Rust开发——数据对象的内存布局
枚举与Sized 数据
一般数据类型的布局是其大小(size)、对齐方式(align)及其字段的相对偏移量。
1. 枚举(Enum)的布局:
枚举类型在内存中的布局通常是由编译器来确定的。不同的编译器可能有不同的实现方式。一般来说,枚举的大小通常与其底层表示的整数类型相同,例如 enum 定义为 int 类型的大小。对于不同的枚举成员,编译器会分配不同的整数值。但是具体如何进行编码和布局是由编译器实现规定的。
在某些情况下,编译器可能会优化枚举类型的大小,特别是当枚举类型的取值在一个较小的范围内时,编译器可能会选择使用较小的整数类型来表示。
2. Sized 数据类型:
在 Rust 编程语言中,Sized 是一个特性(trait),用于表示大小在编译时是已知的类型。所有 Rust 中的类型默认都是 Sized 的,除非使用特殊的语法标记为 ?Sized,表示可能是动态大小的类型。
Rust 中的 size_of 和 align_of 函数可以用于获取类型的大小和对齐方式:
std::mem::size_of::<T>()返回类型T的大小(以字节为单位)。std::mem::align_of::<T>()返回类型T的对齐方式(以字节为单位)。
这些函数返回的结果是在编译时已知的常量值。
需要注意的是,对于不同的平台和编译器,类型的大小和对齐方式可能会有所不同。例如,在32位和64位系统上,同一类型的大小可能不同。
数字类型
在 Rust 中,数字类型的内存布局是按照它们的大小和规范来定义的。这些类型的内存布局通常受到硬件架构和编译器实现的影响。
在 Rust 中,常见的数字类型包括整数类型和浮点数类型。下面是一些常见的数字类型和它们的内存布局特征:
整数类型(Integer Types):
-
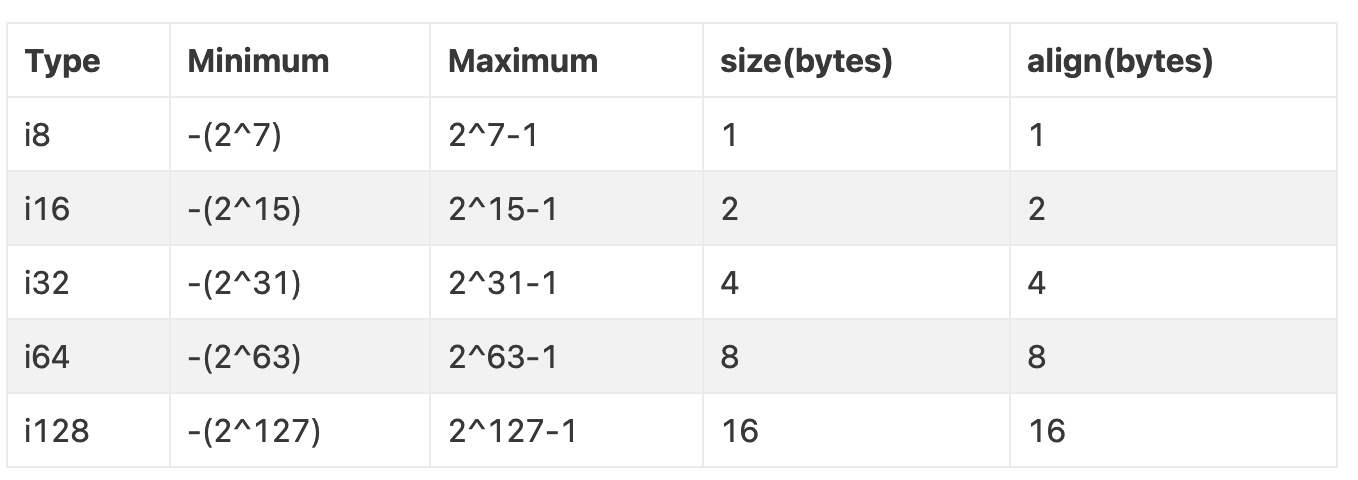
有符号整数:
i8、i16、i32、i64、i128:根据其名称指示的位数存储有符号整数,例如,i32是一个32位的有符号整数,i64是一个64位的有符号整数。- 内存布局:按照补码表示存储。即最高位为符号位,其余位表示数值。
-
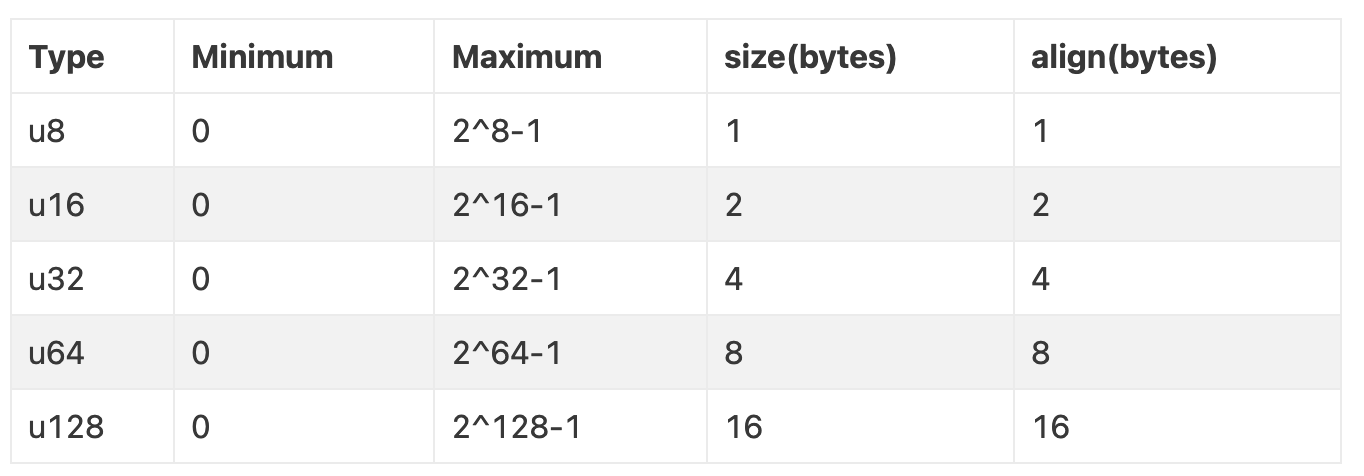
无符号整数:
u8、u16、u32、u64、u128:根据其名称指示的位数存储无符号整数,例如,u32是一个32位的无符号整数,u64是一个64位的无符号整数。- 内存布局:使用全部位来表示数值。
浮点数类型(Floating-Point Types):
-
单精度浮点数:
f32:32位的单精度浮点数。- 内存布局:采用IEEE 754标准,其中1位表示符号位,8位表示指数部分,23位表示尾数部分。
-
双精度浮点数:
f64:64位的双精度浮点数。- 内存布局:同样采用IEEE 754标准,其中1位表示符号位,11位表示指数部分,52位表示尾数部分。
 这些数字类型在内存中以固定大小进行存储,其具体的字节顺序和布局可能因编译器和硬件平台而异。一般来说,这些数字类型在内存中是连续存储的,并且其大小和布局遵循相应的标准,比如整数的补码表示和浮点数的IEEE 754标准。
这些数字类型在内存中以固定大小进行存储,其具体的字节顺序和布局可能因编译器和硬件平台而异。一般来说,这些数字类型在内存中是连续存储的,并且其大小和布局遵循相应的标准,比如整数的补码表示和浮点数的IEEE 754标准。
usized 、isized
在 Rust 中,usize 和 isize 是特殊的整数类型,其大小取决于运行 Rust 代码的操作系统的位数。这两种类型的大小会根据不同系统的位数而变化。
-
usize:代表无符号整数,它的大小等于指针大小,即在 64 位系统上通常是 8 字节,在 32 位系统上通常是 4 字节。它用于表示内存中的索引、大小和指针偏移等。在 Rust 中,usize类型通常用于索引集合或表示内存中对象的大小。 -
isize:代表有符号整数,同样,它的大小也等于指针大小。在 64 位系统上通常是 8 字节,在 32 位系统上通常是 4 字节。它可以用来表示可以为负数的索引或偏移量。
这两种类型在不同位数的系统上都是与机器字长相关的,这样可以更好地适应不同平台上的内存寻址和指针大小。它们的大小是 Rust 编译器根据目标平台自动确定的,并且在不同平台上可能会有所不同。
bool
bool 类型在 Rust 中用于表示布尔值,只能取 true 或 false。它在内存中的长度和对齐长度都是 1 字节,在存储时占用一个字节的内存空间。
数组
在 Rust 中,数组是固定大小的相同类型元素的集合。Rust 中的数组具有连续的内存布局,并且元素是按照其定义顺序依次存储的。
内存布局:
-
连续存储:数组中的元素按照顺序在内存中连续存放。这意味着如果有一个包含多个元素的数组,它们会依次存储在内存中相邻的位置。
-
相同类型元素:数组中的所有元素必须是相同的类型。例如,一个
i32类型的数组必须只包含i32类型的元素。 -
索引访问:通过索引可以访问数组的元素。Rust 中的数组索引从 0 开始,可以使用
[]操作符来访问数组中特定索引的元素。
示例:
// 创建一个包含 4 个整数的数组
let my_array: [i32; 4] = [10, 20, 30, 40];
假设有一个名为 my_array 的数组,包含四个 i32 类型的整数。在内存中,这个数组的存储方式可能如下所示(这里只是示意,不考虑实际内存地址):
my_array: [10, 20, 30, 40]
Memory: | 10 | 20 | 30 | 40 |
这表示这个数组中的四个整数元素在内存中是连续存储的,每个整数占据相应的内存空间。数组的第一个元素 10 存储在第一个内存位置,第二个元素 20 存储在紧随其后的内存位置,以此类推。
通过索引可以访问数组中的元素,例如 my_array[0] 会返回第一个元素 10,my_array[1] 返回第二个元素 20,以此类推。
str类型
1. char 类型:
char表示一个 Unicode 字符,占据 32 位长度(4 字节)。- Unicode 标量值(Unicode Scalar Value)范围在
0x0000 - 0xD7FF或0xE000 - 0x10FFFF。
2. str 类型:
str是一个不可变的 UTF-8 编码字符串片段(slice)。它是对 UTF-8 编码字节序列的引用。- Rust 的标准库假设
str是有效的 UTF-8 编码,并且对其进行操作时会遵循这个假设。 str的内存布局类似于&[u8],但是假设其内容是有效的 UTF-8 编码。
3. slice:
slice是 Rust 中的动态大小类型(DST),表示一部分数据的视图。&[T]是一个“宽指针”,它存储了指向数据的地址和数据的长度。slice的内存布局与其指向的数据类型相同。
4. String 类型:
String是 Rust 中的可变字符串类型,它拥有所有权,并且存储 UTF-8 编码的文本。String本质上是一个指向存储字符串数据的缓冲区的指针,它也是一个Vec<u8>的封装。String的内存布局包含了指向存储字符串数据的地址以及字符串的长度和容量信息。
在 Rust 中,struct是用于定义自定义数据类型的关键字,它允许组合多个不同类型的字段来创建一个新的复合类型。当涉及到struct的内存布局时,需要考虑其字段的排列和对齐方式。
struct
在 Rust 中,struct 的内存布局通常是紧凑且连续的,它的字段按照声明的顺序依次存储在内存中。然而,Rust 也会根据字段的类型和对齐需求进行内存对齐,以提高访问效率。
例如,考虑以下简单的结构体定义:
struct MyStruct {a: u8,b: u16,c: u32,
}
这个结构体 MyStruct 包含了一个 u8 类型的字段 a、一个 u16 类型的字段 b 和一个 u32 类型的字段 c。Rust 会根据这些字段的类型和对齐要求进行内存布局。
通常情况下,Rust 会按照字段的声明顺序进行内存排列,但也可能根据字段的大小和对齐要求进行调整,以保证每个字段能够按照其对齐规则正确地存储在内存中。
对齐规则是为了提高访问效率和减少内存访问的成本。例如,u16 类型通常需要在内存中对齐到 2 字节边界,u32 类型通常对齐到 4 字节边界,以此类推。因此,结构体的内存布局可能会在字段之间增加填充以满足对齐要求。
需要注意的是,Rust 并没有明确的规范指定结构体的内存布局,这是由编译器根据平台和优化策略进行管理的。因此,在特定情况下,结构体的内存布局可能会因编译器、目标架构或优化设置而有所不同。
tuple
元组(Tuple)是一种可以包含多个不同类型值的复合数据类型。元组的内存布局类似于结构体(struct),但有一些区别。
元组的内存布局:
- 连续存储:元组中的元素按照其定义顺序在内存中连续存储。
- 按照顺序排列:元组的元素按照声明的顺序存储在内存中,与结构体类似。
- 无字段名:不同于结构体,元组的元素没有字段名,仅按照位置(索引)进行访问。
考虑一个简单的元组定义:
let my_tuple = (10, "hello", true);
这个元组 my_tuple 包含了一个 i32 类型的整数 10、一个 &str 类型的字符串 "hello" 和一个 bool 类型的布尔值 true。
元组的内存布局是紧凑的,并且其中的元素按照它们在元组中的位置顺序存储。因为元组的元素没有字段名,访问元素时需要通过索引来获取,例如 my_tuple.0、my_tuple.1、my_tuple.2。
和结构体不同,元组的内存布局没有对齐需求或填充。它们的存储是简单而紧凑的,元素之间紧密相邻。
元组的内存布局和访问方式是由 Rust 编译器管理的,而且 Rust 并未对元组的内存布局进行严格的规范。因此,具体的内存布局可能会因编译器、优化策略和目标平台等因素而有所不同。
closure
闭包(Closure)是一个可以捕获其环境中变量并且可以在稍后调用的匿名函数。闭包的内存布局在 Rust 中并没有直接暴露或详细定义,因为它们是由编译器在编译时根据捕获的环境和使用情况生成的。
尽管闭包的具体内存布局是由 Rust 编译器实现的细节,但闭包的内部实现与结构体有关,并且根据捕获的变量及其使用方式来进行编译。因此,理解闭包内存布局的最佳方式是从其行为和 Rust 的 trait 实现角度来理解闭包。
-
环境捕获:闭包可以捕获周围环境中的变量。这些捕获的变量在闭包被创建时会被包含在闭包的内部。
-
Fn、FnMut 和 FnOnce:闭包的调用方式取决于其捕获的变量和如何使用这些变量。根据捕获变量的所有权或可变性,闭包可能实现了
FnOnce、FnMut或Fntrait 中的其中之一。 -
背后的实现:闭包背后的具体实现通常涉及一个结构体,它包含了捕获的变量作为其字段,并且实现了对应的 trait。这个结构体的内存布局由编译器生成,通常会保证捕获变量的正确性和可访问性。
由于闭包的实现细节是由 Rust 编译器处理的,而不是直接暴露给开发者的,因此在大多数情况下,不需要过多关注闭包的具体内存布局。闭包的内存布局是由编译器根据其捕获的环境变量、使用方式和实现的 trait 来动态生成的,具体的实现细节可能会因编译器和闭包的用法而有所不同。
union
union 是一种特殊的数据结构,其所有字段共享相同的内存空间。每个 union 实例的大小由其最大字段的大小决定。
-
字段共享内存:
union的所有字段共享同一块内存。因此,对一个字段的写入可能会覆盖其他字段的数据。 -
大小由最大字段决定:
union的大小由其最大字段的大小决定。它的大小等于所有字段中最大字段的大小。 -
字段访问和数据有效性:在
union中,程序员可以使用其中的某个字段来读取数据,但要确保读取的字段类型与实际存储的数据类型相匹配。否则,试图解释存储的数据为不匹配类型的行为将导致未定义的行为。
#[repr(C)] 和 union 的声明:
#[repr(C)] 是一个属性,用于指示编译器按照 C 语言的布局规则来布局 union 或结构体的内存。它确保 union 的布局与 C 语言的标准兼容,有利于与 C 代码进行交互或者在 Rust 中实现特定的内存布局。
下面是一个示例 #[repr(C)] 的 union 声明:
#[repr(C)]
union MyUnion {f1: u32,f2: f32,
}
在这个 union 中,f1 是一个 u32 类型的字段,f2 是一个 f32 类型的字段。由于这两个字段共享相同的内存空间,因此对一个字段的写入可能会影响另一个字段。
在使用 union 时,确保数据的有效性和正确的字段访问非常重要,否则可能导致不可预期的结果或未定义的行为。
相关文章:
Rust开发——数据对象的内存布局
枚举与Sized 数据 一般数据类型的布局是其大小(size)、对齐方式(align)及其字段的相对偏移量。 1. 枚举(Enum)的布局: 枚举类型在内存中的布局通常是由编译器来确定的。不同的编译器可能有不…...

mySQL踩坑记录
1.MYSQL Workbench-8.0.27.1出现"Exception: Current profile has no WMI enabled"错误的解决方法 MYSQL Workbench-8.0.27.1出现“Exception: Current profile has no WMI enabled“错误的解决方法_赛风扥的博客-CSDN博客 C:\Program Files\MySQL\MySQL Workbench …...
【Java】使用 IDEA 快速生成 SpringBoot 模块
项目目录下新建 module 模块 在 pom.xml 更改为 spring initializr 配置之后的 pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchem…...

2023网络安全产业图谱
1. 前言 2023年7月10日,嘶吼安全产业研究院联合国家网络安全产业园区(通州园)正式发布《嘶吼2023网络安全产业图谱》。 嘶吼安全产业研究院根据当前网络安全发展规划与趋势发布《嘶吼2023网络安全产业图谱》调研,旨在进一步了解…...
一则 MongoDB 副本集迁移实操案例
文中详细阐述了通过全量 增量 Oplog 的迁移方式,完成一套副本集 MongoDB 迁移的全过程。 作者:张然,DBA 数据库技术爱好者~ 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。 本文约 900…...
2022年03月 Scratch图形化(四级)真题解析#中国电子学会#全国青少年软件编程等级考试
Scratch等级考试(1~4级)全部真题・点这里 一、单选题(共10题,每题2分,共30分) 第1题 由1,2,3,4,5,0这六个数字经过排列组合能够组成多少个六位数偶数?注意:每一位都不相同,最高位不能为0。 A:720 B:360 C:312 D:88 答案:C 逻辑知识单选题 第2题 运行以下程…...

传音荣获2023首届全国人工智能应用场景创新挑战赛“智能家居专项赛”三等奖
近日,中国人工智能学会与科技部新一代人工智能发展研究中心联合举办2023首届全国人工智能应用场景创新挑战赛(2023 1st China’s Innovation Challenge on Artificial Intelligence Application Scene,以下简称CICAS 2023),吸引了…...

SQL注入-SQL注入过程
SQL注入的过程 手工注入过程 (1) 判断是否存在注入点; (2) 判断字段长度(字段数); (3) 判断字段回显位置; (4) 判断数据库信息; (5) 查找数据库名; (6) 查找数据库表; (7) 查找数据库表中所有字段以及字段值; (8) 猜解账号密码; (9) 登录管理员后台; 以sql-labs less-2举例 会…...

选择更灵活的设计工具:SOLIDWORKS 软件网络版与单机版的比较
随着科技的飞速发展,工程设计领域对于高效、灵活的设计工具需求日益增加。SOLIDWORKS 作为一款广受欢迎的三维设计软件,提供了网络版和单机版两种选择。在本文中,我们将深入探讨这两个版本的区别,并为您详细介绍它们的价格差异。 …...

Go语言中获取协程ID
简介 java同事都知道,线程会有对应的id,那么go语言中协程有id吗,其实是有的,但是不建议使用。 实在需要使用的话可以使用本文的例子获取 stack 我们先看一下runtime.Stack打印出来的栈结构,其中就包括了协程id fu…...

CH58x-BLE 程序阅读笔记
CH58x-BLE 程序阅读笔记 1. 广播1.1 广播类型设置1.2 广播数据长度 2. MTU设置2.1 CH58x 蓝牙协议栈支持有效最大MTU为247 1. 广播 1.1 广播类型设置 1.2 广播数据长度 1) GAP-广播数据(最大大小31字节,但最好保持较短以节省广告时的电量&a…...
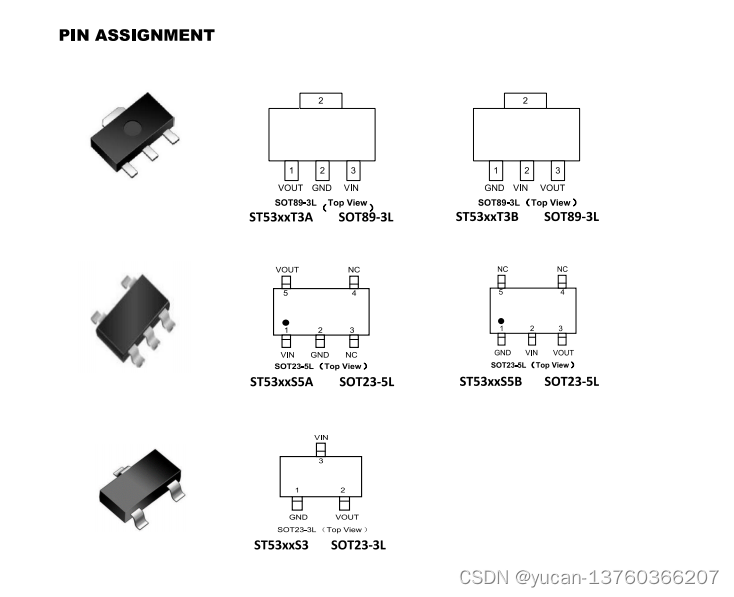
ST53xx 系列是一种高精度、高输入电压、低静态电流、高速度、低压差线性稳压器
ST53xxS/T 40V,低静态电流,高可靠性 LDO 概述: ST53xx 系列是一种高精度、高输入电压、低静态电流、高速度、低压差线性稳压器,具有高纹波抑制能力。在 Vour 5V VIN 7V 时,输入电压高达40V,负载电流高达300…...
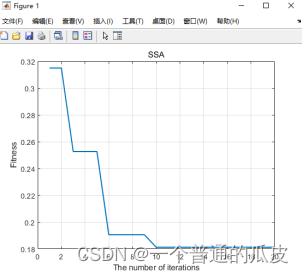
麻雀搜索优化算法MATLAB实现,SSA-BP网络
对于麻雀搜索算法的介绍,网上已经有不少资料了,这边公布SSA的matlab实现 下面展示SSA算法的核心代码以及详细注解 % 麻雀搜索算法函数定义 % 输入:种群大小(pop),最大迭代次数(Max_iter),搜索空间下界(lb),…...

142. 环形链表 II --力扣 --JAVA
题目 给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使…...
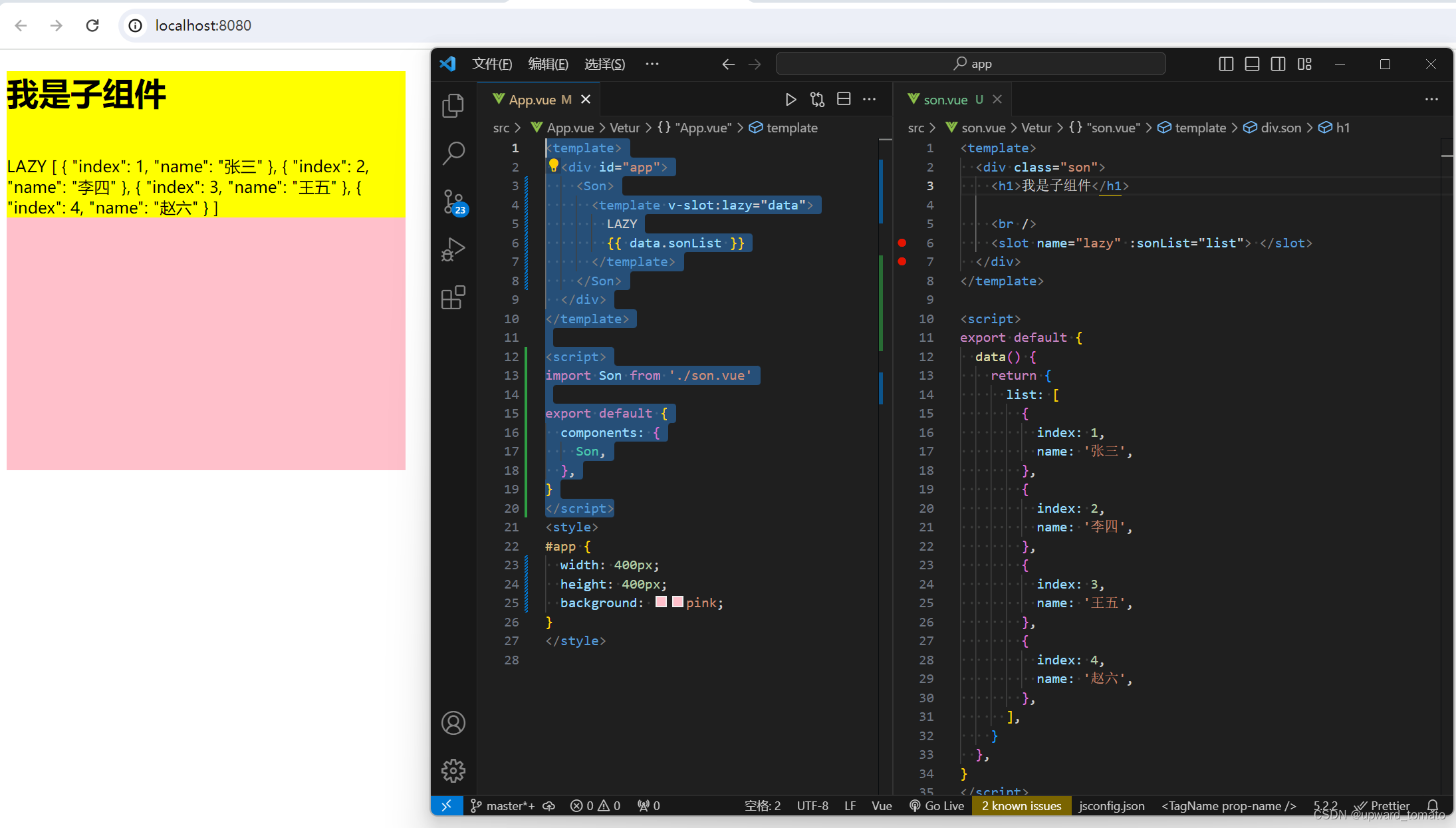
深入浅出 Vue 中的插槽 slot
深入浅出 Vue 中的插槽 slot start 最近被问到好几次 Vue 中的插槽相关知识,掌握的还是有些不全面。抱着重新学习的心态,写这篇博客。首先对基础知识做一个回顾,然后再对源码实现做一个学习。作者:番茄编写时间:2023…...

postgreSQL 查询所有模式的语句
场景 postgre 数据库下携带模式的分组 sql select schema_name from information_schema.schemata;...

pandas教程:Introduction to scikit-learn scikit-learn简介
文章目录 13.4 Introduction to scikit-learn(scikit-learn简介) 13.4 Introduction to scikit-learn(scikit-learn简介) scikit-learn是一个被广泛使用的python机器学习工具包。里面包含了很多监督式学习和非监督式学习的模型&a…...

Linux配置路由功能及添加静态路由
一、配置路由功能 Linux作为路由器,Linux本身就具备路由功能,开启方式如下: 临时开启: echo "1" > /proc/sys/net/ipv4/ip_forward永久开启: vim /etc/sysctl.confnet.ipv4.ip_forward1 # 配置生效 sys…...

什么是Geo Trust OV证书
一、GeoTrust OV证书的介绍 GeoTrust OV证书是由GeoTrust公司提供的SSL证书,它是一种支持OpenSSL的数字证书,具有更高的安全性和可信度。GeoTrust是全球领先的网络安全解决方案提供商,为各类用户提供SSL证书和信任管理服务。GeoTrust OV证书…...
selenium 工具 的基本使用
公司每天要做工作汇报,汇报使用的网页版, 所以又想起 selenium 这个老朋友了。 再次上手,发现很多接口都变了, 怎么说呢, 应该是易用性更强了, 不过还是得重新看看, 我这里是python3。 pip安装…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...
)
紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本+修复模板)
更多请点击: https://intelliparadigm.com 第一章:紧急预警:DeepSeek代码生成中未公开的3类逻辑漂移现象(附自动化检测脚本修复模板) 近期在多轮生产级代码审计中发现,DeepSeek-R1(v2.5&#x…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

UE4SS终极指南:从零开始掌握虚幻引擎脚本系统
UE4SS终极指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE4S…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...

Godot 2D随机地图三大静默故障:黑屏、穿墙、寻路失败的根源与修复
1. 为什么刚上手Godot做2D随机地图就总卡在“生成出来是黑的”“角色穿墙”“房间连不通”这三件事上?如果你是刚从Unity或GameMaker转来Godot,或者第一次用GDScript写程序逻辑的新手,大概率已经在2D随机地图生成这个环节反复摔过跟头——不是…...