torch::和at:: factory function的差別
torch::和at:: factory function的差別
- 前言
- torch::autograd::THPVariable_rand
- torch::rand_symint
- at::rand_symint
- demo
- torch命名空間
- at命名空間
前言
>>> import torch
>>> a = torch.rand(3, 4)
>>> a.requires_grad
False
>>> a = torch.rand(3, 4, requires_grad = True)
>>> a.requires_grad
True
在這兩個例子中,torch.rand factory function會根據requires_grad參數生成一個可微或不可微的張量。深入其C++底層,會發現它們調用的其實是torch::和at::兩個不同命名空間裡的factory function,本篇將會通過查看源碼和範例程序來了解不同factory function生成的張量有何差別。
torch::autograd::THPVariable_rand
如果使用gdb去查看程式運行的backtrace,可以發現torch::autograd::THPVariable_rand是從Python世界到C++世界後第一個與rand有關的函數。
torch/csrc/autograd/generated/python_torch_functions_0.cpp
static PyObject * THPVariable_rand(PyObject* self_, PyObject* args, PyObject* kwargs)
{HANDLE_TH_ERRORSstatic PythonArgParser parser({"rand(SymIntArrayRef size, *, Generator? generator, DimnameList? names, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)","rand(SymIntArrayRef size, *, Generator? generator, Tensor out=None, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)","rand(SymIntArrayRef size, *, Tensor out=None, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)","rand(SymIntArrayRef size, *, DimnameList? names, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)",}, /*traceable=*/true);ParsedArgs<8> parsed_args;auto _r = parser.parse(nullptr, args, kwargs, parsed_args);if(_r.has_torch_function()) {return handle_torch_function(_r, nullptr, args, kwargs, THPVariableFunctionsModule, "torch");}switch (_r.idx) {//...case 2: {if (_r.isNone(1)) {// aten::rand(SymInt[] size, *, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=None) -> Tensorconst auto options = TensorOptions().dtype(_r.scalartypeOptional(2)).device(_r.deviceWithDefault(4, torch::tensors::get_default_device())).layout(_r.layoutOptional(3)).requires_grad(_r.toBool(6)).pinned_memory(_r.toBool(5));torch::utils::maybe_initialize_cuda(options);auto dispatch_rand = [](c10::SymIntArrayRef size, at::TensorOptions options) -> at::Tensor {pybind11::gil_scoped_release no_gil;return torch::rand_symint(size, options);};return wrap(dispatch_rand(_r.symintlist(0), options));} else {// aten::rand.out(SymInt[] size, *, Tensor(a!) out) -> Tensor(a!)check_out_type_matches(_r.tensor(1), _r.scalartypeOptional(2),_r.isNone(2), _r.layoutOptional(3),_r.deviceWithDefault(4, torch::tensors::get_default_device()), _r.isNone(4));auto dispatch_rand_out = [](at::Tensor out, c10::SymIntArrayRef size) -> at::Tensor {pybind11::gil_scoped_release no_gil;return at::rand_symint_out(out, size);};return wrap(dispatch_rand_out(_r.tensor(1), _r.symintlist(0)).set_requires_grad(_r.toBool(6)));}}// ...}Py_RETURN_NONE;END_HANDLE_TH_ERRORS
}
我們是以torch.rand(3, 4)的方式調用,也就是只提供了size參數,對照下面四種簽名的API:
"rand(SymIntArrayRef size, *, Generator? generator, DimnameList? names, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)","rand(SymIntArrayRef size, *, Generator? generator, Tensor out=None, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)","rand(SymIntArrayRef size, *, Tensor out=None, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)","rand(SymIntArrayRef size, *, DimnameList? names, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=False, bool? requires_grad=False)",
當中除了第二種(0-based)簽名的rand函數外都需要額外提供如generator或names等參數。所以此處會進入switch的case 2。
接著檢查第1個(0-based)參數_r.isNone(1),也就是out參數,是否為空:
-
如果未提供
out參數會進入if分支,接著調用torch::rand_symint,回傳可微的at::Tensor -
如果提供了
out參數則會進入else分支,接著調用at::rand_symint,回傳不可微的at::Tensor
此處未提供out參數,所以會進入if分支。
另外注意函數的第六個參數requires_grad,在if分支是以如下方式被解析,並將此資訊記錄在TensorOptions類型的物件裡:
const auto options = TensorOptions().dtype(_r.scalartypeOptional(2)).device(_r.deviceWithDefault(4, torch::tensors::get_default_device())).layout(_r.layoutOptional(3)).requires_grad(_r.toBool(6)).pinned_memory(_r.toBool(5));
接著會將TensorOptions物件當作參數傳入torch::rand_symint:
return torch::rand_symint(size, options);
在else分支則會先調用dispatch_rand_out得到at::Tensor:
auto dispatch_rand_out = [](at::Tensor out, c10::SymIntArrayRef size) -> at::Tensor {pybind11::gil_scoped_release no_gil;return at::rand_symint_out(out, size);};
然後再透過set_requires_grad函數讓它變成可微或不可微:
return wrap(dispatch_rand_out(_r.tensor(1), _r.symintlist(0)).set_requires_grad(_r.toBool(6)));
接著進入torch::rand_symint的源碼來看看它和at::rand_symint的區別。
torch::rand_symint
torch/csrc/autograd/generated/variable_factories.h
inline at::Tensor rand_symint(c10::SymIntArrayRef size, at::TensorOptions options = {}) {at::AutoDispatchBelowADInplaceOrView guard;return autograd::make_variable(at::rand_symint(size, at::TensorOptions(options).requires_grad(c10::nullopt)), /*requires_grad=*/options.requires_grad());
}
可以看到此處是先調用at::rand_symint得到at::Tensor後再調用autograd::make_variable對返回的張量再做一層包裝。
at::Tensor繼承自at::TensorBase,at::TensorBase有一個c10::TensorImpl的成員變數autograd_meta_。autograd::make_variable會根據第二個參數requires_grad調用c10::TensorImpl::set_autograd_meta來將autograd_meta_設為空或一個non-trivial的值。如果autograd_meta_非空,回傳的Variable就會被賦予自動微分的功能。
at::rand_symint
build/aten/src/ATen/Functions.h
// aten::rand(SymInt[] size, *, ScalarType? dtype=None, Layout? layout=None, Device? device=None, bool? pin_memory=None) -> Tensor
inline at::Tensor rand_symint(c10::SymIntArrayRef size, at::TensorOptions options={}) {return at::_ops::rand::call(size, optTypeMetaToScalarType(options.dtype_opt()), options.layout_opt(), options.device_opt(), options.pinned_memory_opt());
}
namespace symint {template <typename T, typename = std::enable_if_t<std::is_same<T, c10::SymInt>::value>>at::Tensor rand(c10::SymIntArrayRef size, at::TensorOptions options={}) {return at::_ops::rand::call(size, optTypeMetaToScalarType(options.dtype_opt()), options.layout_opt(), options.device_opt(), options.pinned_memory_opt());}
}
at::rand_symint函數其實就只是調用at::_ops::rand::call就直接返回。
PYTORCH C++ API - Autograd可以作為印證:
The at::Tensor class in ATen is not differentiable by default. To add the differentiability of tensors the autograd API provides, you must use tensor factory functions from the torch:: namespace instead of the at:: namespace. For example, while a tensor created with at::ones will not be differentiable, a tensor created with torch::ones will be.
at::下的factory function製造出來的張量沒有自動微分功能;如果想讓張量擁有自動微分功能,可以改用torch::下的factory function(但需傳入torch::requires_grad())。
demo
安裝LibTorch後新增一個autograd.cpp,參考AUTOGRAD IN C++ FRONTEND:
#include <torch/torch.h>int main(){torch::Tensor x = torch::ones({2, 2});std::cout << x << std::endl;std::cout << x.requires_grad() << std::endl; // 0x = torch::ones({2, 2}, torch::requires_grad());// 建構時傳入torch::requires_grad(),張量的requires_grad()便會為truestd::cout << x.requires_grad() << std::endl; // 1torch::Tensor y = x.mean();std::cout << y << std::endl;std::cout << y.requires_grad() << std::endl; // 1// 對於非葉子節點,必須事先調用retain_grad(),這樣它在反向傳播時的梯度才會被保留y.retain_grad(); // retain grad for non-leaf Tensory.backward();std::cout << y.grad() << std::endl;std::cout << x.grad() << std::endl;// at命名空間at::Tensor x1 = at::ones({2, 2});std::cout << x1.requires_grad() << std::endl; // 0at::Tensor y1 = x1.mean();std::cout << y1.requires_grad() << std::endl; // 0// y1.retain_grad(); // core dumped// at::Tensor透過set_requires_grad後就可以被微分了x1.set_requires_grad(true);std::cout << "after set requires grad: " << x1.requires_grad() << std::endl; // 1std::cout << y1.requires_grad() << std::endl; // 0// x1改變了之後y1也必須更新y1 = x1.mean();std::cout << y1.requires_grad() << std::endl; // 1y1.retain_grad(); // retain grad for non-leaf Tensory1.backward();std::cout << y1.grad() << std::endl;std::cout << x1.grad() << std::endl;return 0;
}
編寫以下CMakeLists.txt:
cmake_minimum_required(VERSION 3.18 FATAL_ERROR)
project(autograd)find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")add_executable(autograd autograd.cpp)
target_link_libraries(autograd "${TORCH_LIBRARIES}")
set_property(TARGET autograd PROPERTY CXX_STANDARD 17)# The following code block is suggested to be used on Windows.
# According to https://github.com/pytorch/pytorch/issues/25457,
# the DLLs need to be copied to avoid memory errors.
if (MSVC)file(GLOB TORCH_DLLS "${TORCH_INSTALL_PREFIX}/lib/*.dll")add_custom_command(TARGET autogradPOST_BUILDCOMMAND ${CMAKE_COMMAND} -E copy_if_different${TORCH_DLLS}$<TARGET_FILE_DIR:autograd>)
endif (MSVC)
編譯執行:
rm -rf * && cmake -DCMAKE_PREFIX_PATH=/root/Documents/installation/libtorch .. && make && ./autograd
逐行分析如下。
torch命名空間
使用torch命名空間的factory function創造torch::Tensor:
torch::Tensor x = torch::ones({2, 2});std::cout << x << std::endl;
結果如下:
1 11 1
[ CPUFloatType{2,2} ]
此處沒傳入torch::requires_grad(),所以張量的 requires_grad()會為false:
std::cout << x.requires_grad() << std::endl; // 0
如果建構時傳入torch::requires_grad(),張量的requires_grad()便會為true:
x = torch::ones({2, 2}, torch::requires_grad());std::cout << x.requires_grad() << std::endl; // 1
torch::Tensor y = x.mean();std::cout << y << std::endl;
1[ CPUFloatType{} ]
std::cout << y.requires_grad() << std::endl; // 1
對於非葉子節點,必須事先調用retain_grad(),這樣它在反向傳播時的梯度才會被保留:
y.retain_grad(); // retain grad for non-leaf Tensory.backward();std::cout << y.grad() << std::endl;
1[ CPUFloatType{} ]
如果前面沒有y.retain_grad()直接調用y.grad(),將會導致core dumped:
[W TensorBody.h:489] Warning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-lea
f Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations. (function grad) [ Tensor (undefined) ] terminate called after throwing an instance of 'c10::Error' what(): Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward. Exception raised from unpack at ../torch/csrc/autograd/saved_variable.cpp:136 (most recent call first): frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7faba17f4d47 in /root/Documents/installation/libtorch/lib/libc10.so) frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, char const*) + 0x68 (0x7faba17ae0fc in /root/Documents/installation/libtorch/lib/libc10.so) frame #2: torch::autograd::SavedVariable::unpack(std::shared_ptr<torch::autograd::Node>) const + 0x13b2 (0x7fab8f87d6c2 in /root/Documents/installation/libtorch/lib/libtorch_cpu.so) frame #3: torch::autograd::generated::MeanBackward0::apply(std::vector<at::Tensor, std::allocator<at::Tensor> >&&) + 0x98 (0x7fab8eb73998 in /root/Documents/installation/libtorch/lib/libtorch_cpu.so) frame #4: <unknown function> + 0x4d068cb (0x7fab8f8428cb in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #5: torch::autograd::Engine::evaluate_function(std::shared_ptr<torch::autograd::GraphTask>&, torch::autograd::Node*, torch::autograd::InputBuffer&, std::shared_ptr<torch::autograd::ReadyQueue> const&) + 0xe8d (0x7fab8f83b94d in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #6: torch::autograd::Engine::thread_main(std::shared_ptr<torch::autograd::GraphTask> const&) + 0x698 (0x7fab8f83cca8 in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #7: torch::autograd::Engine::execute_with_graph_task(std::shared_ptr<torch::autograd::GraphTask> const&, std::shared_ptr<torch::autograd::Node>, torch::autograd::InputBuffer&&) + 0x3dd (0x7fab8f8378bd in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #8: torch::autograd::Engine::execute(std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&, std::vector<at::Tensor, std::allocator<at::Tensor> > const&, bool, bool, bool, std::vector<torch::autograd::Edge, std::allocator<torch::autograd::Edge> > const&) + 0xa26 (0x7fab8f83a546 in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #9: <unknown function> + 0x4ce0e81 (0x7fab8f81ce81 in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #10: torch::autograd::backward(std::vector<at::Tensor, std::allocator<at::Tensor> > const&, std::vector<at::Tensor, std::allocator<at::Tensor> > const&,c10::optional<bool>, bool, std::vector<at::Tensor, std::allocator<at::Tensor> > const&) + 0x5c (0x7fab8f81f88c in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #11: <unknown function> + 0x4d447de (0x7fab8f8807de in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #12: at::Tensor::_backward(c10::ArrayRef<at::Tensor>, c10::optional<at::Tensor> const&, c10::optional<bool>, bool) const + 0x48 (0x7fab8c51b208 in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #13: <unknown function> + 0x798a (0x5638af5ed98a in ./autograd)frame #14: <unknown function> + 0x4d55 (0x5638af5ead55 in ./autograd)frame #15: <unknown function> + 0x29d90 (0x7fab8a6e9d90 in /lib/x86_64-linux-gnu/libc.so.6)frame #16: __libc_start_main + 0x80 (0x7fab8a6e9e40 in /lib/x86_64-linux-gnu/libc.so.6)frame #17: <unknown function> + 0x4985 (0x5638af5ea985 in ./autograd)
繼續看x的梯度:
std::cout << x.grad() << std::endl;
0.2500 0.25000.2500 0.2500[ CPUFloatType{2,2} ]
at命名空間
改用at命名空間下的factory function創建張量:
// at命名空間at::Tensor x1 = at::ones({2, 2});std::cout << x1.requires_grad() << std::endl; // 0
如果我們使用跟torch::ones類似的方式在at::ones裡加入torch::requires_grad()參數會如何呢?結果x1.requires_grad()仍然會是0。回顧at::rand_symint,我們可以猜想這是因為在進一步調用底層函數時只關注options.dtype_opt,options.layout_opt,options.device_opt和options.pinned_memory_opt等四個選項,而忽略options.requires_grad:
at::_ops::rand::call(size, optTypeMetaToScalarType(options.dtype_opt()), options.layout_opt(), options.device_opt(), options.pinned_memory_opt());
定義y1變數,一開始其requires_grad為false:
at::Tensor y1 = x1.mean();std::cout << y1.requires_grad() << std::endl; // 0
因為此時x1, y1都是不可微的,如果嘗試調用y1.retain_grad()將會導致core dumped:
terminate called after throwing an instance of 'c10::Error'what(): can't retain_grad on Tensor that has requires_grad=FalseException raised from retain_grad at ../torch/csrc/autograd/variable.cpp:503 (most recent call first):frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7f7401f62d47 in /root/Documents/installation/libtorch/lib/libc10.so)frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, char const*) + 0x68 (0x7f7401f1c0fc in /root/Documents/installation/libtorch/lib/libc10.so)frame #2: <unknown function> + 0x4d4751f (0x7f73efff151f in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #3: <unknown function> + 0x4cef (0x560b61ca7cef in ./autograd)frame #4: <unknown function> + 0x29d90 (0x7f73eae57d90 in /lib/x86_64-linux-gnu/libc.so.6)frame #5: __libc_start_main + 0x80 (0x7f73eae57e40 in /lib/x86_64-linux-gnu/libc.so.6)frame #6: <unknown function> + 0x4965 (0x560b61ca7965 in ./autograd)Aborted (core dumped)
如果想要讓它們變成可微的呢?我們可以透過set_requires_grad函數:
x1.set_requires_grad(true);std::cout << "after set requires grad: " << x1.requires_grad() << std::endl; // 1std::cout << y1.requires_grad() << std::endl; // 0
可以看到這時候y1的requires_grad為false,這是因為x1改變了之後y1尚未更新。
透過以下方式更新後y1後,其requires_grad也會變為true:
y1 = x1.mean();std::cout << y1.requires_grad() << std::endl; // 1
y1.retain_grad();的作用是保留非葉子張量的梯度:
y1.retain_grad(); // retain grad for non-leaf Tensor
調用該函數的前提是該張量的requires_grad必須為true,如果省略y1 = x1.mean();這一行,因為y1的requires_grad為false,所以在y1.retain_grad();時會出現如下錯誤:
terminate called after throwing an instance of 'c10::Error'what(): can't retain_grad on Tensor that has requires_grad=FalseException raised from retain_grad at ../torch/csrc/autograd/variable.cpp:503 (most recent call first):frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7fafd2dfcd47 in /root/Documents/installation/libtorch/lib/libc10.so)frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, char const*) + 0x68 (0x7fafd2db60fc in /root/Documents/installation/libtorch/lib/libc10.so)frame #2: <unknown function> + 0x4d4751f (0x7fafc0e8b51f in /root/Documents/installation/libtorch/lib/libtorch_cpu.so)frame #3: <unknown function> + 0x4f77 (0x55f9a73dff77 in ./autograd)frame #4: <unknown function> + 0x29d90 (0x7fafbbcf1d90 in /lib/x86_64-linux-gnu/libc.so.6)frame #5: __libc_start_main + 0x80 (0x7fafbbcf1e40 in /lib/x86_64-linux-gnu/libc.so.6)frame #6: <unknown function> + 0x4985 (0x55f9a73df985 in ./autograd)Aborted (core dumped)
開始反向傳播,然後查看y1的梯度:
y1.backward();std::cout << y1.grad() << std::endl;
1[ CPUFloatType{} ]
如果注釋掉y1.retain_grad();,則y1的梯度不會被保留,只會輸出一個未定義的張量,並出現以下警告:
[W TensorBody.h:489] Warning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations. (function grad)[ Tensor (undefined) ]
查看x1的梯度:
std::cout << x1.grad() << std::endl;
結果與使用torch::時相同:
0.2500 0.25000.2500 0.2500[ CPUFloatType{2,2} ]
相关文章:

torch::和at:: factory function的差別
torch::和at:: factory function的差別 前言torch::autograd::THPVariable_randtorch::rand_symintat::rand_symintdemotorch命名空間at命名空間 前言 >>> import torch >>> a torch.rand(3, 4) >>> a.requires_grad False >>> a torch…...

与珎同行录-开篇-231129
与珎同行录-开篇 珎就是对陪伴并帮助我写代码的AI的昵称 能不能读懂这个绕口令问题呢? 连续的椎体的相邻椎体质心的相邻质心的质心作为当前质心所在的椎体的质心, 该质心的方向代表该椎体的上下方向 如何代码实现呢? 还是没看懂…好吧最终的算法是:...

linux logrotate日志轮询设置案例一
1.编辑/etc/logrotate.conf文件,添加如下配置,并保存 /var/log/ztj.log {missingokhourlycreate 644 root rootsharedscriptspostrotateif [ -f /var/run/syslogd.pid ];then/bin/kill -HUP $(/bin/cat /var/run/syslogd.pid) >/dev/null 2>&…...

Android 12.0 禁用adb reboot recovery命令实现正常重启功能
1.前言 在12.0的系统rom定制化开发中,在定制recovery模块的时候,由于产品开发需要要求禁用recovery的相关功能,比如在通过adb命令的 adb reboot recovery的方式进入recovery也需要实现禁用,所以就需要了解相关进入recovery流程来禁用该功能 2.禁用adb reboot recovery命令…...
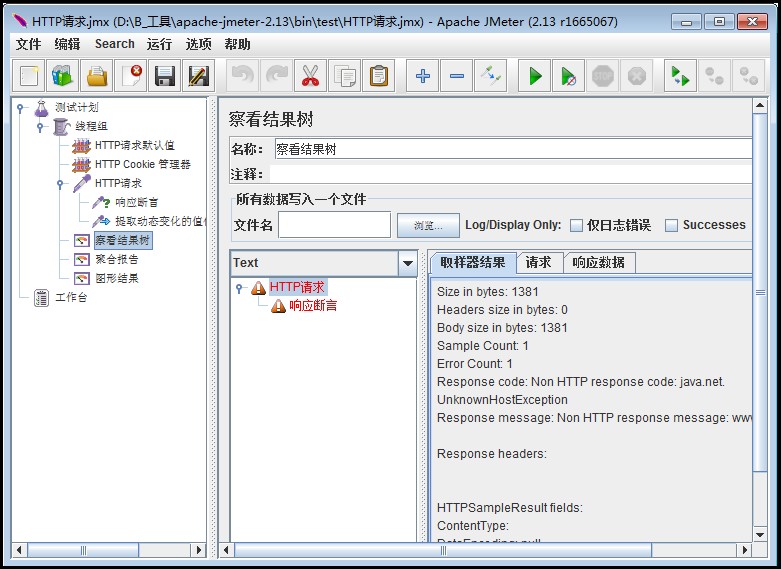
使用Jmeter进行http接口测试
前言: 本文主要针对http接口进行测试,使用Jmeter工具实现。 Jmter工具设计之初是用于做性能测试的,它在实现对各种接口的调用方面已经做的比较成熟,因此,本次直接使用Jmeter工具来完成对Http接口的测试。 一、开发接口…...
:ION 内存管理器——cma heap)
Linux内存管理(六十三):ION 内存管理器——cma heap
源码基于:Linux 5.4 约定: 芯片架构:ARM64内存架构:UMACONFIG_ARM64_VA_BITS:39CONFIG_ARM64_PAGE_SHIFT:12CONFIG_PGTABLE_LEVELS :3ION 系列博文: ION 总篇ION —— cma heapION —— system heap0. 前言 ION 是 Google 在 Android 4.0 中引入,目的主要是通过在硬件…...

条形码格式
条形码格式 简述EAN码EAN-13EAN-8 UPC码UPC-AUPC-E CODE128 简述 EAN码 EAN码(European Article Number)是国际物品编码协会制定的一种全球通用的商用条码。EAN码分为:标准版(EAN-13) 和 缩短版(EAN-8&am…...
)
Java通过Redis进行延时队列,定时发布消息(根据用户选择时间进行发布)
前言 目前很多产品都用到过定时发布或者定时推送等功能,定时推送有两种定义,一种是后台自己有相关规则,通过定时器设置好相应的时间进行推送(例如定时任务框架QuartZ、xxl-job等实现,或者通过springboot自带定时任务Scheduled注解等实现)&am…...
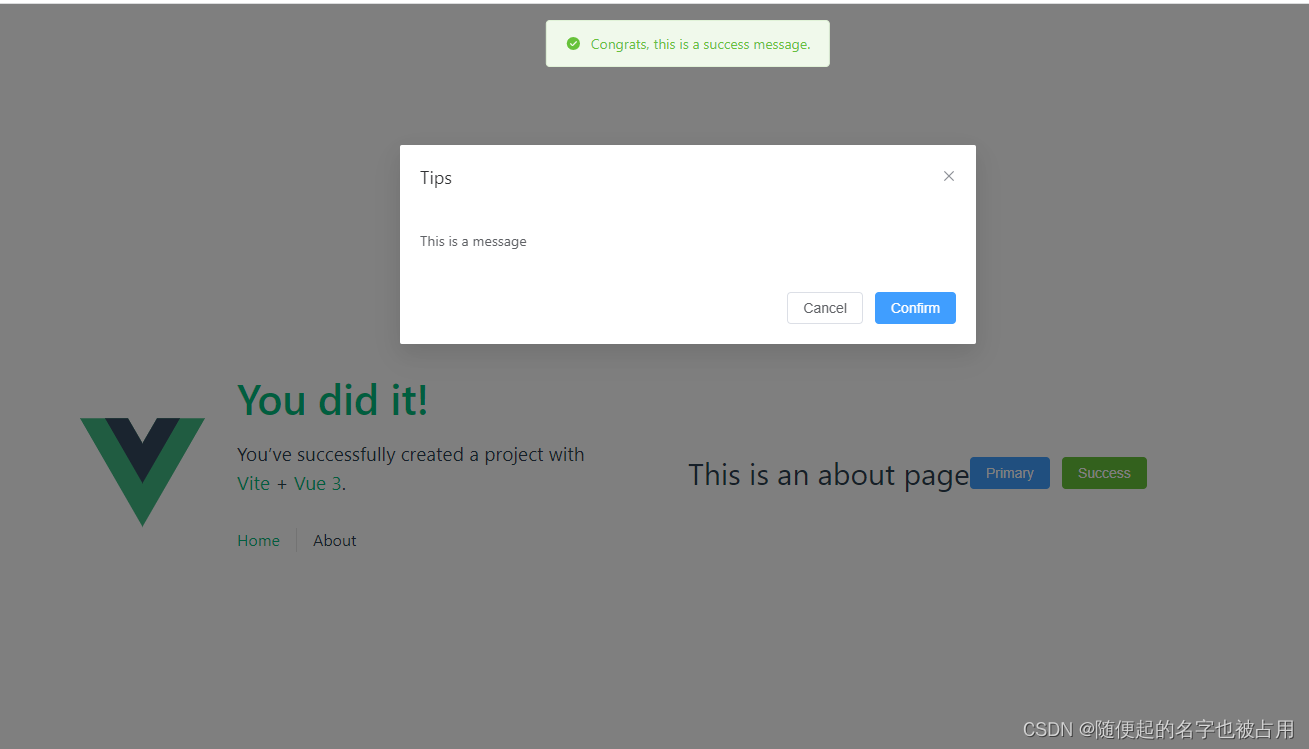
从 0 搭建 Vite 3 + Vue 3 Js版 前端工程化项目
之前分享过一篇vue3+ts+vite构建工程化项目的文章,针对小的开发团队追求开发速度,不想使用ts想继续使用js,所以就记录一下从0搭建一个vite+vue3+js的前端项目,做记录分享。 技术栈 Vite 3 - 构建工具 Vue 3 Vue Router - 官方路由管理器 Pinia - Vue Store你也可以选择vue…...

【论文阅读笔记】Smil: Multimodal learning with severely missing modality
Ma M, Ren J, Zhao L, et al. Smil: Multimodal learning with severely missing modality[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(3): 2302-2310.[开源] 本文的核心思想是探讨和解决多模态学习中的一个重要问题:在训练和测…...
在Windows系统上安装git-Git的过程记录
01-上git的官网下载git的windows安装版本 下载页面链接: https://git-scm.com/downloads 选择Standalone Installer的版本进行下载: 这里给大家一全git-2.43.0的百度网盘下载链接: https://pan.baidu.com/s/11HwNTCZmtSWj0VG2x60HIA?pwdut…...

qt QString常用方法
1. QString 尾部拼接,尾部插入字符.调用append()函数.同时,QString字符串直接用加号 也可以进行拼接. QString s "我的女神";s s "刘亦菲";s "最近可好?";s.append("你跑哪儿去了?");//拼接结果: 我的女神刘亦菲最近可好?你跑…...

吴恩达《机器学习》10-6-10-7:学习曲线、决定下一步做什么
一、学习曲线 1. 学习曲线概述 学习曲线将训练集误差和交叉验证集误差作为训练集实例数量(m)的函数绘制而成。这意味着从较少的数据开始,逐渐增加训练集的实例数量。该方法的核心思想在于,当训练较少数据时,模型可能…...
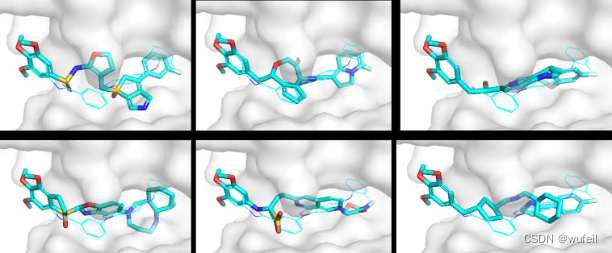
分子骨架跃迁工具-DiffHopp 评测
一、文章背景介绍 DiffHopp模型发表在ICML 2023 Workshop on Computational Biology(简称:2023 ICML-WCB)上的文章。第一作者是剑桥计算机系的Jos Torge。 DiffHopp是一个专门针对骨架跃迁任务而训练的E3等变条件扩散模型。此外,…...

MySQL双主双从数据库集群搭建
1 引言 在之前的文章中提到过相关搭建方法,具体请参考《MySQL主从数据库搭建》这篇文章,本文主要讲述双主双从,双主多从集群的搭建方式。 这里要问一个问题,为什么MySQL要搭建数据库集群呢?我想应该有以下几点原因&…...
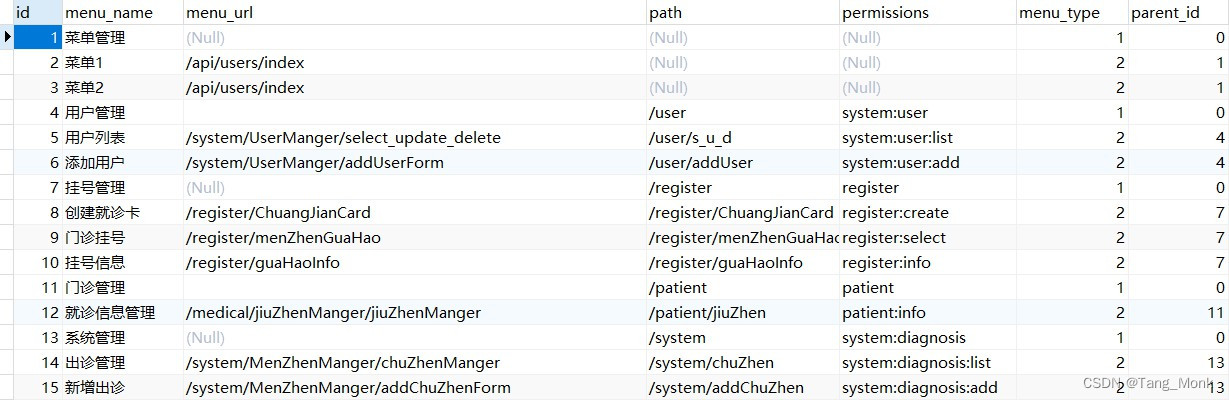
vue实现动态路由菜单!!!
目录 总结一、步骤1.编写静态路由编写router.jsmain.js注册 2.编写permisstions.js权限文件编写permisstions.jsaxios封装的APIstore.js状态库system.js Axios-APIrequest.js axios请求实例封装 3.编写菜单树组件MenuTree.vue 4.主页中使用菜单树组件 总结 递归处理后端响应的…...

企业如何选择安全又快速的大文件传输平台
在现代信息化社会,数据已经成为各个行业的重要资源,而数据的传输和交换则是数据价值的体现。在很多场合,企业需要传输或接收大文件,例如设计图纸、视频素材、软件开发包、数据库备份等。这些文件的大小通常在几百兆字节到几十个字…...
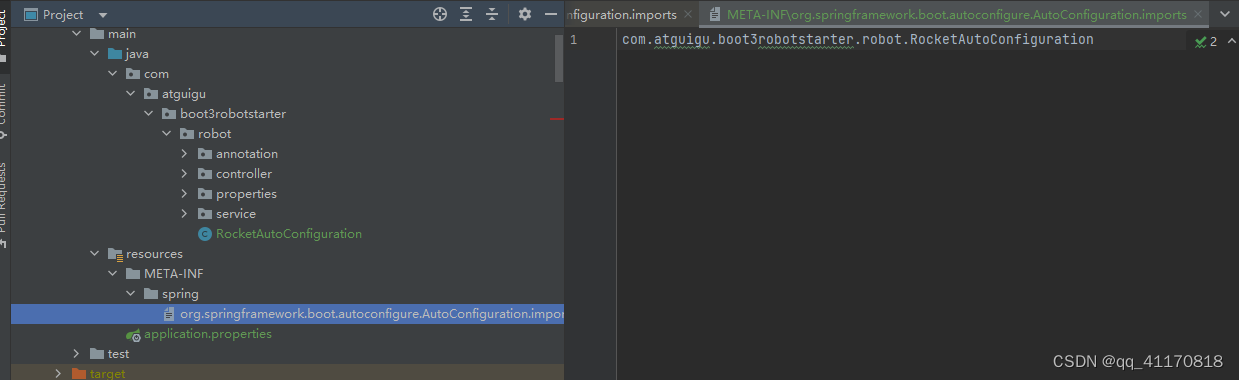
springboot 自定义starter逐级抽取
自定义starter 背景:各个组件需要引入starter 还有自己的配置风格 –基本配置原理 (1)自定义配置文件 导入配置可以在配置文件中自动识别,提示 导入依赖后可以发现提示 (2)配置文件实现 –让配置文件对其他模块生…...

GAN:ImprovedGAN-训练GAN的改进策略
论文:https://arxiv.org/abs/1606.03498 代码:https://github.com/openai/improved_gan 发表:NIPS 2016 一、文章创新 1:Feature matching:特征匹配通过为生成器指定新目标来解决GANs的不稳定性,从而防止…...

docker限制容器内存的方法
在服务器中使用 docker 时,如果不对 docker 的可调用内存进行限制,当 docker 内的程序出现不可预测的问题时,就很有可能因为内存爆炸导致服务器主机的瘫痪。而对 docker 进行限制后,可以将瘫痪范围控制在 docker 内。 因此&#…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

Gofile批量下载自动化工具:5步实现高效文件管理解决方案
Gofile批量下载自动化工具:5步实现高效文件管理解决方案 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader 在当今数字化工作环境中,技术团队经常需要从…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器
BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

UE4SS终极指南:从零开始掌握虚幻引擎脚本系统
UE4SS终极指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE4S…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...

Noto字体终极指南:告别“豆腐块“,让全球文字清晰显示
Noto字体终极指南:告别"豆腐块",让全球文字清晰显示 【免费下载链接】noto-fonts Noto fonts, except for CJK and emoji 项目地址: https://gitcode.com/gh_mirrors/no/noto-fonts 在数字世界中,你是否经常看到那些令人困…...

3PEAK思瑞浦 TPA6531-S5TR SOT23-5 运算放大器
特性 供电电压:1.75V至5.5V 偏移电压:1.5mV(最大值) 最大可调工作频率:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1赫兹至10赫兹电压噪声:1伏峰值 开关电源时无显著输出抖动 低功耗:每通道最大25安培 工作温度范围:-40C至125C...