eKuiper 1.8.0 发布:零代码实现图像/视频流的实时 AI 推理
LF Edge eKuiper 是 Golang 实现的轻量级物联网边缘分析、流式处理开源软件,可以运行在各类资源受限的边缘设备上。eKuiper 的主要目标是在边缘端提供一个流媒体软件框架(类似于 Apache Flink )。eKuiper 的规则引擎允许用户提供基于 SQL 或基于图形(类似于 Node-RED)的规则,在几分钟内创建物联网边缘分析应用。
近日,eKuiper 发布了 1.8.0 版本。该版本的主要亮点有:
- 零编码 AI 推理: 通过通用 AI 函数,用户无需编码即可针对流式数据或视频流实现实时 AI 算法推理。该函数可以推理任意的 Tensor Flow Lite 模型。用户模型训练完成后下发模型即可使用,十分灵活快捷。
- 可视化规则创建: 管理控制台中集成了可视化规则编辑器 Flow Editor。用户使用免费的 eKuiper manager 管理控制台时,可通过可视化拖拽 UI 进行规则的新建和编辑。
- 更灵活的数据传输配置: 重构了外部连接 source/sink 的格式和序列化实现,解耦了格式和传输协议,并支持更多的格式如 csv 和自定义格式。
完整功能列表,请查看 Release Note。
同时,产品团队也重构了文档结构,更新了安装和应用场景文档,方便用户快速找到有用的文档信息。
通用 AI 函数
之前的版本中,eKuiper 支持通过扩展的方式,在插件中调用 AI/ML 模型进行流式数据算法推理。这种方法方便用户进行算法的预处理和后处理,但有较高的使用门槛,运维更新也比较复杂。
新版本提供了 Tensor Flow Lite 函数插件,用于在流式计算和视频流中进行实时 AI 推理。这个函数为通用的 AI 函数,可用于处理大部分已预训练好的 Tensor Flow Lite 模型。使用中,用户只需上传或提前部署好需要使用到的模型,无需额外编码即可在规则中使用这些模型。
tfLite 函数接收两个参数,其中第一个参数为模型(扩展名须为 .tflite)的名称,第二个参数为模型的输入。假设用户预先训练好了文本分类模型 text_model 和智能回复模型 smart_reply_model,需要对实时流入 eKuiper 的数据应用这两个模型分析。使用时仅需要两个步骤:
- 下发模型到 eKuiper 部署的边缘端,可通过 eKuiper 的 upload API 或者其他应用管理。
- 配置规则,使用 tfLite 函数,指定模型名称即可使用,如下示例:
SELECT tfLite(\"text_model\", data) as result FROM demoModel
SELECT tfLite(\"smart_reply_model\", data) as result FROM demoModel
函数会在 eKuiper 层面针对输入数据格式进行验证。用户可以通过更多的 SQL 语句对模型的输入和输出做预处理或者后处理。
图像/视频流推理
配合新版本提供的视频流源(详情见下文),eKuiper 提供了视频接入并定时获取图像帧的能力。图像帧可在规则中,使用 tfLite 函数进行 AI 推理。Tensor Flow 模型通常是针对特定的图像大小进行训练的,对图像进行推理时,经常需要进行变更大小等预处理。eKuiper 也提供了 resize、thumnail 等预处理方法。函数会返回 output tensor 的数组表示供后续规则或应用处理。
在以下的规则 ruleTf 中,我们调用了 label.tflite 模型,对传入的图像先进行预处理,大小调整为 224 * 224。
SELECT tfLite(\"label\", resize(self, 224, 224, true) as result FROM tfdemo
这个规则的执行示意图如下所示。

使用通用 AI 函数,用户可以快速部署、验证和更新 AI 模型,加快应用的迭代更新。
可视化编辑器 Flow Editor
eKuiper 从 1.6.0 版本开始提供适合面向可视化界面的图规则 API,相比于 SQL 更适合于构建 UI 界面。在 1.8.0 版本中,我们正式在免费的 eKuiper manager 管理控制台中提供了 Flow Editor 可视化编辑器。用户在创建和编辑规则时,可选择使用原有的 SQL 规则编辑器或使用试用版本的 Flow Editor。
Flow Editor 的界面如下图所示。它的使用遵循主流可视化工作量编辑器的风格和使用逻辑。左侧是可用节点,用户自定义插件和函数也会出现在列表中。中间是画布,用户可拖拽节点并连线;右侧是属性配置视图,点击节点后可在此配置。欢迎大家试用并反馈宝贵意见。

除了集成原有功能到 Flow Editor 中,新版本中还添加了两种节点:
- Switch node: 该节点允许消息被路由到不同的流程分支,类似于编程语言中的 switch 语句。
- Script node: 该节点允许针对传递的信息运行 JavaScript 代码。
有了这两种节点,Flow Editor 可以创建传统多分支工作流并且更加容易进行节点的扩展,实现脚本编写。
连接格式优化和自定义:序列化和 Schema
eKuiper 通过 source/sink 与外部系统进行连接、读入或写出数据。以 source 为例,每种类型的 source 读取数据时都需要经过连接(connect)和序列化(serialization)两个步骤。例如,MQTT source,连接意味着遵循 MQTT 协议连接 broker,而序列化则是将读取到的数据 payload 解析成 eKuiper 内部的 map 格式。
连接和序列化
此前,连接和序列化通常在 source 内部实现,因此当用户需要解析自定义格式时,即使连接协议是 MQTT 等已支持协议,仍然需要编写完整的 source 插件。新的版本中,格式和 source 类型进一步分离,用户可以自定义格式,而各种格式可以与不同的连接类型结合使用。自定义格式的编写方法请参考格式扩展。
例如,创建 MQTT 类型的数据流时可定义各种不同的 payload 格式。默认的 JSON 格式:
CREATE STREAM demo1() WITH (FORMAT="json", TYPE="mqtt", DATASOURCE="demo")
MQTT 类型的数据流使用自定义格式,此时 MQTT 的 payload 中的数据应当使用自定义的格式:
CREATE STREAM demo1() WITH (FORMAT="custom", SCHEMAID="myFormat.myMessage", TYPE="mqtt", DATASOURCE="demo")
Schema
此前 eKuiper 支持在 Create Stream 的时候指定数据结构类型等。但该方式存在一些不足:
- 额外性能消耗。当前的 Schema 没有与数据原本的格式 Schema 关联,因此在数据解码之后,需要再额外进行一次验证/转换;而且该过程基于反射动态完成,性能较差。例如,使用 Protobuf 等强Schema 时,经 Protobuf 解码之后的数据应当已经符合格式,不应再进行转换。
- Schema 定义繁琐。同样无法利用数据本身格式的 Schema,而是需要额外配置。
新的版本中,Stream 定义时支持逻辑 Schema 和格式中的物理 Schema 定义。SQL 解析时,会自动合并物理 Schema 和逻辑 Schema,用于指导 SQL 的验证和优化。同时,我们也提供了 API,用于外部系统获取数据流的实际推断 Schema。
GET /streams/{streamName}/schema
格式列表
新版本中,支持的格式扩展到如下几种。部分格式包含内置的序列化;部分格式(如 Protobuf)既可以使用内置的动态序列化方式也可以由用户提供静态序列化插件以获得更好的性能。在 Schema 支持方面,部分格式带有 Schema,而自定义格式也可以提供 Schema 实现。

分析能力增强
新的版本继续加强了有状态分析函数的能力,同时提供了统计函数,提升了产品原生的分析能力。
有条件分析函数
分析函数添加了 WHEN 条件判断子句,根据是否满足条件来确定当前事件是否为有效事件。 当为有效事件时,根据分析函数语意计算结果并更新状态。当为无效事件时,忽略事件值,复用保存的状态值。完整的分析函数语法为:
AnalyticFuncName(<arguments>...) OVER ([PARTITION BY <partition key>] [WHEN <Expression>])
增加了 WHEN 子句之后,分析函数可以实现更加复杂的有状态分析。例如,计算状态的持续时间:
SELECT lag(StatusDesc) as status, StartTime - lag(StartTime) OVER (WHEN had_changed(true, StatusCode)), EquipCode FROM demo WHERE had_changed(true, StatusCode)
其中,lag(StartTime) OVER (WHEN had_changed(true, StatusCode)) 将返回上次状态变化时的时间。因此,使用当前时间减去该时间可实时计算出状态的持续时间。
统计函数
新的版本中,我们提供了多个聚合统计函数,例如标准差、方差和百分位的计算。
连接生态扩展
eKuiper 可以处理二进制图像数据,但是此前的测试中,图像都是经由 MQTT、HTTP 等偏向文本数据传输的协议来发送。新版本提供了视频流源,增加了一种新的二进制数据源。另外,我们大幅增强了文件 source 的能力,支持更多文件类型并支持流式消费文件内容。
文件源
之前版本的文件源主要用于创建 Table,对流式处理的支持不够完善。新的版本中,文件源也支持作为用作流,此时通常需要设置 interval 参数以定时拉取更新。同时增加了文件夹的支持,多种文件格式的支持和更多的配置项。
新版本中支持的文件类型有:
- json:标准的 JSON 数组格式文件。如果文件格式是行分隔的 JSON 字符串,需要用 lines 格式定义。
- csv:支持逗号分隔的 csv 文件,以及自定义分隔符。
- lines:以行分隔的文件。每行的解码方法可以通过流定义中的格式参数来定义。例如,对于一个行分开的 JSON 字符串,文件类型应设置为 lines,格式应设置为 JSON。
创建读取 csv 文件的数据流,语法如下:
CREATE STREAM cscFileDemo () WITH (FORMAT="DELIMITED", DATASOURCE="abc.csv", TYPE="file", DELIMITER=",")
视频流源
视频源用于接入视频流,例如来自摄像头的视频或者直播视频流。视频流源定期采集视频流中的帧,作为二进制流接入 eKuiper 中进行处理。
通过视频源接入的数据,可以使用已有的 SQL 功能,例如 AI 推理函数功能等,转换成数据进行计算或输出为新的二进制图像等。
规则自动化运维
部署在边缘端的规则运维相对困难。而边缘端的部署数量通常较大,手工重启规则或重启 eKuiper 也会成为较为繁琐的工作。新的版本中,我们增强了规则的自治和自适应能力。
规则自动重启策略
规则因各种原因出现异常时可能会停止运行,其中有些错误是可恢复的。eKuiper 1.8.0 提供了可配置的规则自动重启功能,使得规则失败后可以自动重试从而从可恢复的错误中恢复运行。
用户可配置全局的规则重启策略,也可以针对每个规则配置单独的重启策略。规则重启配置的选项包括:
- 重试次数
- 重试间隔
- 重试间隔系数,即重试失败后重试时间增加的倍数
- 最大重试间隔
- 随机重试延迟,防止多个规则总是在同一个时间点重试,造成拥塞
通过配置重试,可以在出现偶发错误时自动恢复,减少人工运维的需要。
数据导入导出
新版本中提供了 REST API 和 CLI 接口,用于导入导出当前 eKuiper 实例中的所有配置(流、表、规则、插件、源配置、动作配置、模式)。这样可以快速地备份配置或者移植配置到新的 eKuiper 实例中。导入导出的规则集为文本的 JSON 格式,可读性较强,也可以手工编辑。
- 导出配置的 rest 接口为
GET /data/export,通过此 API 可导出当前节点的所有配置 - 导出配置的 rest 接口为
POST /data/import,通过此 API 可导入已有配置至目标 eKuiper 实例中 - 如果导入的配置中包含插件(native)、静态模式(static schema)的更新,则需要调用接口
POST /data/import?stop=1 - 导入配置的状态统计可用
GET /data/import/status接口查看
Portable 插件热更新
相比原生插件,Portable 插件更加容易打包和部署,因此也有更多的更新需求。之前的版本中,Portable 插件更新后无法立即生效,需要手动重启使用插件的规则或者重启 eKuiper。eKuiper 1.8.0 中,插件更新后,使用插件的规则可无缝切换到新的插件实现中,减少运维工作。
版权声明: 本文为 EMQ 原创,转载请注明出处。
原文链接:https://www.emqx.com/zh/blog/ekuiper-v-1-8-0-release-notes
相关文章:
eKuiper 1.8.0 发布:零代码实现图像/视频流的实时 AI 推理
LF Edge eKuiper 是 Golang 实现的轻量级物联网边缘分析、流式处理开源软件,可以运行在各类资源受限的边缘设备上。eKuiper 的主要目标是在边缘端提供一个流媒体软件框架(类似于 Apache Flink )。eKuiper 的规则引擎允许用户提供基于 SQL 或基…...

[Ansible系列]ansible JinJia2过滤器
目录 一. JinJia2简介 二. JinJia2模板使用 2.1 在play中使用jinjia2 2.2 template模块使用 2.3 jinjia2条件语句 2.4 jinjia2循环语句 2.5 jinjia2过滤器 2.5.1 default过滤器 2.5.2 字符串操作相关过滤器 2.5.3 数字操作相关过滤器 2.5.4 列表操作…...

Cookie、Session、Token区分
一开始接触这三个东西,肯定会被绕的不知道都是干什么的。1、为什么要有它们?首先,由于HTTP协议是无状态的,所谓的无状态,其实就是 客户端每次想要与服务端通信,都必须重新与服务端连接,这就意味…...

回暖!“数”说城市烟火气背后
“人间烟火气,最抚凡人心”。在全国各地政策支持以及企业的积极生产运营下,经济、社会、生活各领域正加速回暖,“烟火气”在城市中升腾,信心和希望正在每个人心中燃起。 发展新阶段,高效统筹经济发展和公共安全&#…...

JS逆向-百度翻译sign
前言 本文是该专栏的第36篇,后面会持续分享python爬虫干货知识,记得关注。 有粉丝留言,近期需要做个翻译功能,考虑到百度翻译语言语种比较全面,但是它的参数被逆向加密了,对于这种情况需要怎么处理呢?所以本文以它为例。 废话不多说,跟着笔者直接往下看正文详细内容。…...
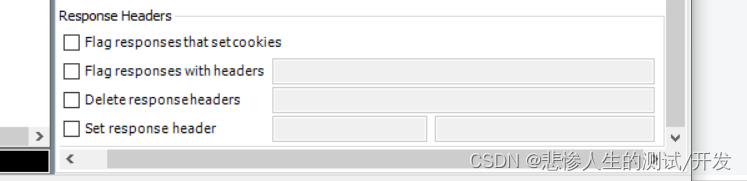
Fiddler抓包之Fiddler过滤器(Filters)调试
Filters:过滤器,帮助我们过滤请求。 如果需要过滤掉与测试项目无关的抓包请求,更加精准的展现抓到的请求,而不是杂乱的一堆,那功能强大的 Filters 过滤器能帮到你。 2、Filters界面说明 fiddler中的过滤 说明&#…...

【xib文件的加载过程 Objective-C语言】
一、xib文件的加载过程: 1.xib文件,是不是在这里啊: View这个文件夹里, 然后呢,我们加载xib是怎么加载的呢, 是不是在控制器里,通过我们这个类方法,加载xib: TestAppView *appView = [TestAppView appView]; + (instancetype)appView{NSBundle *rootBundle = [N…...

react setState学习记录
react setState学习记录1.总体看来2.setState的执行是异步的3.函数式setState1.总体看来 (1). setState(stateChange, [callback])------对象式的setState 1.stateChange为状态改变对象(该对象可以体现出状态的更改) 2.callback是可选的回调函数, 它在状态更新完毕、界面也更新…...

Docker容器cpu利用率问题
1.top原理 top 是读的/proc/stat文件 比如cat /proc/PID/stat 进程的总Cpu时间processCpuTime utime stime cutime cstime,该值包括其所有线程的cpu时间 某一进程Cpu使用率的计算 计算方法: 1 采样两个足够短的时间间隔的cpu快照与进程快照&…...

FreeRTOS入门(06):任务通知
文章目录目的基础说明使用演示作为二进制信号量作为计数信号量作为事件组作为队列或邮箱相关函数总结目的 任务通知(TaskNotify)是RTOS中相对常用的用于任务间交互的功能,这篇文章将对相关内容做个介绍。 本文代码测试环境见前面的文章&…...
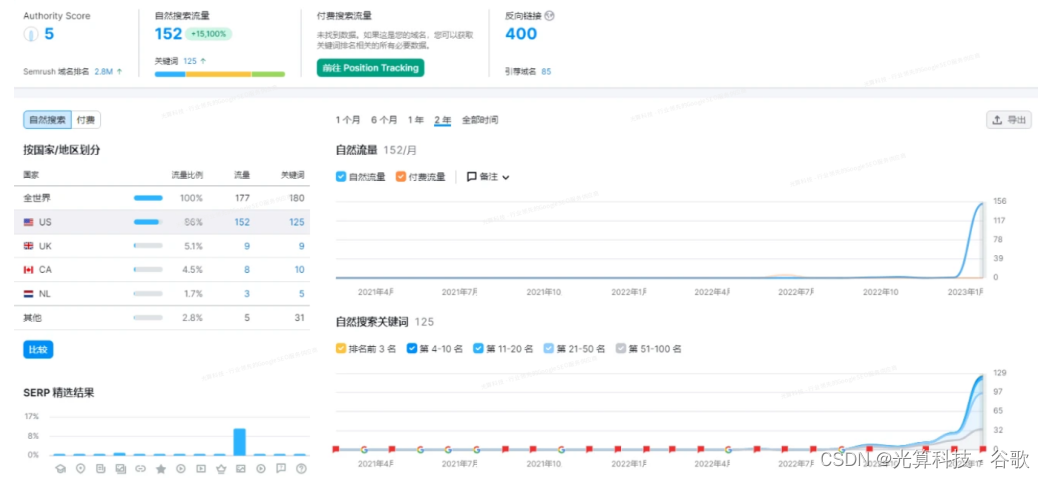
谷歌seo做的外链怎样更快被semrush识别
本文主要分享做谷歌seo外链如何能让semrush工具快速的记录并能查询到。 本文由光算创作,有可能会被剽窃和修改,我们佛系对待这种行为吧。 谷歌seo做的外链怎样更快被semrush识别? 答案是:多使用semrush搜索目标网站可加速爬虫抓…...

Java | IO 模式之 JavaBIO 应用
文章目录IO模型Java BIOJava NIOJava AIO(NIO.2)BIO、NIO、AIO的使用场景BIO1 BIO 基本介绍2 BIO 的工作机制3 BIO 传统通信实现3.1 业务需求3.2 实现思路3.3 代码实现4 BIO 模式下的多发和多收消息4.1 业务需求4.2 实现思路4.3 代码实现5 BIO 模式下接收…...

C语言学习及复习笔记-【18】C内存管理
18 C内存管理 C 语言为内存的分配和管理提供了几个函数。这些函数可以在 <stdlib.h> 头文件中找到。 序号函数和描述1void *calloc(int num, int size); 在内存中动态地分配 num 个长度为 size 的连续空间,并将每一个字节都初始化为 0。所以它的结果是分配了…...

linux--多线程(一)
文章目录Linux线程的概念线程的优点线程的缺点线程异常线程的控制创建线程线程ID以及进程地址空间终止线程线程等待线程分离线程互斥进程线程间的互斥相关概念互斥量mutex有线程安全问题的售票系统查看ticket--部分的汇编代码互斥量的接口互斥量实现原理探究可重入和线程安全常…...
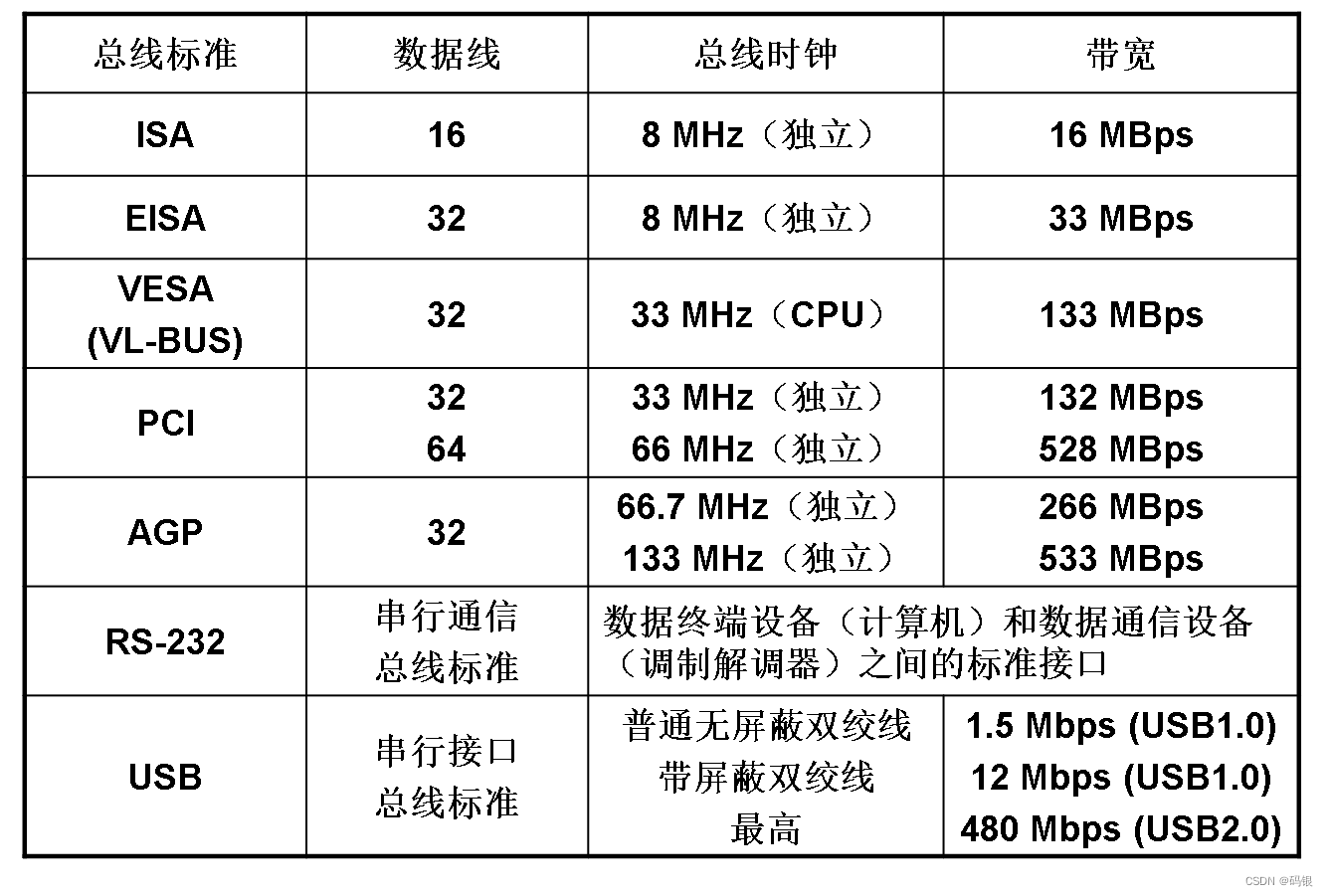
计算机组成原理(2.1)--系统总线
目录 一、总线基本知识 1.总线 2.总线的信息传送 3.分散连接图 4.注 二、总线结构的计算机举例 1.面向 CPU 的双总线结构框图 2.单总线结构框图 3.以存储器为中心的双总线结构框图 三、总线的分类 1.片内总线 2.系统总线 (板级总线或板间总线&#…...

C语言数组【详解】
数组1. 一维数组的创建和初始化1.1 数组的创建1.2 数组的初始化1.3 一维数组的使用1.4 一维数组在内存中的存储2. 二维数组的创建和初始化2.1 二维数组的创建2.2 二维数组的初始化2.3 二维数组的使用2.4 二维数组在内存中的存储3. 数组越界4. 数组作为函数参数4.1 冒泡排序函数…...

并行与体系结构会议
A类会议 USENIX ATC 2022: USENIX Annual Technical Conference(录用率21%) CCF a, CORE a, QUALIS a1 会议截稿日期:2022-01-06 会议通知日期:2022-04-29 会议日期:2022-07-11 会议地点:Carlsbad, Califo…...

【巨人的肩膀】JAVA面试总结(三)
1、💪 目录1、💪1、说说List, Set, Queue, Map 四者的区别1.1、List1.2、Set1.3、Map2、如何选用集合4、线程安全的集合有哪些?线程不安全的呢?3、为什么需要使用集合4、comparable和Comparator的区别5、无序性和不可重复性的含义…...
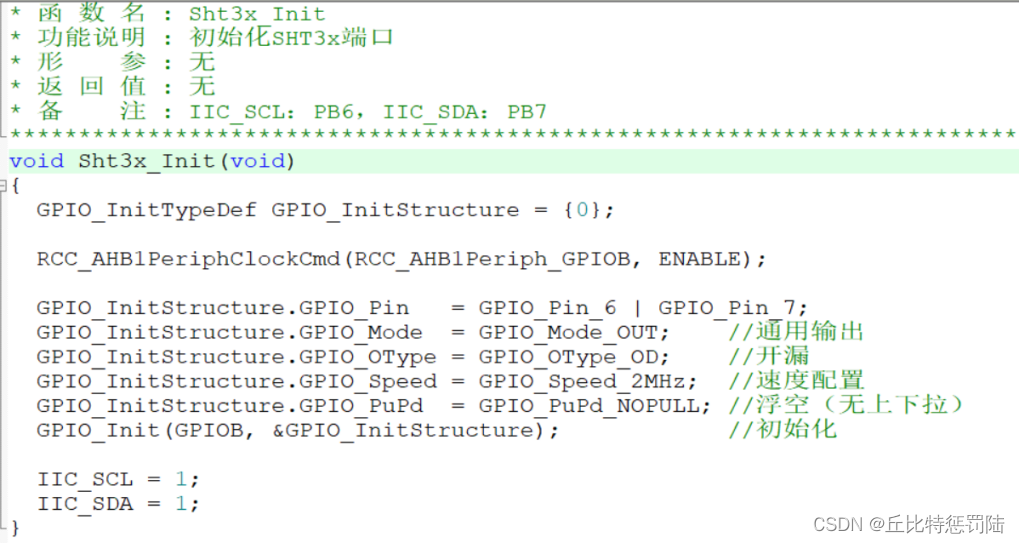
嵌入式 STM32 SHT31温湿度传感器
目录 简介 1、原理图 2、时序说明 数据传输 起始信号 结束信号 3、SHT31读写数据 SHT31指令集 读数据 温湿度转换 4、温湿度转换应用 sht3x初始化 读取温湿度 简介 什么是SHT31? 一主机多从机--通过寻址的方式--每个从机都有唯一的地址&…...

哪款蓝牙耳机打电话好用?打电话音质好的蓝牙耳机
现在几乎是人人离不开耳机的时代。在快节奏的生活和充满嘈杂声音的世界中,戴着耳机听歌,是每个人生活中最不可或缺的一段自由、放松的时光,下面小编就来分享几款通话音质好的蓝牙耳机。 一、南卡小音舱蓝牙耳机 动圈单元:13.3mm…...

DeepSeek API Gateway与大模型推理服务深度协同:如何实现Token级流控、异步响应封装、Streaming SSE自动保活?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek API Gateway架构全景与核心定位 DeepSeek API Gateway 是面向大模型服务的高性能、可扩展网关系统,承担请求路由、认证鉴权、流量控制、协议转换与可观测性聚合等关键职责。它并非…...

VCF 9.1 新特性:安装器与 Fleet Depot 支持 HTTP 无认证离线软件源
VMware Cloud Foundation(VCF)9.0 推出了统一软件仓库(Software Depot),支持连接博通在线源或企业内部离线源。但在 9.0 中,离线源默认必须使用 HTTPS 基础认证,即使关闭 HTTPS 也依然需要认证,对纯内网环境很不友好。在 VCF 9.1…...
)
MATLAB图像处理实战:用imfindcircles函数搞定工业零件瑕疵检测(附完整代码)
MATLAB图像处理实战:工业零件瑕疵检测的精准圆识别技术 在工业自动化质检领域,圆形特征的精准检测直接关系到产品质量控制的可靠性。轴承、垫片、齿轮等标准件上的孔洞缺失或尺寸偏差,往往预示着潜在的产品缺陷。传统人工检测不仅效率低下&am…...
)
NotebookLM深度绑定Google Drive的终极方案(含OAuth2作用域最小化清单+服务账号部署模板)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM深度绑定Google Drive的终极方案(含OAuth2作用域最小化清单服务账号部署模板) NotebookLM 本地知识增强能力依赖于安全、稳定且权限精确的 Google Drive 数据接入。直…...

AI建站多语言怎么做?先懂业务,再谈翻译
AI建站多语言怎么做?先懂业务,再谈翻译当同行还在卷“建站速度”时,聪明的出海商家已经开始卷“AI可见度”了。据近期行业数据显示,超过60%的海外采购商开始习惯使用ChatGPT、Perplexity等AI工具寻找供应商,而非传统的…...
:基于1726张A/B测试图谱验证的色阶偏移阈值与CMYK映射规则)
Midjourney蓝莓印相技术白皮书(2024V2.3权威修订版):基于1726张A/B测试图谱验证的色阶偏移阈值与CMYK映射规则
更多请点击: https://intelliparadigm.com 第一章:Midjourney Blueberry印相技术的演进脉络与核心定义 Midjourney Blueberry印相技术并非官方术语,而是社区对Midjourney V6中基于蓝光敏感通道(Blue Channel Emulation࿰…...

在MacBook Pro上构建工业物联网数据采集:libmodbus实战指南
1. 为什么选择MacBook Pro作为工业物联网开发平台 工业物联网开发通常需要频繁的现场调试和设备对接,传统工控机笨重且不便携。MacBook Pro凭借其出色的性能表现和稳定的macOS系统,正在成为工程师们的新宠。我去年参与一个智慧农业项目时,就深…...

BurstGPT:大语言模型驱动高性能计算,实现自然语言科学仿真
1. 项目概述:当大语言模型遇上高性能计算最近在AI和HPC(高性能计算)的交叉领域,一个名为BurstGPT的项目引起了我的注意。乍一看这个标题,你可能会觉得有点“缝合怪”的味道——Burst通常指代计算资源的突发式使用或高性…...
)
DIY红外热像仪进阶:手把手教你用C语言实现7种伪彩色编码(附完整代码)
DIY红外热像仪进阶:手把手教你用C语言实现7种伪彩色编码(附完整代码) 当32x24的温度矩阵在屏幕上呈现为单调的灰度图像时,你是否想过如何让它焕发生机?伪彩色编码技术正是打开这扇门的钥匙。本文将带你深入探索七种经…...

MTCNN级联网络设计精讲:从P-Net到O-Net,看作者如何用‘奇数特征图’和‘重叠池化’提升召回率
MTCNN级联网络架构解密:奇数特征图与重叠池化的工程智慧 人脸检测领域的技术演进始终围绕着两个核心命题:如何在有限计算资源下实现实时检测,以及如何在小目标场景中保持高召回率。2016年问世的MTCNN(Multi-task Cascaded Convol…...