Elasticsearch:向量搜索 (kNN) 实施指南 - API 版
作者:Jeff Vestal

本指南重点介绍通过 HTTP 或 Python 使用 Elasticsearch API 设置 Elasticsearch 以进行近似 k 最近邻 (kNN) 搜索。
对于主要使用 Kibana 或希望通过 UI 进行测试的用户,请访问使用 Elastic 爬虫的语义搜索入门指南。你也可以参考文章 “ChatGPT 和 Elasticsearch:OpenAI 遇见私有数据(二)”。
如果你想切入主题并在 Jupyter Notebook 中运行一些代码,我们可以为你提供随附的 notebook。
Elastic Learned Sparse Encoder
如果你使用的文本是英文文本,请考虑使用 Elastic Learned Sparse Encoder。
Elastic Learned Sparse EncodeR(或 ELSER)是由 Elastic 训练的 NLP 模型,使你能够使用稀疏向量表示来执行语义搜索。 语义搜索不是根据搜索词进行字面匹配,而是根据搜索查询的意图和上下文含义来检索结果。
否则,请继续阅读下文,了解有关使用近似 kNN 搜索进行语义向量搜索的信息。
高层架构
在 Elastic 中实现向量搜索有四个关键组件:
- 嵌入模型:机器学习模型,将数据作为输入并返回数据的数字表示(向量,也称为 “嵌入(embedding)”)
- 推理端点:将机器学习模型应用于文本数据的 Elastic Inference API 或 Elastic Inference 管道处理器。 当你提取数据和对数据执行查询时,你都可以使用推理端点。 **注意:**对于非文本数据(例如图像文件),请在你的 ML 模型中使用外部脚本,以便生成你将在 Elastic 中存储和使用的嵌入。
- 搜索:Elastic 将嵌入与元数据一起存储在其索引中,然后执行(近似)k 最近邻搜索以查找查询与数据最接近的匹配项(在向量空间中,也称为“嵌入空间”)
- 应用程序逻辑:你的应用程序在核心向量搜索之外所需的一切,例如与用户通信或应用你的业务逻辑。

集群注意事项
集群大小估计
内存注意事项
为了提高性能,向量需要 “适合” 数据节点上的堆外 RAM。 从 Elasticsearch 版本 8.7+ 开始,向量所需的粗略估计为
NumVectors×4×(NumDimensions+12)注意:该公式适用于 float 类型向量。
使用 20,000 个向量字段的快速示例(我们假设每个文档有 1 个向量):
20,000,000×4×(768+12)≈115 GB of RAM off heap注意:添加的每个副本都需要相同数量的额外 RAM(例如,对于上面的示例,1 个主副本和 1 个副本,我们估计需要 2 倍的 RAM,即 130GB)。
性能测试
由于每个用户的数据都不同,估计 RAM 需求的最佳方法是通过测试。 我们建议从单个节点、单个主分片、无副本开始,然后进行测试,以找出在性能下降之前有多少向量 “适合” 节点。
实现这一目标的一种方法是使用 Elastic 的基准测试工具 Rally。
如果所有向量都相当小(例如,64GB 节点上的 3GB),你可以简单地加载向量并一次性开始测试。
使用上面的估计公式,将向量数量的 75% 加载到单个节点中,运行挑战,并评估响应时间指标。 逐渐增加向量计数,重新运行测试,直到性能下降到可接受的水平以下。 响应时间可接受的最大计数通常可以被认为是单个节点的向量数量。 从那里你可以横向扩展节点和副本。
Jupyter Notebook Code

下面的所有代码都可以在 python Jupyter Notebook 中找到 该代码可以完全从浏览器中运行,使用 Google Colab,以便使用随附的 notebook 进行快速设置和测试
集群配置
每个字段单个向量与每个字段多个向量
向量布局的标准方法是每个字段一个向量。 这就是我们下面将遵循的方法。 但是,从 8.11 开始,Elasticsearch 支持嵌套向量,允许每个字段使用多个向量。 有关设置该方法的信息,请查看 Elasticsearch Labs 博客 “通过摄取管道对大型文档进行分块加上嵌套向量等于简单的段落搜索”。
加载嵌入模型
嵌入模型在机器学习节点上运行。 确保你部署了一个或多个 ML 节点。
要将嵌入模型加载到 Elasticsearch 中,你需要使用 Eland。 Eland 是一个 Python Elasticsearch 客户端,用于使用熟悉的 Pandas 兼容 API 探索和分析 Elasticsearch 中的数据。
- 你可以使用 Docker 从 Hugging Face 快速加载模型。
- 吗还可以在 Colab 中使用 jupyter 笔记本快速加载模型(后续“部署NLP模型”)
- 对于无法直接连接到 Hugging Face 的环境,请按照文档在气隙环境中使用 Eland 加载嵌入模型中概述的步骤操作
摄取管道设置
有多种方法可以生成新文档的嵌入。 最简单的方法是创建摄取管道并配置针对索引的数据,以自动使用管道通过推理处理器调用模型。
在下面的示例中,我们将创建一个带有一个处理器(推理处理器)的管道。 该处理器将:
- 将我们要为其创建嵌入的字段 my_text 映射到嵌入模型在本例中期望的名称 text_field
- 通过 model_id 配置要使用的模型。 这是 Elasticsearch 中模型的名称
- 监控可能出现错误时进行处理。
PUT _ingest/pipeline/vector_embedding_demo
{"processors": [{"inference": {"field_map": {"my_text": "text_field"},"model_id": "sentence-transformers__all-distilroberta-v1","target_field": "ml.inference.my_vector","on_failure": [{"append": {"field": "_source._ingest.inference_errors","value": [{"message": "Processor 'inference' in pipeline 'ml-inference-title-vector' failed with message '{{ _ingest.on_failure_message }}'","pipeline": "ml-inference-title-vector","timestamp": "{{{ _ingest.timestamp }}}"}]}}]}},{"set": {"field": "my_vector","if": "ctx?.ml?.inference != null && ctx.ml.inference['my_vector'] != null","copy_from": "ml.inference.my_vector.predicted_value","description": "Copy the predicted_value to 'my_vector'"}},{"remove": {"field": "ml.inference.my_vector","ignore_missing": true}}]
}索引映射/模板设置
嵌入(向量)存储在 Elasticsearch 中的密集向量字段类型中。 接下来,我们将在索引文档和生成嵌入之前配置索引模板。
下面的 API 调用将创建一个索引模板来匹配具有 my_vector_index-* 模式的任何索引
它会:
- 如文档中所述,为 my_vector 配置密集向量。
- 建议从 _source 中排除向量字段
- 我们还将在本示例中包含一个文本字段 my_text,它将作为生成嵌入的源。
PUT /_index_template/my_vector_index
{"index_patterns": ["my_vector_index-*"],"priority": 1,"template": {"settings": {"number_of_shards": 1,"number_of_replicas": 1,"index.default_pipeline": "vector_embedding_demo"},"mappings": {"properties": {"my_vector": {"type": "dense_vector","dims": 768,"index": true,"similarity": "dot_product"},"my_text": {"type": "text"}},"_source": {"excludes": ["my_vector"]}}}
}索引数据
有多种方法可以将数据索引到 Elasticsearch 中。 下面的示例显示了要索引到示例索引中的一组快速测试文档。 当推理处理器对嵌入模型进行内部 API 调用时,嵌入将由摄取管道在摄取中生成。
POST my_vector_index-01/_bulk?refresh=true
{"index": {}}
{"my_text": "Hey, careful, man, there's a beverage here!", "my_metadata": "The Dude"}
{"index": {}}
{"my_text": "I’m The Dude. So, that’s what you call me. You know, that or, uh, His Dudeness, or, uh, Duder, or El Duderino, if you’re not into the whole brevity thing", "my_metadata": "The Dude"}
{"index": {}}
{"my_text": "You don't go out looking for a job dressed like that? On a weekday?", "my_metadata": "The Big Lebowski"}
{"index": {}}
{"my_text": "What do you mean brought it bowling, Dude? ", "my_metadata": "Walter Sobchak"}
{"index": {}}
{"my_text": "Donny was a good bowler, and a good man. He was one of us. He was a man who loved the outdoors... and bowling, and as a surfer he explored the beaches of Southern California, from La Jolla to Leo Carrillo and... up to... Pismo", "my_metadata": "Walter Sobchak"}查询数据
Approximate k-nearest neighbor
GET my_vector_index-01/_search
{"knn": [{"field": "my_vector","k": 1,"num_candidates": 5,"query_vector_builder": {"text_embedding": {"model_id": "sentence-transformers__all-distilroberta-v1","model_text": "Watchout I have a drink"}}}]
}具有倒数排名融合技术预览的混合搜索(kNN + BM25)
GET my_vector_index-01/_search
{"size": 2,"query": {"match": {"my_text": "bowling"}},"knn":{"field": "my_vector","k": 3,"num_candidates": 5,"query_vector_builder": {"text_embedding": {"model_id": "sentence-transformers__all-distilroberta-v1","model_text": "He enjoyed the game"}}},"rank": {"rrf": {}}
}Filtering
GET my_vector_index-01/_search
{"knn": {"field": "my_vector","k": 1,"num_candidates": 5,"query_vector_builder": {"text_embedding": {"model_id": "sentence-transformers__all-distilroberta-v1","model_text": "Did you bring the dog?"}},"filter": {"term": {"my_metadata": "The Dude"}}}
}返回选择字段的聚合
GET my_vector_index-01/_search
{"knn": {"field": "my_vector","k": 2,"num_candidates": 5,"query_vector_builder": {"text_embedding": {"model_id": "sentence-transformers__all-distilroberta-v1","model_text": "did you bring it?"}}},"aggs": {"metadata": {"terms": {"field": "my_metadata"}}},"fields": ["my_text","my_metadata"],"_source": false
}kNN 调整选项
调整近似 kNN 搜索文档中介绍了调整选项的概述
搜索的计算成本:向量数量的对数,前提是它们通过 HNSW 进行索引。 dot_product 相似度的维数略好于线性。
_search
调整近似 kNN 以提高速度或准确性文档
距离度量的选择
- 只要有可能,我们建议在将向量搜索部署到生产环境时使用 dot_product 而不是余弦相似度。 使用点积可以避免每次相似性计算时都必须计算向量幅度(因为向量已提前归一化为全部幅度为 1)。 这意味着它可以将搜索和索引速度提高约 2-3 倍。
- 也就是说,consine 在文本应用程序中很受欢迎:查询的长度通常比摄取的文档短得多,因此与原始文档的距离对相似性的测量没有有意义的贡献。 请记住,余弦每个元组需要 6 次运算,而点积每个维度只需要两次(将每个元素相乘,然后求和)。 因此,我们建议仅将余弦用于测试/探索,并在投入生产时切换到点积(通过归一化,点积毕竟会计算余弦)。
- 在所有其他用例中首先尝试 dot_product - 因为它的执行速度比 L2 规范(标准欧几里得)快得多。
Ingest
Indexing considerations Docs
索引新数据
除非你生成自己的嵌入,否则你必须在摄取新数据时生成嵌入。 对于文本,这是通过带有调用托管嵌入模型的推理处理器的摄取管道来完成的。 请注意,这需要白金许可证。
添加更多数据也会增加 RAM - 因为你需要将所有向量保留在堆外(而传统搜索则需要在磁盘上)
精确 kNN 搜索
又名强力(brute force)或脚本分数
精确 kNN 搜索文档
不要假设你需要 ANN,因为某些用例无需 ANN 也能正常工作。 根据经验,如果你实际排名的文档数量(即应用过滤器后)低于 10k,那么使用强力选项可能会更好。
在本地环境中运行 jupyter notebook
在很多情况下,我们在本地电脑里来运行上面的练习。我们可以按照如下的步骤来进行:
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
特别注意的是:我们将以最新的 Elastic Stack 8.6.1 来进行展示。请参考 Elastic Stack 8.x 的文章进行安装。
启动白金版试用功能
由于上传模型是一个白金版的功能,我们需要启动试用功能。更多关于订阅的信息,请参考网址:订阅 | Elastic Stack 产品和支持 | Elastic。
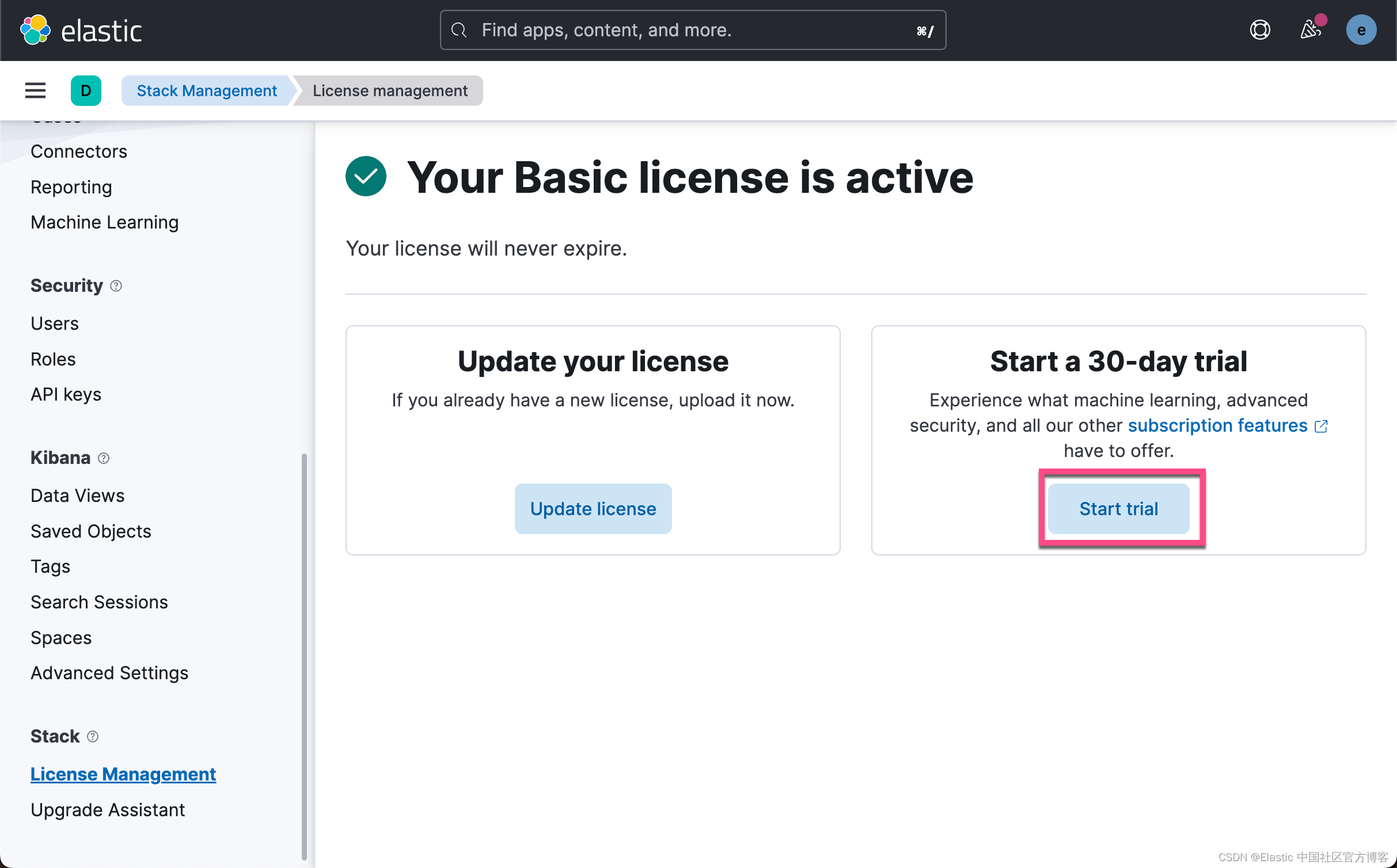
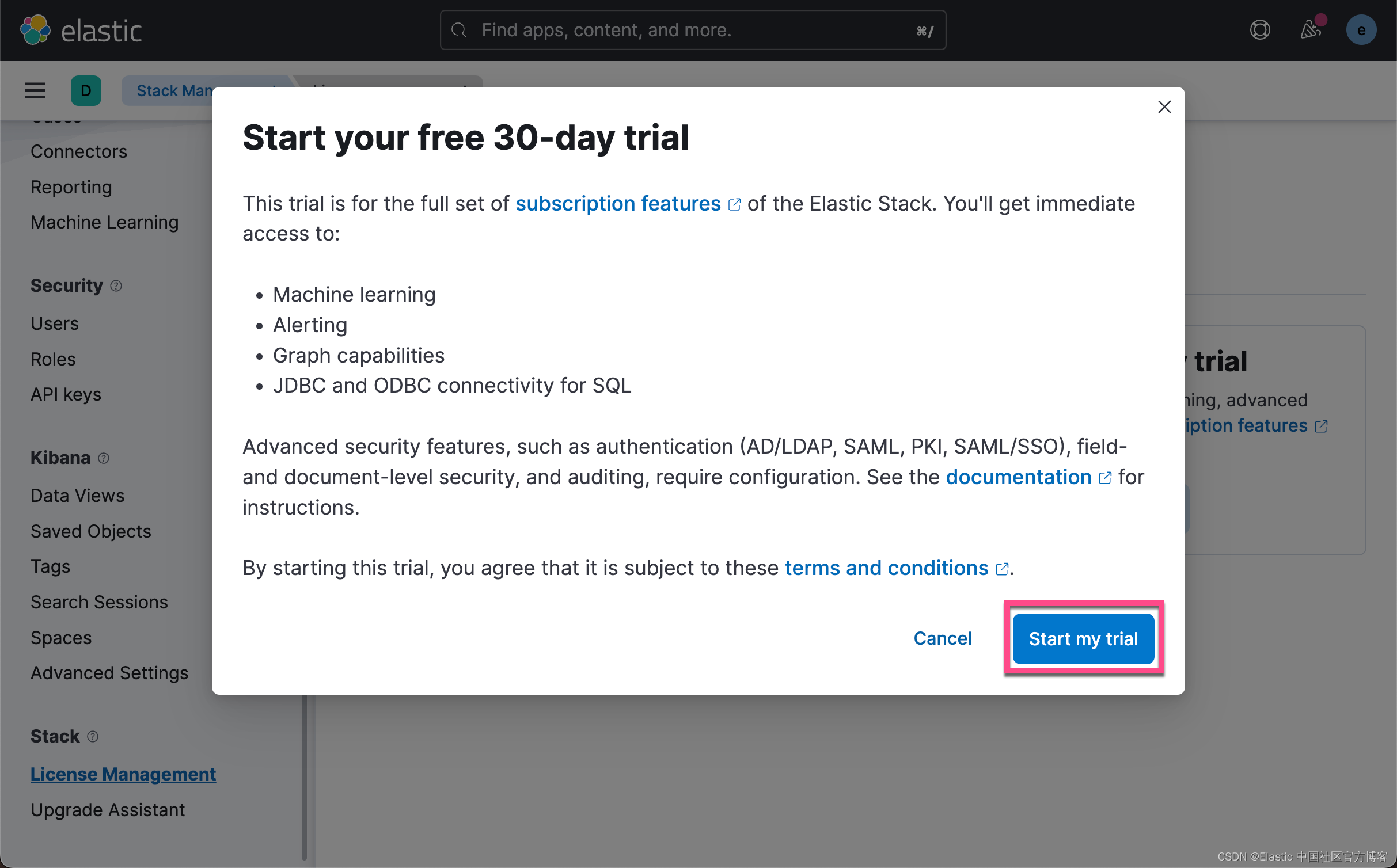
这样我们就成功地启动了白金版试用功能。
上传模型
我们使用如下的命令来安装 eland:
pip3 install eland
pip3 install -q elasticsearch eland[pytorch]
然后,我们使用如下的命令来上传所需要的模型:
eland_import_hub_model --url https://elastic:o6G_pvRL=8P*7on+o6XH@localhost:9200 \--hub-model-id sentence-transformers/all-distilroberta-v1 \--task-type text_embedding \--ca-certs /Users/liuxg/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt \--start
在上面,我们需要根据自己的安装:
- 修改上面的 elastic 超级用户的密码
- 修改上面的证书路径
完成上面的命令后,我们可以在 Kibana 中看到:
运行 Notebook
我们把 Elasticsearch 的证书拷贝到当前的项目根目录下:
cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .我们使用 jupyter notebook 来创建一个叫做 vector_search_implementation_guide_api.ipynb 的 notebook。你可以发现整个 notebook。
原文:Vector Search (kNN) Implementation Guide - API Edition — Elastic Search Labs
相关文章:
Elasticsearch:向量搜索 (kNN) 实施指南 - API 版
作者:Jeff Vestal 本指南重点介绍通过 HTTP 或 Python 使用 Elasticsearch API 设置 Elasticsearch 以进行近似 k 最近邻 (kNN) 搜索。 对于主要使用 Kibana 或希望通过 UI 进行测试的用户,请访问使用 Elastic 爬虫的语义搜索入门指南。你也可以参考文章…...

704 二分查找 day1
class Solution { public: int search(vector<int>& nums, int target) { int left 0; int right nums.size() - 1; // 定义target在左闭右闭的区间里,[left, right] while (left < right) { // 当leftright,区间[left, right]依然有效&…...

Python面试破解:return和yield的细腻差别
更多Python学习内容:ipengtao.com 大家好,我是涛哥,今天为大家分享 Python面试破解:return和yield的细腻差别,全文3000字,阅读大约10钟。 在Python的函数编程中,return和yield是两个常用的关键词…...
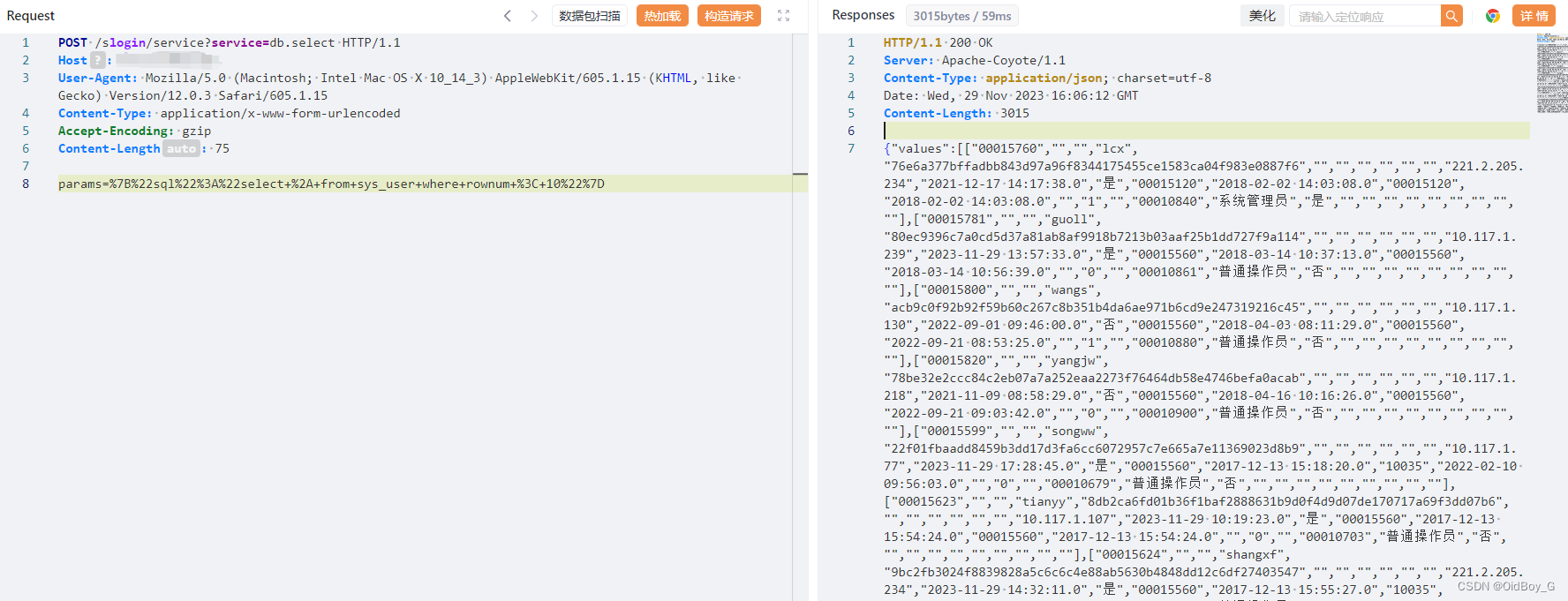
云时空社会化商业 ERP 系统 service SQL 注入漏洞复现
0x01 产品简介 时空云社会化商业ERP(简称时空云ERP) ,该产品采用JAVA语言和Oracle数据库, 融合用友软件的先进管理理念,汇集各医药企业特色管理需求,通过规范各个流通环节从而提高企业竞争力、降低人员成本…...
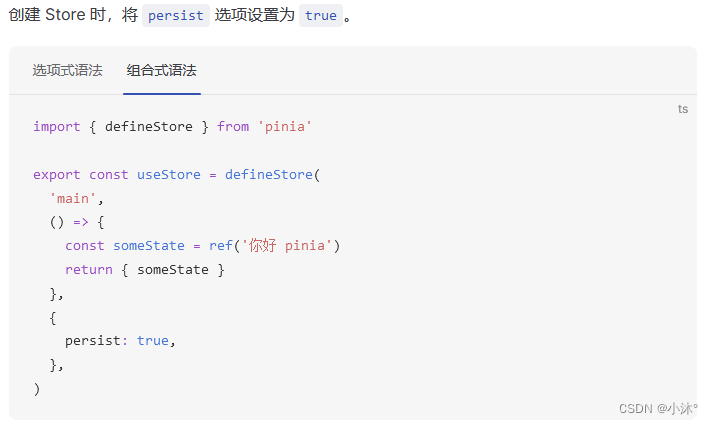
Vue3-Pinia
Pinia是什么 Pinia是Vue的最新状态管理工具,是Vuex的替代品 比Vuex更大的优势在于: 1.提供更加简单的API(去掉了mutation) 2.提供符合,组合式风格的API(和Vue3新语法统一) 3.去掉了modules…...
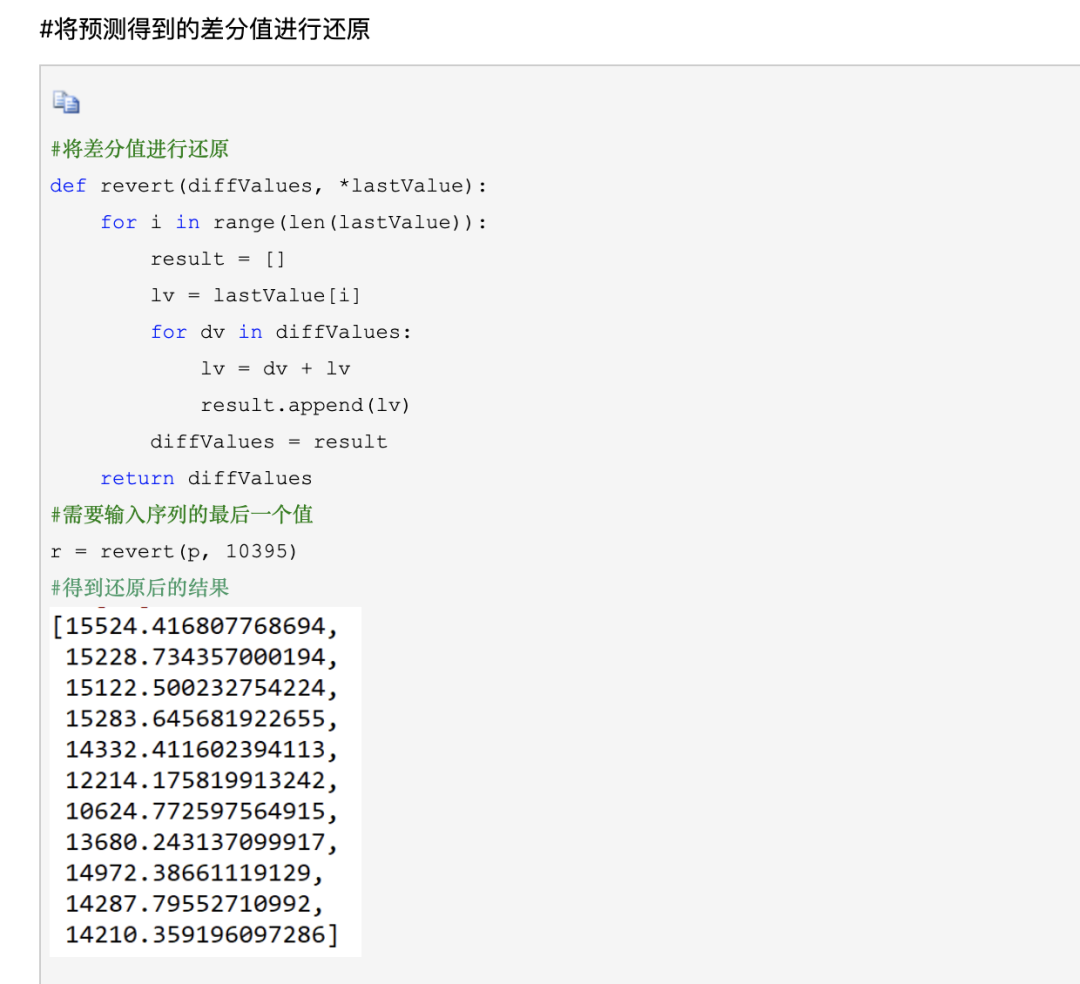
数据挖掘之时间序列分析
一、 概念 时间序列(Time Series) 时间序列是指同一统计指标的数值按其发生的时间先后顺序排列而成的数列(是均匀时间间隔上的观测值序列)。 时间序列分析的主要目的是根据已有的历史数据对未来进行预测。 时间序列分析主要包…...

iOS NSDate的常用API
目录 一、创建日期 1.获取当前时间 2.当前时间指定秒数之后/前的时间 3.指定日期之后/后的时间 4.2001年之后/前指定秒数的时间 5.1970年之后/后指定秒数的时间 二、初始化日期 1.init 2.时间间指定秒数的时间 3.指定时间指定秒数之前/后的时间 4.2001年指定秒数之后…...
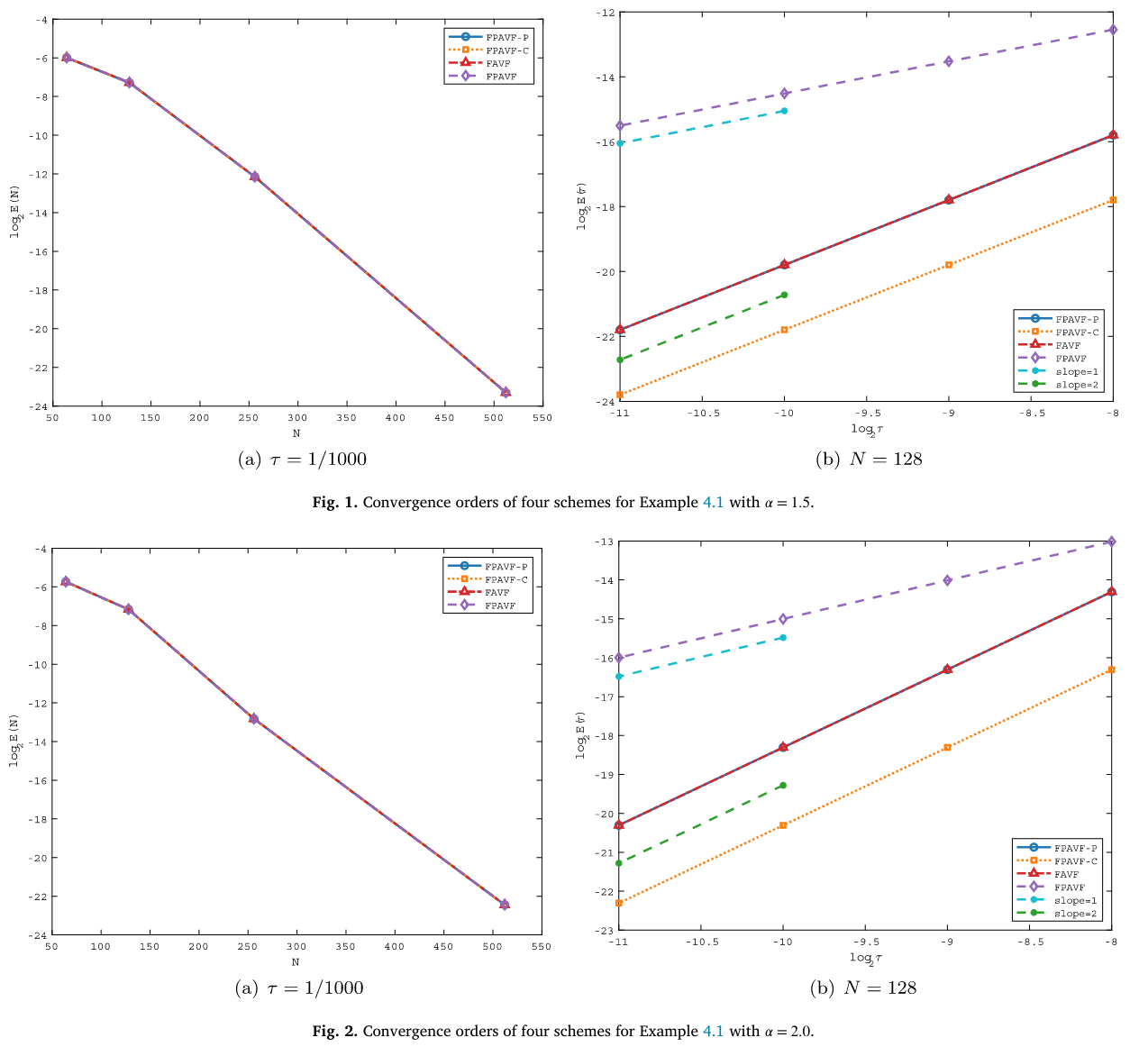
谱方法学习笔记-下(超详细)
谱方法学习笔记📒 谱方法学习笔记-上(超详细) 声明:鉴于CSDN使用 K a T e X KaTeX KaTeX 渲染公式, KaTeX \KaTeX KATEX 与 L a T e X LaTeX LaTeX 不同,不支持直接的交叉引用命令,如\label和\eqref。 KaTeX \KaT…...

iOS--UIPickerView学习
UIPickerView 使用场景和功能UIPickerView遵循代理协议和数据源协议创建对象,添加代理必须实现的代理方法非必要实现的方法demo用到的其他函数提示 效果展示 使用场景和功能 UIPickerView 最常见的用途是作为选项选择器,允许用户从多个选项中选择一个。…...

Docker安装Elasticsearch以及ik分词器
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,Elasticsearch 会集中存储您的数据,让您飞快完成搜索,微调相关性,进行强大的分析ÿ…...

[架构之路-254]:目标系统 - 设计方法 - 软件工程 - 软件设计 - 架构设计 - 全程概述
目录 一、软件架构概述 1.1 什么是软件架构 1.2 为什么需要软件架构设计 1.3 软件架构设计在软件设计中位置 (1)软件架构设计(层次划分、模块划分、职责分工): (2)软件高层设计、概要设计…...

centos7上源码安装mysql--运维高级
第一步,安装必要的依赖: yum install -y cmake ncurses-devel bison gcc gcc-c make unzip libaio numactl 第二步,创建mysql用户和组: wget http://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.18.tar.gz tar zxvf mysql-5.7.18.tar.gz 第三步,下载MySQL 5.7.18 源码…...

Linux小程序之进度条
> 作者简介:დ旧言~,目前大二,现在学习Java,c,c,Python等 > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:自己能实现进度条 > 毒鸡汤: > …...
Grafana采用Nginx反向代理
一、场景介绍 在常规操作中,一般情况下不会放开许多端口给外部访问,特别是直接 ip:port 的方式开放访问。但是 Grafana 的请求方式在默认情况下是没有任何规律可寻的。 为了满足业务需求(后续通过 Nginx 统一一个接口暴露 N 个服务…...

Python接口自动化测试如何设计接口测试用例(详解)
简介 上篇我们已经介绍了什么是接口测试和接口测试的意义。在开始接口测试之前,我们来想一下,如何进行接口测试的准备工作。或者说,接口测试的流程是什么?有些人就很好奇,接口测试要流程干嘛?不就是拿着接口…...

Spring不再支持Java8了
在今天新建模块的时候发现了没有java8的选项了,结果一查发现在11月24日,Spring不再支持8了,这可怎么办呢?我们可以设置来源为阿里云https://start.aliyun.com/ 。 java8没了 设置URL为阿里云的地址...

Android 实现APP可切换多语言
如果是单独给app加上国际化,其实很容易,创建对应的国家资源文件夹即可,如values-en,values-pt,app会根据当前系统语言去使用对应语言资源文件,如果找不到,则使用values文件夹里的资源 但本文讲得是另外一种情况,就是app内置一个切换多语言的页面,可以给用户切换 步骤 1.添加服务…...
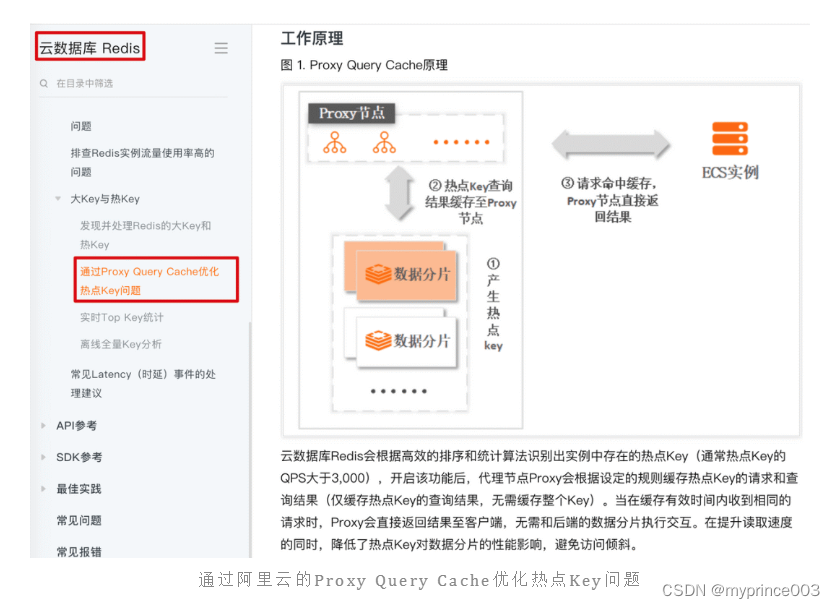
Redis大key与热Key
什么是 bigkey? 简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准: bigkey 是怎么产生的?有什么危害?…...

SQL通配符字符
SQL通配符字符 通配符字符用于替代字符串中的一个或多个字符。通配符字符与LIKE运算符一起使用。LIKE运算符用于在WHERE子句中搜索列中的指定模式。 示例 返回所有以字母 a 开头的客户: SELECT * FROM Customers WHERE CustomerName LIKE a%; 通配符字符 符号…...

力扣 144.二叉树的前序遍历
目录 1.解题思路2.代码实现2.1获得节点数接口:2.2递归接口:2.3最终实现 1.解题思路 该题要利用前序遍历,将树的值存到数组中,所以在申请空间的时候,我们需要知道要申请多少空间,也就是要知道树到底有多少个结点,因此第…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

串口通信粘包问题:成因深度解析与项目实战解决方案
在嵌入式开发、工业工控、上位机下位机交互项目中,串口(RS232/RS485)是最基础、最常用的通信方式。绝大多数开发者都遇到过这样的问题:串口接收的数据偶尔错乱、解析报错、数据拼接异常,单次接收的数据时而半包、时而多…...

录音会议纪要整理不同使用场景,实用口碑选择建议
针对不同场景的录音整理需求(短录音、中长录音、长内容深度整理),本文基于实际使用体验,分享不同场景下的工具选择建议与使用心得。一、场景一:短录音(15-60分钟,发音清晰)典型场景&…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...
)
毕业设计 yolov11骨折检测医疗辅助系统(源码+论文)
文章目录 0 前言1 项目运行效果2 课题背景2.1 研究背景2.2 国内外研究现状2.3 研究意义 3 设计框架(骨折检测系统设计框架说明)3.1. 系统架构图3.2. 技术选型3.2.1 核心组件3.2.2 辅助工具 3.3. 核心模块设计3.3.1 YOLO模型训练模块训练流程图关键伪代码…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...

航空发动机叶片三维扫描-诺斯顿
航空发动机叶片作为发动机的核心动力部件,其精度与性能直接决定发动机的推力、燃油效率及运行安全性,三维扫描技术作为航空制造领域的核心数字化手段,已广泛应用于叶片全生命周期的多个关键环节。其应用涵盖叶片研发设计阶段的逆向工程&#…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...