Scrapy框架内置管道之图片视频和文件(一篇文章齐全)
1、Scrapy框架初识(点击前往查阅)
2、Scrapy框架持久化存储(点击前往查阅)
3、Scrapy框架内置管道
4、Scrapy框架中间件(点击前往查阅)

Scrapy 是一个开源的、基于Python的爬虫框架,它提供了强大而灵活的工具,用于快速、高效地提取信息。Scrapy包含了自动处理请求、处理Cookies、自动跟踪链接、下载中间件等功能
Scrapy框架的架构图(先学会再来看,就能看懂了!) 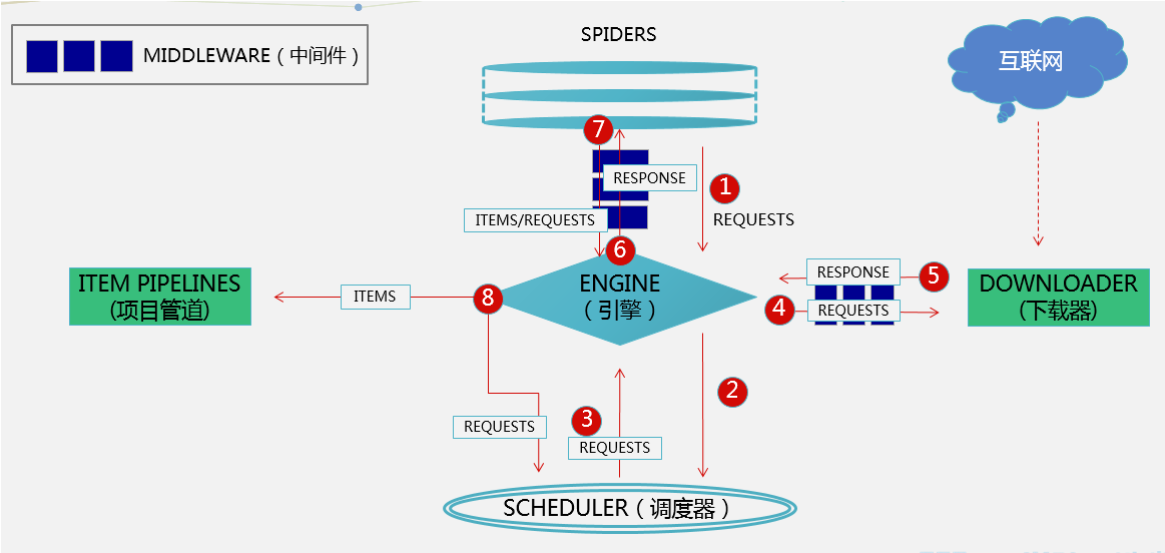
一、内置管道(图片视频)
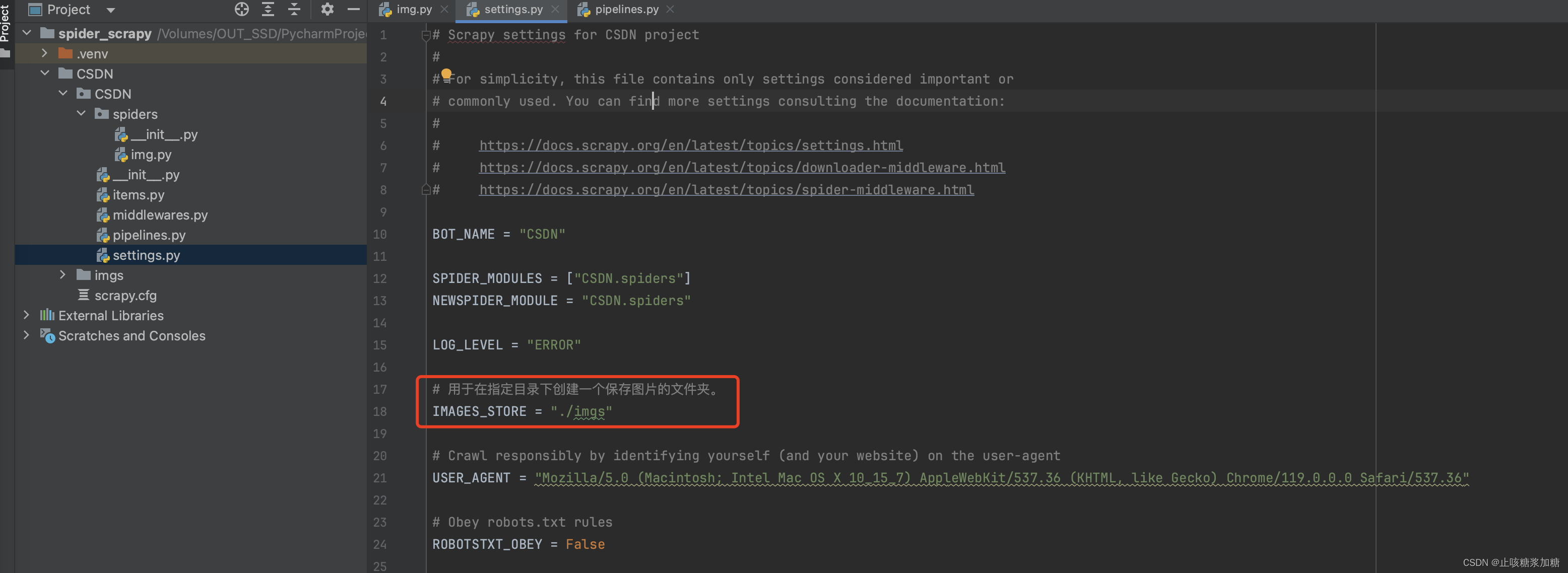
1:sttings设置
# 用于在指定目录下创建一个保存图片的文件夹。
IMAGES_STORE = "./imgs"其他的设置不理解的可以参考: Scrapy框架初识
2:数据分析
详细见图片中注视哦~
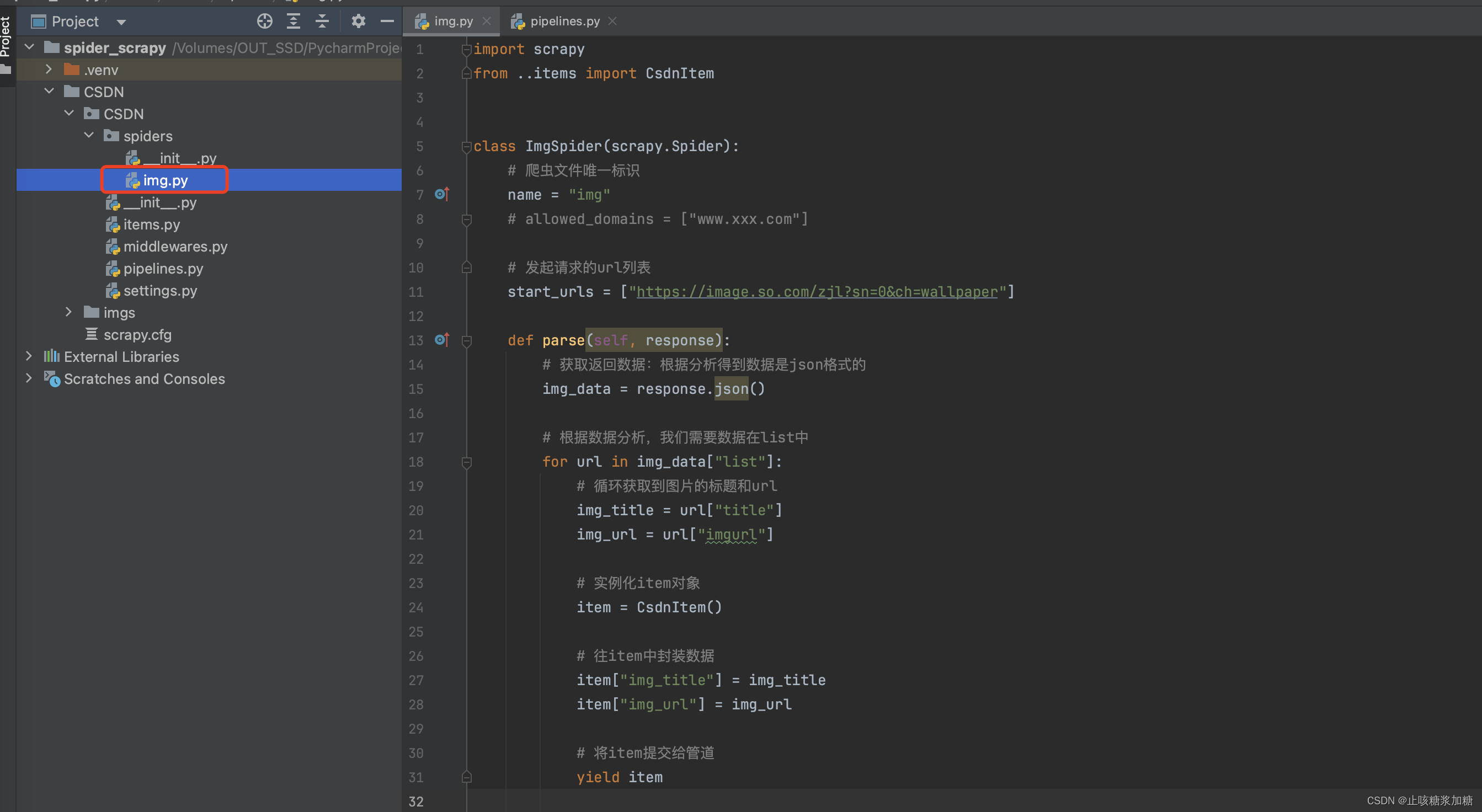
代码:
import scrapy
from ..items import CsdnItemclass ImgSpider(scrapy.Spider):# 爬虫文件唯一标识name = "img"# allowed_domains = ["www.xxx.com"]# 发起请求的url列表start_urls = ["https://image.so.com/zjl?sn=0&ch=wallpaper"]def parse(self, response):# 获取返回数据:根据分析得到数据是json格式的img_data = response.json()# 根据数据分析,我们需要数据在list中for url in img_data["list"]:# 循环获取到图片的标题和urlimg_title = url["title"]img_url = url["imgurl"]# 实例化item对象item = CsdnItem()# 往item中封装数据item["img_title"] = img_titleitem["img_url"] = img_url# 将item提交给管道yield item3:创建item对象
详细见图片中注视哦~
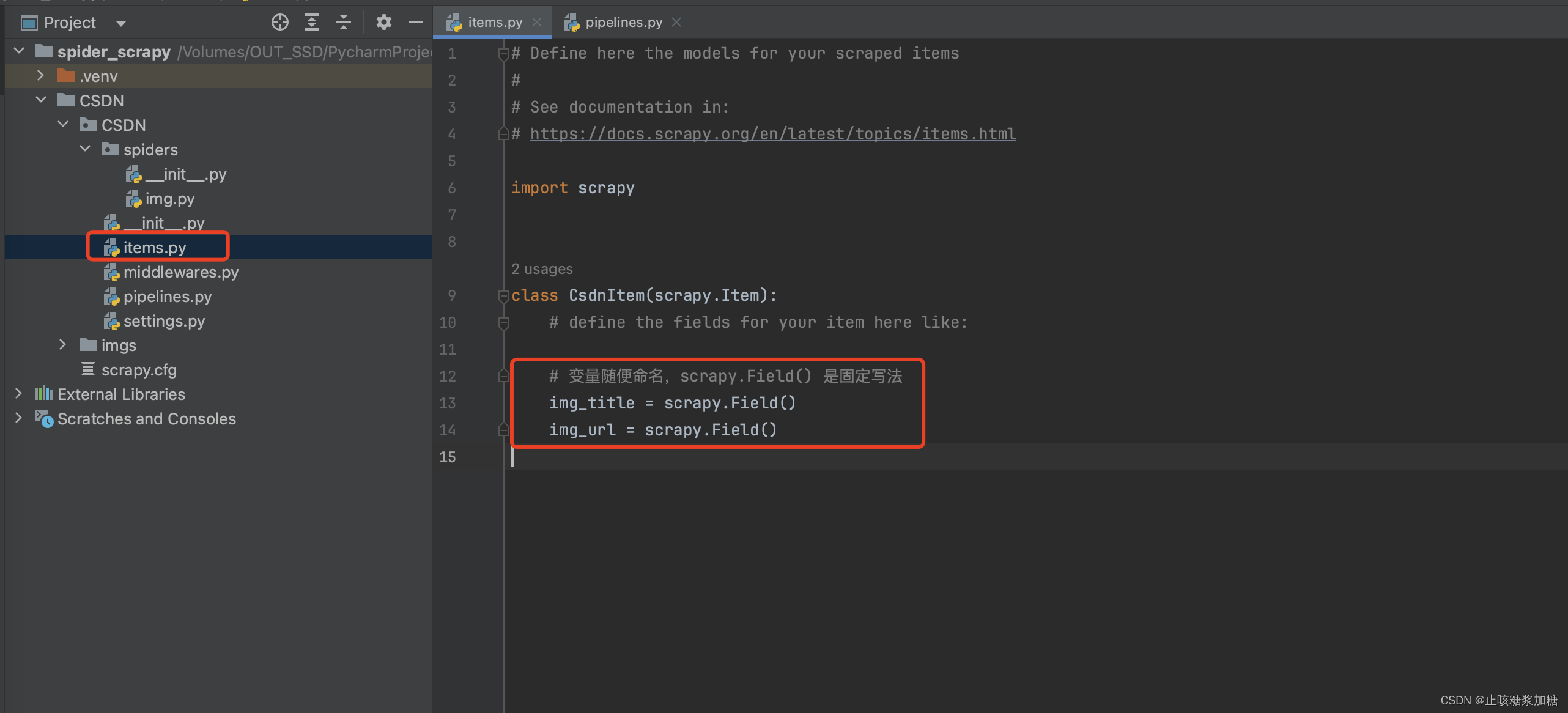
代码:
import scrapyclass CsdnItem(scrapy.Item):# define the fields for your item here like:# 变量随便命名,scrapy.Field() 是固定写法img_title = scrapy.Field()img_url = scrapy.Field()4:提交管道,持久化存储
4.1:模块安装
pip install pillow
4.2:代码分析
配合下方图片:
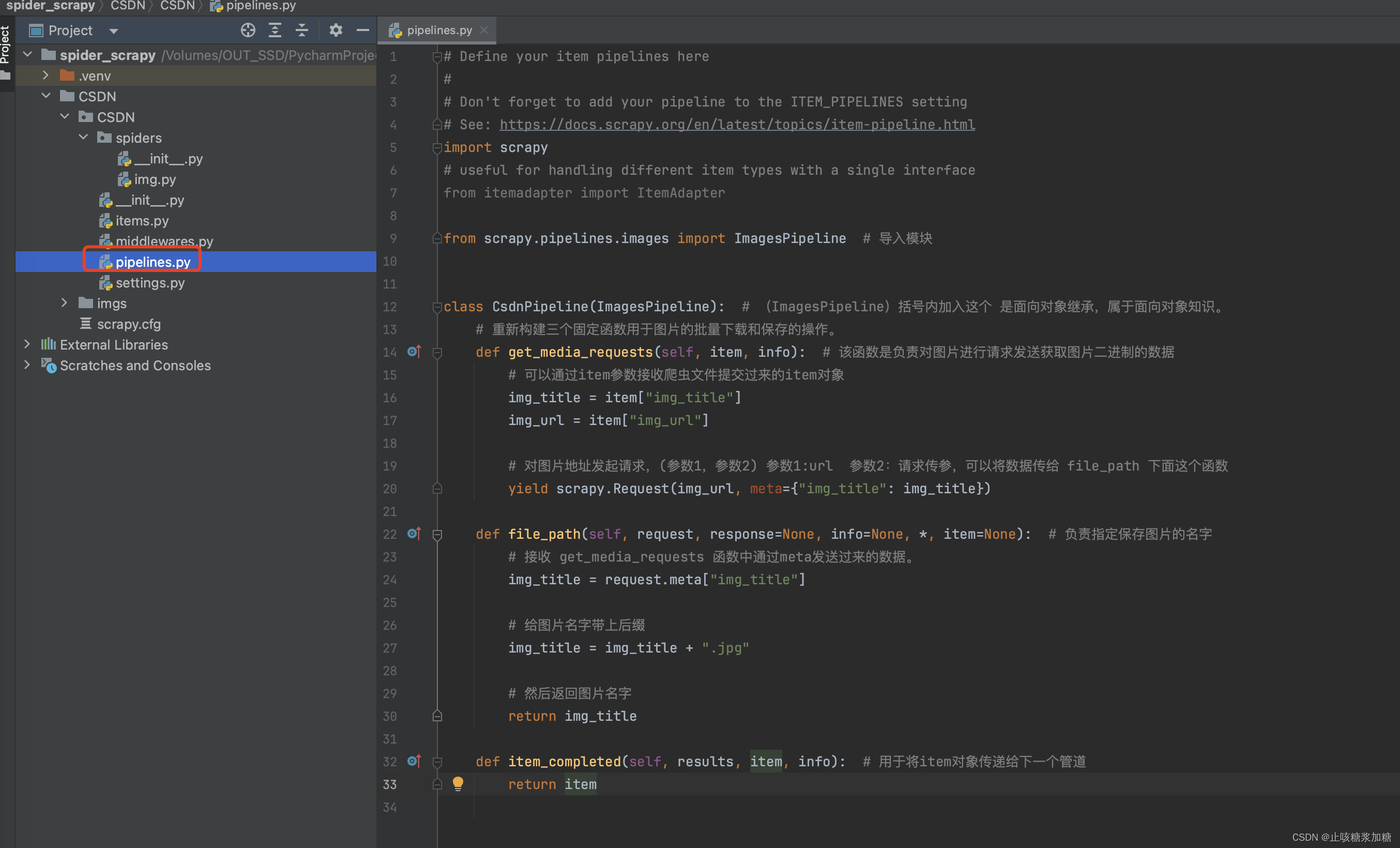
- 1、首先导入 ImagesPipeline 模块,然后class类继承。
- 2、重新构建三个固定函数用于图片的批量下载和保存的操作。
- get_media_requests函数:负责对图片进行请求发送获取图片二进制的数据。
- itme获取爬虫数据传过来的数据这个,不懂理解看这个:item相关知识
- yield发起请求这个是固定写法,参数意思可以看图中注释。
- file_path函数:负责指定保存图片的名字。
- 利用requests来获取上面传过来的数据。
- return返回的值就是图片的名字和后缀
- item_completed函数:用于将item对象传递给下一个管道。
- get_media_requests函数:负责对图片进行请求发送获取图片二进制的数据。
代码:
import scrapy
from scrapy.pipelines.images import ImagesPipeline # 导入模块class CsdnPipeline(ImagesPipeline): # (ImagesPipeline)括号内加入这个 是面向对象继承,属于面向对象知识。# 重新构建三个固定函数用于图片的批量下载和保存的操作。def get_media_requests(self, item, info): # 该函数是负责对图片进行请求发送获取图片二进制的数据# 可以通过item参数接收爬虫文件提交过来的item对象img_title = item["img_title"]img_url = item["img_url"]# 对图片地址发起请求,(参数1,参数2) 参数1:url 参数2:请求传参,可以将数据传给 file_path 下面这个函数yield scrapy.Request(img_url, meta={"img_title": img_title})def file_path(self, request, response=None, info=None, *, item=None): # 负责指定保存图片的名字# 接收 get_media_requests 函数中通过meta发送过来的数据。img_title = request.meta["img_title"]# 给图片名字带上后缀img_title = img_title + ".jpg"# 然后返回图片名字return img_titledef item_completed(self, results, item, info): # 用于将item对象传递给下一个管道return item
5:结果展示与总结
为什么会在这个文件夹中呢?因为刚开始的 settings 中,我们创建并指定了这个文件夹!!!
补充:在设置 settings 中,还可以设置图片的缩略图尺寸。

代码流程:
1.在爬虫文件中进行图片/视频的链接提取
2.将提取到的链接封装到items对象中,提交给管道
3.在管道文件中自定义一个父类为ImagesPipeline的管道类,且重写三个方法即可:
def get_media_requests(self, item, info):接收爬虫文件提交过来的item对象,然后对图片地址发起网路请求,返回图片的二进制数据def file_path(self, request, response=None, info=None, *, item=None):指定保存图片的名称 def item_completed(self, results, item, info):返回item对象给下一个管道类
二、内置管道(文件)
1:sttings设置
# 用于在指定目录下创建一个保存文件的文件夹。
FILES_STORE = "./file"其他的设置不理解的可以参考: Scrapy框架初识
2:数据分析
详细见图片中注视哦,比较简单,不做过多分析了~
代码:
import scrapy
from ..items import CsdnItem # 将item模块导入class FileSpider(scrapy.Spider):# 爬虫文件唯一标识name = "file"# allowed_domains = ["www.xxx.com"]# 发起请求的url列表start_urls = ["https://docs.twisted.org/en/stable/core/examples/"]def parse(self, response):# 解析到url列表url_list = response.xpath('//section[@id="examples"]/section[1]//ul//a/@href').extract()for url in url_list: # 分析得到URL不全。# 利用字符串分割拼接成一个完整的。url = url.split('../../')[-1]download_url = "https://docs.twisted.org/en/stable/" + url# 文件名称,就取链接的最后的title = url.split('/')[-1]# 创建item对象item = CsdnItem()# 封装值item['file_urls'] = download_urlitem['file_title'] = title# 将item提交给管道yield item
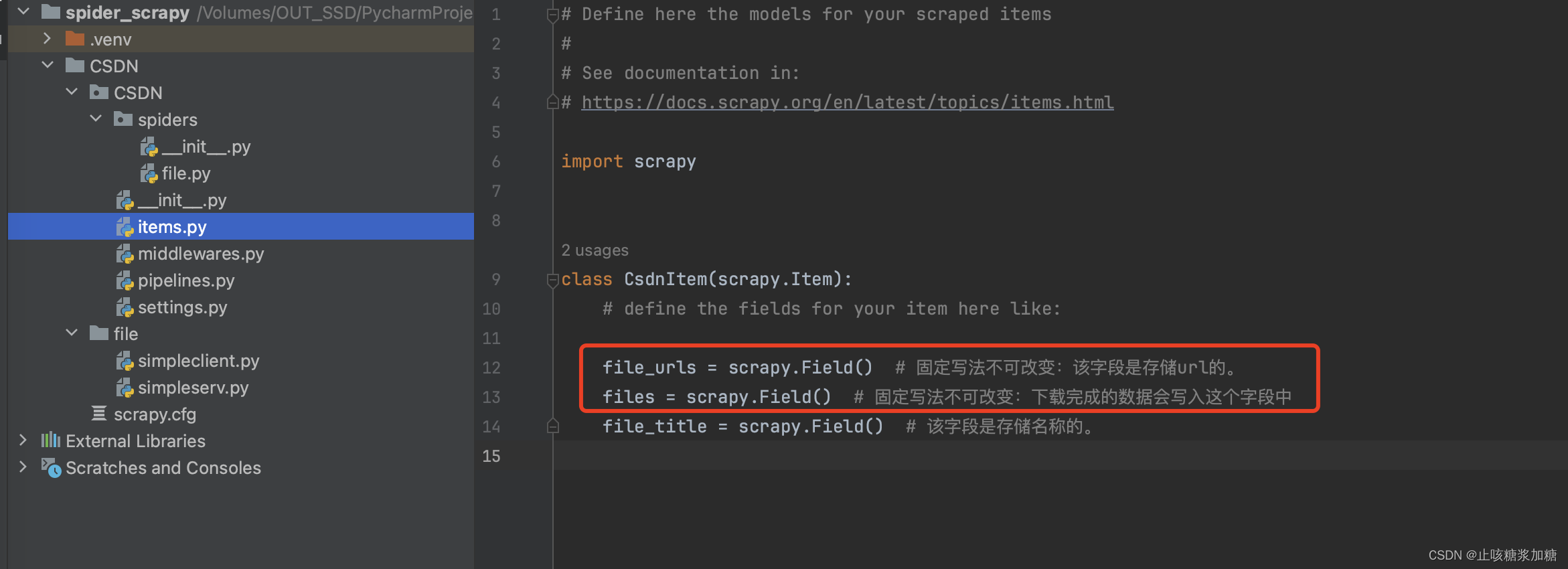
3:创建item对象
详细见图片中注视哦,与前面不同的是有2个字段是必须存在的。
4:提交管道,持久化存储
4.1:模块安装
pip install pillow
4.2:代码分析
配合下方图片:
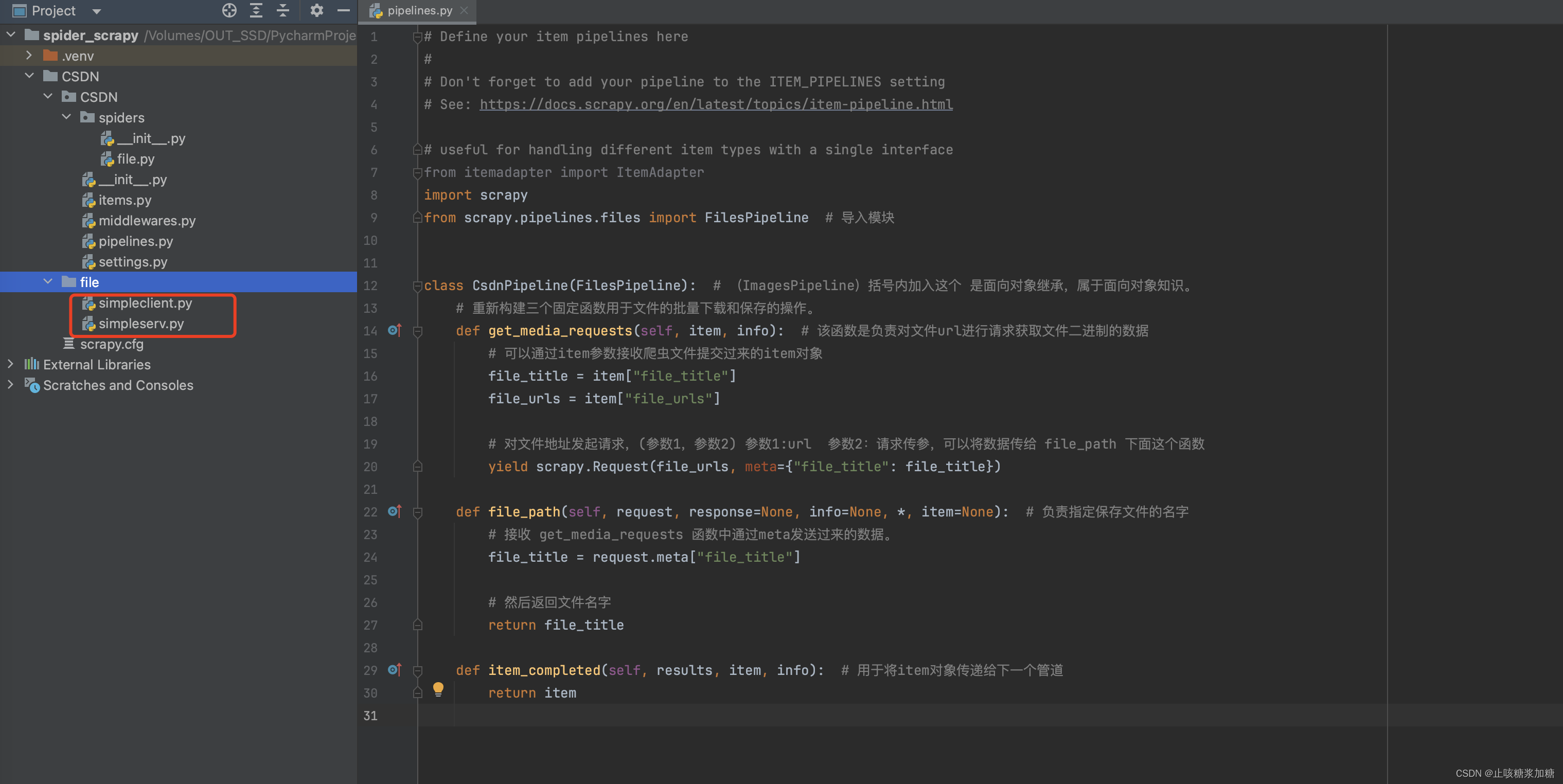
- 1、首先导入FilesPipeline 模块,然后class类继承。
- 2、重新构建三个固定函数用于文件的批量下载和保存的操作。
- get_media_requests函数:负责对文件进行请求,获取图片二进制的数据。
- itme获取爬虫数据传过来的数据这个,不懂理解看这个:item相关知识
- yield发起请求这个是固定写法,参数意思可以看图中注释。
- file_path函数:负责指定保存文件的名字。
- 利用requests来获取上面传过来的数据。
- return返回的值就是文件的名字
- item_completed函数:用于将item对象传递给下一个管道。
- get_media_requests函数:负责对文件进行请求,获取图片二进制的数据。

代码:
import scrapy
from scrapy.pipelines.files import FilesPipeline # 导入模块class CsdnPipeline(FilesPipeline): # (ImagesPipeline)括号内加入这个 是面向对象继承,属于面向对象知识。# 重新构建三个固定函数用于文件的批量下载和保存的操作。def get_media_requests(self, item, info): # 该函数是负责对文件url进行请求获取文件二进制的数据# 可以通过item参数接收爬虫文件提交过来的item对象file_title = item["file_title"]file_urls = item["file_urls"]# 对文件地址发起请求,(参数1,参数2) 参数1:url 参数2:请求传参,可以将数据传给 file_path 下面这个函数yield scrapy.Request(file_urls, meta={"file_title": file_title})def file_path(self, request, response=None, info=None, *, item=None): # 负责指定保存文件的名字# 接收 get_media_requests 函数中通过meta发送过来的数据。file_title = request.meta["file_title"]# 然后返回文件名字return file_titledef item_completed(self, results, item, info): # 用于将item对象传递给下一个管道return item5:结果展示与总结
代码流程:
在
spider中爬取要下载的文件链接,将其放置于item中的file_urls字段中存储spider提交item给FilesPipeline管道
当
FilesPipeline处理时,它会检测是否有file_urls字段,如果有的话,则会对其进行文件下载下载完成之后,会将结果写入item的另一字段
files
Item要包含file_urls和files两个字段
相关文章:
Scrapy框架内置管道之图片视频和文件(一篇文章齐全)
1、Scrapy框架初识(点击前往查阅) 2、Scrapy框架持久化存储(点击前往查阅) 3、Scrapy框架内置管道 4、Scrapy框架中间件(点击前往查阅) Scrapy 是一个开源的、基于Python的爬虫框架,它提供了…...

Linux文件与路径
Linux文件与路径 1、文件结构 Windows和Linux文件系统区别 在windows平台下,打开“此电脑”,我们可以看到盘符分区 每个驱动器都有自己的根目录结构,这样形成了多个树并列的情形 但是在 Linux 下,我们是看不到这些…...

【Qt】获取当前系统用户名:9种获取方式
目的 有时,在项目开发中,需要显示或者用到当前系统用户名信息。以下是几种获取系统用户名解决方案: 解决方案 1. 使用QDir::home() #include <QApplication> #include <QDir> #include <QDebug>int main(int argc, cha…...

ECMAScript2023你学习了吗?
一、ES2023 Features 【Array find from last】 从头到尾搜索数组:findLast() 、findLastIndex()【Hashbang Grammar】Hashbang 语法【Symbols as WeakMap keys】Symbol 作为 WeakMap 的键【Change array by copy】通过副本更改数组:toReversed()、toSo…...

【从删库到跑路 | MySQL总结篇】数据库基础(增删改查的基本操作)
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【MySQL学习专栏】🎈 本专栏旨在分享学习MySQL的一点学习心得,欢迎大家在评论区讨论💌 重点放前面&am…...
【JMeter】配置元件
1. 元件的分类 HTTP Request Default 作用: 可以配置成通用的信息,可复用 JDBC Connection Configuration 作用:连接数据库 前提: 下载好对应数据类型的jar包 HTTP Header Manager信息头管理…...

数据采集静态存储SRAM芯片EMI7064
数据采集是利用一种装置,从系统外部采集数据并输入到系统内部的一个接口。数据采集技术广泛应用在各个领域。比如摄像头,麦克风,都是数据采集工具。 ram工作时可以随时从任何一个指定的地址写入(存入)或读出(取出)信息。RAM在计算…...
网络运维与网络安全 学习笔记2023.11.27
网络运维与网络安全 学习笔记 第二十八天 今日目标 OSPF基本原理、OSPF单区域配置、OSPF多区域配置 特殊区域之Stub、特殊区域之NSSA OSPF基本原理 项目背景 随着企业的发展,网络的规模越来越大,网段的数量越来越多,公司内部的路由器的…...

ansible学习
一文掌握 Ansible 自动化运维 - 知乎 ansible的安装与简单的使用_坚持到所有人都放弃!!!的技术博客_51CTO博客 Ansible中文权威指南 — 国内最专业的Ansible中文官方学习手册 (ansible-tran.readthedocs.io) 安装 # yum -y install epel-release //更新本地安装库 # yu…...
使用Kibana让es集群形象起来
部署Elasticsearch集群详细步骤参考本人: https://blog.csdn.net/m0_59933574/article/details/134605073?spm1001.2014.3001.5502https://blog.csdn.net/m0_59933574/article/details/134605073?spm1001.2014.3001.5502 kibana部署 es集群设备 安装软件主机名…...

机器学习调参指南:提升模型性能的关键步骤
诸神缄默不语-个人CSDN博文目录 文章目录 1. 理解模型的参数和超参数2. 使用网格搜索进行超参数调优3. 随机搜索4. 贝叶斯优化5. 使用交叉验证避免过拟合6. 考虑正则化7. 调整学习率和其他优化器参数8. 实验和记录9. 模型的早停法10. 总结 在机器学习和深度学习的领域中&#x…...
图书管理系统源码,图书管理系统开发,图书借阅系统源码四TuShuManager应用程序MVC视图View
Asp.net web应用程序MVC之View视图 .ASP.NET MVC页面也就是要说的视图基本被放在Views文件夹下; 2.利用APS.NET MVC模板生成框架,Views文件夹下的默认页面为.cshtml页面; 3.ASP.NET MVC默认页面为Razor格式的页面,因此默认页面为.…...
Visual Studio2010保姆式安装教程(VS2010 旗舰版),以及如何运行第一个C语言程序,超详细
安装前请关闭杀毒软件,系统防火墙,断开网络连接 参考链接:请点击 下载链接: 通过百度网盘分享的文件:VS2010.zip 链接:https://pan.baidu.com/s/1yQUUCxMJP7FMaistFX94SQ 提取码:96ga 复制这段内容打开「百度网盘APP …...
第四节HarmonyOS 熟知开发工具DevEco Studio
一、设置主体样式 默认的代码主题样式是黑暗系的,如下图所示: 如果你不喜欢,可以按照一下步骤进行修改: 左上角点击Flie->Settings->Appearance&Behavior->Appearance,点击Theme,在弹出的下拉…...
安防视频监控/视频融合/云存储EasyCVR页面数据显示不全该如何解决?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...

vatee万腾的数字化奇点:Vatee科技的前沿创新之路
随着科技迅猛发展,Vatee万腾在数字化领域创造了引人注目的新迹。Vatee以其独特的数字化力量,引领着科技创新的前沿,为未来的数字化社会描绘着崭新的画卷。 Vatee的数字化力量体现在其对技术的深刻理解和前瞻性思维上。通过持续的技术探索和创…...
C#,《小白学程序》第六课:队列(Queue)其二,队列的应用,编写《实时叫号系统》
医院里面常见的《叫号系统》怎么实现的? 1 文本格式 /// <summary> /// 下面定义一个新的队列,用于演示《实时叫号系统》 /// </summary> Queue<Classmate> q2 new Queue<Classmate>(); /// <summary> /// 《小白学程序…...

打造数字人偶像的意义与影响
在数字化时代,数字人偶像的兴起引发了广泛的关注和讨论。数字人偶像是通过人工智能技术生成真人形象1:1还原的数字人,拥有偶像的外貌、声音和个性。本文将探讨为什么要打造数字人偶像以及其意义与影响。 技术支持:zhibo175 一、…...

Spring加载Bean的多种方式
文章目录 1. XML方式定义2. 使用Component ComponentScan3. 使用Configuration Bean4. 使用FactoryBean的方式加载bean5. Import方式6. Import ImportSelector7. Import ImportBeanDefinitionRegistrar8. 实现接口BeanDefinitionRegistryPostProcessor9. 实现接口BeanFacto…...

minio分布式存储系统
目录 拉取docker镜像 minio所需要的依赖 文件存放的位置 手动上传文件到minio中 工具类上传 yml配置 config类 service类 启动类 测试类 图片 视频 删除minio服务器的文件 下载minio服务器的文件 拉取docker镜像 拉取稳定版本:docker pull minio/minio:RELEASE.20…...

GitHub进阶玩法全解析,零基础可快速上手进阶高手,轻松解决各类常见难题。
GitHub高级使用方法大全:从分支管理到自动化工作流 目录 开篇:超越基础,进入工程化协作高级分支策略:不只是存放代码提交的艺术:让每次提交都有价值Pull Request进阶:打造高效Code Review流程GitHub Acti…...

用Shapely给你的数据加点‘空间感’:非GIS背景也能上手的Python地理分析入门
用Shapely给你的数据加点‘空间感’:非GIS背景也能上手的Python地理分析入门 想象一下,你手里有一份包含全国星巴克门店位置的数据集。传统的分析方法可能告诉你每家店的营业额、客流量,但如果能回答"哪些门店位于地铁站500米范围内&quo…...

内网多机连接fay使用
课程ID:fay-muli-computer作者:课程作者日期:2026-04-13T14:33版本:1.0.0章节数:7 封面 目录 下载cherry studio启动添加fay配置api选择模型配置默认模型开始对话 第1节 下载cherry studio 请到网站https://www.che…...

WarcraftHelper:让魔兽争霸III在现代电脑上焕发新生的终极解决方案
WarcraftHelper:让魔兽争霸III在现代电脑上焕发新生的终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸I…...

基于Multisim14.0的同步时序逻辑电路设计与实现——以模四可逆计数器为例
1. 从零开始认识同步时序逻辑电路 第一次接触同步时序逻辑电路时,我完全被那些专业术语搞晕了。后来才发现,它就像我们生活中的红绿灯控制系统一样简单直观。想象一下,十字路口的红绿灯需要严格按照时间顺序切换状态,这就是典型的…...

探索文本转CAD技术:如何用一句话重构你的3D设计工作流?
探索文本转CAD技术:如何用一句话重构你的3D设计工作流? 【免费下载链接】text-to-cad-ui A lightweight UI for interfacing with the Zoo text-to-cad API, built with SvelteKit. 项目地址: https://gitcode.com/gh_mirrors/te/text-to-cad-ui …...

Cesium 热力图:从原理到实战,打造三维空间数据可视化利器
1. 为什么需要Cesium热力图? 当你在处理地理空间数据时,经常会遇到这样的场景:手上有成百上千个带有经纬度和数值的坐标点,比如气象站的温度数据、共享单车的分布密度、城市人口热力分布等。如果直接在三维地图上用点标记展示&…...

优化labelme中AI Model权重下载体验:手动配置onnx文件的完整指南
1. 为什么需要手动配置onnx权重文件 最近在用labelme做图像标注的朋友可能已经发现了,新版本内置的AI Model功能确实能大幅提升效率。这个功能基于SegmentAnything和EfficientSam等先进模型,可以智能识别图像中的目标区域。但第一次使用时,系…...

GEO重构品牌公关:Infoseek如何破解AI时代的认知困境
2026年,科技圈发生了不少事。OpenAI的Sora模型在今年3月被全面关停,引发了关于AI视频真实性和内容版权的大讨论。同一时期,315晚会曝光了AI“投毒”产业链,不法分子利用GEO技术定向对AI大模型投喂虚假信息。紧接着,4月…...

OpCore-Simplify技术解析:5步实现黑苹果OpenCore EFI自动化配置
OpCore-Simplify技术解析:5步实现黑苹果OpenCore EFI自动化配置 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify OpCore-Simplify是一款基于…...