GLM: 自回归空白填充的多任务预训练语言模型
当前,ChatGLM-6B 在自然语言处理领域日益流行。其卓越的技术特点和强大的语言建模能力使其成为对话语言模型中的佼佼者。让我们深入了解 ChatGLM-6B 的技术特点,探索它在对话模型中的创新之处。
GLM: 自回归空白填充的多任务预训练语言模型
- ChatGLM-6B 技术特点详解
- GLM
- GLM(General Language Model)发展背景:
- GLM特点:
- GLM的改进:
- GLM预训练框架
- 预训练目标
- 自回归空白填充
- 多任务预训练
- 模型架构
- 2D 位置编码
- 微调 GLM
- 对比
- 与 BERT 的比较
- 与 XLNet 的比较
- 与 T5 的比较
- 与 UniLM 的比较
ChatGLM-6B 技术特点详解
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数,基于原文提炼出一些特点
- Tokenization(标记化)
论文采用了基于 icetk 包的文本标记器,词汇量达到 150,000,其中包括 20,000 个图像标记和 130,000 个文本标记。标记的范围从 No.20000 到 No.145653,其中包括常见标点、数字和无扩展定义的空格。 - 层规范化
层规范化在语言建模问题中的重要性得到了深入讨论。论文采用了 DeepNorm 作为 Post-LN 方法,取代了传统的 Pre-LN 方法。该决策是为了应对模型规模扩大至 100B 甚至遇到多模态数据时 Pre-LN 的训练困难的问题。 - 管道并行分析
管道并行性的优化对于训练效率至关重要。论文引入了 Gpipe 和 PipeDream-Flush 策略。在实际 GLM-130B 的预训练中,通过调整微批次的数量,成功减少了 GPU 内存泡沫的占用。具体而言,当微批次数(m)大于等于 4 倍管道数(p)时,总 GPU 内存泡沫的占比可以被降低到可接受的水平。 - 权重量化
为了在推理过程中节省 GPU 内存,论文采用了权重量化技术。Absmax 量化方法在性能和计算效率上的平衡得到了充分的考虑。以下是量化结果的比较:
Model | Original | Absmax INT8 | Absmax INT4 | Zeropoint INT4
-----------|----------|-------------|-------------|----------------
BLOOM-176B | 64.37% | 65.03% | 34.83% | 48.26%
GLM-130B | 80.21% | 80.21% | 79.47% | 80.63%
这表明 GLM-130B 在 INT4 精度下能够保持较高性能,同时有效地减少 GPU 内存占用。考虑到ChatGLM-6B是基于 General Language Model (GLM) 架构实现的,下文将详细对GLM架构展开介绍。
GLM
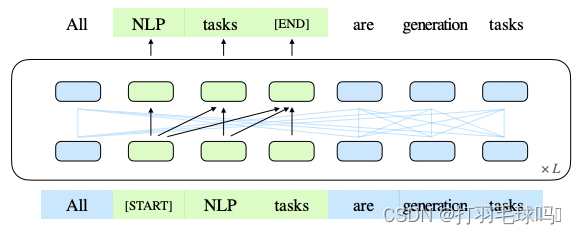
这个图展示了GLM(General Language Model)的基本原理。在这个模型中,我们首先将文本中的一些部分(绿色部分)标记为空白,也就是我们遮挡了其中的一些文本片段。接下来,我们通过自回归的方式逐步生成这些被遮挡的文本片段。也就是说,我们从左到右逐个预测每个被遮挡的位置上应该是什么词语,然后将这些预测组合起来形成完整的文本。
这个过程类似于我们填写一篇文章的空白部分,通过上下文逐步补充缺失的信息。
GLM(General Language Model)发展背景:
当前存在多种预训练模型架构,如自编码模型(BERT)、自回归模型(GPT)和编码-解码模型(T5)。然而,这些框架在自然语言理解(NLU)、无条件生成和条件生成等任务中均无法在所有方面表现最佳。
GLM特点:
GLM是一种基于自回归空白填充的通用语言模型。它通过在输入文本中随机空白化连续跨度的令牌,并训练模型顺序重构这些跨度来进行预训练。GLM改进了空白填充预训练,引入了2D位置编码和允许以任意顺序预测跨度的机制。GLM能够处理不同类型任务的预训练,通过变化空白的数量和长度,实现了对条件和无条件生成任务的预训练。
GLM的改进:
GLM在实现自回归空白填充时引入了两个关键改进:1)跨度洗牌,即对空白的连续跨度进行随机排序;2)2D位置编码,为每个位置引入二维位置编码。这些改进使得GLM在相同参数和计算成本下显著优于BERT,并在多任务学习中表现卓越,尤其在NLU和生成任务中。
自回归模型(例如GPT):
- 原理: 自回归模型是一种通过学习从左到右的语言模型来预训练的框架。它的核心思想是根据上下文左侧的单词来预测下一个单词,实现对整个文本的逐词建模。
- 特点:
-
- 优势在于适用于长文本生成,并在参数规模较大时表现出良好的性能。
-
- 不足之处在于其单向的注意力机制,不能完全捕捉自然语言理解任务中上下文词汇之间的依赖关系。
自编码模型(例如BERT):
- 原理: 自编码模型通过学习一个对输入进行自编码的目标,例如通过将输入文本中的某些单词随机遮蔽,然后尝试预测这些被遮蔽的单词,从而达到学习双向上下文表示的目的。
- 特点:
-
- 通过双向上下文编码,适用于自然语言理解任务,如文本分类、命名实体识别等。
-
- 不同于自回归模型,可以同时考虑上下文中的所有词,更好地捕捉依赖关系。
编码-解码模型(例如T5):
- 原理: 编码-解码模型采用编码器-解码器结构,其中编码器通过双向注意力机制对输入进行编码,解码器通过自回归方式生成输出。
- 特点:
-
- 适用于条件生成任务,如机器翻译、文本摘要等。
-
- 结合了自编码和自回归的优势,但通常需要更多的参数。
三大类预训练框架对比:
| 特点 | 自回归模型(GPT) | 自编码模型(BERT) | 编码-解码模型(T5) |
|---|---|---|---|
| 训练方向 | 左到右 | 双向 | 双向 |
| 任务适用性 | 长文本生成 | 自然语言理解 | 条件生成任务 |
| 上下文捕捉 | 单向上下文 | 双向上下文 | 双向上下文 |
| 应用领域 | 生成任务 | 自然语言理解任务 | 条件生成任务 |
| 训练效率 | 参数较大时效果较好 | 效果较好且能同时处理所有词 | 参数相对较大 |
这些预训练框架在不同的任务和应用场景中有各自的优势和不足,选择合适的框架取决于具体任务的性质和需求。
GLM预训练框架
我们提出了一个通用的预训练框架GLM,基于一种新颖的自回归空白填充目标。GLM将NLU任务形式化为包含任务描述的填空问题,这些问题可以通过自回归生成来回答。
预训练目标
自回归空白填充
GLM通过优化自回归空白填充目标进行训练。在给定输入文本 x = [ x 1 , ⋅ ⋅ ⋅ , x n ] x = [x_1, · · · , x_n] x=[x1,⋅⋅⋅,xn]的情况下,抽样多个文本片段 [ s 1 , ⋅ ⋅ ⋅ , s m ] [s_1, · · · , s_m] [s1,⋅⋅⋅,sm],其中每个片段 s i s_i si对应于输入文本 x x x中的一系列连续令牌 [ s i , 1 , . . . , s i , l i ] [s_{i,1}, ... , s_{i,l_i}] [si,1,...,si,li]。
每个片段用单个 [ M A S K ] [MASK] [MASK]令牌替换,形成一个损坏的文本 x c o r r u p t x_{corrupt} xcorrupt。模型根据损坏的文本以自回归方式预测片段中缺失的令牌,具体而言,模型在预测一个片段的缺失令牌时,可以访问损坏的文本以及先前预测的片段。为了全面捕捉不同片段之间的相互依赖关系,我们随机排列了片段的顺序。这种自回归空白填充目标通过引入二维位置编码和允许以任意顺序预测片段,改进了填充预训练,并在 NLU 任务中相较于 BERT 和 T5 取得了性能提升。
具体而言,自回归空白填充目标的最大化似然函数为:
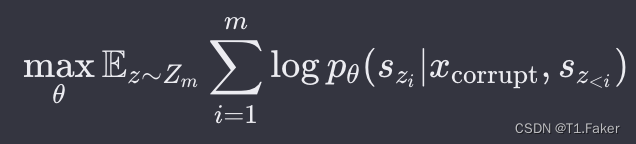
其中, Z m Z_m Zm是长度为 m m m的索引序列的所有可能排列的集合, s z < i s_{z<i} sz<i为 [ s z 1 , ⋅ ⋅ ⋅ , s z i − 1 ] [s_{z_1}, · · · , s_{z_{i−1}}] [sz1,⋅⋅⋅,szi−1]。每个缺失令牌的生成概率在自回归空白填充目标下,被分解为:
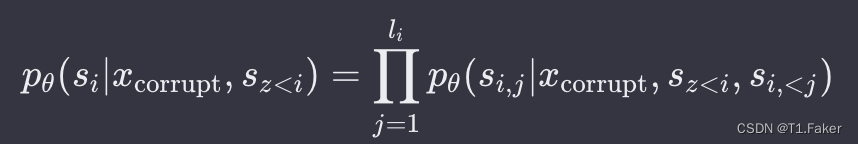
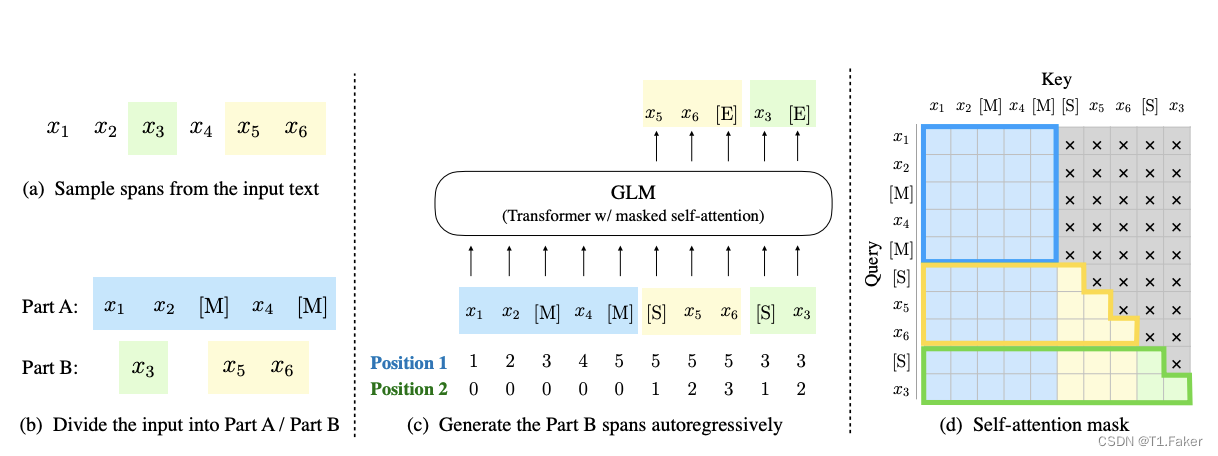
为了实现自回归生成,将输入 x x x划分为两部分:Part A 是损坏的文本 x c o r r u p t x_{corrupt} xcorrupt,Part B 包含被掩蔽的片段。Part A 中的令牌可以互相关注,但不能关注 B 中的任何令牌。Part B 中的令牌可以关注 Part A 以及 B 中的先行令牌,但不能关注 B 中的任何后续令牌。为了实现自回归生成,每个片段都用特殊令牌 [START] 和 [END] 进行填充,作为输入和输出。模型的实现如下图所示:
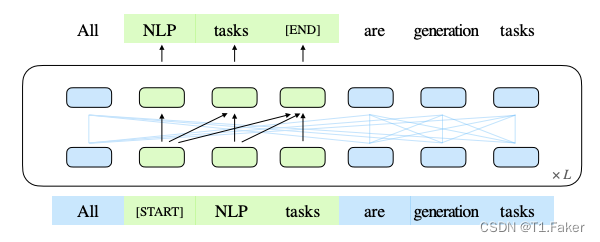
这张图片展示了GLM的预训练流程。原始文本被抽样为多个片段,其中的一些被[MASK]替换,然后进行自回归生成。每个片段都以[S]开始,[E]结束。2D位置编码用于表示片段的内部和相互之间的位置关系。
我们通过从泊松分布中抽样长度为 l i l_i li的片段,反复抽样新片段,直到至少 15% 的原始令牌被掩蔽,来确定片段的数量和长度。实验证明,15% 的比例对于在下游 NLU 任务中取得良好性能至关重要。
多任务预训练
在上述自回归空白填充目标的基础上,GLM 引入了多任务预训练。我们考虑了两个附加目标:
- 文档级别目标: 通过抽样一个长度在原始长度的50%–100%之间的单个片段,鼓励模型进行长文本生成
- 句子级别目标: 限制必须为完整句子的掩蔽片段,以涵盖原始令牌的15%。这个目标旨在处理通常需要生成完整句子或段落的 seq2seq 任务。
这两个新目标都采用与原始目标相同的形式,但有不同数量和长度的片段。
模型架构
GLM 使用单个 Transformer 模型,对其进行了几处修改:
- 将层归一化和残差连接的顺序重新排列,以避免大规模语言模型中的数值错误。
- 使用单个线性层进行输出令牌预测。
- 将 ReLU 激活函数替换为 GeLU(Gaussian Error Linear Unit)。
2D 位置编码
自回归空白填充任务的一个挑战是如何编码位置信息。为了解决这个问题,GLM 引入了二维位置编码。具体而言,每个令牌都用两个位置 id 进行编码。第一个位置 id 表示在损坏的文本 x c o r r u p t x_{corrupt} xcorrupt中的位置,对于被替换的片段,它是相应 [ M A S K ] [MASK] [MASK] 令牌的位置。第二个位置 id 表示片段内部的位置。对于 Part A 中的令牌,它们的第二个位置 id 为0;对于 Part B 中的令牌,它们的第二个位置 id 在1到片段长度之间。这两个位置 id 通过可学习的嵌入表投影为两个向量,然后与输入令牌嵌入相加。
这种编码确保了在模型重建片段时,模型不知道被替换片段的长度,这与其他模型不同。例如,XLNet 在推理时需要知道或枚举答案的长度,而 SpanBERT 替换了多个 [ M A S K ] [MASK] [MASK]令牌并保持长度不变。
微调 GLM
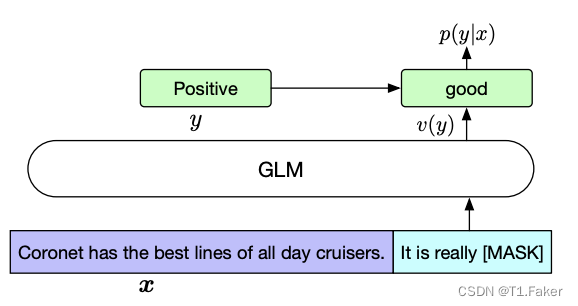
通常,对于下游 NLU 任务,线性分类器将预训练模型生成的序列或令牌表示作为输入,并预测正确的标签。我们将 NLU 分类任务重新构造为空白填充任务,通过 PET(Pattern-Exploiting Training)的方式,将输入文本 x x x转换为包含单个掩蔽令牌的填充问题 c ( x ) c(x) c(x)。这个填充模板以自然语言编写,以表示任务的语义,例如,情感分类任务可以被构造成“{SENTENCE}. It’s really [MASK]”。候选标签 y ∈ Y y∈Y y∈Y也被映射到填充的答案,称为 v e r b a l i z e r v ( y ) verbalizer v(y) verbalizerv(y)。在情感分类中,标签“positive”和“negative”被映射为“good”和“bad”。给定 x x x的条件下预测 y y y的概率为:

微调 GLM 采用交叉熵损失,具体形式如下图所示:
对比
在这一节中,我们讨论 GLM 与其他预训练模型的差异,并关注它们如何适应下游空白填充任务。
与 BERT 的比较
与 BERT 不同,GLM 在 MLM 的独立性假设下,无法捕捉掩蔽令牌之间的相互依赖关系。BERT 的另一个劣势是,它不能很好地填充多个令牌的空白。为了推断长度为 l l l的答案的概率,BERT 需要执行 l l l个连续的预测。如果长度 l l l未知,可能需要枚举所有可能的长度,因为 BERT 需要根据长度改变 [MASK] 令牌的数量。这是 GLM 改进的一个方面。
与 XLNet 的比较
GLM 和 XLNet 都是通过自回归目标进行预训练的,但它们之间存在两个主要区别。首先,XLNet 在损坏之前使用原始位置编码。在推断时,我们需要知道或枚举答案的长度,这与 BERT 有相同的问题。其次,XLNet 使用双流自注意机制,而不是右移,以避免 Transformer 内的信息泄漏。这导致了预训练的时间成本加倍。
与 T5 的比较
T5 提出了一种类似的空白填充目标,以预训练编码器-解码器 Transformer。T5 为编码器和解码器使用独立的位置编码,并依赖于多个 sentinel 令牌来区分被掩蔽的片段。在下游任务中,只使用其中一个 sentinel 令牌,导致模型容量的浪费和预训练与微调之间的不一致性。此外,T5 总是按固定的从左到右顺序预测片段,而 GLM 在 NLU 和 seq2seq 任务上可以使用更少的参数和数据获得更好的性能。
与 UniLM 的比较
结合了不同的预训练目标,通过在自动编码框架中更改注意力掩码,实现了在双向、单向和交叉注意力之间的切换。然而,UniLM总是用[MASK]令牌替换掉掩蔽的片段,这限制了其建模掩蔽片段及其上下文之间依赖关系的能力。与之不同,GLM以自回归的方式输入前一个令牌并生成下一个令牌,提高了模型对片段和上下文之间依赖关系的建模能力。
UniLMv2在生成任务中采用了部分自回归建模,同时在NLU任务中使用自动编码目标。GLM通过自回归预训练来统一NLU和生成任务,使其在两者之间更加高效。
相关文章:
GLM: 自回归空白填充的多任务预训练语言模型
当前,ChatGLM-6B 在自然语言处理领域日益流行。其卓越的技术特点和强大的语言建模能力使其成为对话语言模型中的佼佼者。让我们深入了解 ChatGLM-6B 的技术特点,探索它在对话模型中的创新之处。 GLM: 自回归空白填充的多任务预训练语言模型 ChatGLM-6B 技…...

函数递归所应满足的条件
1.递归的概念 递归是学习C语⾔函数绕不开的⼀个话题,那什么是递归呢? 递归其实是⼀种解决问题的⽅法,在C语⾔中,递归就是函数⾃⼰调⽤⾃⼰。 递归的思想: 把⼀个⼤型复杂问题层层转化为⼀个与原问题相似,但…...

Python入职某新员工大量使用Lambda表达式,却被老员工喷是屎山
Python中Lambda表达式是一种简洁而强大的特性,其在开发中的使用优缺点明显,需要根据具体场景权衡取舍。 Lambda表达式的优点之一是它的紧凑语法,适用于一些短小而简单的函数。这种形式使得代码更为精炼,特别在一些函数式编程场景中,Lambda表达式可以提高代码的表达力。此外…...
Android Bitmap保存成至手机图片文件,Kotlin
Android Bitmap保存成至手机图片文件,Kotlin fun saveBitmap(name: String?, bm: Bitmap) {val savePath Environment.getExternalStoragePublicDirectory(Environment.DIRECTORY_PICTURES).toString()if (!Files.exists(Paths.get(savePath))) {Log.d("保存文…...
frp V0.52.3 搭建
下载 https://github.com/fatedier/frp/releases/ 此版本暂时没有windows的,想在windows使用请下载v0.52.2 简易搭建 frps.toml的配置文件,以下12000、8500需要在云服务器中的防火墙中开放tcp # bindPort为frps和frpc通信的端口,需要在防…...

最近数据分析面试的一点感悟...
我是阿粥,也是小z 最近面了不少应届的同学(数据分析岗位),颇有感触,与各位分享。 简历可以润色,但要适度 运用一些原则,如STAR法则,让简历逻辑更清晰,条块分明࿰…...
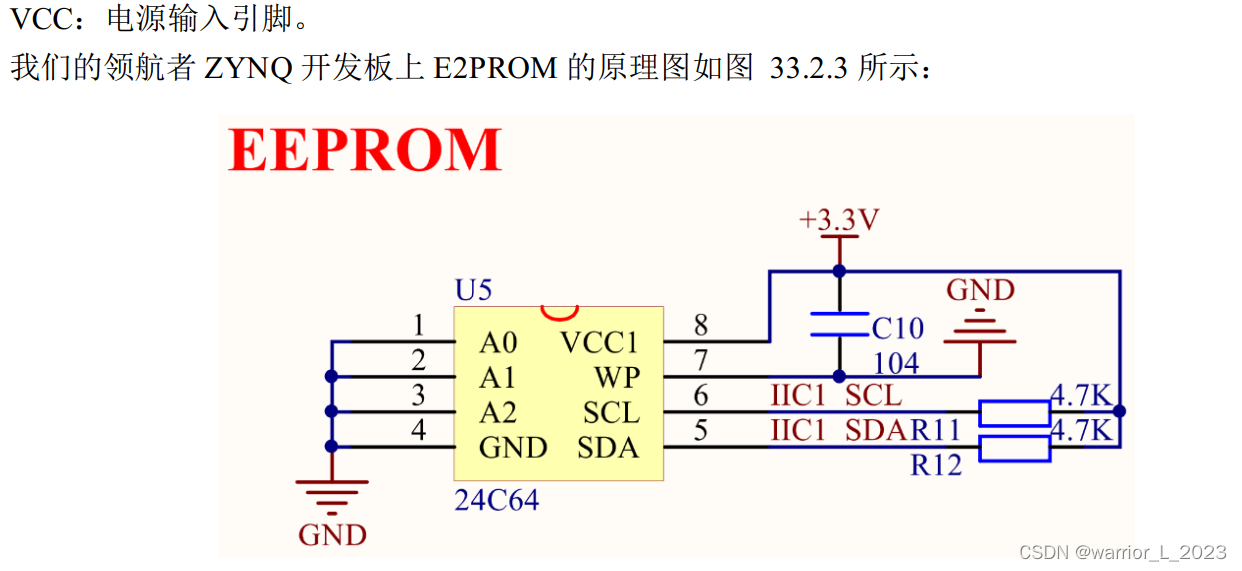
ZYNQ_project:IIC_EEPROM
EEPROM简介: EEPROM(Electrically Erasable Progammable Read Only Memory, E2PROM)是指带电可擦可编程只读存 储器,是一种常用的非易失性存储器(掉电数据不丢失), E2PROM 有多种类型的产品,我…...

Leetcode 2940. Find Building Where Alice and Bob Can Meet
Leetcode 2940. Find Building Where Alice and Bob Can Meet 1. 解题思路2. 代码实现3. 算法优化 题目链接:2940. Find Building Where Alice and Bob Can Meet 1. 解题思路 这一题本质上又是限制条件下求极值的问题,算是我最不喜欢的题目类型之一吧…...
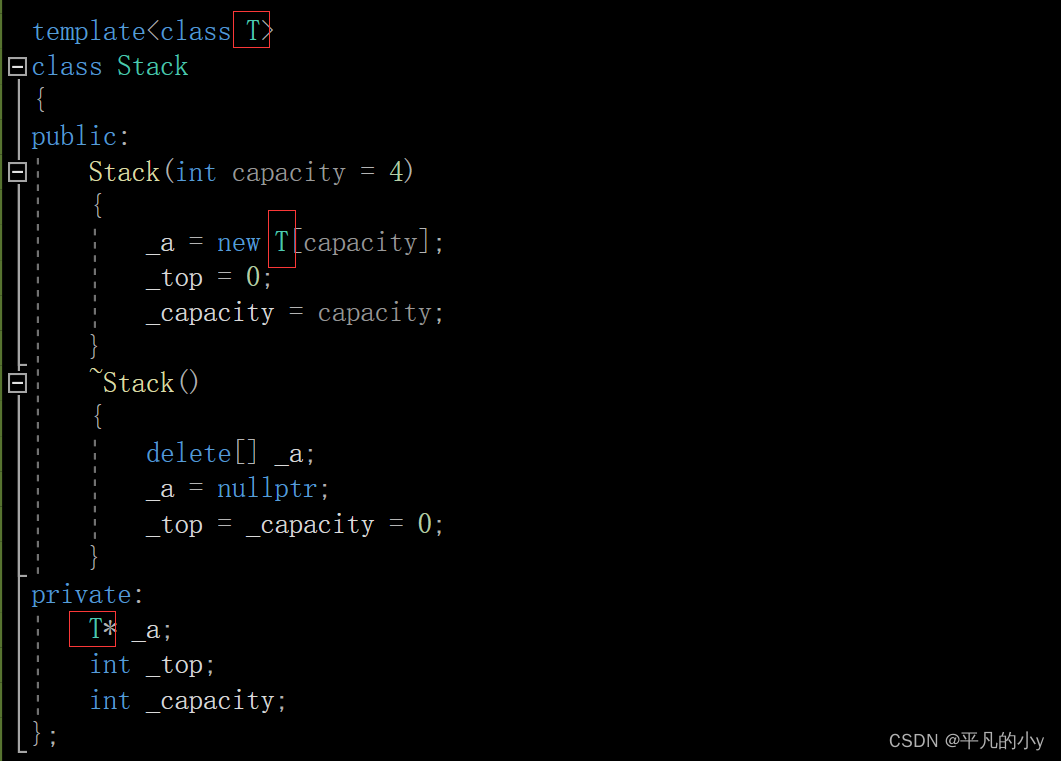
C++ 泛型编程,函数模版和类模版
1.泛型编程 泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础 就比如说活字印刷术,就是提供一个模具,然后根据模具来印刷出不同的字。 泛型编程跟着类似,提供一个模版,根据这…...

【封装UI组件库系列】封装Button图标组件
封装UI组件库系列第四篇封装Button按钮组件 🌟前言 🌟封装Button组件 1.分析封装组件所需支持的属性与事件 支持的属性: 支持的事件: 2.创建Button组件 🌟封装功能属性 type主题颜色 plain是否朴素 loading等…...
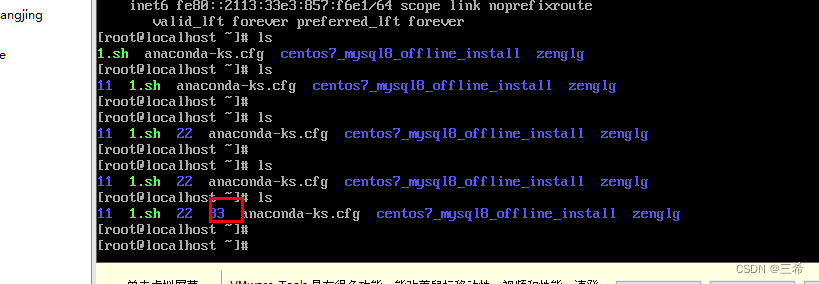
windows系统mobaxterm远程执行linux上ssh命令
命令如下 start "" "%~dp0\MobaXterm_Personal_23.4.exe" -newtab "sshpass -p root ssh root192.168.11.92 mkdir 33" -p 是密码 左边是用户名,右边是服务器ip 后面跟的是服务器上执行的命令 第一次执行的时候要设置mobaxt…...
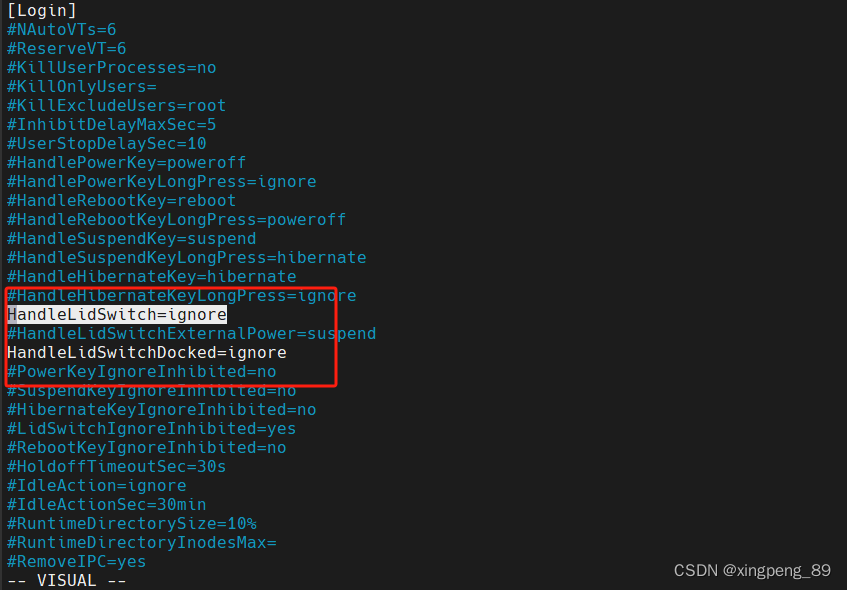
debian 12 配置
1. 修改apt源 修改apt源为http版本 # 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释 deb http://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm main contrib non-free non-free-firmware # deb-src http://mirrors.tuna.tsinghua.edu.cn/d…...
AIGC创作系统ChatGPT网站源码、支持最新GPT-4-Turbo模型、GPT-4图片对话能力+搭建部署教程
一、AI创作系统 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI…...
,包含请求拦截器和响应拦截器)
Vue 中简易封装网络请求(Axios),包含请求拦截器和响应拦截器
Vue 中简易封装网络请求(Axios),包含请求拦截器和响应拦截器 axios简介 Axios 是一个基于 promise 的网络请求库,可以用于浏览器和 node.js Axios官方中文文档 特性 从浏览器创建 XMLHttpRequests从 node.js 创建 http 请求支…...

git提交报错error: failed to push some refs to ‘git url‘
1.产生错误原因 想把本地仓库提交到远程仓库,报错信息如下 git提交报错信息 error: src refspec master does not match any error: failed to push some refs to git url 错误原因: 我们在创建仓库的时候,都会勾选“使用Reamdme文件初始化…...
模块的相对路径导入)
【Python】(自定义函数)模块的相对路径导入
是我以前写的老文章的升级版,本质上使用exec和sys.path实现相对路径导入。 RelativeImport: __version__1.1.0 __author__Ls_Janimport os import sys import inspectdef RelativeImport(module,*args):#模块导入module为模块所在路径(模块名不需要.py后…...

巧妙之中见真章:深入解析常用的创建型设计模式
设计模式之创建型设计模式详解 一、设计模式是什么?二、模板方法2.1、代码结构2.2、符合的设计原则2.3、如何扩展代码2.4、小结 三、观察者模式3.1、代码结构3.2、符合的设计原则3.3、如何扩展代码3.4、小结 四、策略模式4.1、代码结构4.2、符合的设计原则4.3、如何…...

Selenium切换窗口、框架和弹出框window、ifame、alert
一、切换窗口 #获取打开的多个窗口句柄 windows driver.window_handles #切换到当前最新打开的窗口 driver.switch_to.window(windows[-1]) #最大化浏览器 driver.maximize_window() #刷新当前页面 driver.refresh() 二、切换框架frame 如存在以下网页: <htm…...
QT linux下应用程序打包
一、应用程序app 1、应用程序的pro文件 2、 程序工作函数 3、app的UI界面 二、动态库lib 1、Lib类头文件 2、.cpp文件 三、对应用程序和动态库进行构建 1、对动态库进行qmake,然后进行构建 2、对应用程序进行qmake,然后进行构建 3、查看构建目录 四、编写脚本 …...

Java高级技术(单元测试)
一,概括 二,junit 三,案例 (1),实验类 package com.bilibili;public class Name {public static void main(String name) {if (name null){System.out.println("0");return;}System.out.print…...

等保三级 + 密评双达标:SQL Server TDE + 脱敏最佳实践
一、一次审计惊魂:备份硬盘丢失,患者数据险遭泄露去年底,我院一台 SQL Server 2019 备份服务器因机房搬迁,一块存有全量患者数据的硬盘意外遗失。虽未确认是否被恶意获取,但根据《个人信息保护法》第51条:“…...

【紧急预警】AI原生应用上线前必做通信压测:单连接承载>50路token流+多Agent状态同步时,这3类协议已证实失效
第一章:AI原生软件研发实时通信技术选型 2026奇点智能技术大会(https://ml-summit.org) AI原生软件对低延迟、高吞吐、语义感知的实时通信能力提出全新要求——模型推理流式响应、多模态协同状态同步、边缘-云协同训练反馈闭环等场景,已远超传统Web应用…...

电源设计新手看过来:手把手教你用SIMPLIS仿真和Matlab拟合,验证自己的环路设计
电源设计新手实战指南:用SIMPLIS与Matlab双剑合璧验证环路稳定性 作为一名刚踏入电源设计领域的新手,最令人头疼的莫过于面对密密麻麻的公式推导后,却无法确定自己设计的补偿网络是否真的能在实际电路中发挥作用。本文将带你用SIMPLIS仿真和M…...

Harness层接口限流:防止恶意调用
一、 标题 Harness 层接口限流实战:从恶意调用防护到 DevOps 平台稳定性的铜墙铁壁二、 摘要/引言 2.1 开门见山(Hook) 假设你是一家拥有 500 开发者、日均 1000 CI/CD 流水线运行、每月发布 200 新特性的中型 SaaS 公司 DevOps 负责人。周一…...

网约摩的席卷县城:2公里收费超网约车,外卖员排队加入引争议
2026年春,一场由“网约摩的”掀起的出行变革正席卷广东、湖南多地县城。在茂名、乐昌、衡东等地,一款名为“摩的一下”的网约摩托车平台悄然上线,其定价模式引发热议:起步价6元/2公里,折合每公里高达3元,短…...

Mem Reduct终极指南:一键解决Windows内存卡顿的完整教程
Mem Reduct终极指南:一键解决Windows内存卡顿的完整教程 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct …...

大数据专业考CDA数据分析师证书值不值?适合哪些求职方向和岗位
大数据专业考取CDA数据分析师证书的价值分析CDA数据分析师证书的含金量CDA数据分析师证书由经管之家(原人大经济论坛)认证,是国内较早面向数据分析领域的专业认证。其课程体系覆盖统计学、机器学习、数据可视化等核心内容,适合大数…...

SpringCloud微服务进阶-Nacos更加全能的注册中心疗
插件化架构 v3 版本最大的变化是引入了模块化插件系统。此前版本中集成在核心包里的原生功能,现在被拆分成独立的插件。 每个插件都是一个独立的 Composer 包,包含 Swift 和 Kotlin 代码、权限清单以及原生依赖。开发者只需安装实际用到的插件࿰…...

Cogito 3B效果展示:128K上下文内跨章节引用——技术白皮书重点定位实测
Cogito 3B效果展示:128K上下文内跨章节引用——技术白皮书重点定位实测 1. 引言:当模型能“记住”一整本书 想象一下,你拿到一份长达数百页的技术白皮书,里面包含了产品介绍、技术架构、性能参数、应用案例等十几个章节。你需要…...

ORA-31215: DBMS_LDAP PL/SQL无效LDAP修改值,Oracle报错故障修复与远程处理方案,快速解决连接配置难题
针对ORA-31215错误,核心在于DBMS_LDAP包在执行PL/SQL程序时,尝试向LDAP目录服务提交了一个不符合规范(如类型不匹配、格式错误、或为NULL)的属性值修改请求,导致操作失败;解决方法主要围绕检查并修正代码中…...