自己动手实现一个深度学习算法——八、深度学习
深度学习是加深了层的深度神经网络。
1.加深网络
1)向更深的网络出发
创建一个如下图所示的网络结构的CNN

这个网络的层比之前实现的网络都更深。这里使用的卷积层全都是3×3 的小型滤波器,特点是随着层的加深,通道数变大(卷积层的通道数从前面的层开始按顺序以16、16、32、32、64、64的方式增加)。
这个网络有如下特点。
• 基于 3×3 的小型滤波器的卷积层。
• 激活函数是 ReLU。
• 全连接层的后面使用 Dropout 层。
• 基于 Adam 的最优化。
• 使用 He 初始值作为权重初始值。
网络类的实现,deep_convnet类
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *class DeepConvNet:"""识别率为99%以上的高精度的ConvNet网络结构如下所示conv - relu - conv- relu - pool -conv - relu - conv- relu - pool -conv - relu - conv- relu - pool -affine - relu - dropout - affine - dropout - softmax"""def __init__(self, input_dim=(1, 28, 28),conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1},conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1},conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},hidden_size=50, output_size=10):# 初始化权重===========# 各层的神经元平均与前一层的几个神经元有连接(TODO:自动计算)pre_node_nums = np.array([1*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*4*4, hidden_size])wight_init_scales = np.sqrt(2.0 / pre_node_nums) # 使用ReLU的情况下推荐的初始值self.params = {}pre_channel_num = input_dim[0]for idx, conv_param in enumerate([conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]):self.params['W' + str(idx+1)] = wight_init_scales[idx] * np.random.randn(conv_param['filter_num'], pre_channel_num, conv_param['filter_size'], conv_param['filter_size'])self.params['b' + str(idx+1)] = np.zeros(conv_param['filter_num'])pre_channel_num = conv_param['filter_num']self.params['W7'] = wight_init_scales[6] * np.random.randn(64*4*4, hidden_size)self.params['b7'] = np.zeros(hidden_size)self.params['W8'] = wight_init_scales[7] * np.random.randn(hidden_size, output_size)self.params['b8'] = np.zeros(output_size)# 生成层===========self.layers = []self.layers.append(Convolution(self.params['W1'], self.params['b1'], conv_param_1['stride'], conv_param_1['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W2'], self.params['b2'], conv_param_2['stride'], conv_param_2['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Convolution(self.params['W3'], self.params['b3'], conv_param_3['stride'], conv_param_3['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W4'], self.params['b4'],conv_param_4['stride'], conv_param_4['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Convolution(self.params['W5'], self.params['b5'],conv_param_5['stride'], conv_param_5['pad']))self.layers.append(Relu())self.layers.append(Convolution(self.params['W6'], self.params['b6'],conv_param_6['stride'], conv_param_6['pad']))self.layers.append(Relu())self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))self.layers.append(Affine(self.params['W7'], self.params['b7']))self.layers.append(Relu())self.layers.append(Dropout(0.5))self.layers.append(Affine(self.params['W8'], self.params['b8']))self.layers.append(Dropout(0.5))self.last_layer = SoftmaxWithLoss()def predict(self, x, train_flg=False):for layer in self.layers:if isinstance(layer, Dropout):x = layer.forward(x, train_flg)else:x = layer.forward(x)return xdef loss(self, x, t):y = self.predict(x, train_flg=True)return self.last_layer.forward(y, t)def accuracy(self, x, t, batch_size=100):if t.ndim != 1 : t = np.argmax(t, axis=1)acc = 0.0for i in range(int(x.shape[0] / batch_size)):tx = x[i*batch_size:(i+1)*batch_size]tt = t[i*batch_size:(i+1)*batch_size]y = self.predict(tx, train_flg=False)y = np.argmax(y, axis=1)acc += np.sum(y == tt)return acc / x.shape[0]def gradient(self, x, t):# forwardself.loss(x, t)# backwarddout = 1dout = self.last_layer.backward(dout)tmp_layers = self.layers.copy()tmp_layers.reverse()for layer in tmp_layers:dout = layer.backward(dout)# 设定grads = {}for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):grads['W' + str(i+1)] = self.layers[layer_idx].dWgrads['b' + str(i+1)] = self.layers[layer_idx].dbreturn gradsdef save_params(self, file_name="params.pkl"):params = {}for key, val in self.params.items():params[key] = valwith open(file_name, 'wb') as f:pickle.dump(params, f)def load_params(self, file_name="params.pkl"):with open(file_name, 'rb') as f:params = pickle.load(f)for key, val in params.items():self.params[key] = valfor i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):self.layers[layer_idx].W = self.params['W' + str(i+1)]self.layers[layer_idx].b = self.params['b' + str(i+1)]训练类train_deepnet的实现
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from deep_convnet import DeepConvNet
from common.trainer import Trainer(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)network = DeepConvNet()
trainer = Trainer(network, x_train, t_train, x_test, t_test,epochs=20, mini_batch_size=100,optimizer='Adam', optimizer_param={'lr':0.001},evaluate_sample_num_per_epoch=1000)
trainer.train()# 保存参数
network.save_params("deep_convnet_params.pkl")
print("Saved Network Parameters!")权重参数保存在deep_conv_net_params.pkl
2)进一步提高识别精度
集成学习、学习率衰减、Data Augmentation(数据扩充)等都有助于提高识别精度。
Data Augmentation 基于算法“人为地”扩充输入图像(训练图像)。对于输入图像,通过施加旋转、垂直或水平方向上的移动等微小变化,增加图像的数量。这在数据集的图像数量有限时尤其有效。
3)加深层的动机
关于加深层的重要性,现状是理论研究还不够透彻。
层越深,识别性能也越高。
加深层一个好处就是可以减少网络的参数数量。加深层的另一个好处就是使学习更加高效。
通过加深层,可以将各层要学习的问题分解成容易解决的简单问题,从而可以进行高效的学习。
2.深度学习的小历史
现在深度学习之所以受到大量关注,其契机是2012年举办的大规模图像识别大赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge)。在那年的比赛中,基于深度学习的方法(通称 AlexNet)以压倒性的优势胜出,彻底颠覆了以往的图像识别方法。
1)ImageNet
是拥有超过100万张图像的数据集。它包含了各种各样的图像,并且每张图像都被关联了标签(类别名)。每年都会举办使用这个巨大数据集的ILSVRC图像识别大赛。
2)VGG
VGG 是由卷积层和池化层构成的基础的 CNN。它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层),具备了深度(根据层的深度,有时也称为“VGG16”或“VGG19”)。
3)GoogLeNet
GoogLeNet的特征是,网络不仅在纵向上有深度,在横向上也有深度(广度)。
GoogLeNet 在横向上有“宽度”,这称为“Inception 结构”,Inception结构使用了多个大小不同的滤波器(和池化),最后再合并它们的结果。
4)ResNet
它的特征在于具有比以前的网络更深的结构。我们已经知道加深层对于提升性能很重要。但是,在深度学习中,过度加深层的话,很多情况下学习将不能顺利进行,导致最终性能不佳。
3.深度学习的高速化
大多数深度学习的框架都支持GPU(Graphics Processing Unit),可以高速地处理大量的运算。
最近的框架也开始支持多个GPU或多台机器上的分布式学习。
1)需要努力解决的问题
AlexNex中,大多数时间都被耗费在卷积层上。如何高速、高效地进行卷积层中的运算是深度学习的一大课题。
2)基于GPU的高速化
GPU 原本是作为图像专用的显卡使用的,但最近不仅用于图像处理,也用于通用的数值计算。
由于GPU 可以高速地进行并行数值计算,因此GPU 计算的目标就是将这种压倒性的计算能力用于各种用途。所谓 GPU 计算,是指基于GPU进行通用的数值计算的操作。
深度学习中需要进行大量的乘积累加运算(或者大型矩阵的乘积运算)。这种大量的并行运算正是GPU所擅长的(反过来说,CPU比较擅长连续的、复杂的计算)。因此,与使用单个CPU相比,使用GPU进行深度学习的运算可以达到惊人的高速化。
3)分布式学习
为了进一步提高深度学习所需的计算的速度,可以考虑在多个GPU或者多台机器上进行分布式计算。现在的深度学习框架中,出现了好几个支持多GPU或者多机器的分布式学习的框架。
其中,Google的TensorFlow、微软的CNTK(Computational Network Toolki)在开发过程中高度重视分布式学习。以大型数据中心的低延迟·高吞吐网络作为支撑,基于这些框架的分布式学习呈现出惊人的效果。
“如何进行分布式计算”是一个非常难的课题。它包含了机器间的通信、数据的同步等多个无法轻易解决的问题。
4)运算精度的位数缩减
在深度学习的高速化中,除了计算量之外,内存容量、总线带宽等也有可能成为瓶颈。关于内存容量,需要考虑将大量的权重参数或中间数据放在内存中。关于总线带宽,当流经GPU(或者CPU)总线的数据超过某个限制时,就会成为瓶颈。考虑到这些情况,我们希望尽可能减少流经网络的数据的位数。
4.深度学习的应用案例
深度学习并不局限于物体识别,还可以应用于各种各样的问题。此外,在图像、语音、自然语言等各个不同的领域,深度学习都展现了优异的性能。
1)物体检测
物体检测是从图像中确定物体的位置,并进行分类的问题。
物体检测是比物体识别更难的问题。之前介绍的物体识别是以整个图像为对象的,但是物体检测需要从图像中确定类别的位置,而且还有可能存在多个物体。
对于这样的物体检测问题,人们提出了多个基于CNN的方法。这些方法展示了非常优异的性能,并且证明了在物体检测的问题上,深度学习是非常有效的。
在使用CNN进行物体检测的方法中,有一个叫作R-CNN的有名的方法。首先(以某种方法)找出形似物体的区域,然后对提取出的区域应用CNN进行分类。R-CNN 中会将图像变形为正方形,或者在分类时使用 SVM(支持向量机),实际的处理流会稍微复杂一些,不过从宏观上看,也是由刚才的两个处理(候选区域的提取和CNN特征的计算)构成的。
2)图像分割
图像分割是指在像素水平上对图像进行分类。使用以像素为单位对各个对象分别着色的监督数据进行学习。然后,在推理时,对输入图像的所有像素进行分类。
要基于神经网络进行图像分割,最简单的方法是以所有像素为对象,对每个像素执行推理处理。比如,准备一个对某个矩形区域中心的像素进行分类的网络,以所有像素为对象执行推理处理。正如大家能想到的,这样的方法需要按照像素数量进行相应次forward处理,因而需要耗费大量的时间(正确地说,卷积运算中会发生重复计算很多区域的无意义的计算)。为了解决这个无意义的计算问题,有人提出了一个名为FCN的方法。该方法通过一次forward处理,对所有像素进行分类
FCN 的字面意思是 “全部由卷积层构成的网络”。相对于一般的 CNN 包含全连接层,FCN将全连接层替换成发挥相同作用的卷积层。
FCN的特征在于最后导入了扩大空间大小的处理。
3)图像标题的生成
一个基于深度学习生成图像标题的代表性方法是被称为 NIC(Neural Image Caption)的模型。
RNN是呈递归式连接的网络,经常被用于自然语言、时间序列数据等连续性的数据上。
我们将组合图像和自然语言等多种信息进行的处理称为多模态处理。多模态处理是近年来备受关注的一个领域。
5.深度学习的未来
1)图像风格变换
两个输入图像中,一个称为“内容图像”,另一个称为“风格图像”。
2)图像的生成
现在有一种研究是生成新的图像时不需要任何图像(虽然需要事先使用大量的图像进行学习,但在“画”新图像时不需要任何图像)。
3)自动驾驶
4)Deep Q-Network(强化学习)
就像人类通过摸索试验来学习一样(比如骑自行车),让计算机也在摸索试验的过程中自主学习,这称为强化学习(reinforcement learning)。强化学习和有“教师”在身边教的“监督学习”有所不同。
强化学习的基本框架是,代理(Agent)根据环境选择行动,然后通过这个行动改变环境。根据环境的变化,代理获得某种报酬。强化学习的目的是决定代理的行动方针,以获得更好的报酬
相关文章:
自己动手实现一个深度学习算法——八、深度学习
深度学习是加深了层的深度神经网络。 1.加深网络 1)向更深的网络出发 创建一个如下图所示的网络结构的CNN 这个网络的层比之前实现的网络都更深。这里使用的卷积层全都是33 的小型滤波器,特点是随着层的加深,通道数变大(卷积…...

js闭包的必要条件及创建和消失(生命周期)
>创建闭包的必要条件: 1.函数嵌套 2.内部函数引用外部函数的变量 3.将内部函数作为返回值返回 >闭包是什么? 就是可以访问外部函数(作用域)中变量的内部函数 > 闭包是什么时候产生的? - 当调用外部函数…...
鸿蒙开发-ArkTS 语言-基础语法
[写在前面: 文章多处用到gif动图,如未自动播放,请点击图片] 1. 初识 ArkTS 语言 ArkTS 是 HarmonyOS 优选主力开发语言。ArkTS 是基于 TypeScript (TS) 扩展的一门语言,继承了 TS 的所有特性,是TS的超集。 主要是扩展了以下几个方…...

GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF 文章目录 GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHFPretraining 预训练阶段Supervised FineTuning (SFT&#x…...

电子学会C/C++编程等级考试2022年03月(三级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:和数 给定一个正整数序列,判断其中有多少个数,等于数列中其他两个数的和。 比如,对于数列1 2 3 4, 这个问题的答案就是2, 因为3 = 2 + 1, 4 = 1 + 3。 时间限制:10000 内存限制:65536输入 共两行,第一行是数列中数的个数…...

理解 JUnit, JaCoCo 到 SonarQube 的过程及 Maven 配置
Java 项目需要产生单元测试及代码覆盖率的话一直都是走的 JUnit 单元测试,JaCoCo 基于测试产生测试覆盖率,然后送到 SonarQube 去展示这条路子。当然 SonarQube 还可以帮我们进行代码的静态分析。但对其中的具体使用及过程知晓的并不深,基本就…...

人工智能关键技术决定机器人产业的前途
人工智能(Artificial Intelligence,AI)是指让计算机或机器具有类似于人类的智能和学习能力的技术。人工智能技术与机器人技术的结合将改变传统的机器人行业格局,就像智能手机对传统手机的颠覆一样。本文从人工智能技术的发展趋势、…...

2023华为ICT网络初赛试题回顾
所有题目都只能用来学习交流,禁止用于非法不公平的使用,如有侵权,该文章立刻删除。 1、某机房没有合适长度的网线,现需手工制作一个568B标准的双纹线,那么应按照以下哪一线序进行制作? A.绿白,绿,蓝&#…...

Hands-on Machine Learning with Scikit-Learn,Keras TensorFlow
读书记录(缓慢更新) 目录 Part 1. The Fundamentals of Machine Learning The Content of The Machine Learning Landscape The Machine Learning Landscape Part 1. The Fundamentals of Machine Learning The Content of The Machine Learning Landscape Part 1. The F…...

242. 有效的字母异位词
这篇文章会收录到 :算法通关村第十二关-白银挑战字符串经典题目-CSDN博客 242. 有效的字母异位词 描述 : 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t …...

TUP通信——与多个客户端同时通信
一,概括:可以通过多线程思想每加一个客户端由线程池中的主线程交给一个子线程管理 二,案例 (1),线程池 (2),服务端 (3),客户端...
基于helm的方式在k8s集群中部署gitlab - 备份恢复(二)
接上一篇 基于helm的方式在k8s集群中部署gitlab - 部署(一),本篇重点介绍在k8s集群中备份gitlab的数据,并在虚拟机上部署相同版本的gitlab,然后将备份的数据进行还原恢复 文章目录 1. 备份2. 恢复到虚拟机上的gitlab2.…...
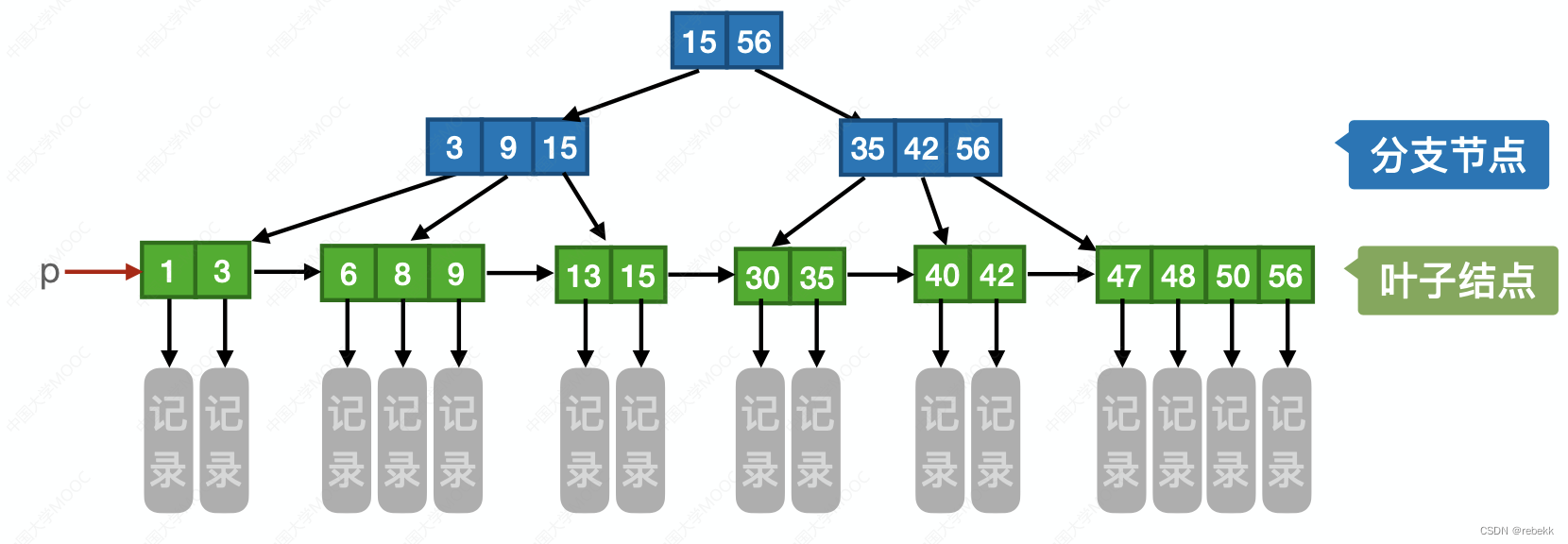
B树与B+树的对比
B树: m阶B树的核心特性: 树中每个节点至多有m棵子树,即至多含有m-1个关键字根节点的子树数属于[2, m],关键字数属于[1, m-1],其他节点的子树数属于 [ ⌈ m 2 ⌉ , m ] [\lceil \frac{m}{2}\rceil, m] [⌈2m⌉,m]&am…...

关键路径-STL版/拓扑排序 关键路径【数据结构】
关键路径-STL版 题目描述 给定有向图无环的边信息,求每个顶点的最早开始时间、最迟开始时间。 输入 第一行图的顶点总数 第二行边的总数 第三行开始,每条边的时间长度,格式为源结点 目的结点 长度 输出 第一行:第个顶点的最早…...
最新AI创作系统ChatGPT系统运营源码,支持GPT-4图片对话能力,上传图片并识图理解对话,支持DALL-E3文生图
一、AI创作系统 SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧!本系统使用NestjsVueTypescript框架技术,持续集成AI能力到本系统。支持OpenAI DALL-E3文生图,…...

小航助学题库蓝桥杯题库stem选拔赛(21年3月)(含题库教师学生账号)
需要在线模拟训练的题库账号请点击 小航助学编程在线模拟试卷系统(含题库答题软件账号)_程序猿下山的博客-CSDN博客 需要在线模拟训练的题库账号请点击 小航助学编程在线模拟试卷系统(含题库答题软件账号)_程序猿下山的博客-CSD…...
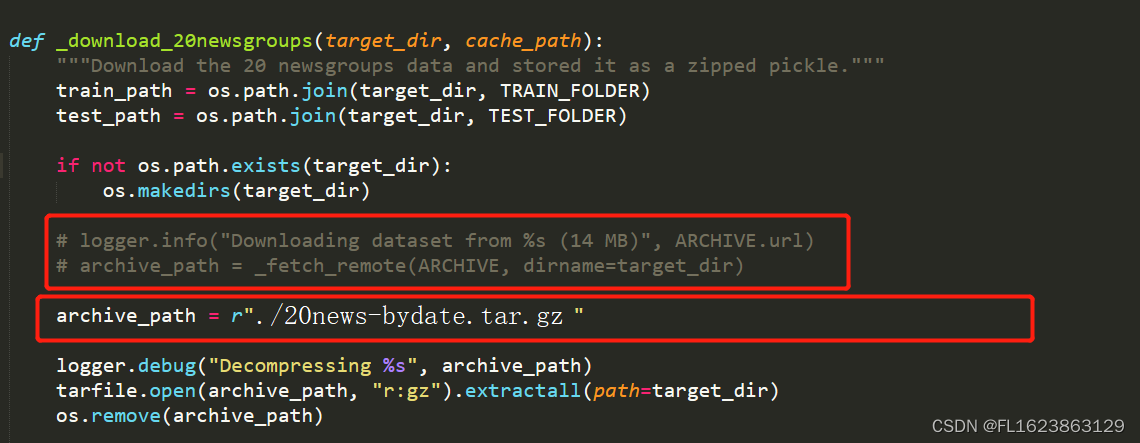
[python]离线加载fetch_20newsgroups数据集
首先手动下载这个数据包 http://qwone.com/~jason/20Newsgroups/20news-bydate.tar.gz 下载这个文件后和脚本放一起就行,然后 打开twenty_newsgroups.py文件(在fetch_20newsgroups函数名上,右键转到定义即可找到) 之后运行代码即…...

Python与设计模式--代理模式
5-Python与设计模式–代理模式 一、网络服务器配置白名单 代理模式是一种使用频率非常高的模式,在多个著名的开源软件和当前多个著名的互联网产品后 台程序中都有所应用。下面我们用一个抽象化的简单例子,来说明代理模式。首先,构造一个网…...

ubuntu挂载磁盘,以及开机自动挂载磁盘
1. 挂载临时磁盘(关机自动取消挂载) 在Ubuntu上挂载磁盘涉及到几个步骤,其中包括查看可用磁盘、创建挂载点、编辑 /etc/fstab 文件以确保在系统启动时自动挂载等。以下是一般的步骤: **查看可用磁盘和分区:**可以使用…...
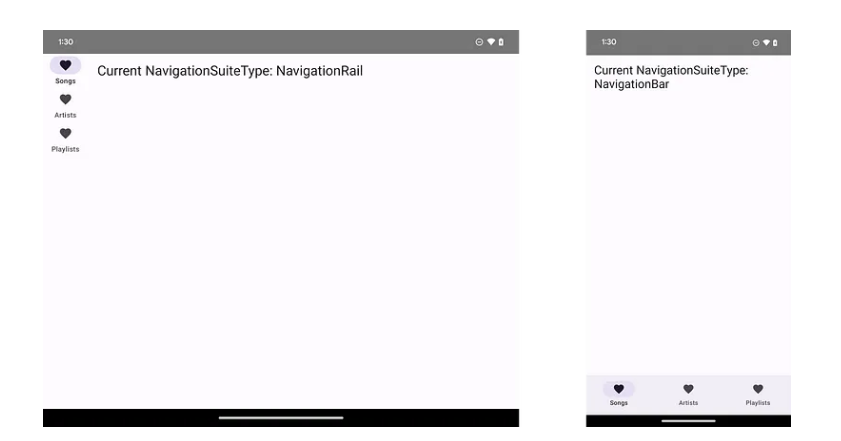
Jetpack Compose中适应性布局的新API
Jetpack Compose中适应性布局的新API 针对大屏幕优化的新组合件。 使用新的Material适应性布局,为手机、可折叠设备和平板电脑构建应用程序变得更加简单!市场上各种不同尺寸的Android设备的存在挑战了构建应用程序时对屏幕尺寸的通常假设。开发者不应该…...

蓝桥杯19725最优分组
import java.util.Scanner; // 1:无需package // 2: 类名必须Main, 不可修改public class Main {public static void main(String[] args) {Scanner scanner new Scanner(System.in);int n scanner.nextInt();double p scanner.nextDouble();double minCost Double.MAX_VAL…...

深入理解Python @dataclass:从基础到高级用法
Python 3.7引入了dataclass装饰器,这是一个强大的工具,能够显著减少数据类的样板代码。本文将详细介绍dataclass的各种用法,特别是如何正确处理可变默认值和类型注解。 什么是dataclass dataclass是位于dataclasses模块中的装饰器,…...
✅)
计算机毕业设计:Python二手车分析与定价系统 Django框架 可视化 线性回归 数据分析 机器学习 深度学习 AI 大模型(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,…...

2025届学术党必备的六大降AI率方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 面向维普系统针对人工智能生成内容的识别机制,要降低AI检测率就得采取系统化策略…...

决策树:从入门到精通,一个算法搞定分类与回归
还在为选择什么算法发愁?决策树既能分类又能回归,解释性还超强,今天带你彻底搞懂它一、引言如果你正在学习机器学习,那么决策树绝对是你绕不开的一道坎。为什么?因为它太实用了——银行用它来判断是否给用户批贷款&…...

别再让数据睡大觉了!手把手教你用泛微Ecology10的报表分析模块,10分钟搞定业务看板
唤醒沉睡数据:10分钟用泛微Ecology10打造动态业务看板 每天早晨,市场部张经理都会收到IT部门发来的Excel报表——那是前一天的销售数据汇总。等他费劲地对比完各个sheet,再手动合并ERP的库存信息时,往往已经过去半小时。更糟的是&…...

新手福音:无需下载安装,在快马平台直接上手体验wsl开发
作为一个刚接触WSL的新手,最头疼的就是漫长的下载安装过程。记得我第一次尝试在Windows上安装WSL时,光是等待wsl --install命令完成就花了近一个小时,中间还因为网络问题失败了好几次。这种体验对初学者来说真的很劝退。 后来我发现了一个更简…...

3大技术突破让shadPS4模拟器实现跨平台PS4游戏体验
3大技术突破让shadPS4模拟器实现跨平台PS4游戏体验 【免费下载链接】shadPS4 PS4 emulator for Windows,Linux,MacOS 项目地址: https://gitcode.com/gh_mirrors/shad/shadPS4 shadPS4作为一款开源的PS4模拟器,通过完全开源的模式和先进的技术架构࿰…...

Xinference 集群部署实战:从零到生产环境的完整指南
1. 为什么选择Xinference集群? 在AI模型推理领域,我们常常面临两个核心痛点:单机性能瓶颈和资源利用率低下。想象一下,你正在运行一个大型语言模型,每次推理都要等待十几秒,同时GPU利用率却只有30%左右——…...

新手福音:在快马平台通过实战示例快速上手w777.7cc框架
作为一名刚接触w777.7cc框架的前端新手,我最近在InsCode(快马)平台上发现了一个超实用的学习方法——通过实际修改和运行示例代码来理解框架特性。这种边做边学的方式,比单纯看文档效率高多了。下面分享我的学习笔记,记录如何用四个经典案例掌…...