python实现rpc的几种方式(SimpleXMLRPCServer 自带的、第三方ZeroRPC)、连接linux远程开发分布式锁、分布式id
1 python实现rpc的几种方式
1.1 SimpleXMLRPCServer 自带的
1.2 第三方ZeroRPC
2 连接linux远程开发
3 分布式锁
4 分布式id
1 python实现rpc的几种方式
# 远程过程调用-1 借助于rabbitmq,可以跨语言-2 SimpleXMLRPCServer 自带的-3 ZeroRPC-4 GRPC:跨语言的 https://zhuanlan.zhihu.com/p/425725192
1.1 SimpleXMLRPCServer 自带的
### 服务端
from xmlrpc.server import SimpleXMLRPCServer# 通信使用xml格式
class RPCServer(object):def add(self,a,b):return a+b# SimpleXMLRPCServer
server = SimpleXMLRPCServer(('localhost', 4242), allow_none=True)
server.register_introspection_functions()
server.register_instance(RPCServer())
server.serve_forever()#### 客户端
import time
from xmlrpc.client import ServerProxy# rpc 调用和http什么关系
'''
1 rpc 不是一种协议,它是一个概念:远程过程调用的概念,中间通过网络,底层可以基于tcp,也可以基于http,基于tcp自定制协议
2 有的rpc框架用了http协议
2 有的rpc框架直接使用tcp'''
# SimpleXMLRPCServer 底层使用了http协议,速度稍微慢一些
def xmlrpc_client():print('xmlrpc client')c = ServerProxy('http://localhost:4242')res=c.add(3,4)print('通过rpc执行结果是:',res)if __name__ == '__main__':xmlrpc_client()# 速度慢: 1 基于http 2 交互使用的xml格式1.2 第三方ZeroRPC
### 服务端
import zerorpcclass RPCServer(object):def add(self,a,b):print('a+b',a+b)return a+b
# zerorpc
s = zerorpc.Server(RPCServer())
s.bind('tcp://0.0.0.0:4243')
s.run()#### 客户端
import zerorpc
import time# zerorpc
def zerorpc_client():print('zerorpc client')c = zerorpc.Client()c.connect('tcp://127.0.0.1:4243')print(c.add(88, 77))if __name__ == '__main__':zerorpc_client()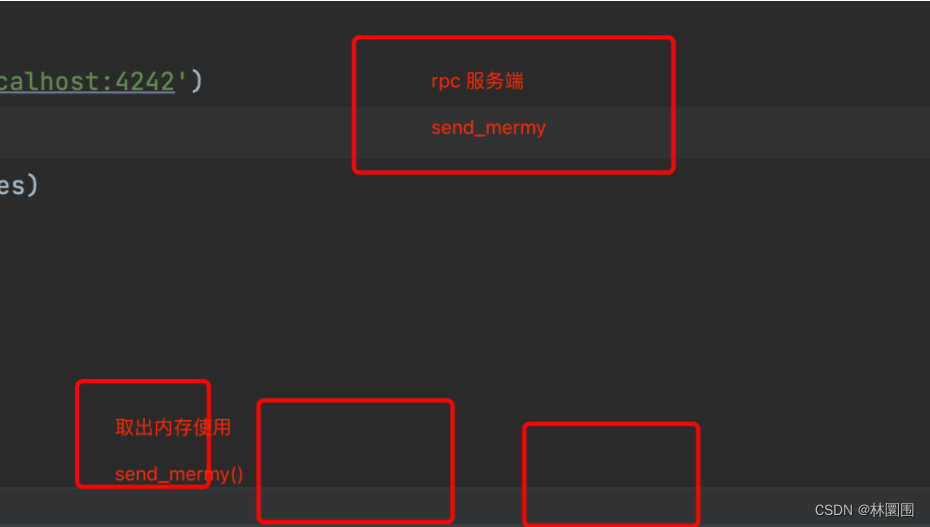
2 连接linux远程开发
# 咱么开发的环境-1 win 开发,linux上线-2 linux开发,Linux上线-乌班图-》台式机--》装乌班图--》乌班图开发-3 mac系统,linux上线-mac环境跟linxu很像# 只有win机器,没有linux,项目要在linux下开发---》远程连接到linux中开发---》解释器用了远程linux的# 使用pycharm远程连接linxu开发-本地代码传到linux-使用linux的解释器运行代码---》配置远端解释器-以后 在本地右键运行,实际上等同于,连到linux机器,执行# win---》远端docker容器中开发
3 分布式锁
# 分布式系统中加锁---》悲观锁-mysql 行锁 性能不高-性能更高的分布式锁# python 线程锁# 分布式锁具备条件
1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
2、高可用的获取锁与释放锁;
3、高性能的获取锁与释放锁;
4、具备可重入特性;
5、具备锁失效机制,防止死锁;
6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败# 三种方式实现
基于数据库实现分布式锁---》行锁
基于缓存(Redis等)实现分布式锁;----redis官方提供
基于Zookeeper实现分布式锁:分布式协调服务
# pip3 install redlock-py
from redlock import Redlock
import time
dlm = Redlock([{"host": "localhost", "port": 6379, "db": 0}, ])# 获得锁
my_lock = dlm.lock("my_resource_name",1000)# 业务逻辑代码
print('sdfasdf')
time.sleep(20)# 释放锁
dlm.unlock(my_lock)# 这个代码可以放在任意的节点上,使用的是分布式锁,某个节点获取到锁后,别的节点获取不到,操作数据,释放锁后,别的节点的线程才能操作数据
3.1 自己基于redis实现分布式锁
# redis 分布式锁底层如何实现的SETNX:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做expire:超过这个时间锁会自动释放,避免死锁delete:Redis实现分布式锁的时候删除锁import redis
import uuid
import timefrom threading import Thread,get_ident# 连接redis
redis_client = redis.Redis(host="localhost",port=6379,# password=password,db=10)# 获取一个锁
# lock_name:锁定名称
# acquire_time: 客户端等待获取锁的时间
# time_out: 锁的超时时间
def acquire_lock(lock_name, acquire_time=10, time_out=10):"""获取一个分布式锁"""identifier = str(uuid.uuid4())end = time.time() + acquire_timelock = "string:lock:" + lock_namewhile time.time() < end:if redis_client.setnx(lock, identifier):# 给锁设置超时时间, 防止进程崩溃导致其他进程无法获取锁redis_client.expire(lock, time_out)return identifierelif not redis_client.ttl(lock):redis_client.expire(lock, time_out)time.sleep(0.001)return False# 释放一个锁
def release_lock(lock_name, identifier):"""通用的锁释放函数"""lock = "string:lock:" + lock_namepip = redis_client.pipeline(True)while True:try:pip.watch(lock)lock_value = redis_client.get(lock)if not lock_value:return Trueif lock_value.decode() == identifier:pip.multi()pip.delete(lock)pip.execute()return Truepip.unwatch()breakexcept redis.excetions.WacthcError:passreturn Falsedef seckill():identifier = acquire_lock('resource')print(get_ident(), "获得了锁")release_lock('resource', identifier)if __name__ == '__main__':for i in range(50):t = Thread(target=seckill)t.start()4 分布式id
# 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识# 分布式id特点全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。 # uuid 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。# 生成分布式锁方案
-uuid :import timeimport uuidres=uuid.uuid1(2,int(time.time())) # b5503ec0-42ff-11ee-adb4-000000000002print(res)-数据自增:性能第-Redis生成ID时间戳+incr-snowflake(雪花算法)方案:pysnowflake雪花算法的使用场景就很明确了,用于确保全局唯一的id。还有一个从名字无法看出的特点就是,还能保证id的自增属性。Snowflake 以 64 bit 来存储组成 ID 的4 个部分:
1、最高位占1 bit,值固定为 0,以保证生成的 ID 为正数;
2、中位占 41 bit,值为毫秒级时间戳;
3、中下位占 10 bit,值为工作机器的 ID,值的上限为 1024;
4、末位占 12 bit,值为当前毫秒内生成的不同 ID,值的上限为 4096;-美团leaf算法
相关文章:
python实现rpc的几种方式(SimpleXMLRPCServer 自带的、第三方ZeroRPC)、连接linux远程开发分布式锁、分布式id
1 python实现rpc的几种方式 1.1 SimpleXMLRPCServer 自带的 1.2 第三方ZeroRPC 2 连接linux远程开发 3 分布式锁 4 分布式id 1 python实现rpc的几种方式 # 远程过程调用-1 借助于rabbitmq,可以跨语言-2 SimpleXMLRPCServer 自带的-3 ZeroRPC-4 GRPC:跨语言的 htt…...

ARM麒麟V10 auditctl启动失败处理
问题: 业务服务器需要启用审计服务,但是启动审计服务失败,查看状态提示audit0。 修改配置文件/boot/efi/EFI/kylin/grub.cfg 删除audit0,或者设置audit1。 重启服务器后验证状态。 auditctl -D echo "-w /data -p rwxa"…...

day67
今日回内容 视图层 响应对象 cbv和fbv 上传文件 模板层 视图层 一、响应对象 响应对象的本质都是 HttpResponse HttpResponse:字符串 render: 将一个模板页面中的模板语法进行渲染,最终渲染成一个html页面作为响应体。 redirect:重定向 …...
04:2440---内存控制器
目录 一:介绍 1:引入 2:概念 3:通信 A:片选信号 B:片选信号的地址空间范围 4:地址线 A:不同位数的接法 B:访问原理 C:访问地址 5:时序 1:NOR FLASH A:2440NOR FLASH时序 B:原理/时序图 C:寄存器 6:SDARM A:访问方式 B:原理图 C:BWSCON D:BANKCON…...

【深度学习】CNN中pooling层的作用
1、pooling是在卷积网络(CNN)中一般在卷积层(conv)之后使用的特征提取层,使用pooling技术将卷积层后得到的小邻域内的特征点整合得到新的特征。一方面防止无用参数增加时间复杂度,一方面增加了特征的整合度…...
基于H1ve一分钟搭好CTF靶场
写在前面 ◉ ‿ ◉ 上一篇文章给大家详细介绍了基于H1ve搭建CTF靶场,以及过程中可能遇到的报错及解决方法,那么这篇文章,我总结了一下,将不会遇到报错的方法给到大家,但是前提是你的服务器最好是一个全新的哦~~~ 我…...

网络篇---第五篇
系列文章目录 文章目录 系列文章目录前言一、如何实现跨域?二、TCP 为什么要三次握手,两次不行吗?为什么?三、说一下 TCP 粘包是怎么产生的?怎么解决粘包问题的?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站…...

Git——Git应用入门
将会介绍以下知识: 搭建Git环境和创建Git版本库(init、clone)。文件添加、状态检查、创建注释和查看历史记录。与其他Git版本库交互(pull、push)。解决合并冲突。创建分支列表、列表切换和合并。创建标签。 1、版本控…...
【SpringBoot】Redisson 分布式锁注解和 @Transactional 注解一起使用问题
一、前言 平时使用切面去加分布式锁,是先开启事务还是先尝试获得锁?这两者有啥区别? 业务中怎么控制切面的顺序?切面的顺序对事务的影响怎么避免? 下面程序分析: OverrideTransactionalpublic ReceiveH5…...

Druid数据库连接池框架
1.Druid概述 Druid 是一个开源的数据库连接池框架,用于管理和优化数据库连接的使用。它提供了高效的、可扩展的连接池管理,可以用于 Java 应用程序连接到关系型数据库。 之前有了解过 C3P0 数据库连接池,所谓数据库连接池就是重复利用连接数据…...

Python项目打包
Python项目如何打包? 本指南总结了Python项目打包的最佳实践,主要涉及代码的打包和分发,以及环境和依赖的管理。 0. 一般项目清单 源代码(可使用git托管)数据包(可使用DVC托管)Docker环境镜像…...
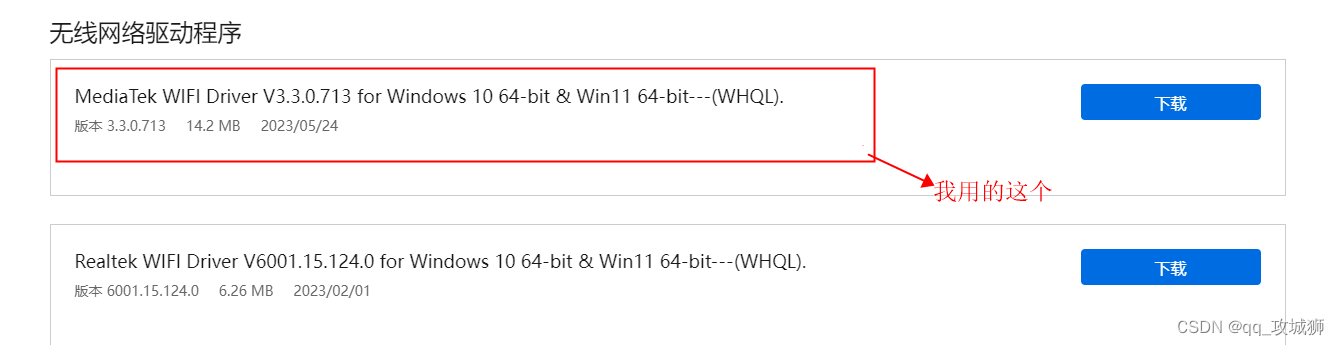
ASUS(华硕) B760M-AYW WIFI D4_解决wifi不能使用
1、最近新购买了一套 diy电脑主机,选用的是 ASUS B760M-AYW WIFI D4电脑主板 win10 系统,到货后 发现右下角电脑图标处及网络适配器中 没有wifi选项 首先 在官网和旗舰店客服处,确认了 该主板 有集成wifi模块,鲨鱼鳍天线未安装…...

Postgresql数据库运维统计信息
如果需要使用以下运维信息,需要如下几步 修改postgresql.conf文件 #shared_preload_libraries # (change requires restart)shared_preload_libraries pg_stat_statements重启数据库创建扩展 CREATE EXTENSION IF NOT EXISTS pg_stat_statements;1. 统计信息…...
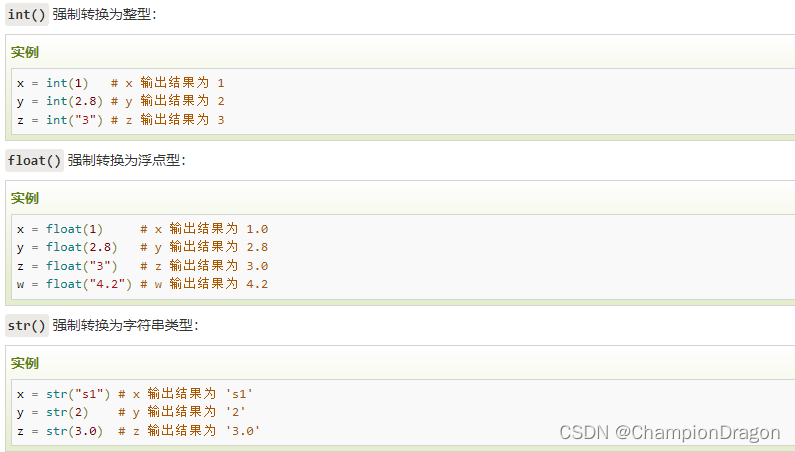
Python3基础
导包 在 python 用 import 或者 from...import 来导入相应的模块。 将整个模块(somemodule)导入,格式为: import somemodule 从某个模块中导入某个函数,格式为: from somemodule import somefunction 从某个模块中导入多个函数,格式为&#…...
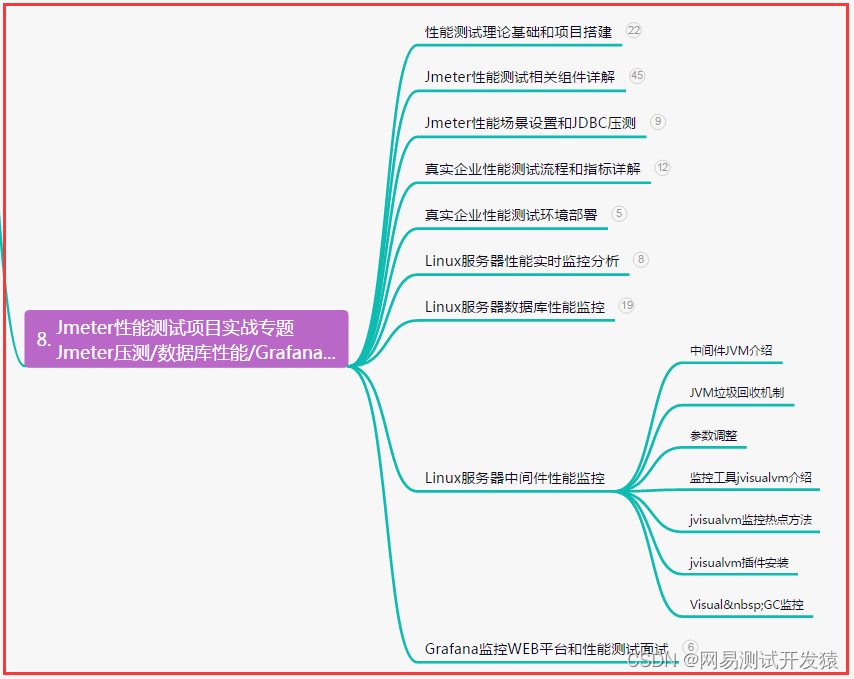
【性能测试】服务器常用的性能指标总结,一文概全...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 压测过程中&#…...

Vue学习笔记-Vuex基本使用
基本使用 初始化数据、配置actions、mutations,操作文件/store/index.js //index.js文件用于创建Vuex中最为核心的store对象 import Vue from vue import Vuex from vuex Vue.use(Vuex) //actions对象用于响应组件中的动作,专门负责业务逻辑 const actions {//函数…...
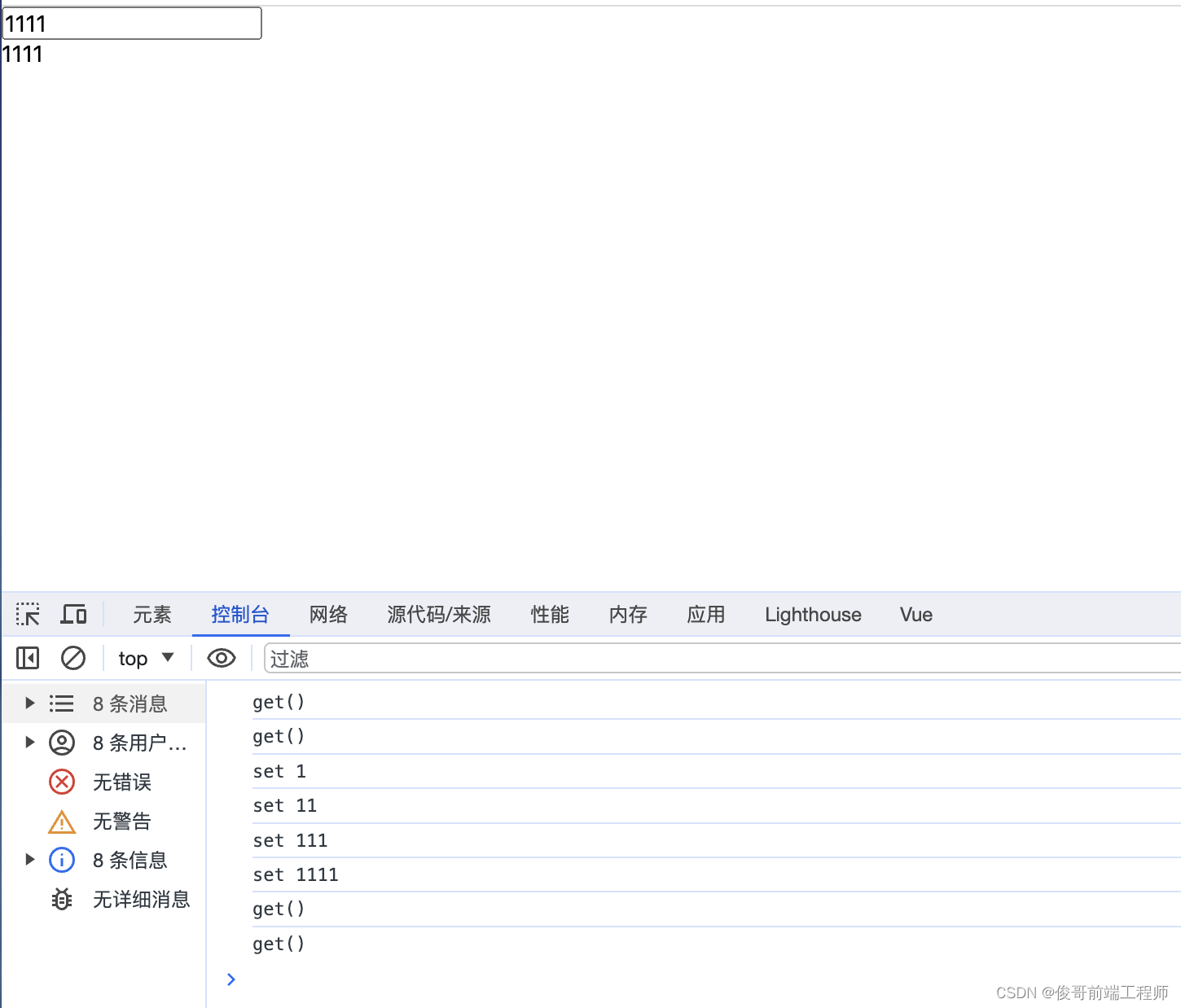
vue3中的customRef创建一个自定义的 ref对象
customRef 创建一个自定义的 ref,并对其依赖项跟踪和更新触发进行显式控制 小案例: 自定义 ref 实现 debounce <template><div style"font-size: 14px;"><input v-model"text" placeholder"搜索关键字"/><…...
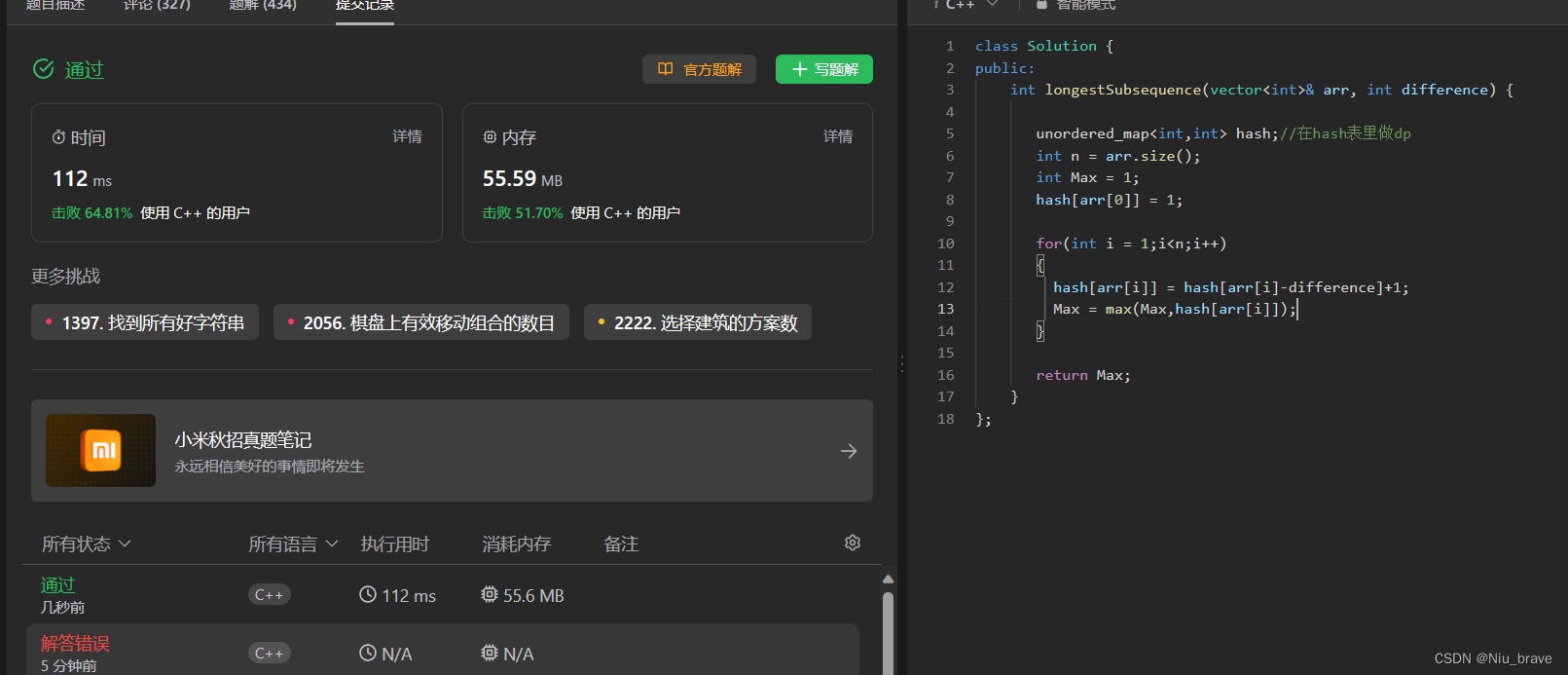
动态规划学习——子序列问题
目录 编辑 一,最长定差子序列 1.题目 2,题目接口 3,解题思路及其代码 一,最长定差子序列 1.题目 给你一个整数数组 arr 和一个整数 difference,请你找出并返回 arr 中最长等差子序列的长度,该子序列…...

使用 COPY 加速 PostgreSQL 批量插入
文章目录 1.copy命令介紹2.copy vs insert的优势3.测量性能4.结论 1.copy命令介紹 PostgreSQL 中的命令COPY是执行批量插入和数据迁移的强大工具。它允许快速有效地将大量数据插入表中。 COPY命令为批量插入和数据迁移提供了更简单且更具成本效益的解决方案。 可以避免使用诸…...
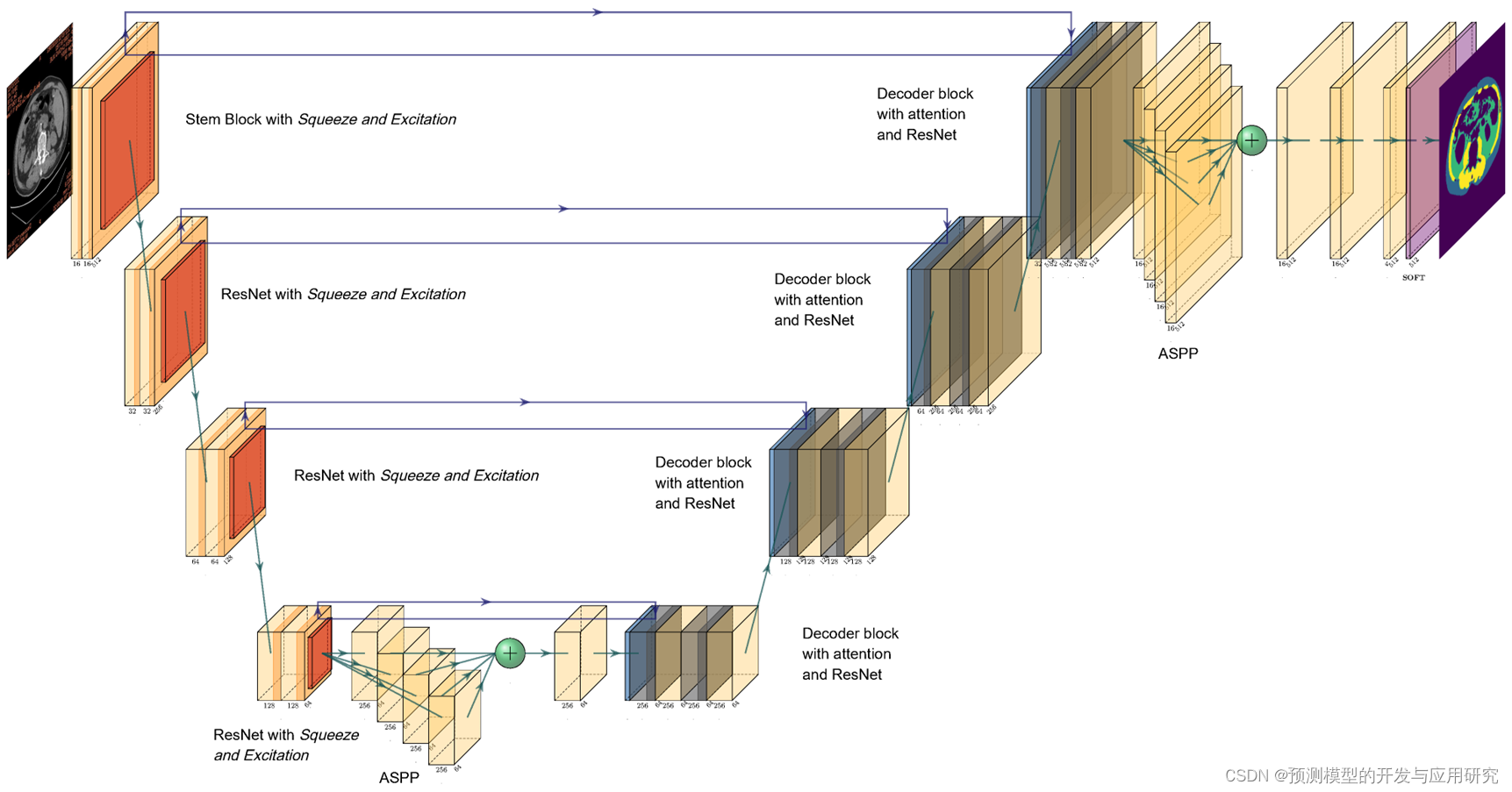
plotneuralnet和netron结合绘制模型架构图
plotneuralnet和netron结合绘制模型架构图 一、plotneuralnet 本身的操作 模型结构图的可视化,能直观展示模型的结构以及各个模块之间的关系。最近借助plotneuralnet python库(windows版)绘制了一个网络结构图,有一些经验和心得…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

2026年HR招聘偏好白皮书:这5项附加技能出现频率暴涨
2026 年的招聘市场,正在从“看你会什么岗位技能”,转向“看你能不能把岗位做得更智能”。HR筛简历时,越来越关注候选人的AI应用能力、数据化思维和业务落地能力。人社部近年发布的新职业中,已经出现生成式人工智能系统应用员、人工…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

AI时代程序员职业发展与个人创业可行性研究报告
一、行业宏观变革(2026核心趋势数据佐证) 1.1 开发范式已彻底重构(行业不可逆拐点) 2026年正式进入AI Agent智能体开发时代,传统CRUD编码价值持续崩塌。 核心权威数据: Gartner预测:2026年75%企…...

【紧急预警】92%的DeepSeek测试用例生成失败源于这4个隐性配置缺陷——资深SDET连夜整理修复清单
更多请点击: https://codechina.net 第一章:DeepSeek测试用例生成的现状与危机本质 当前,DeepSeek系列大模型(如DeepSeek-Coder、DeepSeek-VL)在代码生成与理解任务中展现出强大能力,但其测试用例自动生成…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

CANoe诊断测试没CDD文件怎么办?手把手教你用Fault Memory窗口和CAPL脚本读取解析DTC故障码
CANoe诊断测试无CDD文件的实战解决方案:从Fault Memory到CAPL脚本全解析当CDD文件缺失或定义不清晰时,诊断测试工程师常常陷入困境。本文将深入探讨如何利用Fault Memory窗口的基础功能,并通过CAPL脚本实现更灵活、更强大的故障码读取与解析方…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南
告别漫长等待:UE5.2.1 Windows打包效率优化与插件问题排查指南第一次点击"打包项目"按钮时,进度条仿佛被冻结的场景,每个UE5开发者都经历过。尤其当项目规模达到数十GB时,等待时间可能超过一小时——这背后隐藏着引擎底…...

收藏|2026年AI大模型就业爆发!岗位暴涨12倍、月薪6W+,小白零基础入门指南
2026年,AI已从“科技热点”彻底变为职场“刚需赛道”!脉脉高聘人才智库最新发布的《2026年1-2月中高端人才求职招聘洞察》,用硬核数据揭示行业真相:AI人才成招聘市场顶流,岗位量、薪资双双爆发式增长。尤其对零基础小白…...