数组模拟常见数据结构
我们来学习一下用数组模拟常见的数据结构:单链表,双链表,栈,队列。
用数组模拟这些常见的数据结构,需要我们对这些数据结构有一定的了解哈。
单链表请参考:http://t.csdn.cn/SUv8F
用数组模拟实现比STL要快,在做算法题一般习惯使用数组模拟数据结构。这种数组模拟是非常多的奥,比如:邻接表,哈希表的拉链存储,Trie树,堆等。
数组模拟单链表
会用到的变量或者数组:
head:表示头结点的下标。
e[i]:表示节点i的值、。
ne[i]:表示节点i的next指针是多少,数组模拟链表的话ne[i]的值就是下标啦。
idx:表示当前使用到了数组(e数组和ne数组的使用是同步的)的哪个位置(下标)。
可以把以上变量和数组定义成全局变量。
#define ARRAY_SIZE 1010
int head; //头结点的下标
int e[ARRAY_SIZE]; //存储数据的数组,表示节点的值
int ne[ARRAY_SIZE]; //存储下一个节点的数组
int idx; //当前可以使用的数组下标1.1 单链表的初始化
一开始的时候链表中是没有数据的,我们让头结点的下标为-1即可(类比指针实现单链表的空指针),idx初始化为0,代表从数组下标为0往后的位置的可以使用。
//链表的初始化
void init()
{//初始时链表中没有节点head = -1;//可用的下标为0idx = 0;
}1.2 链表的头插
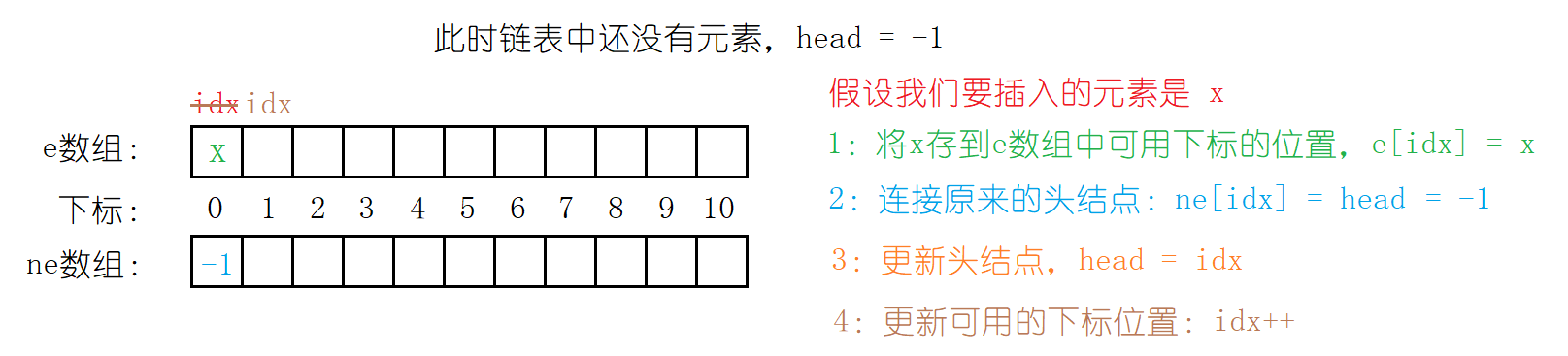
在初始化完一个空链表之后。我们尝试来写头插函数:根用指针实现的单链表类似,数组模拟的单链表实现头插需要一下四步:
1:将要插入的值存储到e数组
2:连接原来的头结点
3:更新新的头结点
4:更新可用的下标值
下面是链表中没有数据的情况:
下面是链表中有数据的情况:
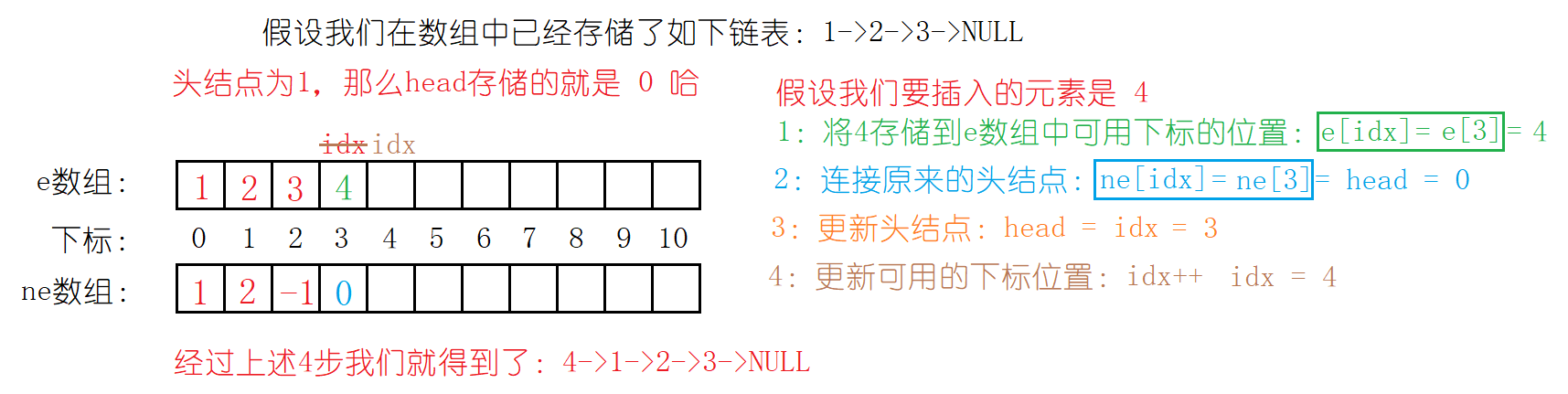
通过上面两种情况的分析我们发现无论链表中是否有数据,都可以用这四步来做。那么我们就可以写出头插的代码啦!还有就是通过对指针实现的单链表的理解:尾插的效率是很慢的,所以数组模拟时不再写尾插函数。
//单链表的头插
//假设数组中存储的都是整型数据哈,如果要存其他的数据类型,可以typedef一下
void ListPushFront(int x)
{//存值e[idx] = x;//连接ne[idx] = head;//更新head = idx;idx++;
}1.3 在下标为k的节点的后面插入值为x的节点
同样通过对指针实现的单链表理解:在一个节点的前面插入节点的时间复杂度很高,我们选择在一个节点之后插入新的节点。数组模拟链表时,就是在下标为k的后面插入新的节点啦!
同样也需要四步操作哈:
1:将要插入的值存储到e数组
2:将新的节点连接到k节点的下一个节点
3:将k这个节点连接到新的节点
4:更新可用的下标值(idx)
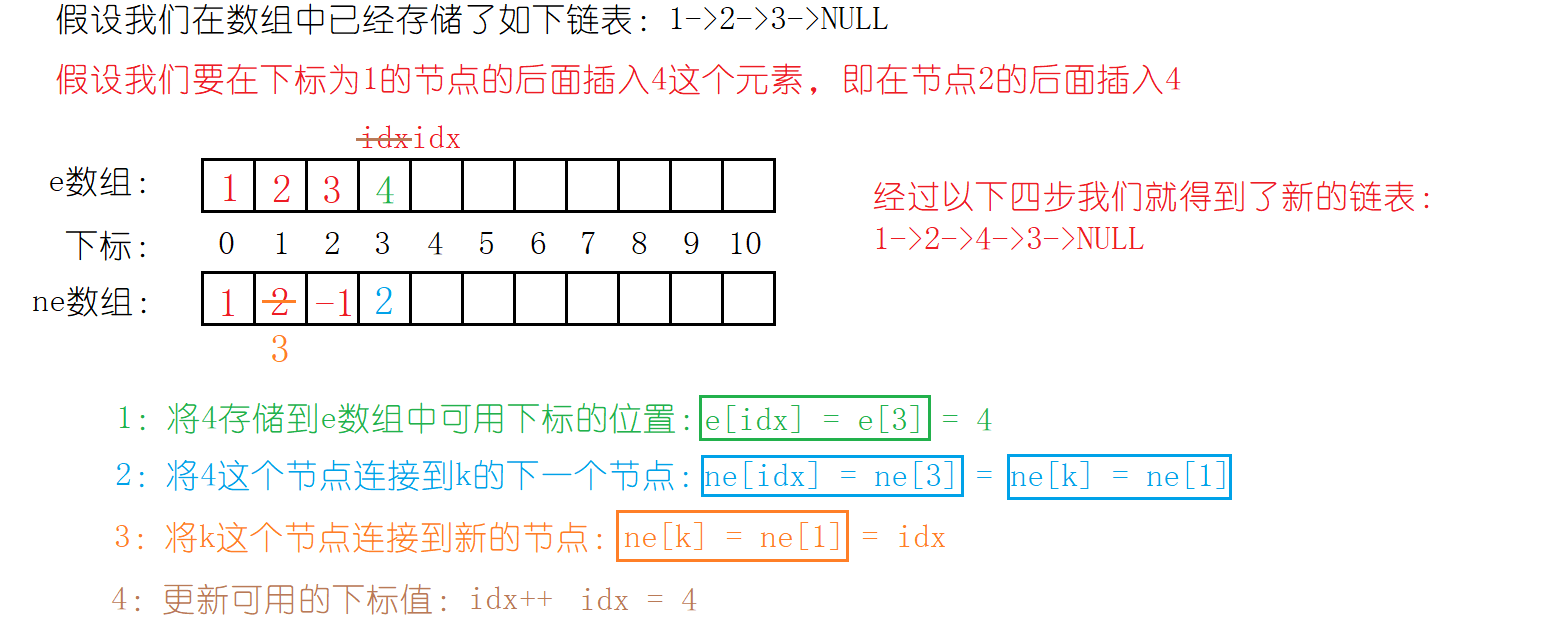
同样地,对于尾插这样的四步操作也是没有啥问题的,行,我们就可以写出在在下标为k的节点的后面插入值为x的节点的代码啦!
//指定下标k后面插入x
//调用这个函数你得确保k是合法的才行撒,即k下标是链表中的一个节点
void ListInsertAfter(int k, int x)
{//将要插入的值存储到e数组e[idx] = x;//将新的节点连接到k节点的下一个节点ne[idx] = ne[k];//将k这个节点连接到新的节点ne[k] = idx;//更新可用的下标值(idx)idx++;
}1.4 将下标为k的节点的后面那个节点删除
同样地,我们不删除前面的节点,时间复杂度太高了哦!在理解了指针版的删除指定位置之后的节点,数组模拟的链表删除指定下标的节点的后面那个节点也是信手拈来好吧!
步骤只有一步哦:
直接让下标为k的节点指向:下标为k的节点的下一个节点的下一个节点就好啦!
是不是很简单 😊
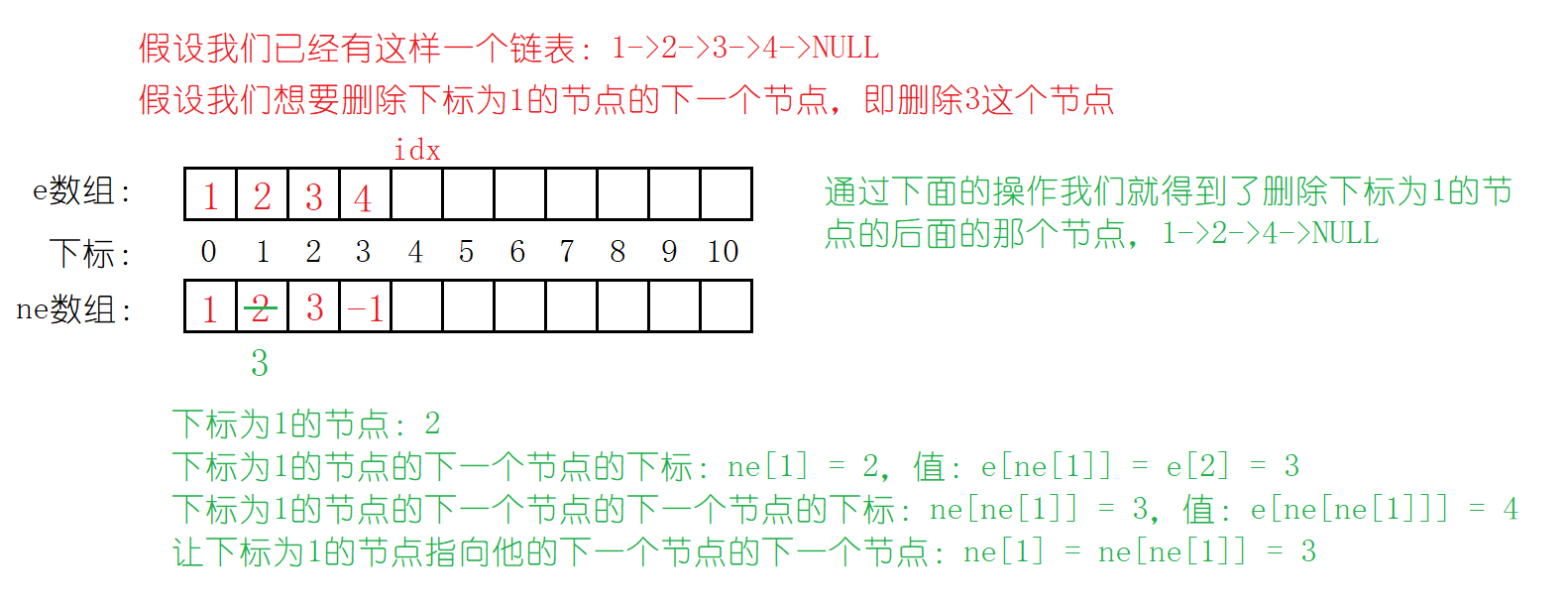
我们发现这个删除只是在逻辑上删除了哈,内存上并没有像指针实现的链表那样删除。也就是说数组模拟的链表被删除的节点理论上还是可以使用的,但实际上并不会再去使用那块空间了,而是使用下标为idx的空间。
//删除指定下标k的后面那个节点
//放到具体的题目中去,k会是合法的哦,直接看代码是有问题的
void ListEraseAfter(int k)
{//连接ne[k] = ne[ne[k]];
}1.5 链表的打印
和指针实现的单链表类似,只不过结束打印的条件是:i = -1,我们用的是-1代表空节点嘛!
为了好看,打印的函数还是和指针模拟单链表时的打印函数差不多!
//打印链表
void ListPrint()
{//用i遍历链表for (int i = head; i != -1; i = ne[i]){printf("%d->", e[i]);}printf("NULL");
}数组模拟双链表
会用到的变量或者数组:
e[i]:表示节点i的值、。
l[i]:表示节点i的prev指针是多少,数组模拟链表的话l[i]的值就是下标啦。
r[i]:表示节点i的next指针是多少,数组模拟链表的话r[i]的值就是下标啦
idx:表示当前使用到了数组(e数组和l数组和r数组的使用是同步的)的哪个位置(下标)。
同样你可以把以上变量和数组定义为全局变量:
//数组的大小
#define ARRAY_SIZE 1010
//存节点的值
int e[ARRAY_SIZE];
//存节点的上一个节点
int l[ARRAY_SIZE];
//存节点的下一个节点
int r[ARRAY_SIZE];
//可用的数组下标
int idx;2.1 链表的初始化
初始化双链表时,我们让双链表有一个小小的结构,有了这个结构能方便我们的插入和删除,可以类比带头双向循环链表中的初始化函数让哨兵位的头结点的next和prev均指向自己,这样做就不用考虑什么头插,尾插,头删,尾删的情况了,即通过哨兵位的头结点能够让插入,删除函数具有普适性。数组模拟双向链表中的初始的小结构,也就是这个目的。

这两个节点并不存储数据的喔,只是方便后续的操作。我们令下标为0的位置代表左侧的那个节点,可以理解为head,下标为1的位置代表右侧的那个节点,可以理解为tail。那么初始化时,idx就得从2这个下标开始咯,并且r[0] = 1,代表head指向tail;l[1] = 0,代表tail指向head。
//链表的初始化,初始化链表的结构
void ListInit()
{//head向右指向tailr[0] = 1;//tail向左指向headl[1] = 0;//因为0代表head,1代表tail所以idx从2开始idx = 2;
}2.2 在下标为k的节点的后面插入一个新的节点
嘿嘿,双链表的在下标为k的位置左右插入一个新节点可以只写一种插入方式即可哦!
我们先来看看在下标为k的节点的后面插入一个新的节点:
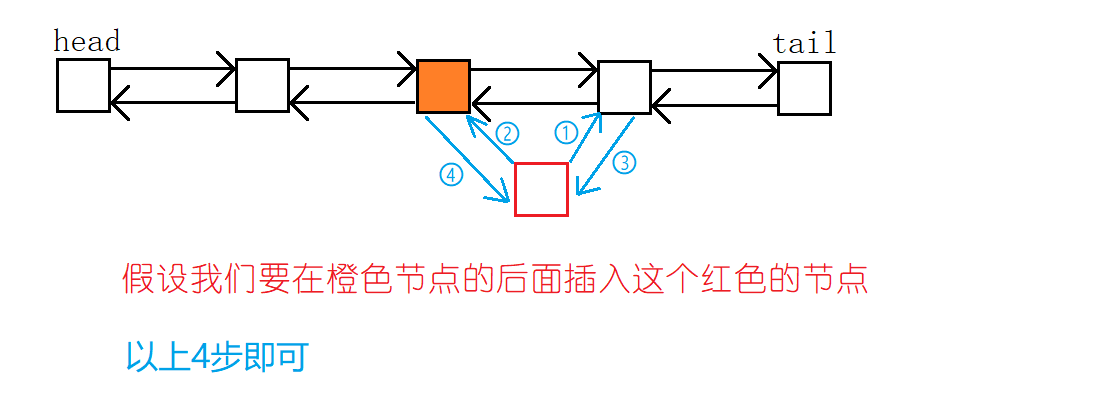
只需要以上4步哦,代码的图解就没啥必要了,原理和单链表的插入一个逻辑。
//在下标为k的节点的后面插入一个值为x的节点
void ListInsertAfter(int k, int x)
{//存储xe[idx] = x;//对应步骤1r[idx] = r[k];//对应步骤2l[idx] = k;//对应步骤3l[r[k]] = idx;//对应步骤4r[k] = idx;//更新可用的下标值idx++;
}emm,那么我们如果想要在下标为k的节点的前面的插入一个节点呢?当然我们可以用上面向后插的逻辑,重新写一个向前插入的函数。但是没有必要哦!
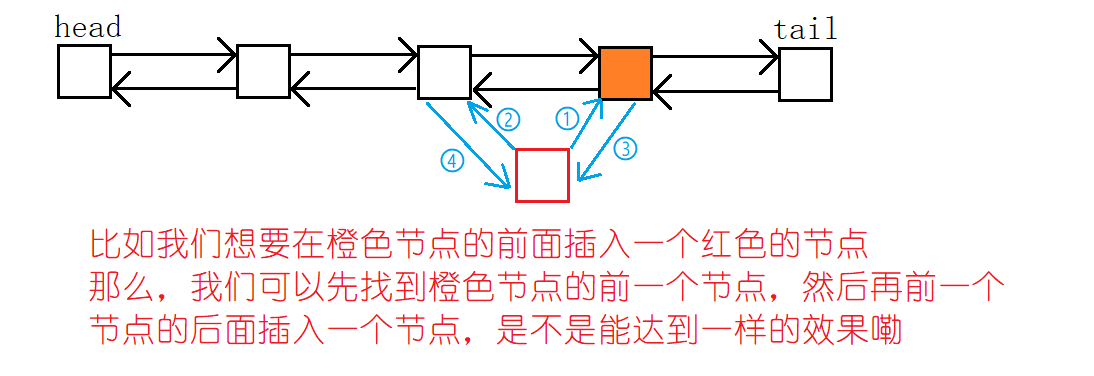
2.3 删除下标为k的节点
这个操作只需要两步哈:
1:下标为k的节点的前一个节点向右指向下标为k的节点的下一个节点。
2:下标为k的节点的下一个节点向左指向下标为k的节点的上一个节点。
方法:
1:l[k]:找到下标为k的节点的上一个节点;r[k]:找到下标为k的节点的下一个节点;r[l[k]] = r[k]:将找到的上一个节点向右连接到找到的下一个节点。
2:r[k]:找到下标为k的节点的下一个节点;l[k]:找到下标为k的节点的上一个节点;l[r[k]] = l[k]:将找到的下一个节点向左连接到找到的上一个节点。

//删除下标为k的节点
void ListErase(int k)
{//步骤1r[l[k]] = r[k];//步骤2l[r[k]] = l[k];
}3. 数组模拟栈
数组模拟栈和队列就非常滴简单了啊!应用请参考单调栈:
http://t.csdn.cn/uBst3
我们会用到的变量和数组:
1:stack[N]:用来模拟栈的数组。
2:top:用来表示栈顶的下标。
你同样可以把他们定义成全局变量:
//模拟栈的数组的大小
#define N 1010
//模拟栈的数组
int stack[N];
//用来表示栈顶元素的下标
int top;3.1 栈的初始化
我们习惯模拟栈的数组是从下标为1的位置开始存储数据的,因为这样很好判断栈是否为空。既然你将top定义成了全局变量,自然就不用初始化了哦!
3.2 添加元素
添加元素是非常的简单啊:先让top++,然后赋值就行了。
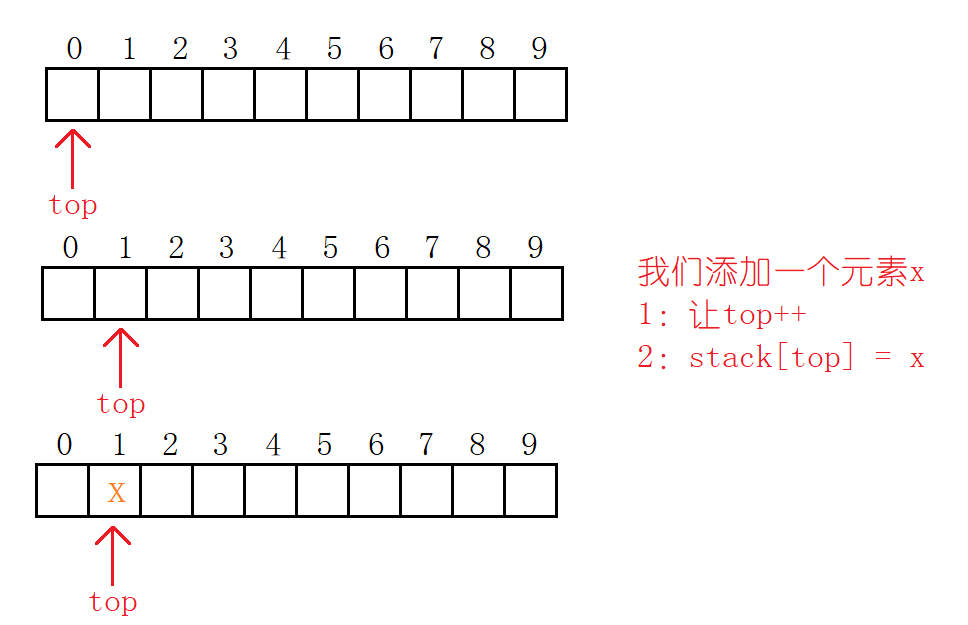
//添加元素
void StackPush(int x)
{stack[++top] = x;
}3.3 删除元素
top--就行。
//弹出栈顶元素
void StackPop()
{//top为0栈为空,不用删if(top)top--;
}3.4 判断栈是否为空
根据top的值判断即可。
//判断栈是否为空,为空返回true
bool StackEmpty()
{return top > 0;
}3.5 查看栈顶元素
stack[top] 就行了哈。
4. 数组模拟队列
我们会用到的变量和数组:
1:q[N]:用来模拟队列的数组。
2:hh:用来表示队列队头。
3:tt:用来表示队列的队尾。
我们习惯是hh初始化为0,tt初始化为-1,从下标为0的位置开始存储数据。
下面的是伪代码哈!能传达意思就行。具体的应用请参考单调队列!
//模拟栈的数组
int stack[N];
//用来表示栈顶元素的下标
int top;//模拟队列的数组大小
#define N 1010
//模拟队列的数组
int q[N];
//表示队头
int hh;
//表示队尾
int tt = -1;//插入元素-队尾入元素
q[++tt] = x;//弹出元素,队头出数据
hh++;//判断队列是否为空
if (hh <= tt)not empty;
elseempty;相关文章:
数组模拟常见数据结构
我们来学习一下用数组模拟常见的数据结构:单链表,双链表,栈,队列。用数组模拟这些常见的数据结构,需要我们对这些数据结构有一定的了解哈。单链表请参考:http://t.csdn.cn/SUv8F 用数组模拟实现比STL要快&a…...
ADC0832的AD模数转换原理及编程
✅作者简介:嵌入式领域优质创作者,博客专家 ✨个人主页:咸鱼弟 🔥系列专栏:单片机设计专栏 📃推荐一款求职面试、刷题神器👉注册免费刷题 目录 一、描述 二、模数转换原理: 三、…...
【工具插件类教学】UnityPackageManager私人定制资源工具包
目录 一.UnityPackageManager的介绍 二.package包命名 三.包的布局 四.生成清单文件 五.制作package内功能 六.为您的软件包撰写文档 1.信息的结构 2.文档格式 七.提交上传云端仓库 1.生成程序集文件 2.上传至云端仓库 八.下载使用package包 1.获取包的云端路径 …...
【软件测试】2023年了还不会接口测试?老鸟总结接口测试面试谁还敢说我不会......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 测试面试࿰…...

类Vuex轻量级状态管理实现
引用自 摸鱼wiki 1. vuex vuex是一个前端广泛流行的状态管理库,主要由以下几大模块组成: state:状态存储getter:属性访问器mutation:可以理解为一个同步的原子性事务,修改state状态action:触发…...

Java 基本数据类型
Java基本数据类型是Java编程语言中最基本的数据类型,包括整型、浮点型、字符型、布尔型和空类型。本文将详细介绍Java基本数据类型的作用和在实际工作中的用途。 整型(int、long、short、byte) 整型是Java中最常见的基本数据类型࿰…...

全网资料最全Java数据结构与算法-----算法分析
算法分析 研究算法的最终目的就是如何花更少的时间,如何占用更少的内存去完成相同的需求,并且也通过案例演示了不同算法之间时间耗费和空间耗费上的差异,但我们并不能将时间占用和空间占用量化,因此,接下来我们要学习…...

【封装xib补充 Objective-C语言】
一、那么首先,咱们就从这个结果来分析 1.就不给大家一步一步分析了,直接分析我们这里怎么想的, 首先,我们看到这样的一个界面,我们想,这些应用数据是不是来源于一个plist文件吧, 所以说,我们首先要,第一步,要懒加载,把这个plist文件中的数据,加载起来, 那么,因…...
linux + jenkins + svn + maven + node 搭建及部署springboot多模块前后端服务
linux搭建jenkins 基础准备 linux配置jdk、maven,配置系统配置文件 vi /etc/profile配置jdk、maven export JAVA_HOME/usr/java/jdk1.8.0_261-amd64 export CLASSPATH.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport MAVEN_H…...
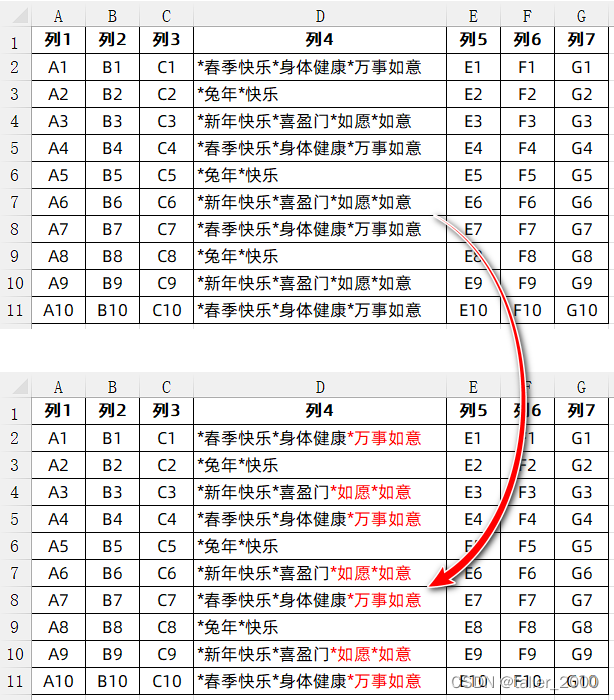
VBA之正则表达式(41)-- 快速标记两个星号之后的字符
实例需求:工作表中的数据保存在A列~G列,现需要识别D列中包含超过两个星号的内容,并将第3个星号及其之后的字符设置为红色字体,如图所示。 示例代码如下。 Sub Demo1()Dim objRegExp As ObjectDim objMatch As ObjectDim strMatch…...

VMware16安装MacOS【详细教程】
安装VMware workstation 双击安装包,然后一直下一步就行了。 进行VMware安装,一直 下一步 在输入产品密钥这一步,如果有查找到可用密钥就填进去,没有就跳过,进入软件后也能输入密钥的。 输入密钥。 最后一步ÿ…...
Netty学习(一):Netty概述
一、原生NIO存在的问题 NIO 的类库和API繁杂,使用麻烦:需要熟练掌握Selector、ServerSocketChannel、SocketChannel、ByteBuffer等。需要具备其他的额外技能:要熟悉Java 多线程编程,因为NIO编程涉及到Reactor 模式,你必须对多线程和网络编程…...
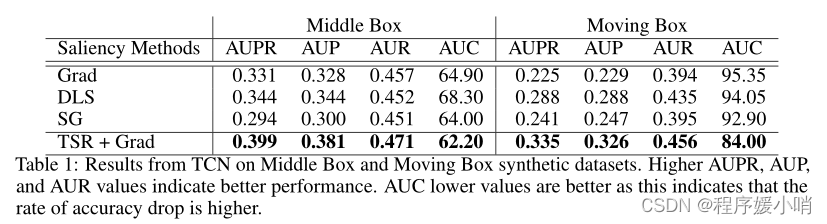
【论文精读】Benchmarking Deep Learning Interpretability in Time Series Predictions
【论文精读】Benchmarking Deep Learning Interpretability in Time Series Predictions Abstract Saliency methods are used extensively to highlight the importance of input features in model predictions. These methods are mostly used in vision and language task…...
自己第一次在虚拟机完整部署ssm项目心得体会
过程使用资源和博文 琳哥发的linux课件文档,阳哥发的linux课件文档(私聊我要) https://www.likecs.com/show-205274015.html https://www.cnblogs.com/aluoluo/articles/15845183.html https://blog.csdn.net/osfipin/article/details/54405445 https://blog.csdn.net/drea…...

操作系统权限提升(二十二)之Linux提权-SUDO滥用提权
系列文章 操作系统权限提升(十八)之Linux提权-内核提权 操作系统权限提升(十九)之Linux提权-SUID提权 操作系统权限提升(二十)之Linux提权-计划任务提权 操作系统权限提升(二十一)之Linux提权-环境变量劫持提权 SUDO滥用提权 SUDO滥用提权原理 sudo是linux系统管理指令&…...

操作系统权限提升(二十四)之Linux提权-明文ROOT密码提权
系列文章 操作系统权限提升(十八)之Linux提权-内核提权 操作系统权限提升(十九)之Linux提权-SUID提权 操作系统权限提升(二十)之Linux提权-计划任务提权 操作系统权限提升(二十一)之Linux提权-环境变量劫持提权 操作系统权限提升(二十二)之Linux提权-SUDO滥用提权 操作系统权限…...

Linux基本命令复习-面试急救版本
1、file 通过探测文件内容判断文件类型,使用权是所有用户, file[options]文件名2、mkdir/rmdir 创建文件目录(文件夹)/删除文件目录 3、grep 指定文件中搜索的特定内容 4、find 通过文件名搜索文件 find name 文件名 5、ps 查…...

随想录二刷Day09——字符串
文章目录字符串1. 反转字符串2. 反转字符串 II3. 替换空格4. 反转字符串中的单词5. 左旋转字符串字符串 1. 反转字符串 344. 反转字符串 思路: 设置两个指针,分别指向字符串首尾,两指针向中间移动,内容交换。 class Solution { …...

正点原子IMX6ULL开发板-liunx内核移植例程-uboot卡在Starting kernel...问题
环境 虚拟机与Linux版本: VMware 17.0.0 Ubuntu16 NXP提供的U-boot与Linux版本: u-boot:uboot-imx-rel_imx_4.1.15_2.1.0_ga.tar.bz2 linux:linux-imx-rel_imx_4.1.15_2.1.0_ga.tar.bz2 开发板: 正点原子-IMX6ULL_EMMC版本,底板版…...
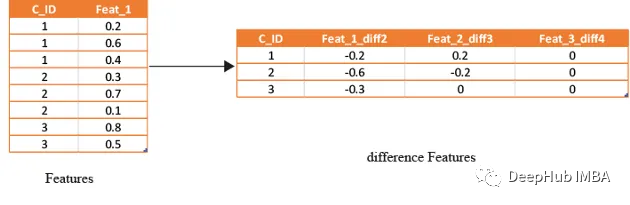
使用手工特征提升模型性能
本文将使用信用违约数据集介绍手工特征的概念和创建过程。 通过对原始数据进行手工的特征工程,我们可以将模型的准确性和性能提升到新的水平,为更精确的预测和更明智的业务决策铺平道路, 可以以前所未有的方式优化模型并提升业务能力。 原始…...

AI任务自动化五阶段工作流:从需求到代码的可靠实践
1. 项目概述:从混乱到有序的AI任务自动化五阶段工作流上次我们聊了这套自动化系统的技术架构,把JIRA、GitHub和Cursor智能体串了起来。今天咱们不聊“怎么连”,聊聊“怎么跑”——也就是那个能把一个粗糙的需求工单,最终变成一行行…...

开关电源传导共模噪声抑制:Y电容原理、安规限制与EMI滤波器设计
1. 项目概述:理解隔离式开关电源中的传导共模噪声在开发离线式开关电源,比如我们常见的手机充电器、笔记本电脑适配器或者工业电源模块时,工程师们常常会遇到一个既棘手又必须解决的难题:传导电磁干扰(Conducted EMI&a…...

RedwoodJS执行器:命令执行与进程管理的终极指南
RedwoodJS执行器:命令执行与进程管理的终极指南 【免费下载链接】redwood RedwoodGraphQL 项目地址: https://gitcode.com/gh_mirrors/re/redwood RedwoodJS是一个功能强大的全栈JavaScript框架,它提供了一套完整的工具链来简化现代web应用的开发…...

浏览器高阶使用指南:从基础操作到效率系统构建
1. 项目概述:浏览器,远不止是“上网”那么简单“abczsl520/browser-use-skill”这个项目名,乍一看可能会觉得有点“标题党”——浏览器使用技巧?这谁不会啊?点开、输入网址、回车,不就完了吗?如…...

功能开关与远程配置:现代Web应用安全发布与动态控制实践
1. 项目概述:从“快乐工具包”到现代应用配置管理 如果你是一名前端或全栈开发者,最近在关注状态管理或应用配置,可能已经听说过 happykit/flags 这个名字。乍一看,它像是一个关于“旗帜”或“开关”的库,但它的核心…...

GoFrame+Vue3后台管理框架的WebSocket即时通讯实战:架构设计与消息推送
在 GoFrame Vue3 后台管理框架的开发中,即时通讯(IM)是一个高频需求——从站内信到客服系统,从通知推送到协作消息,都离不开 WebSocket 长连接。 XYGo Admin 基于 gorilla/websocket 实现了一套完整的即时通讯体系&a…...

系统提示、开发提示、用户提示:在 Agent 里怎么分层
系统提示、开发提示、用户提示在 Agent 里的分层架构:从理论到工业级落地全解析 副标题:基于认知科学、软件工程双视角,构建可复用、可调试、高智能的三层提示架构体系 第一部分:引言与基础 (Introduction & Foundation) 1.1 引人注目的标题(重复+锚定SEO) 系统提…...
DenseNet参数量比ResNet少?从Bottleneck和Transition层设计,聊聊模型轻量化的核心思路
DenseNet与ResNet参数效率对比:从结构设计看模型轻量化本质 在深度学习模型设计中,参数量与计算效率一直是工程师们关注的核心指标。当DenseNet首次提出时,许多研究者对其参数效率感到惊讶——看似复杂的密集连接结构,实际参数量却…...

如何用开源工具永久保存你的微信聊天记忆?完整指南揭秘数据备份终极方案
如何用开源工具永久保存你的微信聊天记忆?完整指南揭秘数据备份终极方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_…...

VSCode + Cline + Codeium + OpenSpec + DeepSeek 完整配置指南
VSCode Cline Codeium OpenSpec DeepSeek 完整配置指南 📋 最终方案概述 组件用途费用VSCode代码编辑器免费Codeium (Windsurf)Tab 补全 生成注释免费ClineAI Agent(复杂任务、多文件操作)免费OpenSpec规范驱动开发(复杂功…...