Spark---SparkCore(五)
五、Spark Shuffle文件寻址
1、Shuffle文件寻址
1)、MapOutputTracker
MapOutputTracker是Spark架构中的一个模块,是一个主从架构。管理磁盘小文件的地址。
- MapOutputTrackerMaster是主对象,存在于Driver中。
- MapOutputTrackerWorker是从对象,存在于Excutor中。
2)、BlockManager
BlockManager块管理者,是Spark架构中的一个模块,也是一个主从架构。
- BlockManagerMaster,主对象,存在于Driver中。
BlockManagerMaster会在集群中有用到广播变量和缓存数据或者删除缓存数据的时候,通知BlockManagerSlave传输或者删除数据。
- BlockManagerSlave,从对象,存在于Excutor中。
BlockManagerSlave会与BlockManagerSlave之间通信。
- 无论在Driver端的BlockManager还是在Excutor端的BlockManager都含有三个对象:
- DiskStore:负责磁盘的管理。
- MemoryStore:负责内存的管理。
- BlockTransferService:负责数据的传输。
3)、Shuffle文件寻址图
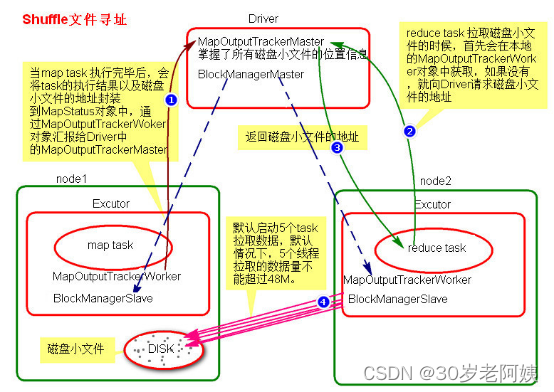
4)、Shuffle文件寻址流程
- 当map task执行完成后,会将task的执行情况和磁盘小文件的地址封装到MpStatus对象中,通过MapOutputTrackerWorker对象向Driver中的MapOutputTrackerMaster汇报。
- 在所有的map task执行完毕后,Driver中就掌握了所有的磁盘小文件的地址。
- 在reduce task执行之前,会通过Excutor中MapOutPutTrackerWorker向Driver端的MapOutputTrackerMaster获取磁盘小文件的地址。
- 获取到磁盘小文件的地址后,会通过BlockManager连接数据所在节点,然后通过BlockTransferService进行数据的传输。
- BlockTransferService默认启动5个task去节点拉取数据。默认情况下,5个task拉取数据量不能超过48M。
六、Spark 内存管理和Shuffle优化
1、Spark内存管理
Spark执行应用程序时,Spark集群会启动Driver和Executor两种JVM进程,Driver负责创建SparkContext上下文,提交任务,task的分发等。Executor负责task的计算任务,并将结果返回给Driver。同时需要为需要持久化的RDD提供储存。Driver端的内存管理比较简单,这里所说的Spark内存管理针对Executor端的内存管理。
Spark内存管理分为静态内存管理和统一内存管理,Spark1.6之前使用的是静态内存管理,Spark1.6之后引入了统一内存管理。
静态内存管理中存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置。
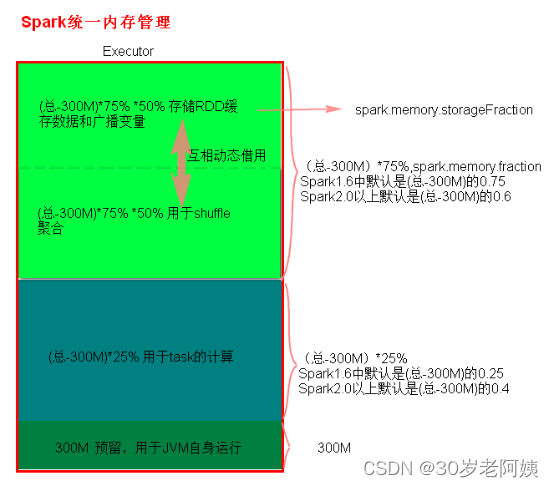
统一内存管理与静态内存管理的区别在于储存内存和执行内存共享同一块空间,可以互相借用对方的空间。
Spark1.6以上版本默认使用的是统一内存管理,可以通过参数spark.memory.useLegacyMode 设置为true(默认为false)使用静态内存管理。
1)、静态内存管理分布图
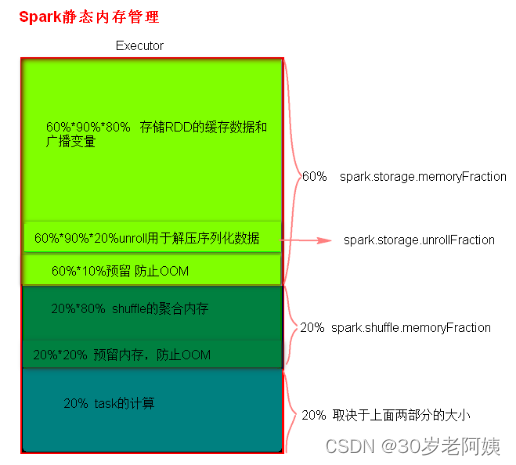
2)、统一内存管理分布图
3)、reduce 中OOM如何处理?
- 减少每次拉取的数据量
- 提高shuffle聚合的内存比例
- 提高Excutor的总内存
2、Shuffle调优
1)、SparkShuffle调优配置项如何使用?
1、在代码中,不推荐使用,硬编码。
new SparkConf().set(“spark.shuffle.file.buffer”,”64”)2、在提交spark任务的时候,推荐使用。
spark-submit --conf spark.shuffle.file.buffer=64 –conf ….3、在conf下的spark-default.conf配置文件中,不推荐,因为是写死后所有应用程序都要用。
2)、Shuffle调优附件
spark.reducer.maxSizeInFlight
默认值:48m
参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。spark.shuffle.io.maxRetries
默认值:3
参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
shuffle file not find taskScheduler不负责重试task,由DAGScheduler负责重试stage
spark.shuffle.io.retryWait
默认值:5s
参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
调优建议:建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
spark.shuffle.sort.bypassMergeThreshold
默认值:200
参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
相关文章:
Spark---SparkCore(五)
五、Spark Shuffle文件寻址 1、Shuffle文件寻址 1)、MapOutputTracker MapOutputTracker是Spark架构中的一个模块,是一个主从架构。管理磁盘小文件的地址。 MapOutputTrackerMaster是主对象,存在于Driver中。MapOutputTrackerWorker是从对…...
k8s中pod的hostport端口突然无法访问故障处理
故障背景: 租户告知生产环境的sftp突然无法访问了,登录环境查看sftp服务运行都是正常的,访问sftp的hostport端口确实不通。 故障处理过程 既然访问不通那就先给服务做个全面检查,看看哪里出了问题,看下sftp日志&#…...

高德开始“跑腿”
在这个万物皆可到家的时代,外卖已经不仅仅只送餐饮了,无论是鲜花、生活用品,亦或是其他急需品,只需要一个订单,就能够通通搞定。而随着消费者需求的增加,以即时物流为代表的新业态也顺势而起,并…...
Notion for Mac:打造您的专属多功能办公笔记软件
在如今这个信息爆炸的时代,一款高效、便捷的笔记软件对于办公人士来说已经成为必不可少的工具。Notion for Mac,作为一款多功能办公笔记软件,凭借其简洁优雅的界面、强大的功能以及无缝的云端同步,成为了众多用户的首选。 一、多…...
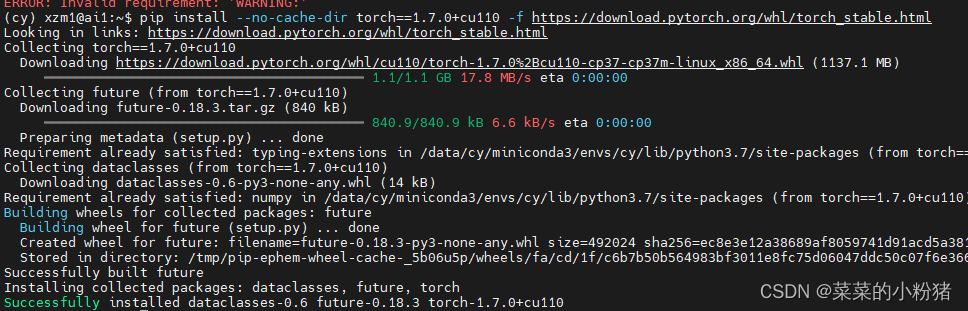
pip 安装软件出现 [No space left on device]
问题: /home文件下空间满了,安装软件可能会出现这个问题 解决方法: pip install --no-cache-dir 安装包名...
【算法刷题】Day8
文章目录 202. 快乐数解法: 11. 盛最多水的容器解法: 202. 快乐数 原题链接 拿到题,我们先看题干 把一个整数替换为每个位置上的数字平方和,有两种情况: 重复这个过程始终不到 1(无限死循环)结…...
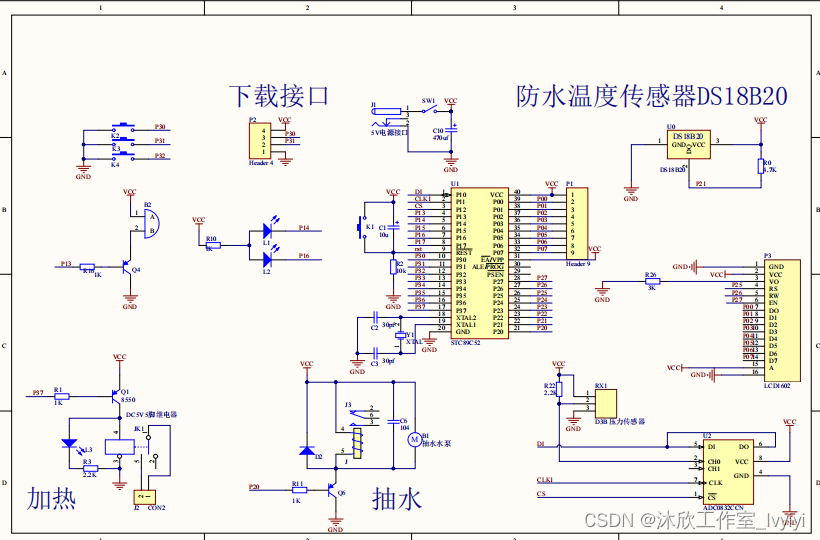
基于单片机的智能饮水机控制系统(论文+源码)
1. 系统设计 本次智能饮水机控制系统的设计研究一款以STC89C52单片机为核心的智能饮水机控制系统,其主要功能设计如下: 1.该饮水机利用DS18B20数字温度传感器实时采集饮水机内水的温度,其检测温度范围为0-100℃,精度0.1℃&#…...
电脑格式化了怎么恢复原来的数据?您可以这样做
电脑是我们日常生活和工作中不可或缺的工具,然而,在一些情况下我们可能需要进行电脑格式化,比如为了清理系统垃圾、解决系统故障等。然而,格式化会导致所有数据被删除,给用户带来不便和困扰。本文将介绍电脑格式化了怎…...

mysql 性能排查
mysql 下常见遇到的问题有,mysql连接池耗尽,死锁、慢查、未提交的事务。等等我们可能需要看;我们想要查看的可能有 1.当前连接池连接了哪些客户端,进行了哪些操作 2.当前造成死锁的语句有哪些,是哪个客户端上的&#x…...
SpringBoot+网易邮箱登录注册
文章目录 SpringBoot网易邮箱登录注册pom.xmlapplication.ymlsqlUserEmail.javaUserEmailMapper.javaUserEmailMapper.xmlEmailService.javaUserEmailService.javaUserEmailServiceImpl.javaUserEmailController.javaregister1.html 编写前参考 SpringBoot网易邮箱登录注册 po…...
——4.7.触发器(Trigger))
SQL Server对象类型(7)——4.7.触发器(Trigger)
4.7. 触发器(Trigger) 4.7.1. 触发器概念 与Oracle中类似,SQL Server中,触发器是虚的、被定义的数据库代码对象,其本身并不存储数据,其通过数据库事件来自动触发预先定义的特定代码片段,以解决用户特定业务需求和完成特定任务。 4.7.2. 触发器注解 1)触发器的本质:…...

让@RefreshScope注解来帮助我们实现动态刷新
文章目录 前言举例作用参考文章总结 前言 在实际开发当中我们常常会看到有些类上会加一个注解:RefreshScope,有没有对应的小伙伴去思考过这个东西,这个注解有什么作用?为什么要加?下面我们就来看看这个 RefreshScope …...

c++ opencv使用drawKeypoints、line实现特征点的连线显示
前言 图像经过算子处理后得到若干特征点,使用opencv进行渲染显示出这些特征点并且连线,更直观的对比处理前后的一些差异性 demo核心代码 //画出特征点并连线 void drawFilterLinePoints(cv::Mat& srcMat, cv::Point2f pointStart, cv::Point2f po…...

Ruoyi-cloud / 若依 SpringCloud服务器部署
1、redis 环境 服务器安装redis ,注意 密码 端口 2、mysql 环境 服务器安装 mysql 5.7 以上的版本 代码中的sql 文件夹中有 sql 文件 创建数据库ry-cloud并导入数据脚本ry_2021xxxx.sql(必须),quartz.sql(可选&…...

Java面试题09
1.什么是反射? 反射是Java中的一种机制,允许在运行时获取类的信息、访问对象的属性和方法,以及调用 对象的方法,使得编程更加灵活,但也需要注意性能和安全问题。 在Java中,反射(Reflection&…...

Linux grep命令
目录 一. 前期准备二. 配置项2.1 -e 配置项2.2 -h 配置项 三. 正则表达式3.1 {} 或查询3.2 文件路径和查询关键词中均包含正则表达式 四. zgrep 一. 前期准备 ✅TEST-2023-07-11.txt MPLE0130 Exception 123 ExecTimeMPLE0190 ExecTime123 MPLE0150 TST 1234 ExecTime454 MPL…...

RPC之GRPC:什么是GRPC、GRPC的优缺点、GRPC使用场景
简介 gRPC是一个现代的开源高性能远程过程调用(RPC)框架,可以在任何环境中运行。它可以高效地连接数据中心内和跨数据中心的服务,支持负载平衡、跟踪、运行状况检查和身份验证。它也适用于分布式计算的最后一英里,将设备、移动应用程序和浏览…...

无人机光伏巡检代替人工,贵州电站运维升级
无人机光伏巡检如何做到降本增效?贵州省光伏电站有新招!某70MWp的光伏电站通过引入复亚智能无人机光伏巡检系统,专注于使用无人机对区域内的光伏面板进行自动巡航巡查,利用自动化巡检和故障识别技术,显著提升了光伏电站…...

【Q3——30min】
1、介绍一下数据库的三大范式 第一范式(1NF):属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列) 第二范式(2NF):满足第一范式;且不存在部分依赖,即非主属性必须完全依赖于主属性。(主属性即主键&a…...

leetcode每日一题35
90. 子集 II 回溯嘛 子集啊排列组合啊棋盘啊都是回溯 回溯三部曲走起 跟78.子集比,本题给出的数组里存在重复元素了 所以在取元素时,如果同一层里取过某个元素,那么在该层就不能取重复的该元素了 如给出的数组[1,2,2] 可以在某一次递归中第一…...

13456
12356...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

长期使用Token Plan套餐在项目开发中的成本观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在项目开发中的成本观察 在AI驱动的项目开发中,成本控制与预算管理是团队负责人必须面对的现实…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

约束感知图缩减算法在量子优化中的应用
1. 约束感知图缩减算法概述在量子计算领域,资源受限一直是制约算法实际应用的主要瓶颈。以当前主流的超导量子计算机为例,其量子比特数通常在50-100个之间,且存在显著的噪声干扰。这种硬件限制使得许多经典优化问题难以直接映射到量子设备上求…...

5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南
5步彻底解决Windows DLL加载冲突:UE4SS系统故障排查指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS…...

Arduino土壤湿度监测仪制作:从传感器原理到自动灌溉实现
1. 项目概述:用Arduino Uno和LCD屏打造你的土壤湿度监测仪作为一个喜欢在阳台种点番茄、辣椒的业余园丁,我经常为浇水这事儿头疼。浇多了怕烂根,浇少了又怕旱着,光靠手指插土里感觉,实在是不准。后来玩上了Arduino&…...

WarcraftHelper:让经典魔兽争霸3完美适配现代电脑的终极解决方案
WarcraftHelper:让经典魔兽争霸3完美适配现代电脑的终极解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代操…...

将deepseek v4 pro集成到codex桌面APP中使用
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、《解密程序员的思维密码——沟通、演讲、思考的实践》作者、清华大学出版社签约作家、Java领域…...