卷积神经网络(CNN)注意力检测
文章目录
- 一、前言
- 二、前期工作
- 1. 设置GPU(如果使用的是CPU可以忽略这步)
- 2. 导入数据
- 3. 查看数据
- 二、数据预处理
- 1.加载数据
- 2. 可视化数据
- 4. 配置数据集
- 三、调用官方网络模型
- 四、设置动态学习率
- 五、编译
- 六、训练模型
- 七、模型评估
- 1. Accuracy与Loss图
- 2. 混淆矩阵
- 八、保存and加载模型
- 九、预测
一、前言
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
往期精彩内容:
- 卷积神经网络(CNN)实现mnist手写数字识别
- 卷积神经网络(CNN)多种图片分类的实现
- 卷积神经网络(CNN)衣服图像分类的实现
- 卷积神经网络(CNN)鲜花识别
- 卷积神经网络(CNN)天气识别
- 卷积神经网络(VGG-16)识别海贼王草帽一伙
- 卷积神经网络(ResNet-50)鸟类识别
- 卷积神经网络(AlexNet)鸟类识别
- 卷积神经网络(CNN)识别验证码
- 卷积神经网络(CNN)车牌识别
来自专栏:机器学习与深度学习算法推荐
二、前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
import tensorflow as tfgpus = tf.config.list_physical_devices("GPU")if gpus:tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用tf.config.set_visible_devices([gpus[0]],"GPU")# 打印显卡信息,确认GPU可用
print(gpus)
2. 导入数据
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号import os,PIL# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)import pathlib
data_dir = "Eye_dataset"data_dir = pathlib.Path(data_dir)
3. 查看数据
image_count = len(list(data_dir.glob('*/*')))print("图片总数为:",image_count)
图片总数为: 4307
二、数据预处理
1.加载数据
batch_size = 64
img_height = 224
img_width = 224
使用image_dataset_from_directory方法将磁盘中的数据加载到tf.data.Dataset中
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
Found 4307 files belonging to 4 classes.
Using 3446 files for training.
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=12,image_size=(img_height, img_width),batch_size=batch_size)
Found 4307 files belonging to 4 classes.
Using 861 files for validation.
我们可以通过class_names输出数据集的标签。标签将按字母顺序对应于目录名称。
class_names = train_ds.class_names
print(class_names)
['close_look', 'forward_look', 'left_look', 'right_look']
2. 可视化数据
plt.figure(figsize=(10, 5)) # 图形的宽为10高为5
plt.suptitle("数据展示")for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1) ax.patch.set_facecolor('yellow')plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")
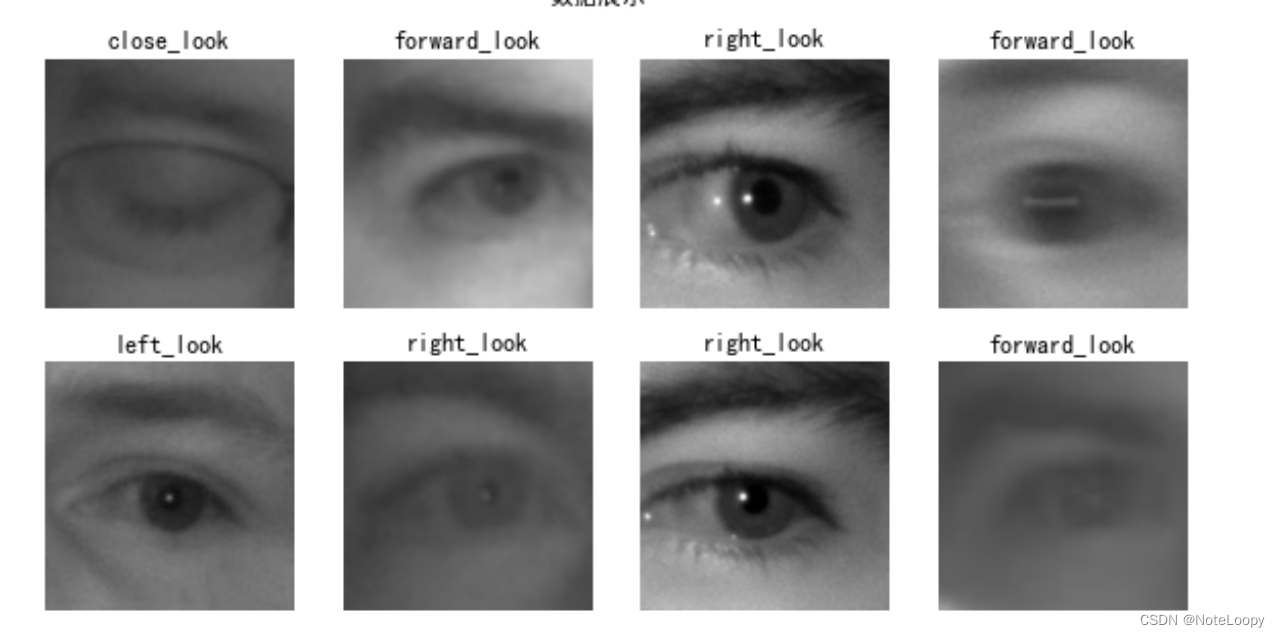
- 再次检查数据
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
(64, 224, 224, 3)
(64,)
Image_batch是形状的张量(8, 224, 224, 3)。这是一批形状240x240x3的8张图片(最后一维指的是彩色通道RGB)。Label_batch是形状(8,)的张量,这些标签对应8张图片
4. 配置数据集
AUTOTUNE = tf.data.AUTOTUNEtrain_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三、调用官方网络模型
model = tf.keras.applications.VGG16()
# 打印模型信息
model.summary()
四、设置动态学习率
这里先罗列一下学习率大与学习率小的优缺点。
- 学习率大
- 优点: 1、加快学习速率。 2、有助于跳出局部最优值。
- 缺点: 1、导致模型训练不收敛。 2、单单使用大学习率容易导致模型不精确。
- 学习率小
- 优点: 1、有助于模型收敛、模型细化。 2、提高模型精度。
- 缺点: 1、很难跳出局部最优值。 2、收敛缓慢。
注意:这里设置的动态学习率为:指数衰减型(ExponentialDecay)。在每一个epoch开始前,学习率(learning_rate)都将会重置为初始学习率(initial_learning_rate),然后再重新开始衰减。计算公式如下:
learning_rate = initial_learning_rate * decay_rate ^ (step / decay_steps)
# 设置初始学习率
initial_learning_rate = 1e-4lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(initial_learning_rate, decay_steps=5, # 敲黑板!!!这里是指 steps,不是指epochsdecay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lrstaircase=True)# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
五、编译
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 损失函数(loss):用于衡量模型在训练期间的准确率。
- 优化器(optimizer):决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 指标(metrics):用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
model.compile(optimizer=optimizer,loss ='sparse_categorical_crossentropy',metrics =['accuracy'])
六、训练模型
epochs = 20history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
七、模型评估
1. Accuracy与Loss图
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
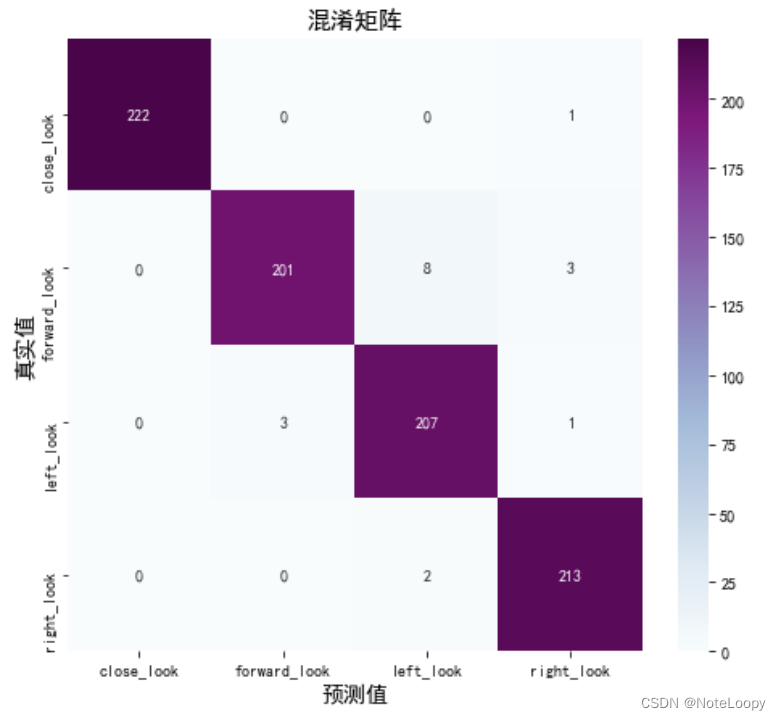
2. 混淆矩阵
Seaborn 是一个画图库,它基于 Matplotlib 核心库进行了更高阶的 API 封装,可以让你轻松地画出更漂亮的图形。Seaborn 的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻。
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd# 定义一个绘制混淆矩阵图的函数
def plot_cm(labels, predictions):# 生成混淆矩阵conf_numpy = confusion_matrix(labels, predictions)# 将矩阵转化为 DataFrameconf_df = pd.DataFrame(conf_numpy, index=class_names ,columns=class_names) plt.figure(figsize=(8,7))sns.heatmap(conf_df, annot=True, fmt="d", cmap="BuPu")plt.title('混淆矩阵',fontsize=15)plt.ylabel('真实值',fontsize=14)plt.xlabel('预测值',fontsize=14)
val_pre = []
val_label = []for images, labels in val_ds:#这里可以取部分验证数据(.take(1))生成混淆矩阵for image, label in zip(images, labels):# 需要给图片增加一个维度img_array = tf.expand_dims(image, 0) # 使用模型预测图片中的人物prediction = model.predict(img_array)val_pre.append(class_names[np.argmax(prediction)])val_label.append(class_names[label])
plot_cm(val_label, val_pre)
八、保存and加载模型
这是最简单的模型保存与加载方法哈
# 保存模型
model.save('model/16_model.h5')
# 加载模型
new_model = tf.keras.models.load_model('model/16_model.h5')
九、预测
九、预测
# 采用加载的模型(new_model)来看预测结果plt.figure(figsize=(10, 5)) # 图形的宽为10高为5
plt.suptitle("预测结果展示")for images, labels in val_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1) # 显示图片plt.imshow(images[i].numpy().astype("uint8"))# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0) # 使用模型预测图片中的人物predictions = new_model.predict(img_array)plt.title(class_names[np.argmax(predictions)])plt.axis("off")
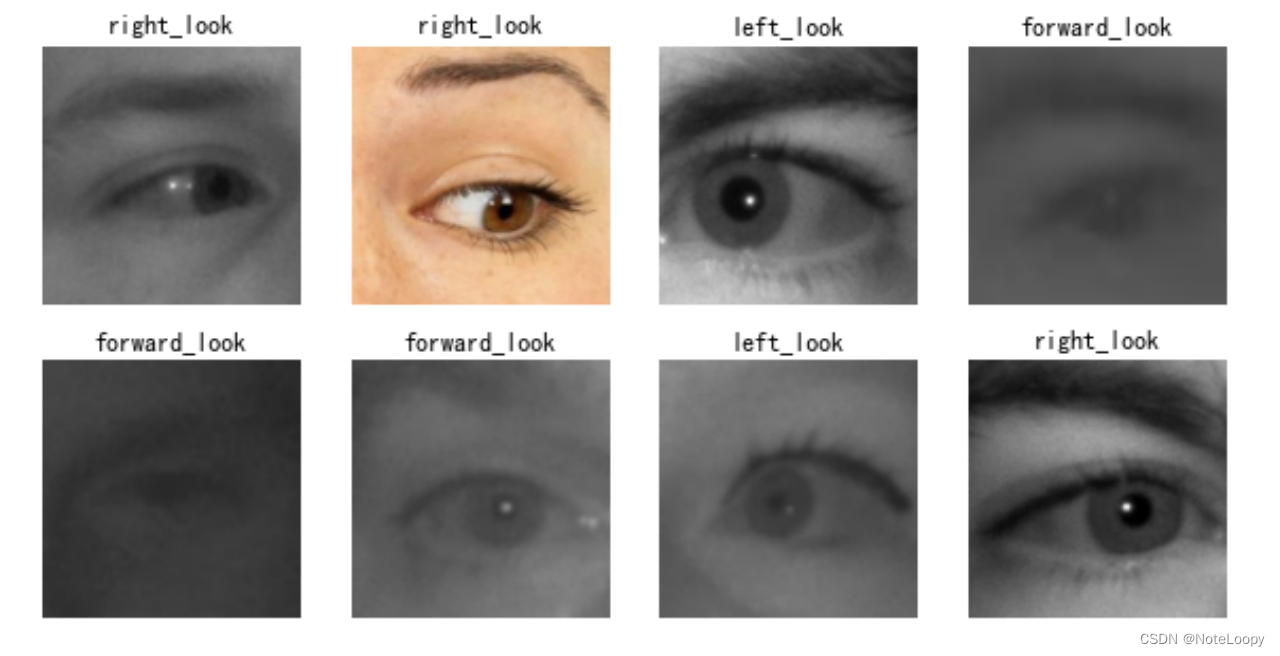
相关文章:
卷积神经网络(CNN)注意力检测
文章目录 一、前言二、前期工作1. 设置GPU(如果使用的是CPU可以忽略这步)2. 导入数据3. 查看数据 二、数据预处理1.加载数据2. 可视化数据4. 配置数据集 三、调用官方网络模型四、设置动态学习率五、编译六、训练模型七、模型评估1. Accuracy与Loss图2. …...

4. 权限,特权
对数据段特权检查对直接转移的代码段特权检查栈段的检查调用门的检查 权限问题: 由于CPL,DPL 无法完整表达权限的问题. 例如用户程序(CPL3)通过调用门(将调用到内核过程,从低权限到高权限)执行,此时CPL0,此时可以为所欲为.因此加入RPL.此参数由操作系统来保证,CPU仅使用 RPL:…...

云原生系列Go语言篇-泛型Part 2
类型推导和泛型 就像在使用:时支持类型推导一样,在调用泛型函数时Go同样支持类型推导。可在上面对Map、Filter和Reduce调用中看出。有些场景无法进行类型推导(如类型参数仅用作返回值)。这时,必…...
借助ETL快速查询金蝶云星空表单信息
随着数字化转型的加速,企业信息化程度越来越高,大量的数据产生并存储在云端,需要进行有效的数据管理和查询。金蝶云星空是金蝶云旗下的一款云ERP产品,为企业提供了完整的业务流程和数据管理功能,因此需要进行有效的数据…...
)
基于深度学习的驾驶员状态监测预警系统(正文)
摘 要 近年来驾驶员因疲劳驾驶而造成的交通事故逐年增多,驾驶员的驾驶状态对道路和人身安全产生重大影响,因此做好驾驶员驾驶状态的管理及预警是非常有必要的。 随着深度学习在目标检测算法应用的不断深入,YOLOv5等目标检测算法也相继具有了广…...

读书笔记之《价值》张磊
读书笔记之《价值》张磊 自序 这是一条长期主义之路 长期主义——把时间和信念投入能够长期产生价值的事情中,尽力学习最有效率的思维方式和行为标准,遵循第一性原理,永远探求真理。 真正的投资,有且只有一条标准,那…...
【shell】文本三剑客之sed详解
目录 一、sed简介(行编辑器) 二、基本用法 三、sed脚本格式(匹配地址 脚本命令) 1、不给地址,那么就是针对全文处理 2、单地址,表示#,指定的行,$表示最后一行,/pattt…...
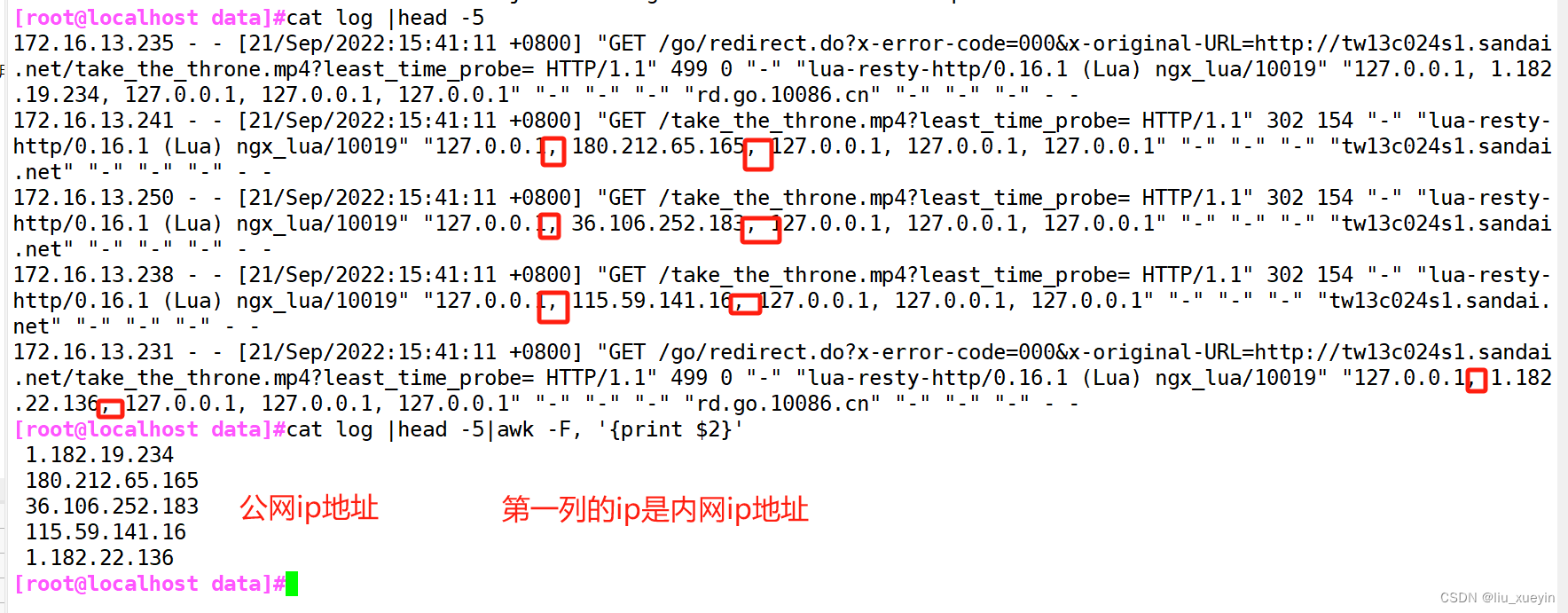
Centos7 制作Openssh9.5 RPM包
Centos7 制作Openssh9.5 RPM包 最近都在升级Openssh版本到9.3.在博客里也放了openssh 9.5的rpm包. 详见:https://blog.csdn.net/qq_29974229/article/details/133878576 但还是有小伙伴不停追问这个rpm包是怎么做的,怕下载别人的rpm包里被加了盐. 于是做了个关于怎么用官方的o…...

C语言--每日选择题--Day30
第一题 1. i 5,j 7,i | j 等于多少? A:1 B:3 C:5 D:7 答案及解析 D |这个是按位或运算符,两个数的二进制位,有1为1,同0为0; i的二进…...

LeetCode 274. H指数——排序
274. H 指数 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。 根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她&…...
)
【洛谷 B2038】奇偶 ASCII 值判断 题解(顺序结构+取余)
奇偶 ASCII 值判断 题目描述 任意输入一个字符,判断其 ASCII 是否是奇数,若是,输出 YES,否则,输出 NO 。 例如,字符 A 的 ASCII 值是 65,则输出 YES,若输入字符 B(ASCII 值是 66…...
)
Ubuntu 20.4 源代码方式安装 cdo(笔记)
目录 动机安装过程python 调用cdo 动机 我找到的处理 era5-land 代码在需要用到 cdo,但是 sudo apt-get install cdo 总是出现 abort (core dump) 等问题,所以放弃这种安装方式,不走捷径,安装源代码,也就是 cdo-x.x.x…...

电子学会C/C++编程等级考试2022年12月(三级)真题解析
C/C++等级考试(1~8级)全部真题・点这里 第1题:鸡兔同笼 一个笼子里面关了鸡和兔子(鸡有2只脚,兔子有4只脚,没有例外)。已经知道了笼子里面脚的总数a,问笼子里面至少有多少只动物,至多有多少只动物。 时间限制:1000 内存限制:65536输入 一行,一个正整数a (a < 327…...
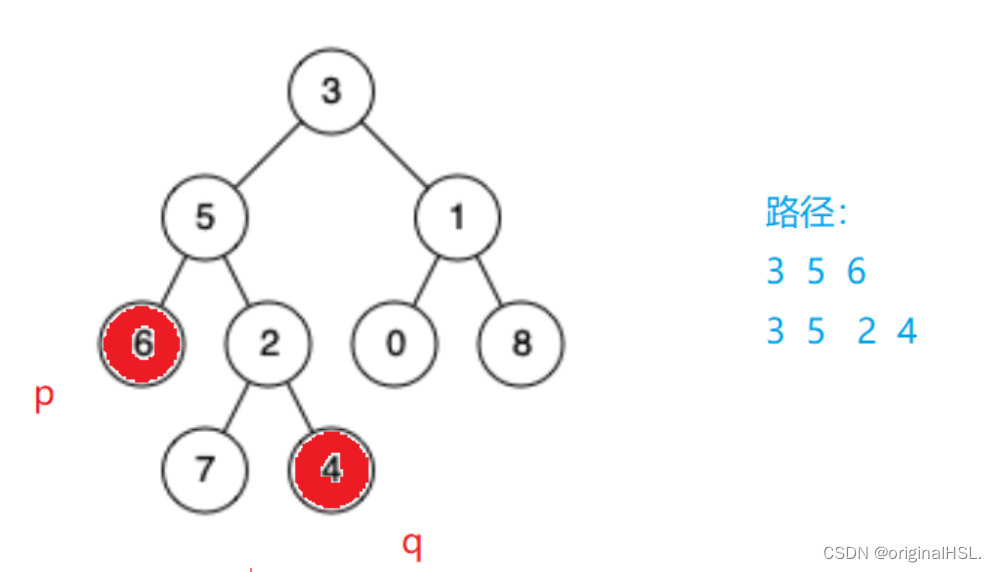
二叉树的最近公共祖先(C++实现)
二叉树的最近公共祖先 题目思路代码(详细注释) 题目 二叉树的最近公共祖先 思路 我们可以通过两个栈来实现 实现一个FindPath函数,用来查找从根节点到目标节点的路径(路径可以用栈来保存) 路径保存好后,…...

【conda】容易遗忘的命令使用总结
1. 在空conda虚拟环境中安装python 退出到base环境 conda activate base 执行命令 conda install -n 空环境名 python版本名 例如: conda install -n test python3.10 2. 无需确认直接创建环境 在末尾加上-y,例如: conda create -n tes…...
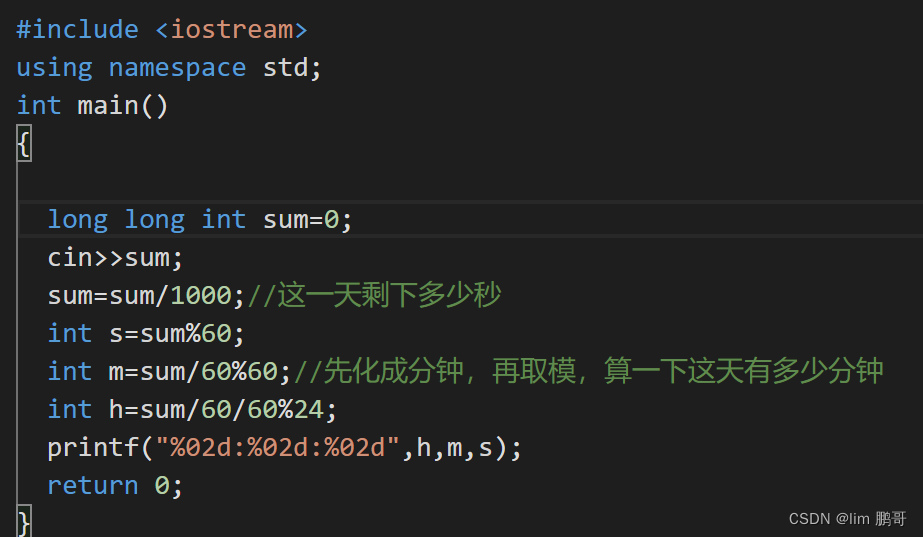
蓝桥杯第一天-----时间显示
文章目录 前言一、题目描述二、测试用例三、题目分析四、具体代码实现总结 前言 本章中将相信介绍蓝桥杯中关于时间显示的题目。 链接:https://www.lanqiao.cn/problems/1452/learning/ 一、题目描述 二、测试用例 三、题目分析 1.输入的时间为毫秒,毫…...

多文件夹图片预处理:清除空值、重置大小、分割训练集
→ 清理空值 防止出现cannot identify image file 参考Python数据清洗----删除读取失败图片__简单版_python用pil读取图片出错删除掉-CSDN博客 import os import shutil import warnings import cv2 import iofrom PIL import Image warnings.filterwarnings("error&qu…...

【Java】集合 之 使用 Map
为什么使用Map 我们知道,List是一种顺序列表,如果有一个存储学生Student实例的List,要在List中根据name查找某个指定的Student的分数,应该怎么办? 最简单的方法是遍历List并判断name是否相等,然后返回指定…...
第二证券:股票几点到几点开盘?
作为股民或许投资者,我们都知道股票是每天都有开盘和收盘时间的。但是,关于股票的开盘时间,很多人并不是很清楚,特别是初学者。在本文中,我们将从多个视点分析股票开盘时间,并为大家供给一些有用的信息。 …...

goweb入门教程
本文是作者自己学习goweb时写的笔记,分享给大家,希望能有些帮助 前言: 关于web:本质 web中最重要的就是浏览器和服务器的request(请求)和response(响应); 一个请求对应一个响应。 一个请求对应一个响应&…...

从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式
从Figma设计到Python GUI:Tkinter-Designer如何重塑可视化开发范式 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发领域&am…...

UE4SS实战指南:虚幻引擎游戏脚本系统的深度解析与应用
UE4SS实战指南:虚幻引擎游戏脚本系统的深度解析与应用 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS …...

TuxGuitar完整指南:免费开源吉他谱编辑器的终极教程 [特殊字符]
TuxGuitar完整指南:免费开源吉他谱编辑器的终极教程 🎸 【免费下载链接】tuxguitar Open source guitar tablature editor 项目地址: https://gitcode.com/gh_mirrors/tu/tuxguitar TuxGuitar是一款功能强大的开源吉他谱编辑器,支持多…...

告别L298N!用TB6612驱动模块给你的STM32循迹小车降功耗提性能
告别L298N!用TB6612驱动模块给你的STM32循迹小车降功耗提性能 在嵌入式开发领域,电机驱动模块的选择往往决定了整个项目的能效表现和稳定性。对于参加电子设计竞赛的学生和硬件爱好者来说,如何在有限的电池容量下实现更长的运行时间和更精准的…...

Keil C166汇编头文件路径问题解决方案
1. 问题现象与背景解析作为一名长期使用Keil C166开发工具的嵌入式工程师,我最近在移植一个老项目时遇到了一个典型的路径查找问题。项目混合了C和汇编代码,当我把自定义的DEFS.INC汇编头文件放在项目INC目录下,并在Target Environment中正确…...

RePKG架构深度解析:Wallpaper Engine资源逆向工程与高性能转换方案
RePKG架构深度解析:Wallpaper Engine资源逆向工程与高性能转换方案 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg RePKG是一款专为Wallpaper Engine设计的C#开源工具&a…...

Mapbox Studio Classic快速上手:10分钟创建你的第一个地图项目
Mapbox Studio Classic快速上手:10分钟创建你的第一个地图项目 【免费下载链接】mapbox-studio-classic 项目地址: https://gitcode.com/gh_mirrors/ma/mapbox-studio-classic Mapbox Studio Classic是一款强大的地图设计工具,通过直观的界面和简…...

量子机器学习实战:用变分量子电路对泰坦尼克数据集分类
1. 项目概述:当量子计算遇上经典分类难题量子机器学习(QML)听起来像是科幻小说里的概念,但如果你像我一样,在经典机器学习领域摸爬滚打多年,再一头扎进量子计算的海洋,你会发现它更像是一场激动…...
的默认证书替换为自己企业CA的证书)
将vCenter(VCSA)的默认证书替换为自己企业CA的证书
安装了vCenter之后访问其页面,默认的证书并不被Windows系统信任,浏览器提示不安全的网站;如果之前曾经给ESXi主机替换过合法证书,加入vCenter的数据中心之后,证书也被换为vCenter的不合法证书了。注:如果Ed…...

Selenium WebDriver协议层原理与稳定性实战
1. 这不是“又一个Selenium教程”——它解决的是你写完第一行代码后立刻卡住的问题“Selenium WebDriver教程”这六个字,我过去三年在团队内部文档、外包需求评审、新人入职培训材料里见过至少278次。但几乎每次打开,都只看到“安装ChromeDriver”“启动…...