HiveSQL一天一个小技巧:如何将分组内数据填充完整?
0 需求
1 需求分析
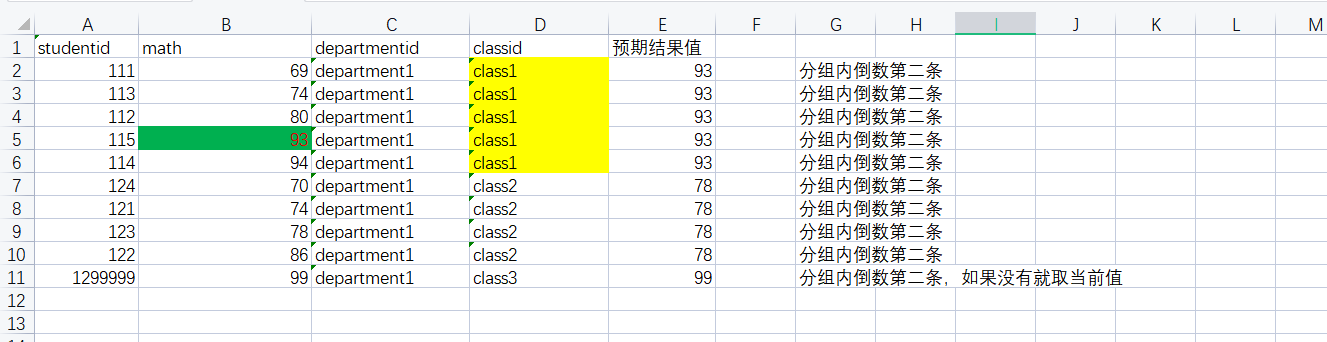
需求分析:需求中需要求出分组中按成绩排名取倒数第二的值作为新字段,且分组内没有倒数第二条的时候取当前值。
如果本题只是求分组内排序后倒数第二,则很简单,使用row_number()函数即可求出,但是本题问题点在于没有倒数第二时候需要保留当前值,如何优雅求出呢?
使用row_number()函数得到如下结果
with data as(select 111 as stu_id, 'class1' as class_name, 69 as scoreunion allselect 113 as stu_id, 'class1' as class_name, 74 as scoreunion allselect 112 as stu_id, 'class1' as class_name, 80 as scoreunion allselect 115 as stu_id, 'class1' as class_name, 93 as scoreunion allselect 114 as stu_id, 'class1' as class_name, 94 as scoreunion allselect 124 as stu_id, 'class2' as class_name, 70 as scoreunion allselect 121 as stu_id, 'class2' as class_name, 74 as scoreunion allselect 123 as stu_id, 'class2' as class_name, 78 as scoreunion allselect 122 as stu_id, 'class2' as class_name, 86 as scoreunion allselect 9999 as stu_id, 'class3' as class_name, 99 as score)
select stu_id, class_name, score, row_number() over (partition by class_name order by score desc ) rn1from data
根据上述结果,如何取出倒数第二值?上层使用case when rn = 2 then score end ,看看效果
with data as(select 111 as stu_id, 'class1' as class_name, 69 as scoreunion allselect 113 as stu_id, 'class1' as class_name, 74 as scoreunion allselect 112 as stu_id, 'class1' as class_name, 80 as scoreunion allselect 115 as stu_id, 'class1' as class_name, 93 as scoreunion allselect 114 as stu_id, 'class1' as class_name, 94 as scoreunion allselect 124 as stu_id, 'class2' as class_name, 70 as scoreunion allselect 121 as stu_id, 'class2' as class_name, 74 as scoreunion allselect 123 as stu_id, 'class2' as class_name, 78 as scoreunion allselect 122 as stu_id, 'class2' as class_name, 86 as scoreunion allselect 9999 as stu_id, 'class3' as class_name, 99 as score)
select stu_id, class_name, score, case when rn1 = 2 then score end as res
from (select stu_id, class_name, score, row_number() over (partition by class_name order by score desc ) rn1--, row_number() over (partition by class_name order by score ) rn2from data) t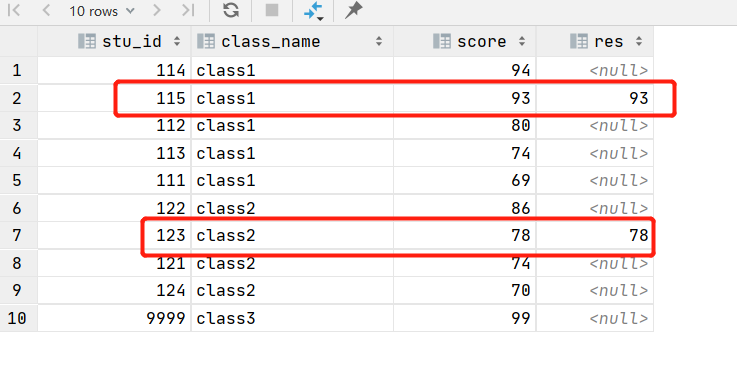
倒数第二值是取出来了,但是还不符合要求,需求中要求该分组内生成的字段每一行全部为该值,如何做呢?这里有个小技巧,也是数据清洗的手段,如何将分组内空值用该分组内有值的值填充完整?我们采用max()函数开窗的技巧:max() over(partition by 分组字段),这样同一个组内的所有空值都会被赋值为同一个字段。SQL如下:
with data as(select 111 as stu_id, 'class1' as class_name, 69 as scoreunion allselect 113 as stu_id, 'class1' as class_name, 74 as scoreunion allselect 112 as stu_id, 'class1' as class_name, 80 as scoreunion allselect 115 as stu_id, 'class1' as class_name, 93 as scoreunion allselect 114 as stu_id, 'class1' as class_name, 94 as scoreunion allselect 124 as stu_id, 'class2' as class_name, 70 as scoreunion allselect 121 as stu_id, 'class2' as class_name, 74 as scoreunion allselect 123 as stu_id, 'class2' as class_name, 78 as scoreunion allselect 122 as stu_id, 'class2' as class_name, 86 as scoreunion allselect 9999 as stu_id, 'class3' as class_name, 99 as score)
select stu_id, class_name, score, max(case when rn1 = 2 then score end ) over(partition by class_name) as res
from (select stu_id, class_name, score, row_number() over (partition by class_name order by score desc ) rn1--, row_number() over (partition by class_name order by score ) rn2from data) t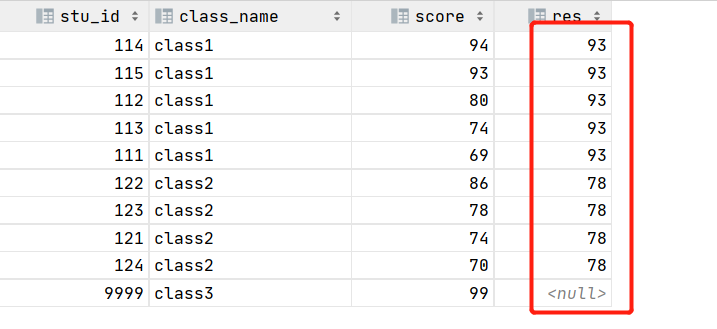
我们看到其结果值越来越符合预期,但是对于分组内只有一个值的如何处理呢?这里我们需要辅助判断,我们可以采用采用min() =max()判断,也可以采用percent_rank()=0判断等等,这里我们采用min() =max()判断,只要最大值等于最小值说明就分组内值唯一,最终SQL如下:
with data as(select 111 as stu_id, 'class1' as class_name, 69 as scoreunion allselect 113 as stu_id, 'class1' as class_name, 74 as scoreunion allselect 112 as stu_id, 'class1' as class_name, 80 as scoreunion allselect 115 as stu_id, 'class1' as class_name, 93 as scoreunion allselect 114 as stu_id, 'class1' as class_name, 94 as scoreunion allselect 124 as stu_id, 'class2' as class_name, 70 as scoreunion allselect 121 as stu_id, 'class2' as class_name, 74 as scoreunion allselect 123 as stu_id, 'class2' as class_name, 78 as scoreunion allselect 122 as stu_id, 'class2' as class_name, 86 as scoreunion allselect 9999 as stu_id, 'class3' as class_name, 99 as score)
select stu_id, class_name, score, max(casewhen rn1 != rn2 and rn1 = 2 --正序和倒序值不等 则取倒数第二的值 (rn1=2的值)then scorewhen rn1 = rn2 then score --正序和倒序值相等 则取当前值end) over (partition by class_name) res
from (select stu_id, class_name, score, dense_rank() over (partition by class_name order by score desc ) rn1, dense_rank() over (partition by class_name order by score) rn2 --用来辅助判断-- , percent_rank() over (partition by class_name order by score) pr --也可以采用该函数辅助判断(pr=0时候)from data) t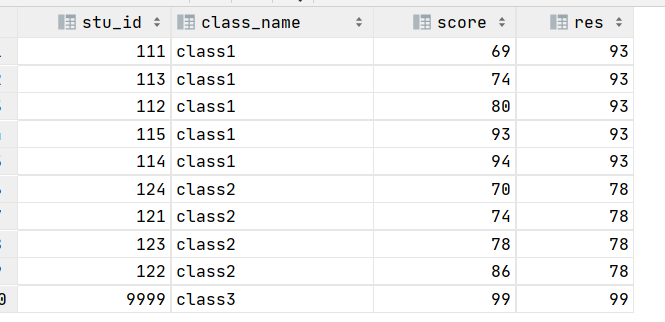
2 小结
本文通过实际需求中的案例,讲解了如何将分组内空值补充完整的技巧,通过开窗,min()/max() over(partition by 分组字段)来补充,注意点max()函数中根据实际情况写case when语句,或构造符合实际需求的条件,往往数据清晰中会用到这一技巧。
相关文章:
HiveSQL一天一个小技巧:如何将分组内数据填充完整?
0 需求1 需求分析需求分析:需求中需要求出分组中按成绩排名取倒数第二的值作为新字段,且分组内没有倒数第二条的时候取当前值。如果本题只是求分组内排序后倒数第二,则很简单,使用row_number()函数即可求出,但是本题问…...
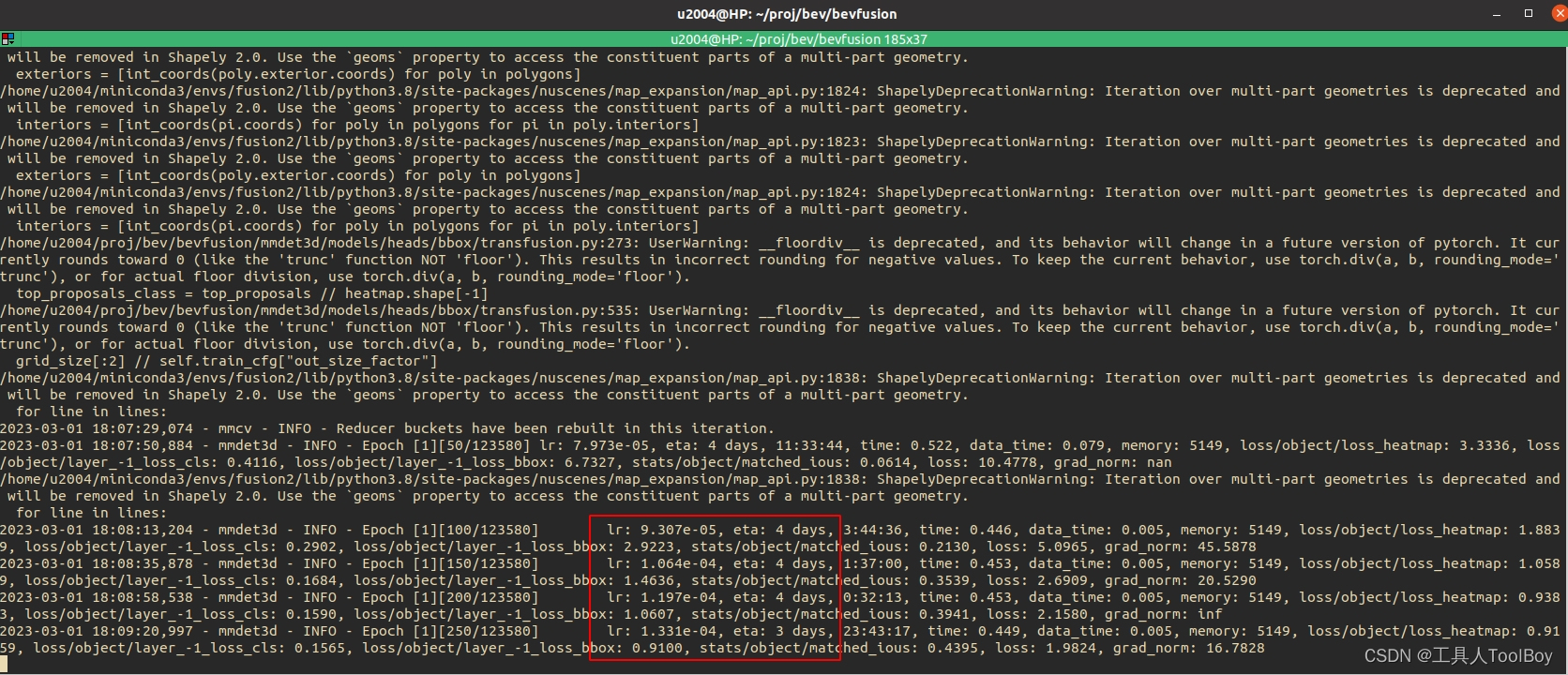
【亲测可用】BEV Fusion (MIT) 环境配置
CUDA环境 首先我们需要打上对应版本的显卡驱动: 接下来下载CUDA包和CUDNN包: wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda_11.6.2_510.47.03_linux.run sudo sh cuda_11.6.2_510.47.03_linux.runwget htt…...
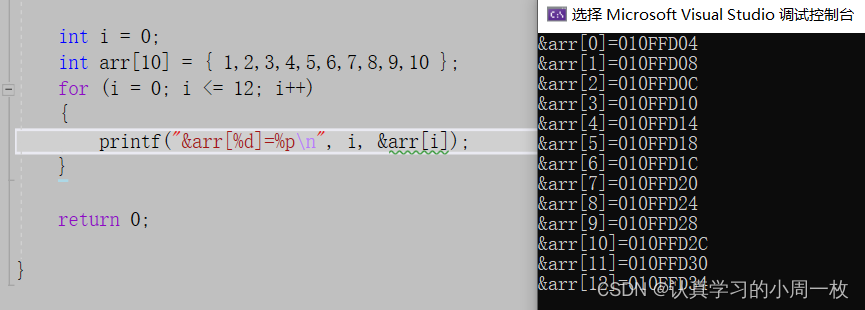
【调试方法】基于vs环境下的实用调试技巧
前言: 对万千程序猿来说,在这个世界上如果有比写程序更痛苦的事情,那一定是亲手找出自己编写的程序中的bug(漏洞)。作为新手在我们日常写代码中,经常会出现报错的情况(好的程序员只是比我们见过…...

单目标应用:蜣螂优化算法DBO优化RBF神经网络实现数据预测(提供MATLAB代码)
一、RBF神经网络 1988年,Broomhead和Lowc根据生物神经元具有局部响应这一特点,将RBF引入神经网络设计中,产生了RBF(Radical Basis Function)。1989年,Jackson论证了RBF神经网络对非线性连续函数的一致逼近性能。 RBF的基本思想是…...
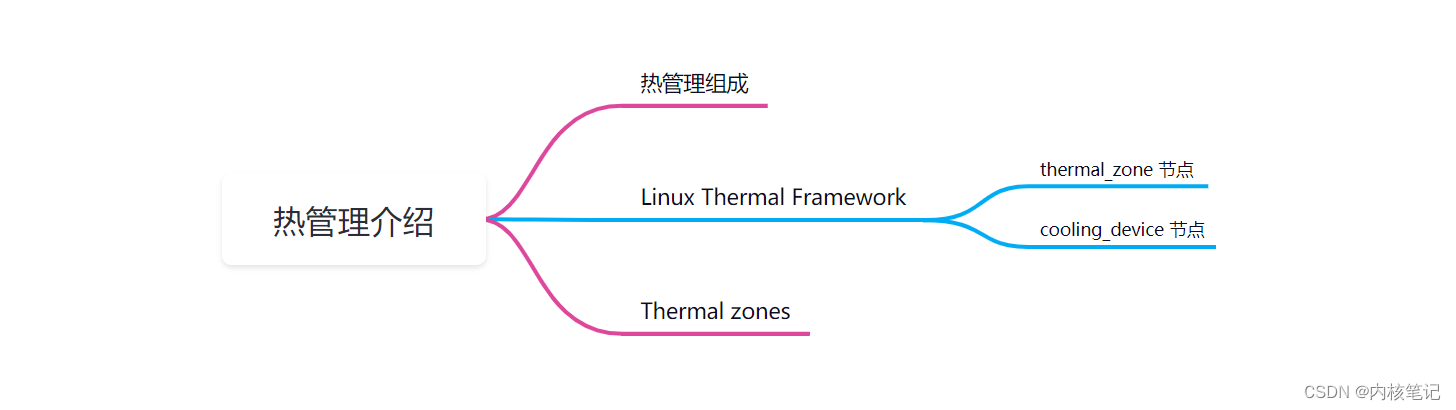
MTK平台开发入门到精通(Thermal篇)热管理介绍
文章目录 一、热管理组成二、Linux Thermal Framework2.1、thermal_zone 节点2.2、cooling_device 节点三、Thermal zones沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍MTK平台的热管理机制,热管理机制是为了防止模组在高温下工作导致硬件损坏而存在的…...
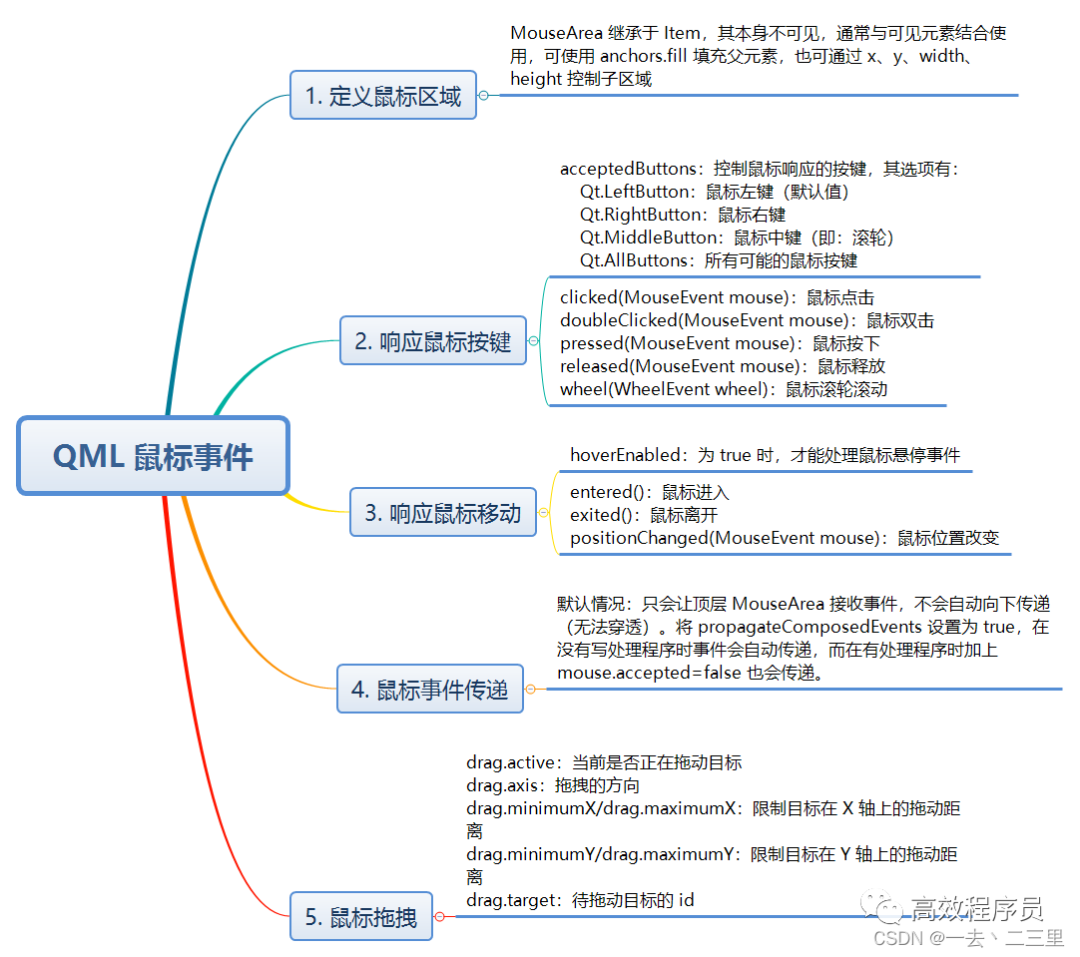
最好的 QML 教程,让你的代码飞起来!
想必大家都知道,亮哥一直深耕于 CSDN,坚持了好很多年,目前为止,原创已经 500 多篇了,一路走来相当不易。当然了,中间有段时间比较忙,没怎么更新。就拿 QML 来说,最早的一篇文章还是 …...
——stack容器的基础理论知识)
笔记(六)——stack容器的基础理论知识
stack是堆栈容器,元素遵循先进后出的顺序。头文件:#include<stack>一、stack容器的对象构造方法stack采用模板类实现默认构造例如stack<T> vecT;#include<iostream> #include<stack> using namespace std; int main(…...
Web前端学习:四 - 练习
三九–四一:百度页面制作 1、左右居中: text-align: center; 2、去掉li默认的状态 list-style: none; li中有的有点,有的有序,此代码去掉默认状态 3、伪类:hovar 一般显示为color: #0f0e0f, 当鼠标接触时…...
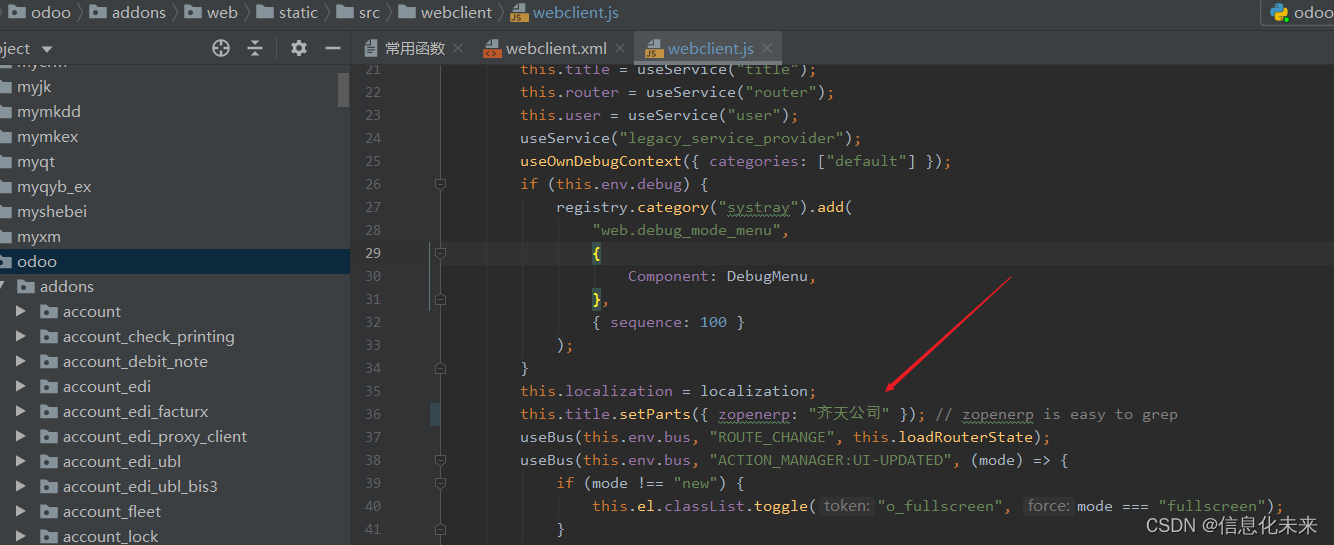
odoo15 标题栏自定义
odoo15 标题栏自定义 如何显示为自定义呢 效果如下: 代码分析: export class WebClient extends Component {setup() {this.menuService = useService("menu");this.actionService = useService("action");this.title = useService("title&…...

视觉SLAM十四讲 ch3 (三维空间刚体运动)笔记
本讲目标 ●理解三维空间的刚体运动描述方式:旋转矩阵、变换矩阵、四元数和欧拉角。 ●学握Eigen库的矩阵、几何模块使用方法。 旋转矩阵、变换矩阵 向量外积 向量外积(又称叉积或向量积)是一种重要的向量运算,它表示两个向量所形成的平行…...

问题解决:java.net.SocketTimeoutException: Read timed out
简单了解Sockets Sockets:两个计算机应用程序之间逻辑链接的一个端点,是应用程序用来通过网络发送和接收数据的逻辑接口 是IP地址和端口号的组合每个Socket都被分配了一个用于标识服务的特定端口号基于连接的服务使用基于tcp的流Sockets Java为客户端…...

前端代码优化方法
1.封装的css样式,增加样式复用性。如果页面加载10个css文件,每个文件1k,那么也要比只加载一个100k的css文件慢 2.减少css嵌套,最好不要嵌套三层以上 3.不要在ID选择器前面进行嵌套,ID本来就是唯一的而且权限值大,嵌套完…...

【批处理脚本】-1.16-文件内字符串查找增强命令findstr
"><--点击返回「批处理BAT从入门到精通」总目录--> 共9页精讲(列举了所有findstr的用法,图文并茂,通俗易懂) 在从事“嵌入式软件开发”和“Autosar工具开发软件”过程中,经常会在其集成开发环境IDE(CodeWarrior,S32K DS,Davinci,EB Tresos,ETAS…)中…...
三天吃透Redis面试八股文
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~ Github地址:https://github.com/…...

数据湖架构Hudi(三)Hudi核心概念
三、Apache Hudi核心概念 3.1 基本概念 Hudi 提供了Hudi 表的概念, 这些表支持CRUD操作, 可以利用现有的大数据集群比如HDFS做数据文件存储, 然后使用SparkSQL或Hive等分析引擎进行数据分析查询。 Hudi表的三个主要组件: 有序的…...

在数字优先的世界中打击知识产权盗窃
在当今数据驱动的世界中,全球许多组织所面临的期望和需求正在达到前所未有的水平。 为了迎接挑战,数据驱动的方法是必要的,需要有效的数字化转型来提高运营效率、简化流程并从遗留技术中获得更多收益。 但是,虽然数字优先方法可…...

机器学习算法原理——逻辑斯谛回归
文章目录逻辑斯谛回归二项逻辑斯谛回归模型极大似然估计多项逻辑斯谛回归模型总结归纳逻辑斯谛回归 写在前面:逻辑斯谛回归最初是数学家 Verhulst 用来研究人口增长是所发现的,是一个非常有趣的发现过程, b 站有更详细的背景及过程推导&…...
)
【华为OD机试 】最优资源分配/芯片资源占用(C++ Java JavaScript Python)
文章目录 题目描述输入描述输出描述备注用例题目解析C++JavaScriptJavaPython题目描述 某块业务芯片最小容量单位为1.25G,总容量为M*1.25G,对该芯片资源编号为1,2,…,M。该芯片支持3种不同的配置,分别为A、B、C。 配置A:占用容量为 1.25 * 1 = 1.25G配置B:占用容量为 …...

600 条最强 Linux 命令总结
1、基本命令 uname -m 显示机器的处理器架构 uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统部件 (SMBIOS / DMI) hdparm -i /dev/hda 罗列一个磁盘的架构特性 hdparm -tT /dev/sda 在磁盘上执行测试性读取操作系统信息 arch 显示机器…...

python自学之《21天学通Python》(15)——第18章 数据结构基础
数据结构是用来描述一种或多种数据元素之间的特定关系,算法是程序设计中对数据操作的描述,数据结构和算法组成了程序。对于简单的任务,只要使用编程语言提供的基本数据类型就足够了。而对于较复杂的任务,就需要使用比基本的数据类…...

Cursor Pro破解工具:5步实现永久免费使用的完整指南
Cursor Pro破解工具:5步实现永久免费使用的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

终极矢量图标库完全指南:Remix Icon 3200+免费图标深度解析
终极矢量图标库完全指南:Remix Icon 3200免费图标深度解析 【免费下载链接】RemixIcon Open source neutral style icon system 项目地址: https://gitcode.com/gh_mirrors/re/RemixIcon Remix Icon 是一套开源的矢量图标库,包含超过3200个精心设…...

如何通过HWInfo插件实现精准硬件监控与风扇控制:完整配置指南
如何通过HWInfo插件实现精准硬件监控与风扇控制:完整配置指南 【免费下载链接】FanControl.HWInfo FanControl plugin to import HWInfo sensors. 项目地址: https://gitcode.com/gh_mirrors/fa/FanControl.HWInfo 想要让电脑散热系统更智能、更安静吗&#…...

面试官最爱问的FPGA亚稳态问题,我用这3个真实波形图给你讲透
FPGA亚稳态问题深度解析:从波形图到面试实战 在数字电路设计中,亚稳态(Metastability)是一个无法回避的核心问题。对于准备FPGA相关岗位面试的工程师来说,能否清晰解释亚稳态现象、分析其成因并提出解决方案࿰…...

AntiDupl.NET:告别数字杂乱,让图片管理回归优雅
AntiDupl.NET:告别数字杂乱,让图片管理回归优雅 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾经在整理照片时,发现手机里…...

长期使用后观察Taotoken聚合路由在高并发下的稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用后观察Taotoken聚合路由在高并发下的稳定性 在构建和运营依赖大模型API的中大型项目时,服务的长期稳定性是技术…...

LENS多模态模型评估实战:从模块消融到失败案例的深度剖析
1. 项目概述:从评估报告到实战指南最近在复现和深入分析LENS这个多模态模型时,我发现原始论文的补充材料虽然数据详实,但更像一份“内部技术报告”,对于想真正理解其能力边界、复现评估过程,甚至想借鉴其架构思路的同行…...

3大技术创新:重新定义Windows Android生态的工具体验
3大技术创新:重新定义Windows Android生态的工具体验 【免费下载链接】wsa-toolbox A Windows 11 application to easily install and use the Windows Subsystem For Android™ package on your computer. 项目地址: https://gitcode.com/gh_mirrors/ws/wsa-tool…...

收藏必备!小白程序员轻松入门大模型:RAG架构详解与实践
本文详细介绍了检索增强生成(RAG)架构,旨在帮助初学者理解大模型如何结合外部知识库提升回答的准确性和时效性。文章涵盖了RAG的四种架构类型、黑盒与白盒增强策略、知识库构建、查询与检索增强方法,以及系统评估和优化增强过程。…...

ESP32内存不够用?手把手教你修改Arduino IDE分区表,榨干16MB Flash
ESP32内存优化实战:深度定制Arduino IDE分区表释放16MB Flash潜力 当你兴致勃勃地为ESP32开发板换上16MB大容量Flash芯片,却发现Arduino IDE仍然报出"内存不足"的错误时,那种挫败感我深有体会。去年我在开发一个智能家居网关项目时…...