pandas教程:Introduction to scikit-learn scikit-learn简介
文章目录
- 13.4 Introduction to scikit-learn(scikit-learn简介)
13.4 Introduction to scikit-learn(scikit-learn简介)
scikit-learn是一个被广泛使用的python机器学习工具包。里面包含了很多监督式学习和非监督式学习的模型,可以实现分类,聚类,预测等任务。
虽然scikit-learn并没有和pandas深度整合,但在训练模型之前,pandas在数据清洗阶段能起很大作用。
译者:构建的机器学习模型的一个常见流程是,用
pandas对数据进行查看和清洗,然后把处理过的数据喂给scikit-learn中的模型进行训练。
这里用一个经典的kaggle比赛数据集来做例子,泰坦尼克生还者数据集。加载训练集和测试集:
import numpy as np
import pandas as pd
train = pd.read_csv('../datasets/titanic/train.csv')
test = pd.read_csv('../datasets/titanic/test.csv')
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
statsmodels和scikit-learn通常不能应付缺失值,所以我们先检查一下哪些列有缺失值:
train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
test.isnull().sum()
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64
对于这样的数据集,通常的任务是预测一个乘客最后是否生还。在训练集上训练模型,在测试集上验证效果。
上面的Age这一列有缺失值,这里我们简单的用中位数来代替缺失值:
impute_value = train['Age'].median()
train['Age'] = train['Age'].fillna(impute_value)
test['Age'] = test['Age'].fillna(impute_value)
对于Sex列,我们将其变为IsFemale,用整数来表示性别:
train['IsFemale'] = (train['Sex'] == 'female').astype(int)
test['IsFemale'] = (test['Sex'] == 'female').astype(int)
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | IsFemale | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 0 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 1 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 1 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 1 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 0 |
接下来决定一些模型参数并创建numpy数组:
predictors = ['Pclass', 'IsFemale', 'Age']
X_train = train[predictors].values
X_test = test[predictors].values
y_train = train['Survived'].values
X_train[:5]
array([[ 3., 0., 22.],[ 1., 1., 38.],[ 3., 1., 26.],[ 1., 1., 35.],[ 3., 0., 35.]])
y_train[:5]
array([0, 1, 1, 1, 0])
这里我们用逻辑回归模型(LogisticRegression):
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
然后是fit方法来拟合模型:
model.fit(X_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,penalty='l2', random_state=None, solver='liblinear', tol=0.0001,verbose=0, warm_start=False)
在测试集上进行预测,使用model.predict:
y_predict = model.predict(X_test)
y_predict[:10]
array([0, 0, 0, 0, 1, 0, 1, 0, 1, 0])
如果我们有测试集的真是结果的话,可以用来计算准确率或其他一些指标:
(y_true == y_predcit).mean()
实际过程中,训练模型的时候,经常用到交叉验证(cross-validation),用于调参,防止过拟合。这样得到的预测效果会更好,健壮性更强。
交叉验证是把训练集分为几份,每一份上又取出一部分作为测试样本,这些被取出来的测试样本不被用于训练,但我们可以在这些测试样本上验证当前模型的准确率或均方误差(mean squared error),而且还可以在模型参数上进行网格搜索(grid search)。一些模型,比如逻辑回归,自带一个有交叉验证的类。LogisticRegressionCV类可以用于模型调参,使用的时候需要指定正则化项C,来控制网格搜索的程度:
from sklearn.linear_model import LogisticRegressionCV
model_cv = LogisticRegressionCV(10)
model_cv.fit(X_train, y_train)
LogisticRegressionCV(Cs=10, class_weight=None, cv=None, dual=False,fit_intercept=True, intercept_scaling=1.0, max_iter=100,multi_class='ovr', n_jobs=1, penalty='l2', random_state=None,refit=True, scoring=None, solver='lbfgs', tol=0.0001, verbose=0)
如果想要自己来做交叉验证的话,可以使用cross_val_score函数,可以用于数据切分。比如,把整个训练集分为4个不重叠的部分:
from sklearn.model_selection import cross_val_score
model = LogisticRegression(C=10)
model
LogisticRegression(C=10, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,penalty='l2', random_state=None, solver='liblinear', tol=0.0001,verbose=0, warm_start=False)
scores = cross_val_score(model, X_train, y_train, cv=4)
scores
array([ 0.77232143, 0.80269058, 0.77027027, 0.78828829])
默认的评价指标每个模型是不一样的,但是可以自己指定评价函数。交叉验证的训练时间较长,但通常能得到更好的模型效果。
相关文章:

pandas教程:Introduction to scikit-learn scikit-learn简介
文章目录 13.4 Introduction to scikit-learn(scikit-learn简介) 13.4 Introduction to scikit-learn(scikit-learn简介) scikit-learn是一个被广泛使用的python机器学习工具包。里面包含了很多监督式学习和非监督式学习的模型&a…...

Linux配置路由功能及添加静态路由
一、配置路由功能 Linux作为路由器,Linux本身就具备路由功能,开启方式如下: 临时开启: echo "1" > /proc/sys/net/ipv4/ip_forward永久开启: vim /etc/sysctl.confnet.ipv4.ip_forward1 # 配置生效 sys…...

什么是Geo Trust OV证书
一、GeoTrust OV证书的介绍 GeoTrust OV证书是由GeoTrust公司提供的SSL证书,它是一种支持OpenSSL的数字证书,具有更高的安全性和可信度。GeoTrust是全球领先的网络安全解决方案提供商,为各类用户提供SSL证书和信任管理服务。GeoTrust OV证书…...
selenium 工具 的基本使用
公司每天要做工作汇报,汇报使用的网页版, 所以又想起 selenium 这个老朋友了。 再次上手,发现很多接口都变了, 怎么说呢, 应该是易用性更强了, 不过还是得重新看看, 我这里是python3。 pip安装…...

Excel如何比较两列数据的不同
当遇到exel有两个列表的数据,需要比较得到他们的不同的部分,并且得到一个不同的值的列表。示例如下: 目的是:通过比较,知道Column2的哪些值不在在Column1里。 WPS直接提供了这一个功能,如下图:…...

力扣labuladong——一刷day47
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣993. 二叉树的堂兄弟节点二、力扣1315. 祖父节点值为偶数的节点和三、力扣1448. 统计二叉树中好节点的数目四、力扣1469. 寻找所有的独生节点 前言 二叉…...

蓝桥杯-02-python组考点与14届真题
文章目录 蓝桥杯python组考点与14届真题参考资源python组考点1. 组别2. 竞赛赛程3. 竞赛形式4. 参赛选手机器环境5. 试题形式5.1. 结果填空题5.2. 编程大题 6. 试题考查范围7. 答案提交8. 评分9. 样题样题 1:矩形切割(结果填空题)样题 2&…...
)
【0240】源码分析PG内核中的关键字列表(SQL keywords)
相关文章: 【0236】聊一聊PG内核中的命令标签(Command Tags、CommandTag、tag_behavior) 【0239】从编译原理角度理解 #include “xxx“ 或 #include<xxx> 的实现机制 1. PostgreSQL的SQL关键字列表(SQL Keywords) 1.1 keywords.c源文件内容 keywords.c源文件中的内容…...
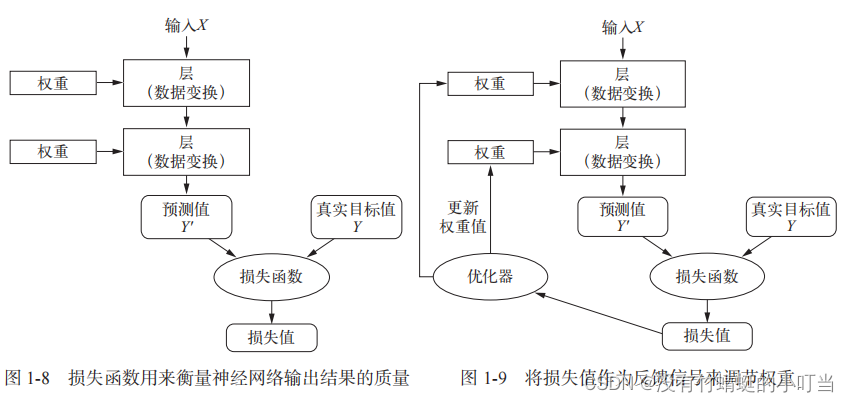
【Python深度学习第二版】学习笔记之——什么是深度学习
机器学习是将输入(比如图像)映射到目标(比如标签“猫”)的过程。 这一过程是通过观察许多输入和目标的示例来完成的。 深度神经网络通过一系列简单的数据变换(层)来实现这种输入到目标的映射,这…...
ddns-go部署在linux虚拟机
ddns-go部署ubuntu1804 1.二进制部署 1.虚拟机部署 1.下载linux的x86二进制包 wget https://github.com/jeessy2/ddns-go/releases/download/v5.6.3/ddns-go_5.6.3_linux_x86_64.tar.gz2.解压 tar -xzf ddns-go_5.6.3_linux_x86_64.tar.gz3.拷贝执行文件到PATH下,…...

LeetCode Hot100 543.二叉树的直径
题目: 给你一棵二叉树的根节点,返回该树的 直径 。 二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。 两节点之间路径的 长度 由它们之间边数表示。 方法:灵神 代码: …...
Breadcrumb面包屑(antd-design组件库)简单用法和自定义分隔符
1.Breadcrumb面包屑 显示当前页面在系统层级结构中的位置,并能向上返回。 2.何时使用 当系统拥有超过两级以上的层级结构时; 当需要告知用户『你在哪里』时; 当需要向上导航的功能时。 组件代码来自: 面包屑 Breadcrumb - Ant Des…...

Mybatis 源码搭建
文章目录 源码下载测试模块搭建学习博客 源码下载 首先下载mybatis-parent的源码:gitee地址 > https://gitee.com/callback_lab/mybatis-parent.git 然后下载mybatis的源码:gitee地址 > https://gitee.com/callback_lab/mybatis-src.git 带中文…...
-函数的定义)
shell编程系列(5)-函数的定义
文章目录 前言函数定义处理函数参数通过getopts接收参数 前言 函数是编程语言中最重要的部分之一,虽然在shell脚本中并不是必须的,但是函数可以提高代码的复用性和可读性,当我们编写稍微复杂的脚本时,函数就是一个好帮手…...

鸿蒙应用开发-初见:入门知识、应用模型
基础知识 Stage模型应用程序包结构 开发并打包完成后的App的程序包结构如图 开发者通过DevEco Studio把应用程序编译为一个或者多个.hap后缀的文件,即HAP一个应用中的.hap文件合在一起称为一个Bundle,bundleName是应用的唯一标识 需要特别说明的是&…...

通过测试驱动开发(TDD)的方式开发Web项目
最近在看一本书《Test-Driven Development with Python》,里面非常详细的介绍了如何一步一步通过测试驱动开发(TDD)的方式开发Web项目。刚好这本书中使用了我之前所了解的一些技术,Django、selenium、unittest等。所以,读下来受益匪浅。 我相…...

技巧-PyCharm中Debug和Run对训练的影响和实验测试
简介 在训练深度学习模型时,使用PyCharm的Debug模式和Run模式对训练模型的耗时会有一些区别。 Debug模式:Debug模式在训练模型时,会对每一行代码进行监视,这使得CPU的利用率相对较高。由于需要逐步执行、断点调试、查看变量值等操…...
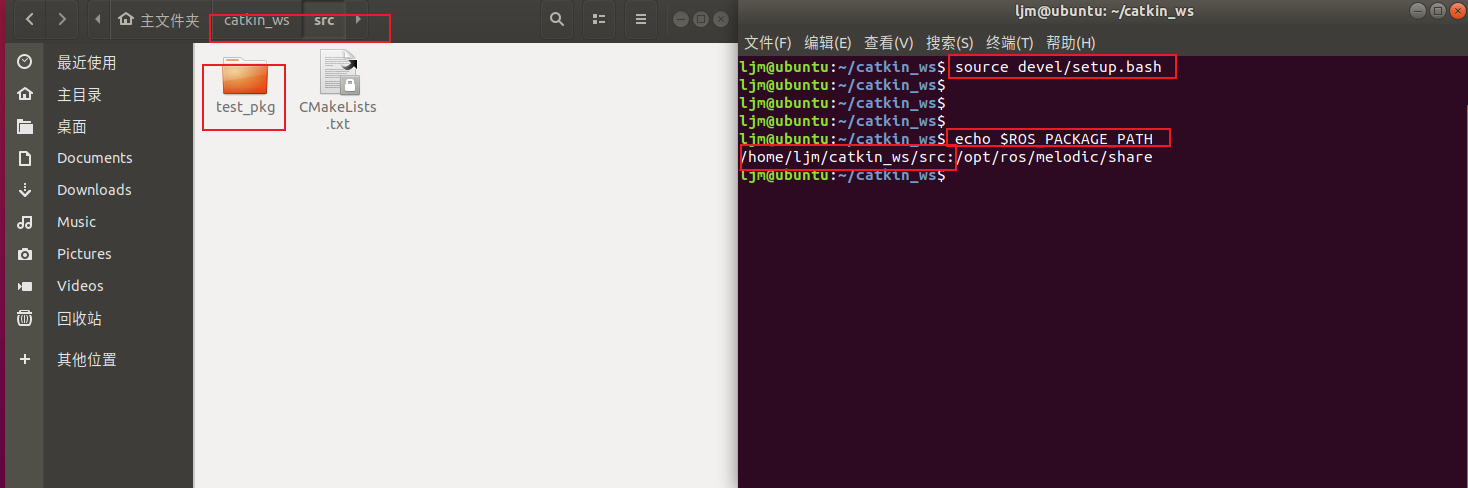
【古月居《ros入门21讲》学习笔记】07_创建工作空间和功能包
目录 说明: 1. 工作空间(workspace) 结构: 2. 创建工作空间和功能包 创建工作空间 编译工作空间 创建功能包 设置环境变量 3. 注意 同一个工作空间下,不能存在同名的功能包; 不同工作空间下,可以存在同名的功…...
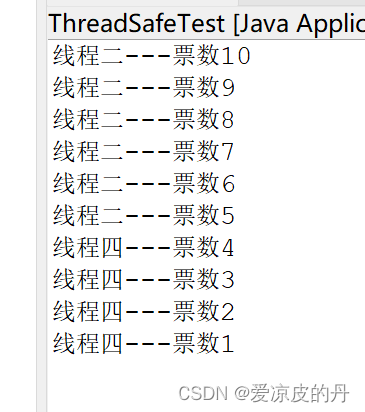
第20章多线程
20.1线程简介 Windows操作系统是多任务操作系统,它以进程为单位。一个进程是一个包含有自身地址的程序,每个独立执行的程序都称为进程。也就是说每个正在执行的程序都是一个进程。系统可以分配给每一个进程有一段有限的使用CPU的时间(也可以称…...
深信服防火墙设置应用控制策略(菜鸟必看)
PS:前几天发布了关于深信服防火墙路由部署的流程:深信服防火墙路由模式开局部署-手把手教学(小白篇)-CSDN博客 昨天晚上有csdn的朋友联系我,说有一个关于ACL访问的问题要帮忙看一下 解决了以后,写个大概的…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

为Alchitry Au FPGA开发板外接JTAG接口的完整指南
1. 项目概述与核心价值如果你正在使用基于Xilinx Artix-7 FPGA的Alchitry Au或Au开发板,并且已经厌倦了每次调试或烧录都要依赖板载的USB-JTAG桥接芯片,或者你的项目已经将板载USB接口挪作他用,那么为你的开发板外接一个独立的JTAG调试器&…...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...

Taotoken的稳定性与低延迟在实时对话应用中的实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的稳定性与低延迟在实时对话应用中的实际体验 在开发需要快速响应的AI聊天应用时,后端API的稳定性和延迟表现是…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...

从配置到运行时:Forge Admin 的动态 API 配置管理是怎么做的
问题:同一个接口,今天要加认证、明天要加加密、后天要限流,这些行为散落在拦截器、过滤器、注解里,改一次牵一发动全身,怎么集中管理和动态刷新? 1. 这个问题在企业后台里为什么常见 在企业后台开发中&am…...