Elasticsearch:ES|QL 函数及操作符
如果你对 ES|QL 还不是很熟悉的话,请阅读之前的文章 “Elasticsearch:ES|QL 查询语言简介”。ES|QL 提供了一整套用于处理数据的函数和运算符。 功能分为以下几类:

目录
ES|QL 聚合函数
AVG
COUNT
COUNT_DISTINCT
计数为近似值
精度可配置
MAX
MEDIAN
MEDIAN_ABSOLUTE_DEVIATION
MIN
PERCENTILE
PERCENTILE(通常)是近似值
SUM
ES|QL 数学函数
ABS
ACOS
ASIN
ATAN
ATAN2
CEIL
COS
COSH
E
FLOOR
LOG10
PI
POW
类型规则
算术错误
分数指数
支持的输入和输出类型表
ROUND
SIN
SINH
SQRT
TAN
TANH
TAU
ES|QL 字符串函数
CONCAT
LEFT
LENGTH
LTRIM
REPLACE
RIGHT
RTRIM
SPLIT
SUBSTRING
TRIM
ES|QL 日期时间函数
AUTO_BUCKET
数字字段
DATE_EXTRACT
DATE_FORMAT
DATE_PARSE
DATE_TRUNC
NOW
ES|QL 类型转换函数
TO_BOOLEAN
TO_DATETIME
TO_DEGREES
TO_DOUBLE
TO_INTEGER
TO_IP
TO_LONG
TO_RADIANS
TO_STRING
TO_UNSIGNED_LONG
TO_VERSION
ES|QL 条件函数和表达式
CASE
COALESCE
GREATEST
LEAST
ES|QL 多值函数
MV_AVG
MV_CONCAT
MV_COUNT
MV_DEDUPE
MV_MAX
MV_MEDIAN
MV_MIN
MV_SUM
ES|QL 操作符
Binary operators
逻辑运算符
IS NULL 和 IS NOT NULL 谓词
CIDR_MATCH
ENDS_WITH
IN
IS_FINITE
IS_INFINITE
IS_NAN
LIKE
RLIKE
STARTS_WITH
ES|QL 聚合函数
STATS ... BY 函数支持以下聚合函数:
- AVG
- COUNT
- COUNT_DISTINCT
- MAX
- MEDIAN
- MEDIAN_ABSOLUTE_DEVIATION
- MIN
- PERCENTILE
- SUM
AVG
数值字段的平均值。
FROM employees
| STATS AVG(height)| AVG(height):double |
|---|
| 1.7682 |
无论输入类型如何,结果始终是双精度值。
COUNT
计算字段值。
FROM employees
| STATS COUNT(height)| COUNT(height):long |
|---|
| 100 |
可以采用任何字段类型作为输入,并且无论输入类型如何,结果总是 long 类型。
要计算行数,请使用 COUNT(*):
FROM employees
| STATS count = COUNT(*) BY languages
| SORT languages DESC| count:long | languages:integer |
|---|---|
| 10 | null |
| 21 | 5 |
| 18 | 4 |
| 17 | 3 |
| 19 | 2 |
| 15 | 1 |
COUNT_DISTINCT
独特值的近似数量。
FROM hosts
| STATS COUNT_DISTINCT(ip0), COUNT_DISTINCT(ip1)| COUNT_DISTINCT(ip0):long | COUNT_DISTINCT(ip1):long |
|---|---|
| 7 | 8 |
可以采用任何字段类型作为输入,并且无论输入类型如何,结果总是 long 类型。
计数为近似值
计算精确计数需要将值加载到集合中并返回其大小。 当处理高基数集和/或大的数据集时,这不会扩展,因为所需的内存使用量以及在节点之间通信这些每个分片集的需要将利用集群的太多资源。
此 COUNT_DISTINCT 函数基于 HyperLogLog++ 算法,该算法基于具有一些有趣属性的值的哈希值进行计数:
- 可配置的精度,决定如何用内存换取准确性,
- 在低基数集上具有出色的准确性,
- 固定内存使用:无论有数百个还是数十亿个唯一值,内存使用仅取决于配置的精度。
对于 c 的精度阈值,我们使用的实现需要大约 c * 8 字节。
下图显示了阈值前后误差的变化情况:
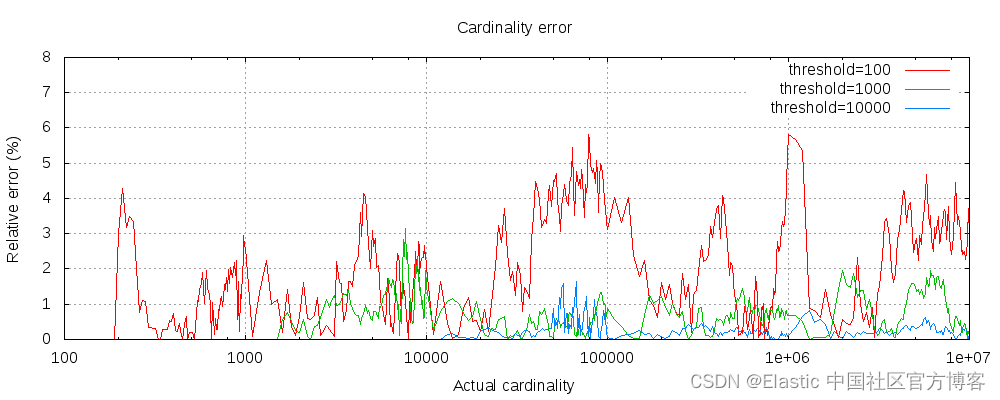
对于所有 3 个阈值,计数均准确至配置的阈值。 尽管不能保证,但情况很可能如此。 实践中的准确性取决于所讨论的数据集。 一般来说,大多数数据集都显示出一致的良好准确性。 另请注意,即使阈值低至 100,即使计算数百万个项目,误差仍然非常低(如上图所示,为 1-6%)。
HyperLogLog++ 算法取决于哈希值的前导零,数据集中哈希值的精确分布会影响基数的准确性。
精度可配置
COUNT_DISTINCT 函数采用可选的第二个参数来配置前面讨论的精度。
FROM hosts
| STATS COUNT_DISTINCT(ip0, 80000), COUNT_DISTINCT(ip1, 5)| COUNT_DISTINCT(ip0,80000):long | COUNT_DISTINCT(ip1,5):long |
|---|---|
| 7 | 9 |
MAX
数字字段的最大值。
FROM employees | STATS MAX(languages)
| MAX(languages):integer |
|---|
| 5 |
MEDIAN
大于所有值一半且小于所有值一半的值,也称为 50% PERCENTILE。
FROM employees
| STATS MEDIAN(salary), PERCENTILE(salary, 50)| MEDIAN(salary):double | PERCENTILE(salary,50):double |
|---|---|
| 47003 | 47003 |
注意:与 PERCENTILE 一样,MEDIAN 通常是近似值。
警告:MEDIAN 也是不确定的(non-deterministic)。 这意味着使用相同的数据可能会得到略有不同的结果。
MEDIAN_ABSOLUTE_DEVIATION
Median 绝对偏差,变异性的测量。 它是一个稳健的统计数据,这意味着它对于描述可能具有异常值或可能不呈正态分布的数据很有用。 对于此类数据,它比标准差更具描述性。
它的计算方法是每个数据点与整个样本中值的偏差的中值。 即,对于随机变量 X,中值绝对偏差为 median(|median(X) - Xi|)。
FROM employees
| STATS MEDIAN(salary), MEDIAN_ABSOLUTE_DEVIATION(salary)| MEDIAN(salary):double | MEDIAN_ABSOLUTE_DEVIATION(salary):double |
|---|---|
| 47003 | 10096.5 |
注意:与 PERCENTILE 一样,MEDIAN_ABSOLUTE_DEVIATION 通常是近似值。
警告:MEDIAN_ABSOLUTE_DEVIATION 也是不确定的(non-disterministic)。 这意味着使用相同的数据可能会得到略有不同的结果。
MIN
数值字段的最小值。
FROM employees
| STATS MIN(languages)| MIN(languages):integer |
|---|
| 1 |
PERCENTILE
观察值出现一定百分比时的值。 例如,第 95 个百分位数是大于观测值 95% 的值,第 50 个百分位数是中位数 (MEDIAN)。
FROM employees
| STATS p0 = PERCENTILE(salary, 0), p50 = PERCENTILE(salary, 50), p99 = PERCENTILE(salary, 99)| p0:double | p50:double | p99:double |
|---|---|---|
| 25324 | 47003 | 74970.29 |
PERCENTILE(通常)是近似值
有许多不同的算法来计算百分位数。 简单的实现只是将所有值存储在排序数组中。 要查找第 50 个百分位数,只需查找 my_array[count(my_array) * 0.5] 处的值即可。
显然,简单的实现不会扩展 —— 排序数组随着数据集中值的数量线性增长。 为了计算 Elasticsearch 集群中可能数十亿个值的百分位数,需要计算近似百分位数。
百分位数度量使用的算法称为 TDigest(由 Ted Dunning 在使用 T-Digests 计算准确分位数中介绍)。
使用此指标时,需要牢记一些准则:
- 准确度与 q(1-q) 成正比。 这意味着极端百分位数(例如 99%)比不太极端的百分位数(例如中位数)更准确
- 对于较小的值集,百分位数非常准确(如果数据足够小,则可能 100% 准确)。
- 随着桶中值数量的增加,算法开始近似百分位数。 它实际上是用准确性来换取内存节省。 准确的不准确程度很难概括,因为它取决于你的数据分布和聚合的数据量
下图显示了均匀分布的相对误差,具体取决于收集值的数量和请求的百分位数:
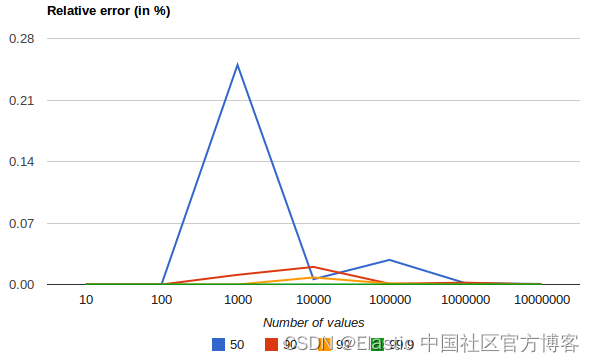
它显示了极端百分位数的精度如何更好。 对于大量值,误差会减小的原因是大数定律使值的分布越来越均匀,并且 t-digest 树可以更好地进行汇总。 如果分布更加倾斜,情况就不会如此。
警告:PERCENTILE 也是不确定的(non-deterministic)。 这意味着使用相同的数据可能会得到略有不同的结果。
SUM
数字字段的总和。
FROM employees
| STATS SUM(languages)| SUM(languages):long |
|---|
| 281 |
ES|QL 数学函数
ES|QL 支持这些数学函数:
- ABS
- ACOS
- ASIN
- ATAN
- ATAN2
- CEIL
- COS
- COSH
- E
- FLOOR
- LOG10
- PI
- POW
- ROUND
- SIN
- SINH
- SQRT
- TAN
- TANH
- TAU
ABS

返回绝对值。
FROM employees
| KEEP first_name, last_name, height
| EVAL abs_height = ABS(0.0 - height)支持的类型:
| n | result |
|---|---|
| double | double |
| integer | integer |
| long | long |
| unsigned_long | unsigned_long |
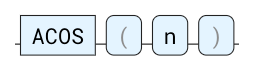
ACOS
语法:
参数:
n: 数字表达。 如果为 null,则该函数返回 null。
描述:
角度形式返回 n 的反余弦,以弧度表示。
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
例子:
ROW a=.9
| EVAL acos=ACOS(a)
a:double acos:double
.90.45102681179626236ASIN
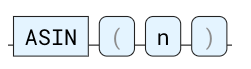
反正弦三角函数。
ROW a=.9
| EVAL asin=ASIN(a)| a:double | asin:double |
|---|---|
| .9 | 1.1197695149986342 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
ATAN
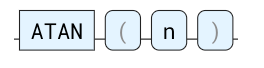
反正切三角函数。
ROW a=12.9
| EVAL atan=ATAN(a)| a:double | atan:double |
|---|---|
| 12.9 | 1.4934316673669235 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
ATAN2
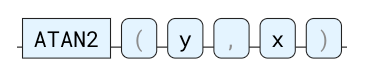
笛卡尔平面中正 x 轴与从原点到点 (x , y) 的射线之间的角度。
ROW y=12.9, x=.6
| EVAL atan2=ATAN2(y, x)| y:double | x:double | atan2:double |
|---|---|---|
| 12.9 | 0.6 | 1.5243181954438936 |
支持的类型:
| y | x | result |
|---|---|---|
| double | double | double |
| double | integer | double |
| double | long | double |
| double | unsigned_long | double |
| integer | double | double |
| integer | integer | double |
| integer | long | double |
| integer | unsigned_long | double |
| long | double | double |
| long | integer | double |
| long | long | double |
| long | unsigned_long | double |
| unsigned_long | double | double |
| unsigned_long | integer | double |
| unsigned_long | long | double |
| unsigned_long | unsigned_long | double |
CEIL
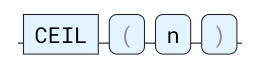
将数字向上舍入到最接近的整数。
ROW a=1.8
| EVAL a=CEIL(a)| a:double |
|---|
| 2 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | integer |
| long | long |
| unsigned_long | unsigned_long |
COS
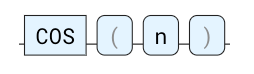
余弦三角函数。
ROW a=1.8
| EVAL cos=COS(a)| a:double | cos:double |
|---|---|
| 1.8 | -0.2272020946930871 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
COSH
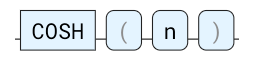
余弦双曲函数。
ROW a=1.8
| EVAL cosh=COSH(a)| a:double | cosh:double |
|---|---|
| 1.8 | 3.1074731763172667 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
E
欧拉数。
ROW E()| E():double |
|---|
| 2.718281828459045 |
FLOOR
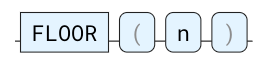
将数字向下舍入到最接近的整数。
ROW a=1.8
| EVAL a=FLOOR(a)| a:double |
|---|
| 1 |
注意:这是长整型(包括无符号)和整数的 noop (no operation, 不做任何处理)。 对于双精度,这会选择最接近双精度值的整数(Math.floor)。
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | integer |
| long | long |
| unsigned_long | unsigned_long |
LOG10
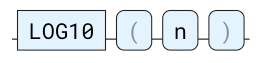
返回以 10 为底的对数。输入可以是任何数值,返回值始终是双精度型。
负数的对数为 NaN。 无穷大的对数是无穷大的,就像 0 的对数一样。
ROW d = 1000.0
| EVAL s = LOG10(d)| d: double | s:double |
|---|---|
| 1000.0 | 3.0 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
PI
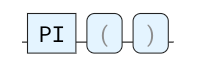
圆的周长与其直径的比率。
ROW PI()| PI():double |
|---|
| 3.141592653589793 |
POW

返回基数(第一个参数)的指数(第二个参数)次方的值。 两个参数都必须是数字。
ROW base = 2.0, exponent = 2
| EVAL result = POW(base, exponent)| base:double | exponent:integer | result:double |
|---|---|---|
| 2.0 | 2 | 4.0 |
类型规则
返回值的类型由底数和指数的类型决定。 应用以下规则来确定结果类型:
- 如果基数或指数中有一个是浮点类型,则结果将为 double
- 否则,如果基数或指数是 64 位(长整型或无符号长整型),则结果将为 long
- 否则,结果将是一个 32 位整数(这涵盖所有其他数字类型,包括 int、short 和 byte)
例如,使用简单整数作为参数将产生整数结果:
ROW base = 2, exponent = 2
| EVAL s = POW(base, exponent)| base:integer | exponent:integer | s:integer |
|---|---|---|
| 2 | 2 | 4 |
注意:对于所有情况,实际 pow 函数均使用双精度值执行。 这意味着,对于非常大的非浮点值,该操作导致结果与预期略有不同的可能性很小。 然而,非常大的非浮点值更可能的结果是数值溢出。
算术错误
算术错误和数字溢出不会导致错误。 相反,结果将为 null,并添加 ArithmeticException 警告。 例如:
ROW x = POW(9223372036854775808, 2)| warning:Line 1:9: evaluation of [POW(9223372036854775808, 2)] failed, treating result as null. Only first 20 failures recorded. |
|---|
| warning:Line 1:9: java.lang.ArithmeticException: long overflow |
| x:long |
|---|
| null |
如果需要防止数字溢出,请在任一参数上使用 TO_DOUBLE:
ROW x = POW(9223372036854775808, TO_DOUBLE(1))| x:double |
|---|
| 9.223372036854776E18 |
分数指数
指数可以是分数,这类似于求根。 例如,0.5 的指数将给出底数的平方根:
ROW base = 4, exponent = 0.5
| EVAL s = POW(base, exponent)| base:integer | exponent:double | s:double |
|---|---|---|
| 4 | 0.5 | 2.0 |
支持的输入和输出类型表
为了清楚起见,下表描述了所有数字输入类型组合的输出结果类型:
| base | exponent | result |
|---|---|---|
| double | double | double |
| double | integer | double |
| integer | double | double |
| integer | integer | integer |
| long | double | double |
| long | integer | long |
ROUND
将数字四舍五入为最接近指定位数的数字。 如果未提供位数,则默认为 0 位。 如果指定的位数为负数,则四舍五入到小数点左边的位数。
FROM employees
| KEEP first_name, last_name, height
| EVAL height_ft = ROUND(height * 3.281, 1)| first_name:keyword | last_name:keyword | height:double | height_ft:double |
|---|---|---|---|
| Arumugam | Ossenbruggen | 2.1 | 6.9 |
| Kwee | Schusler | 2.1 | 6.9 |
| Saniya | Kalloufi | 2.1 | 6.9 |
SIN
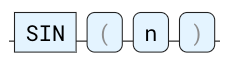
正弦三角函数。
ROW a=1.8
| EVAL sin=SIN(a)| a:double | sin:double |
|---|---|
| 1.8 | 0.9738476308781951 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
SINH
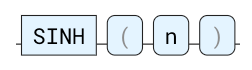
正弦双曲函数。
ROW a=1.8
| EVAL sinh=SINH(a)| a:double | sinh:double |
|---|---|
| 1.8 | 2.94217428809568 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
SQRT
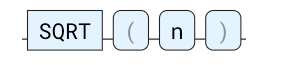
返回数字的平方根。 输入可以是任何数值,返回值始终是双精度值。
负数的平方根为 NaN。 无穷大的平方根是无穷大。
ROW d = 100.0
| EVAL s = SQRT(d)| d: double | s:double |
|---|---|
| 100.0 | 10.0 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
TAN

正切三角函数。
ROW a=1.8
| EVAL tan=TAN(a)| a:double | tan:double |
|---|---|
| 1.8 | -4.286261674628062 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
TANH
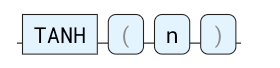
正切双曲函数。
ROW a=1.8
| EVAL tanh=TANH(a)| a:double | tanh:double |
|---|---|
| 1.8 | 0.9468060128462683 |
支持的类型:
| n | result |
|---|---|
| double | double |
| integer | double |
| long | double |
| unsigned_long | double |
TAU
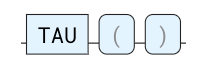
圆的周长与其半径之比。
ROW TAU()| TAU():double |
|---|
| 6.283185307179586 |
ES|QL 字符串函数
ES|QL 支持以下字符串函数:
- CONCAT
- LEFT
- LENGTH
- LTRIM
- REPLACE
- RIGHT
- RTRIM
- SPLIT
- SUBSTRING
- TRIM
CONCAT
连接两个或多个字符串。
FROM employees
| KEEP first_name, last_name, height
| EVAL fullname = CONCAT(first_name, " ", last_name)LEFT

返回从字符串左侧开始提取长度字符的子字符串。
FROM employees
| KEEP last_name
| EVAL left = LEFT(last_name, 3)
| SORT last_name ASC
| LIMIT 5| last_name:keyword | left:keyword |
|---|---|
| Awdeh | Awd |
| Azuma | Azu |
| Baek | Bae |
| Bamford | Bam |
| Bernatsky | Ber |
支持的类型:
| string | length | result |
|---|---|---|
| keyword | integer | keyword |
LENGTH
返回字符串的字符长度。
FROM employees
| KEEP first_name, last_name, height
| EVAL fn_length = LENGTH(first_name)LTRIM
从字符串中删除前导空格。
ROW message = " some text ", color = " red "
| EVAL message = LTRIM(message)
| EVAL color = LTRIM(color)
| EVAL message = CONCAT("'", message, "'")
| EVAL color = CONCAT("'", color, "'")| message:keyword | color:keyword |
|---|---|
| 'some text ' | 'red ' |
REPLACE
该函数将字符串(第一个参数)中正则表达式(第二个参数)的任何匹配项替换为替换字符串(第三个参数)。
如果任何参数为 NULL,则结果为 NULL。
此示例将出现的单词 “World” 替换为单词 “Universe”:
ROW str = "Hello World"
| EVAL str = REPLACE(str, "World", "Universe")
| KEEP str| str:keyword |
|---|
| Hello Universe |
RIGHT

返回从右侧开始的字符串中提取 length 字符的子字符串。
FROM employees
| KEEP last_name
| EVAL right = RIGHT(last_name, 3)
| SORT last_name ASC
| LIMIT 5| last_name:keyword | right:keyword |
|---|---|
| Awdeh | deh |
| Azuma | uma |
| Baek | aek |
| Bamford | ord |
| Bernatsky | sky |
支持的类型:
| string | length | result |
|---|---|---|
| keyword | integer | keyword |
RTRIM
删除字符串中的尾随空格。
ROW message = " some text ", color = " red "
| EVAL message = RTRIM(message)
| EVAL color = RTRIM(color)
| EVAL message = CONCAT("'", message, "'")
| EVAL color = CONCAT("'", color, "'")| message:keyword | color:keyword |
|---|---|
| ' some text' | ' red' |
SPLIT
将单个值字符串拆分为多个字符串。 例如:
ROW words="foo;bar;baz;qux;quux;corge"
| EVAL word = SPLIT(words, ";")将 “foo;bar;baz;qux;quux;corge” 以 ; 进行分割, 并返回一个数组:
| words:keyword | word:keyword |
|---|---|
| foo;bar;baz;qux;quux;corge | [foo,bar,baz,qux,quux,corge] |
警告:目前仅支持单字节分隔符。
SUBSTRING
返回字符串的子字符串,由起始位置和可选长度指定。 此示例返回每个姓氏的前三个字符:
FROM employees
| KEEP last_name
| EVAL ln_sub = SUBSTRING(last_name, 1, 3)| last_name:keyword | ln_sub:keyword |
|---|---|
| Awdeh | Awd |
| Azuma | Azu |
| Baek | Bae |
| Bamford | Bam |
| Bernatsky | Ber |
负的起始位置被解释为相对于字符串的结尾。 此示例返回每个姓氏的最后三个字符:
FROM employees
| KEEP last_name
| EVAL ln_sub = SUBSTRING(last_name, -3, 3)| last_name:keyword | ln_sub:keyword |
|---|---|
| Awdeh | deh |
| Azuma | uma |
| Baek | aek |
| Bamford | ord |
| Bernatsky | sky |
如果省略 length,则 substring 返回字符串的剩余部分。 此示例返回除第一个字符之外的所有字符:
FROM employees
| KEEP last_name
| EVAL ln_sub = SUBSTRING(last_name, 2)| last_name:keyword | ln_sub:keyword |
|---|---|
| Awdeh | wdeh |
| Azuma | zuma |
| Baek | aek |
| Bamford | amford |
| Bernatsky | ernatsky |
TRIM
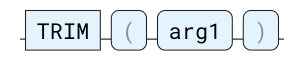
从字符串中删除前导和尾随空格。
ROW message = " some text ", color = " red "
| EVAL message = TRIM(message)
| EVAL color = TRIM(color)| message:s | color:s |
|---|---|
| some text | red |
支持的类型:
| arg1 | result |
|---|---|
| keyword | keyword |
| text | text |
ES|QL 日期时间函数
ES|QL 支持以下日期时间函数:
- AUTO_BUCKET
- DATE_EXTRACT
- DATE_FORMAT
- DATE_PARSE
- DATE_TRUNC
- NOW
AUTO_BUCKET
创建人性化的桶并为每行返回与该行所属的结果桶相对应的日期时间值。 将 AUTO_BUCKET 与 STATS ... BY 结合起来创建日期直方图。
你提供目标桶数量、开始日期和结束日期,它会选择适当的桶大小来生成目标数量或更少的桶。 例如,这要求全年最多 20 个桶,其中选择每月桶:
ROW date=TO_DATETIME("1985-07-09T00:00:00.000Z")
| EVAL bucket=AUTO_BUCKET(date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z")| date:datetime | bucket:datetime |
|---|---|
| 1985-07-09T00:00:00.000Z | 1985-07-01T00:00:00.000Z |
我们的目标不是提供准确的目标桶数,而是选择一个人们感到满意的范围,最多提供目标桶数。
如果你要求更多的存储桶,那么 AUTO_BUCKET 可以选择较小的范围。 例如,一年内最多请求 100 个桶将为你提供一周的桶:
ROW date=TO_DATETIME("1985-07-09T00:00:00.000Z")
| EVAL bucket=AUTO_BUCKET(date, 100, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z")| date:datetime | bucket:datetime |
|---|---|
| 1985-07-09T00:00:00.000Z | 1985-07-08T00:00:00.000Z |
AUTO_BUCKET 不过滤任何行。 它仅使用提供的时间范围来选择合适的桶大小。 对于日期超出范围的行,它返回与范围之外的存储桶对应的日期时间。 将 AUTO_BUCKET 与 WHERE 结合起来以过滤行。
更完整的示例可能如下所示:
FROM employees
| WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z"
| EVAL bucket = AUTO_BUCKET(hire_date, 20, "1985-01-01T00:00:00Z", "1986-01-01T00:00:00Z")
| STATS AVG(salary) BY bucket
| SORT bucket| AVG(salary):double | bucket:date |
|---|---|
| 46305.0 | 1985-02-01T00:00:00.000Z |
| 44817.0 | 1985-05-01T00:00:00.000Z |
| 62405.0 | 1985-07-01T00:00:00.000Z |
| 49095.0 | 1985-09-01T00:00:00.000Z |
| 51532.0 | 1985-10-01T00:00:00.000Z |
| 54539.75 | 1985-11-01T00:00:00.000Z |
注意:AUTO_BUCKET 不会创建与任何文档都不匹配的存储桶。 这就是上面的示例缺少 1985-03-01 和其他日期的原因。
数字字段
auto_bucket 还可以对数字字段进行操作,如下所示:
FROM employees
| WHERE hire_date >= "1985-01-01T00:00:00Z" AND hire_date < "1986-01-01T00:00:00Z"
| EVAL bs = AUTO_BUCKET(salary, 20, 25324, 74999)
| SORT hire_date, salary
| KEEP hire_date, salary, bs| hire_date:date | salary:integer | bs:double |
|---|---|---|
| 1985-02-18T00:00:00.000Z | 66174 | 65000.0 |
| 1985-02-24T00:00:00.000Z | 26436 | 25000.0 |
| 1985-05-13T00:00:00.000Z | 44817 | 40000.0 |
| 1985-07-09T00:00:00.000Z | 62405 | 60000.0 |
| 1985-09-17T00:00:00.000Z | 49095 | 45000.0 |
| 1985-10-14T00:00:00.000Z | 54329 | 50000.0 |
| 1985-10-20T00:00:00.000Z | 48735 | 45000.0 |
| 1985-11-19T00:00:00.000Z | 52833 | 50000.0 |
| 1985-11-20T00:00:00.000Z | 33956 | 30000.0 |
| 1985-11-20T00:00:00.000Z | 74999 | 70000.0 |
| 1985-11-21T00:00:00.000Z | 56371 | 55000.0 |
与上面的示例不同,你有意在日期范围上进行过滤,你很少想在数字范围上进行过滤。 所以你必须分别找到最小值和最大值。 我们还没有一种简单的方法来自动做到这一点。 改进即将到来!
DATE_EXTRACT
提取日期的部分内容,例如年、月、日、小时。 支持的字段类型是 java.time.temporal.ChronoField 提供的字段类型。
ROW date = DATE_PARSE("yyyy-MM-dd", "2022-05-06")
| EVAL year = DATE_EXTRACT("year", date)| date:date | year:long |
|---|---|
| 2022-05-06T00:00:00.000Z | 2022 |
DATE_FORMAT
以提供的格式返回日期的字符串表示形式。 如果未指定格式,则使用 yyyy-MM-dd'T'HH:mm:ss.SSSZ 格式。
FROM employees
| KEEP first_name, last_name, hire_date
| EVAL hired = DATE_FORMAT("YYYY-MM-dd", hire_date)DATE_PARSE
语法:
DATE_PARSE([format,] date_string)参数:
| format | 日期格式。 有关语法,请参阅 DateTimeFormatter 文档。 如果为 null,则该函数返回 null。 |
| date_string | 作为字符串的日期表达式。 如果为 null 或空字符串,则该函数返回 null。 |
描述:
通过使用第一个参数中指定的格式解析第二个参数来返回日期。
ROW date_string = "2022-05-06"
| EVAL date = DATE_PARSE("yyyy-MM-dd", date_string)| date_string:keyword | date:date |
|---|---|
| 2022-05-06 | 2022-05-06T00:00:00.000Z |
DATE_TRUNC
将日期向下舍入到最接近的间隔。 间隔可以使用时间跨度文字语法来表达。
FROM employees
| EVAL year_hired = DATE_TRUNC(1 year, hire_date)
| STATS COUNT(emp_no) BY year_hired
| SORT year_hiredROW date_string = "2022-05-06"
| EVAL date = DATE_PARSE("yyyy-MM-dd", date_string)
| EVAL year_hired = DATE_TRUNC(1 year, date)
| keep date, year_hired
NOW
返回当前日期和时间。
ROW current_date = NOW()ES|QL 类型转换函数
ES|QL 支持以下类型转换函数:
- TO_BOOLEAN
- TO_DATETIME
- TO_DEGREES
- TO_DOUBLE
- TO_INTEGER
- TO_IP
- TO_LONG
- TO_RADIANS
- TO_STRING
- TO_UNSIGNED_LONG
- TO_VERSION
TO_BOOLEAN
将输入值转换为布尔值。
输入可以是单值或多值字段或表达式。 输入类型必须是字符串或数字类型。
字符串值 “true” 将不区分大小写地转换为布尔值 true。 对于其他任何内容,包括空字符串,该函数将返回 false。 例如:
ROW str = ["true", "TRuE", "false", "", "yes", "1"]
| EVAL bool = TO_BOOLEAN(str)| str:keyword | bool:boolean |
|---|---|
| ["true", "TRuE", "false", "", "yes", "1"] | [true, true, false, false, false, false] |
数值 0 将转换为 false,其他值将转换为 true。
别名:TO_BOOL
TO_DATETIME
将输入值转换为日期值。
输入可以是单值或多值字段或表达式。 输入类型必须是字符串或数字类型。
仅当字符串遵循 yyyy-MM-dd'T'HH:mm:ss.SSS'Z' 格式时才会成功转换(要转换其他格式的日期,请使用 DATE_PARSE)。 例如:
ROW string = ["1953-09-02T00:00:00.000Z", "1964-06-02T00:00:00.000Z", "1964-06-02 00:00:00"]
| EVAL datetime = TO_DATETIME(string)| string:keyword | datetime:date |
|---|---|
| ["1953-09-02T00:00:00.000Z", "1964-06-02T00:00:00.000Z", "1964-06-02 00:00:00"] | [1953-09-02T00:00:00.000Z, 1964-06-02T00:00:00.000Z] |
请注意,在此示例中,源多值字段中的最后一个值尚未转换。 原因是,如果不遵守日期格式,转换将导致空值。 发生这种情况时,警告标头将添加到响应中。 标头将提供有关失败来源的信息:
"Line 1:112: evaluation of [TO_DATETIME(string)] failed, treating result as null. Only first 20 failures recorded."以下标头将包含失败原因和违规值:
"java.lang.IllegalArgumentException: failed to parse date field [1964-06-02 00:00:00] with format [yyyy-MM-dd'T'HH:mm:ss.SSS'Z']"如果输入参数是数字类型,则其值将被解释为自 Unix 纪元以来的毫秒数。 例如:
ROW int = [0, 1]
| EVAL dt = TO_DATETIME(int)| int:integer | dt:date |
|---|---|
| [0, 1] | [1970-01-01T00:00:00.000Z, 1970-01-01T00:00:00.001Z] |
别名:TO_DT
TO_DEGREES
将弧度数转换为度数。
输入可以是单值或多值字段或表达式。 输入类型必须是数字类型,并且结果始终为 double。
例子:
ROW rad = [1.57, 3.14, 4.71]
| EVAL deg = TO_DEGREES(rad)| rad:double | deg:double |
|---|---|
| [1.57, 3.14, 4.71] | [89.95437383553924, 179.9087476710785, 269.86312150661774] |
TO_DOUBLE
将输入值转换为双精度值。
输入可以是单值或多值字段或表达式。 输入类型必须是布尔型、日期型、字符串型或数字型。
例子:
ROW str1 = "5.20128E11", str2 = "foo"
| EVAL dbl = TO_DOUBLE("520128000000"), dbl1 = TO_DOUBLE(str1), dbl2 = TO_DOUBLE(str2)| str1:keyword | str2:keyword | dbl:double | dbl1:double | dbl2:double |
|---|---|---|---|---|
| 5.20128E11 | foo | 5.20128E11 | 5.20128E11 | null |
请注意,在此示例中,不可能对字符串进行最后一次转换。 发生这种情况时,结果为空值。 在这种情况下,警告标头将添加到响应中。 标头将提供有关失败来源的信息:
"Line 1:115: evaluation of [TO_DOUBLE(str2)] failed, treating result as null. Only first 20 failures recorded."以下标头将包含失败原因和违规值:
"java.lang.NumberFormatException: For input string: \"foo\""如果输入参数是日期类型,则其值将被解释为自 Unix 纪元以来的毫秒数,并转换为双精度。
布尔值 true 将转换为 double 1.0, false 则转换为 0.0。
别名:TO_DBL
TO_INTEGER
将输入值转换为整数值。
输入可以是单值或多值字段或表达式。 输入类型必须是布尔型、日期型、字符串型或数字型。
例子:
ROW long = [5013792, 2147483647, 501379200000]
| EVAL int = TO_INTEGER(long)| long:long | int:integer |
|---|---|
| [5013792, 2147483647, 501379200000] | [5013792, 2147483647] |
请注意,在此示例中,多值字段的最后一个值无法转换为整数。 发生这种情况时,结果为空值。 在这种情况下,警告标头将添加到响应中。 标头将提供有关失败来源的信息:
"Line 1:61: evaluation of [TO_INTEGER(long)] failed, treating result as null. Only first 20 failures recorded."以下标头将包含失败原因和违规值:
"org.elasticsearch.xpack.ql.QlIllegalArgumentException: [501379200000] out of [integer] range"如果输入参数是日期类型,则其值将被解释为自 Unix 纪元以来的毫秒数,并转换为整数。
布尔值 true 将转换为整数 1, false 将转换为 0。
别名:TO_INT
TO_IP
将输入字符串转换为 IP 值。
输入可以是单值或多值字段或表达式。
例子:
ROW str1 = "1.1.1.1", str2 = "foo"
| EVAL ip1 = TO_IP(str1), ip2 = TO_IP(str2)
| WHERE CIDR_MATCH(ip1, "1.0.0.0/8")| str1:keyword | str2:keyword | ip1:ip | ip2:ip |
|---|---|---|---|
| 1.1.1.1 | foo | 1.1.1.1 | null |
请注意,在上面的示例中,字符串的最后一次转换是不可能的。 发生这种情况时,结果为空值。 在这种情况下,警告标头将添加到响应中。 标头将提供有关失败来源的信息:
"Line 1:68: evaluation of [TO_IP(str2)] failed, treating result as null. Only first 20 failures recorded."以下标头将包含失败原因和违规值:
"java.lang.IllegalArgumentException: 'foo' is not an IP string literal."TO_LONG
将输入值转换为长整型值。
输入可以是单值或多值字段或表达式。 输入类型必须是布尔型、日期型、字符串型或数字型。
例子:
ROW str1 = "2147483648", str2 = "2147483648.2", str3 = "foo"
| EVAL long1 = TO_LONG(str1), long2 = TO_LONG(str2), long3 = TO_LONG(str3)| str1:keyword | str2:keyword | str3:keyword | long1:long | long2:long | long3:long |
|---|---|---|---|---|---|
| 2147483648 | 2147483648.2 | foo | 2147483648 | 2147483648 | null |
请注意,在此示例中,不可能对字符串进行最后一次转换。 发生这种情况时,结果为空值。 在这种情况下,警告标头将添加到响应中。 标头将提供有关失败来源的信息:
"Line 1:113: evaluation of [TO_LONG(str3)] failed, treating result as null. Only first 20 failures recorded."以下标头将包含失败原因和违规值:
"java.lang.NumberFormatException: For input string: \"foo\""如果输入参数是日期类型,则其值将被解释为自 Unix 纪元以来的毫秒数,并转换为 long。
布尔值 true 将转换为 long 1, false 将转换为 0。
TO_RADIANS
将度数转换为弧度。
输入可以是单值或多值字段或表达式。 输入类型必须是数字类型,并且结果始终为 double。
例子:
ROW deg = [90.0, 180.0, 270.0]
| EVAL rad = TO_RADIANS(deg)| deg:double | rad:double |
|---|---|
| [90.0, 180.0, 270.0] | [1.5707963267948966, 3.141592653589793, 4.71238898038469] |
TO_STRING

将字段转换为字符串。 例如:
ROW a=10
| EVAL j = TO_STRING(a)| a:integer | j:keyword |
|---|---|
| 10 | "10" |
它也适用于多值字段:
ROW a=[10, 9, 8]
| EVAL j = TO_STRING(a)| a:integer | j:keyword |
|---|---|
| [10, 9, 8] | ["10", "9", "8"] |
别名:TO_STR
支持的类型:
| v | result |
|---|---|
| boolean | keyword |
| datetime | keyword |
| double | keyword |
| integer | keyword |
| ip | keyword |
| keyword | keyword |
| long | keyword |
| text | keyword |
| unsigned_long | keyword |
| version | keyword |
TO_UNSIGNED_LONG
将输入值转换为无符号长整型值。
输入可以是单值或多值字段或表达式。 输入类型必须是布尔型、日期型、字符串型或数字型。
例子:
ROW str1 = "2147483648", str2 = "2147483648.2", str3 = "foo"
| EVAL long1 = TO_UNSIGNED_LONG(str1), long2 = TO_ULONG(str2), long3 = TO_UL(str3)| str1:keyword | str2:keyword | str3:keyword | long1:unsigned_long | long2:unsigned_long | long3:unsigned_long |
|---|---|---|---|---|---|
| 2147483648 | 2147483648.2 | foo | 2147483648 | 2147483648 | null |
请注意,在此示例中,不可能对字符串进行最后一次转换。 发生这种情况时,结果为空值。 在这种情况下,警告标头将添加到响应中。 标头将提供有关失败来源的信息:
"Line 1:133: evaluation of [TO_UL(str3)] failed, treating result as null. Only first 20 failures recorded."以下标头将包含失败原因和违规值:
"java.lang.NumberFormatException: Character f is neither a decimal digit number, decimal point, nor \"e\" notation exponential mark."如果输入参数是日期类型,则其值将被解释为自 Unix 纪元以来的毫秒数,并转换为 unsigned long。
Boolean true 将转换为 unsigned long 1, false 则转换为 0。
别名:TO_ULONG、TO_UL
TO_VERSION
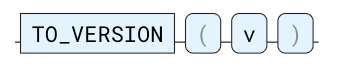
将输入字符串转换为版本值。 例如:
ROW v = TO_VERSION("1.2.3")| v:version |
|---|
| 1.2.3 |
输入可以是单值或多值字段或表达式。
别名:TO_VER
支持的类型:
| v | result |
|---|---|
| keyword | version |
| text | version |
| version | version |
ES|QL 条件函数和表达式
条件函数通过以 if-else 方式求值来返回其参数之一。 ES|QL 支持这些条件函数:
- CASE
- COALESCE
- GREATEST
- LEAST
CASE
语法:
CASE(condition1, value1[, ..., conditionN, valueN][, default_value])参数:
| conditionX | 一个条件 |
| valueX | 当相应条件第一个评估为 true 时返回的值。 |
| default_value | 没有条件匹配时返回的默认值。 |
描述:
接受条件和值对。 该函数返回属于第一个值为 true 的条件的值。
如果参数数量为奇数,则最后一个参数为默认值,当没有条件匹配时返回该默认值。
FROM employees
| EVAL type = CASE(languages <= 1, "monolingual",languages <= 2, "bilingual","polyglot")
| KEEP emp_no, languages, type| emp_no:integer | languages:integer | type:keyword |
|---|---|---|
| 10001 | 2 | bilingual |
| 10002 | 5 | polyglot |
| 10003 | 4 | polyglot |
| 10004 | 5 | polyglot |
| 10005 | 1 | monolingual |
COALESCE
返回第一个非空值。
ROW a=null, b="b"
| EVAL COALESCE(a, b)| a:null | b:keyword | COALESCE(a,b):keyword |
|---|---|---|
| null | b | b |
GREATEST

返回许多列中的最大值。 这与 MV_MAX 类似,只是它旨在一次在多个列上运行。
ROW a = 10, b = 20
| EVAL g = GREATEST(a, b)| a:integer | b:integer | g:integer |
|---|---|---|
| 10 | 20 | 20 |
注意:当在 keyword 或 text 字段上运行时,这将按字母顺序返回最后一个字符串。 当在布尔列上运行时,如果任何值为 true,则返回 true。
支持的类型:
| first | rest | result |
|---|---|---|
| boolean | boolean | boolean |
| double | double | double |
| integer | integer | integer |
| ip | ip | ip |
| keyword | keyword | keyword |
| long | long | long |
| text | text | text |
| version | version | version |
LEAST

返回许多列中的最小值。 这与 MV_MIN 类似,只是它旨在一次在多个列上运行。
ROW a = 10, b = 20
| EVAL l = LEAST(a, b)| a:integer | b:integer | l:integer |
|---|---|---|
| 10 | 20 | 10 |
注意:当在 keyword 或 text 字段上运行时,这将按字母顺序返回第一个字符串。 当在布尔列上运行时,如果任何值为 false,则返回 false。
支持的类型:
| first | rest | result |
|---|---|---|
| boolean | boolean | boolean |
| double | double | double |
| integer | integer | integer |
| ip | ip | ip |
| keyword | keyword | keyword |
| long | long | long |
| text | text | text |
| version | version | version |
ES|QL 多值函数
ES|QL 支持以下多值函数:
- MV_AVG
- MV_CONCAT
- MV_COUNT
- MV_DEDUPE
- MV_MAX
- MV_MEDIAN
- MV_MIN
- MV_SUM
MV_AVG
将多值字段转换为包含所有值的平均值的单值字段。 例如:
ROW a=[3, 5, 1, 6]
| EVAL avg_a = MV_AVG(a)| a:integer | avg_a:double |
|---|---|
| [3, 5, 1, 6] | 3.75 |
注意:输出类型始终为 double,输入类型可以是任意数字。
MV_CONCAT
将多值字符串字段转换为单值字段,其中包含由分隔符分隔的所有值的串联:
ROW a=["foo", "zoo", "bar"]
| EVAL j = MV_CONCAT(a, ", ")| a:keyword | j:keyword |
|---|---|
| ["foo", "zoo", "bar"] | "foo, zoo, bar" |
如果要连接非字符串字段,请先对它们调用 TO_STRING:
ROW a=[10, 9, 8]
| EVAL j = MV_CONCAT(TO_STRING(a), ", ")| a:integer | j:keyword |
|---|---|
| [10, 9, 8] | "10, 9, 8" |
MV_COUNT
将多值字段转换为包含值数量的单值字段:
ROW a=["foo", "zoo", "bar"]
| EVAL count_a = MV_COUNT(a)| a:keyword | count_a:integer |
|---|---|
| ["foo", "zoo", "bar"] | 3 |
MV_DEDUPE
从多值字段中删除重复项。 例如:
ROW a=["foo", "foo", "bar", "foo"]
| EVAL dedupe_a = MV_DEDUPE(a)| a:keyword | dedupe_a:keyword |
|---|---|
| ["foo", "foo", "bar", "foo"] | ["foo", "bar"] |
注意:MV_DEDUPE 可能(但并不总是)对字段中的值进行排序。
MV_MAX
将多值字段转换为包含最大值的单值字段。 例如:
ROW a=[3, 5, 1]
| EVAL max_a = MV_MAX(a)| a:integer | max_a:integer |
|---|---|
| [3, 5, 1] | 5 |
它可以由任何字段类型使用,包括 keyword 字段。 在这种情况下,选择最后一个字符串,逐字节比较它们的 utf-8 表示形式:
ROW a=["foo", "zoo", "bar"]
| EVAL max_a = MV_MAX(a)| a:keyword | max_a:keyword |
|---|---|
| ["foo", "zoo", "bar"] | "zoo" |
MV_MEDIAN
将多值字段转换为包含中值的单值字段。 例如:
ROW a=[3, 5, 1]
| EVAL median_a = MV_MEDIAN(a)| a:integer | median_a:integer |
|---|---|
| [3, 5, 1] | 3 |
它可以被任何数字字段类型使用并返回相同类型的值。 如果该行的一列有偶数个值,则结果将是中间两个条目的平均值。 如果该字段不是浮点型,则平均值向下舍入:
ROW a=[3, 7, 1, 6]
| EVAL median_a = MV_MEDIAN(a)| a:integer | median_a:integer |
|---|---|
| [3, 7, 1, 6] | 4 |
MV_MIN
将多值字段转换为包含最小值的单值字段。 例如:
ROW a=[2, 1]
| EVAL min_a = MV_MIN(a)| a:integer | min_a:integer |
|---|---|
| [2, 1] | 1 |
它可以由任何字段类型使用,包括 keyword 字段。 在这种情况下,选择第一个字符串,逐字节比较它们的 utf-8 表示形式:
ROW a=["foo", "bar"]
| EVAL min_a = MV_MIN(a)| a:keyword | min_a:keyword |
|---|---|
| ["foo", "bar"] | "bar" |
MV_SUM
将多值字段转换为包含所有值之和的单值字段。 例如:
ROW a=[3, 5, 6]
| EVAL sum_a = MV_SUM(a)| a:integer | sum_a:integer |
|---|---|
| [3, 5, 6] | 14 |
ES|QL 操作符
用于与一个或多个表达式进行比较的布尔运算符。
- Binary operators
- Logical operators
- IS NULL and IS NOT NULL predicates
- CIDR_MATCH
- ENDS_WITH
- IN
- IS_FINITE
- IS_INFINITE
- IS_NAN
- LIKE
- RLIKE
- STARTS_WITH
Binary operators
支持以下二进制比较运算符:
- 等于:==
- 不等式:!=
- 小于:<
- 小于或等于:<=
- 大于:>
- 大于或等于:>=
逻辑运算符
支持以下逻辑运算符:
ANDORNOT
IS NULL 和 IS NOT NULL 谓词
对于 NULL 比较,请使用 IS NULL 和 IS NOT NULL 谓词:
FROM employees
| WHERE birth_date IS NULL
| KEEP first_name, last_name
| SORT first_name
| LIMIT 3| first_name:keyword | last_name:keyword |
|---|---|
| Basil | Tramer |
| Florian | Syrotiuk |
| Lucien | Rosenbaum |
FROM employees
| WHERE is_rehired IS NOT NULL
| STATS COUNT(emp_no)| COUNT(emp_no):long |
|---|
| 84 |
CIDR_MATCH
如果提供的 IP 包含在提供的 CIDR 块之一中,则返回 true。
CIDR_MATCH 接受两个或多个参数。 第一个参数是 ip 类型的 IP 地址(支持 IPv4 和 IPv6)。 后续参数是用于测试 IP 的 CIDR 块。
FROM hosts
| WHERE CIDR_MATCH(ip, "127.0.0.2/32", "127.0.0.3/32")ENDS_WITH

返回一个布尔值,指示关键字字符串是否以另一个字符串结尾:
FROM employees
| KEEP last_name
| EVAL ln_E = ENDS_WITH(last_name, "d")| last_name:keyword | ln_E:boolean |
|---|---|
| Awdeh | false |
| Azuma | false |
| Baek | false |
| Bamford | true |
| Bernatsky | false |
支持的类型:
| arg1 | arg2 | result |
|---|---|---|
| keyword | keyword | boolean |
IN
IN 运算符允许测试字段或表达式是否等于文字、字段或表达式列表中的元素:
ROW a = 1, b = 4, c = 3
| WHERE c-a IN (3, b / 2, a)IS_FINITE
返回一个布尔值,指示其输入是否是有限数。
ROW d = 1.0
| EVAL s = IS_FINITE(d/0)IS_INFINITE
返回一个布尔值,指示其输入是否是无限的。
ROW d = 1.0
| EVAL s = IS_INFINITE(d/0)IS_NAN
返回一个布尔值,指示其输入是否不是数字。
ROW d = 1.0
| EVAL s = IS_NAN(d)LIKE
使用 LIKE 使用通配符根据字符串模式过滤数据。 LIKE 通常作用于位于运算符左侧的字段,但它也可以作用于常量(文字)表达式。 运算符的右侧代表模式。
支持以下通配符:
- * 匹配零个或多个字符。
- ? 匹配一个字符。
FROM employees
| WHERE first_name LIKE "?b*"
| KEEP first_name, last_nameRLIKE
使用 RLIKE 使用正则表达式根据字符串模式过滤数据。 RLIKE 通常作用于位于运算符左侧的字段,但它也可以作用于常量(文字)表达式。 运算符的右侧代表模式。
FROM employees
| WHERE first_name RLIKE ".leja.*"
| KEEP first_name, last_nameSTARTS_WITH

返回一个布尔值,指示关键字字符串是否以另一个字符串开头:
FROM employees
| KEEP last_name
| EVAL ln_S = STARTS_WITH(last_name, "B")| last_name:keyword | ln_S:boolean |
|---|---|
| Awdeh | false |
| Azuma | false |
| Baek | true |
| Bamford | true |
| Bernatsky | true |
支持的类型:
| arg1 | arg2 | result |
|---|---|---|
| keyword | keyword | boolean |
相关文章:
Elasticsearch:ES|QL 函数及操作符
如果你对 ES|QL 还不是很熟悉的话,请阅读之前的文章 “Elasticsearch:ES|QL 查询语言简介”。ES|QL 提供了一整套用于处理数据的函数和运算符。 功能分为以下几类: 目录 ES|QL 聚合函数 AVG COUNT COUNT_DISTINCT 计数为近…...
SpringBoot——Swagger2 接口规范
优质博文:IT-BLOG-CN 如今,REST和微服务已经有了很大的发展势头。但是,REST规范中并没有提供一种规范来编写我们的对外REST接口API文档。每个人都在用自己的方式记录api文档,因此没有一种标准规范能够让我们很容易的理解和使用该…...
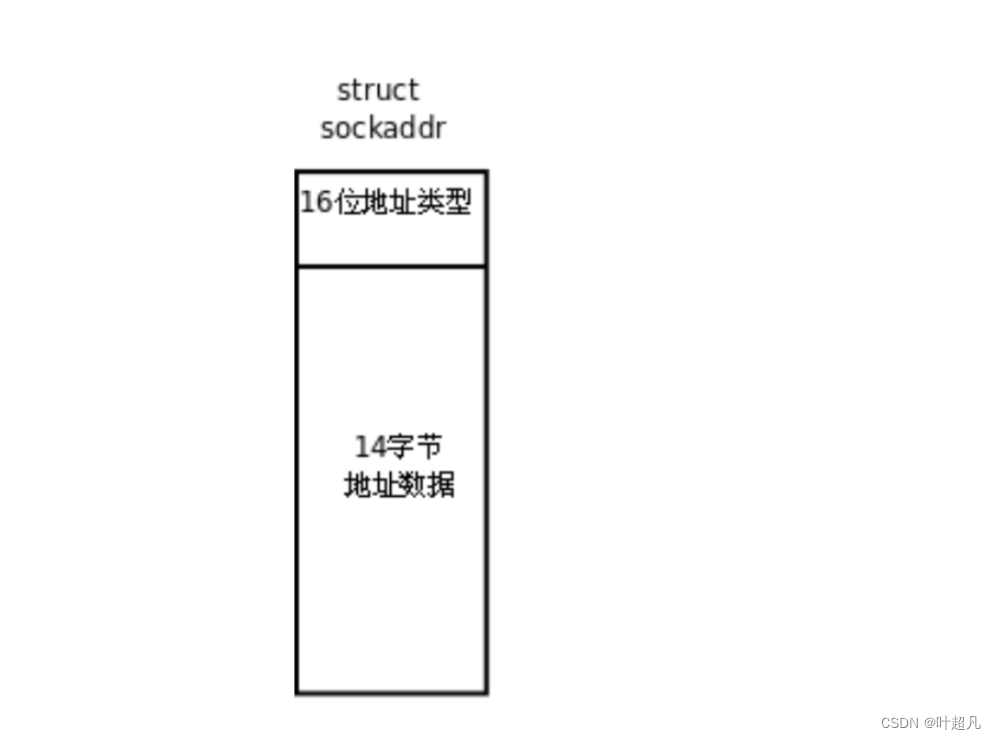
网络入门---网络编程预备知识
目录标题 ifconfigip地址和mac地址的区别端口号pid和端口号UDP和TCP的初步了解网络字节序socket套接字 ifconfig 通过指令ifconfig便可以查看到两个网络接口: 我们当前使用的是一个linux服务器并是一个终端设备,所以他只需要一个接口用来入网即可&…...

记录一次YAMLException异常
记录一次YAMLException异常 ✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: 报错以及B…...

calendar --- 日历相关函数
calendar --- 日历相关函数 源代码: Lib/calendar.py 这个模块让你可以输出像 Unix cal 那样的日历,它还提供了其它与日历相关的实用函数。 默认情况下,这些日历把星期一作为一周的第一天,星期天作为一周的最后一天(这…...

中国信息通信研究院产业与规划研究所校招一面、二面内容
本文介绍2024届秋招中,中国信息通信研究院的数字孪生智慧城市研究员岗位一面、二面的面试基本情况、提问问题等。 10月投递了中国信息通信研究院的数字孪生智慧城市研究员岗位,所在部门为数字孪生与城市数字化研究部。目前完成了一面与二面,在…...

一些数据库学习的小结
一些数据库学习的小结: SQL: 遵循ACID原则。支持Transaction。适合在线交易处理(OLTP),不适合在线分析处理(OLAP)。例子有 MySQL 读写效率 单机约1KQPS POSTGRESQL NoSQL: 遵循BASE原则。不支持Transaction。例子有 DynamoDB - Amazon Key-Value BigTa…...
【计算机网络】虚拟路由冗余(VRRP)协议原理与配置
目录 1、VRRP虚拟路由器冗余协议 1.1、协议作用 1.2、名词解释 1.3、简介 1.4、工作原理 1.5、应用实例 2、 VRRP配置 2.1、配置命令 1、VRRP虚拟路由器冗余协议 1.1、协议作用 虚拟路由冗余协议(Virtual Router Redundancy Protocol,简称VRRP)是由IETF…...

Using Set Processing Examples 使用集合处理示例
Using Set Processing Examples 使用集合处理示例 Each of the following topics contains an example of set processing. 以下每个主题都包含一个集处理示例。 Payroll 工资单 In this example, suppose the payroll department needs to give a 1000 USD salary increase to…...
Spark将execl表格文件导入到mysql中
实现代码 excel所需的pom依赖 案例实现 实现代码 package excel_mysqlimport org.apache.spark.sql.SparkSession import java.util.Propertiesobject t1 {def main(args: Array[String]): Unit {val spark SparkSession.builder().appName("ExcelToMySQL") /…...
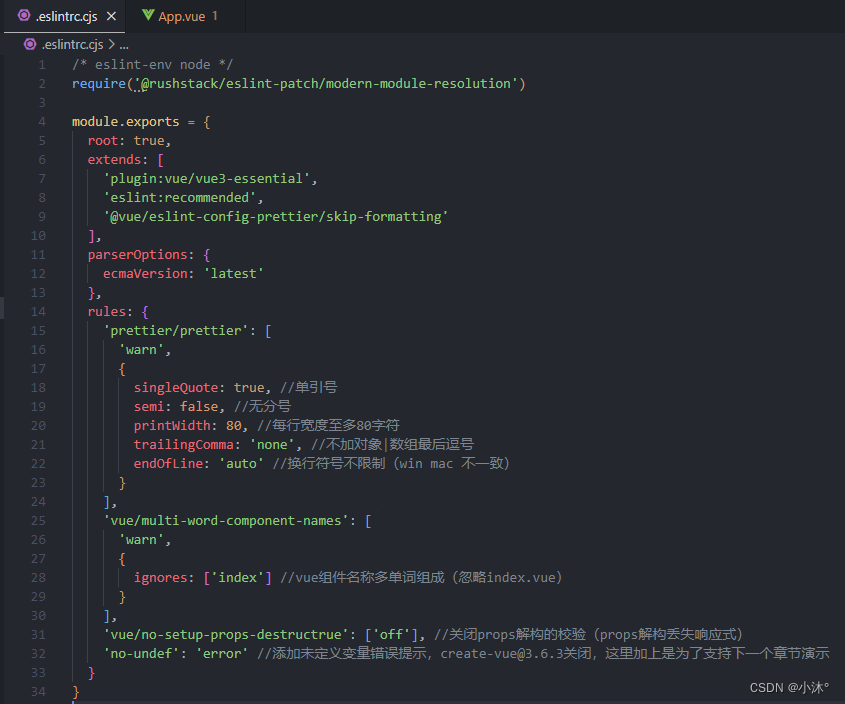
Vue3-Eslint配置代码风格
prettier风格配置 官网:https://prettier.io Eslint:代码纠错,关注于规范 prettier:专注于代码格式化的插件,让代码更加美观 两者各有所长,配合使用优化代码 生效前提: 1)禁用…...

“Install Js dependencies failed“JS SDK安装失败【Bug已解决-鸿蒙开发】
文章目录 项目场景:问题描述原因分析:解决方案:解决措施1解决方案2:其他解决方案解决方案3:此Bug解决方案总结项目场景: 在下载JS SDK时,出现下载失败的情况,并显示“Install Js dependencies failed”。 在使用版本为DevEco Studio 3.0.0.601 Beta1进行低代码开发时…...

接口测试入门8问(含答案+文档)
Q1:什么是接口测试,基础知识什么的讲讲吧! A:你好,接口可以分下面几种 1、系统与系统之间的调用,比如银行会提供接口供电子商务网站调用,或者说,支付宝会提供接口给淘宝调用 2、上…...

【Spring之事务底层源码解析,持续更新中~~~】
文章目录 一、EnableTransactionManagement工作原理二、Spring事务基本执行原理三、Spring事务传播机制与分类四、Spring事务强制回滚五、TransactionSynchronization六、Spring事务详细执行流程 一、EnableTransactionManagement工作原理 二、Spring事务基本执行原理 三、Sp…...

吃火锅(Python)
题目描述 吃火锅 以上图片来自微信朋友圈:这种天气你有什么破事打电话给我基本没用。但是如果你说“吃火锅”,那就厉害了,我们的故事就开始了。 本题要求你实现一个程序,自动检查你朋友给你发来的信息里有没有 chi1 huo3 guo1。…...

深圳市东星制冷机电受邀莅临2024国际生物发酵展,济南与您相约
深圳市东星制冷机电有限公司受邀莅临2024国际生物发酵展,济南3月5-7日与您相约! 展位号:1号馆A53 深圳市东星制冷机电有限公司,(东星集团)是一家专业生产制冷设备的外商独资大型集团企业,拥有30多年的生产…...
内网渗透(哈希传递)
概念 早期SMB协议明文在网络上传输数据,后来诞生了LM验证机制,LM机制由于过于简单,微软提出了WindowsNT挑战/响应机制,这就是NTLM。 哈希传递前提 同密码(攻击主机与实现主机两台要密码一致)。 NTLM协议 加密ntlm哈希 转换成…...

如何在langchain中对大模型的输出进行格式化
简介 我们知道在大语言模型中, 不管模型的能力有多强大,他的输入和输出基本上都是文本格式的,文本格式的输入输出虽然对人来说非常的友好,但是如果我们想要进行一些结构化处理的话还是会有一点点的不方便。 不用担心,langchain已…...

【送书活动二期】Java和MySQL数据库中关于小数的保存问题
之前总结过一篇文章mysql数据库:decimal类型与decimal长度用法详解,主要是个人学习期间遇到的mysql中关于decimal字段的详解,最近在群里遇到一个小伙伴提出的问题,也有部分涉及,今天就再大致总结一下Java和MySQL数据库…...

11月21日,每日信息差
今天是2023年11月21日,以下是为您准备的16条信息差 第一、国内首条PPP模式市域铁路台州S1线客运量破900万人次。PPP(Public-Private Partnership)是公共基础设施的一种项目运作模式,指社会资本与政府合作,参与公共基础…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

从开题到定稿零焦虑:okbiye AI 论文写作,帮你把毕业季的 “大山” 变成坦途
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的深夜,宿舍台灯下的屏幕亮着刺眼的光,文档里的字数停留在三位数,而 deadline 正一天天逼近。你是…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...