存模型
# 保存模型
torch.save(model.state_dict(), 'model.pth')二,使用自己训练的.pth模型进行训练的步骤如下:
1.导入必要的库和模型
import torch
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
from my_dataset import MyDataset # 自定义数据集
from my_model import MyModel # 自定义模型2.设置超参数和路径
batch_size = 32 # 批大小
num_epochs = 10 # 训练轮数
learning_rate = 0.001 # 学习率
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设置设备
train_data_path = 'train_data/' # 训练数据集路径
test_data_path = 'test_data/' # 测试数据集路径
model_path = 'my_model.pth' # 模型保存路径3.加载数据集
train_transforms = transforms.Compose([transforms.Resize((224, 224)), # 调整图像大小transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 转换为张量transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 标准化
])test_transforms = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])train_dataset = MyDataset(train_data_path, train_transforms) # 自定义数据集
test_dataset = MyDataset(test_data_path, test_transforms)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 训练集加载器
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 测试集加载器4.加载模型
model = MyModel() # 自定义模型
model.load_state_dict(torch.load(model_path)) # 加载.pth模型
model.to(device) # 将模型移动到设备上5.定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate) # Adam优化器6.训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):images = images.to(device)labels = labels.to(device)outputs = model(images)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 100 == 0:print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))torch.save(model.state_dict(), 'fine_tuned_model.pth') # 保存.pth模型7.测试模型
model.eval() # 切换到评估模式
with torch.no_grad():correct = 0total = 0for images, labels in test_loader:images = images.to(device)labels = labels.to(device)outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Accuracy of the network on the test images: {} %'.format(100 * correct / total))相关文章:

如何使用.pth训练模型
一.使用.pth训练模型的步骤如下: 1.导入必要的库和模型 import torch import torchvision.models as models# 加载预训练模型 model models.resnet50(pretrainedTrue) 2.定义数据集和数据加载器 # 定义数据集和数据加载器 dataset MyDataset() dataloader to…...
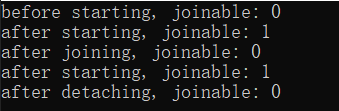
C++11线程以及线程同步
C11中提供的线程类std::thread,基于此类创建一个新的线程相对简单,只需要提供线程函数和线程对象即可 一.命名空间 this_thread C11 添加一个关于线程的命名空间std::this_pthread ,此命名空间中提供四个公共的成员函数; 1.1 get_id() 调用命名空间s…...
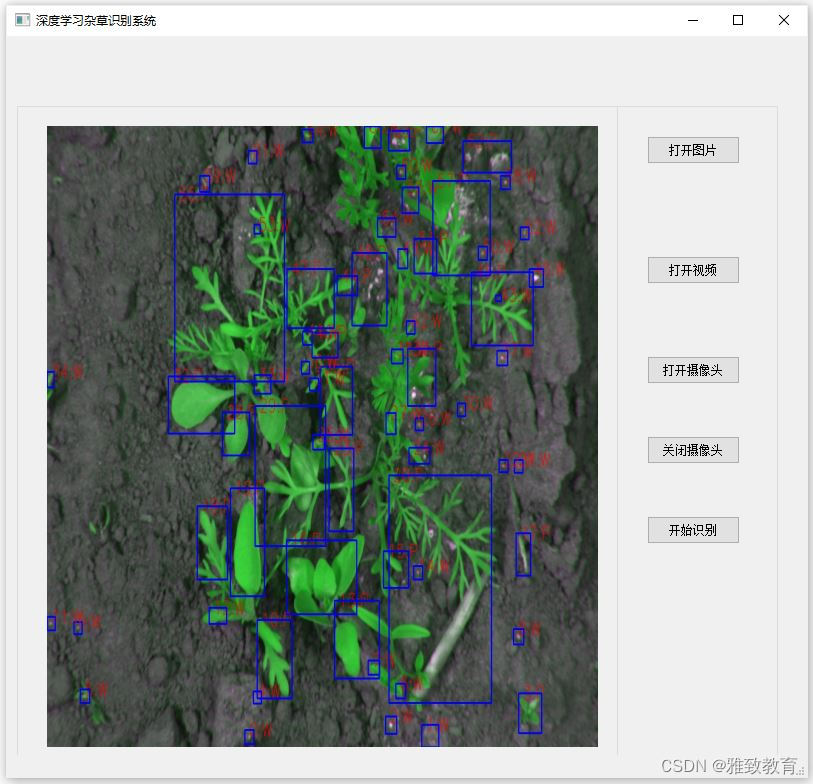
深度学习之基于YoloV3杂草识别系统
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 深度学习在图像识别领域已经取得了显著的成果,其中基于YOLO(You Only Look Once)…...

Linux 命令vim(编辑器)
(一)vim编辑器的介绍 vim是文件编辑器,是vi的升级版本,兼容vi的所有指令,同时做了优化和延伸。vim有多种模式,其中常用的模式有命令模式、插入模式、末行模式:。 (二)vim编辑器基本操作 1 进入vim编辑文件 1 vim …...

轻松配置PPPoE连接:路由器设置和步骤详解
在家庭网络环境中,我们经常使用PPPoE(点对点协议过夜)连接来接入宽带互联网。然而,对于一些没有网络专业知识的人来说,配置PPPoE连接可能会有些困难。在本文中,我将详细介绍如何轻松配置PPPoE连接ÿ…...
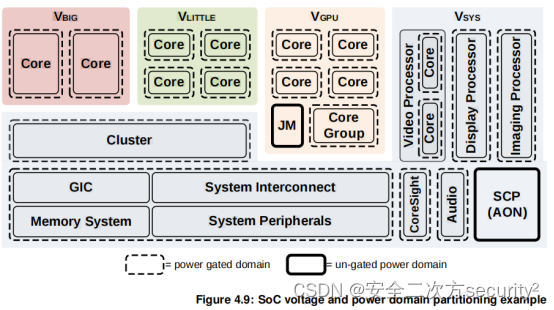
电源控制系统架构(PCSA)之系统分区电源域
目录 4.2 电源域 4.2.1 电源模式 4.2.2 电源域的选择 4.2.3 系统逻辑 4.2.4 Always-On域 4.2.5 处理器Clusters 4.2.6 CoreSight逻辑 4.2.7 图像处理器 4.2.8 显示处理器 4.2.9 其他功能 4.2.10 电源域层次结构要求 4.2.11 SOC域示例 4.2 电源域 电源域在这里被定…...

Linux:docker基础操作(3)
docker的介绍 Linux:Docker的介绍(1)-CSDN博客https://blog.csdn.net/w14768855/article/details/134146721?spm1001.2014.3001.5502 通过yum安装docker Linux:Docker-yum安装(2)-CSDN博客https://blog.…...

【Axure教程】用中继器制作卡片多条件搜索效果
卡片设计通过提供清晰的信息结构、可视化吸引力、易扩展性和强大的交互性,为用户界面设计带来了许多优势,使得用户能够更轻松地浏览、理解和互动。 那今天就教大家如何用中继器制作卡片的模板,以及完成多条件搜索的效果,我们会以…...
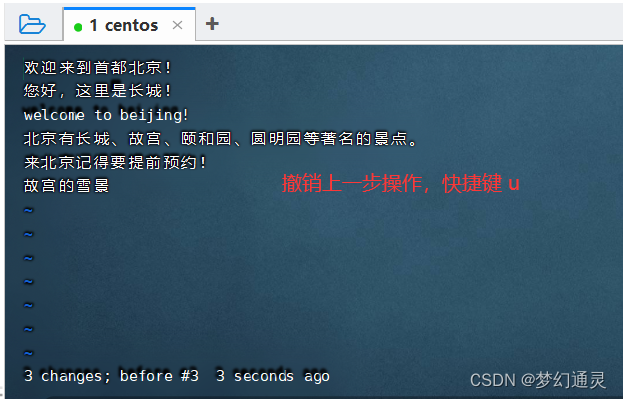
Linux中vi常用命令-批量替换
在日常服务器日志查看中常用到的命令有grep、tail等,有时想查看详细日志,用到vi命令,记录下来,方便查看。 操作文件:test.properites 一、查看与编辑 查看命令:vi 文件名 编辑命令:按键 i&…...

logback-spring.xml的内容格式
目录 一、logback-spring.xml 二、Logback 中的三种日志文件类型 一、logback-spring.xml <?xml version"1.0" encoding"UTF-8"?> <configuration scan"true" scanPeriod"10 seconds" ><!-- <statusListener…...
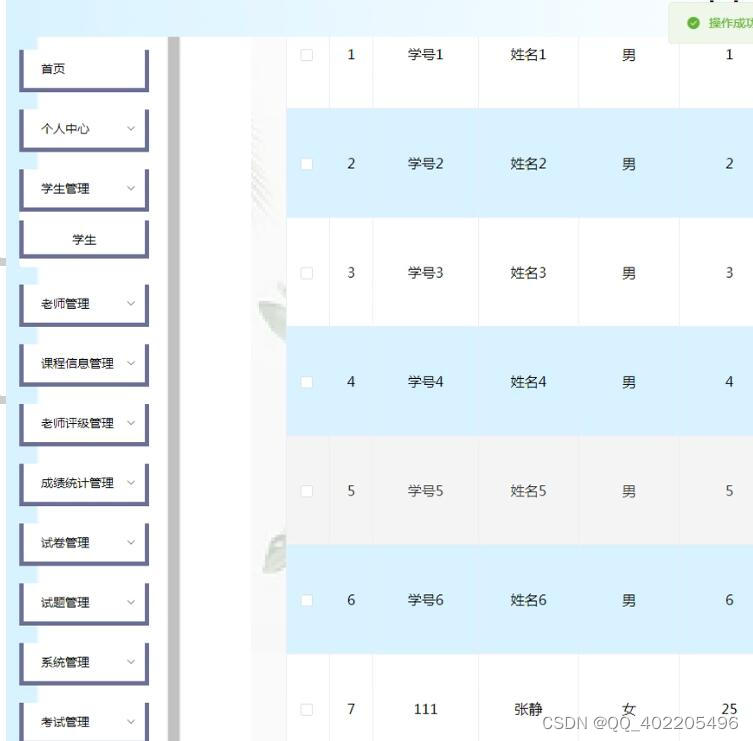
nodejs+vue+elementui+express青少年编程课程在线考试系统
针对传统线下考试存在的老师阅卷工作量较大,统计成绩数据时间长等问题,实现一套高效、灵活、功能强大的管理系统是非常必要的。该系统可以迅速完成随机组卷,及时阅卷、统计考试成绩排名的效果。该考试系统要求:该系统将采用B/S结构…...
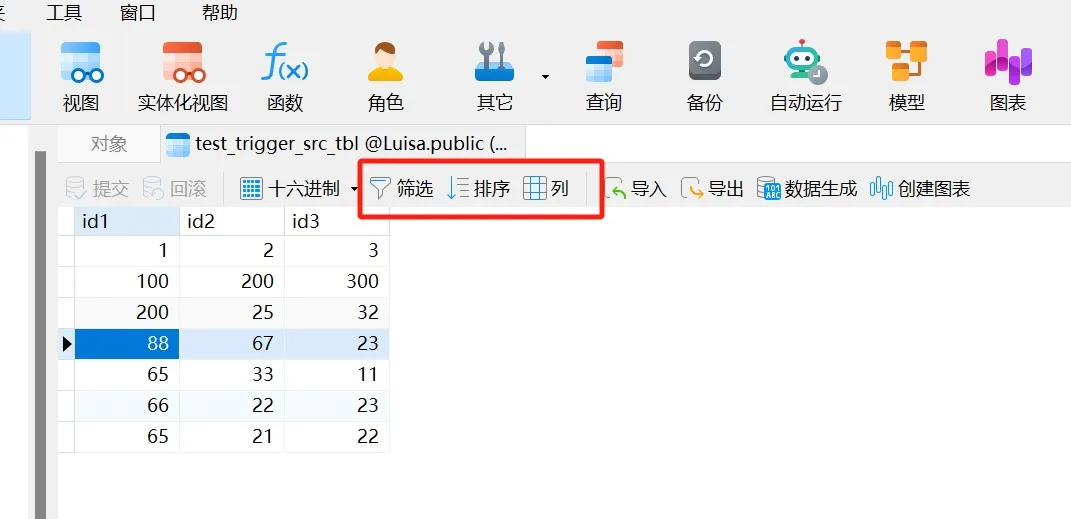
Navicat 技术指引 | GaussDB 数据查看器
Navicat Premium(16.2.8 Windows版或以上) 已支持对GaussDB 主备版的管理和开发功能。它不仅具备轻松、便捷的可视化数据查看和编辑功能,还提供强大的高阶功能(如模型、结构同步、协同合作、数据迁移等),这…...

Docker的registry
简介 地址:https://hub.docker.com/_/registry Dcoker registry是存储Dcoker image的仓库,运行push,pull,search时,是通过Dcoker daemon与docker registry通信。有时候会用Dcoker Hub这样的公共仓库可能不方便&#x…...
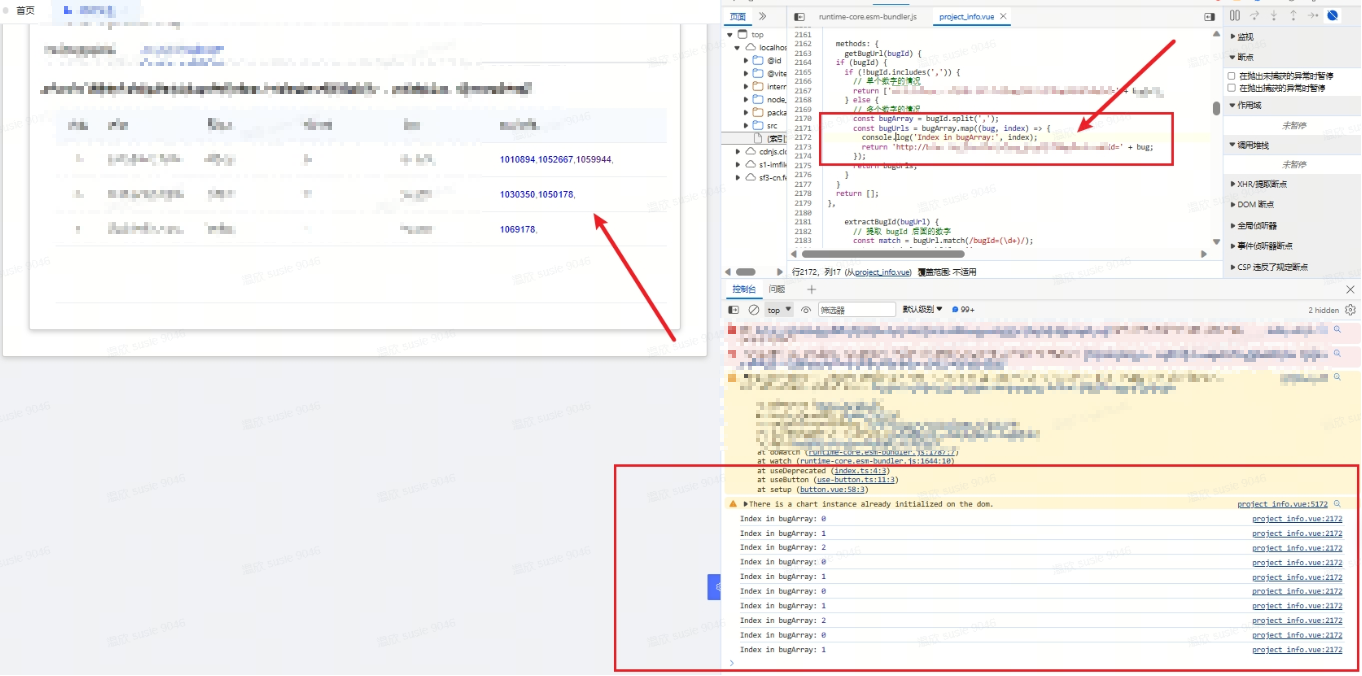
【vue_3】关于超链接的问题
1、需求2、修改前的代码3、修改之后(1)第一次(2)第二次(3)第三次(4)第四次(5)第五次 1、需求 需求:要给没有超链接的列表添加软超链接 2、修改前…...

redis优化秒杀和消息队列
redis优化秒杀 1. 异步秒杀思路1.1 在redis存入库存和订单信息1.2 具体流程图 2. 实现2.1 总结 3. Redis的消息队列3.1 基于list实现消息队列3.2 基于PubSub实现消息队列3.3 基于stream实现消息队列3.3.1 stream的单消费模式3.3.2 stream的消费者组模式 3.4 基于stream消息队列…...

arm-eabi-gcc 和 arm-none-eabi-gcc 都是基于 GCC 的交叉编译器
arm-eabi-gcc 和 arm-none-eabi-gcc 都是基于 GCC 的交叉编译器,用于编译 ARM 架构的嵌入式系统。它们的命名规则如下: arm 表示目标架构是 ARM。eabi 表示嵌入式应用程序二进制接口(Embedded Application Binary Interface)&…...

《大话设计模式》(持续更新中)
《大话设计模式》 序 为什么要学设计模式第0章 面向对象基础什么是对象?什么是类?什么是构造方法?什么是重载?属性与字段有什么区别?什么是封装?什么是继承?什么是多态?抽象类的目的…...

人工智能原理复习--绪论
文章目录 人工智能原理概述图灵测试人工智能的研究方法符号主义连接主义行为主义总结 人工智能原理概述 人工智能是计算机科学基础理论研究的重要组成部分 现代人工智能一般认为起源于美国1956你那夏季的达特茅斯会议,在这次会议上,John McCarthy第一次…...

[网络] 字节一面~ 2. HTTP 2 与 HTTP 1.x 有什么区别
头部压缩 在 HTTP2 当中,如果你发出了多个请求,并且它们的头部(header)是相同的,那么 HTTP2 协议会帮你消除同样的部分。(其实就是在客户端和服务端维护一张索引表来实现)二进制格式 HTTP1.1 采用明文的形式 HTTP/2 全⾯采⽤了⼆进制格式&…...

自己动手实现一个深度学习算法——八、深度学习
深度学习是加深了层的深度神经网络。 1.加深网络 1)向更深的网络出发 创建一个如下图所示的网络结构的CNN 这个网络的层比之前实现的网络都更深。这里使用的卷积层全都是33 的小型滤波器,特点是随着层的加深,通道数变大(卷积…...

CANOE进阶:CAPL文件读写实战与数据持久化策略
1. CAPL文件读写在车载测试中的核心价值 第一次接触CAPL文件读写功能时,我正负责一个车载ECU的耐久性测试项目。当时需要连续记录72小时的CAN报文数据,如果仅靠CANoe的Trace窗口查看,不仅效率低下,后期分析更是无从下手。这时我才…...

3步精通UndertaleModTool:解锁GameMaker游戏修改全流程
3步精通UndertaleModTool:解锁GameMaker游戏修改全流程 【免费下载链接】UndertaleModTool The most complete tool for modding, decompiling and unpacking Undertale (and other GameMaker games!) 项目地址: https://gitcode.com/gh_mirrors/un/UndertaleModT…...

BiliTools:2026年最强大的免费哔哩哔哩资源管理工具终极指南
BiliTools:2026年最强大的免费哔哩哔哩资源管理工具终极指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...
突破语言壁垒:XUnity Auto Translator全场景应用指南
突破语言壁垒:XUnity Auto Translator全场景应用指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 当玩家面对一款画面精美却语言不通的Unity游戏时,那种渴望深入剧情却受制于语…...

【带AI】基于SpringBoot+Vue图书管理系统设计与实现+文档+指导搭建视频
特色实现QQ邮箱注册/找回密码,WebSocket实时推送,协同过滤算法图书推荐,接入DeepSeek大模型技术栈 1.后端:Spring Boot2、MyBatis、Java Mail(QQ SMTP)、WebSocket、DevTools、Spring Security Crypto&…...

3分钟学会用Greasy Fork终极改造你的浏览器:从零到精通的完整指南
3分钟学会用Greasy Fork终极改造你的浏览器:从零到精通的完整指南 【免费下载链接】greasyfork An online repository of user scripts. 项目地址: https://gitcode.com/gh_mirrors/gr/greasyfork 你是否厌倦了千篇一律的网页浏览体验?是否想过让…...

Win11Debloat系统优化全指南:从卡顿到流畅的蜕变之路
Win11Debloat系统优化全指南:从卡顿到流畅的蜕变之路 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and cus…...

实战演练:基于快马平台快速开发与部署plc数据监控web应用
最近在做一个工业自动化的小项目,需要搭建一个PLC数据监控的Web应用。作为一个经常需要快速验证想法的开发者,我选择了InsCode(快马)平台来快速实现这个需求。整个过程比想象中顺利很多,下面分享下具体实现思路和关键点。 系统架构设计 这个项…...

分人群AI建站工具解决方案:中小企、创业者、外贸人、创作者怎么选?
分人群AI建站工具解决方案:中小企、创业者、外贸人、创作者怎么选?同样是找“AI建站工具”,一个个体摄影师和一个初创公司老板,心里的需求清单可能完全不同。这篇内容我们就来对不同人群,分别给出适合的建站思路和工具…...

AI辅助开发:利用快马智能生成技能学习路径推荐算法
AI辅助开发:利用快马智能生成技能学习路径推荐算法 最近在做一个技能学习平台的项目,需要实现一个智能推荐系统。作为独立开发者,面对复杂的推荐算法和数据处理逻辑有点无从下手。这时候发现了InsCode(快马)平台的AI辅助开发功能,…...