21- 神经网络模型_超参数搜索 (TensorFlow系列) (深度学习)
知识要点
-
fetch_california_housing:加利福尼亚的房价数据,总计20640个样本,每个样本8个属性表示,以及房价作为target
-
超参数搜索的方式: 网格搜索, 随机搜索, 遗传算法搜索, 启发式搜索
-
超参数训练后用: gv.estimator调取最佳模型
-
函数式添加神经网络:
-
model.add(keras.layers.Dense(layer_size, activation = 'relu'))
-
model.compile(loss = 'mse', optimizer = optimizer) # optimizer = keras.optimizers.SGD (learning_rate)
-
sklearn_model = KerasRegressor(build_fn = build_model)
-
from tensorflow.keras.wrappers.scikit_learn import KerasRegressor # 回归神经网络
# 搜索最佳学习率
def build_model(hidden_layers = 1, layer_size = 30, learning_rate = 3e-3):model = keras.models.Sequential()model.add(keras.layers.Dense(layer_size, activation = 'relu', input_shape = x_train.shape[1:]))for _ in range(hidden_layers - 1):model.add(keras.layers.Dense(layer_size, activation = 'relu'))model.add(keras.layers.Dense(1))optimizer = keras.optimizers.SGD(learning_rate)model.compile(loss = 'mse', optimizer = optimizer)# model.summary()return model
sklearn_model = KerasRegressor(build_fn = build_model)-
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)] # 回调函数设置
-
gv = GridSearchCV(sklearn_model, param_grid = params, n_jobs = 1, cv= 5,verbose = 1) # 找最佳参数
-
gv.fit(x_train_scaled, y_train)
1 导包
from tensorflow import keras
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
cpu=tf.config.list_physical_devices("CPU")
tf.config.set_visible_devices(cpu)
print(tf.config.list_logical_devices())2 导入数据
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housinghousing = fetch_california_housing()
x_train_all, x_test, y_train_all, y_test = train_test_split(housing.data,housing.target,random_state= 7)
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all,random_state = 11)3 标准化处理数据
from sklearn.preprocessing import StandardScaler, MinMaxScalerscaler =StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)4 函数式定义模型
from tensorflow.keras.wrappers.scikit_learn import KerasRegressor # 回归神经网络
# 搜索最佳学习率
def build_model(hidden_layers = 1, layer_size = 30, learning_rate = 3e-3):model = keras.models.Sequential()model.add(keras.layers.Dense(layer_size, activation = 'relu', input_shape = x_train.shape[1:]))for _ in range(hidden_layers - 1):model.add(keras.layers.Dense(layer_size, activation = 'relu'))model.add(keras.layers.Dense(1))optimizer = keras.optimizers.SGD(learning_rate)model.compile(loss = 'mse', optimizer = optimizer)# model.summary()return model
sklearn_model = KerasRegressor(build_fn = build_model) 
5 模型训练
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]
history = sklearn_model.fit(x_train_scaled, y_train, epochs = 10,validation_data = (x_valid_scaled, y_valid), callbacks = callbacks)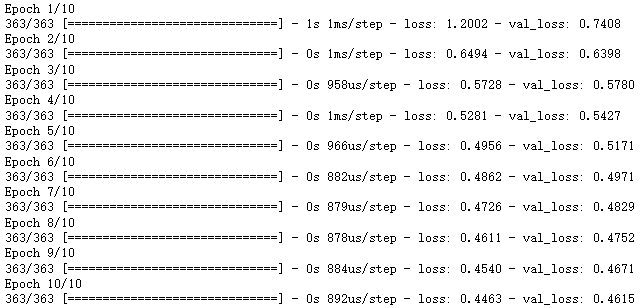
6 超参数搜索
超参数搜索的方式:
-
网格搜索
-
定义n维方格
-
每个方格对应一组超参数
-
一组一组参数尝试
-
-
随机搜索
-
遗传算法搜索
-
对自然界的模拟
-
A: 初始化候选参数集合 --> 训练---> 得到模型指标作为生存概率
-
B: 选择 --> 交叉--> 变异 --> 产生下一代集合
-
C: 重新到A, 循环.
-
-
启发式搜索
-
研究热点-- AutoML的一部分
-
使用循环神经网络来生成参数
-
使用强化学习来进行反馈, 使用模型来训练生成参数.
-
# 使用sklearn 的网格搜索, 或者随机搜索
from sklearn.model_selection import GridSearchCV, RandomizedSearchCVparams = {'learning_rate' : [1e-4, 3e-4, 1e-3, 3e-3, 1e-2, 3e-2],'hidden_layers': [2, 3, 4, 5], 'layer_size': [20, 60, 100]}gv = GridSearchCV(sklearn_model, param_grid = params, n_jobs = 1, cv= 5,verbose = 1)
gv.fit(x_train_scaled, y_train)- 输出最佳参数
# 最佳得分
print(gv.best_score_) # -0.47164334654808043
# 最佳参数
print(gv.best_params_) # {'hidden_layers': 5,'layer_size': 100,'learning_rate':0.01}
# 最佳模型
print(gv.estimator)
'''<keras.wrappers.scikit_learn.KerasRegressor object at 0x0000025F5BB12220>'''
gv.score
7 最佳参数建模
model = keras.models.Sequential()
model.add(keras.layers.Dense(100, activation = 'relu', input_shape = x_train.shape[1:]))
for _ in range(4):model.add(keras.layers.Dense(100, activation = 'relu'))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(0.01)
model.compile(loss = 'mse', optimizer = optimizer)
model.summary()
callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-3)]
history = model.fit(x_train_scaled, y_train, epochs = 10,validation_data = (x_valid_scaled, y_valid), callbacks = callbacks)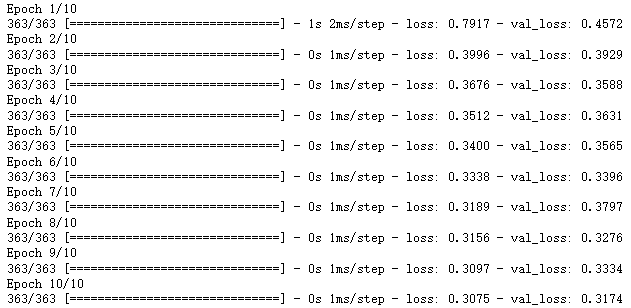
8 手动实现超参数搜索
- 根据参数进行多次模型的训练, 然后记录 loss
# 搜索最佳学习率
learning_rates = [1e-4, 3e-4, 1e-3, 3e-3, 1e-2, 3e-2]
histories = []
for lr in learning_rates:model = keras.models.Sequential([keras.layers.Dense(30, activation = 'relu', input_shape = x_train.shape[1:]),keras.layers.Dense(1)])optimizer = keras.optimizers.SGD(lr)model.compile(loss = 'mse', optimizer = optimizer, metrics = ['mse'])callbacks = [keras.callbacks.EarlyStopping(patience = 5, min_delta = 1e-2)]history = model.fit(x_train_scaled, y_train, validation_data = (x_valid_scaled, y_valid), epochs = 100, callbacks = callbacks)histories.append(history) 
# 画图
import pandas as pd
def plot_learning_curves(history):pd.DataFrame(history.history).plot(figsize = (8, 5))plt.grid(True)plt.gca().set_ylim(0, 1)plt.show()for lr, history in zip(learning_rates, histories): print(lr)plot_learning_curves(history) 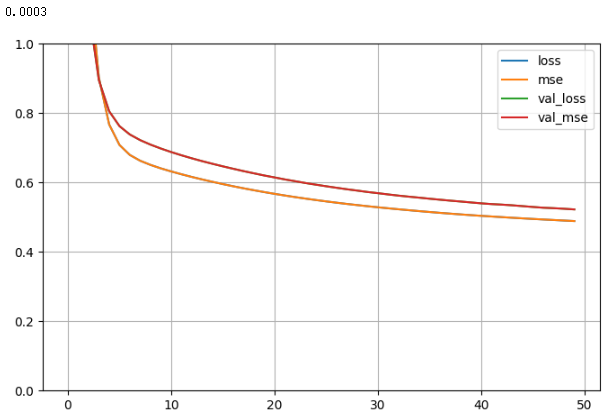
相关文章:
21- 神经网络模型_超参数搜索 (TensorFlow系列) (深度学习)
知识要点 fetch_california_housing:加利福尼亚的房价数据,总计20640个样本,每个样本8个属性表示,以及房价作为target 超参数搜索的方式: 网格搜索, 随机搜索, 遗传算法搜索, 启发式搜索 超参数训练后用: gv.estimat…...

《NFL橄榄球》:芝加哥熊·橄榄1号位
芝加哥熊(英语:Chicago Bears)是一支职业美式橄榄球球队。位于伊利诺伊州的芝加哥。现时为全国橄榄球联盟的国家联盟北区的球队。他们曾经赢出九次美式橄榄球比赛的冠军,分别为八次旧制全国橄榄球联盟和一次超级碗冠军(…...

【ES】Elasticsearch核心基础概念:文档与索引
es的核心概念主要是:index(索引)、Document(文档)、Clusters(集群)、Node(节点)与实例,下面我们先来了解一下Document与Index。 RESTful APIs 在讲解Document与Index概念之前,我们先来了解一下RESTful APIs,因为下面讲解Documen…...
实时手势识别(C++与python都可实现)
一、前提配置: Windows,visual studio 2019,opencv,python10,opencv-python,numpy,tensorflow,mediapipe,math 1.安装python环境 这里我个人使用的安装python10&#…...
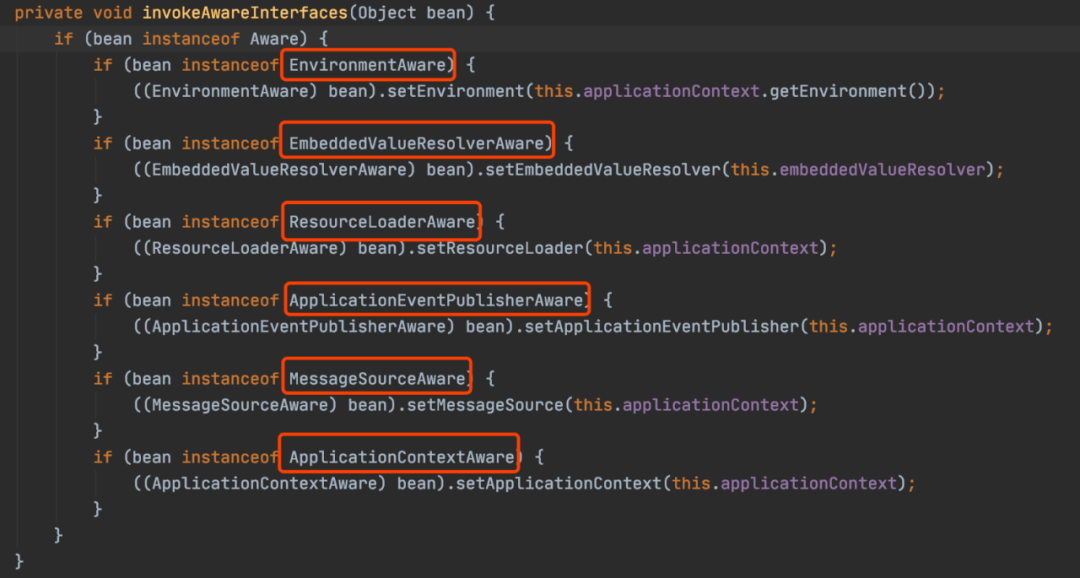
15个Spring扩展点,一般人知道的不超过5个!
Spring的核心思想就是容器,当容器refresh的时候,外部看上去风平浪静,其实内部则是一片惊涛骇浪,汪洋一片。Spring Boot更是封装了Spring,遵循约定大于配置,加上自动装配的机制。很多时候我们只要引用了一个…...

Elasticsearch:以 “Painless” 方式保护你的映射
Elasticsearch 是一个很棒的工具,可以从各种来源收集日志和指标。 它为我们提供了许多默认处理,以便提供最佳用户体验。 但是,在某些情况下,默认处理可能不是最佳的(尤其是在生产环境中); 因此&…...
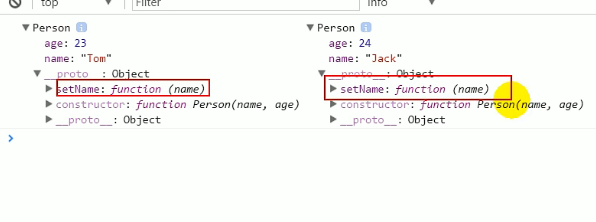
js几种对象创建方式
适用于不确定对象内部数据方式一:var p new Object(); p.name TOM; p.age 12 p.setName function(name) {this.name name; }// 测试 p.setName(jack) console.log(p.name,p.age)方式二: 对象字面量模式套路:使用{}创建对象,同…...

阿里云服务器ECS适用于哪些应用场景?
云服务器ECS具有广泛的应用场景,既可以作为Web服务器或者应用服务器单独使用,又可以与其他阿里云服务集成提供丰富的解决方案。 云服务器ECS的典型应用场景包括但不限于本文描述,您可以在使用云服务器ECS的同时发现云计算带来的技术红利。 阿…...
Ajax学习笔记01
引入 翻译成中文就是“异步的Javascript和XML”。即使用Javascript语言与服务器进行异步交互,传输的数据为XML(当然,传输的数据不只是XML)。 AJAX 不是新的编程语言,而是一种使用现有标准的新方法。 AJAX 最大的优点…...
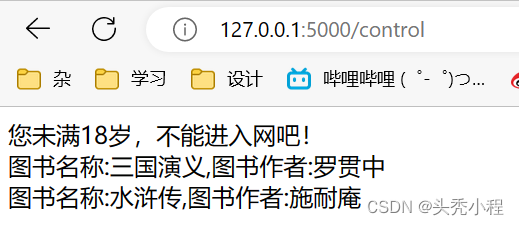
Jinja2----------过滤器的使用、控制语句
目录 1.过滤器的使用 1.过滤器和测试器 2.过滤器 templates/filter.html app.py 效果 3.自定义过滤器 app.py templates/filter.html 效果 2.控制语句 1.if app.py templates/control.html 2.for app.py templates/control.htm 1.过滤器的使用 1.过滤器和测…...
面试了1个自动化测试,开口40W年薪,只能说痴人做梦...
公司前段缺人,也面了不少测试,结果竟然没有一个合适的。一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资在10-20k,面试的人很多,但平均水平很让人失望。看简历很多都是3年工作经验,但面试…...
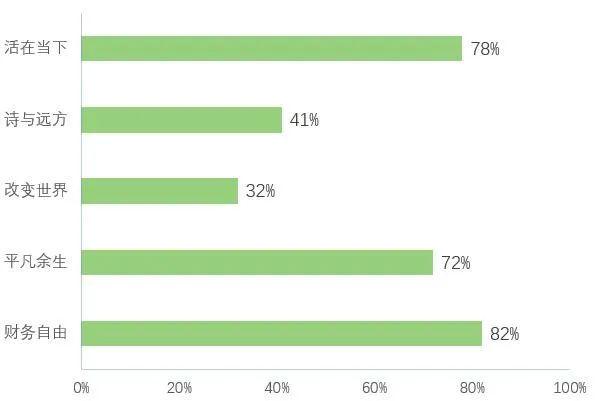
冲鸭!33% 程序员月薪达到 5 万元以上~
2023年,随着互联网产业的蓬勃发展,程序员作为一个自带“高薪多金”标签的热门群体,被越来越多的人所关注。在过去充满未知的一年中,他们的职场现状发生了一定的改变。那么,程序员岗位的整体薪资水平、婚恋现状、职业方…...
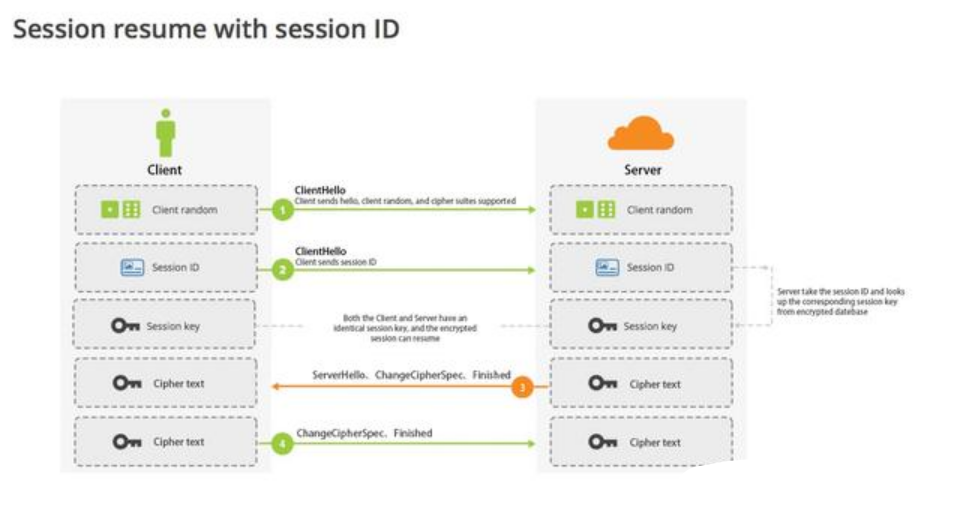
【RSA】HTTPS中SSL/TLS握手时RSA前后端加密流程
SSL/TLS层的位置 SSL/TLS层在网络模型的位置,它属于应用层协议。接管应用层的数据加解密,并通过网络层发送给对方。 SSL/TLS协议分握手协议和记录协议,握手协议用来协商会话参数(比如会话密钥、应用层协议等等)&…...

clion在linux设置桌面启动图标(jetbrains全家桶均适用)
clion在linux设置桌面启动图标(jetbrains全家桶均适用) 网上大部分步骤都只是pycharm的教程,其实对于jetbrains全家桶都适合,vs code编辑器也可以这样。 刚开始是使用pycharm在linux设置的教程,参照:http…...
Java数据结构LinkedList单链表和双链表模拟实现及相关OJ题秒AC总结知识点
本篇文章主要讲述LinkedList链表中从初识到深入相关总结,常见OJ题秒AC,望各位大佬喜欢 一、单链表 1.1链表的概念及结构 1.2无头单向非循环链表模拟实现 1.3测试模拟代码 1.4链表相关面试OJ题 1.4.1 删除链表中等于给定值 val 的所有节点 1.4.2 反转…...
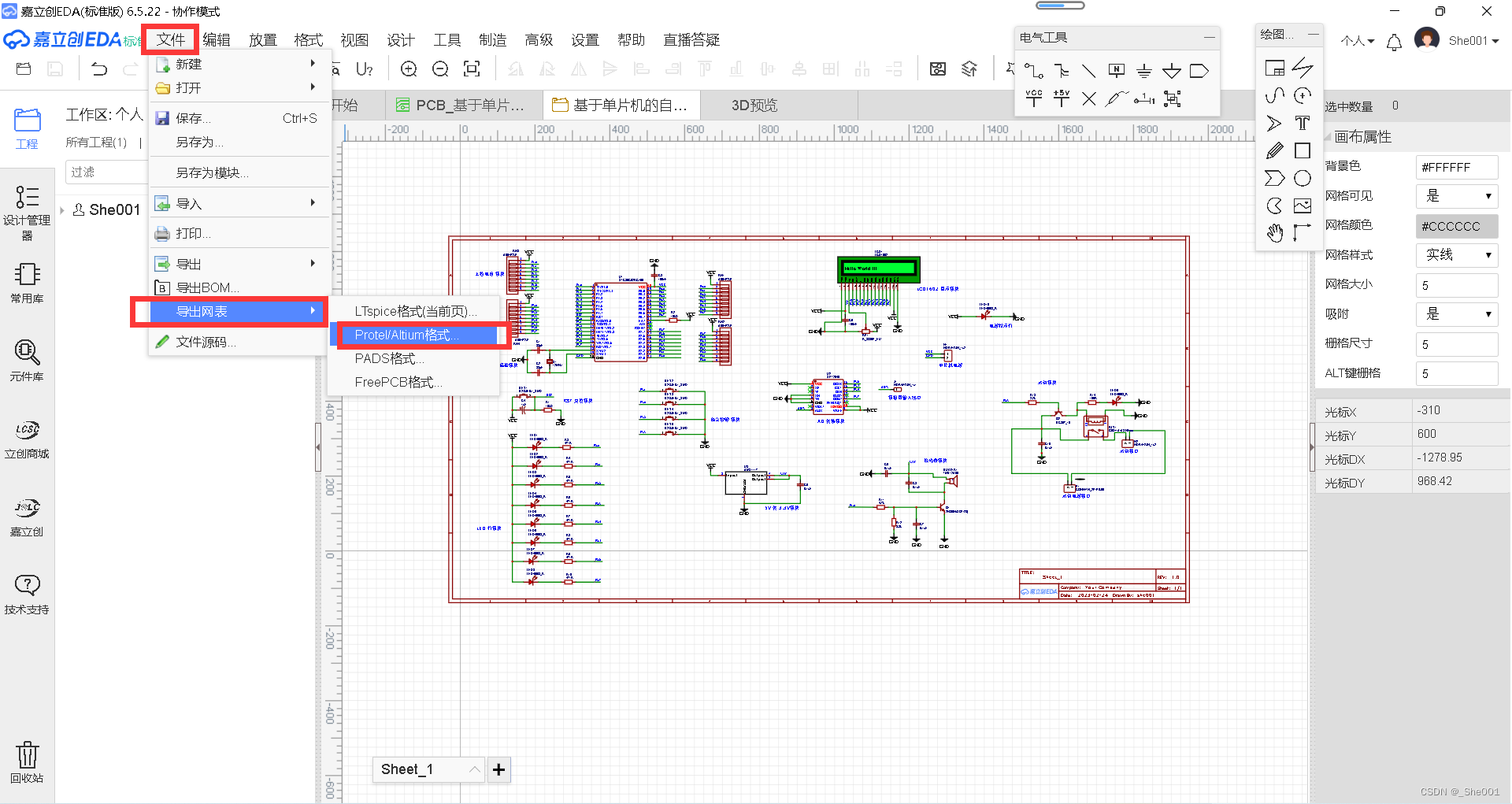
立创EDA 学习 day01 应用下载安装,基本使用的操作
1.下载网站 1.链接:立创EDA下载-立创EDA官方版-PC下载网 (pcsoft.com.cn) 2.安装立创EDA 1.直接 next (简单的操作) 3.注册账号 1. 最好注册一个账号,等下在原理图转PCB 板的时候要登录,才可以。 4.新建工程 1.新…...
)
华为OD机试真题Python实现【火星文计算】真题+解题思路+代码(20222023)
火星文计算 题目 已经火星人使用的运算符号为# $ 其与地球人的等价公式如下 x#y=2*x+3*y+4 x$y=3*x+y+2 x y是无符号整数 地球人公式按照 c 语言规则进行计算 火星人公式中$符优先级高于#相同的运算符按从左到右的顺序运算 🔥🔥🔥🔥🔥👉👉👉👉👉👉 华…...

yolov8 修改类别 自定义数据集
yolov8 加载yolo网络模型 yolov8n.yaml nc: 80 # number of classes 分类数量 depth_multiple: 0.33 # scales module repeats 重复规模 width_multiple: 0.25 # scales convolution channels 缩放卷积通道 backbone head 指定配置 coco128.yaml path: ../datasets/coco128 # d…...
Linux环境下验证python项目
公司大佬开发的python rpa跑数项目,Windows运行没问题后,需要搭建一个linux环境进行验证,NOW START! Install VMware官网 下载好之后打开按步骤安装 最后一步会让填许可证(密钥),这里自行百…...

MAC开发使用技巧
1. 查看所有安装的程序 您可以通过以下步骤在 macOS 中查看所有已安装的程序: 点击屏幕左上角的苹果图标,选择“关于本机”。 在打开的窗口中,选择“系统报告”。 在系统报告窗口中,选择“软件”选项卡,然后选择“安…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

claude code用户如何迁移到taotoken解决封号与token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何迁移到 Taotoken 解决封号与 Token 不足问题 应用场景类,针对 Claude Code 用户常遇封号与 Token…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...

3步搞定B站缓存视频转换:m4s转MP4的终极解决方案
3步搞定B站缓存视频转换:m4s转MP4的终极解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的视频&a…...

ESP32搭建TFT_LCD中文字库,附常用字库
(一)简介 在使用ESP32的时候,我们知道OLED屏幕是有中文库的,里面有非常多的常用字,但是LCD屏幕只有取模才能得到中文字体,那我们本期教程就来教大家如何搭建自己的字体库,使用中文字体更加方便快…...

独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken的TokenPlan在项目初期有效控制AI实验成本 对于独立开发者或学生而言,在构建AI应用原型时&…...