如何在langchain中对大模型的输出进行格式化
简介
我们知道在大语言模型中, 不管模型的能力有多强大,他的输入和输出基本上都是文本格式的,文本格式的输入输出虽然对人来说非常的友好,但是如果我们想要进行一些结构化处理的话还是会有一点点的不方便。
不用担心,langchain已经为我们想到了这个问题,并且提出了完满的解决方案。
langchain中的output parsers
langchain中所有的output parsers都是继承自BaseOutputParser。这个基础类提供了对LLM大模型输出的格式化方法,是一个优秀的工具类。
我们先来看下他的实现:
class BaseOutputParser(BaseModel, ABC, Generic[T]):@abstractmethoddef parse(self, text: str) -> T:"""Parse the output of an LLM call.A method which takes in a string (assumed output of a language model )and parses it into some structure.Args:text: output of language modelReturns:structured output"""def parse_with_prompt(self, completion: str, prompt: PromptValue) -> Any:"""Optional method to parse the output of an LLM call with a prompt.The prompt is largely provided in the event the OutputParser wantsto retry or fix the output in some way, and needs information fromthe prompt to do so.Args:completion: output of language modelprompt: prompt valueReturns:structured output"""return self.parse(completion)def get_format_instructions(self) -> str:"""Instructions on how the LLM output should be formatted."""raise NotImplementedError@propertydef _type(self) -> str:"""Return the type key."""raise NotImplementedError(f"_type property is not implemented in class {self.__class__.__name__}."" This is required for serialization.")def dict(self, **kwargs: Any) -> Dict:"""Return dictionary representation of output parser."""output_parser_dict = super().dict()output_parser_dict["_type"] = self._typereturn output_parser_dict
BaseOutputParser 是一个基础的类,可能被其他特定的输出解析器继承,以实现特定语言模型的输出解析。
这个类使用了Python的ABC模块,表明它是一个抽象基类(Abstract Base Class),不能被直接实例化,而是需要子类继承并实现抽象方法。
Generic[T] 表示这个类是一个泛型类,其中T 是一个类型变量,它表示解析后的输出数据的类型。
@abstractmethod 装饰器标记了 parse 方法,说明它是一个抽象方法,必须在子类中实现。parse 方法接受一个字符串参数 text,通常是语言模型的输出文本,然后将其解析成特定的数据结构,并返回。
parse_with_prompt 方法也是一个抽象方法,接受两个参数,completion 是语言模型的输出,prompt 是与输出相关的提示信息。这个方法是可选的,可以用于在需要时解析输出,可能根据提示信息来调整输出。
get_format_instructions 方法返回关于如何格式化语言模型输出的说明。这个方法可以用于提供解析后数据的格式化信息。
_type 是一个属性,可能用于标识这个解析器的类型,用于后续的序列化或其他操作。
dict 方法返回一个包含输出解析器信息的字典,这个字典可以用于序列化或其他操作。
其中子类必须要实现的方法就是parse。其他的都做为辅助作用。
langchain中有哪些Output Parser
那么langchain中有哪些Output Parser的具体实现呢?具体对应我们应用中的什么场景呢?
接下来我们将会一一道来。
List parser
ListOutputParser的作用就是把LLM的输出转成一个list。ListOutputParser也是一个基类,我们具体使用的是他的子类:CommaSeparatedListOutputParser。
看一下他的parse方法:
def parse(self, text: str) -> List[str]:"""Parse the output of an LLM call."""return text.strip().split(", ")
还有一个get_format_instructions:
def get_format_instructions(self) -> str:return ("Your response should be a list of comma separated values, ""eg: `foo, bar, baz`")
get_format_instructions是告诉LLM以什么样的格式进行数据的返回。
就是把LLM的输出用逗号进行分割。
下面是一个基本的使用例子:
output_parser = CommaSeparatedListOutputParser()format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(template="列出几种{subject}.\n{format_instructions}",input_variables=["subject"],partial_variables={"format_instructions": format_instructions}
)_input = prompt.format(subject="水果")
output = model(_input)
print(output)
print(output_parser.parse(output))
我们可以得到下面的输出:
Apple, Orange, Banana, Grape, Watermelon, Strawberry, Pineapple, Peach, Mango, Cherry
['Apple', 'Orange', 'Banana', 'Grape', 'Watermelon', 'Strawberry', 'Pineapple', 'Peach', 'Mango', 'Cherry']
看到这里,大家可能有疑问了, 为什么我们问的是中文,返回的却是因为呢?
这是因为output_parser.get_format_instructions就是用英文描述的,所以LLM会自然的用英文来回答。
别急,我们可以稍微修改下运行代码,如下:
output_parser = CommaSeparatedListOutputParser()format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(template="列出几种{subject}.\n{format_instructions}",input_variables=["subject"],partial_variables={"format_instructions": format_instructions + "用中文回答"}
)_input = prompt.format(subject="水果")
output = model(_input)
print(output)
print(output_parser.parse(output))
我们在format_instructions之后,提示LLM需要用中文来回答问题。这样我们就可以得到下面的结果:
苹果,橘子,香蕉,梨,葡萄,芒果,柠檬,桃
['苹果,橘子,香蕉,梨,葡萄,芒果,柠檬,桃']
是不是很棒?
Datetime parser
DatetimeOutputParser用来将LLM的输出进行时间的格式化。
class DatetimeOutputParser(BaseOutputParser[datetime]):format: str = "%Y-%m-%dT%H:%M:%S.%fZ"def get_format_instructions(self) -> str:examples = comma_list(_generate_random_datetime_strings(self.format))return f"""Write a datetime string that matches the following pattern: "{self.format}". Examples: {examples}"""def parse(self, response: str) -> datetime:try:return datetime.strptime(response.strip(), self.format)except ValueError as e:raise OutputParserException(f"Could not parse datetime string: {response}") from e@propertydef _type(self) -> str:return "datetime"
在get_format_instructions中,他告诉LLM返回的结果是一个日期的字符串。
然后在parse方法中对这个LLM的输出进行格式化,最后返回datetime。
我们看下具体的应用:
output_parser = DatetimeOutputParser()
template = """回答下面问题:
{question}
{format_instructions}"""
prompt = PromptTemplate.from_template(template,partial_variables={"format_instructions": output_parser.get_format_instructions()},
)
chain = LLMChain(prompt=prompt, llm=model)
output = chain.run("中华人民共和国是什么时候成立的?")
print(output)
print(output_parser.parse(output))
1949-10-01T00:00:00.000000Z
1949-10-01 00:00:00
回答的还不错,给他点个赞。
Enum parser
如果你有枚举的类型,那么可以尝试使用EnumOutputParser.
EnumOutputParser的构造函数需要传入一个Enum,我们主要看下他的两个方法:
@propertydef _valid_values(self) -> List[str]:return [e.value for e in self.enum]def parse(self, response: str) -> Any:try:return self.enum(response.strip())except ValueError:raise OutputParserException(f"Response '{response}' is not one of the "f"expected values: {self._valid_values}")def get_format_instructions(self) -> str:return f"Select one of the following options: {', '.join(self._valid_values)}"
parse方法接收一个字符串 response,尝试将其解析为枚举类型的一个成员。如果解析成功,它会返回该枚举成员;如果解析失败,它会抛出一个 OutputParserException 异常,异常信息中包含了所有有效值的列表。
get_format_instructions告诉LLM需要从Enum的有效value中选择一个输出。这样parse才能接受到正确的输入值。
具体使用的例子可以参考前面两个parser的用法。篇幅起见,这里就不列了。
Pydantic (JSON) parser
JSON可能是我们在日常代码中最常用的数据结构了,这个数据结构很重要。
在langchain中,提供的JSON parser叫做:PydanticOutputParser。
既然要进行JSON转换,必须得先定义一个JSON的类型对象,然后告诉LLM将文本输出转换成JSON格式,最后调用parse方法把json字符串转换成JSON对象。
我们来看一个例子:
class Student(BaseModel):name: str = Field(description="学生的姓名")age: str = Field(description="学生的年龄")student_query = "告诉我一个学生的信息"parser = PydanticOutputParser(pydantic_object=Student)prompt = PromptTemplate(template="回答下面问题.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()+"用中文回答"},
)_input = prompt.format_prompt(query=student_query)output = model(_input.to_string())
print(output)
print(parser.parse(output))
这里我们定义了一个Student的结构体,然后让LLM给我一个学生的信息,并用json的格式进行返回。
之后我们使用parser.parse来解析这个json,生成最后的Student信息。
我们可以得到下面的输出:
示例输出:{"name": "张三", "age": "18"}
name='张三' age='18'
Structured output parser
虽然PydanticOutputParser非常强大, 但是有时候我们只是需要一些简单的结构输出,那么可以考虑StructuredOutputParser.
我们看一个具体的例子:
response_schemas = [ResponseSchema(name="name", description="学生的姓名"),ResponseSchema(name="age", description="学生的年龄")
]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(template="回答下面问题.\n{format_instructions}\n{question}",input_variables=["question"],partial_variables={"format_instructions": format_instructions}
)_input = prompt.format_prompt(question="给我一个女孩的名字?")
output = model(_input.to_string())
print(output)
print(output_parser.parse(output))
这个例子是上面的PydanticOutputParser的改写,但是更加简单。
我们可以得到下面的结果:
` ` `json
{"name": "Jane","age": "18"
}` ` `
{'name': 'Jane', 'age': '18'}
output返回的是一个markdown格式的json字符串,然后通过output_parser.parse得到最后的json。
其他的一些parser
除了json,xml格式也是比较常用的格式,langchain中提供的XML parser叫做XMLOutputParser。
另外,如果我们在使用parser的过程中出现了格式问题,langchain还贴心的提供了一个OutputFixingParser。也就是说当第一个parser报错的时候,或者说不能解析LLM输出的时候,就会换成OutputFixingParser来尝试修正格式问题:
from langchain.output_parsers import OutputFixingParsernew_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())new_parser.parse(misformatted)如果错误不是因为格式引起的,那么langchain还提供了一个RetryOutputParser,来尝试重试:
from langchain.output_parsers import RetryWithErrorOutputParserretry_parser = RetryWithErrorOutputParser.from_llm(parser=parser, llm=OpenAI(temperature=0)
)retry_parser.parse_with_prompt(bad_response, prompt_value)
这几个parser都非常有用,大家可以自行尝试。
总结
虽然langchain中的有些parser我们可以自行借助python语言的各种工具来实现。但是有一些parser实际上是要结合LLM一起来使用的,比如OutputFixingParser和RetryOutputParser。
所以大家还是尽可能的使用langchain提供的parser为好。毕竟轮子都给你造好了,还要啥自行车。
相关文章:

如何在langchain中对大模型的输出进行格式化
简介 我们知道在大语言模型中, 不管模型的能力有多强大,他的输入和输出基本上都是文本格式的,文本格式的输入输出虽然对人来说非常的友好,但是如果我们想要进行一些结构化处理的话还是会有一点点的不方便。 不用担心,langchain已…...

【送书活动二期】Java和MySQL数据库中关于小数的保存问题
之前总结过一篇文章mysql数据库:decimal类型与decimal长度用法详解,主要是个人学习期间遇到的mysql中关于decimal字段的详解,最近在群里遇到一个小伙伴提出的问题,也有部分涉及,今天就再大致总结一下Java和MySQL数据库…...

11月21日,每日信息差
今天是2023年11月21日,以下是为您准备的16条信息差 第一、国内首条PPP模式市域铁路台州S1线客运量破900万人次。PPP(Public-Private Partnership)是公共基础设施的一种项目运作模式,指社会资本与政府合作,参与公共基础…...

极速整理文件!Python自动化办公新利器
更多资料获取 📚 个人网站:ipengtao.com 当涉及到自动化办公和文件整理,Python确实是一个强大的工具。在这篇博客文章中,我将深入探讨《极速整理文件!Python自动化办公新利器》这个话题,并提供更加丰富和全…...

电机控制学习
电机开发板...

leetcode 1670
leetcode 1670 解题思路 使用2个deque作为类的成员变量 code class FrontMiddleBackQueue { public:deque<int> left;deque<int> right;FrontMiddleBackQueue() {}void pushFront(int val) {left.push_front(val);if(left.size() right.size()2){right.push_fr…...

Nginx热部署
快捷查看指令 ctrlf 进行搜索会直接定位到需要的知识点和命令讲解(如有不正确的地方欢迎各位小伙伴在评论区提意见,小编会及时修改) Nginx热部署 首先来讲一下为什么要进行热部署 nginx 支持热加载 热部署 ,在不打断用户请求的情…...

京东数据运营-京东数据平台-京东店铺数据分析-2023年10月京东烘干机品牌销售榜
鲸参谋监测的京东平台10月份烘干机市场销售数据已出炉! 10月份,烘干机市场整体销售上涨。鲸参谋数据显示,今年10月份,京东平台上烘干机的销量将近5万件,环比增长约77%,同比增长约22%;销售额将近…...

java中的方法引用和Stream流
知识模块: 一.方法引用a.方法概述b.方法引用格式 二.Stream流1.Stream流概述2.Stream流操作步骤一.方法引用a.方法概述/*方法引用概述:当我们使用已有类中的方法作为Lambda表达式对应的接口中的抽象方法实现我们可以用方法引用来简化Lambda表达式*/impor…...
《第一行代码:Android》第三版-3.4.4体验Activity的生命周期
本文的代码是在主Activity中,重载了几个生命周期函数,在日志中打印出对应的日志信息,有两个按钮,负责启动另外的Activity,并回到主Activity 由此查看日志,来体会生命周期。 MainActivity.kt 文件如下 pac…...

用java编写一个网络聊天室
网络聊天室 服务器: 1.启动服务器,在服务器端循环监听客户端的连接 try {ServerSocket serverSocketnew ServerSocket(6622);System.out.println("服务器已启动");while(true){//把客户端实例添加到sockets里Socket socketserverSocket.acc…...

Opencv颜色追踪
废话不多说直接上代码!! # 这是一个示例 Python 脚本。 import cv2 import numpy as npdef track_object():# 打开摄像头外接cap cv2.VideoCapture(0)while True:# 读取摄像头帧# ret(Return Value)是一个布尔值,表示…...
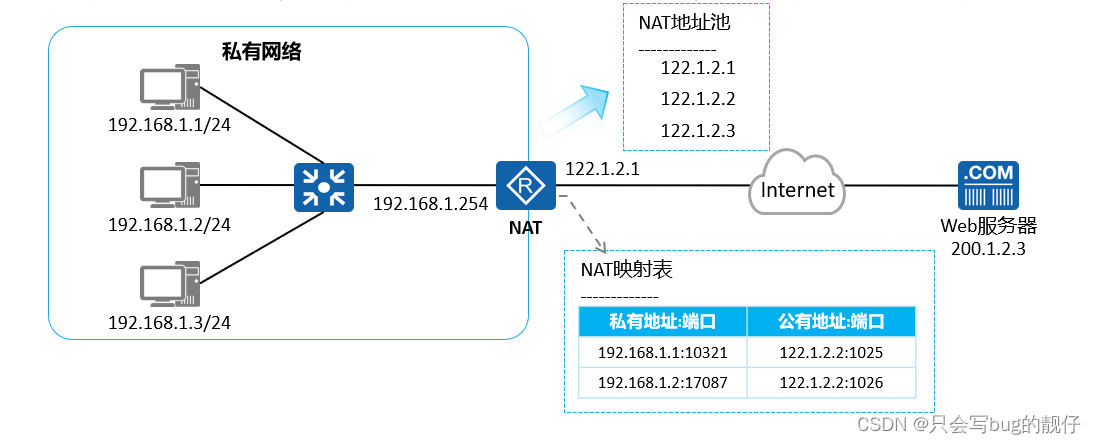
计算机网络——网络可靠性及网络出口配置
1. 前言: 学习目标: 1.了解链路聚合的作用 2. 了解ACL的工作原理 3. 了解NAT的工作原理和配置 2. 网络可靠性方案 网络可靠性是指网络在面对各种异常情况或故障时,能够维持正常运行和提供服务的能力。这包括防止网络中断、减小数据丢失的可能…...
在虚拟机搭建nignx,和使用本地访问nginx的情况
下载nginx yum install nginx 查看nginx是否安装成功。 nginx -v nginx的配置文件的目录和资源的目录。 先到nginx.conf的目录下,在 /etc/nginx/nginx.conf,编辑它。 vi /etc/nginx/nginx.conf 可以看到默认的html的目录。在 /usr/share/nginx/html 下面…...
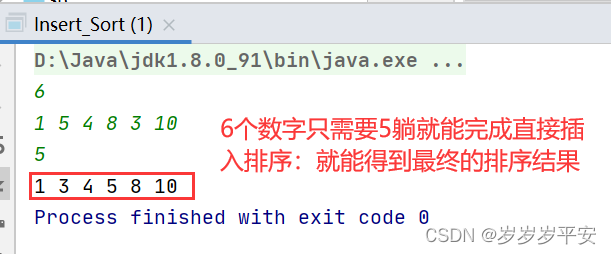
Java数据结构之《直接插入排序》问题
一、前言: 这是怀化学院的:Java数据结构中的一道难度中等的一道编程题(此方法为博主自己研究,问题基本解决,若有bug欢迎下方评论提出意见,我会第一时间改进代码,谢谢!) 后面其他编程题只要我写完…...

向量场中的几个恒等式
向量场中的几个恒等式 1. ∇ 2 A ∇ ∇ ⋅ A − ∇ ∇ A \nabla ^2 A \nabla \nabla\cdot A-\nabla \times\nabla\times A ∇2A∇∇⋅A−∇∇A 2. ∇ ⋅ ∇ A 0 \nabla \cdot \nabla \times A 0 ∇⋅∇A0 3. ∇ ∇ ϕ 0 \nabla \times \nabla \phi0 ∇∇ϕ0...
)
异行星低代码平台--第三方插件对接:钉钉平台对接(一)
异行星低代码平台可以集成钉钉,实现单点登录、消息推送和组织机构同步。 提示 此功能需要企业版授权才能使用。 钉钉集成 单点登录 异行星低代码平台集成到钉钉后,只要使用钉钉账户登录钉钉客户端,即可在钉钉中直接使用管理后台&#…...

MyBatis使用教程详解<下>
回顾上一篇博文,我们讲了如何使用注解/XML的方式来操作数据库,实际上,一个Mapper接口的实现,这两种方式是可以并存的. 上一篇博文中,我们演示的都是比较简单的SQL语句,没有设计到复杂的逻辑,本篇博文会讲解复杂SQL的实现及一些细节处理.话不多说,让我们开始吧. 一. #{}和${} …...
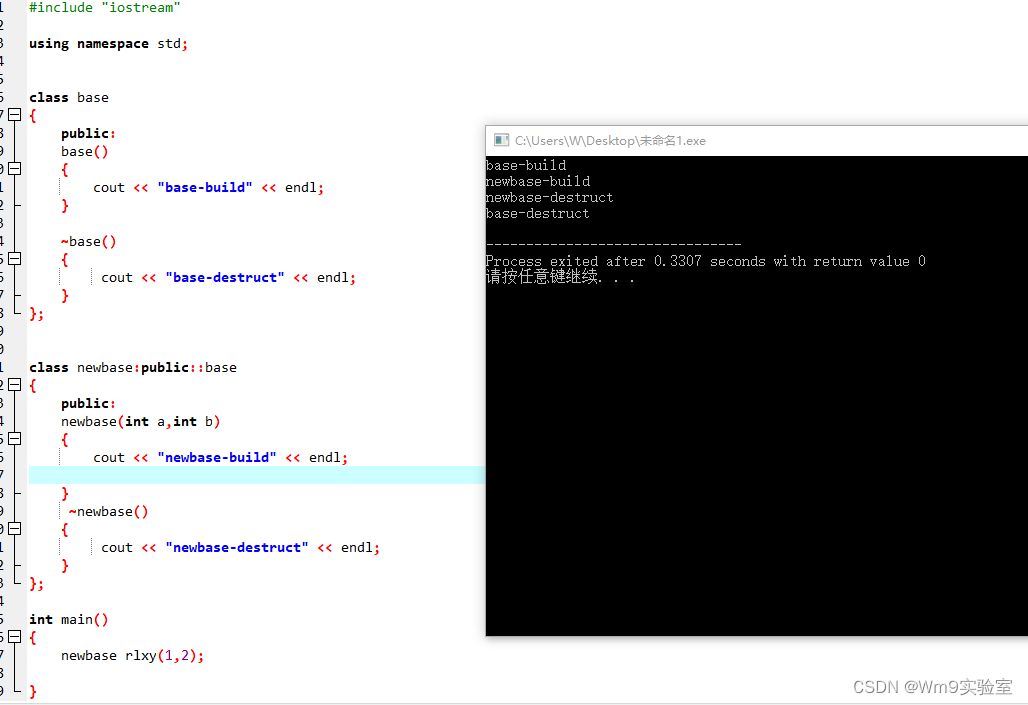
C++基础 -17-继承中 基类与派生构造和析构调用顺序
首先声明 定义了派生类会同时调用基类和派生的构造函数 定义了派生类会同时调用基类和派生的析构函数 那么顺序如何如下图 构造由上往下顺序执行 析构则完全相反 #include "iostream"using namespace std;class base {public:base(){cout << "base-bui…...
uniapp实现表单弹窗
uni.showModal({title: 删除账户,confirmColor:#3A3A3A,cancelColor:#999999,confirmText:确定,editable:true,//显示content:请输入“delete”删除账户,success: function (res) {console.log(res)if(res.confirm){if(res.contentdelete){console.log(123123123213)uni.setSto…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

除了排错,你可能不知道OPC Expert v8.1还能做这些:数据归档、计算与冗余实战
解锁OPC Expert v8.1的隐藏潜力:数据归档、实时计算与冗余架构实战指南在工业自动化领域,OPC Expert常被视为故障排查的"急救箱",但它的能力远不止于此。当大多数工程师还在用它解决DCOM配置问题时,少数先行者已经用它重…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪?
DAIR-V2X-V数据集深度评测:与KITTI、nuScenes比,它到底强在哪? 当技术团队着手开发面向中国道路的自动驾驶系统时,数据集的选择往往成为第一个关键决策点。过去十年间,KITTI和nuScenes等国际数据集一直是行业标杆&…...

Go开发者必备:circuitbreaker API全解析与最佳实践指南 [特殊字符]
Go开发者必备:circuitbreaker API全解析与最佳实践指南 🚀 【免费下载链接】circuitbreaker Circuit Breakers in Go 项目地址: https://gitcode.com/gh_mirrors/circ/circuitbreaker 作为一名Go开发者,你是否经常遇到远程服务调用失败…...
)
保姆级教程:手把手教你搞定ESXi 6.7安装前的BIOS设置(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7安装前的BIOS设置终极指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我记得自己第一次在Dell PowerEdge服务器上安装ESXi时,光是搞清楚BIOS里那些晦涩的选项就花了整整一…...