Postgresql数据库运维统计信息
如果需要使用以下运维信息,需要如下几步
- 修改
postgresql.conf文件
#shared_preload_libraries = '' # (change requires restart)shared_preload_libraries = 'pg_stat_statements'
- 重启数据库
- 创建扩展
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
1. 统计信息的收集维度配置
1.1. 关键配置
- track_activities : 收集SQL执行开始时间以及SQL语句的内容,默认打开
- track_activity_query_size : 指定统计信息中允许存储的SQL长度,超出长度的SQL被截断,默认1024
- track_counts : 收集数据库的活动信息(如新增的行数和删除的行数等)
- track_io_timing : 收集IO操作的时间开销,因为需要不断的调用系统当前时间,所以某些系统中会带来极大的开销,从而带来极大的负面影响。
- track_functions : 跟踪函数的调用次数和时间开销
- update_process_title : 每次服务端process接收到新的SQL时更新command状态。
- log_statement_stats (boolean) – 类似unix的getrusage()操作系统函数, 用于收集SQL语句级的资源开销统计. 包含以下3种层面的 全部. 因此配置了log_statement_stats就不需要配置以下选项.
- log_parser_stats (boolean) – 同上, 但是只包含SQL parser部分的资源开销统计.
- log_planner_stats (boolean) – 同上, 但是只包含SQL planner部分的资源开销统计.
- log_executor_stats (boolean) – 同上, 但是只包含SQL executor部分的资源开销统计.
1.2 其他配置

| 字段名 | 字段类型 | 字段信息描述 |
|---|---|---|
| pg_stat_get_backend_idset() | setof integer | 当前活动后端ID号的集合(从1到活动后端数量) |
| pg_stat_get_backend_activity(integer) | text | 此后端最近查询的文本 |
| pg_stat_get_backend_activity_start(integer) | timestamp with time zone | 最近一次查询开始的时间 |
| pg_stat_get_backend_client_addr(integer) | inet | 与此后端连接的客户端的IP地址 |
| pg_stat_get_backend_client_port(integer) | integer | 客户端用于通信的TCP端口号 |
| pg_stat_get_backend_dbid(integer) | oid | 此后端所连接的数据库的OID |
| pg_stat_get_backend_pid(integer) | integer | 后端进程ID |
| pg_stat_get_backend_start (integer) | timestamp with time zone | 此过程开始的时间 |
| pg_stat_get_backend_userid(integer) | oid | 登录到该后端用户的OID |
| pg_stat_get_backend_waiting(integer) | boolean | 如果此后端当前正在等待锁,则为True |
| pg_stat_get_backend_xact_start(integer) | timestamp with time zone | 如果此后端当前正在等待锁,则为True |
2. 常用的监控数据库活动的sql
2.1. 调用次数倒序输出
select * from pg_stat_statements order by calls desc limit 1 offset 0;

2.2. 单次SQL执行时间倒序输出
select * from pg_stat_statements order by total_exec_time/calls desc limit 10 offset 0;

2.3. 按shared buffer “未命中块读” 倒序输出
select * from pg_stat_statements order by shared_blks_read desc limit 10 offset 0;

2.4. 获取CPU time Top20的统计结果
export PGPORT=1921
export PGDATA=/data01/pgdata/1921/pg_root
export LANG=en_US.utf8
export PGHOME=/opt/pgsql
export LD_LIBRARY_PATH=$PGHOME/lib:/lib64:/usr/lib64:/usr/local/lib64:/lib:/usr/lib:/usr/local/lib
export DATE=`date +"%Y%m%d%H%M"`
export PATH=$PGHOME/bin:$PATH:.
export PGHOST=$PGDATA
export PGDATABASE=postgres
psql -A -x -c "select row_number() over() as rn, * from (select query,' calls:'||calls||' total_exec_time_s:'||round(total_exec_time::numeric,2)||' avg_time_ms:'||round(1000*(total_exec_time::numeric/calls),2) as stats from pg_stat_statements order by total_exec_time desc limit 20) t;" >/tmp/stat_query.log 2>&1
echo -e "$DATE avcp TOP20 query report yest"|mutt -s "$DATE avcp TOP20 query report yest" -a /tmp/stat_query.log digoal@126.com
psql -c "select pg_stat_statements_reset()
crontab -e1 8 * * * /home/postgres/script/report.sh

2.5. 查看数据库级统计信息
如数据库的 事务提交次数, 回滚次数, 未命中数据块读, 命中读, 行的统计信息(扫描, 输出,插入,更新,删除), 临时文件, 死锁, IOTIME等统计信息.
select tup_returned,tup_fetched from pg_stat_database where datname ='generalquery_frame';

| 字段名 | 字段类型 | 字段信息描述 |
|---|---|---|
| datid | id | 数据库OID |
| dataname | name | 数据库Name |
| numbackends | integer | 当前连接到此数据库的后端数量。这是该视图中唯一返回反映当前状态的值的列;所有其他列返回自上次重置以来的累积值 |
| xact_commit | bigint | 此数据库中已提交的事务数 |
| xact_rollback | bigint | 此数据库中已回滚的事务数 |
| blks_read | bigint | 在此数据库中读取的磁盘块数目 |
| blks_hit | bigint | 磁盘块已经在缓冲缓存中被发现的次数,因此不需要读取(这只包括在PostgreSQL缓冲区中的命中)缓存,而不是操作系统的文件系统缓存) |
| tup_returned | bigint | 在此数据库中查询返回的行数 |
| tup_fetched | bigint | 在此数据库中查询获取的行数 |
| tup_inserted | bigint | 查询在此数据库中插入的行数 |
| tup_updated | bigint | 此数据库中查询更新的行数 |
| tup_deleted | bigint | 查询在此数据库中删除的行数 |
| conflicts | bigint | 由于与此数据库中的恢复冲突而取消的查询数。冲突只发生在备用服务器上;参见pa_stat_database_conflicts获取细节。) |
| temp_files | bigint | 查询在此数据库中创建的临时文件数。所有临时文件都会被计算在内,而不管临时文件是为什么创建的(例如:排序或散列),而不考虑日志临时文件的设置。 |
| temp_bytes | bigint | 在此数据库中查询写入临时文件的数据总量。所有临时文件都会被计算在内,而不管临时文件的原因是什么创建,而不考虑日志临时文件设置。 |
| deadlocks | bigint | 在此数据库中检测到的死锁数目 |
| blk_read_time | double precision | 后端在此数据库中读取数据文件块所花费的时间,以毫秒为单位 |
| blk_write_time | double precision | 后端在此数据库中写入数据文件块所花费的时间,以毫秒为单位 |
| stats_reset | timestamp_with | 这些统计数据最后重置的时间 |
2.6. 查看表级统计信息
区分全表扫描和索引扫描的次数和输出的行, 以及DML的行数, 评估的当前活动行数和垃圾行数

| 字段名 | 字段类型 | 字段信息描述 |
|---|---|---|
| relid | id | 数据库OID |
| schemaname | name | 该表所在的模式名称 |
| relname | name | 该表的名称 |
| heap_blks_read | bigint | 从该表中读取的磁盘块数量 |
| heap_blks_hit | bigint | 该表中的缓冲区命中数 |
| idx_blks_read | bigint | 从该表的所有索引中读取的磁盘块数 |
| idx_blks_hit | bigint | 该表上所有索引中的缓冲区命中数 |
| toast_blks_read | bigint | 从该表的TOAST表中读取的磁盘块数量(如果有的话) |
| toast_blks_hit | bigint | 该表的TOAST表中的缓冲区命中次数(如果有的话) |
| tidx_blks_read | bigint | 从该表的TOAST表索引中读取的磁盘块数量(如果有的话) |
| tidx_blks_hit | bigint | 该表的TOAST表索引中的缓冲区命中数(如果有的话) |
2.7. 查看索引级统计信息

| 字段名 | 字段类型 | 字段信息描述 |
|---|---|---|
| relid | oid | 索引表的OID |
| indexrelid | oid | 该索引的OID |
| schemaname | name | 此索引所在的模式的名称 |
| relname | name | 此索引的表名 |
| indexrelname | name | 该索引的名称 |
| idx_scan | bigint | 在该索引上启动的索引扫描次数 |
| idx_tup_read | bigint | 扫描该索引返回的索引条目数 |
| idx_tup_fetch | bigint | 使用该索引进行简单索引扫描获取的活动表行数 |
2.8. 表的IO级统计信息
如heap主存储的块读(区分未命中shared buffer和命中shared buffer的统计)

| 字段名 | 字段类型 | 字段信息描述 |
|---|---|---|
| relid | oid | 表的OID |
| schemaname | name | 该表所在的模式名称 |
| relname | name | 该表的名称 |
| heap_blks_read | bigint | 从该表中读取的磁盘块数量 |
| heap_blks_hit | bigint | 该表中的缓冲区命中数 |
| idx_blks_read | bigint | 从该表的所有索引中读取的磁盘块数 |
| idx_blks_hit | bigint | 该表上所有索引中的缓冲区命中数 |
| toast_blks_read | bigint | 从该表的TOAST表中读取的磁盘块数量(如果有的话) |
| toast_blks_hit | bigint | 该表的TOAST表中的缓冲区命中次数(如果有的话) |
| tidx_blks_read | bigint | 从该表的TOAST表索引中读取的磁盘块数量(如果有的话) |
| tidx_blks_hit | bigint | 该表的TOAST表索引中的缓冲区命中数(如果有的话) |
2.9. 索引的IO级统计信息
索引的块读(区分未命中shared buffer和命中shared buffer的统计)

| 字段名 | 字段类型 | 字段信息描述 |
|---|---|---|
| relid | oid | 索引表的OID |
| indexrelid | oid | OID of this index |
| schemaname | name | 该索引的OID |
| relname | name | 此索引的表名 |
| indexrelname | name | 该索引的名称 |
| idx_blks_read | bigint | 从该索引读取的磁盘块数目 |
| idx_blks_hit | bigint | 这个索引中的缓冲区命中数 |
2.10. 序列的IO级统计信息
序列的块读(区分未命中shared buffer和命中shared buffer的统计)

| 字段名 | 字段类型 | 字段信息描述 |
|---|---|---|
| relid | oid | 序列的OID |
| schemaname | name | 此序列所在的模式名称 |
| relname | name | 这个序列的名称 |
| blks_read | bigint | 从这个序列中读取的磁盘块的数目 |
| blks_hit | bigint | 这个序列中缓冲区命中的次数 |
2.11. , 函数的统计信息
调用次数, 总的时间开销.
必须要先打开track_functions参数.

| 字段名 | 字段类型 | 字段信息描述 |
|---|---|---|
| funcid | oid | 函数的OID |
| schemaname | name | 此函数所在的模式名称 |
| funcname | name | 此函数的名称 |
| calls | bigint | 这个函数被调用的次数 |
| total time | double precision | 在这个函数和它调用的所有其他函数中花费的总时间,以毫秒为单位 |
| self_time | double precision | 在这个函数本身中花费的总时间,不包括它调用的其他函数,以毫秒为单位 |
相关文章:
Postgresql数据库运维统计信息
如果需要使用以下运维信息,需要如下几步 修改postgresql.conf文件 #shared_preload_libraries # (change requires restart)shared_preload_libraries pg_stat_statements重启数据库创建扩展 CREATE EXTENSION IF NOT EXISTS pg_stat_statements;1. 统计信息…...
Python3基础
导包 在 python 用 import 或者 from...import 来导入相应的模块。 将整个模块(somemodule)导入,格式为: import somemodule 从某个模块中导入某个函数,格式为: from somemodule import somefunction 从某个模块中导入多个函数,格式为&#…...
【性能测试】服务器常用的性能指标总结,一文概全...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 压测过程中&#…...

Vue学习笔记-Vuex基本使用
基本使用 初始化数据、配置actions、mutations,操作文件/store/index.js //index.js文件用于创建Vuex中最为核心的store对象 import Vue from vue import Vuex from vuex Vue.use(Vuex) //actions对象用于响应组件中的动作,专门负责业务逻辑 const actions {//函数…...
vue3中的customRef创建一个自定义的 ref对象
customRef 创建一个自定义的 ref,并对其依赖项跟踪和更新触发进行显式控制 小案例: 自定义 ref 实现 debounce <template><div style"font-size: 14px;"><input v-model"text" placeholder"搜索关键字"/><…...
动态规划学习——子序列问题
目录 编辑 一,最长定差子序列 1.题目 2,题目接口 3,解题思路及其代码 一,最长定差子序列 1.题目 给你一个整数数组 arr 和一个整数 difference,请你找出并返回 arr 中最长等差子序列的长度,该子序列…...

使用 COPY 加速 PostgreSQL 批量插入
文章目录 1.copy命令介紹2.copy vs insert的优势3.测量性能4.结论 1.copy命令介紹 PostgreSQL 中的命令COPY是执行批量插入和数据迁移的强大工具。它允许快速有效地将大量数据插入表中。 COPY命令为批量插入和数据迁移提供了更简单且更具成本效益的解决方案。 可以避免使用诸…...
plotneuralnet和netron结合绘制模型架构图
plotneuralnet和netron结合绘制模型架构图 一、plotneuralnet 本身的操作 模型结构图的可视化,能直观展示模型的结构以及各个模块之间的关系。最近借助plotneuralnet python库(windows版)绘制了一个网络结构图,有一些经验和心得…...

MYSQL 中如何导出数据?
文章目录 前言MySQL 导出数据使用 SELECT ... INTO OUTFILE 语句导出数据SELECT ... INTO OUTFILE 语句有以下属性:导出表作为原始数据导出SQL格式的数据将数据表及数据库拷贝至其他主机 后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:…...
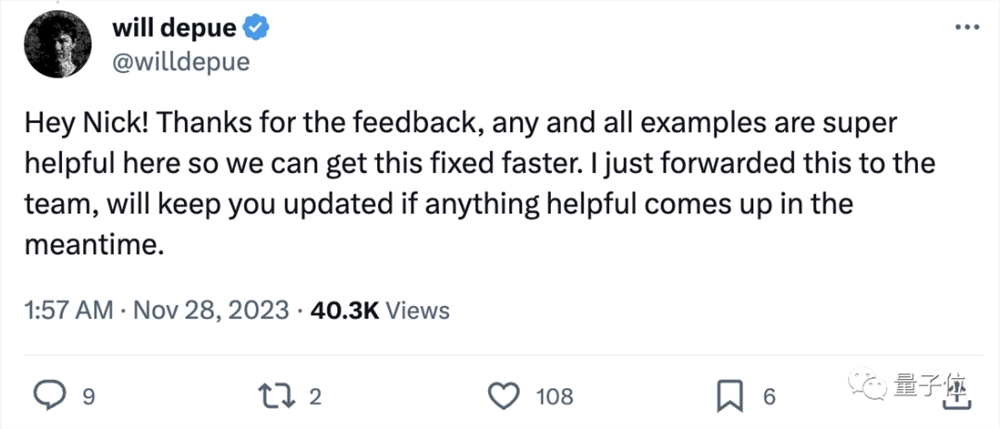
GPT-4惨遭削弱,偷懒摸鱼绝不多写一行代码,OpenAI已介入调查
GPT-4再次遭网友“群攻”,原因是“懒”得离谱! 有网友想在Android系统开发一个能够与OpenAI API实时交互的应用。 于是把方法示例链接发给GPT-4,让它参考用Kotlin语言编写代码: 没成想,和GPT-4一来二去沟通半天,GPT-4死活给不出…...

CSS特效020:涌动的弹簧效果
CSS常用示例100专栏目录 本专栏记录的是经常使用的CSS示例与技巧,主要包含CSS布局,CSS特效,CSS花边信息三部分内容。其中CSS布局主要是列出一些常用的CSS布局信息点,CSS特效主要是一些动画示例,CSS花边是描述了一些CSS…...

系列五、Spring整合MyBatis不忽略mapper接口同目录的xxxMapper.xml
一、概述 默认情况下maven要求我们将xml配置、properties配置等都放在resources目录下,如果我们强行将其放在java目录,即将xxxMapper.xml和xxxMapper接口放在同一个目录下,那么默认情况下maven打包时会将这个xxxMapper.xml文件忽略掉…...

第454题.四数相加II
力扣题目链接 给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 < i, j, k, l < nnums1[i] nums2[j] nums3[k] nums4[l] 0 分析: 当需要判断一个元素是…...
RabbitMQ消息队列
简介 MQ(message queue),从字面意思上看就个 FIFO 先入先出的队列,只不过队列中存放的内容是 message 而已,它是一种具有接收数据、存储数据、发送数据等功能的技术服务。 作用:流量削峰、应用解耦、异步处理。 生产者将消息发送…...

ModBus电表与RS485电表有哪些区别?
在能源计量领域,ModBus电表和RS485电表是两种常见的设备,它们都具有监测和记录电能数据的功能。然而,它们之间存在一些区别,比如通信协议、连接方式、数据格式等等参数的区别有哪些? ModBus电表和RS485电表都是用于电能…...
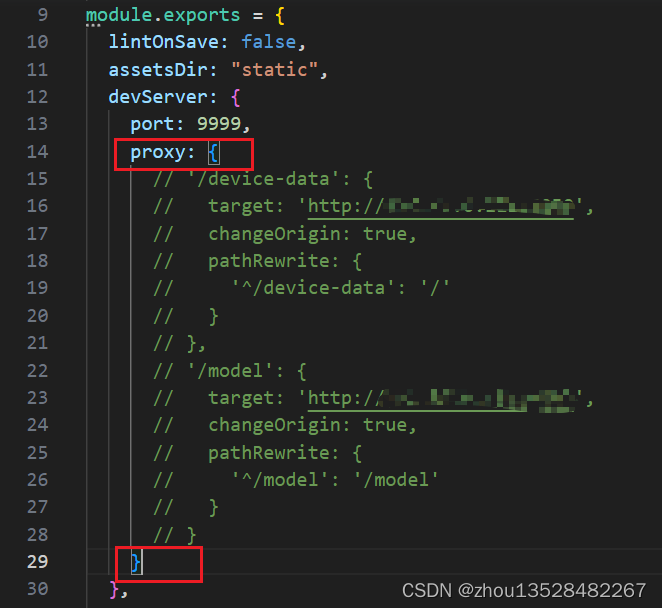
vue项目运行时,报错:ValidationError: webpack Dev Server Invalid Options
在运行vue项目中,遇到报错:ValidationError: webpack Dev Server Invalid Options,如下图截图: 主要由于vue.config.js配置文件错误导致的,具体定位到proxy配置代理不能为空,导致运行项目报错,需…...

书摘:C 嵌入式系统设计模式 02
本书的原著为:《Design Patterns for Embedded Systems in C ——An Embedded Software Engineering Toolkit 》,讲解的是嵌入式系统设计模式,是一本不可多得的好书。 本系列描述我对书中内容的理解。 结构化编程将软件组织成两个截然不同的…...

排序算法基本原理及实现1
📑打牌 : da pai ge的个人主页 🌤️个人专栏 : da pai ge的博客专栏 ☁️宝剑锋从磨砺出,梅花香自苦寒来 📑插入排序 Ǵ…...
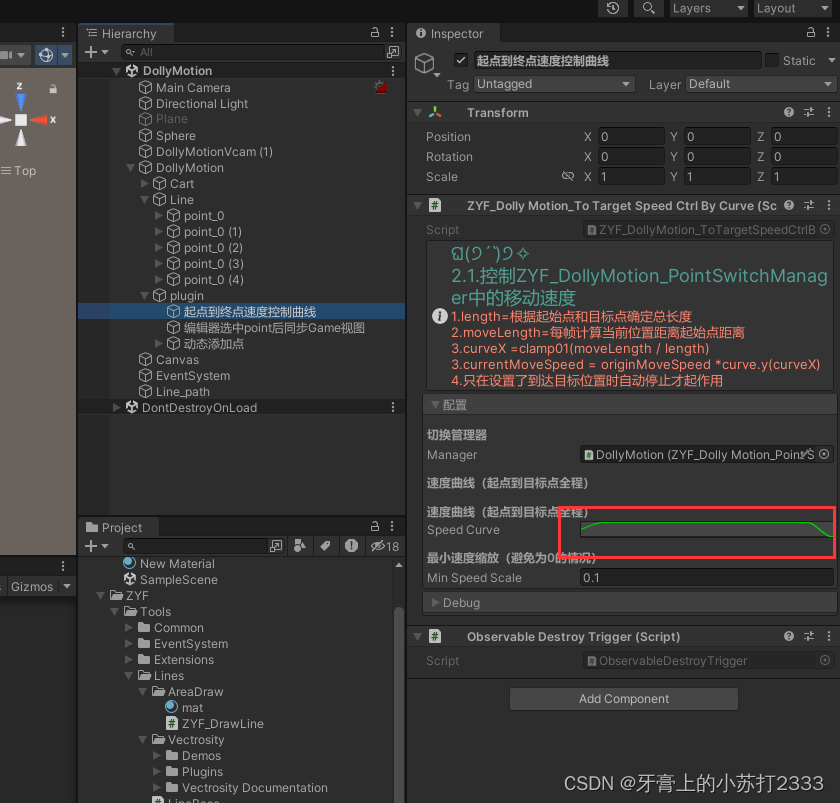
Unity 轨道展示系统(DollyMotion)
DollyMotion 🍱功能展示🥙使用💡设置路径点💡触发点位切换💡动态更新路径点💡事件触发💡设置路径💡设置移动方案固定速度方向最近路径方向 💡设置移动速度曲线 传送门 &a…...
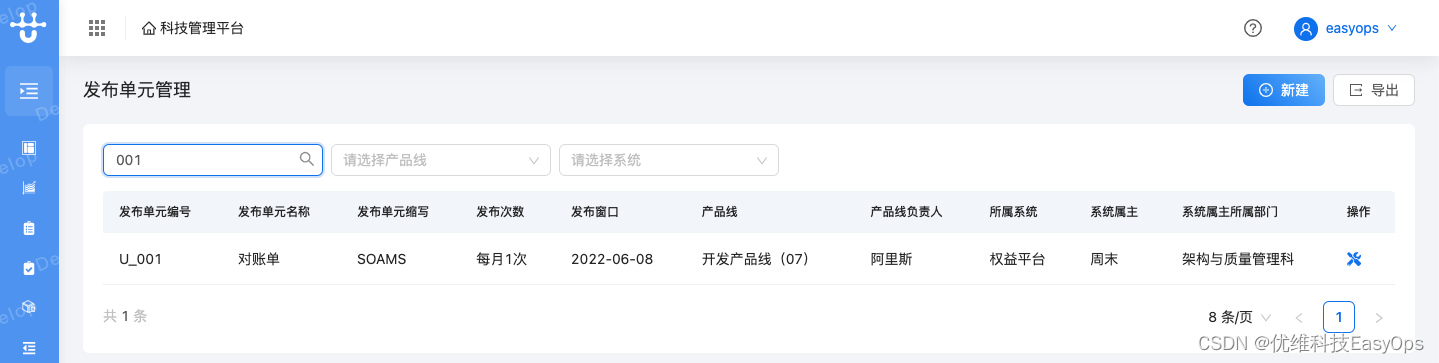
优维低代码实践:搜索功能
优维低代码技术专栏,是一个全新的、技术为主的专栏,由优维技术委员会成员执笔,基于优维7年低代码技术研发及运维成果,主要介绍低代码相关的技术原理及架构逻辑,目的是给广大运维人提供一个技术交流与学习的平台。 优维…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

嵌入式快速原型开发:基于Sceptre平台与LPC2148的实战指南
1. 项目概述:Sceptre,一个被低估的嵌入式快速原型利器 在嵌入式开发的世界里,我们总是在寻找那个“刚刚好”的平台:它要足够强大,能跑复杂的算法;要足够小巧,能塞进各种外壳;要足够便…...
)
CentOS 8.5最小化安装后,这5个必做的安全与效率优化设置(附一键脚本)
CentOS 8.5最小化安装后的5个必做安全与效率优化刚完成CentOS 8.5最小化安装的系统就像一张白纸——干净但缺乏生产力。作为运维老手,我见过太多人跳过基础优化直接部署应用,结果在后续使用中频繁遇到权限混乱、软件安装慢、SSH爆破等问题。本文将分享我…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...
)
Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环)
更多请点击: https://kaifayun.com 第一章:Lovable内部工具开发方法论(从需求黑洞到用户自发推广的完整闭环) Lovable 方法论的核心不是交付功能,而是培育“工具依赖感”——当一线工程师在凌晨三点调试线上问题时&am…...

Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案
Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 厌倦了繁琐的Switch游戏安…...

软件测试行业的未来趋势:这3类测试将成为主流
随着数字化转型的深入推进,软件已经成为驱动各行业变革的核心生产力,从自动驾驶汽车到企业级云原生平台,从智慧医疗设备到工业互联网系统,软件的复杂度、规模和对安全性的要求都在呈指数级增长。作为软件质量保障的核心环节&#…...

Actor Framework里的“多米诺骨牌”:一个错误如何让整个嵌套操作者链崩溃?
Actor Framework中的“多米诺效应”:如何避免嵌套操作者链的崩溃 在分布式系统设计中,Actor模型因其天然的并发处理能力而备受青睐。LabVIEW的Actor Framework(AF)通过操作者(actor)的嵌套结构,为复杂系统提供了模块化解决方案。然而&#x…...