【Java学习笔记】73 - 正则表达式
项目代码
https://github.com/yinhai1114/Java_Learning_Code/tree/main/IDEA_Chapter27/src/com/yinhai/regexp
一、引入正则表达式
1.提取文章中所有的英文单词
2.提取文章中所有的数字
3.提取文章中所有的英文单词和数字
4.提取百度热榜标题
正则表达式是处理文本的利器
public class Regexp {public static void main(String[] args) {//假定编写了爬虫 从百度页面得到文本String content = "1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的" +"静态网页能够“灵活”起来,急需一种软件技术来开发一种程序,这种程序可以通" +"过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投入了大量的" +"人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且" +"重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结" +"构进行编写的,所以非常小,特别适用于网络上的传输系统,而Oak也是一种精简的" +"语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以嵌入网页并且可以" +"随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的技术)," +"并将Oak更名为Java(在申请注册商标时,发现Oak已经被人使用了,再想了一系列" +"名字之后,最终,使用了提议者在喝一杯Java咖啡时无意提到的Java词" +"语)。5月23日,Sun公司在Sun world会议上正式发" +"布Java和HotJava浏览器。IBM、Apple、DEC、Adobe、HP、Oracle、Netscape和微软" +"等各大公司都纷纷停止了自己的相关开发项目,竞相购买了Java使用许可证,并为自己的产" +"品开发了相应的Java平台";//(1). 传统方法. 使用遍历方式,代码量大,效率不高//(2). 正则表达式技术//1. 先创建一个Pattern对象 , 模式对象, 可以理解成就是一个正则表达式对象Pattern pattern = Pattern.compile("[a-zA-Z]+");//提取文章中所有的英文单词//Pattern pattern = Pattern.compile("[0-9]+");//提取文章中所有的数字//Pattern pattern = Pattern.compile("([0-9]+)|([a-zA-Z]+)");//提取文章中所有的英文单词和数字//Pattern pattern = Pattern.compile("<a target=\"_blank\" title=\"(\\S*)\"");//提取百度热榜 标题// Pattern pattern = Pattern.compile("\\d+\\.\\d+\\.\\d+\\.\\d+");//2. 创建一个匹配器对象//理解: 就是 matcher 匹配器按照 pattern(模式/样式), 到 content 文本中去匹配//找到就返回true, 否则就返回falseint no = 0;Matcher matcher = pattern.matcher(content);//3. 可以开始循环匹配while (matcher.find()) {//匹配内容,文本,放到 m.group(0)System.out.println("找到: " + (++no) + " " +matcher.group(0));}}
}
1.给你一个字符串(或文章),请你找出所有四个数字连在一起的子串?
2.给你一个字符串(或文章),请你找出所有四个数字连在一起的子串,并且这四个数字要满足:第一位与第四位相同,第二位与第三位相同,比如1221 , 5775
3.请验证输入的邮件,是否符合电子邮件格式.
4.请验证输入的手机号,是否符合手机号格式
解决之道-正则表达式
1.为了解决上述问题,Java提供 了正则表达式技术,专门用于处理类似文本处理问题
2.简单的说:正则表达式是对字符串执行模式匹配的技术。
3.正则表达式: regular expression => RegExp
二、基本介绍
1.一个正则表达式,就是用某种模式去匹配字符串的一个公式。很多人因为它们看上去比较古怪而且复杂所以不敢去使用,不过,经过练习后,就觉得这些复杂的表达式写起来还是相当简单的,而且,一旦你弄懂它们,你就能把数小时辛苦而且易错的文本处理工作缩短在几分钟(甚至几秒钟)内完成
2.老韩这里要特别强调,正则表达式不是只有java才有,实际上很多编程语言都支持正则表达式进行字符串操作!如图所示。
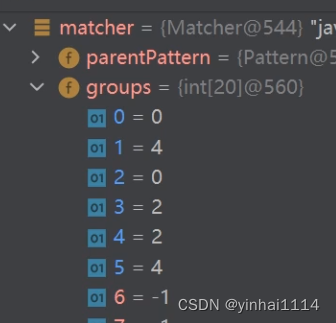
public class RegTheory {public static void main(String[] args) {String content = "1998年12月8日,第二代Java平台的企业版J2EE发布。1999年6月,Sun公司发布了" +"第二代Java平台(简称为Java2)的3个版本:J2ME(Java2 Micro Edition,Java2平台的微型" +"版),应用于移动、无线及有限资源的环境;J2SE(Java 2 Standard Edition,Java 2平台的" +"标准版),应用于桌面环境;J2EE(Java 2Enterprise Edition,Java 2平台的企业版),应" +"用3443于基于Java的应用服务器。Java 2平台的发布,是Java发展过程中最重要的一个" +"里程碑,标志着Java的应用开始普及9889 ";//目标:匹配所有四个数字//说明//1. \\d 表示一个任意的数字String regStr = "(\\d\\d)(\\d\\d)";//2. 创建模式对象[即正则表达式对象]Pattern pattern = Pattern.compile(regStr);//3. 创建匹配器//说明:创建匹配器matcher, 按照 正则表达式的规则 去匹配 content字符串Matcher matcher = pattern.matcher(content);//4.开始匹配/**** matcher.find() 完成的任务 (考虑分组)* 什么是分组,比如 (\d\d)(\d\d) ,正则表达式中有() 表示分组,第1个()表示第1组,第2个()表示第2组...* 1. 根据指定的规则 ,定位满足规则的子字符串(比如(19)(98))* 2. 找到后,将 子字符串的开始的索引记录到 matcher对象的属性 int[] groups;* 2.1 groups[0] = 0 , 把该子字符串的结束的索引+1的值记录到 groups[1] = 4* 2.2 记录1组()匹配到的字符串 groups[2] = 0 groups[3] = 2* 2.3 记录2组()匹配到的字符串 groups[4] = 2 groups[5] = 4* 2.4.如果有更多的分组.....* 3. 同时记录oldLast 的值为 子字符串的结束的 索引+1的值即35, 即下次执行find时,就从35开始匹配** matcher.group(0) 分析** 源码:* public String group(int group) {* if (first < 0)* throw new IllegalStateException("No match found");* if (group < 0 || group > groupCount())* throw new IndexOutOfBoundsException("No group " + group);* if ((groups[group*2] == -1) || (groups[group*2+1] == -1))* return null;* return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();* }* 1. 根据 groups[0]=31 和 groups[1]=35 的记录的位置,从content开始截取子字符串返回* 就是 [31,35) 包含 31 但是不包含索引为 35的位置** 如果再次指向 find方法.仍然安上面分析来执行*/while (matcher.find()) {//小结//1. 如果正则表达式有() 即分组//2. 取出匹配的字符串规则如下//3. group(0) 表示匹配到的子字符串//4. group(1) 表示匹配到的子字符串的第一组字串//5. group(2) 表示匹配到的子字符串的第2组字串//6. ... 但是分组的数不能越界.System.out.println("找到: " + matcher.group(0));System.out.println("第1组()匹配到的值=" + matcher.group(1));System.out.println("第2组()匹配到的值=" + matcher.group(2));}}
}
三、语法
1.转义符
符号说明:在我们使用正则表达式去检索某些特殊字符的时候,需要用到转义符号,否则检索不到结果,甚至会报错的。案例:用$去匹配"abc$(" 会怎样?用(去匹配"abc$(" 会怎样?
元字符-转义符
需要用到转义符号的字符有以下: . * + () $ / \ ? [ ] ^ {}
public class RegExp02 {public static void main(String[] args) {String content = "abc$(a.bc(123( )";//匹配( => \\( String regStr = "\\(";//匹配. => \\. String regStr = "\\.";//String regStr = "\\d\\d\\d";String regStr = "\\d{3}";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}
2.字符匹配符
应用实例:
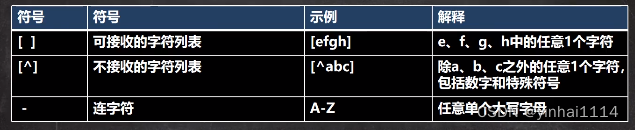
1. [a-z] 说明:[a-z]表示可以匹配a-z中任意一个字符,比如[a-z]、[A-Z] 去匹配a11c8会得到什么结果?
2. java正则表达式默认是区分字母大小写的,如何实现不区分大小写
(?i)abc表示abc都不区分大小写
a(?i)bc表示bc不区分大小写
a((?i)b)c表示只有b不区分大小写
Pattern pat = Pattern.compile(regEx, Pattern.CASE_INSENSITIVE);
[A-Z]表示可以匹配A-Z中任意一个字符。
[0-9]表示可以匹配0-9中任意一个字符。
3. [^a-z] 说明:
[^ a-z]表示可以四配不是a-z中的任意一个字符,比如
我们看看[^a-z]去匹配a11c8会得到什么结果?用[^a-z]{2}又会得到什么结果呢?
[^A-Z]表示可以匹配不是A- Z中的任意一个字符。
[^0-9]表示可以匹配不是0-9中的任意一个字符。
4. [abcd] 表示可以匹配abcd中的任意一个字符。
5.[^abcd]表示可以匹配不是abcd中的任意一个字符。当然上面的abcd你可以根据实际情况修改,以适应你的需求
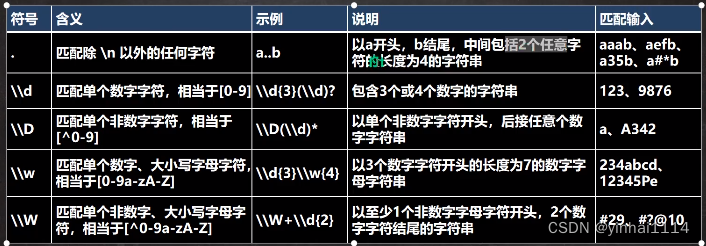
6. \\d 表示可以四配-9的任意-个数字,相当于[0-9]。
7. \\D 表示可以四配不是0-9中的任意一个数字,相当于[^0-9]
8. \\w 四配任意英文字符、数字和下划线,相当于[a-zA-Z0-9 ]
9.\\W相当于[^a-zA-Z0-9 ]是\w刚好相反
10. \\s四配任何空白字符(空格制表符等)
11.\\S匹配任何非空白字符和\\s刚好相反
12. . 匹配出\n之外的所有字符,如果要匹配 .本身则需要使用 \\.
public class RegExp03 {public static void main(String[] args) {String content = "a11c8abc _ABCy @";//String regStr = "[a-z]";//匹配 a-z之间任意一个字符//String regStr = "[A-Z]";//匹配 A-Z之间任意一个字符//String regStr = "abc";//匹配 abc 字符串[默认区分大小写]//String regStr = "(?i)abc";//匹配 abc 字符串[不区分大小写]//String regStr = "[0-9]";//匹配 0-9 之间任意一个字符//String regStr = "[^a-z]";//匹配 不在 a-z之间任意一个字符//String regStr = "[^0-9]";//匹配 不在 0-9之间任意一个字符//String regStr = "[abcd]";//匹配 在 abcd中任意一个字符//String regStr = "\\D";//匹配 不在 0-9的任意一个字符//String regStr = "\\w";//匹配 大小写英文字母, 数字,下划线//String regStr = "\\W";//匹配 等价于 [^a-zA-Z0-9_]//\\s 匹配任何空白字符(空格,制表符等)//String regStr = "\\s";//\\S 匹配任何非空白字符 ,和\\s刚好相反//String regStr = "\\S";//. 匹配出 \n 之外的所有字符,如果要匹配.本身则需要使用 \\.String regStr = ".";//说明//1. 当创建Pattern对象时,指定 Pattern.CASE_INSENSITIVE, 表示匹配是不区分字母大小写.Pattern pattern = Pattern.compile(regStr/*, Pattern.CASE_INSENSITIVE*/);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}3.选择匹配符
在匹配某个字符串的时候是选择性的,即:既可以匹配这个,又可以四配那个,这时你需
要用到选择匹配符号RegExp04.java
public class RegExp04 {public static void main(String[] args) {String content = "hanshunping 韩 寒冷";String regStr = "han|韩|寒";Pattern pattern = Pattern.compile(regStr/*, Pattern.CASE_INSENSITIVE*/);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}
4.限定符
用于指定其前面的字符和组合项连续出现多少次
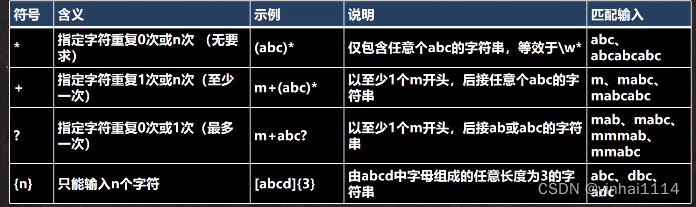

public class RegExp05 {public static void main(String[] args) {String content = "a211111aaaaaahello";//a{3},1{4},\\d{2}//String regStr = "a{3}";// 表示匹配 aaa//String regStr = "1{4}";// 表示匹配 1111//String regStr = "\\d{2}";// 表示匹配 两位的任意数字字符//a{3,4},1{4,5},\\d{2,5}//细节:java匹配默认贪婪匹配,即尽可能匹配多的//String regStr = "a{3,4}"; //表示匹配 aaa 或者 aaaa//String regStr = "1{4,5}"; //表示匹配 1111 或者 11111//String regStr = "\\d{2,5}"; //匹配2位数或者3,4,5//1+//String regStr = "1+"; //匹配一个1或者多个1//String regStr = "\\d+"; //匹配一个数字或者多个数字//1*//String regStr = "1*"; //匹配0个1或者多个1//演示?的使用, 遵守贪婪匹配String regStr = "a1?"; //匹配 a 或者 a1Pattern pattern = Pattern.compile(regStr/*, Pattern.CASE_INSENSITIVE*/);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}5.定位符
定位符,规定要匹配的字符串出现的位置,比如在字符串的开始还是在结束的位置,这个
也是相当有用的

public class RegExp06 {public static void main(String[] args) {String content = "hanshunping sphan nnhan";//String content = "123-abc";//以至少1个数字开头,后接任意个小写字母的字符串//String regStr = "^[0-9]+[a-z]*";//以至少1个数字开头, 必须以至少一个小写字母结束//String regStr = "^[0-9]+\\-[a-z]+$";//表示匹配边界的han[这里的边界是指:被匹配的字符串最后,也可以是空格的子字符串的后面]//String regStr = "han\\b";//和\\b的含义刚刚相反String regStr = "han\\B";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到=" + matcher.group(0));}}
}
6.分组

public class RegExp07 {public static void main(String[] args) {String content = "hanshunping s7789 nn1189han";//下面就是非命名分组//说明// 1. matcher.group(0) 得到匹配到的字符串// 2. matcher.group(1) 得到匹配到的字符串的第1个分组内容// 3. matcher.group(2) 得到匹配到的字符串的第2个分组内容//String regStr = "(\\d\\d)(\\d\\d)";//匹配4个数字的字符串//命名分组: 即可以给分组取名String regStr = "(?<g1>\\d\\d)(?<g2>\\d\\d)";//匹配4个数字的字符串Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到=" + matcher.group(0));System.out.println("第1个分组内容=" + matcher.group(1));System.out.println("第1个分组内容[通过组名]=" + matcher.group("g1"));System.out.println("第2个分组内容=" + matcher.group(2));System.out.println("第2个分组内容[通过组名]=" + matcher.group("g2"));}}
}
7.特别分组
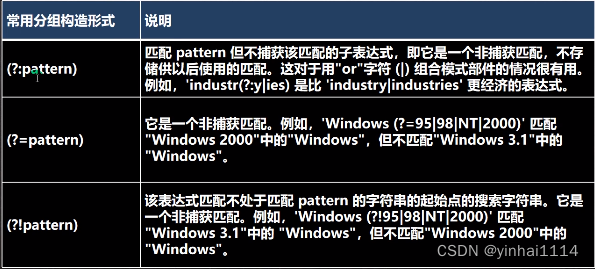
给字符串String content = "hello韩顺平教育jack韩顺平老师韩顺平同学hello";
使用非捕获分组完成,如下要求
1.找到韩顺平教育、韩顺平老师、韩顺平同学子字符串
2.找到韩顺平这个关键字,但是要求只是查找韩顺平教育和韩顺平老师中包含有的韩顺平
3.找到韩顺平这个关键字,但是要求只是查找不是(韩顺平教育和韩顺平老师)中包含有的韩顺平
1.
2.
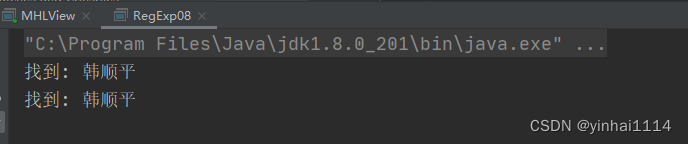
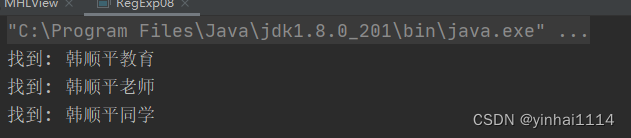
public class RegExp08 {public static void main(String[] args) {String content = "hello韩顺平教育 jack韩顺平老师 韩顺平同学hello韩顺平学生";// 找到 韩顺平教育 、韩顺平老师、韩顺平同学 子字符串//String regStr = "韩顺平教育|韩顺平老师|韩顺平同学";//上面的写法可以等价非捕获分组, 注意:不能 matcher.group(1)// String regStr = "韩顺平(?:教育|老师|同学)";//找到 韩顺平 这个关键字,但是要求只是查找韩顺平教育和 韩顺平老师 中包含有的韩顺平//下面也是非捕获分组,不能使用 matcher.group(1)// String regStr = "韩顺平(?:教育|老师)";// String regStr = "韩顺平(?=教育|老师)";//找到 韩顺平 这个关键字,但是要求只是查找 不是 (韩顺平教育 和 韩顺平老师) 中包含有的韩顺平//下面也是非捕获分组,不能使用 matcher.group(1)String regStr = "韩顺平(?!教育|老师)";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到: " + matcher.group(0));}}
}
8.非贪婪匹配
当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?"只匹配单个"o",而"o+"匹配所有"o"。
public class RegExp09 {public static void main(String[] args) {String content = "hello111111 ok";//String regStr = "\\d+"; //默认是贪婪匹配// String regStr = "\\d+?"; //非贪婪匹配String regStr = "\\d+?"; //非贪婪匹配Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到: " + matcher.group(0));}}
}四、 正则表达式元字符说明表
字符
说明
\
将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如,"n"匹配字符"n"。"\n"匹配换行符。序列"\\\\"匹配"\\","\\("匹配"("。
^
匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n"或"\r"之后的位置匹配。
$
匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与"\n"或"\r"之前的位置匹配。
*
零次或多次匹配前面的字符或子表达式。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。
+
一次或多次匹配前面的字符或子表达式。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。
?
零次或一次匹配前面的字符或子表达式。例如,"do(es)?"匹配"do"或"does"中的"do"。? 等效于 {0,1}。
{n}
n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。
{n,}
n 是非负整数。至少匹配 n 次。例如,"o{2,}"不匹配"Bob"中的"o",而匹配"foooood"中的所有 o。"o{1,}"等效于"o+"。"o{0,}"等效于"o*"。
{n,m}
m 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。'o{0,1}' 等效于 'o?'。注意:您不能将空格插入逗号和数字之间。
?
当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?"只匹配单个"o",而"o+"匹配所有"o"。
.
匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。
(pattern)
匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果"匹配"集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用"\("或者"\)"。
(?:pattern)
匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用"or"字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 'industry|industries' 更经济的表达式。
(?=pattern)
执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?=95|98|NT|2000)' 匹配"Windows 2000"中的"Windows",但不匹配"Windows 3.1"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。
(?!pattern)
执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?!95|98|NT|2000)' 匹配"Windows 3.1"中的 "Windows",但不匹配"Windows 2000"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。
x|y
匹配 x 或 y。例如,'z|food' 匹配"z"或"food"。'(z|f)ood' 匹配"zood"或"food"。
[xyz]
字符集。匹配包含的任一字符。例如,"[abc]"匹配"plain"中的"a"。
[^xyz]
反向字符集。匹配未包含的任何字符。例如,"[^abc]"匹配"plain"中"p","l","i","n"。
[a-z]
字符范围。匹配指定范围内的任何字符。例如,"[a-z]"匹配"a"到"z"范围内的任何小写字母。
[^a-z]
反向范围字符。匹配不在指定的范围内的任何字符。例如,"[^a-z]"匹配任何不在"a"到"z"范围内的任何字符。
\b
匹配一个字边界,即字与空格间的位置。例如,"er\b"匹配"never"中的"er",但不匹配"verb"中的"er"。
\B
非字边界匹配。"er\B"匹配"verb"中的"er",但不匹配"never"中的"er"。
\cx
匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是"c"字符本身。
\d
数字字符匹配。等效于 [0-9]。
\D
非数字字符匹配。等效于 [^0-9]。
\f
换页符匹配。等效于 \x0c 和 \cL。
\n
换行符匹配。等效于 \x0a 和 \cJ。
\r
匹配一个回车符。等效于 \x0d 和 \cM。
\s
匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。
\S
匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。
\t
制表符匹配。与 \x09 和 \cI 等效。
\v
垂直制表符匹配。与 \x0b 和 \cK 等效。
\w
匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。
\W
与任何非单词字符匹配。与"[^A-Za-z0-9_]"等效。
\xn
匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,"\x41"匹配"A"。"\x041"与"\x04"&"1"等效。允许在正则表达式中使用 ASCII 代码。
\num
匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,"(.)\1"匹配两个连续的相同字符。
\n
标识一个八进制转义码或反向引用。如果 \n 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。
\nm
标识一个八进制转义码或反向引用。如果 \nm 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 \nm 前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 \nm 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。
\nml
当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。
\un
匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。
五、案例
1.汉字

2.邮政编码
要求:是1-9开头的一个六位数.比如: 123890
3.QQ号码
要求:是1-9开头的一个(5位数10位数)比如: 12389 , 1345687,187698765
4.手机号码
要求必须以13,14,15,18开头的11位数,比如13588889999
public class RegExp10 {public static void main(String[] args) {//汉字//String content = "韩顺平教育";// String regStr = "^[\u0391-\uffe5]+$";//邮政编码//要求:是1-9开头的一个六位数.比如: 123890// String content = "111140";//要求是1-9开头的六位数 比如123890// String regStr = "^[1-9]\\d{5}$";//QQ号码//要求:是1-9开头的一个(5位数10位数)比如: 12389 , 1345687,187698765// String content = "111140";// String regStr = "^[1-9]\\d{4,9}$";//手机号码//要求必须以13,14,15,18开头的11位数,比如13588889999String content = "13588889999";String regStr = "^1[3|4|5|8]\\d{9}$";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);if(matcher.find()){System.out.println("满足格式");}else{System.out.println("不满足格式");}}
}5. URL: 如: https://www.bilibili.com/video/BV1fh411y7R8?p=893&spm_id_from=pageDriver&vd_source=6af85ae96c487fe7bd51b3d5644ebafc
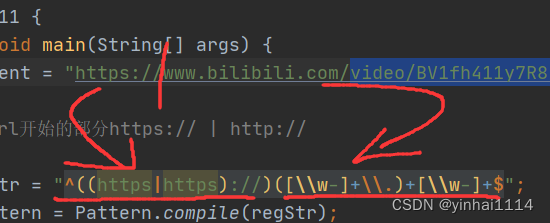
public class RegExp11 {public static void main(String[] args) {String content = "https://www.bilibili.com/video/BV1fh411y7R8?p=893&spm_id_from=pageDriver&vd_source=6af85ae96c487fe7bd51b3d5644ebafc";/*1.先确定url开始的部分https:// | http://2.然后匹配www.bilibili.com -> ([\w-]+\.)+[\w-]+3.然后匹配/video/BV1fh411y7R8?p=893&spm_id_from=page... -> (\/[\w-?=&/%.#]*)?*///中括号内的?.都是表示字符的?.并不带有其他含义String regStr = "^((https|https)://)([\\w-]+\\.)+[\\w-]+(\\/[\\w-?=&/%.#]*)?$";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);if(matcher.find()){System.out.println("格式正确");}else{System.out.println("格式错误");}}
}六、正则表达式三个常用类
正则表达式三个常用类
java.util.regex包主要包括以下三个类Pattern类、Matcher 类和PatternSyntaxException
Pattern 类
pattern对象是一个正则表达式对象。 Pattern 类没有公共构造方法。要创建一个Pattern对象,调用其公共静态方法,它返回一个Pattern对象。该方法接受一个正则表达式作为它的第个参数,比如: Pattern r = Pattern.compile(pattern);
Matcher类
Matcher对象是对输入字符串进行解释和匹配的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用Pattern对象的matcher方法来获得一个Matcher对象
PatternSyntaxException
PatternSyntaxException是一个非强制异常类,它表示个正则表达式模式中的语法错误。
1.Matcher类
public class PatternMethod {public static void main(String[] args) {String content = "hello abc hello, 韩顺平教育";//String regStr = "hello";String regStr = "hello.*";boolean matches = Pattern.matches(regStr, content);System.out.println("整体匹配= " + matches);}
}



public class MatcherMethod {public static void main(String[] args) {String content = "hello edu jack hspedutom hello smith hello hspedu hspedu";String regStr = "hello";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("=================");System.out.println(matcher.start());System.out.println(matcher.end());System.out.println("找到: " + content.substring(matcher.start(), matcher.end()));}//整体匹配方法,常用于,去校验某个字符串是否满足某个规则System.out.println("整体匹配=" + matcher.matches());//完成如果content 有 hspedu 替换成 韩顺平教育regStr = "hspedu";pattern = Pattern.compile(regStr);matcher = pattern.matcher(content);//注意:返回的字符串才是替换后的字符串 原来的 content 不变化String newContent = matcher.replaceAll("韩顺平教育");System.out.println("newContent=" + newContent);System.out.println("content=" + content);}
}
七、分组、捕获 、反向引用
给你一段文本,请你找出所有四个数字连在一起的子串, 并且这四个数字要满足(1)第1位与,第4位相同(2)第2位与第3位相同,比如1221,5775
1.介绍
要解决前面的问题,我们需要了解正则表达式的几个概念:
1. 分组我们可以用圆括号组成一个比较复杂的匹配模式,那么一个圆括号的部分我们可
以看作是一个子表达式 / 一个分组。
2.捕获把正则表达式中子表达式 / 分组四配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用,从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。组0代表的是整个正则式
3.反向引用圆括号的内容被捕获后,可以在这个括号后被使用,从而写出一个比较实用的匹配模式,这个我们称为反向引用,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部,内部反向引用 \\分组号,外部反向引用$分组号
2.案例
1.要匹配两个连续的相同数字: (\\d)\\1
2.要匹配五个连续的相同数字:(\\d)\\1\\1\\1\\1
3.要匹配个位与干位相同,十位与百位相同的数5225, 1551 (\\d)(\\d)\\2\\1
public class RegExp12 {public static void main(String[] args) {String content = "h1234el9876lo33333 j12324-333999111a1551ck14 tom11 jack22 yyy12345 xxx";//要匹配两个连续的相同数字 : (\\d)\\1//String regStr = "(\\d)\\1";//要匹配五个连续的相同数字: (\\d)\\1{4}//String regStr = "(\\d)\\1{4}";//要匹配个位与千位相同,十位与百位相同的数 5225 , 1551 (\\d)(\\d)\\2\\1//String regStr = "(\\d)(\\d)\\2\\1";/*** 请在字符串中检索商品编号,形式如:12321-333999111 这样的号码,* 要求满足前面是一个五位数,然后一个-号,然后是一个九位数,连续的每三位要相同*/String regStr = "\\d{5}-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";Pattern pattern = Pattern.compile(regStr);Matcher matcher = pattern.matcher(content);while (matcher.find()) {System.out.println("找到 " + matcher.group(0));}}
}
3.经典结巴程序
//0898_韩顺平Java_结巴去重案例_哔哩哔哩_bilibili
有点不了解底层原理 可以再搜一下 先过一遍
public class RegExp13 {public static void main(String[] args) {String content = "我....我要....学学学学....编程java!";//1. 去掉所有的.Pattern pattern = Pattern.compile("\\.");Matcher matcher = pattern.matcher(content);content = matcher.replaceAll("");// System.out.println("content=" + content);//2. 去掉重复的字 我我要学学学学编程java!// 思路//(1) 使用 (.)\\1+//(2) 使用 反向引用$1 来替换匹配到的内容// 注意:因为正则表达式变化,所以需要重置 matcher
// pattern = Pattern.compile("(.)\\1+");//分组的捕获内容记录到$1
// matcher = pattern.matcher(content);
// while (matcher.find()) {
// System.out.println("找到=" + matcher.group(0));
// }
//
// //使用 反向引用$1 来替换匹配到的内容
// content = matcher.replaceAll("$1");
// System.out.println("content=" + content);//3. 使用一条语句 去掉重复的字 我我要学学学学编程java!content = Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");System.out.println("content=" + content);}
}八、在String类中使用正则表达式
public class StringReg {public static void main(String[] args) {String content = "2000年5月,JDK1.3、JDK1.4和J2SE1.3相继发布,几周后其" +"获得了Apple公司Mac OS X的工业标准的支持。2001年9月24日,J2EE1.3发" +"布。" +"2002年2月26日,J2SE1.4发布。自此Java的计算能力有了大幅提升";//使用正则表达式方式,将 JDK1.3 和 JDK1.4 替换成JDKcontent = content.replaceAll("JDK1\\.3|JDK1\\.4", "JDK");System.out.println(content);//要求 验证一个 手机号, 要求必须是以138 139 开头的content = "13888889999";if (content.matches("1(38|39)\\d{8}")) {System.out.println("验证成功");} else {System.out.println("验证失败");}//要求按照 # 或者 - 或者 ~ 或者 数字 来分割System.out.println("===================");content = "hello#abc-jack12smith~北京";String[] split = content.split("#|-|~|\\d+");for (String s : split) {System.out.println(s);}}
}
相关文章:
【Java学习笔记】73 - 正则表达式
项目代码 https://github.com/yinhai1114/Java_Learning_Code/tree/main/IDEA_Chapter27/src/com/yinhai/regexp 一、引入正则表达式 1.提取文章中所有的英文单词 2.提取文章中所有的数字 3.提取文章中所有的英文单词和数字 4.提取百度热榜标题 正则表达式是处理文本的利器…...
【算法】滑动窗口题单——1.定长滑动窗口⭐
文章目录 1456. 定长子串中元音的最大数目2269. 找到一个数字的 K 美丽值1984. 学生分数的最小差值(排序)643. 子数组最大平均数 I1343. 大小为 K 且平均值大于等于阈值的子数组数目2090. 半径为 k 的子数组平均值2379. 得到 K 个黑块的最少涂色次数1052…...

可观测性项目开发与学习ing
http1,2,3的区别 HTTP/1.0、HTTP/1.1、HTTP/2 和 HTTP/3 是不同版本的协议,它们在以下方面有所不同: HTTP/1.0: 是最早的版本,主要特点如下: 每个请求和响应都需要建立一个新的 TCP 连接。不支持持久连接(Keep-Alive&…...

apache-poi
excel类型 excel分为03版本和07版本 03版本 new HSSFWorkbook(); 优点:速度快 缺点:只能写入65536行数据 文件类型:.xls07版本 new XSSFWorkbook(); 优点:不限制写入数量 缺点:容易造成内存溢出(OOM),速度…...
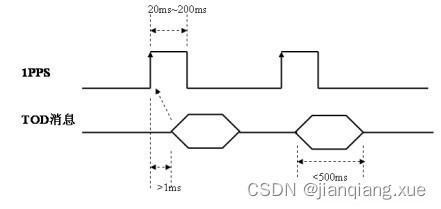
TOD和PPS精确时间同步技术
介绍 PPS和TOD PPS和TOD是两种用于精确时间同步的技术,它们在许多领域都有广泛的应用,总的来说,PPS和TOD被广泛应用于各种需要高度精确时间同步的领域,包括通信、测量、测试、系统集成和计算机网络等。 一、PPS PPS(…...

通过一个例子理解pytest的fixture的使用
需求 希望编写登陆web后做一些操作的测试用例,使用pytest框架具体测试用例执行前,需要先拿到web的token,这个获取token的动作只执行一次 例一 先上测试用例代码 adminpc-1:~$ cat my_test.py import pytestclass TestWebLogin:pytest.fi…...
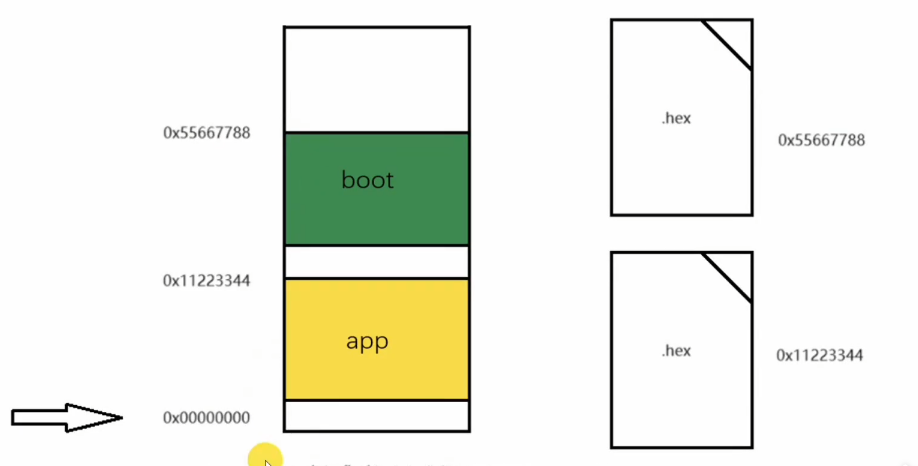
单片机BootLoader是咋回事?
BootLoader的定义: CPU进入APP之前运行的一小段程序代码就叫做BootLoader。它是由程序员编写的,作用是更新应用程序。这也就说明了只有BootLoader的单片机才可以升级。有的产品有升级的需要就需要BootLoader了。 单片机的启动过程可以这么叙述ÿ…...
)
python与机器学习1,机器学习的一些基础知识(完善ing)
目录 1 关于阈值θ和偏移量b和公式变形的由来 2 激活函数 3 关于回归,分类等 4 关于模型 5 关于回归 6 关于分类 7 关于误差和梯度下降 7-2 最小二乘法修改θ 8 深度学习 10 分类 11 参考书籍 1 关于阈值θ和偏移量b和公式变形的由来 比如很多信息传入可…...

移动应用开发介绍及iOS方向学习路线(HUT移动组版)
移动应用开发介绍及iOS方向学习路线(HUT移动组版) 前言 作为一个HUT移动组待了一坤年(两年半)多的老人,在这里为还在考虑进哪个组的萌新们以及将来进组的新朋友提供一份关于移动应用开发介绍以及学习路线的白话文…...
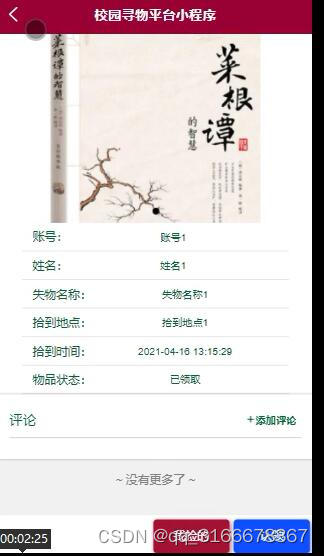
vue+uniapp校园寻物失物招领平台 微信小程序1f6z5
系统中的核心用户是管理员,管理员登录后,通过管理员菜单来管理后台系统。主要功能有:首页、个人中心、用户管理、物品分类管理、物品信息管理、物品归还管理、留言板管理、系统管理等功能。管理员用例如图3-7所示。 对于本网上失物招领小程序…...
物理内存分页机制--kmalloc及slub机制)
Linux内核--内存管理(三)物理内存分页机制--kmalloc及slub机制
一、引言 二、slub机制 ------>2.1、slub分配原理slub原理 ------>2.2、slub分配原理 ------>2.3、slub释放原理 ------>2.4、SLUB分配器 三、slub数据结构 ------>3.1、kmem_cache ------>3.2、kmem_cache_cpu ------>3.3、kmem_cache_node --…...
Shell - cron_protect.sh 监控 Python、Streaming 程序
目录 一.引言 二.Flink 程序监控 1.shell 脚本 2.crontab 配置 三.Python 程序监控 1.shell 脚本 2.crontab 配置 四.总结 一.引言 业务有流式处理数据的需求,需要 7x24 通过 Flink Python 程序进行处理。为了监控 Flink 与 Python 的程序运行状态并在程…...
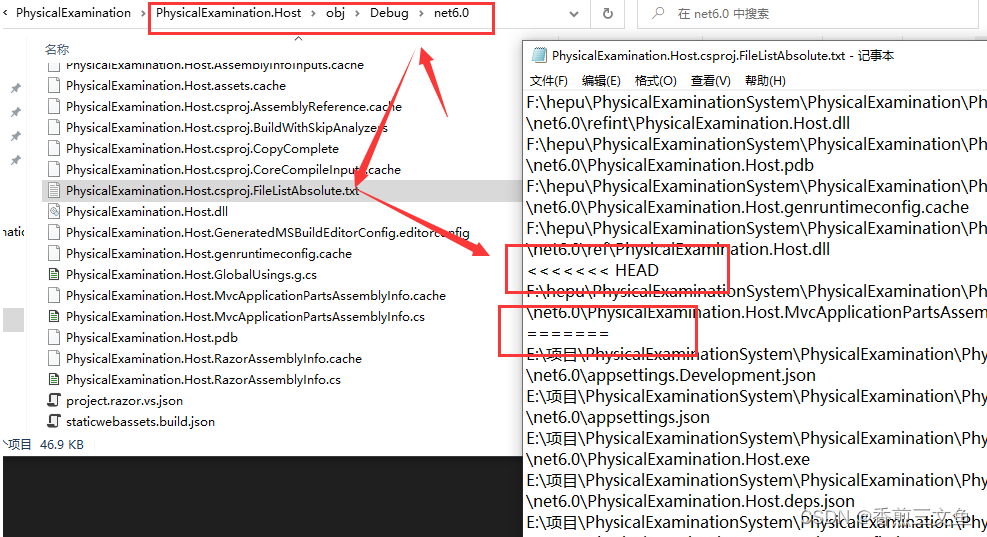
MSB3541 Files 的值“<<<<<<< HEAD”无效。路径中具有非法字符。
MSB3541 Files 的值“<<<<<<< HEAD”无效。路径中具有非法字符。 一般来说出现这个问题是因为使用git版本控制工具合并代码出现了问题,想要解决也很简单。 如图点击错误后定位到文件,发现也没有什么问题。 根据错误后边的提示&a…...

【赠书第9期】巧用ChatGPT高效搞定Excel数据分析
文章目录 前言 1 操作步骤 1.1 数据清理和整理 1.2 公式和函数的优化 1.3 图表和可视化 1.4 数据透视表的使用 1.5 条件格式化和筛选 1.6 数据分析技巧 1.7 自动化和宏的创建 2 推荐图书 3 粉丝福利 前言 ChatGPT 是一个强大的工具,可以为你提供在 Exce…...
会声会影2024旗舰版系统配置要求及格式支持
会声会影2024旗舰版是一款广受欢迎的视频编辑软件,它的最新版本,会声会影2023,已经发布。在这篇文章中,我们将探讨会声会影2024旗舰版系统配置要求及格式支持 会声会影2024是一款专业的视频剪辑软件,能够帮助用户制作高…...

【部署运维】docker:入门到进阶
0 前言 部署运维博客系列一共有三篇: 拥抱开源,将工作中的经验分享出来,尽量避免新手踩坑。 【部署运维】docker:入门到进阶 【部署运维】kubernetes:容器集群管理掌握这些就够了 【部署运维】pythonredisceleryd…...
鸿蒙开发学习——应用程序框架
文章目录 UIAbility的生命周期Create状态WindowStageCreateForeground和Background前后台展示控制onWindowStageDestroyDestory 总结 UIAbility的生命周期 感觉这里他讲的不清晰,UIAbility的4个声明周期是Create、Foreground(桌面展示)、Back…...
)
Linux dd命令详解:如何从标准输入或文件中读取、转换并输出数据(附实例教程和注意事项)
Linux dd命令介绍 Linux dd命令用于读取、转换并输出数据。dd可以从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。这个命令在备份硬盘、创建启动盘、数据恢复等场景中非常有用。 Linux dd命令适用的Linux版本 d…...
Python——常见内置模块
Python 模块(Modules)1、概念模块函数类变量2、分类3、模块导入的方法:五种4、使用import 导入模块5、使用from……import部分导入6、使用as关键字为导入模块或功能命名别名7、模块的搜索目录8、自定义模块 常见内置模块一、math模块二、rand…...

JAVA毕业设计112—基于Java+Springboot+Vue的宠物领养社区小程序(源码+数据库)
基于JavaSpringbootVue的宠物领养社区小程序(源码数据库)112 一、系统介绍 本系统前后端分离带小程序 小程序(用户端),后台管理系统(管理员) 小程序: 登录、注册、宠物领养、发布寻宠、发布领养、宠物社…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程
SpeakingURL版本升级指南:从旧版本迁移到最新版本的完整教程 【免费下载链接】speakingurl Generate a slug – transliteration with a lot of options 项目地址: https://gitcode.com/gh_mirrors/sp/speakingurl SpeakingURL是一款强大的URL友好化工具&…...